深入理解前端缓存
sorryhc 2024-07-02 15:33:02 阅读 90
前端缓存是所有前端程序员在成长历程中必须要面临的问题,它会让我们的项目得到非常大的优化提升,同样也会带来一些其它方面的困扰。大部分前端程序员也了解一些缓存相关的知识,比如:强缓存、协商缓存、cookie等,但是我相信大部分的前端程序员不了解它们的缓存机制。接下来我将带你们深入理解缓存的机制以及缓存时间的判断公式,如何合理的使用缓存机制来更好的提升优化。我将会把前端缓存分成HTTP缓存和浏览器缓存两个部分来和大家一起聊聊。
HTTP 缓存
HTTP是一种超文本传输协议,它通常运行在TCP之上,从浏览器Network中可以看到,它分为Respnse Headers(响应头)、Request Headers(请求头)两部分组成。
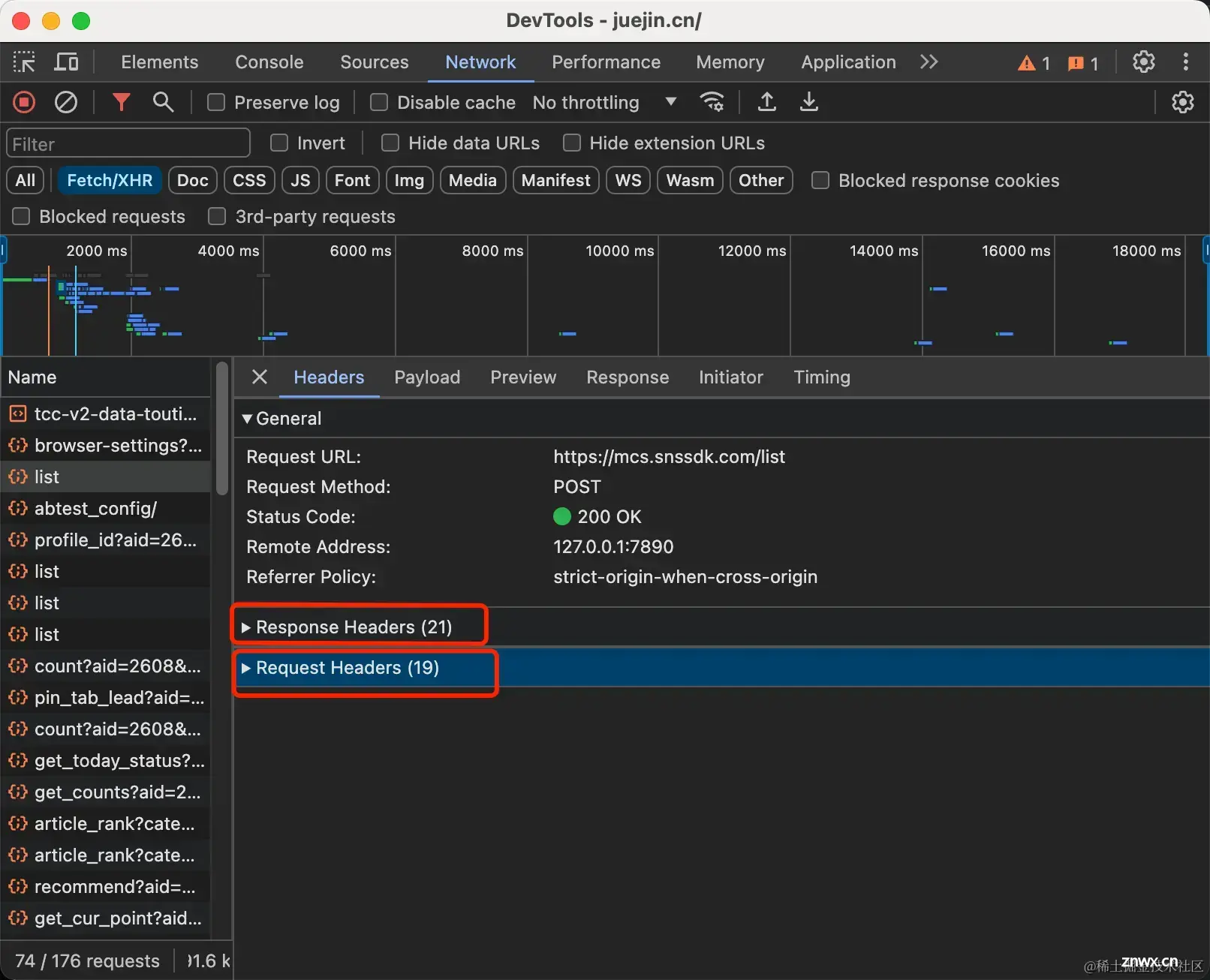
接下来介绍一下与缓存相关的头部字段:
expires
我们先来看一下MDN对于expires的介绍
响应标头包含响应应被视为过期的日期/时间。
备注: 如果响应中有指令为
max-age或s-maxage的Cache-Control标头,则Expires标头会被忽略。
Expires: Wed, 24 Apr 2024 14:27:26 GMT
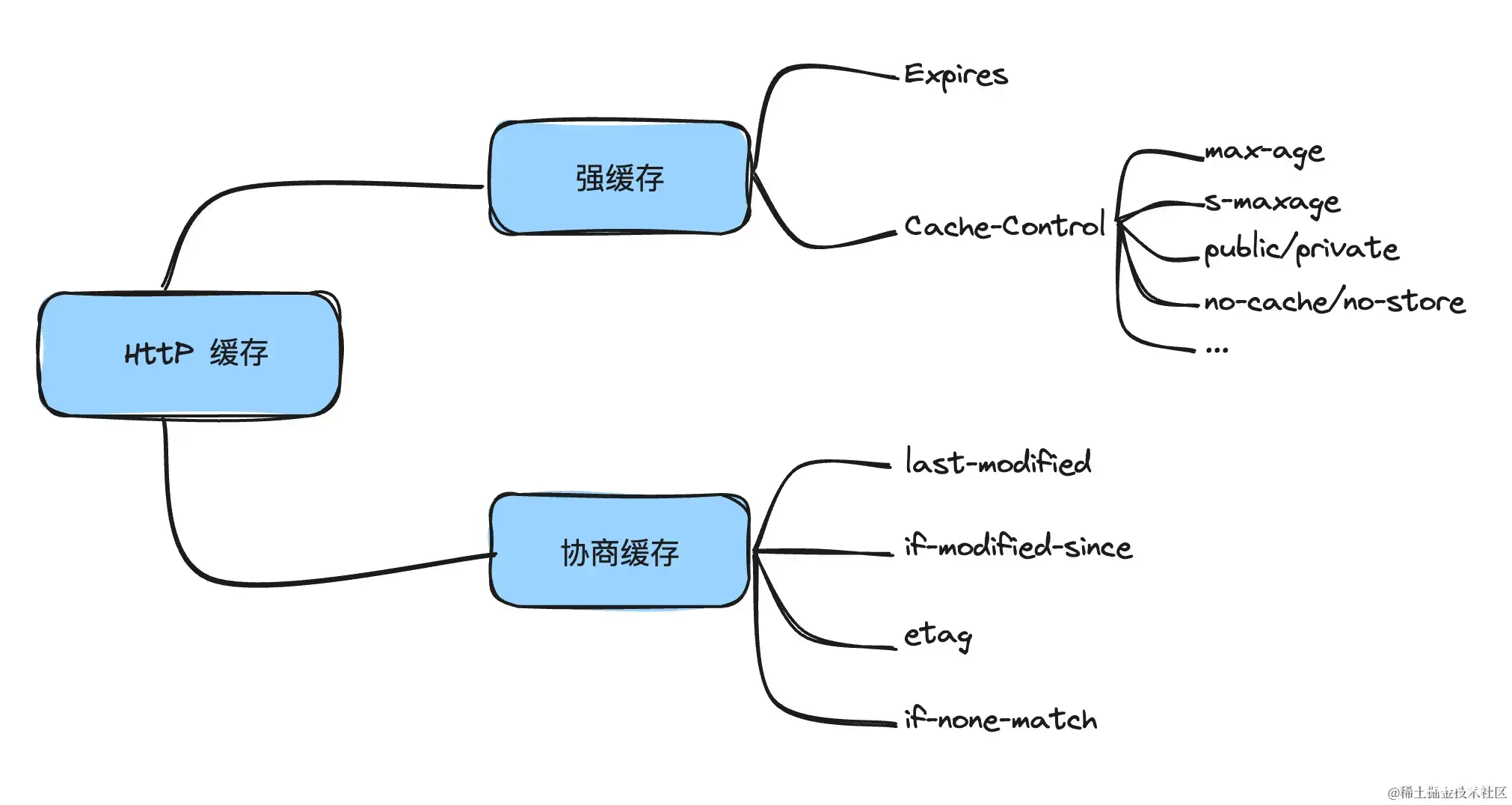
Cache-Control
Cache-Control是HTTP/1.1中定义的缓存字段,它可以由多种组合使用,分开列如:max-age、s-maxage、public/private、no-cache/no-store等
Cache-Control: max-age=3600, s-maxage=3600, public
