第十五篇【传奇开心果系列】Python自动化办公库技术点案例示例:深度解读Python 自动化处理图像在各行各业的应用场景
传奇开心果编程 2024-06-13 16:37:22 阅读 60
传奇开心果博文系列
系列博文目录Python自动化办公库技术点案例示例系列 博文目录前言一、行业应用场景介绍二、 **计算机视觉研究与开发示例代码**三、人工智能与机器学习示例代码四、医疗健康领域示例代码五、制造业与质量控制示例代码六、农业与环境科学示例代码七、电子商务与零售示例代码八、艺术与设计示例代码九、媒体与娱乐示例代码十、知识点归纳
系列博文目录
Python自动化办公库技术点案例示例系列
博文目录
前言

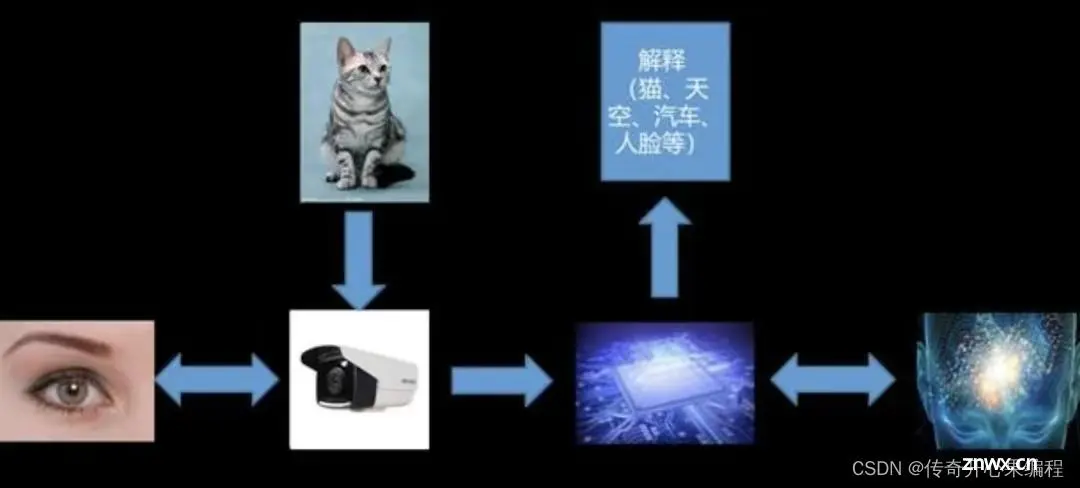
Python 自动化操作处理图像在众多行业中发挥着关键作用,其强大的图像处理能力、丰富的库支持以及高度可定制化的特性,使得它成为实现图像相关任务自动化的重要工具。Python 自动化操作图像在计算机视觉、人工智能、医疗、制造、农业、电商、艺术、媒体等多个行业均展现出显著价值,不仅提高了工作效率,还推动了技术创新与业务流程的智能化转型。随着技术进步与应用场景的拓展,其作用将进一步深化和多元化。
一、行业应用场景介绍

以下是对 Python 在不同行业应用图像自动化处理的概括介绍:
(一)计算机视觉研究与开发:
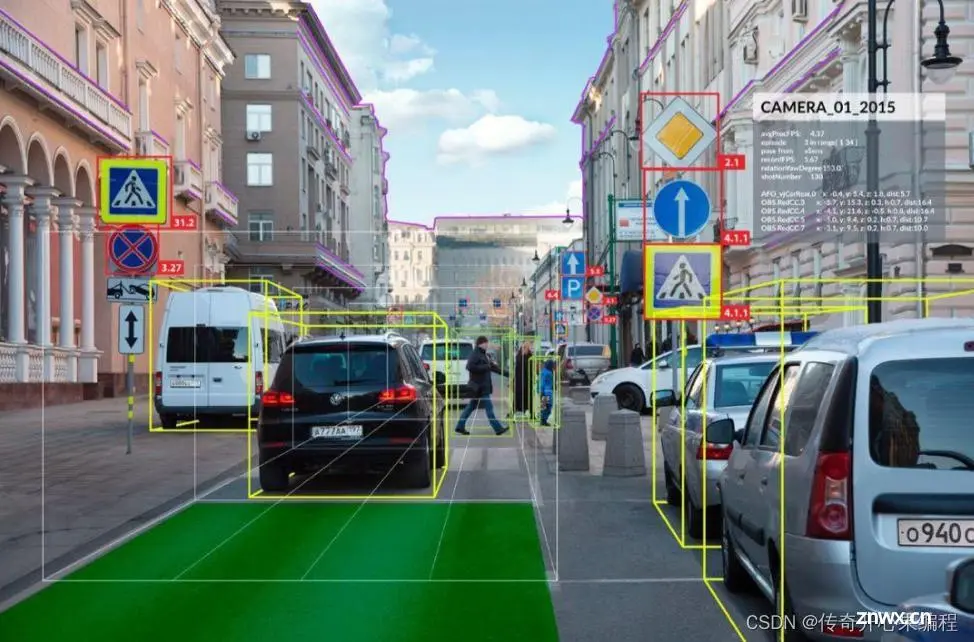
图像识别:Python 中的 OpenCV、TensorFlow、PyTorch 等库被广泛用于构建深度学习模型,自动识别图像中的物体、人脸、车牌、手势等,对于自动驾驶、安防监控、医疗影像诊断等领域至关重要。目标检测与跟踪:在视频流中实时定位并追踪特定目标,应用于智能交通管理、无人机导航、体育赛事分析等场景。图像分割:自动划分图像中的各个区域或对象,有助于医学图像分析(如肿瘤边界识别)、遥感图像解译(如土地覆盖分类)及自动驾驶中的道路、车辆、行人分割。
(二) 人工智能与机器学习:
数据预处理:Python 图像库如 Pillow、scikit-image 提供图像缩放、裁剪、旋转、噪声去除、色彩空间转换等功能,对大量图像数据进行标准化处理,为后续机器学习模型训练做准备。特征提取:自动化计算图像特征(如 SIFT、SURF、HOG),用于图像检索、比对、识别等任务,在生物识别、版权保护、艺术品鉴定等领域有广泛应用。模型评估与可视化:自动化绘制混淆矩阵、ROC曲线、PR曲线等图表,直观呈现模型性能,辅助模型选择与优化。
(三) 医疗健康领域:
医疗影像分析:Python 自动化工具用于 CT、MRI、超声等影像的分割、标注、病变检测、定量测量等,支持医生快速准确地做出诊断。病理切片分析:通过自动识别和量化组织病理学图像中的细胞、组织结构等特征,辅助癌症分级、预测疾病进展。
(四)制造业与质量控制:
缺陷检测:在生产线中,Python 驱动的系统可以自动检测产品表面瑕疵、部件缺失等,提高生产效率和产品质量。机器人视觉:引导工业机器人进行精确抓取、装配、定位等操作,依赖于 Python 实现的图像识别与定位算法。
(五)农业与环境科学:
作物病虫害监测:通过无人机拍摄的农田图像,Python 自动化程序识别病虫害迹象,帮助农民及时采取防治措施。植被覆盖分析:处理卫星遥感图像,自动化计算植被指数、变化检测,用于森林监测、土地利用规划等。
(六)电子商务与零售:
商品识别与推荐:自动分析用户上传的商品图片,实现商品搜索、分类、相似推荐等功能,提升购物体验。视觉搜索:用户通过上传图片寻找相似商品,Python 自动化技术支撑这种新颖的搜索方式。
(七)艺术与设计:
图像合成与编辑:使用 Python 实现的自动化工具,如图像拼接、滤镜应用、风格迁移等,简化创意过程,增强艺术表现力。AI 创作:结合如 Stable Diffusion 等 AI 生成模型,Python 可驱动程序自动生成艺术作品、设计素材等。
(八)媒体与娱乐:
内容审核:自动检测社交媒体、直播平台上的违规图像内容,确保合规性。视频分析:对视频帧进行自动化处理,如动作识别、人脸识别、内容摘要生成,服务于内容推荐、版权保护、体育赛事数据分析等。
二、 计算机视觉研究与开发示例代码
(一)图像识别示例代码
使用 Python 和 OpenCV 库进行简单物体识别的基本示例,使用预训练的 Haar 分类器来检测图像中的面部。如果您需要 TensorFlow 或 PyTorch 的深度学习模型示例,您可以提出具体需求,如使用某种预训练模型(如 YOLOv5、EfficientDet 等)进行特定物体识别。
(1)OpenCV 的图像识别示例代码:
import cv2# 加载预训练的 Haar 分类器(人脸检测器)face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')# 读取要检测的图像image_path = 'path_to_your_image.jpg'image = cv2.imread(image_path)if image is None: print("Failed to load the image.")else: # 转换为灰度图像 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 进行人脸检测 faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30)) # 在检测到的面部周围画矩形框 for (x, y, w, h) in faces: cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2) # 显示带有面部标记的图像 cv2.imshow('Face Detection', image) cv2.waitKey(0) cv2.destroyAllWindows()
这段代码首先加载了一个预训练的 Haar 分类器,该分类器专门用于识别面部。然后,它读取您指定路径下的图像,将其转换为灰度模式,因为 Haar 分类器通常在灰度图像上运行更高效。接着,detectMultiScale 函数被调用,它在图像中查找符合面部特征的区域,并返回这些区域的坐标(左上角 x, y 坐标以及宽度 w 和高度 h)。最后,代码在检测到的每个面部位置绘制一个绿色矩形框,并显示结果图像。
对于深度学习模型的物体识别示例,通常涉及加载预训练模型、准备输入数据、执行前向传播、解析输出并可视化结果等步骤。如果您有具体的需求(如识别汽车、动物种类或其他特定对象),请提供详细信息,我可以为您提供更针对性的代码示例。

(2)TensorFlow实现图像示例代码
以下是一个基于TensorFlow实现图像识别的基本示例代码,假设我们正在构建一个简单的卷积神经网络(CNN)模型来识别MNIST手写数字数据集。这个示例涵盖了数据加载、模型定义、训练以及对单张图像进行预测的步骤。
import tensorflow as tffrom tensorflow.keras import datasets, layers, modelsimport matplotlib.pyplot as plt# 1. 数据加载(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()# 2. 数据预处理train_images = train_images.reshape((60000, 28, 28, 1))train_images = train_images / 255.0test_images = test_images.reshape((10000, 28, 28, 1))test_images = test_images / 255.0# 3. 模型定义model = models.Sequential()model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.Flatten())model.add(layers.Dense(64, activation='relu'))model.add(layers.Dense(10))# 4. 编译模型model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])# 5. 训练模型history = model.fit(train_images, train_labels, epochs=5, validation_data=(test_images, test_labels))# 6. 评估模型性能test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)print(f'Test accuracy: { test_acc}')# 7. 对单张图像进行预测example_image = test_images[0]example_label = test_labels[0]prediction = model.predict(example_image.reshape(1, 28, 28, 1))predicted_class = tf.argmax(prediction, axis=1).numpy()[0]plt.imshow(example_image.squeeze(), cmap='gray')plt.title(f'Label: { example_label}, Predicted: { predicted_class}')plt.show()
代码解释:
数据加载:使用tensorflow.keras.datasets.mnist.load_data()加载MNIST数据集,它会返回训练集和测试集的图像及对应的标签。
数据预处理:将图像数据重塑为适合卷积神经网络输入的形状(包括通道数),并将其归一化到[0, 1]区间。
模型定义:创建一个顺序模型,添加卷积层、最大池化层、全连接层等组成一个简单的CNN架构。最后一层输出节点数为10,对应MNIST数据集中10个不同的数字类别。
编译模型:设置优化器(如Adam)、损失函数(如SparseCategoricalCrossentropy)和评估指标(如准确率)。
训练模型:使用训练数据集对模型进行训练,指定训练轮数(epochs)和验证数据。
评估模型性能:使用测试数据集计算模型的损失和准确率。
对单张图像进行预测:选择测试集中的一张图像,通过模型进行预测,获取预测类别,并使用matplotlib展示该图像及其真实的标签和模型预测的类别。
请注意,实际应用中的图像识别任务可能涉及更复杂的模型结构、自定义数据预处理、数据增强、模型超参数调优等步骤。此示例旨在提供一个基础的TensorFlow图像识别代码框架。如果您需要处理其他图像数据集或执行特定的图像识别任务,请根据实际情况调整代码。

