[Linux#57][HTTP] URL结构 | 原理 | 请求与响应 | postman | fiddler
lvy- 2024-09-30 10:07:03 阅读 87
目录
对比思考:
一. 预备知识
服务器的设计原则与常见协议
OSI 七层模型和 TCP/IP 模型
HTTP 协议
1. URL 的结构
2. HTTP 是超文本传输协议
3. URL 编码与解码
二. HTTP 协议
1.原理
响应
2. 基本工具(postman,fiddler)
3. 代码验证
学习思路:
✔️2 个简单的预备知识✔️http 请求和响应 格式画出来,两个工具见一见 http 请求/响应的样子写一个最简单的 httpserver,用浏览器直接测试开始研究 http 的细节字段--回归理论+http code谈 http 报文细节
对比思考:
编码和解码 | 序列化和反序列化
相同点:
都是数据处理的过程,涉及到数据的转换。都有一个逆过程,编码对应解码,序列化对应反序列化。
不同点:
目的不同:编码通常是为了数据的传输或存储的兼容性,而解码是为了恢复原始数据;序列化是为了保存对象的状态,反序列化是为了恢复对象的状态。处理的数据类型不同:编码通常处理基本数据类型(如字符、字节等),而序列化处理的是复杂的数据结构(如对象、数组等)。复杂度不同:序列化通常比编码更复杂,因为它需要处理对象之间的引用关系、类型信息等。上下文不同:编码和解码更多地在字节和字符层面操作,序列化和反序列化则与特定的编程语言和对象模型相关。
总的来说,编码和解码是序列化和反序列化的一个子集,序列化和反序列化包含了编码和解码的过程,但涉及更复杂的结构和状态转换。
一. 预备知识
服务器的设计原则与常见协议
在之前的学习中,我们已经完成了基于 Socket 的基本服务器实现,并且通过多进程、多线程、线程池等模式处理并发请求。我们还了解了如何使用自定义协议进行通信,结合序列化和反序列化处理数据。这些知识让我们具备了开发基础的网络应用的能力。
