CNN经典网络模型(五):ResNet简介及代码实现(PyTorch超详细注释版)
华科附小第一名 2024-06-13 08:07:24 阅读 54
目录
一、开发背景
二、网络结构
三、模型特点
四、代码实现
1. model.py
2. train.py
3. predict.py
4. spilit_data.py
五、参考内容
一、开发背景
残差神经网络(ResNet)是由微软研究院的何恺明、张祥雨、任少卿、孙剑等人提出的, 斩获2015年ImageNet竞赛中分类任务第一名, 目标检测第一名。 残差神经网络的主要贡献是发现了“退化现象(Degradation)”,并针对退化现象发明了 “直连边/短连接(Shortcut connection)”,极大的消除了深度过大的神经网络训练困难问题。神经网络的“深度”首次突破了100层、最大的神经网络甚至超过了1000层。
二、网络结构
ResNet的前两层为输出通道数为64、步幅为2的7×7卷积层,后接步幅为2的3×3的最大池化层。 不同于GoogLeNet,ResNet在每个卷积层后增加了批量规一化层。接着, ResNet使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。 第一个模块的通道数同输入通道数一致。 由于之前已经使用了步幅为2的最大池化层,所以无须减小高和宽。 之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。最后,输入全局平均汇聚层,以及全连接层输出。通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。34层ResNet如下图所示:
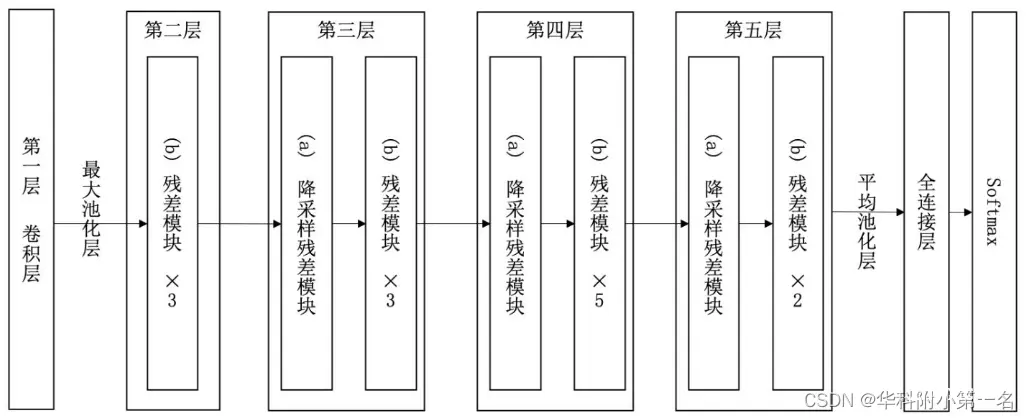
残差单元(残差块)
ResNet团队分别构建了带有“直连边(Shortcut Connection)”的ResNet残差块、以及降采样的ResNet残差块,区别是降采样残差块的直连边增加了一个1×1的卷积操作。对于直连边,当输入和输出维度一致时,可以直接将输入加到输出上,这相当于简单执行了同等映射,不会产生额外的参数,也不会增加计算复杂度。但是当维度不一致时,这就不能直接相加,通过添加1×1卷积调整通道数。这种残差学习结构可以通过前向神经网络+直连边实现, 而且整个网络依旧可以通过端到端的反向传播训练。结构如下图所示:
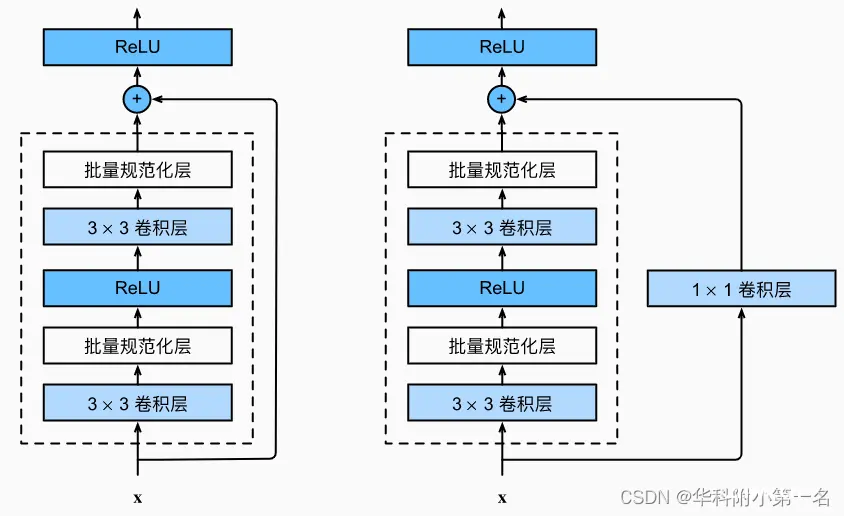
三、模型特点
1.超深的网络结构(突破1000层)
网络深度为什么重要?因为CNN能够提取low/mid/high-level的特征,网络的层数越多,意味着能够提取到不同level的特征越丰富。并且,越深的网络提取的特征越抽象,越具有语义信息。
2.使用Batch Normalization
为什么不能简单地增加网络层数?对于原来的网络,如果简单地增加深度,会导致梯度弥散或梯度爆炸。Batch Normalization可以解决该问题的,因此可以训练到几十层的网络。
3.残差块
随着网络层数增加,出现了新的问题:退化问题,在训练集上准确率饱和甚至下降了。这个不能解释为过拟合,因为过拟合表现为在训练集上表现更好才对。退化问题说明了深度网络不能很简单地被很好地优化。作者通过实验说明:通过浅层网络y=x 等同映射构造深层模型,结果深层模型并没有比浅层网络有更低甚至等同的错误率,推断退化问题可能是因为深层的网络很那难通过训练利用多层网络拟合同等函数。
怎么解决退化问题?深度残差网络。如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。所以要解决的就是学习恒等映射函数。但是直接让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x) = F(x) + x。我们可以转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x. 此外,拟合残差会更加容易。
总的来说,一是其导数总比原导数加1,这样即使原导数很小时,也能传递下去,能解决梯度消失的问题; 二是y=f(x)+x式子中引入了恒等映射(当f(x)=0时,y=2),解决了深度增加时神经网络的退化问题。
4.结构简单
虽然ResNet的主体结构跟GoogLeNet类似,但ResNet结构更简单,修改也更方便,因此ResNet迅速被广泛使用。
四、代码实现
model.py :定义ResNet网络模型train.py:加载数据集并训练,计算loss和accuracy,保存训练好的网络参数predict.py:用自己的数据集进行分类测试spilit_data.py:划分给定的数据集为训练集和测试集1. model.py
import torch.nn as nnimport torch# 定义ResNet18/34的残差结构,为2个3x3的卷积class BasicBlock(nn.Module): # 判断残差结构中,主分支的卷积核个数是否发生变化,不变则为1 expansion = 1 # init():进行初始化,申明模型中各层的定义 # downsample=None对应实线残差结构,否则为虚线残差结构 def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs): super(BasicBlock, self).