(三)InfluxDB入门(借助Web UI)
灵泽~ 2024-08-01 09:03:01 阅读 61
以下内容来自 尚硅谷,写这一系列的文章,主要是为了方便后续自己的查看,不用带着个PDF找来找去的,太麻烦!
第 3 章 InfluxDB入门(借助Web UI)
借助Web UI,我们可以更好地理解InfluxDB的功能划分。接下来,我们就从Web UI入手,先了解InfluxDB的基本功能。
3.1 数据源相关
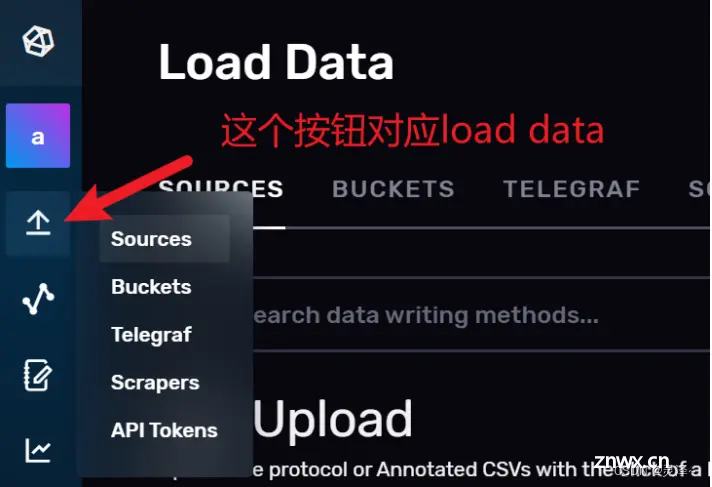
3.1.1 Load Data(加载数据)

如图所示,页面上左侧的向上箭头,对应着InfluxDB Web UI的Load Data(加载数据)页面。
3.1.1.1 上传数据文件
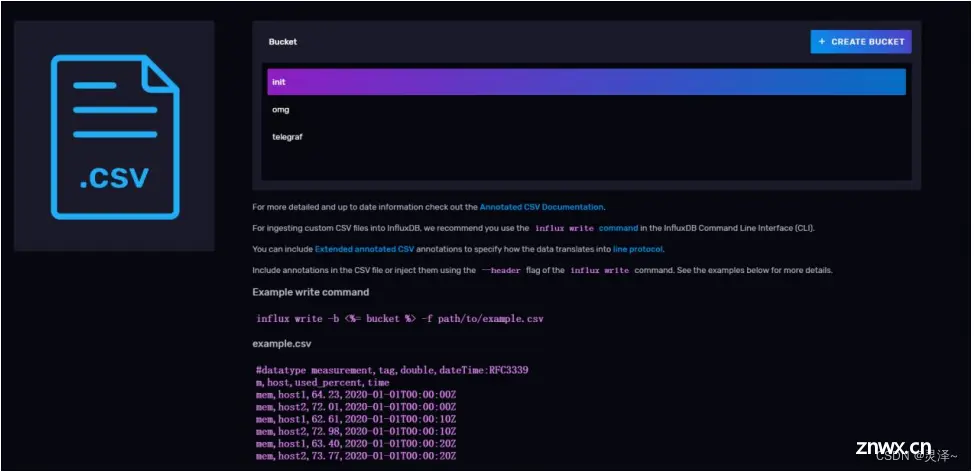
在Web UI上,你可以用文件的方式上传数据,前提是文件中的数据符合InfluxDB支持的类型,包括CSV、带Flux注释的CSV和InfluxDB行协议。

点击其中任意一个按钮,将进入数据的上传页面,页面中包含了详细的说明文档,包含你的数据应该符合什么格式,你要把数据放到哪个存储桶里,还包括用命令行来上传数据的命令模板。
3.1.1.2 写入InfluxDB的代码模板
InfluxDB提供了各种编程语言的连接库,你甚至可以在前端嵌入向InfluxDB写入数据的代码,因为InfluxDB向外提供了一套功能完整的REST API。
点击任何一个语言的LOGO,你会看到使用这门语言,将数据写入到InfluxDB的代码模板。建议从这里拷贝初始化客户端的代码
配置Telegraf的输入插件
Telegraf是一个插件化的数据采集组件,在这里你可以找一下没有对应你的目标数据源的插件,点击它的logo。可以看到这个插件配置的写法,但是关于这方面的内容,还是建议参考Telegraf的官方文档,那个更细更全一些。
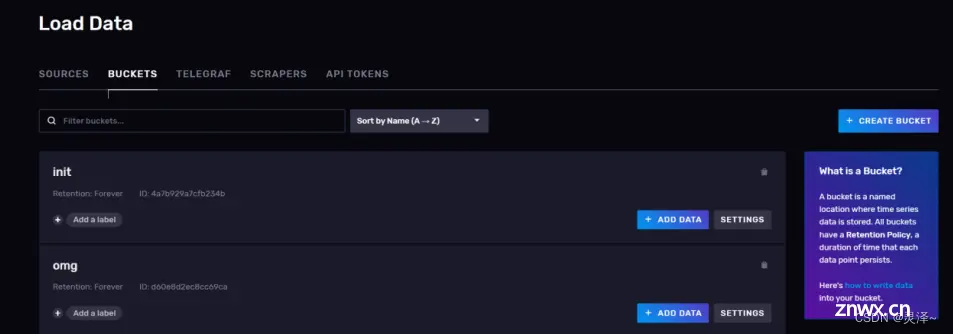
3.1.2 管理存储桶
你可以将InfluxDB中的bucket理解为普通关系型数据库中的database。在Load data页面上,点击上访的BUCKETS选项卡,就可以进入bucket管理页面了。
3.1.2.1 创建Bucket
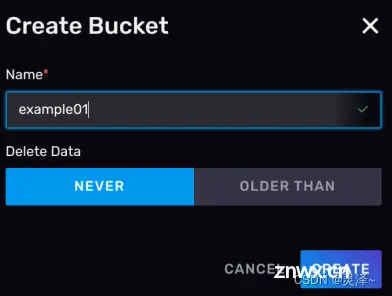
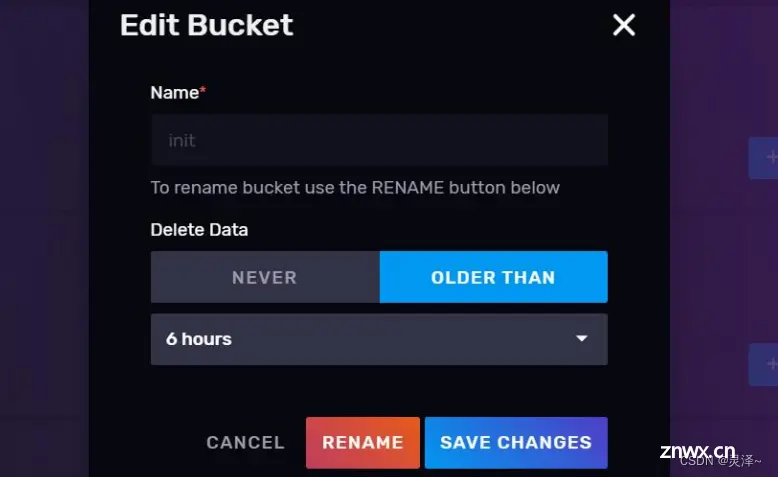
点击右上角的CREATE BUCKET按钮,会有一个创建存储桶的弹窗,这里你可以给bucket指定一个名称和数据的过期时间。比如,你设置过期时间为 6 小时,那InfluxDB就会自动把这个存储桶中距离当前时间超过 6 小时的数据删除。
3.1.2.2 调整Bucket的设置
存储桶的过期时间的名称都是可以修改的,点击任一Bucket信息卡的SETTINGS按钮会弹出一个调整设置的会话框。

