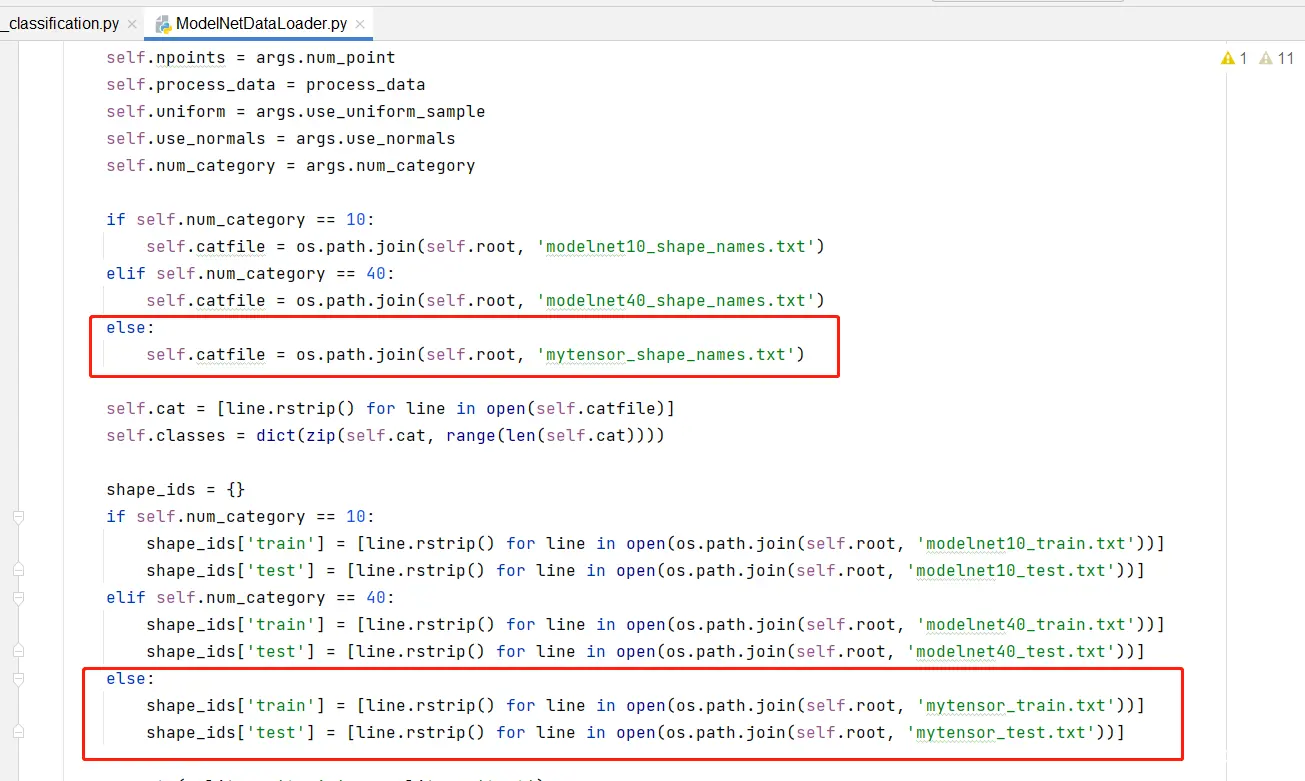
本文针对PointNet++强大的三维点云分类功能,详细讲解怎么训练自己的数据集,在此之前,需要确保已经能够跑通源码的训练和测试,如果没有,请参考。_pointnet训练自己的数据...

3.模型收敛:trainloss下降趋于稳定,valloss下降也趋于稳定,且trainloss的值与valloss的值相差不大。5.trainloss上升,valloss上升:网络结构设计...
这里仅仅介绍一下AI图像识别App的实现原理,AI的基础技术细节不在本文讨论范围。。我们都知道,人工智能AI的基本原理是事先准备好样本数据(这里指的是图片)及数据的标注信息(如图片中的人物是高兴、愤怒、哭泣等图片的判...