那么,是否有针对常见场景的现成协议软件可以直接使用呢?答案是肯定的,最典型的例子就是 HTTP 协议。未来我们使用 HTTP 做的事情,本质上和我们之前做的一样,只不过 HTTP 协议是为特定的应用场景而设计的。
OSI 七层模型和 TCP/IP 模型
在网络基础中,我们知道 OSI 模型将网络通信划分为七层:应用层、表示层、会话层等。而在 TCP/IP 协议中,应用层、表示层和会话层通常被合并为一层,称为应用层。
当我们设计网络版的计数器应用时,实际上也将功能划分为三层:
会话层:处理获取连接、启动多进程、多线程或线程池。表示层:负责读取完整报文、提取有效载荷,并进行序列化与反序列化。应用层:处理具体业务逻辑(即回调函数 <code>callback)。
实际上,OSI 模型中的七层划分是为了编码时保持层次结构的清晰性。比如表示层有多种方案:自定义协议、JSON、Protobuf、XML 等。这些并没有被固定到操作系统内核中,使得开发者能够灵活选择适合的表示层方案。
HTTP 协议
虽然我们可能对 HTTP 还不够了解,但可以确定,HTTP 协议中肯定包含了以下几方面:
使用套接字进行通信。具备序列化和反序列化的机制。包含报头的添加和解析过程。
HTTP 协议作为应用层协议,也必须处理与我们所讨论的相同的三项任务:
解析 URL。处理客户端与服务器之间的请求与响应。根据请求路径返回文件资源。
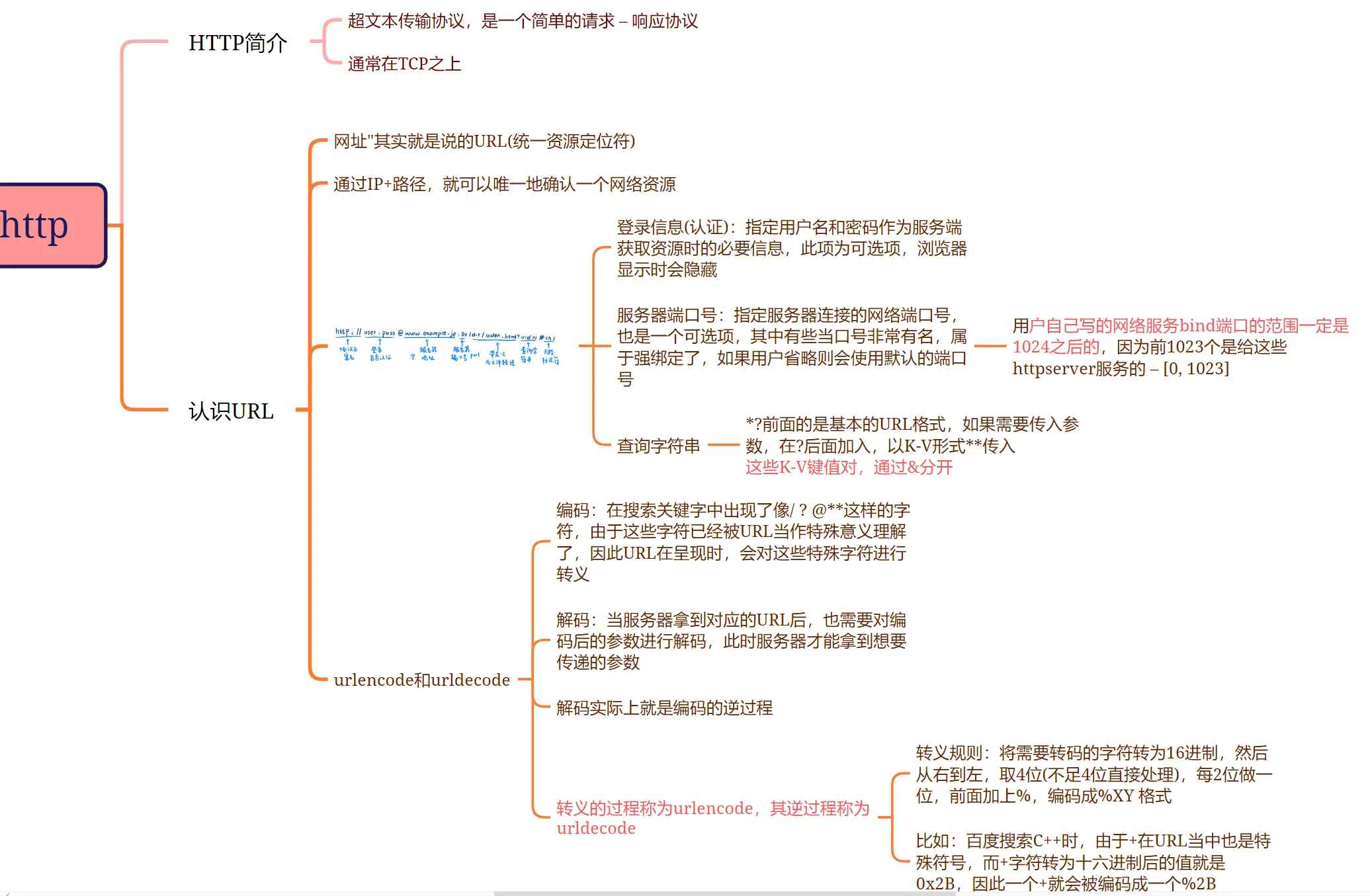
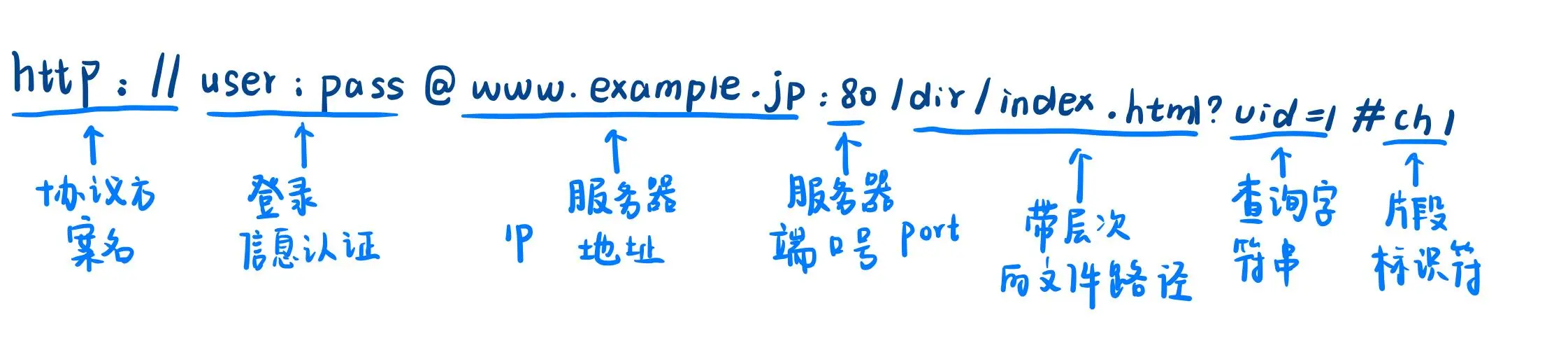
1. URL 的结构
常见的 URL 结构如下:
https://blog.csdn.net/fight_p/article/details/137103487