重命名是 InfluxDB不建议的操作,因为大量的代码和InfluxDB定时任务都需要通过指定Bucket的名称来进行连接,贸然更改Bucket的名称可能导致这些程序无法正常工作。
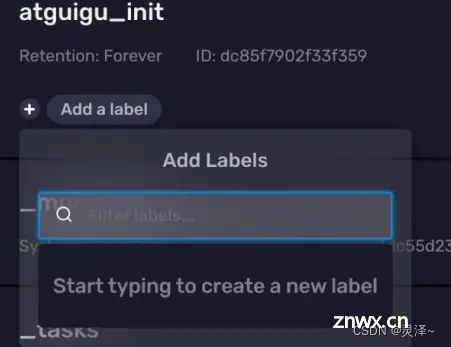
3.1.2.3 设置Label
在每个Bucket信息卡的左下方都有一个 Add a label按钮,点击这个按钮,你可以为Bucket添加一个标签。不过这个功能一般很少用
3.1.2.4 向Bucket添加数据
每个存储桶信息卡的右边都有一个添加数据按钮,点击这个按钮可以快速导入一些数据。这里还可以创建一个抓取任务(被抓取的数据在格式上必须符合prometheus数据格式)
3.1.3 示例 1 :创建Bucket并从文件导入数据
3.1.3.1 创建Bucket
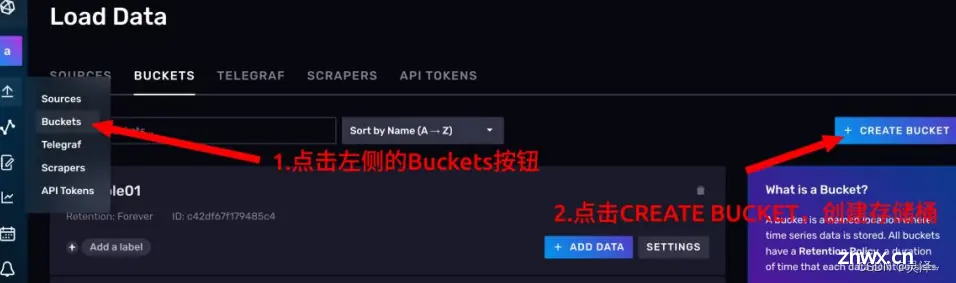
1、将鼠标悬停在左侧的按钮上,点击 Buckets,进入Bucketde的管理页面。
2、点击 CREATE BUCKET按钮,指定一个名称,这里我们将其设为example01,删除策略保留默认的NEVER,表示永远不会删除数据
3、点击CREATE按钮,可以看到我们的Buckets已经创建成功了。
3.1.3.2 进入上传数据引导页面
在Load Data页面,点击Line Prtocol进入InfluxDB行协议格式数据的上传引导页面。
3.1.3.3 录入数据

1、点击选择存储桶
2、选择ENTER MANUALLY,手动输入数据
3、将数据粘到输入框
4、在右侧指明时间精度,包括纳秒、微秒、毫秒和秒
数据如下:
people,name=tony age=12
people,name=xiaohong age=13
people,name=xiaobai age=14
people,name=xiaohei age=15
people,name=xiaohua age=12
当前我们写的数据格式叫做InfluxDB 行协议。最后点击WRITE DATA,将数据写到InfluxDB。如果出现Data Written Successfully,那么说明数据写入成功。

3.1.3.4 小结
InfluxDB是一个无模式的数据库,也就是除了在输入数据之前需要显示创建存储桶(数据库),你不需要手动创建 measurement或者指定各个field都是什么类型,你甚至可以前后在同一个measurement下插入filed不同的数据。
3.1.4 管理Telegraf数据源
点击Load Data页面的TELEGRAF选项卡,可以快速生成一些Telegraf配置文件。并向外暴露一个端口,允许telegraf远程使用InfluxDB中生成的配置。

3.1.4.1 什么是Telegraf
Telegraf是InfluxDB生态中的一个数据采集组件,它可以讲各种时序数据自动采集到InfluxDB。现在,Telegraf不仅仅是 InfluxDB的数据采集组件了,很多时序数据库都支持与Telegraf进行协作,不少类似的时序数据收集组件选择在Telegraf的基础上二次开发。
3.1.4.2 创建Telegraf配置文件
InfluxDB的Web UI 为我们提供了几种最常用的telegraf配置模板,包括监控主机指标、云原生容器状态指标,nginx和redis等。

通过页面,你可以勾选几种监控目标,然后一步步操作去创建一个 Telegraf的配置文出来。
3.1.4.3 管理Telegraf配置文件接口
完成Telegraf的配置后,页面上会多出一个关于telegraf实例的信息卡。
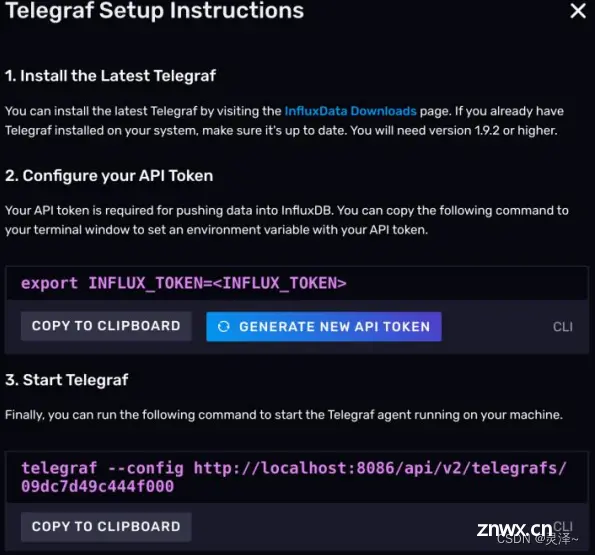
如图所示:点击蓝色的Setup Instructions。

会弹出一个对话框,引导你完成telegraf的配置。可以看到第三步的命令。
telegraf --config http://localhost:8086/api/v2/telegrafs/09dc7d49c444f
这个命令中有一个 URL,其实意思也就是 InluxDB向外提供了一个API,通过这个API你可以访问到刚才生成的配置文件。
3.1.4.4 修改Telegraf配置
已经生成的配置文件如何去修改呢?你可以点击卡片的标题。