max-age是相对当前时间,单位是秒,当设置max-age时则expires就会失效,max-age的优先级更高。
而 s-maxage 与 max-age 不同之处在于,其只适用于公共缓存服务器,比如资源从源服务器发出后又被中间的代理服务器接收并缓存。
public是指该资源可以被任何节点缓存,而private只能提供给客户端缓存。当设置了private之后,s-maxage则会无效
。
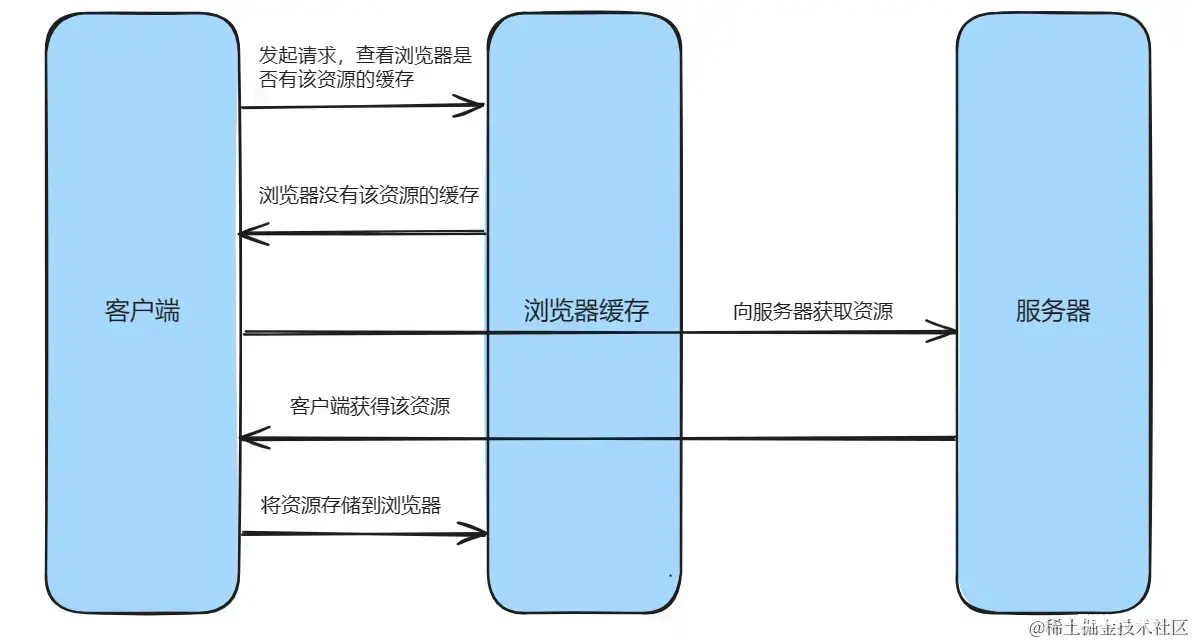
强缓存
强缓存的具体流程如下:
上面我们介绍了expires设置的是绝对的时间,它会根据客户端的时间来判断,所以会造成expires不准确,如果我有一个资源缓存到到期时间是2024年4月31日我将客户端时间修改成过期的时间,则在一次访问该资产会重新请求服务器获取最新的数据。
而max-age则是相对的时间,它的值是以秒为单位的时间,但是max-age也会不准确。
那么到底浏览器是怎么判断该资源的缓存是否有效的呢?这里就来介绍一下资源新鲜度的公式。
我们来用生活中的食品新鲜度来举例:
食品是否新鲜 = (生产日期 + 保质期) > 当前日期
那么缓存是否新鲜也可以借助这个公式来判断
缓存是否新鲜 = (创建时间 + expire || max-age) > 缓存使用期
这里的创建时间可以理解为服务器返回资源的时间,它和expires一样是一个绝对时间。
缓存使用期 = 响应使用期 + 传输延迟时间 + 停留缓存时间
响应使用期
响应使用期有两种获取方式:
max(0, responseTime - dateTime)age
responseTime: 是指客户端收到响应的时间
dateTime: 是指服务器创建资源的时间
age:是响应头部的字段,通常是秒为单位
传输延迟时间
