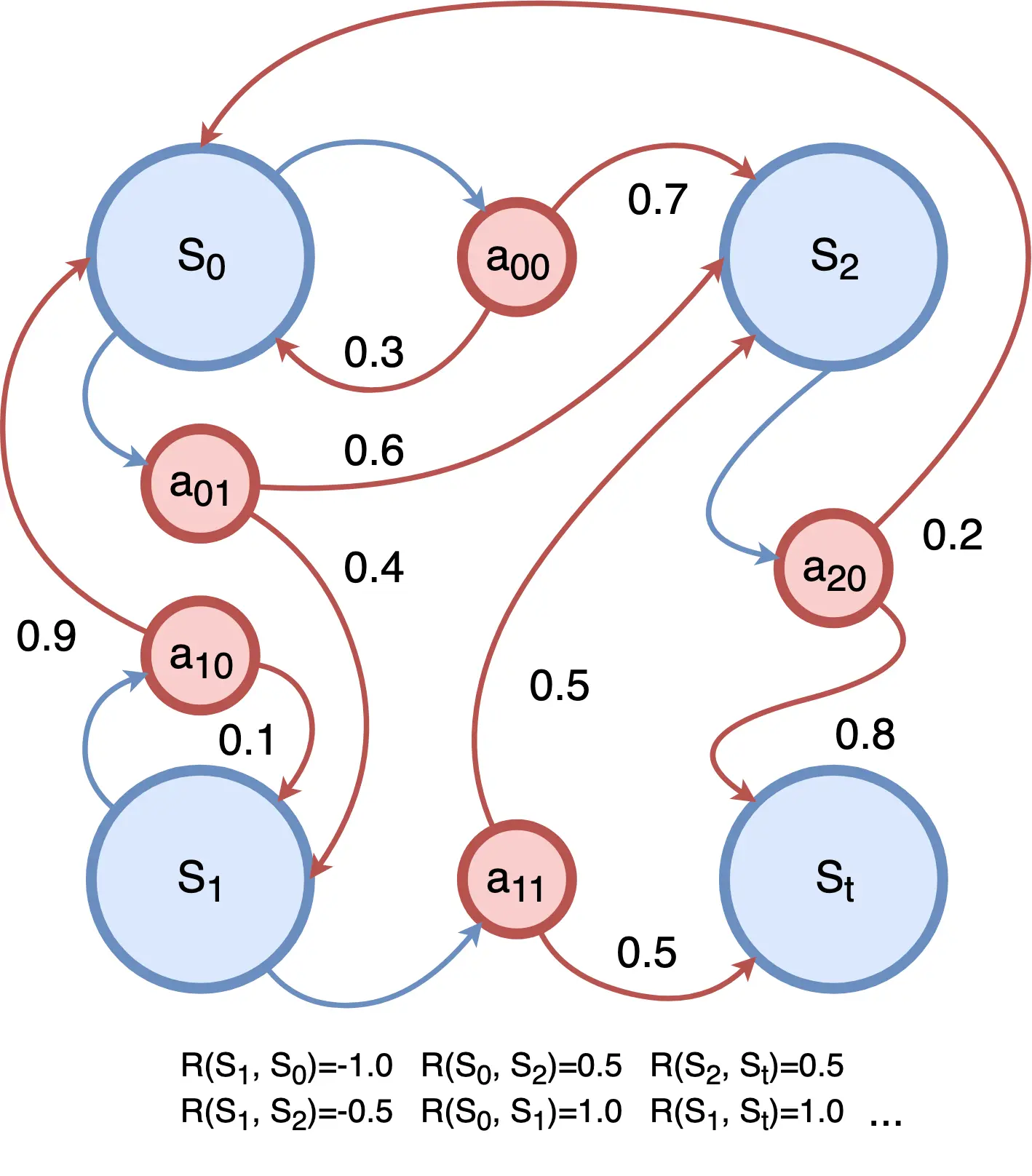
Q-learning是一种基于强化学习的算法,用于解决Markov决策过程(MDP)中的问题。这类问题我们理解为一种可以用有限状态机表示的问题。它具有一些离散的状态state、每一个state可以通过动作actio...
![[青少年CTF训练平台]web部分题解(已完结!)](/uploads/2024/06/21/1718956984102024186.webp)
青少年平台的CTF-web简单的口语化题解,师傅没看懂可以私信我电话给分享...
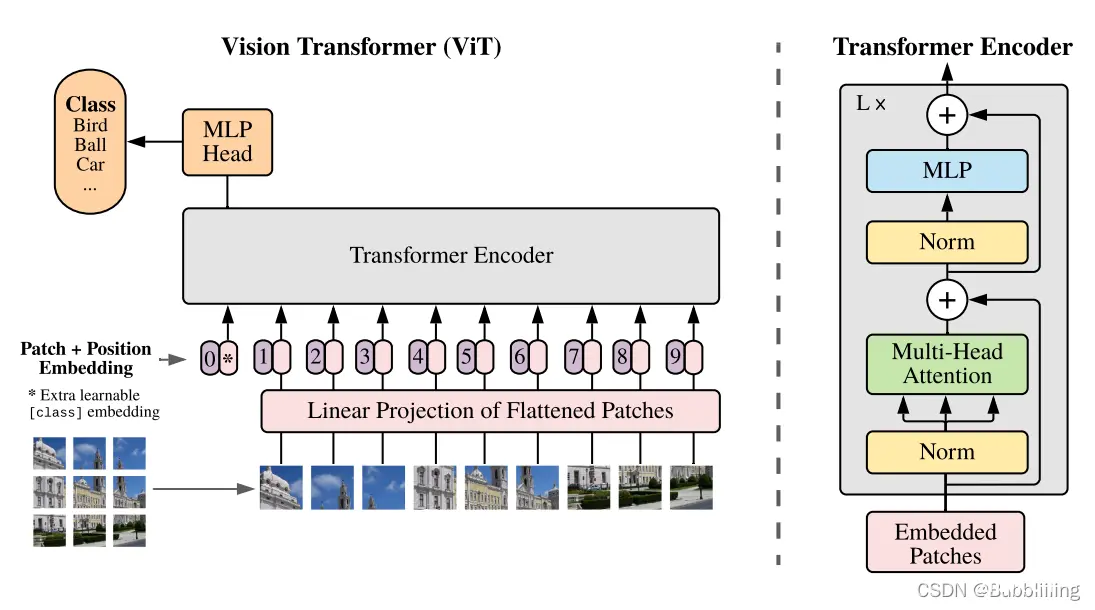
学了一些多模态的知识,CLIP算是其中最重要也是最通用的一环,一起来看一下吧。CLIP的全称是ContrastiveLanguage-ImagePre-Training,中文是对比语言-图像预训练,是一个预训...