(3)PyTorch 图像识别示例代码
以下是一个使用PyTorch实现图像识别的基本示例代码,以识别MNIST手写数字数据集为例。该示例涵盖了数据加载、数据预处理、模型定义、训练过程、模型保存与加载,以及对单张图像进行预测的步骤。
import torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import datasets, transformsimport matplotlib.pyplot as plt# 1. 数据加载与预处理transform = transforms.Compose([ transforms.Resize((28, 28)), transforms.ToTensor(), transforms.Normalize(mean=[0.5], std=[0.5])])train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)batch_size = 64train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 2. 模型定义class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1) self.relu = nn.ReLU() self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2) self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(32 * 7 * 7, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = self.relu(x) x = self.maxpool(x) x = self.conv2(x) x = self.relu(x) x = self.maxpool(x) x = x.view(-1, 32 * 7 * 7) x = self.fc1(x) x = self.relu(x) x = self.fc2(x) return xmodel = SimpleCNN()# 3. 损失函数与优化器criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)# 4. 训练模型num_epochs = 5device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.to(device)for epoch in range(num_epochs): running_loss = 0.0 for i, (images, labels) in enumerate(train_loader): images, labels = images.to(device), labels.to(device) optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() print(f"Epoch { epoch + 1}, Loss: { running_loss / (i + 1)}")# 5. 保存与加载模型torch.save(model.state_dict(), 'mnist_cnn.pth')model.load_state_dict(torch.load('mnist_cnn.pth'))# 6. 评估模型model.eval()correct = 0total = 0with torch.no_grad(): for images, labels in test_loader: images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item()print(f"Test Accuracy: { 100 * correct / total}%")# 7. 对单张图像进行预测example_image, example_label = test_dataset[0]example_image = example_image.unsqueeze(0).to(device)output = model(example_image)_, predicted_class = torch.max(output, dim=1)print(f"Label: { example_label}, Predicted: { predicted_class.item()}")plt.imshow(example_image.squeeze().cpu().numpy(), cmap='gray')plt.title(f'Label: { example_label}, Predicted: { predicted_class.item()}')plt.show()
代码解释:
数据加载与预处理:使用torchvision库加载MNIST数据集,定义数据预处理流程(包括缩放、转为Tensor、标准化)。创建数据加载器用于批量训练和测试。
模型定义:定义一个简单的卷积神经网络(CNN)类SimpleCNN,包含两个卷积层、两个最大池化层以及两个全连接层。
损失函数与优化器:选择交叉熵损失函数作为模型的损失计算方式,使用Adam优化器进行参数更新。
训练模型:将模型和数据转移到可用的设备(GPU或CPU),按照设定的轮数进行训练。在每一轮训练中,计算损失并反向传播更新权重。
保存与加载模型:训练完成后,保存模型的权重到文件,然后演示如何从文件加载模型权重。
评估模型:切换模型至评估模式,计算在测试集上的准确率。
对单张图像进行预测:从测试集中选取一张图像,通过模型进行预测,获取预测类别,并使用matplotlib显示该图像及其真实的标签和模型预测的类别。
这个示例展示了使用PyTorch进行图像识别的基本流程。对于更复杂的任务,您可能需要调整模型结构、增加数据增强、调整学习率策略等。确保根据您的具体需求对代码进行相应修改。
(二)目标检测与跟踪示例代码
下面是一个简化的Python代码片段,演示了如何使用OpenCV库进行基本的目标检测与跟踪。这里我们使用预训练的YOLOv5模型进行目标检测,并结合卡尔曼滤波器进行简单的目标跟踪。请注意,实际应用中可能需要更复杂的配置和优化以适应具体场景需求。
首先,确保已经安装了必要的依赖库,如opencv-python, torch, yolov5等。然后,您可以参考以下代码示例:
import cv2import torch# 加载预训练的YOLOv5模型model = torch.hub.load('ultralytics/yolov5', 'yolov5s')# 初始化卡尔曼滤波器,假设跟踪一个目标kalman_filter = cv2.KalmanFilter(4, 2)kalman_filter.measurementMatrix = np.array([[1, 0, 0, 0], [0, 1, 0, 0]], np.float32)# 假设视频流来自摄像头,替换0为实际视频文件路径cap = cv2.VideoCapture(0)while True: ret, frame = cap.read() if not ret: break # 将BGR图像转换为YOLOv5所需的格式 img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) img = img.transpose((2, 0, 1))[None, :, :, :] # HWC to NCHW # 进行目标检测 results = model(img) detections = results.xyxy[0] # 获取第一帧的检测结果 # 在当前帧中绘制并跟踪检测到的目标 for det in detections: x1, y1, x2, y2 = det.tolist() bbox = (x1, y1, x2 - x1, y2 - y1) # 如果有历史跟踪目标,则更新卡尔曼滤波器并预测当前位置 if has_tracked_target: # 更新卡尔曼滤波器状态 kalman_filter.correct(np.array([x1, y1])) predicted_pos = kalman_filter.predict() x1, y1 = predicted_pos[:2] # 更新或初始化跟踪框 cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2) # 显示带有检测和跟踪结果的图像 cv2.imshow('Object Detection & Tracking', frame) key = cv2.waitKey(1) if key == ord('q'): breakcap.release()cv2.destroyAllWindows()
这段代码仅为示例目的,实际使用时需要根据具体需求进行调整,包括但不限于:
使用更精确的目标检测模型或参数。实现更复杂的多目标跟踪算法,如DeepSORT、KCF、MOTChallenge算法等。处理目标检测结果,如关联检测框以维持跟踪的连续性、处理目标消失与重新出现等情况。针对特定应用场景优化,如智能交通管理中可能需要考虑车辆类型识别、速度估计等附加信息。
此外,对于实时处理高分辨率视频流,可能还需要考虑性能优化措施,如模型推理加速、硬件加速(如GPU)等。实际项目开发中,建议使用成熟的计算机视觉库(如OpenCV、dlib、mediapipe等)或专门的跟踪框架(如DeepSORT、SORT、FairMOT等)来构建稳定高效的目标检测与跟踪系统。

(三)图像分割示例代码
以下是使用Python和PyTorch库进行图像分割的一个简化示例,以U-Net模型为例,这是一种广泛应用于医学图像分割和其他领域(如遥感图像和自动驾驶场景)的深度学习架构。在这个示例中,我们将使用预训练的U-Net模型对一张医学图像(例如MRI脑扫描)进行分割。假设您已经安装了torch、torchvision等必要库,并且有一个预训练的U-Net模型可用。
import torchimport torchvision.transforms as transformsfrom PIL import Imageimport numpy as np# 加载预训练的U-Net模型device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = torch.load('path/to/pretrained/unet_model.pt', map_location=device).eval() # 替换为实际模型路径# 定义图像预处理和后处理函数preprocess = transforms.Compose([ transforms.Resize((512, 512)), # 调整图像大小以匹配模型输入要求 transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 根据预训练模型要求进行归一化])postprocess = lambda x: (x.sigmoid().cpu().numpy()[0, 0] * 255).astype(np.uint8) # 将sigmoid激活后的概率图转换为灰度分割图# 读取待分割的医学图像(例如MRI脑扫描)image_path = 'path/to/input/image.png' # 替换为实际图像路径input_image = Image.open(image_path).convert('RGB') # 假设图像为RGB格式# 对图像进行预处理input_tensor = preprocess(input_image)input_tensor.unsqueeze_(0) # 添加批量维度,因为模型通常期望4D张量作为输入# 使用模型进行预测with torch.no_grad(): output_tensor = model(input_tensor.to(device))# 对模型输出进行后处理,得到分割结果segmentation_mask = postprocess(output_tensor)# 可视化分割结果import matplotlib.pyplot as pltfig, axs = plt.subplots(1, 2, figsize=(12, 6))axs[0].imshow(input_image)axs[0].set_title('Original Image')axs[1].imshow(segmentation_mask, cmap='gray')axs[1].set_title('Segmentation Mask')plt.show()# 保存分割结果(可选)cv2.imwrite('output_segmentation_mask.png', segmentation_mask) # 使用OpenCV保存为PNG格式
请注意,这个示例假设您已经有了一个预训练的U-Net模型,并且该模型的输入尺寸、通道数、归一化参数等与上述代码中设定的预处理步骤相匹配。实际应用中,您可能需要根据实际模型的要求调整预处理和后处理代码。此外,为了训练自己的U-Net模型,您需要准备相应的标注数据集,并编写训练脚本,这部分内容超出了此代码示例的范围。
另外,对于不同的分割任务(如遥感图像分割或自动驾驶场景分割),可能需要对模型结构、预处理步骤、后处理逻辑等进行相应的调整以适应不同任务的特点和数据特性。