AI语音合成VITS-fast-fine-tuning项目旨在提供快速微调模型的指导,并支持中、日、英三种语言。只需解压文件,将模型和配置文件放入根目录,运行inference.exe即可使用。页面简单易懂,便于合成语音。...
在人工智能的宏伟蓝图中,大语言模型(LLM)的预训练是构筑智慧之塔的基石。预训练过程通过调整庞大参数空间以吸纳数据中蕴含的知识,为模型赋予从语言理解到文本生成等多样化能力。本文将深入探讨预训练过程中的技术细节、...

大规模语言模型(LargeLanguageModels,LLM),也称大语言模型或大型语言模型,是一种由包含数百亿以上参数的深度神经网络构建的语言模型,通常使用自监督学习方法通过大量无标注文本进行训练。_统...
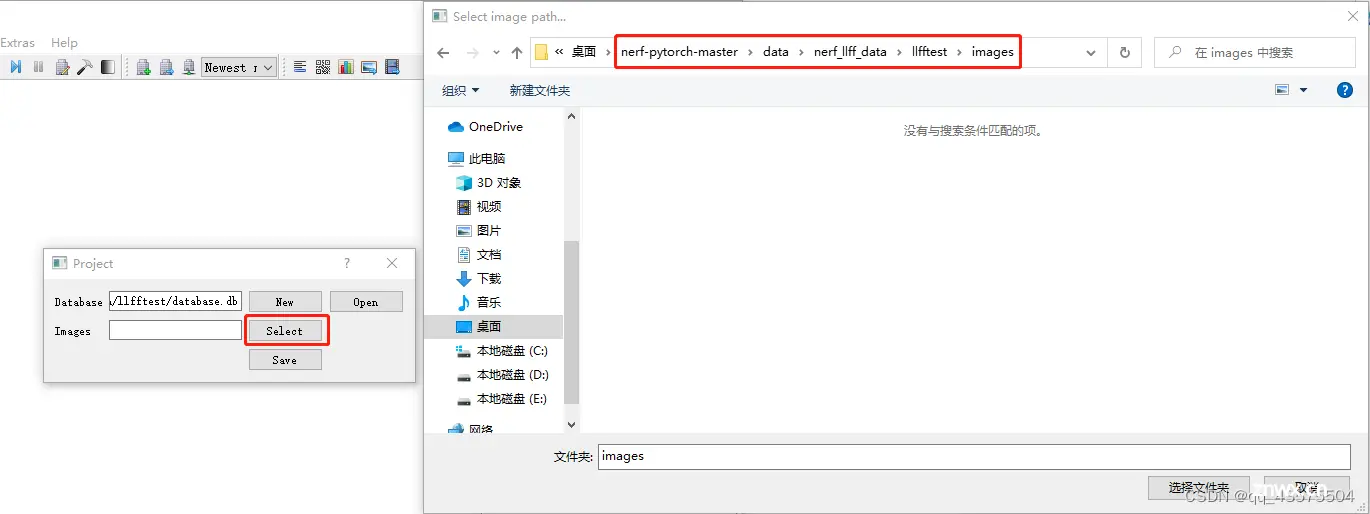
用nerf渲染自己拍摄的数据,过程详细且配图解释!!!_nerf训练自己的数据...

在深度学习的不断进步中,大型语言模型(LLMs)的预训练和微调技术成为了研究的热点。其中,量化技术以其在模型压缩和加速方面的潜力备受关注。本文将深入探讨QLoRA(QuantizedLow-RankAdap...
yolov8从环境搭建到推理训练(超级详细)_yolov8n.pt下载...

为了训练自定义模型,通常需要使用大量标注好的图像数据来训练模型。但是,当可用的训练数据不够多时,可以使用预训练权重来提高模型的性能。_预训练权重...