https:协议(HTTP 或 HTTPS)。blog.csdn.net:域名,经过 DNS 解析后转换为服务器的 IP 地址。/fight_p/article/details/137103487:文件路径,指向服务器上的某个资源。
完整如下,之后会详细解释:

浏览器通过这个 URL 找到对应的服务器,并请求该路径下的资源。值得注意的是,URL 中可以没有明确指定端口号,但服务器必须绑定到众所周知的端口(例如 HTTP 使用端口 80,HTTPS 使用端口 443)。如果 URL 中没有显示指定端口号,浏览器会根据协议自动填充。
2. HTTP 是超文本传输协议
HTTP 协议的本质是从服务器获取文件资源。资源可以是:
图片、视频、音频等文件。HTML、CSS、JavaScript 文件。API 接口返回的数据。
无论是哪种资源,它们最终都存储在服务器的某个路径下,而 HTTP 协议则负责根据客户端的请求,定位并返回这些资源。
3. URL 编码与解码
在 URL 中,一些特殊字符(如 <code>/, ?, : 等)具有特定的含义,因此不能直接出现在请求的参数中。这些字符在传递时需要进行 URL 编码。编码后的字符以 %XY 的形式表示,其中 XY 是字符的 16 进制表示。
编码规则如下:
将需要编码的字符转换为 16 进制。每个字符占 8 位,从右到左取 4 位转成 16 进制数。16 进制数前面加 %,形成 %XY 格式。
解码 则是将 %XY 转回原始字符。
虽然我们可以从头开始实现这个编码和解码过程,但实际上现成的编码和解码函数已经非常成熟,可以直接使用。我们可以在网上查找相关的 URL 解码源码,作为工程师使用即可。
总结:

二. HTTP 协议
1.原理
实现如下:
可以发现 HTTP 协议是由多个部分组成的,下面我们将逐一分析这些部分。
请求
请求行