三、人工智能与机器学习示例代码
(一)数据预处理示例代码
以下是一个使用 Python 的 Pillow 库和 scikit-image 库对图像进行预处理的示例代码:
from PIL import Imageimport numpy as npfrom skimage import exposure, transform, color, io# 1. 读取图像image_path = 'path_to_your_image.jpg'img = Image.open(image_path)# 2. 裁剪图像# 假设我们想要裁剪出左上角坐标为 (100, 50),右下角坐标为 (400, 300) 的部分cropped_img = img.crop((100, 50, 400, 300))# 3. 缩放图像# 将图像缩放到指定大小(例如:256x256)resized_img = cropped_img.resize((256, 256))# 4. 旋转图像# 以图像中心为旋转点,逆时针旋转 45 度rotated_img = resized_img.rotate(45, expand=True)# 5. 去除噪声# 将 PIL 图像转换为 numpy 数组,以便使用 scikit-image 库进行噪声去除np_img = np.array(rotated_img)denoised_img = exposure.denoise_bilateral(np_img)# 6. 色彩空间转换# 将 RGB 图像转换为灰度图像gray_img = color.rgb2gray(denoised_img)# 7. 保存预处理后的图像io.imsave('preprocessed_image.jpg', gray_img)# 如果需要将预处理后的图像用于机器学习模型训练,# 可以进一步将其转换为模型所需的输入格式(例如:归一化、批处理等)# 示例:# 归一化到 [0, 1] 区间normalized_img = gray_img / 255.0# 假设 batch_size=32,这里仅作演示,实际应包含多个样本batched_img = np.expand_dims(normalized_img, axis=0)# 现在 batched_img 可作为机器学习模型的输入
这段代码展示了如何使用 Pillow 和 scikit-image 对图像进行裁剪、缩放、旋转、噪声去除和色彩空间转换等预处理操作。请注意替换 image_path 为你要处理的实际图像路径,并根据具体需求调整预处理参数。在实际应用中,你可能需要对大量图像进行批量处理,可以考虑使用 glob 导入所有图像文件,然后用循环对每个图像进行上述预处理步骤。
(二)特征提取示例代码
以下是使用 Python 的 OpenCV 库对图像进行 SIFT、SURF 和 HOG 特征提取的示例代码:
import cv2import numpy as npdef extract_sift_features(image_path): # 读取图像 img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE) # 初始化 SIFT 特征检测器 sift = cv2.xfeatures2d.SIFT_create() # 提取 SIFT 特征 keypoints, descriptors = sift.detectAndCompute(img, None) return keypoints, descriptorsdef extract_surf_features(image_path): # 读取图像 img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE) # 初始化 SURF 特征检测器 surf = cv2.xfeatures2d.SURF_create() # 提取 SURF 特征 keypoints, descriptors = surf.detectAndCompute(img, None) return keypoints, descriptorsdef extract_hog_features(image_path): # 读取图像 img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE) # 初始化 HOG 描述符计算器 hog = cv2.HOGDescriptor() win_size = (64, 64) # 可根据需要调整窗口大小 block_size = (16, 16) block_stride = (8, 8) cell_size = (8, 8) nbins = 9 # 通常使用 9 个方向直方图 hog.setBlockSize(block_size) hog.setBlockStride(block_stride) hog.setCellSize(cell_size) hog.setNBins(nbins) # 提取 HOG 特征 hog_descriptors = [] for y in range(0, img.shape[0] - win_size[1], block_stride[1]): for x in range(0, img.shape[1] - win_size[0], block_stride[0]): hog_descriptor = hog.compute(img[y:y + win_size[1], x:x + win_size[0]]) hog_descriptors.append(hog_descriptor.flatten()) hog_descriptors = np.array(hog_descriptors) return hog_descriptors# 示例:提取并保存 SIFT 特征sift_keypoints, sift_descriptors = extract_sift_features('path_to_your_image.jpg')np.save('sift_keypoints.npy', sift_keypoints)np.save('sift_descriptors.npy', sift_descriptors)# 示例:提取并保存 SURF 特征surf_keypoints, surf_descriptors = extract_surf_features('path_to_your_image.jpg')np.save('surf_keypoints.npy', surf_keypoints)np.save('surf_descriptors.npy', surf_descriptors)# 示例:提取并保存 HOG 特征hog_descriptors = extract_hog_features('path_to_your_image.jpg')np.save('hog_descriptors.npy', hog_descriptors)
这段代码定义了三个函数,分别用于提取 SIFT、SURF 和 HOG 特征。每个函数都读取指定路径下的图像,然后使用 OpenCV 提供的相关类和方法进行特征提取。提取到的特征点(对于 SIFT 和 SURF)和描述符(对于所有三种方法)被返回并保存为 NumPy 数组文件,便于后续的图像检索、比对或识别任务。
注意,由于 OpenCV 版本更新和模块迁移,某些功能可能需要调整。请确保使用的 OpenCV 版本支持所选特征提取方法,并可能需要相应的导入语句。此外,对于 SIFT 和 SURF,由于专利问题,这些算法可能在某些 OpenCV 版本中不再默认包含,可能需要手动编译或安装带有非免费模块的 OpenCV 版本。
对于 HOG 特征,代码中使用了一个滑动窗口遍历整幅图像,提取多个局部 HOG 描述符。你可以根据实际应用场景调整窗口大小、步长、块大小、单元格大小和方向直方图的分桶数。如果需要全局 HOG 特征,可以使用整个图像作为输入计算单个 HOG 描述符。
(三)模型评估与可视化示例代码
以下是一段使用 Python 与 sklearn 库绘制混淆矩阵、ROC 曲线和 PR 曲线的示例代码。假设您已经有一个经过训练的分类模型,并且有对应的测试数据集,包括真实标签 y_test 和模型预测的概率输出 y_pred_proba:
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.metrics import confusion_matrix, roc_curve, precision_recall_curve, auc, ConfusionMatrixDisplay# 定义模型评估所需的函数def plot_confusion_matrix(y_true, y_pred, classes, normalize=False, title=None, cmap=plt.cm.Blues): cm = confusion_matrix(y_true, y_pred, normalize=normalize) disp = ConfusionMatrixDisplay(cm, display_labels=classes) disp.plot(cmap=cmap, values_format='.2f') plt.title(title) plt.show()def plot_roc_curve(y_true, y_pred_proba, classes, title=None): fpr = dict() tpr = dict() roc_auc = dict() for i, class_label in enumerate(classes): fpr[class_label], tpr[class_label], _ = roc_curve(y_true==class_label, y_pred_proba[:, i]) roc_auc[class_label] = auc(fpr[class_label], tpr[class_label]) plt.figure() for i, class_label in enumerate(classes): plt.plot(fpr[class_label], tpr[class_label], label=f'{ class_label} (AUC = { roc_auc[class_label]:.2f})') plt.plot([0, 1], [0, 1], 'k--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title(title) plt.legend(loc="lower right") plt.show()def plot_pr_curve(y_true, y_pred_proba, classes, title=None): precision = dict() recall = dict() average_precision = dict() for i, class_label in enumerate(classes): precision[class_label], recall[class_label], _ = precision_recall_curve(y_true==class_label, y_pred_proba[:, i]) average_precision[class_label] = auc(recall[class_label], precision[class_label]) plt.figure() for i, class_label in enumerate(classes): plt.plot(recall[class_label], precision[class_label], label=f'{ class_label} (AP = { average_precision[class_label]:.2f})') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.0]) plt.xlabel('Recall') plt.ylabel('Precision') plt.title(title) plt.legend(loc="upper right") plt.show()# 示例数据:二分类问题,假设已有 y_test 和 y_pred_probay_test = np.array([0, 1, 0, 1, 1, 0, 0, 1]) # 真实标签y_pred_proba = np.array([[0.3, 0.7], [0.¼, 0.9], [0.7, 0.3], [0.9, 0.1], [0.8, 0.2], [0.1, 0.9], [0.6, 0.4], [0.9, 0.1]]) # 模型预测概率# 示例:绘制混淆矩阵plot_confusion_matrix(y_test, np.argmax(y_pred_proba, axis=1), classes=[0, 1], title='Confusion Matrix')# 示例:绘制 ROC 曲线plot_roc_curve(y_test, y_pred_proba, classes=[0, 1], title='ROC Curve')# 示例:绘制 PR 曲线plot_pr_curve(y_test, y_pred_proba, classes=[0, 1], title='PR Curve')
这段代码定义了三个函数:plot_confusion_matrix、plot_roc_curve 和 plot_pr_curve,分别用于绘制混淆矩阵、ROC 曲线和 PR 曲线。在示例部分,我们假设有一个二分类问题,已知 y_test(真实标签)和 y_pred_proba(模型预测的每个类别的概率)。函数接收这些数据并根据提供的类标签绘制相应的图表。
请注意,这段代码适用于多分类问题,只需确保 y_test 和 y_pred_proba 的格式与示例数据一致。在实际应用中,请替换为您的真实测试数据和模型预测结果。
四、医疗健康领域示例代码
(一)医疗影像分析示例代码
在医疗影像分析领域,Python 提供了丰富的库和框架,如 SimpleITK、ITK、Pillow、numpy、scikit-image、OpenCV、PyTorch、TensorFlow 等,用于处理 CT、MRI、超声等影像的分割、标注、病变检测、定量测量等工作。
SimpleITK影像基本处理示例代码
下面是一个基于 SimpleITK 的简单示例,展示如何进行影像读取、基本预处理、二值化分割和病变区域体积计算。对于更复杂的任务如深度学习驱动的病变检测,可以使用 PyTorch 或 TensorFlow 构建神经网络模型。
import SimpleITK as sitkimport numpy as np# 1. 影像读取ct_image_file = 'path/to/your/ct_scan.nii.gz'ct_image = sitk.ReadImage(ct_image_file)# 2. 基本预处理(如窗口 leveling、平滑等)window_level = 50 # 调整窗宽、窗位以突出感兴趣组织window_width = 200ct_image = sitk.IntensityWindowing(ct_image, windowMinimum=window_level - window_width / 2, windowMaximum=window_level + window_width / 2)# 可选:进行平滑处理gaussian_filter = sitk.SmoothingRecursiveGaussianImageFilter()ct_image = gaussian_filter.Execute(ct_image, sigma=1.0)# 3. 影像分割(这里仅展示阈值分割,实际可能需要更复杂的分割方法如深度学习模型)threshold_value = -500 # 根据具体数据设定阈值binary_mask = sitk.BinaryThreshold(ct_image, lowerThreshold=threshold_value, upperThreshold=threshold_value)# 4. 病变区域体积计算label_stats_filter = sitk.LabelStatisticsImageFilter()label_stats_filter.Execute(binary_mask, ct_image) # 计算标签统计信息# 获取病变区域标签(假设二值化后病变区域标签为 1)lesion_label = 1lesion_volume_mm3 = label_stats_filter.GetPhysicalSize(lesion_label)print(f"Lesion volume: { lesion_volume_mm3} mm³")# 可视化(可选)sitk.Show(sitk.LabelOverlay(ct_image, binary_mask, opacity=0.5), title='Segmented Lesion')
这是一个非常基础的示例,仅涉及了影像读取、窗口 leveling、二值化分割以及病变体积计算。实际医疗影像分析任务可能需要更复杂的预处理步骤(如配准、去噪、标准化等)、更精准的分割算法(如基于深度学习的语义分割模型)、以及对多种特征的定量测量(如形状特征、纹理特征等)。
深度学习驱动的病变检测示例代码
对于深度学习驱动的病变检测,可以使用 PyTorch 或 TensorFlow 构建 U-Net、ResNet、Mask R-CNN 等神经网络模型。以下是一个简化的 PyTorch 模型训练与推断示例:
import torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import DataLoader, Dataset# 定义你的深度学习模型(例如 U-Net)class MySegmentationModel(nn.Module): def __init__(self): super(MySegmentationModel, self).__init__() # ... 构建模型结构 ... def forward(self, x): # ... 定义前向传播逻辑 ...class MedicalImageDataset(Dataset): def __init__(self, image_files, mask_files, transform=None): self.image_files = image_files self.mask_files = mask_files self.transform = transform def __len__(self): return len(self.image_files) def __getitem__(self, idx): image = load_and_preprocess_image(self.image_files[idx]) mask = load_and_preprocess_mask(self.mask_files[idx]) if self.transform: image, mask = self.transform(image, mask) return image, mask# 加载数据集、定义损失函数、优化器等dataset = MedicalImageDataset(image_files, mask_files)dataloader = DataLoader(dataset, batch_size=4, shuffle=True)model = MySegmentationModel()criterion = nn.BCEWithLogitsLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型(这里省略具体的训练循环)for epoch in range(num_epochs): for inputs, targets in dataloader: optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, targets) loss.backward() optimizer.step()# 使用训练好的模型进行预测test_image = load_and_preprocess_image(test_image_file)with torch.no_grad(): prediction = model(test_image.unsqueeze(0)).squeeze().sigmoid() > 0.5 prediction = prediction.numpy()# 可视化预测结果show_prediction(test_image, prediction)
上述代码仅为示例,实际应用时需要根据具体任务需求和数据集特性进行详细设计和实现。同时,确保遵循医学伦理规定,使用合规的数据集进行训练和验证,并在专业医疗人员指导下进行模型开发与应用。
TensorFlow深度学习驱动的病变检测示例代码
以下是一个使用 TensorFlow 构建深度学习模型进行病变检测的基本示例。在这个例子中,我们将构建一个简单的卷积神经网络(CNN)模型来对医学影像进行二分类(病变存在与否)。请注意,实际应用中可能需要更复杂的网络架构、更精细的预处理步骤以及更大的数据集来达到理想性能。此外,确保使用合规的医学影像数据集,并在医疗专业人士的指导下进行模型开发与应用。
import tensorflow as tffrom tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense, Dropoutfrom tensorflow.keras.models import Modelfrom tensorflow.keras.preprocessing.image import ImageDataGeneratorfrom sklearn.model_selection import train_test_splitimport numpy as npimport os# 1. 数据预处理与加载# 假设已将医学影像数据整理为如下目录结构:# - data/# - train/# - normal/# - img1.png# - img2.png# ...# - abnormal/# - img1.png# - img2.png# ...# - test/# - normal/# ...# - abnormal/# ...# 设置数据路径和参数data_dir = 'data'img_height, img_width = 256, 256batch_size = 32epochs = 50# 定义数据生成器,进行数据增强和标准化train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest')test_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory( os.path.join(data_dir, 'train'), target_size=(img_height, img_width), batch_size=batch_size, class_mode='binary')validation_generator = test_datagen.flow_from_directory( os.path.join(data_dir, 'test'), target_size=(img_height, img_width), batch_size=batch_size, class_mode='binary')# 2. 构建深度学习模型input_shape = (img_height, img_width, 3) # 假设使用 RGB 影像inputs = Input(shape=input_shape)x = Conv2D(32, (3, 3), activation='relu')(inputs)x = MaxPooling2D((2, 2))(x)x = Conv2D(64, (3, 3), activation='relu')(x)x = MaxPooling2D((2, 2))(x)x = Conv2D(128, (3, 3), activation='relu')(x)x = MaxPooling2D((2, 2))(x)x = Flatten()(x)x = Dense(512, activation='relu')(x)x = Dropout(0.5)(x)outputs = Dense(1, activation='sigmoid')(x)model = Model(inputs=inputs, outputs=outputs)# 3. 编译模型model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 4. 训练模型history = model.fit(train_generator, epochs=epochs, validation_data=validation_generator)# 5. 评估模型性能test_loss, test_acc = model.evaluate(validation_generator)print(f'Test accuracy: { test_acc:.4f}')# 6. 保存模型model.save('path/to/save/model.h5')
在这个示例中:
我们首先设置了数据路径、图像尺寸、批次大小和训练轮数等参数,并使用 ImageDataGenerator 实现数据增强和标准化。然后构建了一个简单的 CNN 模型,包含几个卷积层、最大池化层、全连接层和 dropout 层,最后使用 sigmoid 激活函数输出二分类结果。编译模型时选择了 Adam 优化器,使用二元交叉熵作为损失函数,并监控准确率指标。使用训练数据生成器对模型进行训练,并在验证集上评估模型性能。训练结束后,保存训练好的模型以便后续使用。
请根据实际项目需求调整模型结构、超参数以及数据预处理步骤。在实际部署之前,可能还需要进一步评估模型在独立测试集上的表现,确保泛化性能良好。
(二)病理切片分析示例代码:
为了演示病理切片分析中自动识别和量化组织病理学图像中的细胞、组织结构等特征,这里提供一个使用 TensorFlow 和 Keras 搭建卷积神经网络(CNN)模型的基本示例。本示例假设您已经准备好了标注好的病理切片图像数据集,其中每个样本被标记为癌症级别或其他相关临床指标。为了简化说明,我们以癌症分级为例,但同样的框架可以扩展到其他预测任务,如疾病进展预测。
(1)病例切片分析基本示例代码
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, BatchNormalizationfrom tensorflow.keras.preprocessing.image import ImageDataGeneratorfrom sklearn.model_selection import train_test_splitimport numpy as npimport os# 1. 数据预处理与加载# 假设已将病理切片图像数据整理为如下目录结构:# - data/# - train/# - grade_1/# - img1.png# - img2.png# ...# - grade_2/# - img1.png# - img2.png# ...# - grade_3/# - img1.png# - img2.png# ...# - test/# - grade_1/# ...# - grade_2/# ...# - grade_3/# ...# 设置数据路径和参数data_dir = 'data'img_height, img_width = 512, 512 # 调整为实际图像大小num_classes = 3 # 假设有3个癌症等级batch_size = 16epochs = 50# 定义数据生成器,进行数据增强和标准化train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest')test_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory( os.path.join(data_dir, 'train'), target_size=(img_height, img_width), batch_size=batch_size, class_mode='categorical') # 多分类问题validation_generator = test_datagen.flow_from_directory( os.path.join(data_dir, 'test'), target_size=(img_height, img_width), batch_size=batch_size, class_mode='categorical')# 2. 构建深度学习模型input_shape = (img_height, img_width, 3) # 假设使用 RGB 影像model = Sequential([ Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=input_shape), BatchNormalization(), MaxPooling2D(pool_size=(2, 2)), Conv2D(64, (3, 3), activation='relu', padding='same'), BatchNormalization(), MaxPooling2D(pool_size=(2, 2)), Conv2D(128, (3, 3), activation='relu', padding='same'), BatchNormalization(), MaxPooling2D(pool_size=(2, 2)), Conv2D(256, (3, 3), activation='relu', padding='same'), BatchNormalization(), MaxPooling2D(pool_size=(2, 2)), Flatten(), Dense(512, activation='relu'), Dense(num_classes, activation='softmax') # 输出癌症级别的概率分布])# 3. 编译模型model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 4. 训练模型history = model.fit(train_generator, epochs=epochs, validation_data=validation_generator)# 5. 评估模型性能test_loss, test_acc = model.evaluate(validation_generator)print(f'Test accuracy: { test_acc:.4f}')# 6. 保存模型model.save('path/to/save/model.h5')
在这个示例中:
我们首先设置了数据路径、图像尺寸、批次大小、癌症等级数量等参数,并使用 ImageDataGenerator 实现数据增强和标准化。由于这是一个多分类问题,我们设置 class_mode='categorical' 并使用 one-hot 编码表示类别标签。然后构建了一个更深的 CNN 模型,包含多个卷积层、批量归一化层、最大池化层,以及最后的全连接层(用于特征整合)和 softmax 输出层(用于癌症级别的概率分布)。这样的网络结构能够捕获病理切片中的复杂细胞和组织结构特征。编译模型时选择了 Adam 优化器,使用多类交叉熵作为损失函数,并监控准确率指标。使用训练数据生成器对模型进行训练,并在验证集上评估模型性能。训练结束后,保存训练好的模型以便后续使用。
在实际应用中,可能需要对模型结构进行调整以适应特定的病理图像特点,或者采用更先进的网络结构(如预训练的 ResNet、Inception 等)。此外,可能还需要考虑使用更精细的数据预处理、更复杂的特征工程、模型融合等策略来提高预测性能。最后,务必确保所使用的数据集符合伦理法规要求,并在医疗专业人士的指导下进行模型开发与应用。
(2)疾病进展预测示例代码
为了演示如何将上述框架扩展到疾病进展预测任务,假设您已经准备了相应的病理切片图像数据集,每个样本不仅被标记为当前的癌症级别,还附加了一个反映疾病进展程度的连续变量(如预后的生存时间、疾病进展评分等)。这种情况下,我们将面临一个回归问题而非分类问题。以下是基于之前的 CNN 结构修改以适应疾病进展预测任务的示例代码:
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, BatchNormalizationfrom tensorflow.keras.preprocessing.image import ImageDataGeneratorfrom sklearn.model_selection import train_test_splitimport numpy as npimport os# 1. 数据预处理与加载# 假设已将病理切片图像数据整理为如下目录结构:# - data/# - train/# - image1.png # 图像文件名与对应的疾病进展标签文件名相同# - image1_label.txt # 包含单个数值,表示该图像对应的疾病进展程度# - image2.png# - image2_label.txt# ...# - test/# - image1.png# - image1_label.txt# ...# - imageN.png# - imageN_label.txt# 设置数据路径和参数data_dir = 'data'img_height, img_width = 512, 512 # 调整为实际图像大小batch_size = 16epochs = 50# 加载数据def load_data(directory): images = [] labels = [] for filename in os.listdir(directory): if filename.endswith('.png'): image_path = os.path.join(directory, filename) label_path = os.path.join(directory, filename.replace('.png', '_label.txt')) with open(label_path, 'r') as f: label = float(f.readline().strip()) images.append(image_path) labels.append(label) return images, np.array(labels)train_images, train_labels = load_data(os.path.join(data_dir, 'train'))test_images, test_labels = load_data(os.path.join(data_dir, 'test'))# 数据增强与标准化train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest')train_generator = train_datagen.flow_from_dataframe( pd.DataFrame({ 'image': train_images, 'label': train_labels}), x_col='image', y_col='label', target_size=(img_height, img_width), batch_size=batch_size, class_mode=None) # 回归任务不使用 class_modetest_datagen = ImageDataGenerator(rescale=1./255)test_generator = test_datagen.flow_from_dataframe( pd.DataFrame({ 'image': test_images, 'label': test_labels}), x_col='image', y_col='label', target_size=(img_height, img_width), batch_size=batch_size, class_mode=None)# 2. 构建深度学习模型input_shape = (img_height, img_width, 3) # 假设使用 RGB 影像model = Sequential([ Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=input_shape), BatchNormalization(), MaxPooling2D(pool_size=(2, 2)), Conv2D(64, (3, 3), activation='relu', padding='same'), BatchNormalization(), MaxPooling2D(pool_size=(2, 2)), Conv2D(128, (3, 3), activation='relu', padding='same'), BatchNormalization(), MaxPooling2D(pool_size=(2, 2)), Conv2D(256, (3, 3), activation='relu', padding='same'), BatchNormalization(), MaxPooling2D(pool_size=(2, 2)), Flatten(), Dense(512, activation='relu'), Dense(1) # 输出单个数值,表示疾病进展程度])# 3. 编译模型model.compile(optimizer='adam', loss='mean_squared_error', # 使用均方误差作为回归任务的损失函数 metrics=['mean_absolute_error']) # 监控平均绝对误差# 4. 训练模型history = model.fit(train_generator, epochs=epochs, validation_data=test_generator)# 5. 评估模型性能test_loss, test_mae = model.evaluate(test_generator)print(f'Test mean absolute error: { test_mae:.4f}')# 6. 保存模型model.save('path/to/save/model.h5')
在这个示例中:
我们首先调整了数据加载部分,使得每个病理切片图像与其对应的疾病进展标签文件对应。数据加载函数 load_data 从文件名匹配的 .txt 文件中读取标签值。修改了数据生成器的使用方式,通过 flow_from_dataframe 函数接收包含图像路径和标签的 DataFrame,而不是使用 flow_from_directory。这是因为我们的标签不再是类别标签,而是与图像文件名关联的单独文件中的数值。在构建模型时,将最后一层的输出节点数改为 1,以适应回归任务输出单个连续数值的要求。编译模型时,将损失函数改为均方误差(mean_squared_error),并监控平均绝对误差(mean_absolute_error)作为评估指标。其余部分(训练、评估、保存模型)保持不变。
请注意,这个示例假设您的数据集已按要求组织,并且每个图像都有对应的标签文件。如果数据集结构不同,您可能需要相应地调整数据加载和数据生成器的配置。同时,实际应用中仍需关注模型性能的提升策略、数据预处理的细节以及模型解释性等方面。