__init__() self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=3, stride=stride, padding=1, bias=False) # 使用批量归一化 self.bn1 = nn.BatchNorm2d(out_channel) # 使用ReLU作为激活函数 self.relu = nn.ReLU() self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(out_channel) self.downsample = downsample # forward():定义前向传播过程,描述了各层之间的连接关系 def forward(self, x): # 残差块保留原始输入 identity = x # 如果是虚线残差结构,则进行下采样 if self.downsample is not None: identity = self.downsample(x) out = self.conv1(x) out = self.bn1(out) out = self.relu(out) # ----------------------------------------- out = self.conv2(out) out = self.bn2(out) # 主分支与shortcut分支数据相加 out += identity out = self.relu(out) return out# 定义ResNet50/101/152的残差结构,为1x1+3x3+1x1的卷积class Bottleneck(nn.Module): # expansion是指在每个小残差块内,减小尺度增加维度的倍数,如64*4=256 # Bottleneck层输出通道是输入的4倍 expansion = 4 # init():进行初始化,申明模型中各层的定义 # downsample=None对应实线残差结构,否则为虚线残差结构,专门用来改变x的通道数 def __init__(self, in_channel, out_channel, stride=1, downsample=None, groups=1, width_per_group=64): super(Bottleneck, self).__init__() width = int(out_channel * (width_per_group / 64.)) * groups self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width, kernel_size=1, stride=1, bias=False) # 使用批量归一化 self.bn1 = nn.BatchNorm2d(width) # ----------------------------------------- self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups, kernel_size=3, stride=stride, bias=False, padding=1) self.bn2 = nn.BatchNorm2d(width) # ----------------------------------------- self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel * self.expansion, kernel_size=1, stride=1, bias=False) self.bn3 = nn.BatchNorm2d(out_channel * self.expansion) # 使用ReLU作为激活函数 self.relu = nn.ReLU(inplace=True) self.downsample = downsample # forward():定义前向传播过程,描述了各层之间的连接关系 def forward(self, x): # 残差块保留原始输入 identity = x # 如果是虚线残差结构,则进行下采样 if self.downsample is not None: identity = self.downsample(x) out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) # 主分支与shortcut分支数据相加 out += identity out = self.relu(out) return out# 定义ResNet类class ResNet(nn.Module): # 初始化函数 def __init__(self, block, blocks_num, num_classes=1000, include_top=True, groups=1, width_per_group=64): super(ResNet, self).__init__() self.include_top = include_top # maxpool的输出通道数为64,残差结构输入通道数为64 self.in_channel = 64 self.groups = groups self.width_per_group = width_per_group self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(self.in_channel) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 浅层的stride=1,深层的stride=2 # block:定义的两种残差模块 # block_num:模块中残差块的个数 self.layer1 = self._make_layer(block, 64, blocks_num[0]) self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2) self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2) self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2) if self.include_top: # 自适应平均池化,指定输出(H,W),通道数不变 self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 全连接层 self.fc = nn.Linear(512 * block.expansion, num_classes) # 遍历网络中的每一层 # 继承nn.Module类中的一个方法:self.modules(), 他会返回该网络中的所有modules for m in self.modules(): # isinstance(object, type):如果指定对象是指定类型,则isinstance()函数返回True # 如果是卷积层 if isinstance(m, nn.Conv2d): # kaiming正态分布初始化,使得Conv2d卷积层反向传播的输出的方差都为1 # fan_in:权重是通过线性层(卷积或全连接)隐性确定 # fan_out:通过创建随机矩阵显式创建权重 nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') # 定义残差模块,由若干个残差块组成 # block:定义的两种残差模块,channel:该模块中所有卷积层的基准通道数。