HTTP请求的第一行被称为请求行,它由三部分组成:
请求方法:如GET、POST、PUT等,表示对资源的操作。URL:统一资源定位符,指定请求的资源。HTTP版本:常见的有HTTP/1.0、HTTP/1.1、HTTP/2.0等。
请求行以<code>\r\n或\n作为分隔符。
请求报头
请求报头是请求的第二大部分,由多行组成,每行包含一个属性,格式为name:value。这些属性提供了关于请求的额外信息,如客户端类型、请求内容类型等。
空行
紧随请求报头之后的是一个空行,这个空行非常重要,它标志着请求头的结束和请求正文的开始。
请求正文
请求的最后一部分是正文,这部分是可选的。例如,在提交表单数据或上传文件时,正文将包含这些数据。
一个完整的HTTP请求报文包括上述四大块,并通过TCP连接发送到服务器。
响应
HTTP响应的格式与请求格式非常相似,也分为四部分。
1. 状态行
响应的第一行是状态行,同样由三部分组成:
HTTP版本:表明使用的HTTP协议版本。状态码:如200、400、302、307、500、404等,用于表示请求的结果。状态码描述:对状态码的文本描述,如404表示"Not Found",200表示"OK"。
2. 响应报文
响应报文由多行组成,包含了关于响应的额外信息,如内容类型、服务器类型等。
3. 空行
与请求格式一样,响应报文后也跟着一个空行。
4. 响应正文
响应正文中包含了从服务器返回的实际内容,通常是HTML、CSS、JS、图片、视频或音频等。
这四部分构成了HTTP响应报文,并通过TCP连接发送回客户端。
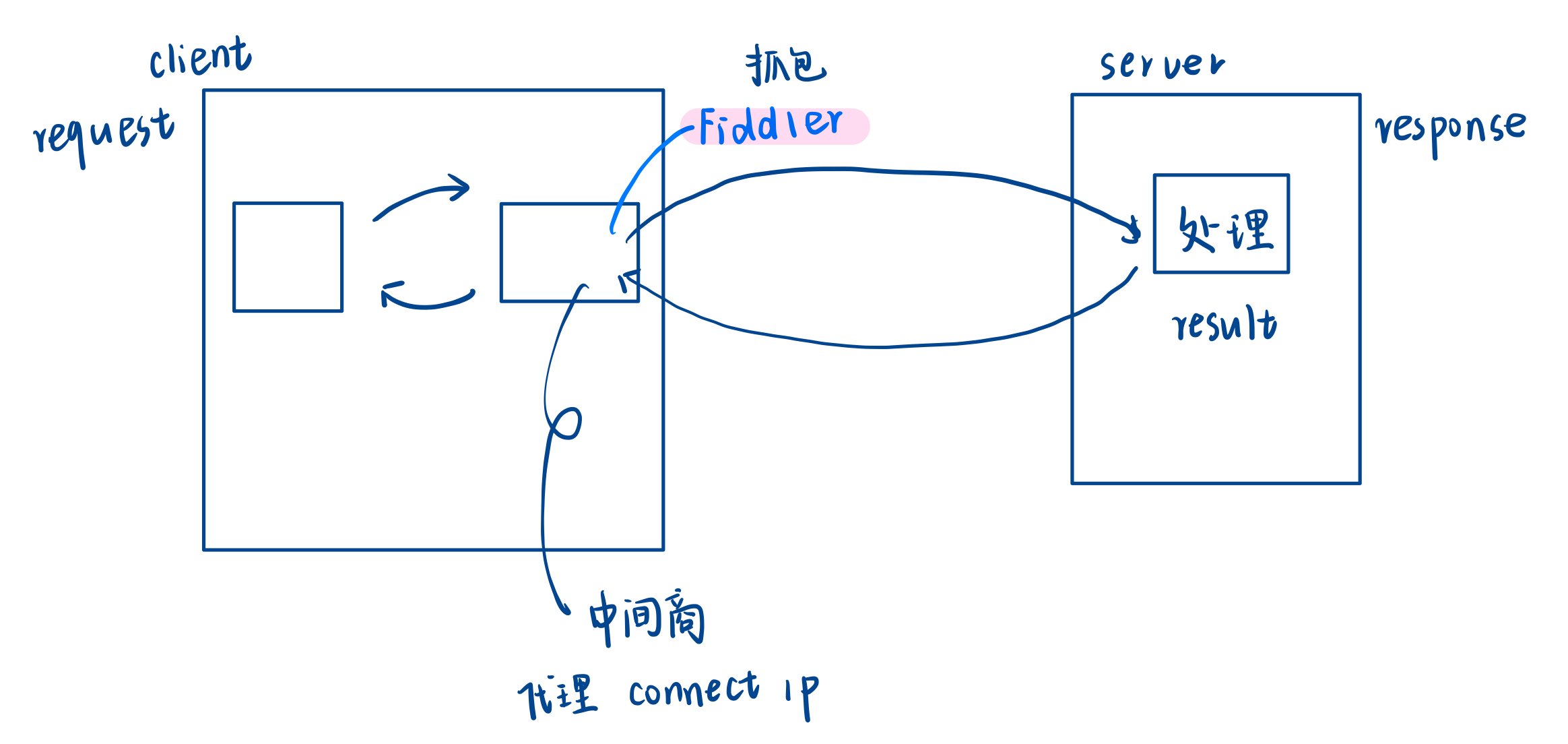
2. 基本工具(postman,fiddler)
postman,不是抓包工具,模拟客户端 ----> 浏览器行为
postman可以认为就是把浏览器换成它发起请求然后服务器给响应。