五、制造业与质量控制示例代码
(一)缺陷检测示例代码
在实现缺陷检测系统时,通常会采用计算机视觉技术,尤其是深度学习方法,如卷积神经网络(CNN)。这里给出一个基于Python和深度学习库TensorFlow/Keras的简单示例代码,用于训练一个CNN模型来识别产品表面瑕疵或部件缺失。假设您已经准备了一个标注好的图像数据集,其中包含正常产品和存在缺陷的产品图像。
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropoutfrom tensorflow.keras.preprocessing.image import ImageDataGeneratorimport numpy as npimport os# 1. 数据预处理与加载# 假设已将标注好的图像数据整理为如下目录结构:# - data/# - train/# - normal/# - image1.png# - image2.png# ...# - defect/# - image1.png# - image2.png# ...# - validation/# - normal/# - image1.png# - image2.png# ...# - defect/# - image1.png# - image2.png# ...data_dir = 'data'img_height, img_width = 256, 256 # 调整为实际图像大小batch_size = 32epochs = 50num_classes = 2 # 正常和缺陷两类train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest')val_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory( os.path.join(data_dir, 'train'), target_size=(img_height, img_width), batch_size=batch_size, class_mode='binary')validation_generator = val_datagen.flow_from_directory( os.path.join(data_dir, 'validation'), target_size=(img_height, img_width), batch_size=batch_size, class_mode='binary')# 2. 构建深度学习模型model = Sequential([ Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=(img_height, img_width, 3)), MaxPooling2D(pool_size=(2, 2)), Conv2D(64, (3, 3), activation='relu', padding='same'), MaxPooling2D(pool_size=(2, 2)), Conv2D(128, (3, 3), activation='relu', padding='same'), MaxPooling2D(pool_size=(2, 2)), Conv2D(256, (3, 3), activation='relu', padding='same'), MaxPooling2D(pool_size=(2, 2)), Flatten(), Dense(512, activation='relu'), Dropout(0.5), Dense(num_classes, activation='sigmoid') # 输出二分类概率])# 3. 编译模型model.compile(optimizer='adam', loss='binary_crossentropy', # 二分类任务使用 binary_crossentropy 损失函数 metrics=['accuracy'])# 4. 训练模型history = model.fit( train_generator, epochs=epochs, validation_data=validation_generator, callbacks=[tf.keras.callbacks.ModelCheckpoint('best_model.h5', save_best_only=True, monitor='val_accuracy')]) # 保存最优模型# 5. 评估模型性能model.load_weights('best_model.h5') # 加载最优模型权重test_loss, test_acc = model.evaluate(validation_generator)print(f'Validation accuracy: { test_acc * 100:.2f}%')# 6. 使用模型进行预测def predict_defect(image_path): img = tf.keras.preprocessing.image.load_img(image_path, target_size=(img_height, img_width)) img_array = tf.keras.preprocessing.image.img_to_array(img) img_array = tf.expand_dims(img_array, axis=0) img_array = img_array / 255.0 # 预处理与训练时一致 predictions = model.predict(img_array) class_id = np.argmax(predictions) # 获取最高概率对应的类别 probability = predictions[0][class_id] if class_id == 0: label = 'Normal' else: label = 'Defective' return label, probability# 示例预测result_label, result_prob = predict_defect('path/to/test/image.png')print(f'Predicted label: { result_label} (Probability: { result_prob:.2f})')
在这个示例中:
我们使用ImageDataGenerator对训练和验证数据进行数据增强,并从相应的目录结构中加载数据。这些目录分别包含正常产品和存在缺陷产品的子目录。构建了一个简单的CNN模型,包括多层卷积、最大池化、全连接层和Dropout层。最后输出层使用sigmoid激活函数,适合二分类任务。编译模型时,选择binary_crossentropy作为损失函数,监控accuracy指标。同时添加了一个ModelCheckpoint回调,用于保存每轮验证集上精度最高的模型。训练模型后,加载最优模型权重,评估其在验证集上的性能。定义了一个predict_defect函数,用于接收单个图像路径,加载、预处理图像,并使用模型进行预测。返回预测的类别(正常或缺陷)及其对应的概率。
请注意,这个示例假设您的数据集已按要求组织,并且每个图像都已被正确标注。实际应用中,您可能还需要根据具体任务调整模型结构、优化参数、处理不平衡数据集等问题。
(二)机器人视觉示例代码