传输延迟的时间 = 客户端收到响应的时间 - 请求时间
停留时间
停留时间 = 当前客户端时间 - 客户端收到响应的时间
所以max-age也会失效的问题就是它也使用到了客户端的时间。
协商缓存
协商缓存的具体流程如下:
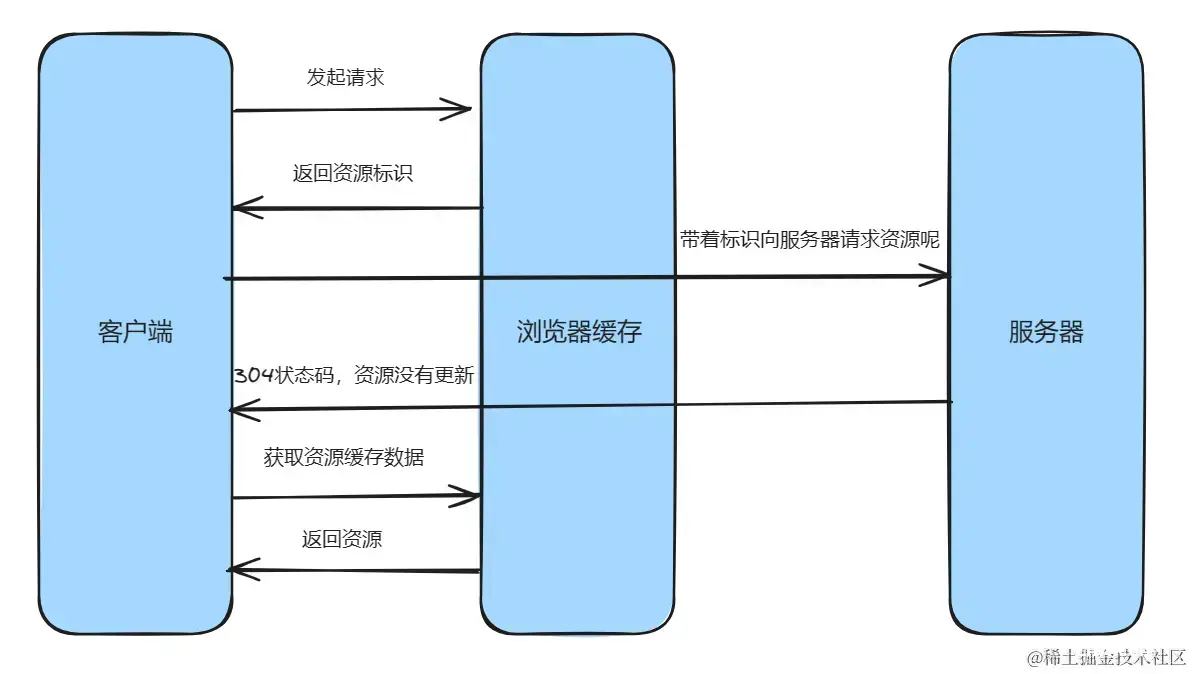
从上文可以知道,协商缓存就是通过Etag和Last-Modified这两个字段来判断。那么这个Etag的标识是如何生成的呢?
我们可以看node中etag第三方库。
该库会通过isState方法来判断文件的类型,如果是文件形式的话就会使用第一种方法:通过文件内容和修改时间来生成Etag。

第二种方法:通过文件内容和hash值和内容长度来生成Etag。

浏览器缓存
我们访问掘金的网站,查看Network可以看到有Size列有些没有大小的,而是disk cache、memory cache这样的标识。
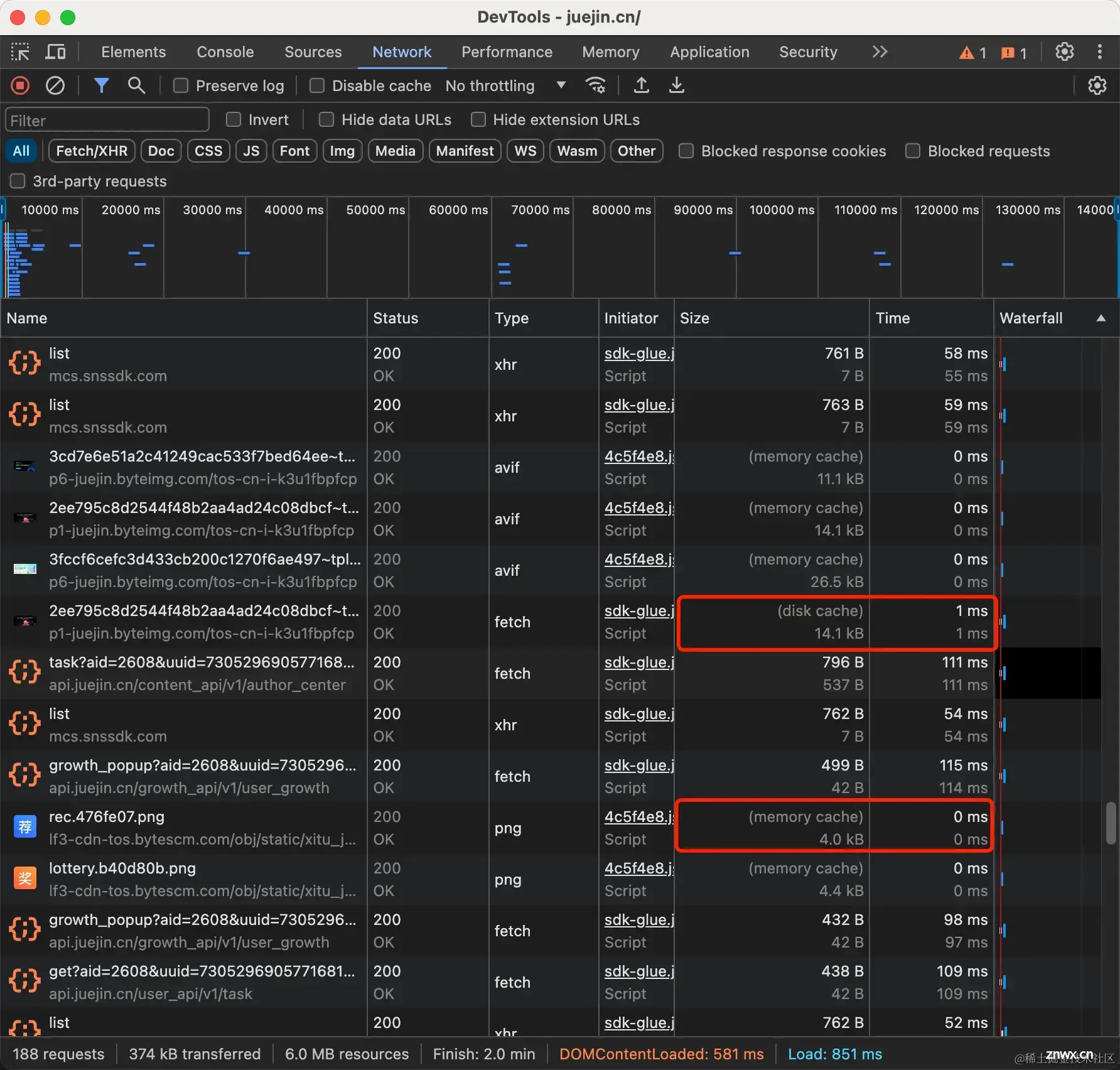
memory cache翻译就是内存缓存,顾名思义,它是存储在内存中的,优点就是速度非常快,可以看到Time列是0ms,缺点就是当网页关闭则缓存也就清空了,而且内存大小是非常有限的,如果要存储大量的资源的话还是使用磁盘缓存。
disk cache翻译就是磁盘缓存,它是存储在计算机磁盘中的一种缓存,它的优缺点和memory cache相反,它的读取是需要时间的,可以看到上方的图片Time列用了1ms的时间。
缓存获取顺序
浏览器会先查找内存缓存,如果存在则直接获取内存缓存中的资源内存缓存没有,就回去磁盘缓存中查找,如果存在就返回磁盘缓存中的资源磁盘缓存没有,那么就会进行网络请求,获取最新的资源然后存入到内存缓存或磁盘缓存
缓存存储优先级
浏览器是如何判断该资源要存储在内存缓存还是磁盘缓存的呢?