你可以从简单的模型开始,如多层感知器(MLP),然后逐步尝试更复杂的结构,如循环神经网络(RNN)、长短期记忆网络(LSTM)或Transformer。选择合适的框架:选择一个适合初学者的AI框架,如TensorF...
深度强化学习DRL现存问题和训练指南(D3QN(DuelingDoubleDQN))_doubledqn存在的不足...
本文先对LLaMA-Factory项目进行介绍,之后逐行详细介绍了该项目在国内网络环境下如何安装、部署,最后以Baichuan2-7B为例,通过讲解训练参数的方式详细介绍了基于LLaMA-FactoryWebU...
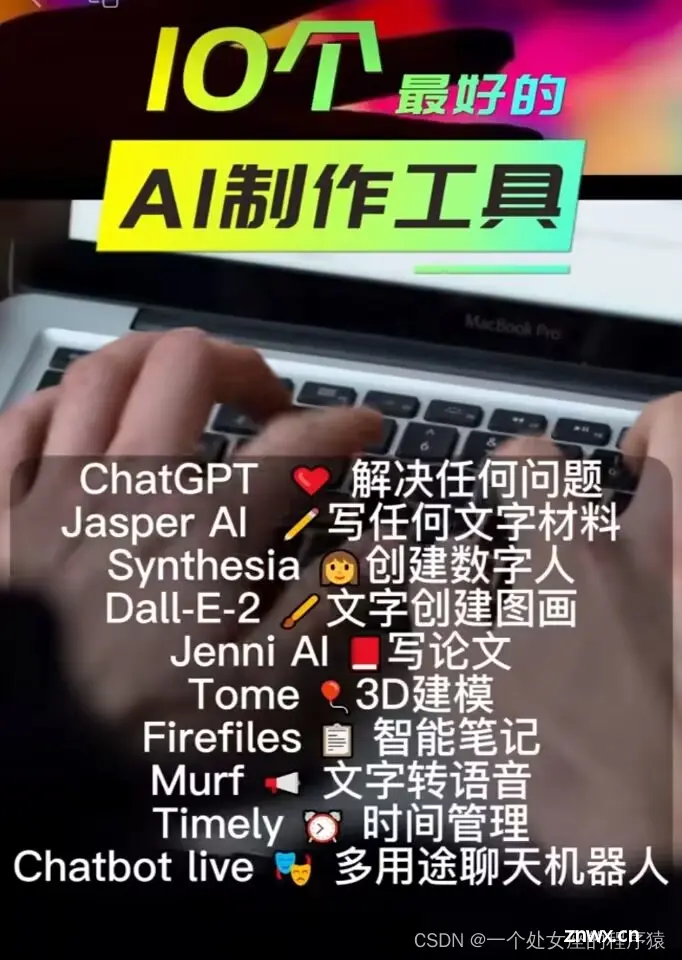
AI:大模型领域最新算法SOTA核心技术要点总结(一直持续更新)、大模型实战与理论经验总结(训练优化+代码实战+前沿技术探讨+最新案例应用)、带你精细解读多篇优秀的大模型论文、AI领域各种工具产品集合(文本...

通过计算查询(Query)、键(Key)和值(Value)向量之间的相似度,自注意力机制能够为每个单词分配不同的权重,反映其在当前上下文中的重要性。具体来说,将查询、键和值矩阵分成多个头,每个头独立地计算注意力,...

YOLOv8(n/s/m/l/x)&YOLOv7(yolov7-tiny/yolov7/yolov7x)&YOLOv5(n/s/m/l/x)不同模型参数/性能对比(含训练及推理速度)_yolov7和yolov8...

在课程前言我们也提到过,如果你直接开始训练,可能会不停的调整训练参数,比如素材图质量、数量、训练轮次等,一轮又一轮,一次又一次的不停调试,观察每一次的Loss损失函数值和其他数据,那么这就是一个耗费时间和精力以及...