这个时候,会弹出一个配置文件的编辑页面,不过这个时候没有交互式的选项了,你需要自己直接面对配置文件。

修改完配置文件后,记得点击右方的SAVE CHANGES保存修改。
3.1.5 示例 2 :使用Telegraf将数据收集到InfluxDB
在本示例中,我们会使用Telegraf这个工具将一台机器上的CPU使用情况转变成时序数据,写到我们的InfluxDB中。
3.1.5.1 下载Telegraf
可以使用下面的命令下载telegraf
wget 1.23.4_linux_amd64.tar.gzhttps://dl.influxdata.com/telegraf/releases/telegraf-1.23.4_linux_amd64.tar.gz
3.1.5.2 解压压缩包
将telegraf解压到目标路径。
tar -zxvf telegraf-1.23.4_linux_amd64.tar.gz -C /opt/module/
3.1.5.3 创建一个新的Bucket
回到Web UI界面
点击左侧工具栏中的Buckets按钮点击右侧蓝色的CREATE BUCKET按钮
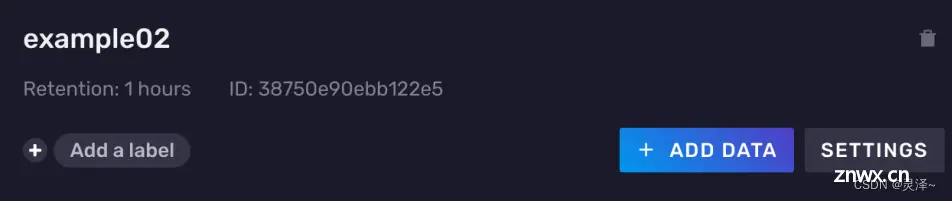
创建一个名为example02的buckets,因为是演示,所以这里将过期时间设为 1 小时。设置好后点击CREATE
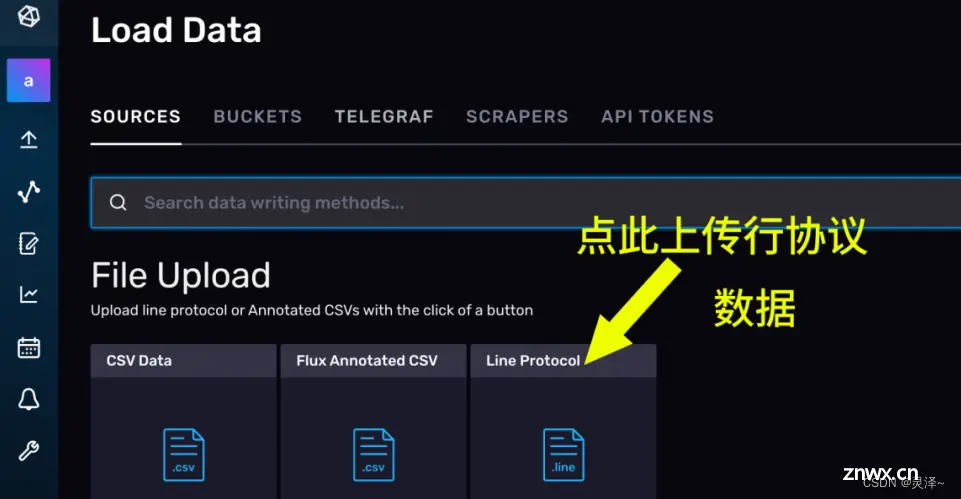
如果出现相应的example02的卡片,说明存储桶已经创建成功。
3.1.5.4 在Web UI上创建telegraf配置文件
1、在左侧的工具栏上点击Telegraf按钮。
2、点击右侧蓝色的CREATE CONFIGURATION创建telegraf配置文件

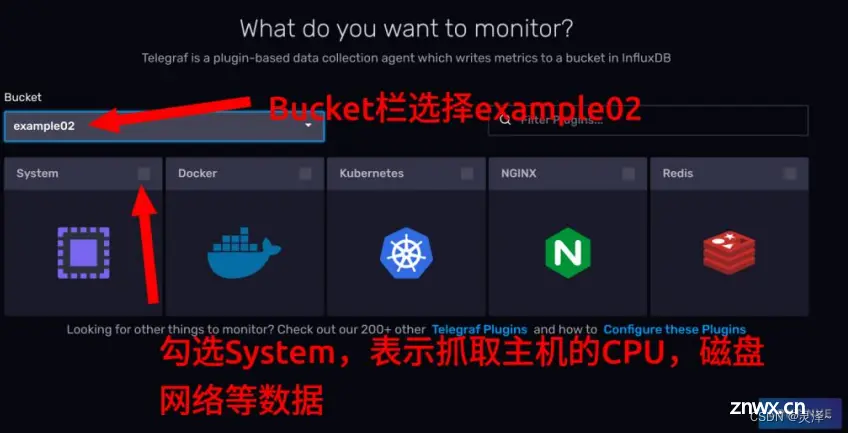
3、在Bucket栏选择example02,表示让telegraf将抓取到的数据写到example02存储桶中,下面的选项卡勾选System。点击CONTINUE。
4、点击 CONTINUE按钮后,会进入一个配置插件的页面。你可以自己决定是否启用这些插件。这里需要给生成的Telegraf配置起一个名字,方便管理。
5、点击CREATE AND VERIFY按钮,这个时候其实Telegraf的配置就已经创建好了,你会进入一个Telegraf的配置引导界面,如图所示:
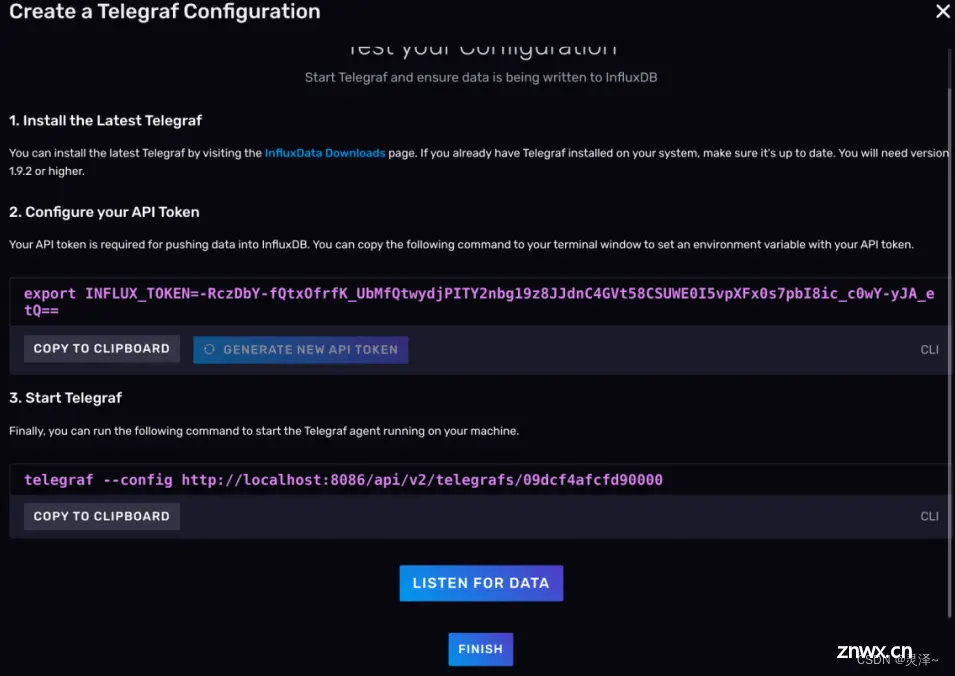
3.1.5.5 声明Telegraf环境变量
按照Web UI上的建议,首先,你要在部署 Telegraf的主机上声明一个环境变量叫 INFLUX_TOKEN,它是用来赋予Telegraf向 InfluxDB写数据权限的。这里我们就不配环境变量了,请在单一的shell会话下完成后面的操作。
所以到你下载好Telegraf的机器上,执行下面的命令。(注意!TOKEN是随机生成的,请按照自己的情况修改命令)
export INFLUX_TOKEN=v4TsUzZWtqgot18kt_adS1r-7PTsMIQkbnhEQ7oqLCP2TQ5Q-PcUP6RMyTHLy4IryP1_2rIamNarsNqDc_S_eA==
3.1.5.6 启动Telegraf
首先cd到我们解压的telegraf目录。
cd /opt/module/telegraf-1.23.4