fiddler,是一个抓包工具,专门用来抓http的,抓的是本地的,可以用来调试的
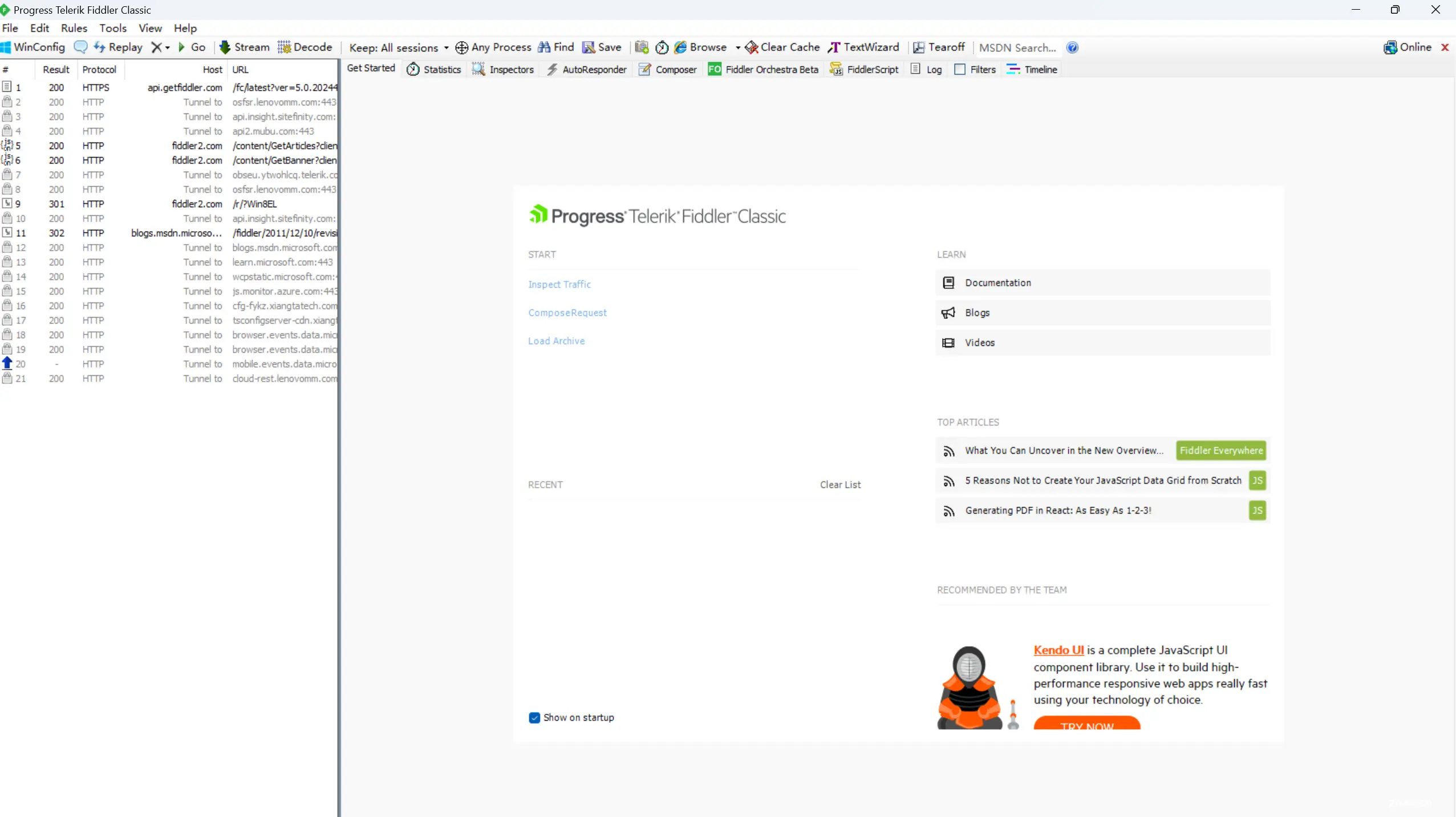
fiddler原理就是,未来浏览器在发起请求时是把请求交给fiddler,由fiddler代替你去请求服务器,服务器响应也是给fiddler,然后fiddler再把响应转发给浏览器。
3. 代码验证
接下来,我们将通过编写代码来验证上述理论。我们将使用套接字(socket)来模拟HTTP请求和响应的过程。
<code># 示例代码,使用Python的socket库
import socket
# 创建socket对象
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接到服务器
client_socket.connect(('www.example.com', 80))
# 发送HTTP请求
request = "GET / HTTP/1.1\r\nHost: www.example.com\r\n\r\n"
client_socket.send(request.encode())
# 接收响应
response = b''
while True:
part = client_socket.recv(1024)
if not part:
break
response += part
# 打印响应内容
print(response.decode())
# 关闭连接
client_socket.close()
基于上述代码进行完善,我们可以看到如何通过套接字发送HTTP请求并接收响应,从而验证我们对HTTP协议格式的理解,下篇文章将 完整的实现自定义 http协议~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。