(1)模板匹配技术示例代码
在实现机器人视觉系统时,通常需要结合图像识别、定位和深度学习等技术来引导工业机器人进行精确操作。以下是一个基于 Python 和 OpenCV 的简单示例,演示如何使用图像处理和特征匹配技术帮助机器人定位目标物体并进行抓取。对于更复杂的任务,如深度学习驱动的物体识别与定位,可以使用 TensorFlow 或 PyTorch 构建神经网络模型。
import cv2import numpy as np# 1. 加载模板图像(要抓取的目标物体的参考图像)template_image_path = 'path/to/template_image.png'template = cv2.imread(template_image_path, 0) # 读取为灰度图像# 2. 读取实时摄像头或视频流中的图像cap = cv2.VideoCapture('path/to/video_stream.mp4') # 或使用 0 代替字符串以访问默认摄像头while cap.isOpened(): ret, frame = cap.read() if not ret: break # 3. 将实时图像转换为灰度图像 gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 4. 使用模板匹配算法找到目标物体在实时图像中的位置 res = cv2.matchTemplate(gray, template, cv2.TM_CCOEFF_NORMED) threshold = 0.8 # 设置匹配阈值 loc = np.where(res >= threshold) # 5. 绘制匹配到的目标物体的位置轮廓 for pt in zip(*loc[::-1]): cv2.rectangle(frame, pt, (pt[0] + template.shape[1], pt[1] + template.shape[0]), (0, 255, 0), 2) # 6. 显示结果并发送坐标信息给机器人控制系统(此处仅为模拟,实际应用中需对接机器人API) cv2.imshow('Robot Vision', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break # 假设目标物体位于匹配结果的第一个位置 target_position = loc[0][0], loc[0][1] send_target_position_to_robot(target_position) # 实际应用中替换为实际通信函数cap.release()cv2.destroyAllWindows()
在这个示例中:
我们首先加载一个模板图像,即要抓取的目标物体的参考图像。接着,我们从实时摄像头或视频流中获取帧图像,并将其转换为灰度图像。使用 OpenCV 的 matchTemplate 函数对灰度图像和模板图像进行匹配,得到匹配结果。设置一个匹配阈值,筛选出高于阈值的匹配结果,并使用 np.where 找到匹配位置的坐标。在原始帧图像上绘制匹配到的目标物体的位置轮廓,并显示结果。假设目标物体位于匹配结果的第一个位置,我们将其坐标发送给机器人控制系统。在实际应用中,这一步需要替换为实际与机器人通信的函数或接口。
请注意,这个示例仅使用了简单的模板匹配技术,适用于目标物体特征明显、背景相对简单的情况。对于复杂场景或需要识别多种目标物体的任务,可能需要使用更高级的图像识别与定位技术,如基于深度学习的物体检测模型(如 YOLO、SSD、Faster R-CNN 等)。在实际应用中,还需要考虑光照变化、物体姿态变化、遮挡等因素对识别与定位准确性的影响,并进行相应的鲁棒性优化。
(2)基于深度学习的物体检测模型示例代码
在实际应用中,基于深度学习的物体检测模型(如 YOLO、SSD、Faster R-CNN 等)能够更好地应对复杂场景下的物体识别与定位问题。以下是一个使用 YOLOv5(一种高效的实时目标检测模型)的 Python 示例代码,展示如何对摄像头输入进行实时物体检测,并考虑光照变化、物体姿态变化、遮挡等因素的鲁棒性优化:
import torchimport cv2from PIL import Imageimport numpy as np# 1. 导入预训练的 YOLOv5 模型from yolov5.models.experimental import attempt_loadmodel = attempt_load('yolov5s.pt', map_location=torch.device('cuda' if torch.cuda.is_available() else 'cpu'))# 2. 设置模型运行参数model.conf = 0.9 # 提高检测置信度阈值,减少误检model.half() # 使用半精度计算以提高速度(如果设备支持)# 3. 定义图像预处理函数def preprocess(image): img = image.copy() img = img[..., ::-1].transpose((2, 0, 1)) # BGR to RGB, HWC to CHW img /= 255.0 # Normalize pixel values return img.unsqueeze(0).to(model.device)# 4. 开启摄像头或视频流cap = cv2.VideoCapture('path/to/video_stream.mp4') # 或使用 0 代替字符串以访问默认摄像头while cap.isOpened(): ret, frame = cap.read() if not ret: break # 5. 进行实时物体检测 img_pil = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)) img_tensor = preprocess(img_pil) pred = model(img_tensor)[0] # 6. 解码检测结果 boxes = pred[:, :, 0:4] scores = pred[:, :, 4] * pred[:, :, 5] labels = pred[:, :, 6] # 7. 应用非极大抑制(NMS)去除重复检测结果 boxes, scores, labels = model.nms(boxes, scores, labels, iou_threshold=0.¾) # 8. 将检测框绘制到原图上 for box, score, label in zip(boxes, scores, labels): if score > model.conf: x1, y1, x2, y2 = box.tolist() class_name = model.names[label] color = (0, 255, 0) if score > 0.9 else (0, 0, 255) # 高置信度用绿色,低置信度用红色 cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), color, 2) cv2.putText(frame, f'{ class_name} { score:.2f}', (int(x1), int(y1)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2) # 9. 显示结果 cv2.imshow('YOLOv5 Object Detection', frame) if cv2.waitKey(1) & 0xFF == ord('q'): breakcap.release()cv2.destroyAllWindows()
在这个示例中:
我们导入预训练的 YOLOv5 模型,并设置其运行参数,如提高检测置信度阈值以减少误检,启用半精度计算(如果设备支持)以提高检测速度。定义一个图像预处理函数,将输入图像转换为模型所需的格式。开启摄像头或视频流。对每一帧图像进行实时物体检测,获取预测结果。解码检测结果,包括边界框、得分和类别标签。应用非极大抑制(NMS)去除重复或重叠的检测结果。将检测到的物体用矩形框标出,并在框内显示类别名和置信度分数。高置信度结果使用绿色框,低置信度结果使用红色框。显示检测结果。
针对光照变化、物体姿态变化、遮挡等因素的鲁棒性优化:
预训练模型的选择:使用在大规模数据集上预训练的模型,如 COCO 数据集,这些模型已经具备了一定的泛化能力,能够应对不同光照、姿态和部分遮挡的情况。数据增强:在模型训练阶段采用数据增强技术,如随机改变亮度、对比度、饱和度、色调、旋转、缩放、翻转、添加噪声等,以模拟各种实际环境条件,提升模型的鲁棒性。模型融合或多尺度检测:融合多个模型的预测结果,或者在一个模型中使用多尺度特征进行检测,有助于捕捉不同尺度和姿态的物体。后处理规则:根据具体应用场景设定额外的后处理规则,如根据物体大小、形状、与其他物体的空间关系等信息过滤掉不合理或不符合应用场景的检测结果。
以上代码仅为示例,实际应用时需根据具体需求调整模型参数、后处理逻辑以及与机器人系统的接口对接。同时,为了应对特定场景或物体,可能需要对预训练模型进行微调(fine-tuning),使用包含特定目标的标注数据进行进一步训练。
六、农业与环境科学示例代码
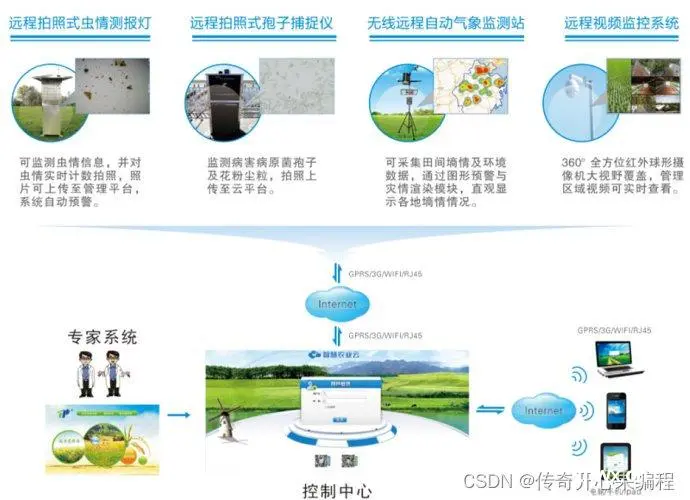
(一)作物病虫害监测
以下是一个使用 Python 和基于深度学习的图像识别模型(如预训练的 YOLOv5)来实现作物病虫害监测的示例代码。假设无人机已经采集了农田图像,并将其保存为本地文件。这个示例将读取这些图像,使用 YOLOv5 模型进行病虫害检测,并在检测到病虫害时输出相关信息。
import torchimport cv2import numpy as npfrom PIL import Imagefrom yolov5.models.experimental import attempt_load# 1. 加载预训练的 YOLOv5 模型,针对病虫害检测进行微调model = attempt_load('yolov5_crop_diseases.pt', map_location=torch.device('cuda' if torch.cuda.is_available() else 'cpu'))model.conf = 0.8 # 设置检测置信度阈值model.half() # 使用半精度计算以提高速度(如果设备支持)# 2. 图像预处理函数def preprocess(image_path): img = Image.open(image_path) img = img.convert('RGB') img = np.array(img).astype(np.float32) img /= 255.0 img = img.transpose(2, 0, 1) # HWC to CHW img = torch.from_numpy(img).unsqueeze(0) # Add batch dimension return img.to(model.device)# 3. 定义病虫害检测函数def detect_diseases(image_path): img = preprocess(image_path) pred = model(img)[0] # 解码检测结果 boxes = pred[:, :, 0:4] scores = pred[:, :, 4] * pred[:, :, 5] labels = pred[:, :, 6] # 应用非极大抑制(NMS)去除重复检测结果 boxes, scores, labels = model.nms(boxes, scores, labels, iou_threshold=0.5) # 提取并返回检测到的病虫害信息 detections = [] for box, score, label in zip(boxes, scores, labels): if score > model.conf: x1, y1, x2, y2 = box.tolist() class_id = int(label) class_name = model.names[class_id] detections.append({ 'class_id': class_id, 'class_name': class_name, 'confidence': score.item(), 'bbox': [x1, y1, x2, y2], }) return detections# 4. 读取无人机拍摄的农田图像,并进行病虫害检测image_paths = ['path/to/image1.jpg', 'path/to/image2.jpg', 'path/to/image3.jpg'] # 替换为实际图像路径列表for image_path in image_paths: detections = detect_diseases(image_path) if detections: print(f"Image: { image_path}") print("Detected Diseases:") for detection in detections: print(f"- { detection['class_name']} (Confidence: { detection['confidence']:.2f}, Bounding Box: { detection['bbox']})") print("\n") else: print(f"No diseases detected in image: { image_path}\n")# 可选:可视化检测结果(需要 OpenCV)def visualize_detection(image_path, detections): img = cv2.imread(image_path) for detection in detections: x1, y1, x2, y2 = detection['bbox'] cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2) cv2.putText(img, f"{ detection['class_name']} { detection['confidence']:.2f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2) cv2.imshow("Crop Disease Detection", img) cv2.waitKey(0) cv2.destroyAllWindows()# 示例:对某一张图像可视化检测结果visualize_detection(image_paths[0], detect_diseases(image_paths[0]))
在这个示例中:
我们加载了一个针对作物病虫害检测微调过的 YOLOv5 模型,并设置其运行参数。定义了一个图像预处理函数,用于将图像文件转换为模型所需的输入格式。定义了一个病虫害检测函数,它接收图像路径,返回检测到的病虫害信息(类名、置信度、边界框坐标)。循环遍历无人机拍摄的农田图像列表,对每张图像进行病虫害检测,并打印出检测结果。可选地,提供了可视化检测结果的辅助函数,它在原图像上绘制出检测到的病虫害的边界框及类名、置信度信息。
注意:
yolov5_crop_diseases.pt 是假设已有的针对作物病虫害检测微调后的模型权重文件,需要替换为实际路径。image_paths 列表应替换为实际无人机拍摄的农田图像文件路径。如果需要在实际应用中部署此代码,可能需要进一步封装成服务或集成到现有农业管理系统中,以便自动化处理大量图像数据和触发防治措施。
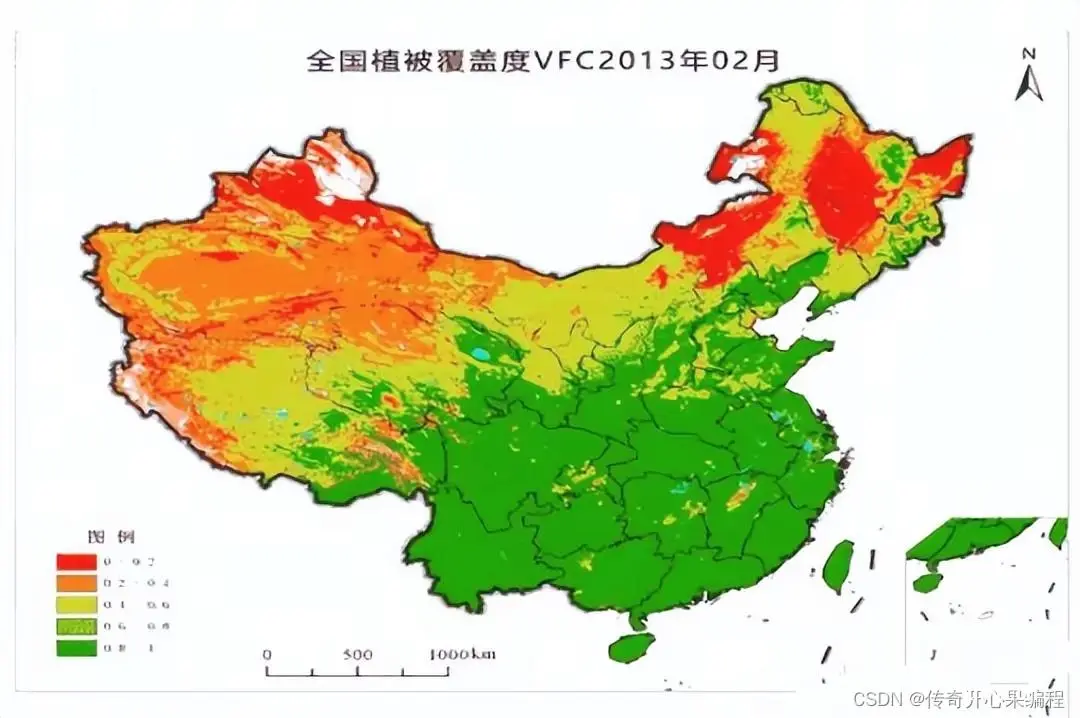
(二)植被覆盖分析示例代码
以下是一个使用 Python 和相关库(如 GDAL、NumPy、rasterio)进行植被覆盖分析的示例代码,包括计算植被指数(例如 NDVI,归一化差分植被指数)和进行简单的变化检测。假设我们有两个不同时间点的卫星遥感图像(通常为多光谱数据),分别代表同一区域在两个时期的植被情况。
import numpy as npimport rasteriofrom rasterio.plot import showfrom rasterio.merge import mergefrom rasterio.windows import Windowfrom rasterio.transform import Affinefrom scipy.ndimage import binary_dilation, binary_opening# 1. 定义植被指数计算函数(以NDVI为例)def calculate_ndvi(red_band, nir_band): ndvi = (nir_band - red_band) / (nir_band + red_band) ndvi[~np.isfinite(ndvi)] = 0 # 将无效值(如除以零)置为0 return ndvi# 2. 读取两个时期卫星图像image_path_1 = 'path/to/satellite_image_1.tif'image_path_2 = 'path/to/satellite_image_2.tif'with rasterio.open(image_path_1) as src1, rasterio.open(image_path_2) as src2: # 确保两幅图像具有相同的地理参考和分辨率 assert src1.crs == src2.crs assert src1.res == src2.res # 获取红色波段和近红外波段数据 red_band1 = src1.read(3) # 假设红波段在第3个索引(根据实际数据调整) nir_band1 = src1.read(4) # 假设近红外波段在第4个索引(根据实际数据调整) red_band2 = src2.read(3) nir_band2 = src2.read(4) # 计算两个时期的NDVI ndvi_1 = calculate_ndvi(red_band1, nir_band1) ndvi_2 = calculate_ndvi(red_band2, nir_band2) # 保存NDVI结果 with rasterio.open('ndvi_period1.tif', 'w', driver='GTiff', height=ndvi_1.shape[0], width=ndvi_1.shape[1], count=1, dtype=ndvi_1.dtype, crs=src1.crs, transform=src1.transform) as dst: dst.write(ndvi_1, 1) with rasterio.open('ndvi_period2.tif', 'w', driver='GTiff', height=ndvi_2.shape[0], width=ndvi_2.shape[1], count=1, dtype=ndvi_2.dtype, crs=src1.crs, transform=src1.transform) as dst: dst.write(ndvi_2, 1)# 3. 变化检测:计算两期NDVI差异并应用阈值与形态学操作简化边界threshold = 0.2 # 变化阈值,根据实际情况调整ndvi_diff = np.abs(ndvi_2 - ndvi_1)change_mask = np.where(ndvi_diff > threshold, 1, 0) # 仅保留显著变化区域# 形态学操作,平滑边界并消除小面积噪声structuring_element = np.ones((3, 3)) # 3x3方形结构元素change_mask = binary_dilation(change_mask, structure=structuring_element, iterations=1)change_mask = binary_opening(change_mask, structure=structuring_element, iterations=1)# 保存变化检测结果with rasterio.open('change_detection.tif', 'w', driver='GTiff', height=change_mask.shape[0], width=change_mask.shape[1], count=1, dtype=change_mask.dtype, crs=src1.crs, transform=src1.transform) as dst: dst.write(change_mask.astype('uint8'), 1)# 可视化NDVI和变化检测结果show(ndvi_1, cmap='RdYlGn', vmin=-1, vmax=1, title='NDVI Period 1')show(ndvi_2, cmap='RdYlGn', vmin=-1, vmax=1, title='NDVI Period 2')show(change_mask, cmap='coolwarm', title='Change Detection')# 注:以上可视化仅在Jupyter notebook环境中有效,若在命令行执行,需使用其他绘图库如matplotlib进行展示
在这个示例中:
我们定义了一个计算 NDVI 的函数 calculate_ndvi,接受红色波段和近红外波段数据作为输入。使用 rasterio 读取两个时期的卫星图像,并提取红波段和近红外波段数据。计算两期的 NDVI 并保存结果。对两期 NDVI 进行差异计算,并设定阈值以确定显著变化区域。通过形态学操作(膨胀和开运算)平滑边界,消除小面积噪声。最后,保存变化检测结果,并使用 rasterio.plot.show(在 Jupyter notebook 环境下)简单地可视化 NDVI 和变化检测结果。
注意:
path/to/satellite_image_1.tif 和 path/to/satellite_image_2.tif 应替换为实际的卫星遥感图像文件路径。在实际应用中,可能需要根据具体数据调整波段索引(此处假设红波段为第3个索引,近红外波段为第4个索引)。确保所使用的卫星数据包含所需的波段。变化阈值 threshold 可根据实际需求进行调整,以适应不同场景下的植被变化敏感度。可视化部分需要在 Jupyter notebook 环境中运行。如果在命令行或其他环境执行,可以使用 matplotlib 或其他绘图库进行替代。
七、电子商务与零售示例代码
(一)商品识别与推荐示例代码
(1)相似商品推荐示例代码
实现商品识别与推荐功能通常涉及图像识别、特征提取、深度学习模型以及推荐算法等技术。以下是一个基于 Python 和相关库(如 TensorFlow、Keras、PIL、sklearn)的简要示例代码,展示如何构建一个简单的商品识别模型,并进行相似商品推荐。由于实际应用中可能需要大量的训练数据、预处理步骤及复杂的模型结构,此处仅提供一个概念性的示例以说明基本流程。
import osimport numpy as npfrom PIL import Imagefrom tensorflow.keras.applications import VGG16from tensorflow.keras.preprocessing import imagefrom sklearn.metrics.pairwise import cosine_similarity# 1. 准备商品图片数据集data_dir = 'path/to/your/product_dataset' # 替换为实际的商品图片数据集路径class_labels = os.listdir(data_dir) # 假设每个子目录对应一种商品类别# 2. 加载预训练模型(如 VGG16)并移除顶层全连接层base_model = VGG16(weights='imagenet', include_top=False)# 3. 编写函数处理单张图片并提取特征向量def extract_features(img_path, model): img = image.load_img(img_path, target_size=(224, 224)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = preprocess_input(x) features = model.predict(x) return features.flatten()# 4. 提前计算所有商品图片的特征向量并存储features_dict = { }for label in class_labels: label_dir = os.path.join(data_dir, label) for img_file in os.listdir(label_dir): img_path = os.path.join(label_dir, img_file) features = extract_features(img_path, base_model) features_dict[img_path] = features# 5. 用户上传图片并提取其特征向量user_uploaded_img_path = 'path/to/uploaded/image.jpg' # 替换为用户上传的图片路径user_img_features = extract_features(user_uploaded_img_path, base_model)# 6. 计算用户上传图片与所有商品图片的相似度similarities = { img_path: cosine_similarity([user_img_features], [features])[0][0] for img_path, features in features_dict.items()}# 7. 推荐最相似的商品(按相似度排序)top_n = 5 # 推荐数量sorted_similarities = sorted(similarities.items(), key=lambda x: x[1], reverse=True)recommended_products = [item[0] for item in sorted_similarities[:top_n]]print(f"Top { top_n} recommended products:")for i, product_path in enumerate(recommended_products): print(f"{ i+1}. { product_path} (Similarity: { similarities[product_path]:.3f})")
在这个示例中:
我们首先设置商品图片数据集的路径,并假设每个类别的商品图片存放在对应的子目录下。使用预训练的 VGG16 模型作为基础特征提取器,移除顶层全连接层以获取中间层特征。定义一个函数 extract_features,用于加载图片、预处理并使用模型提取特征向量。提前计算所有商品图片的特征向量,并存储在一个字典中,键为图片路径,值为特征向量。当用户上传图片时,同样使用 extract_features 函数提取其特征向量。计算用户上传图片与所有商品图片之间的余弦相似度,得到一个字典,其中键为商品图片路径,值为相似度分数。按相似度从高到低排序,选择前 top_n 个最相似的商品图片作为推荐结果,并打印出它们的路径及相似度分数。
注意:
path/to/your/product_dataset 和 path/to/uploaded/image.jpg 应替换为实际的数据集路径和用户上传的图片路径。本示例使用了 VGG16 预训练模型作为特征提取器,并采用余弦相似度进行相似性度量。实际应用中,可能需要选择更适合特定任务的模型(如 ResNet、EfficientNet 等),并考虑使用更先进的相似度计算方法或深度学习匹配网络。为了简化示例,这里未涉及图片预处理、数据增强、模型微调等重要步骤,这些在实际项目中通常是必不可少的。该示例仅展示了基于内容的相似商品推荐,实际应用中还可能结合用户的购买历史、浏览行为、协同过滤等信息进行更精准的个性化推荐。