telegraf的可执行文件在 ./usr/bin目录下。cd过去。
cd ./usr/bin
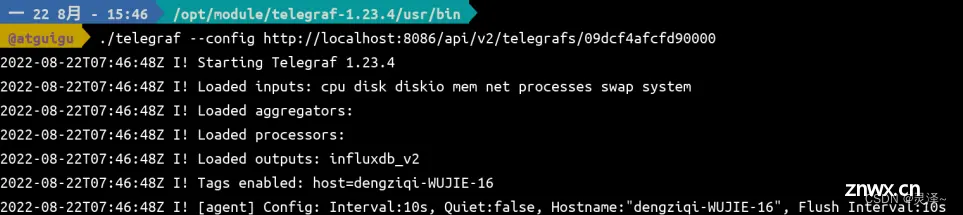
从 Web UI中复制运行 telegraf 的命令,修改 host然后执行,当前的 telegraf 和 InfluxDB 在同一台机器上,所以可以使用localhost。最终命令如下。
telegraf --config http://localhost:8086/api/v2/telegrafs/09dcf4afcfd90000telegraf
运行效果如下图所示。
3.1.5.7 验证数据采集结果
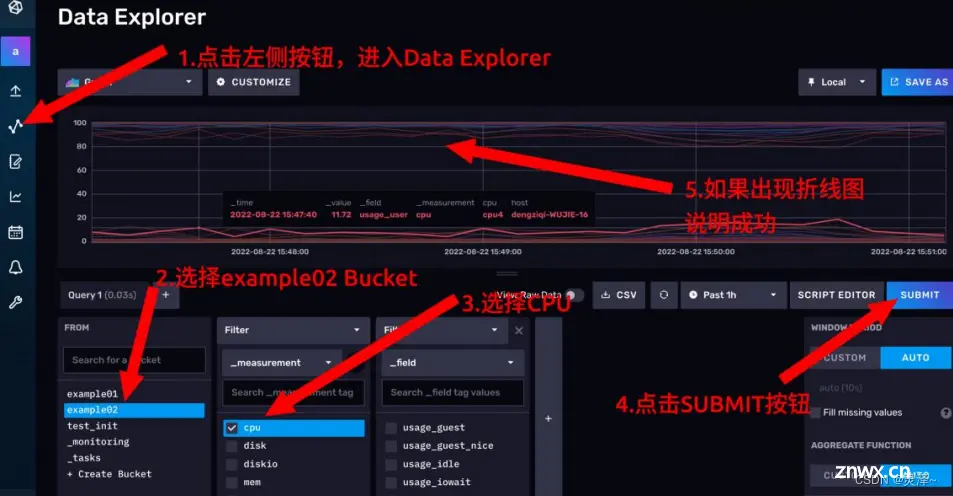
1、点击左侧 按钮进入Data Explorer页面。
2、在左下角第一个选项卡选择example02,表示要从 example02这个存储桶中查数据。
3、点击好第一个选项卡后,会自动弹出第二个选项卡,勾选cpu。
4、点击右上方的SUBMIT按钮。
5、如果出现折线图,说明我们成功地使用Telegraf把数据导进来了。
3.1.5.8 编写启停脚本
后面我们很多时候都要使用telegraf抓取的主机监控数据来进行查询演示。为了方便启停,我们编写一个shell脚本来管理telegraf任务。
1、首先cd到 当前用户家的bin 路径下,如果~路径下没有bin,就创建bin这个目录。通常 ~/bin 是PATH环境变量包含的一个目录。
cd ~
mkdir bin
cd ~/bin
2、到~/bin路径下创建一个文件 host_tel.sh
vim host_tel.sh
3、键入如下内容

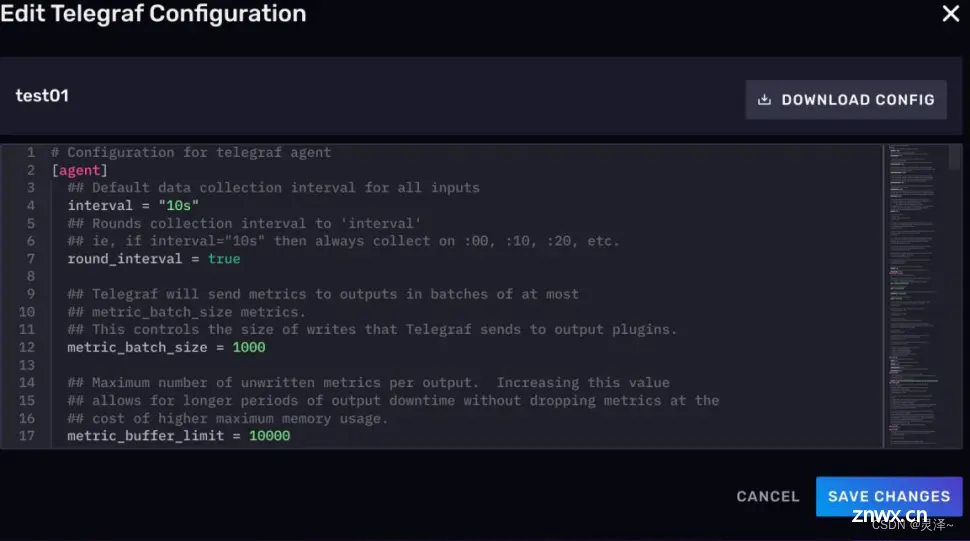
4、最后给这个脚本加上一个执行权限,你可以执行下面的代码。
chmod 755 ./host_tel.sh
3.1.5.9 小结
最终需要注意,InfluxDB只是帮你管理了一下Telegraf的配置文件。InfluxDB并不能管理Telegraf的启停和运行状态。如何运行Telegraf还是需要开发者手动或者编写脚本来维护的。
3.1.6 管理抓取任务
3.1.6.1 什么是抓取任务
抓取任务就是你给定一个URL,InfluxDB每隔一段时间去访问这个链接,把访问到的数据入库。在InfluxDB 1.x的时候,类似的任务只能由Telegraf来实现。在InfluxDB 2.x中,内置了抓取功能(但是定制性上不如Telegraf,比如轮询间隔只能是 10 秒)
另外,目标 URL 暴露出来的数据格式必须得是Prometheus数据格式。关于Prometheus数据格式的详细介绍,大家可以参考附录3
3.1.6.2 InfluxDB自身暴露的监控接口
你可以访问http://localhost:8086/metrics 来查看InfluxDB暴露出来的性能数据。这里面有,InfluxDB的GC情况