打开掘金网站可以看到,发现除了base64图片会从内存中获取,其它大部分资源会从磁盘中获取。
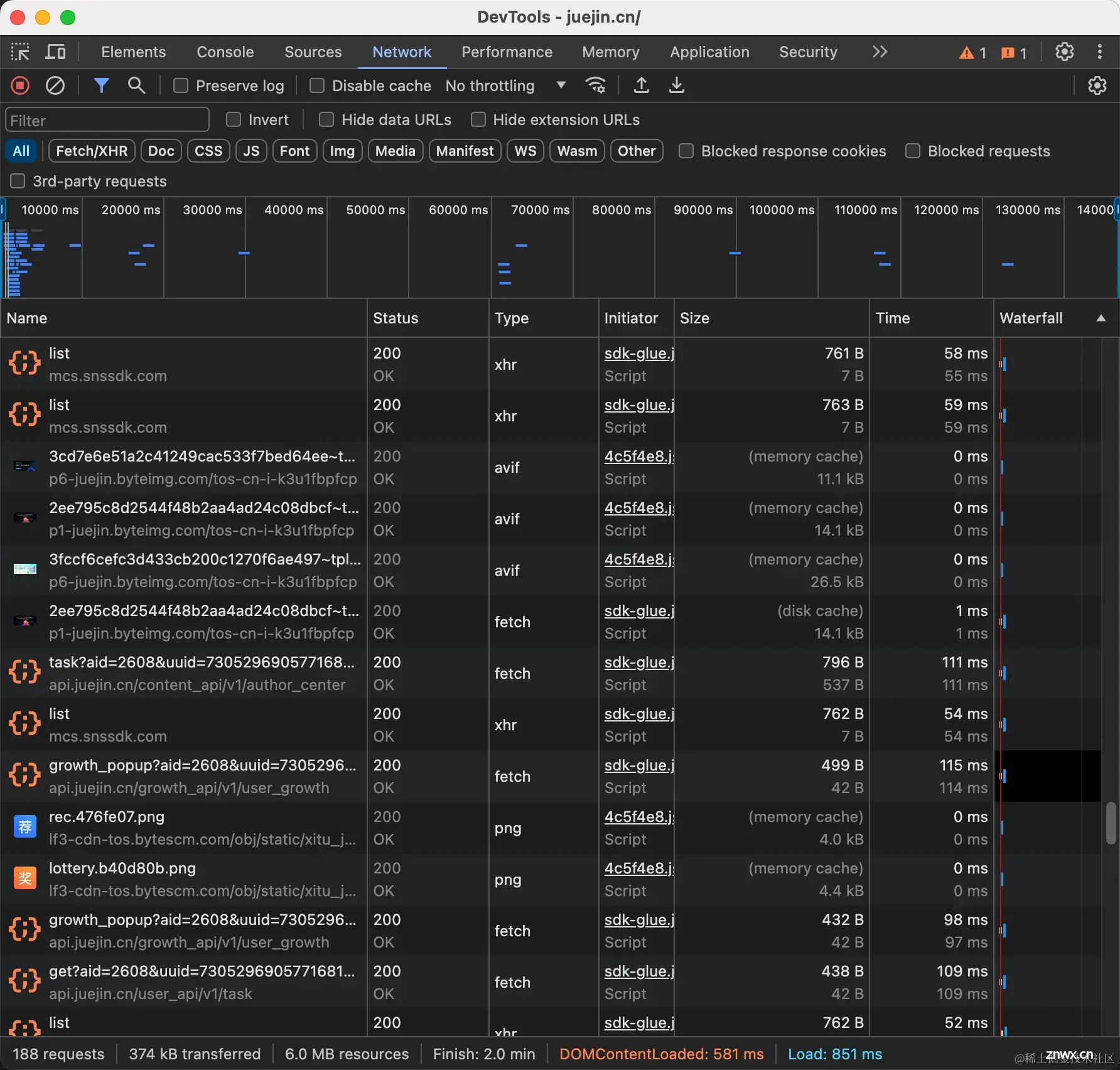
js文件是一个需要注意的地方,可以看到下面的有些js文件会被磁盘缓存有些则会被内存缓存,这是为什么呢?