(2)个性化推荐示例代码
实现结合用户购买历史、浏览行为、协同过滤等信息的个性化推荐系统通常涉及到用户画像构建、用户-商品交互矩阵、协同过滤算法等技术。以下是一个基于 Python 和相关库(如 pandas、scikit-surprise、lightfm)的简要示例代码,展示如何结合这些信息进行个性化推荐。由于实际应用中可能需要处理大规模数据、考虑冷启动问题、优化推荐算法等复杂情况,此处仅提供一个概念性的示例以说明基本流程。
import pandas as pdfrom surprise import Dataset, Reader, SVD, KNNBasicfrom lightfm.datasets import fetch_movielensfrom lightfm import LightFM# 1. 假设已有用户购买历史、浏览行为数据(存储在 CSV 文件中)purchase_history_df = pd.read_csv('path/to/purchase_history.csv')browse_history_df = pd.read_csv('path/to/browse_history.csv')# 2. 合并购买历史与浏览行为数据,形成用户-商品交互矩阵(二值化表示用户是否与商品有过交互)interaction_matrix = pd.concat([purchase_history_df, browse_history_df]).pivot_table(index='user_id', columns='product_id', aggfunc='any').fillna(0).astype(int)# 3. 使用协同过滤算法(如 SVD、KNN)进行推荐reader = Reader(rating_scale=(0, 1))data = Dataset.load_from_df(interaction_matrix, reader)svd = SVD()svd.fit(data.build_full_trainset())predictions = svd.test(data.build_full_trainset())top_n_svd = predictions.sort_by('est', ascending=False).head(n=10)# 或者使用 LightFM 混合模型(考虑用户-商品交互和商品内容特征)movielens_data = fetch_movielens(min_rating=4.0) # 使用 MovieLens 数据集作为示例,实际应用中替换为自己的数据train_interactions, test_interactions = movielens_data.split_by_time()model = LightFM(no_components=30, loss='warp')model.fit(train_interactions, epochs=30, num_threads=2)# 4. 获取用户对商品的预测评分,并进行排序,选择 top N 作为推荐结果user_id = 1 # 替换为实际用户 IDuser_predictions = model.predict(user_id, np.arange(interaction_matrix.shape[1]), num_threads=2)top_n_lightfm = np.argsort(-user_predictions)[:10]print("Top 10 recommendations based on SVD:")for i, (_, rating) in enumerate(top_n_svd): print(f"{ i+1}. Product { rating.iid} (Score: { rating.est:.3f})")print("\nTop 10 recommendations based on LightFM:")for i, product_id in enumerate(top_n_lightfm): print(f"{ i+1}. Product { product_id} (Score: { user_predictions[product_id]:.3f})")
在这个示例中:
我们首先读取用户购买历史和浏览行为数据,假设它们存储在 CSV 文件中,格式为:user_id, product_id。将购买历史和浏览行为数据合并,并构建用户-商品交互矩阵,二值化表示用户是否与商品有过交互。使用协同过滤算法(如 SVD、KNN)进行推荐。此处以 SVD 和 LightFM 为例,实际应用中可根据数据特性和需求选择合适的算法。获取用户对商品的预测评分,并进行排序,选择 top N 作为推荐结果。分别展示了基于 SVD 和 LightFM 的推荐结果。
注意:
path/to/purchase_history.csv 和 path/to/browse_history.csv 应替换为实际的购买历史和浏览行为数据文件路径。本示例使用了 SVD 和 LightFM 两种协同过滤算法进行推荐。SVD 是基于矩阵分解的模型,LightFM 则是一种混合模型,同时考虑了用户-商品交互和商品内容特征。实际应用中,可能需要选择更适合特定任务的算法(如 ALS、BPR 等),并考虑调整模型参数以优化推荐效果。为了简化示例,这里未涉及用户画像构建、商品内容特征提取、冷启动问题处理等重要步骤,这些在实际项目中通常是必不可少的。本示例使用了 MovieLens 数据集作为 LightFM 示例数据,实际应用中需要替换为自己的用户-商品交互数据,并根据数据特性调整 LightFM 参数。

(二)视觉搜索示例代码
(1)ResNet模型示例代码
实现视觉搜索功能通常需要借助深度学习中的图像特征提取模型(如 ResNet、VGG、Inception 等)以及相似度计算方法(如余弦相似度、欧氏距离等)。以下是一个基于 Python 和相关库(如 tensorflow、torch、torchvision、pandas、numpy)的简要示例代码,展示如何使用深度学习模型进行视觉搜索。这里以 PyTorch 和 ResNet50 作为示例,实际应用中可能需要调整模型、数据处理等环节以适应具体需求。
import torchimport torchvisionimport torchvision.transforms as transformsfrom PIL import Imageimport numpy as npimport pandas as pd# 1. 加载预训练的 ResNet50 模型,去掉最后一层全连接层,只保留特征提取部分model = torchvision.models.resnet50(pretrained=True)model.fc = torch.nn.Identity() # Replace the last layer with an identity function to extract features# 2. 设置模型为评估模式model.eval()# 3. 定义图像预处理函数,与模型训练时使用的预处理保持一致transform = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 4. 假设已有一个包含商品图片路径和商品ID的 DataFrameimage_df = pd.read_csv('path/to/image_db.csv') # Replace with your actual image database# 5. 提前计算所有商品图片的特征向量并存储features_db = { }for _, row in image_df.iterrows(): img_path = row['image_path'] img = Image.open(img_path) img_tensor = transform(img) img_tensor.unsqueeze_(0) # Add batch dimension with torch.no_grad(): feature_vector = model(img_tensor).squeeze().numpy() features_db[row['product_id']] = feature_vector# 6. 用户上传图片并提取特征向量uploaded_img_path = 'path/to/uploaded_image.jpg' # Replace with the uploaded image pathuploaded_img = Image.open(uploaded_img_path)uploaded_img_tensor = transform(uploaded_img)uploaded_img_tensor.unsqueeze_(0)with torch.no_grad(): uploaded_feature_vector = model(uploaded_img_tensor).squeeze().numpy()# 7. 计算上传图片与数据库中商品图片的相似度,并按相似度排序similarities = { pid: np.dot(feature, uploaded_feature_vector) / (np.linalg.norm(feature) * np.linalg.norm(uploaded_feature_vector)) for pid, feature in features_db.items()}sorted_similarities = sorted(similarities.items(), key=lambda x: x[1], reverse=True)# 8. 输出最相似的商品 IDtop_n = 5 # Number of similar products to displayprint("Top {} visually similar products:".format(top_n))for i, (product_id, similarity_score) in enumerate(sorted_similarities[:top_n]): print(f"{ i+1}. Product { product_id} (Similarity Score: { similarity_score:.3f})")
在这个示例中:
我们加载预训练的 ResNet50 模型,并去掉最后一层全连接层,只保留特征提取部分。设置模型为评估模式。定义图像预处理函数,与模型训练时使用的预处理保持一致。假设有一个包含商品图片路径和商品ID的 DataFrame,我们遍历该 DataFrame,提前计算所有商品图片的特征向量并存储在字典中。用户上传图片并提取特征向量。计算上传图片与数据库中商品图片的相似度,这里使用了余弦相似度,并按相似度排序。输出最相似的商品 ID。
注意:
path/to/image_db.csv 应替换为实际的商品图片数据库文件路径,其中应包含 image_path(图片路径)和 product_id(商品ID)两列。path/to/uploaded_image.jpg 应替换为用户上传的图片文件路径。本示例使用了 ResNet50 作为特征提取模型,实际应用中可根据需求选择其他预训练模型(如 VGG、Inception 等)。图像预处理和特征提取部分可以根据实际需求进行调整,例如改变图像尺寸、使用不同的预训练模型对应的预处理方式等。相似度计算部分也可以选择其他方法,如欧氏距离、马氏距离等,根据实际场景选择最适合的相似度度量方法。
(2)VGG模型示例代码
以下是一个使用 PyTorch 实现 VGG16 模型的示例代码,包括模型定义、加载预训练权重、对单张图片进行前向传播以获取其特征向量,以及使用该模型进行图像分类的基本流程:
import torchimport torch.nn as nnimport torchvision.models as modelsfrom PIL import Imageimport torchvision.transforms as transforms# 1. 定义 VGG16 模型class VGG16(nn.Module): def __init__(self, pretrained=True): super(VGG16, self).__init__() self.model = models.vgg16(pretrained=pretrained) self.model.classifier[-1] = nn.Linear(in_features=4096, out_features=1000) # Replace the last layer to match the desired number of classes def forward(self, x): return self.model(x)# 2. 加载预训练权重(若指定)model = VGG16(pretrained=True)# 3. 定义图像预处理函数transform = transforms.Compose([ transforms.Resize(224), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 4. 对单张图片进行前向传播以获取其特征向量image_path = 'path/to/image.jpg' # 替换为实际图片路径image = Image.open(image_path)input_tensor = transform(image)input_tensor.unsqueeze_(0) # Add batch dimensionwith torch.no_grad(): features = model.model.features(input_tensor)# 5. 使用模型进行图像分类class_names = ['Class_0', 'Class_1', ..., 'Class_999'] # Replace with actual class namesoutput = model(input_tensor)_, predicted_class = torch.max(output.data, 1)print(f"Predicted class: { class_names[predicted_class]}")# 6. (可选)保存模型torch.save(model.state_dict(), 'vgg16.pth')# 7. (可选)加载已保存的模型loaded_model = VGG16()loaded_model.load_state_dict(torch.load('vgg16.pth'))loaded_model.eval()
在这个示例中:
我们定义了一个 VGG16 类,继承自 nn.Module,并在 __init__ 方法中加载预训练的 VGG16 模型。这里将模型的最后一层替换为具有 1000 个输出节点的线性层,以适应具有 1000 个类别的分类任务。您可以根据实际任务调整输出节点数量。创建一个 VGG16 实例,并加载预训练权重。定义图像预处理函数,与模型训练时使用的预处理保持一致。对单张图片进行预处理,并通过模型进行前向传播,获取其特征向量。使用模型进行图像分类,输出预测的类别名称。(可选)保存模型状态字典到磁盘。(可选)加载已保存的模型状态字典,并将模型设置为评估模式。
注意:
path/to/image.jpg 应替换为实际图片文件路径。class_names 列表应包含实际的类别名称,与模型输出节点一一对应。图像预处理和特征提取部分可以根据实际需求进行调整,例如改变图像尺寸、使用不同的预训练模型对应的预处理方式等。分类任务中,实际应用可能需要对输出概率进行后处理,如设置阈值、使用 softmax 等,这里仅展示了获取最大概率对应的类别。
(3)Inception示例代码
以下是一个使用 PyTorch 实现 Inception v3 模型的示例代码,包括模型定义、加载预训练权重、对单张图片进行前向传播以获取其特征向量,以及使用该模型进行图像分类的基本流程:
import torchimport torch.nn as nnimport torchvision.models as modelsfrom PIL import Imageimport torchvision.transforms as transforms# 1. 定义 Inception v3 模型class InceptionV3(nn.Module): def __init__(self, num_classes=1000, pretrained=True): super(InceptionV3, self).__init__() self.model = models.inception_v3(pretrained=pretrained) self.model.AuxLogits.fc = nn.Linear(in_features=768, out_features=num_classes) # Replace the auxiliary classifier's output layer self.model.fc = nn.Linear(in_features=2048, out_features=num_classes) # Replace the main classifier's output layer def forward(self, x): return self.model(x)# 2. 加载预训练权重(若指定)model = InceptionV3(pretrained=True)# 3. 定义图像预处理函数transform = transforms.Compose([ transforms.Resize(299), transforms.CenterCrop(299), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 4. 对单张图片进行前向传播以获取其特征向量image_path = 'path/to/image.jpg' # 替换为实际图片路径image = Image.open(image_path)input_tensor = transform(image)input_tensor.unsqueeze_(0) # Add batch dimensionwith torch.no_grad(): features = model.model.Conv2d_7b_1x1(input_tensor)# 5. 使用模型进行图像分类class_names = ['Class_0', 'Class_1', ..., 'Class_999'] # Replace with actual class namesoutput = model(input_tensor)_, predicted_class = torch.max(output.data, 1)print(f"Predicted class: { class_names[predicted_class]}")# 6. (可选)保存模型torch.save(model.state_dict(), 'inception_v3.pth')# 7. (可选)加载已保存的模型loaded_model = InceptionV3()loaded_model.load_state_dict(torch.load('inception_v3.pth'))loaded_model.eval()
在这个示例中:
我们定义了一个 InceptionV3 类,继承自 nn.Module,并在 __init__ 方法中加载预训练的 Inception v3 模型。这里将模型的辅助分类器(AuxLogits)和主分类器(fc)的最后一层替换为具有 num_classes 个输出节点的线性层,以适应具有 num_classes 个类别的分类任务。您可以根据实际任务调整输出节点数量。创建一个 InceptionV3 实例,并加载预训练权重。定义图像预处理函数,与模型训练时使用的预处理保持一致。对单张图片进行预处理,并通过模型进行前向传播,获取其特征向量。使用模型进行图像分类,输出预测的类别名称。(可选)保存模型状态字典到磁盘。(可选)加载已保存的模型状态字典,并将模型设置为评估模式。
注意:
path/to/image.jpg 应替换为实际图片文件路径。class_names 列表应包含实际的类别名称,与模型输出节点一一对应。图像预处理和特征提取部分可以根据实际需求进行调整,例如改变图像尺寸、使用不同的预训练模型对应的预处理方式等。分类任务中,实际应用可能需要对输出概率进行后处理,如设置阈值、使用 softmax 等,这里仅展示了获取最大概率对应的类别。
八、艺术与设计示例代码