以及各个API的使用情况,如图所示,说的是各个API被谁请求过多少次。

3.1.7 示例 3 :让InfluxDB主动拉取数据
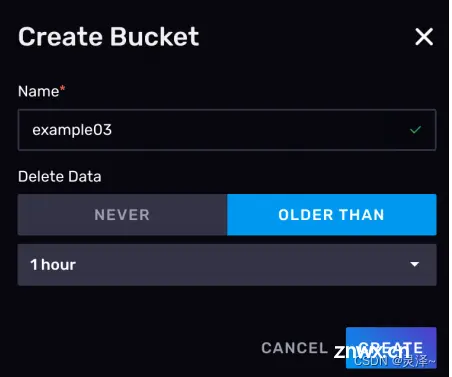
3.1.7.1 创建一个存储桶
如图所示,我们创建了一个名为example03的存储桶。数据的过期时间设为 1 小时。
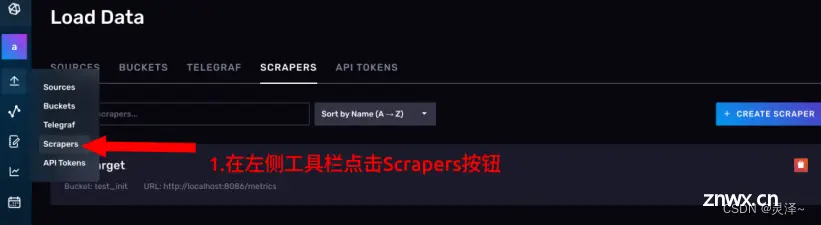
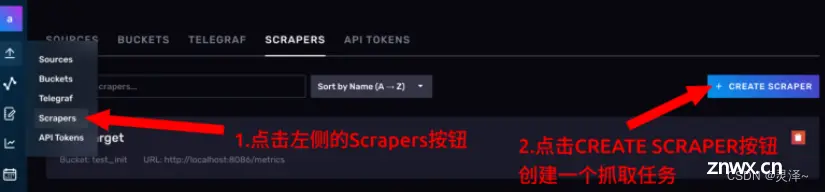
3.1.7.2 创建抓取任务
1、进入抓取任务的管理页面
2、点击CREATE SCRAPER按钮,创建抓取任务。
3、在对话框上,给抓取任务起一个名字,此处命名为example03_scraper
4、右方的下拉框上,选择我们刚才创建的存储桶,example03。
5、最下方设置一下目标路径,最后点击CREATE
6、如果页面上出现新的卡片,说明配置成功。接下来去看一下数据有没有进来。
3.1.7.3 验证抓取结果
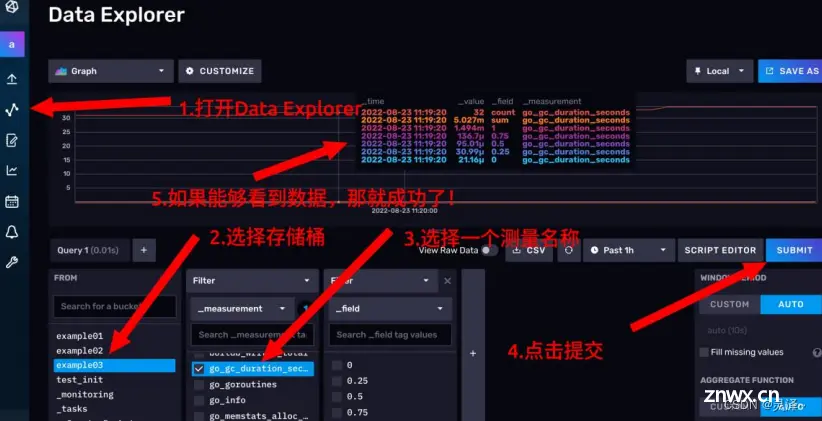
1、点击左侧的按钮,打开Data Explorer
2、在左下角第一个卡片选择要从哪个存储桶抽取数据,本例对应的是example03
3、第一个卡片选择好后,会自动弹出第二个卡片,你可以选择任意一个指标名称。
4、点击右侧的SUBMIT按钮,提交查询。
5、如果折线图成功加载,说明有数据了,抓取成功!
3.1.7.4 补充
1、 InfluxDB的监控数据默认会被抓取到初始化的存储桶中抓取任务管理面板上,我们发现自己还没创建什么东西呢,就有一个抓取任务。
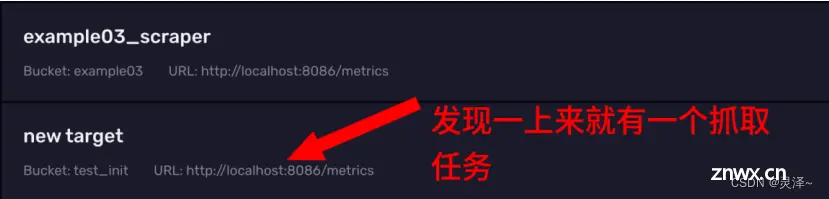
2、 这个抓取任务是InfluxDB自动为我们创建的,它会把我们刚才访问/metrics拿到的数据写到 test_init 这个存储桶中去,而test_init 这个存储桶是我们首次登录的时候为了初始化而创建的。所以大家要知道 test_init 中的一些监控数据是怎么产生的。
3、InfluxDB的抓取任务都是 10 秒一次,无法自定义设置
至少截至目前( 2 .4版本),用户无法去自定义抓取间隔。InfluxDB会每隔 10 秒一次去抓取数据,这一点需要注意。
3.1.8 管理API Token
点击左侧的API Tokens按钮,进入API Token的管理页面。
3.1.8.1 API Token是干什么用的
1、简单来说,influxdb会向外暴露一套HTTP API。我们后面要学的命令行工具什么的,其实都是封装的对 influxdb 的http请求。所以,在InfluxDB中,对权限的管理主要就体现在API的Tokens上。客户端会将token放到http的请求头上,influxdb 服务端就根据客户端发来的请求头部的token,来判断你能不能对某个存储桶读写,能不能删除存储桶,创建仪表盘等。
3.1.8.2 查看API Token权限
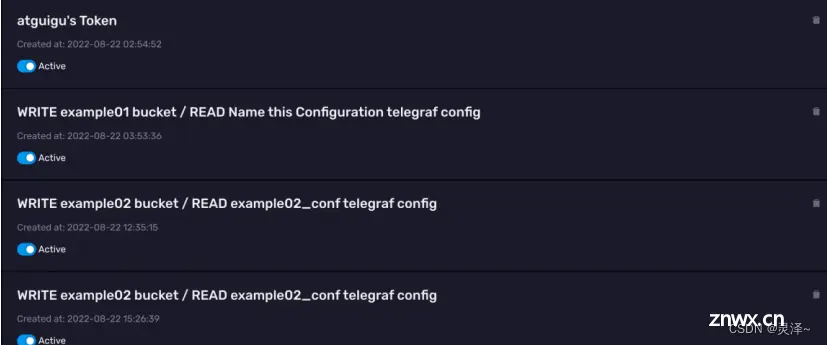
截至目前,我们还没有自己手动创建过API Token。但是可以看到页面上已经有一些Token了,这些Token是由我们之前示例里面的操作自动生成的。
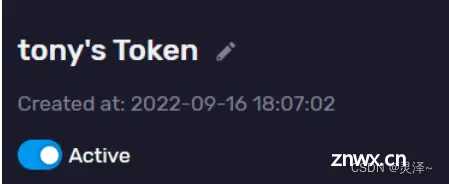
3.1.8.3 了解tony’s Token
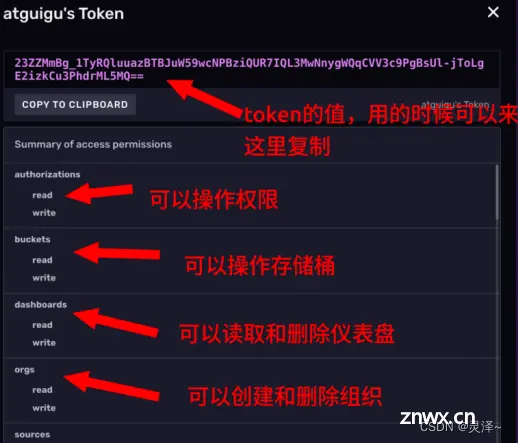
1、现在,我们围绕着InfluxDB中已有的Token来学习相关的知识,我们的InfluxDB上现在只有初始化时创建的tony账户,在Token列表中,我们可以看到有一个名为tony’s Token 的token。
2、 修改token的名称
点击token右边的 符号,可以修改token名称。没有客户端会用token的名称来调用token,所以修改token名称不会影响已经部署的应用。InfluxDB从未要求token的名称必须全局唯一,所以名称重复也是可以的。如图:
3、 token可以临时关停、也可以删除正如你说看到,token卡片下面的Active按钮是一个开关,可以在启用和停用之间进行
切换。
同时,你也可以删除token,但是这可能对你已经部署的应用产生不可挽回的影响。
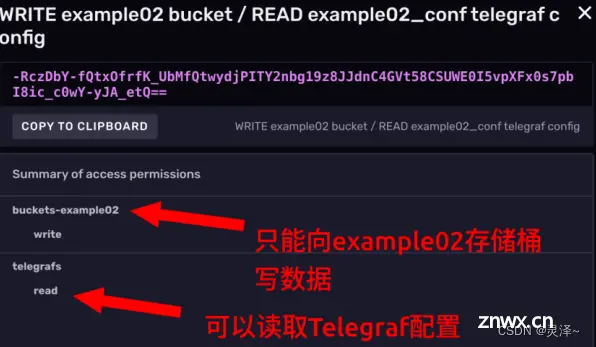
4、 查看Token权限点击token的名称,可以看到这个token具体有哪些权限。这里我们比较两个token,可以看到tony’ Token的权限很高。

5、下面这个Token是我们前面示例,生成Telegraf配置的时候自动生成的token。

6、点开看一下它的权限。可以看到这个token的权限就小得多了,它只能向一个存储桶里写数据,查的权限都没有。
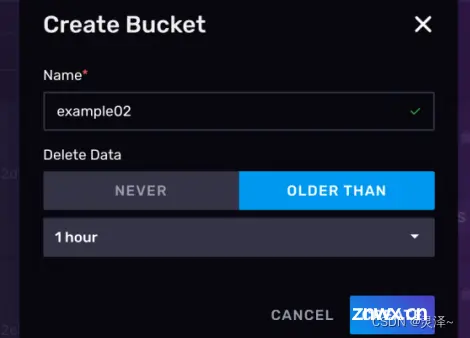
3.1.8.4 创建API Token
1、页面的右方有一个 GENERATE API TOKEN。点一下会出来一个下拉菜单,这其实是Web UI上的权限模板