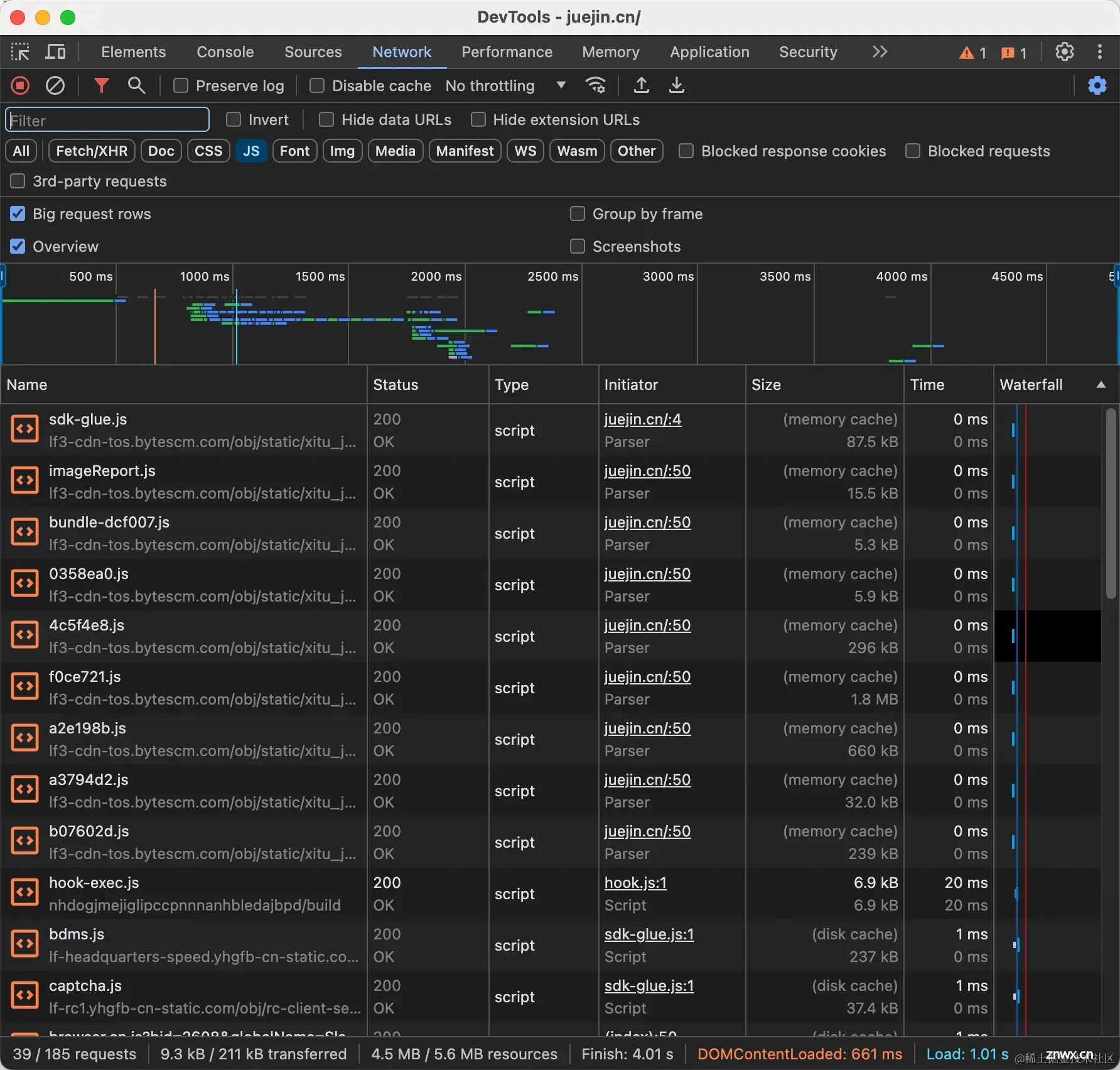
Initiator列表示资源加载的位置,我们点击从内存获取资源的该列发现资源在HTML渲染阶段就被加载了,列入一下代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>DocumentÏ</title>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.7.1/jquery.min.js"></script>
</head>
<body>
<div id="root">这样加载的js资源大概率会存储到内存中</div>
</body>
</html>
而被内存抛弃的可以发现就是异步资源,这些资源不会被缓存到内存中。
上图我们可以看到有一个Initiator列的值是(index):50但是它还是被内存缓存了,我们可以点击进去看到他的代码如下:
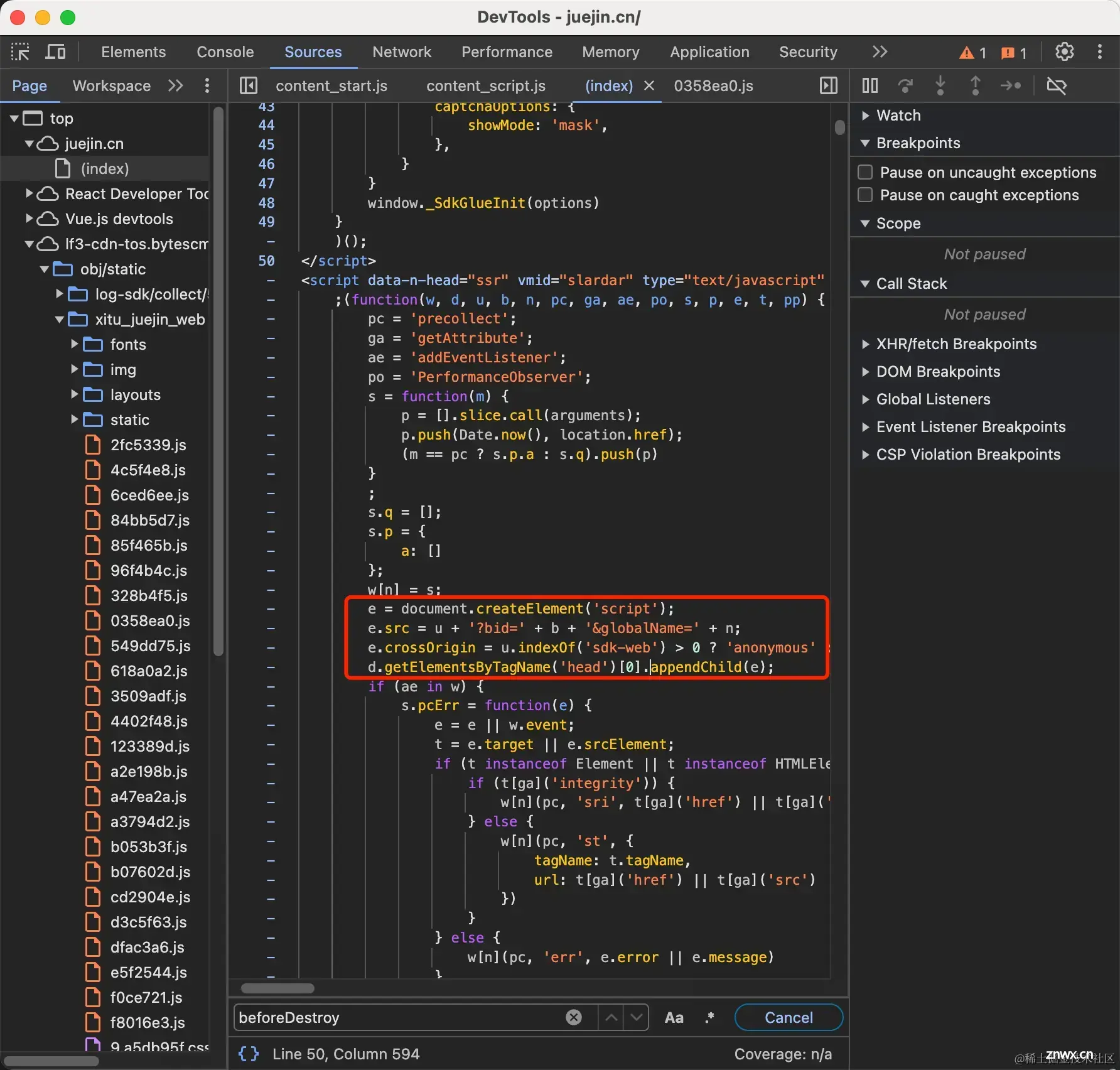
这个js文件还是通过动态创建script标签来动态引入的。
Preload 与 Prefetch
Preload和Prefetch也会影响浏览器缓存的资源加载。
Preload称为预加载,用在link标签中,是指哪些资源需要页面加载完成后立刻需要的,浏览器会在渲染机制介入前加载这些资源。
<link rel="preload" href="//lf3-cdn-tos.bytescm.com/obj/static/xitu_juejin_web/0358ea0.js" as="script">