(一)图像合成与编辑示例代码
以下是一些使用 Python 实现图像合成与编辑功能的示例代码,包括图像拼接、滤镜应用(使用 OpenCV)和风格迁移(使用 PyTorch 和 neural-style-pt 库):
图像拼接
import cv2import numpy as np# 读取待拼接的两张图片img1 = cv2.imread('image1.jpg')img2 = cv2.imread('image2.jpg')# 获取图片高度和宽度h1, w1 = img1.shape[:2]h2, w2 = img2.shape[:2]# 创建一个足够大的空白图像用于拼接merged_img = np.zeros((max(h1, h2), w1 + w2, 3), dtype=np.uint8)# 将图片1粘贴到空白图像左侧merged_img[:h1, :w1, :] = img1# 将图片2粘贴到空白图像右侧merged_img[:h2, w1:, :] = img2# 保存拼接后的图片cv2.imwrite('merged_image.jpg', merged_img)
滤镜应用
import cv2# 读取待处理的图片img = cv2.imread('image.jpg')# 应用色彩平衡滤镜blue_balance = 1.1green_balance = 0.9red_balance = 1.2img = cv2.cvtColor(img, cv2.COLOR_BGR2LAB)img[:, :, 0] = img[:, :, 0] * blue_balanceimg[:, :, 1] = img[:, :, 1] * green_balanceimg[:, :, 2] = img[:, :, 2] * red_balanceimg = cv2.cvtColor(img, cv2.COLOR_LAB2BGR)# 应用模糊滤镜kernel_size = (5, 5)img = cv2.GaussianBlur(img, kernel_size, 0)# 保存处理后的图片cv2.imwrite('filtered_image.jpg', img)
风格迁移
首先安装所需库:
pip install torch torchvision neural-style-pt
然后运行以下代码:
import torchfrom neural_style_pt import NeuralStyle# 初始化模型,加载预训练权重model = NeuralStyle()model.load_weights('models/vgg19-d01eb7cb.pth')# 读取内容图像和风格图像content_img = cv2.imread('content_image.jpg')style_img = cv2.imread('style_image.jpg')# 将图像转换为 PyTorch 张量,并进行预处理content_img = model.preprocess(content_img)style_img = model.preprocess(style_img)# 进行风格迁移output_img = model.transfer(content_img, style_img, steps=100)# 将输出图像转换回 OpenCV 格式并保存output_img = model.postprocess(output_img)cv2.imwrite('stylized_image.jpg', output_img)
在这个示例中:
使用 neural_style_pt 库实现风格迁移,首先初始化模型并加载预训练权重。读取内容图像和风格图像,将其转换为 PyTorch 张量,并进行预处理。调用 transfer 方法进行风格迁移,指定迭代次数。将输出图像转换回 OpenCV 格式并保存。
注意:
content_image.jpg 和 style_image.jpg 应替换为实际的内容图像和风格图像文件路径。models/vgg19-d01eb7cb.pth 是预训练权重文件路径,可能需要根据实际安装的 neural_style_pt 版本或自定义模型进行调整。风格迁移过程可能需要较长时间,具体取决于图像大小、迭代次数等因素。可以通过调整 steps 参数控制迭代次数,以平衡生成效果和计算时间。


(二)AI 创作示例代码
Stable Diffusion 是一款基于深度学习的文本到图像生成模型,它利用扩散模型技术来根据用户提供的文本描述创建高质量的艺术作品和设计素材。要使用 Python 驱动 Stable Diffusion 模型进行创作,通常需要通过其官方 API 或第三方库(如 diffusers)来交互。以下是一个使用 diffusers 库与 Stable Diffusion 后端 API 进行创作的示例代码:
首先确保已安装 diffusers 库及其依赖:
pip install diffusers transformers
然后编写 Python 代码以利用 Stable Diffusion 进行图像生成:
import torchfrom PIL import Imagefrom diffusers import StableDiffusionPipeline# 定义 Stable Diffusion 模型的配置参数api_key = "your_api_key" # 替换为你的 API 密钥endpoint_url = "https://api.stability.ai/prompt" # 或使用其他可用的 Stable Diffusion API 端点# 初始化 Stable Diffusion 管道pipe = StableDiffusionPipeline.from_pretrained( "runwayml/stable-diffusion-v1-5", revision="fp16", use_auth_token=api_key, endpoint_url=endpoint_url,)# 定义要生成的图像描述prompt = "A beautiful sunset over a futuristic city, painted in the style of Vincent van Gogh"# 设置其他生成参数(可选)num_images = 1height = 512width = 512seed = 42# 生成图像images = pipe(prompt=prompt, num_inference_steps=50, guidance_scale=7.5, height=height, width=width, seed=seed)# 保存第一张生成的图像image = images[0].make_grid(num_rows=1, padding=10).to("cpu")image = Image.fromarray(image.numpy().transpose(1, 2, 0))image.save("generated_artwork.png")
在这个示例中:
首先安装所需的 diffusers 和 transformers 库。使用 StableDiffusionPipeline 类从预训练模型 runwayml/stable-diffusion-v1-5 初始化管道,指定 API 密钥、端点 URL、模型修订版和是否使用半精度浮点数(fp16)。定义要生成的图像描述,例如 "A beautiful sunset over a futuristic city, painted in the style of Vincent van Gogh"。设置生成参数,如生成图像数量、图像尺寸、随机种子等。这里选择了生成一张尺寸为 512x512 的图像,使用 50 步推理和较高的指导尺度(guidance_scale=7.5)以增强对提示的响应。调用 pipe 对象的 __call__ 方法,传入文本提示和生成参数,得到生成的图像列表。从生成的图像列表中选择第一张图像,将其转换为 PIL 图像格式,并保存为 generated_artwork.png 文件。
请注意,使用 Stable Diffusion API 可能需要注册并获取 API 密钥。请替换示例代码中的 your_api_key 为实际的 API 密钥。此外,endpoint_url 应指向可用的 Stable Diffusion API 端点。如果使用的是本地部署的 Stable Diffusion 模型,可以相应地修改 endpoint_url 为本地服务器地址。
由于 Stable Diffusion 模型的计算复杂度较高,实际运行上述代码时可能会需要一定的时间,具体取决于硬件性能、网络状况以及模型设置。
九、媒体与娱乐示例代码
(一)内容审核示例代码
实现内容审核功能,特别是针对社交媒体和直播平台上的违规图像内容,通常需要借助专门的图像识别服务或API。这些服务通常由云服务商(如AWS、Google Cloud、Azure等)或者专业的内容审核解决方案提供商提供。下面以使用 AWS Rekognition 为例,展示如何编写 Python 代码来检测图像中的潜在违规内容:
首先确保已安装 boto3 库,这是 AWS SDK for Python,用于与 AWS 服务交互:
pip install boto3
然后编写 Python 代码以使用 AWS Rekognition 进行图像内容审核:
import boto3import iofrom PIL import Image# 初始化 Rekognition 客户端rekognition_client = boto3.client('rekognition')# 定义要检测的本地图像路径image_path = 'path/to/your/image.jpg'# 加载图像并转换为 BytesIO 对象with Image.open(image_path) as img: img_byte_arr = io.BytesIO() img.save(img_byte_arr, format='JPEG') img_byte_arr = img_byte_arr.getvalue()# 定义 Rekognition 内容审核请求参数content_moderation_params = { 'Image': { 'Bytes': img_byte_arr }, 'MinConfidence': 75, # 可调整的阈值,表示检测结果的最低可信度}# 调用 Rekognition 的 DetectModerationLabels API 进行内容审核response = rekognition_client.detect_moderation_labels(**content_moderation_params)# 解析审核结果violations = []for moderation_label in response['ModerationLabels']: label_name = moderation_label['Name'] confidence = moderation_label['Confidence'] violations.append((label_name, confidence))print("Detected potential violations:")for violation in violations: print(f"{ violation[0]} (Confidence: { violation[1]}%)")# 根据需要,根据检测结果做出决策(例如:标记违规、拒绝发布等)
在这个示例中:
安装 boto3 库并初始化 AWS Rekognition 客户端。定义要检测的本地图像路径,加载该图像,并将其转换为 BytesIO 对象以便作为 Rekognition API 的输入。设置 Rekognition 内容审核请求参数,包括图像数据和最低可信度阈值(如 75%)。这个阈值可以根据实际需求进行调整,以控制误报率和漏报率。调用 detect_moderation_labels API 方法,传入准备好的参数,获取内容审核结果。解析审核结果,提取出违规标签(如“Adult”、“Violence”等)及其对应的可信度,并打印出来。根据检测到的违规情况,可以进一步编写逻辑来执行相应的操作,如标记违规图像、拒绝发布等。
请确保在运行此代码前已经正确设置了 AWS 凭证,使其能够访问 Rekognition 服务。此外,实际应用中可能还需要考虑错误处理、批量处理图像、集成到特定社交媒体或直播平台的工作流中等更复杂的场景。
注意:使用 AWS Rekognition 等付费服务会产生费用。请查阅相关服务定价以了解详情,并合理管理使用。如果您不打算使用 AWS,请选择适合您需求的其他内容审核服务,并参照其官方文档编写相应的接口调用代码。
(二)视频分析中的图像处理示例代码
(1)视频基本分析中的图像处理示例代码
视频分析涉及多个复杂的计算机视觉任务,如动作识别、人脸识别、内容摘要生成等。由于这些任务通常需要深度学习模型的支持,并且处理流程较为复杂,直接提供完整的示例代码会过于冗长。下面以 Python 为基础,简述各任务的基本思路,并给出部分关键代码片段,供您参考:

动作识别
动作识别通常使用预训练的深度学习模型(如 3D CNN 或 LSTM 结合 CNN)来处理视频帧序列。这里以使用 OpenCV 读取视频、TensorFlow/Keras 引入预训练模型为例:
import cv2import numpy as npimport tensorflow as tf# 加载预训练动作识别模型model = tf.keras.models.load_model('path/to/action_recognition_model.h5')# 定义视频文件路径video_path = 'path/to/video.mp4'# 使用 OpenCV 打开视频cap = cv2.VideoCapture(video_path)while cap.isOpened(): ret, frame = cap.read() if not ret: break # 对单个帧进行预处理(缩放、归一化等) preprocessed_frame = preprocess(frame) # 将帧堆叠成合适的输入形状(例如,时间维度上的帧数) input_data = stack_frames(preprocessed_frame) # 使用模型预测动作类别 prediction = model.predict(input_data) action_class = decode_prediction(prediction) # 在帧上标注动作或记录结果 # ...cv2.destroyAllWindows()cap.release()