2、 在Web UI上,有两种类型的模板让你可以快速创建token。
Read/Write API Token 仅读写存储桶的Token,创建Token时还可以限定这个Token能操作哪些存储桶。
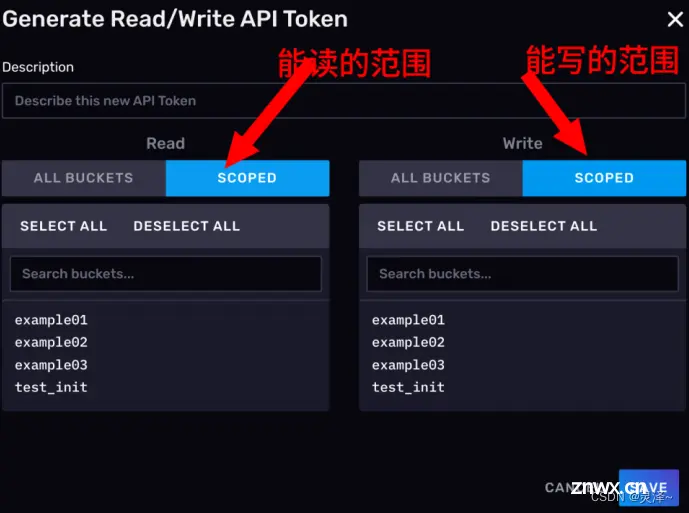
All Access API Token 生成带所有权限的Token
注意!InfluxDB的Token是可以进行更细的管理的,Web UI上给的只是生成Token的模板,准备了用户的常用需求,但不代表它的全部功能。
3.2 查询工具
1、如果继续后面内容的学习,最好先掌握附录 4 :时序数据库中的数据模型 中的知识。
3.2.1 前言
1、关于InfluxDB的查询,需要用户掌握一门叫FLUX的语言。本节暂时不讲解FLUX语言的知识,而是先了解InfluxDB重要的两个开发工具——Data Explorer和Notebook。
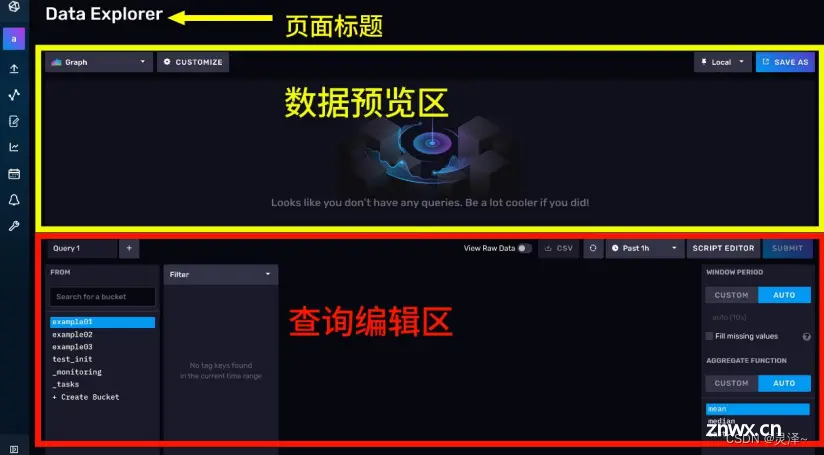
3.2.2 了解Data Explorer
3.2.2.1 什么是Data Explorer
1、explorer,探险家、探索者的意思。所以正如其字面意思,你可以使用Data Explorer探索数据,理解数据。说白了,就是你可以尝试性地写写FLUX查询语言(InfluxDB独创的一门独立查询语言,课程后面会讲解),看一下数据的效果。开发过程中,你可以将它作为一个FLUX语言的IDE。但是,目前我们不会向大家讲解FLUX语言。后面会这门语言起一个专门的章节。
3.2.2.2 认识Data Explorer的页面
1、点击左边的 图标,进入Data Explorer。
2、我们可以将Data Explorer的界面简单分为两个区域,上半部分为数据预览区,下半部分为查询编辑区。
3.2.2.3 查询编辑区
1、查询编辑区为你提供了两种查询工具,一个是查询构造器,一个是FLUX脚本编辑器。
查询构造器
你一进入Data Explorer页面,默认会打开查询构造器。使用查询构造器,你可以通过点按的方式完成查询。它背后的原理其实是根据你的设置,自动生成一条 FLUX语句,提交给数据库完成查询。能够出现查询构造器这种东西,说明时序数据的查询之间遵循着某种规律。不同业务之间的查询步骤可能高度相似。
如图,这是查询构造器的极简介绍。在后面的示例中,我们会详细讲解它的使用
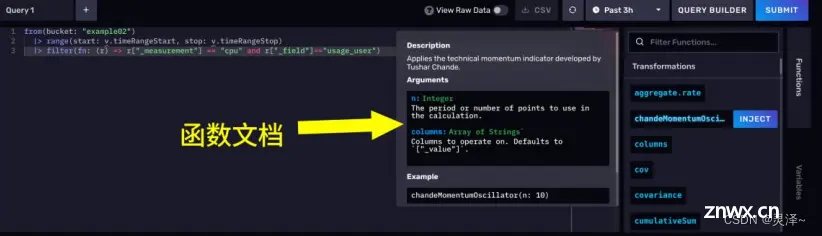
FLUX脚本编辑器
你可以手动将查询构造器切换为FLUX脚本编辑器(点击 script editor 按钮即可)。然后愉快地编写FLUX脚本,实现各种奇葩查询。编辑器十分友好,还带自动提示和函数文档。
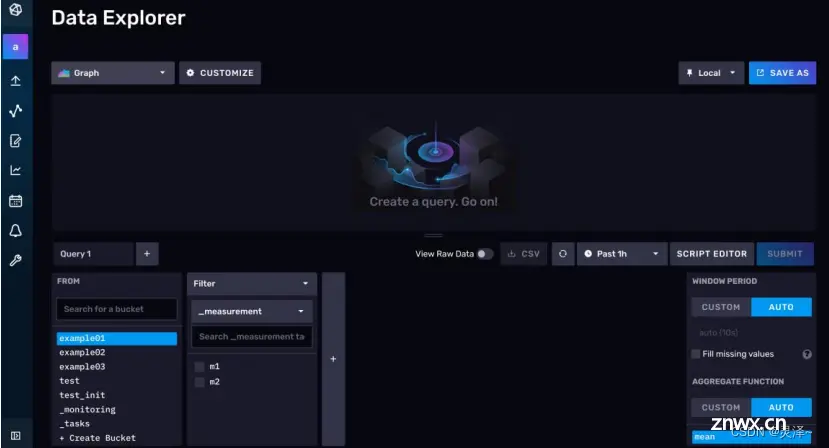
3.2.2.4 数据预览区
1、数据预览区可以将你的数据展示出来。下图是一个效果图。
2、默认情况下,数据预览区会将你的数据展示为一个折线图。不过除此之外,你还可以让数据展示为散点图、饼图或者查看原始数据等等。
3.2.2.5 其他功能
1、除了查询和展示数据的功能外。Data Explorer还有一些拓展功能
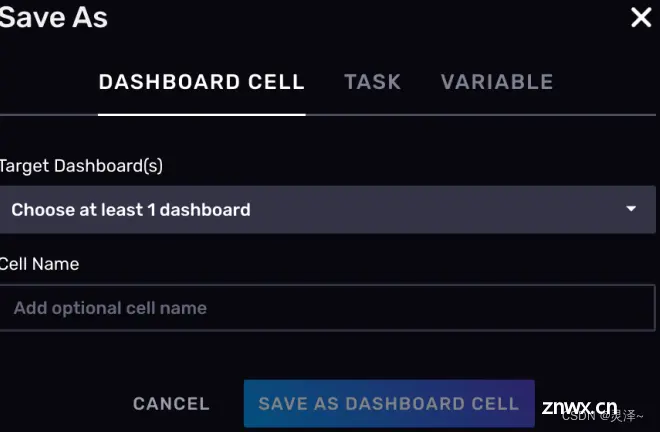
将数据导出为CSV 在执行查询之后,DataExplorer允许你快速地将数据导出为一个CSV文件。
将当前查询和可视化效果保存为仪表盘的一个单元
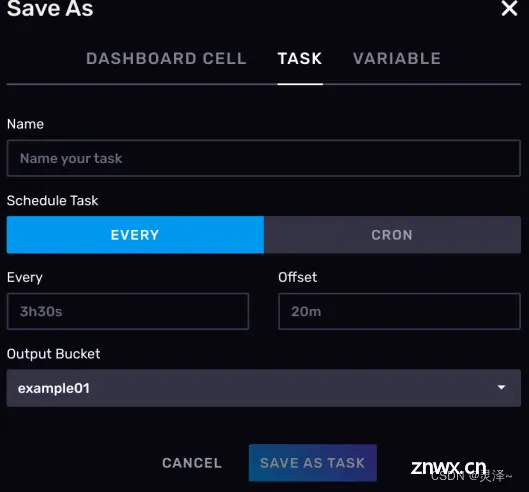
你可以将当前的查询逻辑和图形展示保存为某个仪表盘的一部分。这个功能需要在查询逻辑已经实现的前提下,点击右上角的SAVE AS触达。
创建定时任务
Data Explorer中的查询逻辑可以保存为一个定时任务,也就是 TASK。这里提前说一下InfluxDB中的TASK是什么。TASK其实是一个定时执行的FLUX语言写的脚本。因为FLUX是一个脚本语言,所以它其实有一定的IO能力。可以使用http与外面的系统进行通信,还可以将计算完的数据回写给InfluxDB。所以通常TASK有两种使用场景。
( 1 )数据检查与报警。对查询后的结果进行一下条件判断,如果不合规,就使用http向外通知报警。
( 2 )聚合操作。在InfluxDB里开窗完成聚合计算,计算后的数据再写回到InfluxDB,这样下游 BI(数据看板)可以直接去查询聚合后的数据了,而不是每次都把数据从InfluxDB里拉出来重新计算。这样可以减少IO,不过会增加InfluxDB的压力。生产环境
下需要根据实际情况进行取舍。
定义全局变量
在DataExplorer里,你可以声明一些全局变量。全局变量的类型可以是Map(键值对)、CSV和FLUX脚本。这样,将来你可以直接引用这些变量,比如你的数据里有地区编码。你就可以将编码到地区名称的映射保存为一个全局Map,供以后每次查询时使用。