当使用preload预加载资源时,这些资源一直会从磁盘缓存中读取。
prefetch表示预提取,告诉浏览器下一个页面可能会用到该资源,浏览器会利用空闲时间进行下载并存储到缓存中。
<link rel="prefretch" href="//lf3-cdn-tos.bytescm.com/obj/static/xitu_juejin_web/0358ea0.js"Ï>
使用 prefetch 加载的资源,刷新页面时大概率会从磁盘缓存中读取,如果跳转到使用它的页面,则直接会从磁盘中加载该资源。
使用no-store表示不进行资源缓存。使用no-cache表示告知(代理)服务器不直接使用缓存,要求向源服务器发起请求,而当在响应首部中被返回时,表示客户端可以缓存资源,但每次使用缓存资源前都必须先向服务器确认其有效性,这对每次访问都需要确认身份的应用来说很有用。
当然,我们也可以在代码里加入 meta 标签的方式来修改资源的请求首部:
<meta http-equiv="Cache-Control" content="no-cache" />
示例
这里我起了一个nestjs的服务,该getdata接口缓存10s的时间,Ï代码如下:
@Get('/getdata')
getData(@Response() res: Res) {
return res.set({ 'Expires': new Date(Date.now() + 10).toUTCString() }).json({
list: new Array(1000000).fill(1).map((item, index) => ({ index, item: 'index' + index }))
});Ï
}
第一次请求,花费了334ms的时间。
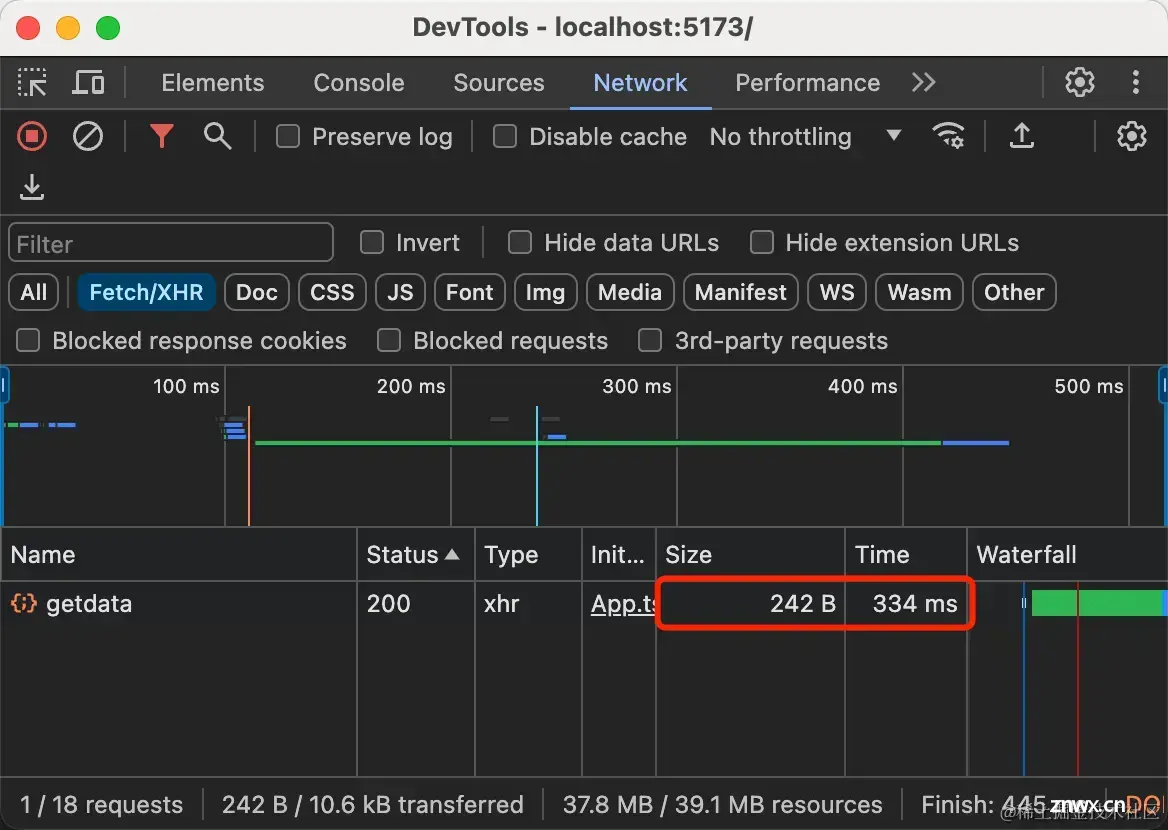
第二次请求花费了163ms的时间,走的是磁盘缓存,快了近50%的速度
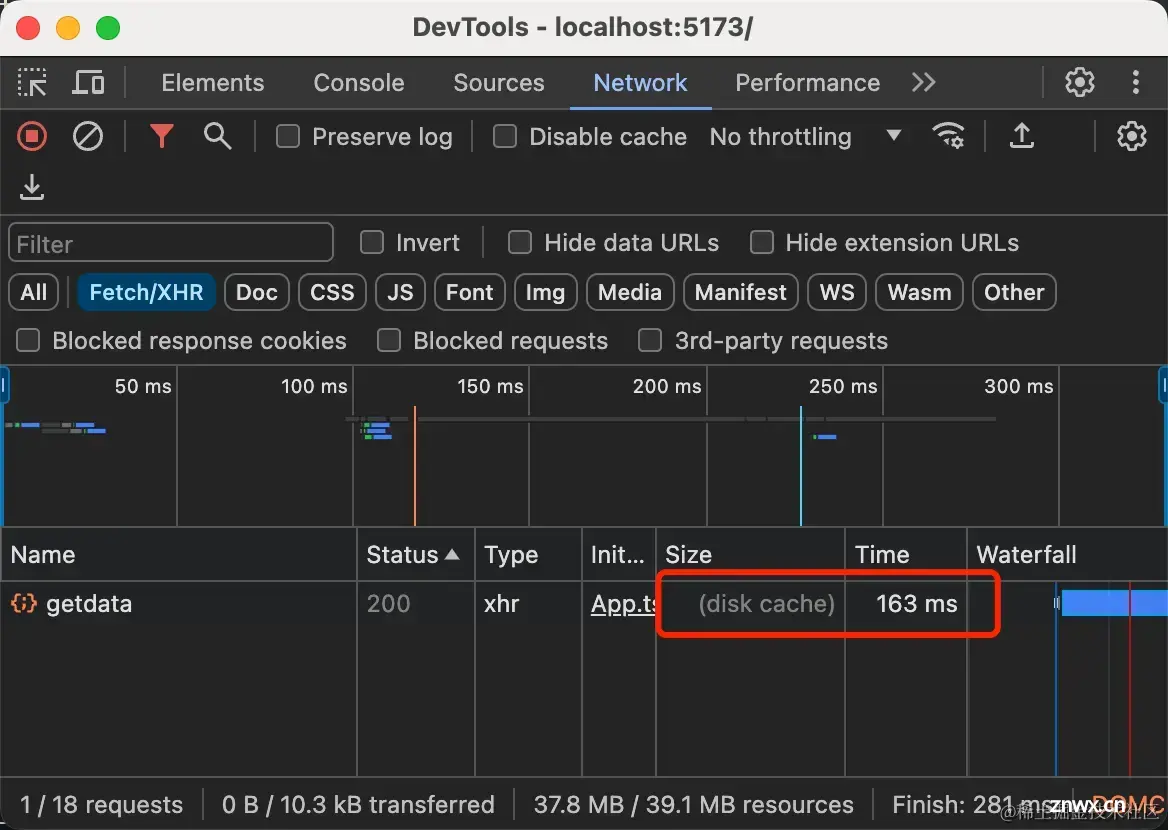
接下来我们来验证使用Cache-Control是否可以覆盖Exprie,我们将getdata接口修改如下,Cache-Control设置了1s。Ï我们刷新页面可以看到getdata接口并没有缓存,每次都会想服务器发送请求。
@Get('/getdata')
getData(@Response() res: Res) {
return res.set({ 'Expires': new Date(Date.now() + 10).toUTCString(), 'Cache-Control': 1 }).json({
list: new Array(1000000).fill(1).map((item, index) => ({ index, item: 'index' + index }))
});
}
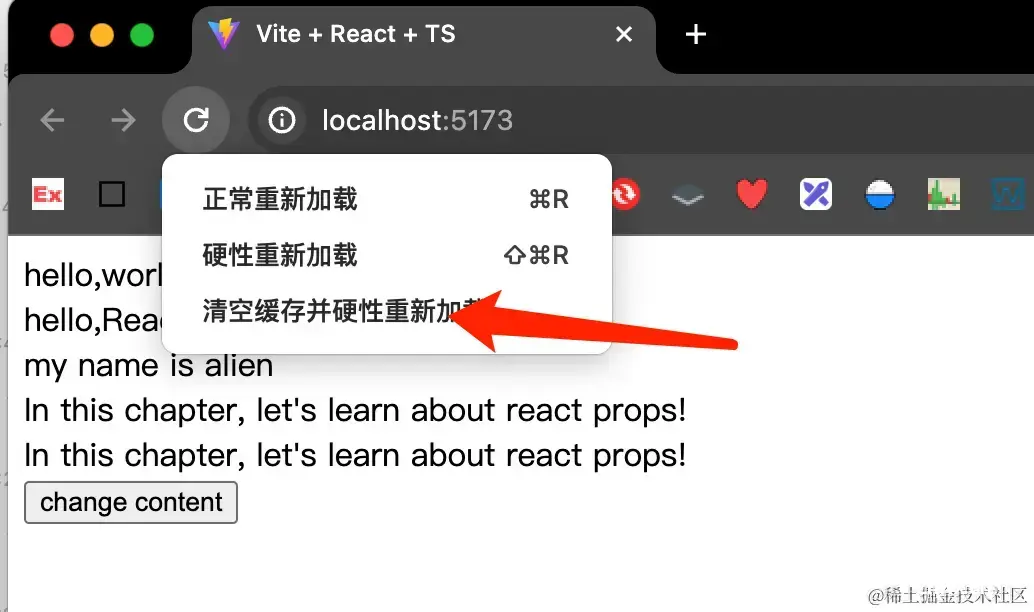
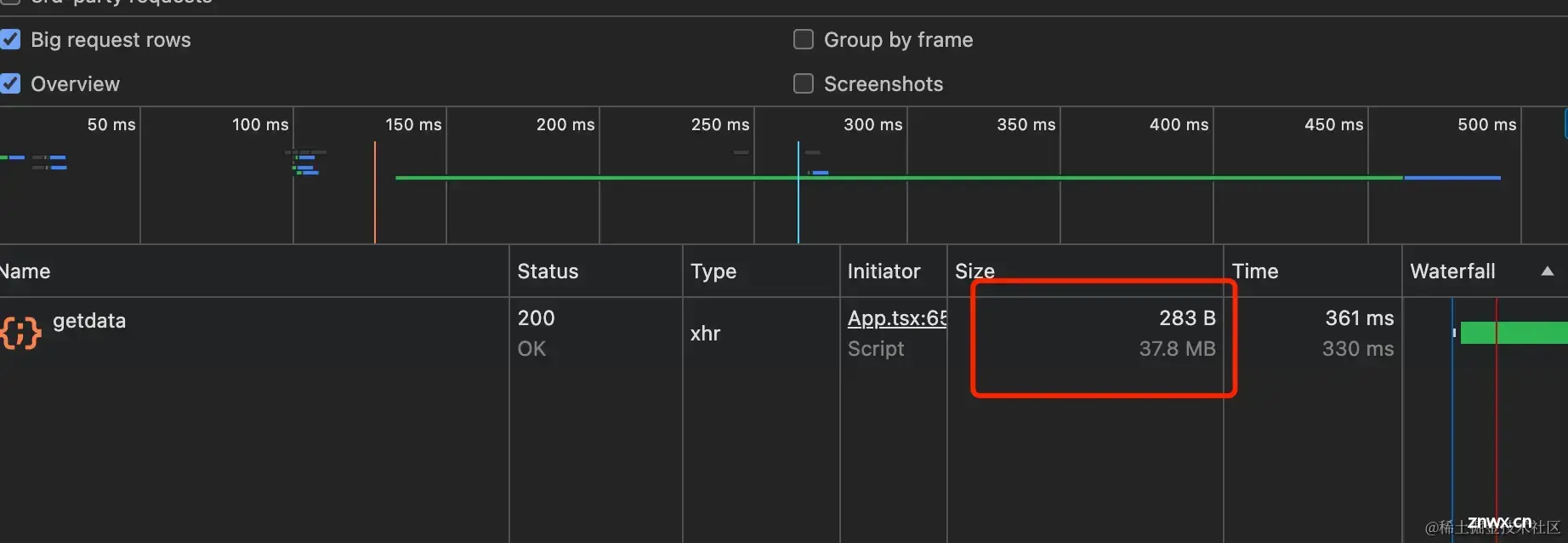
仔细的同学应该会发现一个问题,清除缓存后的第一次请求和第二次请求Size的大小不一样,这是为什么呢?