block_num:模块中残差块的个数 def _make_layer(self, block, channel, block_num, stride=1): downsample = None # 如果满足条件,则是虚线残差结构 if stride != 1 or self.in_channel != channel * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(channel * block.expansion)) layers = [] layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride, groups=self.groups, width_per_group=self.width_per_group)) self.in_channel = channel * block.expansion for _ in range(1, block_num): layers.append(block(self.in_channel, channel, groups=self.groups, width_per_group=self.width_per_group)) # Sequential:自定义顺序连接成模型,生成网络结构 return nn.Sequential(*layers) # forward():定义前向传播过程,描述了各层之间的连接关系 def forward(self, x): # 无论哪种ResNet,都需要的静态层 x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) # 动态层 x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) if self.include_top: x = self.avgpool(x) x = torch.flatten(x, 1) x = self.fc(x) return x# ResNet()中block参数对应的位置是BasicBlock或Bottleneck# ResNet()中blocks_num[0-3]对应[3, 4, 6, 3],表示残差模块中的残差数# 34层的resnetdef resnet34(num_classes=1000, include_top=True): # https://download.pytorch.org/models/resnet34-333f7ec4.pth return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)# 50层的resnetdef resnet50(num_classes=1000, include_top=True): # https://download.pytorch.org/models/resnet50-19c8e357.pth return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)# 101层的resnetdef resnet101(num_classes=1000, include_top=True): # https://download.pytorch.org/models/resnet101-5d3b4d8f.pth return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
2. train.py
import osimport sysimport jsonimport torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import transforms, datasetsfrom tqdm import tqdm# 训练resnet34from model import resnet34def main(): # 如果有NVIDA显卡,转到GPU训练,否则用CPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print("using {} device.".format(device)) data_transform = { # 训练 # Compose():将多个transforms的操作整合在一起 "train": transforms.Compose([ # RandomResizedCrop(224):将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为给定大小 transforms.RandomResizedCrop(224), # RandomVerticalFlip():以0.5的概率竖直翻转给定的PIL图像 transforms.RandomHorizontalFlip(), # ToTensor():数据转化为Tensor格式 transforms.ToTensor(), # Normalize():将图像的像素值归一化到[-1,1]之间,使模型更容易收敛 transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]), # 验证 "val": transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])} # abspath():获取文件当前目录的绝对路径 # join():用于拼接文件路径,可以传入多个路径 # getcwd():该函数不需要传递参数,获得当前所运行脚本的路径 data_root = os.path.abspath(os.getcwd()) # 得到数据集的路径 image_path = os.path.join(data_root, "flower_data") # exists():判断括号里的文件是否存在,可以是文件路径 # 如果image_path不存在,序会抛出AssertionError错误,报错为参数内容“ ” assert os.path.exists(image_path), "{} path does not exist.".format(image_path) train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"), transform=data_transform["train"]) # 训练集长度 train_num = len(train_dataset) # {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4} # class_to_idx:获取分类名称对应索引 flower_list = train_dataset.class_to_idx # dict():创建一个新的字典 # 循环遍历数组索引并交换val和key的值重新赋值给数组,这样模型预测的直接就是value类别值 cla_dict = dict((val, key) for key, val in flower_list.items()) # 把字典编码成json格式 json_str = json.dumps(cla_dict, indent=4) # 把字典类别索引写入json文件 with open('class_indices.json', 'w') as json_file: json_file.write(json_str) # 一次训练载入16张图像 batch_size = 16 # 确定进程数 # min():返回给定参数的最小值,参数可以为序列 # cpu_count():返回一个整数值,表示系统中的CPU数量,如果不确定CPU的数量,则不返回任何内容 nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) print('Using {} dataloader workers every process'.format(nw)) # DataLoader:将读取的数据按照batch size大小封装给训练集 # dataset (Dataset):输入的数据集 # batch_size (int, optional):每个batch加载多少个样本,默认: 1 # shuffle (bool, optional):设置为True时会在每个epoch重新打乱数据,默认: False # num_workers(int, optional): 决定了有几个进程来处理,默认为0意味着所有的数据都会被load进主进程 train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=nw) # 加载测试数据集 validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"), transform=data_transform["val"]) # 测试集长度 val_num = len(validate_dataset) validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size, shuffle=False, num_workers=nw) print("using {} images for training, {} images for validation.".format(train_num, val_num)) # 模型实例化 net = resnet34() net.to(device) # 加载预训练模型权重 # model_weight_path = "./resnet34-pre.pth" # exists():判断括号里的文件是否存在,可以是文件路径 # assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path) # net.load_state_dict(torch.load(model_weight_path, map_location='cpu')) # 输入通道数 # in_channel = net.fc.in_features # 全连接层 # net.fc = nn.Linear(in_channel, 5) # 定义损失函数(交叉熵损失) loss_function = nn.CrossEntropyLoss() # 抽取模型参数 params = [p for p in net.parameters() if p.requires_grad] # 定义adam优化器 # params(iterable):要训练的参数,一般传入的是model.parameters() # lr(float):learning_rate学习率,也就是步长,默认:1e-3 optimizer = optim.Adam(params, lr=0.0001) # 迭代次数(训练次数) epochs = 3 # 用于判断最佳模型 best_acc = 0.0 # 最佳模型保存地址 save_path = './resNet34.pth' train_steps = len(train_loader) for epoch in range(epochs): # 训练 net.train() running_loss = 0.0 # tqdm:进度条显示 train_bar = tqdm(train_loader, file=sys.stdout) # train_bar: 传入数据(数据包括:训练数据和标签) # enumerate():将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中 # enumerate返回值有两个:一个是序号,一个是数据(包含训练数据和标签) # x:训练数据(inputs)(tensor类型的),y:标签(labels)(tensor类型) for step, data in enumerate(train_bar): # 前向传播 images, labels = data # 计算训练值 logits = net(images.to(device)) # 计算损失 loss = loss_function(logits, labels.to(device)) # 反向传播 # 清空过往梯度 optimizer.zero_grad() # 反向传播,计算当前梯度 loss.backward() optimizer.step() # item():得到元素张量的元素值 running_loss += loss.item() # 进度条的前缀 # .3f:表示浮点数的精度为3(小数位保留3位) train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss) # 测试 # eval():如果模型中有Batch Normalization和Dropout,则不启用,以防改变权值 net.eval() acc = 0.0 # 清空历史梯度,与训练最大的区别是测试过程中取消了反向传播 with torch.no_grad(): val_bar = tqdm(validate_loader, file=sys.stdout) for val_data in val_bar: val_images, val_labels = val_data outputs = net(val_images.to(device)) # torch.max(input, dim)函数 # input是具体的tensor,dim是max函数索引的维度,0是每列的最大值,1是每行的最大值输出 # 函数会返回两个tensor,第一个tensor是每行的最大值;第二个tensor是每行最大值的索引 predict_y = torch.max(outputs, dim=1)[1] # 对两个张量Tensor进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回False # .sum()对输入的tensor数据的某一维度求和 acc += torch.eq(predict_y, val_labels.to(device)).sum().item() val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1, epochs) val_accurate = acc / val_num print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate)) # 保存最好的模型权重 if val_accurate > best_acc: best_acc = val_accurate # torch.save(state, dir)保存模型等相关参数,dir表示保存文件的路径+保存文件名 # model.state_dict():返回的是一个OrderedDict,存储了网络结构的名字和对应的参数 torch.save(net.state_dict(), save_path) print('Finished Training')if __name__ == '__main__': main()
3. predict.py
import osimport jsonimport torchfrom PIL import Imagefrom torchvision import transformsimport matplotlib.pyplot as pltfrom model import resnet34def main(): # 如果有NVIDA显卡,转到GPU训练,否则用CPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 将多个transforms的操作整合在一起 data_transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]) # 加载图片 img_path = "../tulip.jpg" # 确定图片存在,否则反馈错误 assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path) img = Image.open(img_path) # imshow():对图像进行处理并显示其格式,show()则是将imshow()处理后的函数显示出来 plt.imshow(img) # [C, H, W],转换图像格式 img = data_transform(img) # [N, C, H, W],增加一个维度N img = torch.unsqueeze(img, dim=0) # 获取结果类型 json_path = './class_indices.json' # 确定路径存在,否则反馈错误 assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path) # 读取内容 with open(json_path, "r") as f: class_indict = json.load(f) # 模型实例化,将模型转到device,结果类型有5种 model = resnet34(num_classes=5).to(device) # 载入模型权重 weights_path = "./resNet34.pth" # 确定模型存在,否则反馈错误 assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path) # 加载训练好的模型参数 model.load_state_dict(torch.load(weights_path, map_location=device)) # 进入验证阶段 model.eval() with torch.no_grad(): # 预测类别 # squeeze():维度压缩,返回一个tensor(张量),其中input中大小为1的所有维都已删除 output = torch.squeeze(model(img.to(device))).cpu() # softmax:归一化指数函数,将预测结果输入进行非负性和归一化处理,最后将某一维度值处理为0-1之内的分类概率 predict = torch.softmax(output, dim=0) # argmax(input):返回指定维度最大值的序号 # .numpy():把tensor转换成numpy的格式 predict_cla = torch.argmax(predict).numpy() # 输出的预测值与真实值 print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)], predict[predict_cla].numpy()) # 图片标题 plt.title(print_res) for i in range(len(predict)): print("class: {:10} prob: {:.3}".format(class_indict[str(i)], predict[i].numpy())) plt.show()if __name__ == '__main__': main()