3.2.3 示例 4 :在Data Explorer使用查询构造器进行查询和可视化
3.2.3.1 打开Data Explorer
1、点击左侧的 按钮,进入Data Explorer页面。

3.2.3.2 设置查询条件
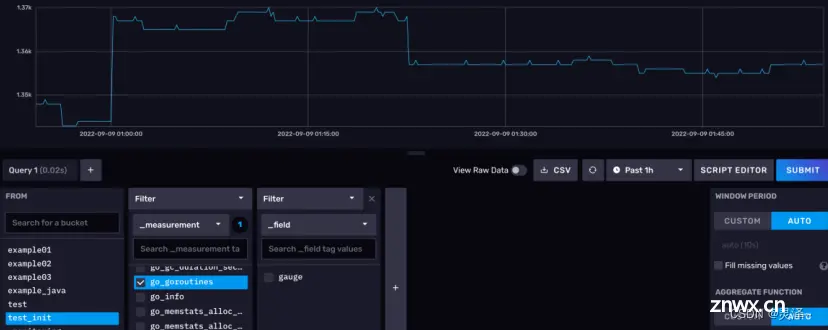
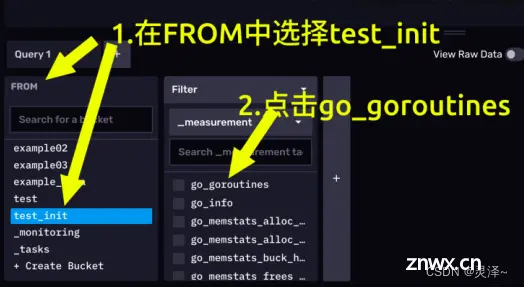
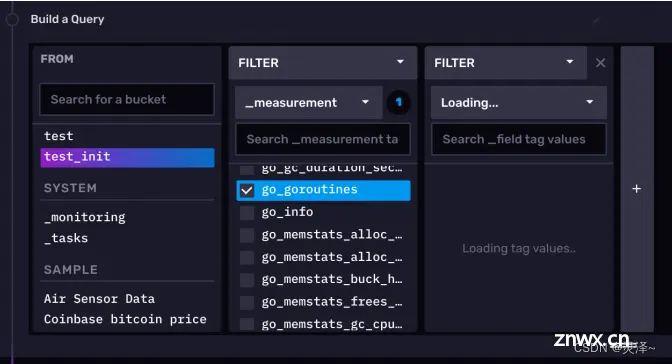
1、我们现在要查询的是 test_init 存储桶下的 go_goroutines 测量,这个测量反应的是我们InfluxDB进程中的goroutines(轻量级线程)数量。首先,在左下角的查询构造器的FROM选项卡,选择test_init存储桶。接着会弹出一个 Filter选项卡,默认情况下这里是选择_measurement,此处我们选择 go_goroutines。
3.2.3.3 注意查询时间范围
1、右上角有一个带时钟符号的下拉菜单,这个菜单可以帮你纵向选择要查询数据的时间范围,通常默认是 1 h。如下图所示:
3.2.3.4 注意右侧的窗口聚合选项
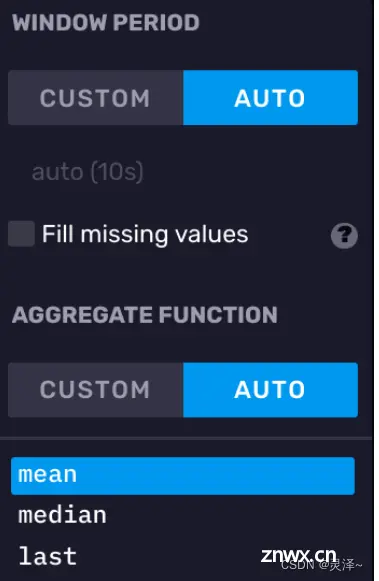
1、 在查询构造器的最右边,有一个开窗聚合选项卡。使用查询构造器进行查询,就必须使用开窗聚合。默认情况下,DataExplorer会根据你设置的查询时间范围,自动调整窗口大小,此处查询范围 1 h对应窗口大小 10 s。同时,聚合方式默认是平均值。
3.2.3.5 提交查询
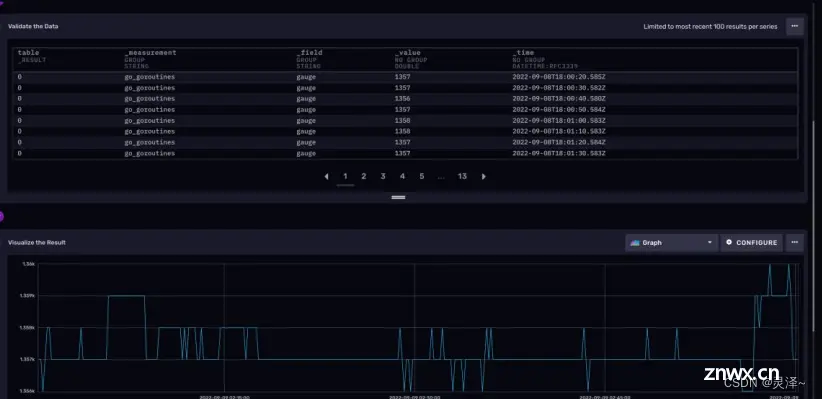
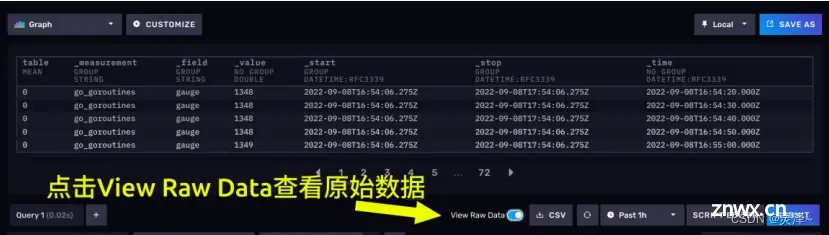
1、点击右侧的SUBMIT按钮可以立刻提交查询。之后,数据展示区会出现相应的折线图。如下图所示:

2 、点击View Raw Data,可以看到原始数据。
3.2.3.6 查询原理
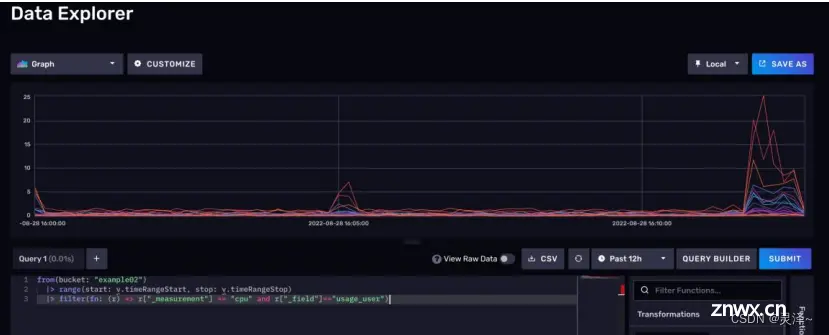
1、我们使用查询构造器进行查询,其实是 Web UI根据我们指定的查询条件生成了一套FLUX查询脚本。点击SCRIPT EDITOR按钮,可以看到查询构造器生成的FLUX脚本。
3.2.3.7 可视化原理
1、其实默认情况下的可视化,是依据返回数据中的_value来展示的,但是有些时候,你想查询的数据可能字段名不会被判别为_value。它会安静地躺在原始数据中。
3.2.4 了解Notebook
3.2.4.1 什么是Notebook
1、Notebook是InfluxDB2.x推出的功能,交互上模仿了Jupyter NoteBook。它可以用于开发、文档编写、运行代码和展示结果。
你可以将InfluxDB笔记本视为按照顺序处理数据的集合。每个步骤都由一个“单元格”表示。一个单元格可以执行查询、可视化、处理或将数据写入存储桶等操作。Notebook可以帮你完成下述操作
执行FLUX代码、可视化数据和添加注释性的片段创建报警或者计划任务对数据进行降采样或者清洗生成要和团队分享的Runbooks将数据回写到存储桶
2、Notebook和DataExplorer相比,主要是交互风格上的不同。DataExplorer倾向于一锤子买卖,而Notebook可以将数据展示拆分为一个又一个具体的步骤。另外,NoteBook可以用来开发告警任务DataExplorer则不能。
3.2.4.2 进入Notebook的导航界面
1、点击左侧的 按钮,即可进入Notebook的导航页面。

2、导航页面分两个部分:
上面是创建引导,除了创建一个空白的Notebook,InfluxDB还为你提供了 3 个模板。分别是Set an Alert(设置一个报警)、Schedule a Task (调度一个任务)、write a Flux Script(写一个Flux脚本)。
-下面是Notebook列表,过去你创建过的NoteBook再这里都会展示出来。卡片上还有这个 Notebook对应的创建时间和修改时间。通过卡片你可以对一个Notebook重命名,还可以将它复制和删除。
3.2.4.3 创建一个空白的notebook
1、想要继续后面的步骤,我们必须先创建一个Notebook。如下图所示,在页面上方点击New Notebook按钮即可。
2、现在,你看到的就是Notebook的操作页面了。

3.2.4.4 NoteBook工作流
1、目前你看到的页面应当是如下图所示的样子。

2、我们在页面中看到的一个又一个卡片,在NoteBook中叫做Cell。一个NoteBook工作流就是多个Cell按照先后顺序组合起来的执行流程。这些Cell中间随时可以插入别的Cell,而且Cell和Cell还可以调换顺序。按照Cell功能,Cell可以按照下面的方式分类。
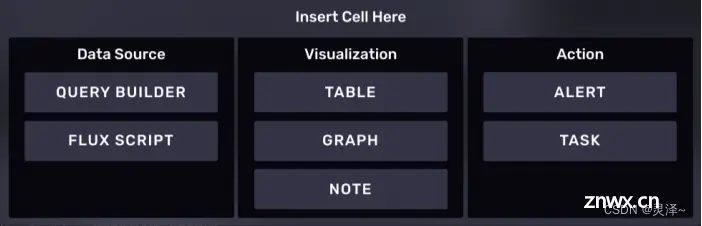
数据源相关的Cell
查询构造器直接编写FLUX脚本 可视化相关的Cell
将数据展示为一个Table将数据展示为一张图添加笔记。 行为Cell
进行报警定时任务设定
3.2.4.5 工作流范式
1、在NoteBook里编写工作流通常是有套路可循的。

2、通常一个notebook工作流以查询数据开始,后面的Cell跟上把数据展示出来,当数据需要进一步修改的时候,可以再加一个FLUX脚本 cell,notebook为我们留了一个接口,通过这种方式,后面的Flux cell可以将前面的数据作为数据源进行查询。
3、最终,notebook工作流可以以任务设置或者报警操作作为整个工作流的终点,当然这不是强制要求。
3.2.4.6 NoteBook控件
1、在notebook上存在下述几种控件
时区转换
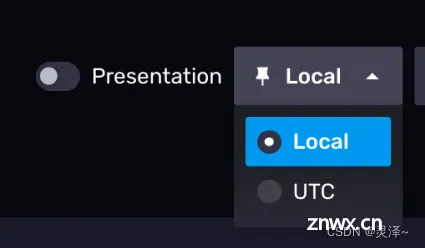
右上角有一个Local按钮,通过这个按钮,你可以选择将日期时间显示为系统所设时区还是UTC时间。
仅显示可视化
点击Presentation按钮,可以选择是否仅显示数据展示的cell。如果开启这个选项,那么查询构造器和FLUX脚本的Cell就会被折叠。

删除按钮
点击确定后,可以删除整个notebook。
复制按钮
右上角的复制按钮可以立刻为当前NoteBook创建一个副本。
运行按钮
RUN按钮可以快速地执行Notebook中的查询操作并重新渲染其中的可视化Cell。
3.2.5 示例 5 :使用NoteBook查询和可视化数据
3.2.5.1 使用查询构造器记性查询
1、默认情况下,你创建的空白NoteBook,自带 3 个cell。
2、第一个cell,默认是一个查询构造器,相对于DataExplorer来说,notebook的查询构造器不同的地方在于它没有开窗聚合操作。此处,同样还是查询test_init中的go_goroutines测量。
3.2.5.2 提交查询
1、点击RUN按钮。
2、可以看到下面的原始数据和折线图都出现了

3.2.5.3 添加说明cell
1、notebook允许用户在工作流中加入说明性的cell。我们选择在最前面加一个说明性cell。首先,点击左侧的紫色+号。
2、点击NOTE 按钮。可以看到,我们已经创建了一个说明 cell。这里面还支持 MarkDown语法

3、现在,我们随便写点东西

4、点击右上右上角的PREVIEW按钮,markdown就会被渲染展示。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。