打开f12右键刷新按钮,点击清空缓存并硬性重新加载。
我们开启Big request rows更方便查看Size的大小,开启时Size显示两行,第一行就是请求内容的大小,第二行则是实际的大小。
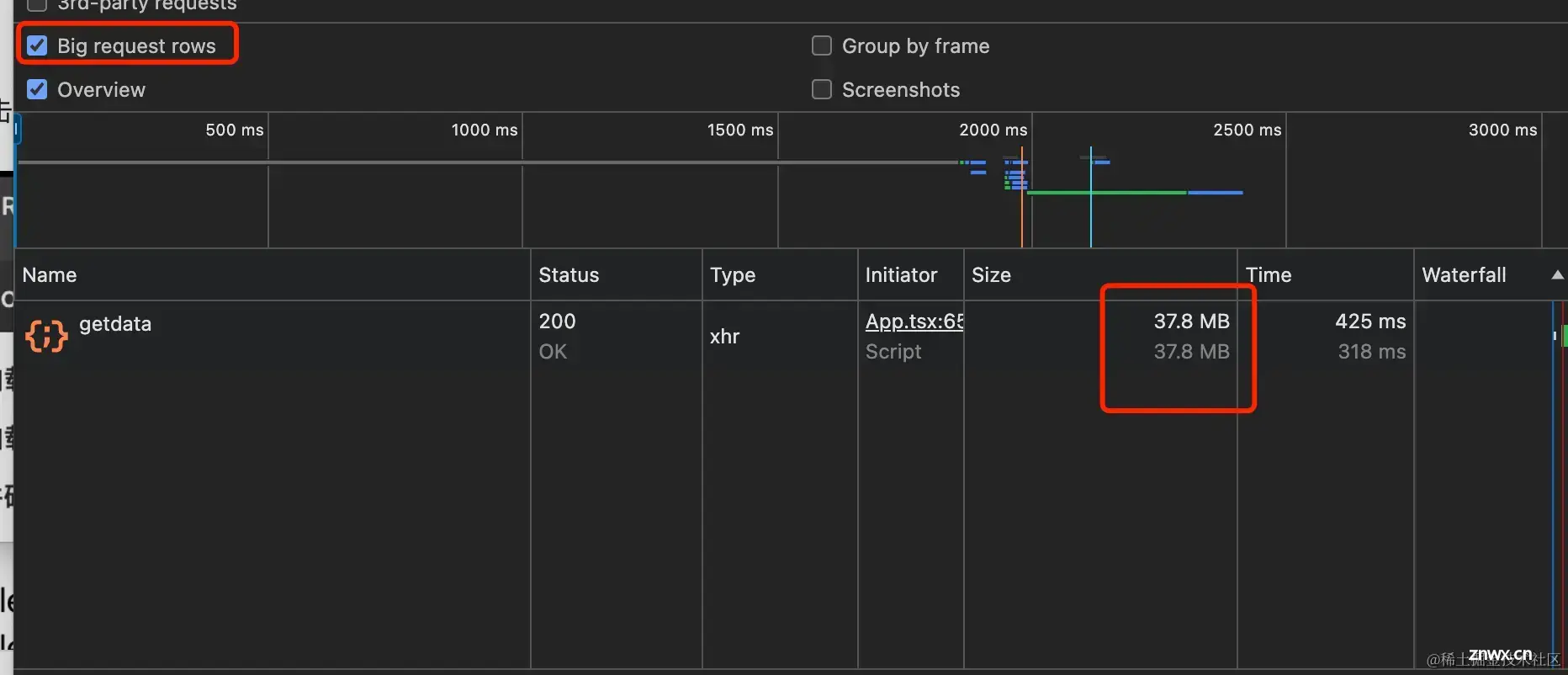
刷新一下,可以看到Size变成了283B大小了。
带着这个问题我们来深入研究一下浏览器的压缩。HTTP2和HTTP3的压缩算法是大致相同,我们就拿HTTP2的压缩算法(HPACK)来了解一下。
HTTP2 HPACK压缩算法
HPACK压缩算法大致分为:静态Huffman(哈夫曼)压缩和动态Huffman哈夫曼压缩,所谓静态压缩是指根据HTTP提供的静态字典表来查找对应的请求头字段从而存储对应的index值,可以极大的减少内催空间。
动态压缩它是在同一个会话级的,第一个请求的响应里包含了一个比如 {list: [1, 2, 3]},那么就会把它存进表里面,后续的其它请求的响应,就可以只返回这个 header 在动态表里的索引,实现压缩的目的
需要详细了解哈夫曼算法原理的可以去这个博客看一看。
Last-Modified 与 If-Modified-Since
Last-Modified代表资源的最后修改时间,其属于响应首部字段。当浏览器第一次接收到服务器返回资源的 Last-Modified 值后,其会把这个值存储起来,并下次访问该资源时通过携带If-Modified-Since请求首部发送给服务器验证该资源是否过期。
yaml
复制代码
Last-Modified: Fri , 14 May 2021 17:23:13 GMT
If-Modified-Since: Fri , 14 May 2021 17:23:13 GMT
如果在If-Modified-Since字段指定的时间之后资源都没有发生更新,那么服务器会返回状态码 304 Not Modified 的响应。
Etag 与 If-None-Match
Etag代码该资源的唯一标识,它会根据资源的变化而变化着,同样浏览器第一次收到服务器返回的Etag值后,会把它存储起来,并下次访问该资源通过携带If-None-Match请求首部发送给服务器验证资源是否过期
Etag: "29322-09SpAhH3nXWd8KIVqB10hSSz66"
If-None-Match: "29322-09SpAhH3nXWd8KIVqB10hSSz66"
如果两者不相同则代表服务器资源已经更新,服务器会返回该资源最新的Etag值。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。