4. spilit_data.py
import osfrom shutil import copy, rmtreeimport randomdef mk_file(file_path: str): if os.path.exists(file_path): # 如果文件夹存在,则先删除原文件夹再重新创建 rmtree(file_path) os.makedirs(file_path)def main(): # 保证随机可复现 random.seed(0) # 将数据集中10%的数据划分到验证集中 split_rate = 0.1 # 指向解压后的flower_photos文件夹 # getcwd():该函数不需要传递参数,获得当前所运行脚本的路径 cwd = os.getcwd() # join():用于拼接文件路径,可以传入多个路径 data_root = os.path.join(cwd, "flower_data") origin_flower_path = os.path.join(data_root, "flower_photos") # 确定路径存在,否则反馈错误 assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path) # isdir():判断某一路径是否为目录 # listdir():返回指定的文件夹包含的文件或文件夹的名字的列表 flower_class = [cla for cla in os.listdir(origin_flower_path) if os.path.isdir(os.path.join(origin_flower_path, cla))] # 创建训练集train文件夹,并由类名在其目录下创建子目录 train_root = os.path.join(data_root, "train") mk_file(train_root) for cla in flower_class: # 建立每个类别对应的文件夹 mk_file(os.path.join(train_root, cla)) # 创建验证集val文件夹,并由类名在其目录下创建子目录 val_root = os.path.join(data_root, "val") mk_file(val_root) for cla in flower_class: # 建立每个类别对应的文件夹 mk_file(os.path.join(val_root, cla)) # 遍历所有类别的图像并按比例分成训练集和验证集 for cla in flower_class: cla_path = os.path.join(origin_flower_path, cla) # iamges列表存储了该目录下所有图像的名称 images = os.listdir(cla_path) num = len(images) # 随机采样验证集的索引 # 从images列表中随机抽取k个图像名称 # random.sample:用于截取列表的指定长度的随机数,返回列表 # eval_index保存验证集val的图像名称 eval_index = random.sample(images, k=int(num*split_rate)) for index, image in enumerate(images): if image in eval_index: # 将分配至验证集中的文件复制到相应目录 image_path = os.path.join(cla_path, image) new_path = os.path.join(val_root, cla) copy(image_path, new_path) else: # 将分配至训练集中的文件复制到相应目录 image_path = os.path.join(cla_path, image) new_path = os.path.join(train_root, cla) copy(image_path, new_path) # '\r'回车,回到当前行的行首,而不会换到下一行,如果接着输出,本行以前的内容会被逐一覆盖 # end="":将print自带的换行用end中指定的str代替 print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") print() print("processing done!")if __name__ == '__main__': main()
五、参考内容
1.文章
Deep Residual Learning for Image Recognition

https://arxiv.org/abs/1512.03385
残差神经网络(ResNet)
https://zhuanlan.zhihu.com/p/101332297
残差网络笔记
https://www.cnblogs.com/alanma/p/6877166.html
2.视频
使用pytorch搭建ResNet并基于迁移学习训练
https://www.bilibili.com/video/av92497251?vd_source=78dedbc0ab33a4edb884e1ef98f3c6b8
ResNet代码(超详细注释)+数据集下载地址:
https://download.csdn.net/download/qq_43307074/86731982
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。