人脸识别
人脸识别一般涉及人脸检测(找出图像中的人脸位置)、特征提取(对检测到的人脸生成特征向量)和比对(比较特征向量以确定是否为同一个人)。这里以使用 Dlib 和 FaceNet 模型为例:
import cv2import dlibimport numpy as npfrom facenet_pytorch import MTCNN, InceptionResnetV1# 初始化人脸检测器detector = dlib.get_frontal_face_detector()# 加载预训练 FaceNet 模型用于特征提取facenet = InceptionResnetV1(pretrained='vggface2').eval()# 定义视频文件路径video_path = 'path/to/video.mp4'# 使用 OpenCV 打开视频cap = cv2.VideoCapture(video_path)while cap.isOpened(): ret, frame = cap.read() if not ret: break # 使用 Dlib 进行人脸检测 faces = detector(frame, 1) for face_rect in faces: face_roi = frame[face_rect.top():face_rect.bottom(), face_rect.left():face_rect.right()] # 对人脸区域进行预处理 preprocessed_face = preprocess(face_roi) # 使用 FaceNet 提取特征 face_embedding = facenet(preprocessed_face.unsqueeze(0)).detach().numpy() # 与数据库中的人脸特征进行比对,或存储特征以备后续比对 # ... # 显示带有人脸框或识别结果的帧 # ...cv2.destroyAllWindows()cap.release() 内容摘要生成
内容摘要生成可能涉及到关键帧选择、对象跟踪、场景变化检测等技术,结合自然语言生成模型(如 GPT-3)来生成文本描述。这里仅给出关键帧选择的简单示例:
import cv2import numpy as np# 定义视频文件路径video_path = 'path/to/video.mp4'# 定义关键帧间隔、相似性阈值等参数frame_interval = 30 # 每隔多少帧选取一个候选关键帧similarity_threshold = 0.¾ # 相邻关键帧之间的相似度阈值# 使用 OpenCV 打开视频cap = cv2.VideoCapture(video_path)keyframes = []current_frame = Nonewhile cap.isOpened(): ret, frame = cap.read() if not ret: break if current_frame is None: current_frame = frame continue # 计算相邻帧之间的相似度 similarity = calculate_similarity(current_frame, frame) if similarity < similarity_threshold: keyframes.append(current_frame) current_frame = framecv2.destroyAllWindows()cap.release()# 对选出的关键帧进行进一步处理(如特征提取、描述生成等)# ...
上述代码片段仅为示例,实际应用中需要根据具体任务需求、使用的模型类型和库进行详细的实现。同时,处理视频时要考虑性能优化,如多线程、GPU加速等。对于复杂的视频分析任务,建议使用专门的视频处理库(如 MoviePy、OpenCV VideoWriter 等)或深度学习框架(如 TensorFlow、PyTorch)提供的视频处理工具,以简化操作并提高效率。

(2)MoviePy、OpenCV VideoWriter视频分析中的图像处理示例代码
虽然 MoviePy 和 OpenCV VideoWriter 主要用于视频的编辑、合成与输出,而非专门的视频分析工具,但它们可以辅助完成一些基础的视频分析任务,如关键帧提取、视频剪辑、添加分析结果的可视化等。以下是使用这两个库进行相关操作的示例代码:
使用 MoviePy 进行视频图像处理
from moviepy.editor import VideoFileClip, concatenate_videoclips, TextClip# 定义视频文件路径video_path = 'path/to/video.mp4'# 使用 MoviePy 打开视频clip = VideoFileClip(video_path)# 示例:提取关键帧作为静止图像keyframes = clip.get_frame_list(np.arange(0, clip.duration, clip.duration / 10))for time in keyframes: image = clip.get_frame(time) # 对图像进行分析或保存...# 示例:剪辑视频片段start_time = 10 # 秒end_time = 20 # 秒clipped_clip = clip.subclip(start_time, end_time)# 示例:添加文字注释到视频text = "This is an annotated video."text_clip = TextClip(text=text, fontsize=24, color='white').set_position('center').set_duration(clip.duration)annotated_clip = clip.set_mask(text_clip.mask).set_opacity(0.7) + text_clip.set_opacity(1.0)# 输出处理后的视频annotated_clip.write_videofile("output_annotated.mp4", codec='libx264', fps=clip.fps)clip.close() 使用 OpenCV VideoWriter 进行视频图像输出
import cv2# 定义视频文件路径、帧率、编码器及输出尺寸output_video_path = 'output.avi'fps = 30fourcc = cv2.VideoWriter_fourcc(*'XVID')output_size = (clip.w, clip.h) # 假设已获取原始视频的宽度和高度# 创建 VideoWriter 对象out = cv2.VideoWriter(output_video_path, fourcc, fps, output_size)# 示例:逐帧处理视频并写入新视频cap = cv2.VideoCapture(video_path)while cap.isOpened(): ret, frame = cap.read() if not ret: break # 对 frame 进行分析或处理... analyzed_frame = analyze_frame(frame) # 写入处理后的帧到输出视频 out.write(analyzed_frame)cap.release()out.release()
请注意,上述代码并未展示具体的视频分析部分(如动作识别、人脸识别、内容摘要生成等),因为这些通常涉及更专业的计算机视觉算法和深度学习模型。MoviePy 和 OpenCV VideoWriter 主要用于视频的读取、裁剪、拼接、添加文本/图像叠加以及最终输出处理后的视频文件。实际的视频分析工作应该在获取到视频帧后,通过调用相应的分析函数或模型进行处理。您可以结合前面给出的视频分析任务示例代码,将分析结果整合到 MoviePy 或 OpenCV VideoWriter 的处理流程中。
(3)利用 TensorFlow 和 PyTorch 提供的工具和库来简化视频中的图像处理示例代码
深度学习框架如 TensorFlow 和 PyTorch 不仅提供了构建和训练神经网络模型的能力,还包含一些工具和模块来简化视频处理任务,以方便进行视频分析、理解与生成。以下是一些利用这些框架进行视频处理的工具和方法:
TensorFlow IO 是一个官方扩展库,提供了对多种数据源(包括视频)的高效读取支持。它包含了专门针对视频处理的模块,如 tensorflow_io.video,可以方便地加载、预处理视频数据,并将其转换为适合深度学习模型输入的形式。
import tensorflow as tfimport tensorflow_io as tfio# 加载视频文件video_path = 'path/to/video.mp4'video = tfio.experimental.video.decode_video(video_path, dtype=tf.uint8)# 将视频数据转换为帧序列frames = tf.squeeze(video, axis=0)# 对帧序列进行预处理,如调整大小、归一化等preprocessed_frames = preprocess_frames(frames)# 构建数据集,供模型训练或推断使用dataset = tf.data.Dataset.from_tensor_slices(preprocessed_frames)dataset = dataset.batch(batch_size).prefetch(buffer_size=tf.data.AUTOTUNE)
TensorFlow Data API 提供了高效的数据输入管道(pipeline),能够处理大规模数据集,包括视频。通过 tf.data.Dataset,您可以轻松构建复杂的预处理流水线,如随机裁剪、翻转、色彩变换等,并且可以与 tf.data.Dataset.from_generator 结合使用自定义的视频读取器。
import tensorflow as tfdef load_and_preprocess_video(path): frames = load_video_frames(path) # 自定义函数加载视频帧 preprocessed_frames = preprocess_frames(frames) # 自定义函数预处理帧 return preprocessed_framesvideo_paths = ['path/to/video1.mp4', 'path/to/video2.mp4', ...]dataset = tf.data.Dataset.from_tensor_slices(video_paths)dataset = dataset.map(load_and_preprocess_video, num_parallel_calls=tf.data.AUTOTUNE)dataset = dataset.batch(batch_size).prefetch(buffer_size=tf.data.AUTOTUNE)
torchvision 是 PyTorch 生态中的一个重要库,专注于视觉领域的数据处理、模型定义和常用转换。它提供了 torchvision.io 模块来处理视频数据,以及丰富的数据加载和预处理工具。
import torchvisionimport torchvision.transforms as transforms# 加载视频文件video_path = 'path/to/video.mp4'video = torchvision.io.read_video(video_path, pts_unit='sec')# 获取视频帧和对应的采样时间戳frames, timestamps = video['data'], video['pts']# 对帧序列进行预处理,如调整大小、归一化等preprocessed_frames = torch.stack([transforms.ToTensor()(frame) for frame in frames])# 构建数据集,供模型训练或推断使用dataset = torch.utils.data.TensorDataset(preprocessed_frames)dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
PyTorch DataLoader & Transforms
PyTorch 的 DataLoader 与 transforms 模块共同构成了强大的数据处理流水线。可以使用 torch.utils.data.Dataset 子类实现自定义视频数据集,并结合 torchvision.transforms 中的预处理方法或自定义函数对视频帧进行处理。
import torchfrom torch.utils.data import Dataset, DataLoaderfrom torchvision import transformsclass VideoDataset(Dataset): def __init__(self, video_paths, transform=None): self.video_paths = video_paths self.transform = transform def __len__(self): return len(self.video_paths) def __getitem__(self, idx): path = self.video_paths[idx] frames = load_video_frames(path) # 自定义函数加载视频帧 preprocessed_frames = self.transform(frames) if self.transform else frames return preprocessed_framesvideo_paths = ['path/to/video1.mp4', 'path/to/video2.mp4', ...]transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])dataset = VideoDataset(video_paths, transform=transform)dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
以上示例展示了如何利用 TensorFlow 和 PyTorch 提供的工具和库来简化视频图像处理,包括加载、预处理视频数据,并构建高效的数据集供深度学习模型使用。这些工具有助于提高视频分析任务的开发效率,并确保数据处理过程与模型训练无缝衔接。
十、知识点归纳

Python 自动化处理图像在各行各业有着广泛的应用,其强大而灵活的图像处理库(如 OpenCV、PIL、scikit-image、matplotlib 等)以及深度学习框架(如 TensorFlow、PyTorch)使得图像分析、识别、合成等任务变得高效且易于实现。以下是对各行业应用场景的知识点归纳:
1. 医疗影像诊断
图像预处理:去除噪声、校正偏色、增强对比度、平滑滤波、边缘锐化等,提高医疗影像的清晰度和诊断价值。分割与标注:自动分割病灶区域(如肿瘤、骨折、血管等),或者标注关键解剖结构,辅助医生精准定位和定量分析。特征提取:利用深度学习模型提取图像特征,用于疾病分类、病变分级、病程监测等任务。辅助诊断:构建AI诊断系统,如肺结节检测、眼底病变识别、皮肤癌筛查等,提供初步诊断意见或风险评估。三维重建与可视化:处理CT、MRI等多切片数据,实现三维重建,便于医生从不同角度观察和分析复杂结构。
2. 安防监控
实时视频流分析:使用OpenCV等库实时处理摄像头捕捉的视频流,进行运动检测、目标跟踪、人数统计等。人脸识别:集成人脸识别算法(如Dlib、face_recognition库)实现人员身份验证、黑名单比对、陌生人预警等功能。异常行为检测:通过机器学习或深度学习模型识别异常行为模式,如打架斗殴、物品遗留、入侵禁区等。车牌识别:自动识别车辆车牌号码,用于交通监控、违章管理、停车场出入控制等场景。
3. 工业自动化与质量控制
缺陷检测:对产品表面或内部结构图像进行分析,自动识别划痕、凹陷、裂纹、异物等缺陷,提升生产线上质检的准确性和效率。尺寸测量:通过图像分析精确测量零部件的几何尺寸、角度、间距等,确保制造精度符合规格要求。视觉引导机器人:利用图像处理技术为机器人提供实时的视觉反馈,指导其进行精准定位、抓取、装配等操作。
4. 农业与生态环境监测
作物病虫害识别:通过无人机拍摄或地面设备采集的农田图像,识别病虫害症状,辅助精准施药和农事决策。植被指数计算:处理卫星遥感图像,计算NDVI(归一化差异植被指数)等指标,监测作物生长状态、估产、土壤水分等。动物种群监测:自动识别和计数野生动物或家畜,支持生物多样性保护、牧场管理等工作。
5. 电子商务与零售
商品图像分析:识别商品主图中的颜色、纹理、形状等特征,用于智能分类、相似商品推荐、视觉搜索。虚拟试衣/妆容:利用图像合成技术,让用户在线试穿衣物或尝试不同妆容效果,提升购物体验。用户生成内容分析:分析用户上传的产品评价图片,自动提取关键词、情感倾向,辅助商家了解消费者反馈。
6. 新闻媒体与社交媒体
图像内容审核:自动检测图片中的违规内容(如暴力、色情、敏感信息),保障平台内容合规。图像新闻生成:快速处理突发事件图像,自动摘要关键信息,生成图文新闻报道。视觉情感分析:分析社交媒体上的图片情绪,如喜悦、悲伤、愤怒等,为舆情监测提供依据。
7. 文物保护与艺术研究
文物数字化:高精度扫描文物,进行图像修复、色彩还原,为文物保护和研究提供高质量数字资源。艺术品鉴别:利用图像特征分析技术,鉴别艺术品真伪,辅助艺术品交易市场规范。风格迁移与合成:将经典艺术作品的风格应用于现代图像,或合成全新艺术图像,用于教育、娱乐或创意产业。
8. 无人驾驶与智能交通
环境感知:通过摄像头捕捉路面图像,识别车道线、交通标志、行人、障碍物等,为自动驾驶系统提供环境信息。车辆定位:结合地图数据和视觉里程计,通过图像处理实现车辆在道路上的精确定位。

综上所述,Python 在图像处理方面的应用涵盖了医疗、安防、工业、农业、电商、新闻媒体、文化艺术、交通运输等多个领域,通过自动化处理技术极大地提升了工作效率、精确度和智能化水平。随着技术的不断发展,其应用范围还将进一步拓展。
上一篇: 【码银送书第十五期】一本书掌握数字化运维方法,构建数字化运维体系
下一篇: linux搭建hadoop集群
本文标签
第十五篇【传奇开心果系列】Python自动化办公库技术点案例示例:深度解读Python 自动化处理图像在各行各业的应用场景
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。