Linux shell编程学习笔记73:sed命令——沧海横流任我行(上)
紫郢剑侠 2024-09-12 11:07:02 阅读 75

0 前言
在大数据时代,我们要面对大量数据,有时需要对数据进行替换、删除、新增、选取等特定工作。
在Linux中提供很多数据处理命令,如果我们要以行为单位进行数据处理,可以使用sed。
1 sed 的帮助信息,功能,格式,选项和参数说明,退出状态
1.1 sed 的帮助信息
我们可以使用命令sed--help来获取帮助信息。
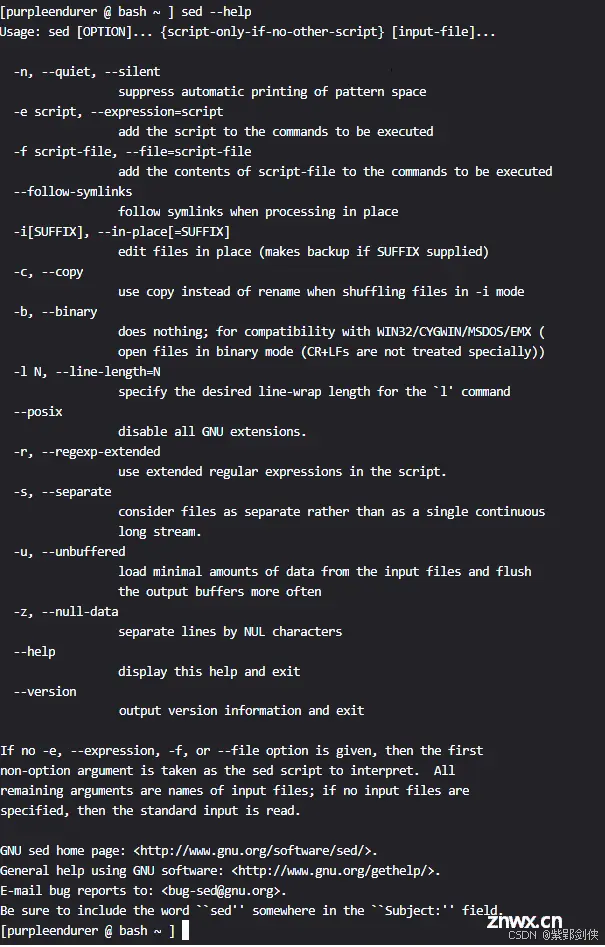
1.1.1 CSDN程序员研究院bash中的sed 的帮助信息
<code>[purpleendurer @ bash ~] sed --help
Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file]...
-n, --quiet, --silent
suppress automatic printing of pattern space
-e script, --expression=script
add the script to the commands to be executed
-f script-file, --file=script-file
add the contents of script-file to the commands to be executed
--follow-symlinks
follow symlinks when processing in place
-i[SUFFIX], --in-place[=SUFFIX]
edit files in place (makes backup if SUFFIX supplied)
-c, --copy
use copy instead of rename when shuffling files in -i mode
-b, --binary
does nothing; for compatibility with WIN32/CYGWIN/MSDOS/EMX (
open files in binary mode (CR+LFs are not treated specially))
-l N, --line-length=N
specify the desired line-wrap length for the `l' command
--posix
disable all GNU extensions.
-r, --regexp-extended
use extended regular expressions in the script.
-s, --separate
consider files as separate rather than as a single continuous
long stream.
-u, --unbuffered
load minimal amounts of data from the input files and flush
the output buffers more often
-z, --null-data
separate lines by NUL characters
--help
display this help and exit
--version
output version information and exit
If no -e, --expression, -f, or --file option is given, then the first
non-option argument is taken as the sed script to interpret. All
remaining arguments are names of input files; if no input files are
specified, then the standard input is read.
GNU sed home page: <http://www.gnu.org/software/sed/>.
General help using GNU software: <http://www.gnu.org/gethelp/>.
E-mail bug reports to: <bug-sed@gnu.org>.
Be sure to include the word ``sed'' somewhere in the ``Subject:'' field.
[purpleendurer @ bash ~]
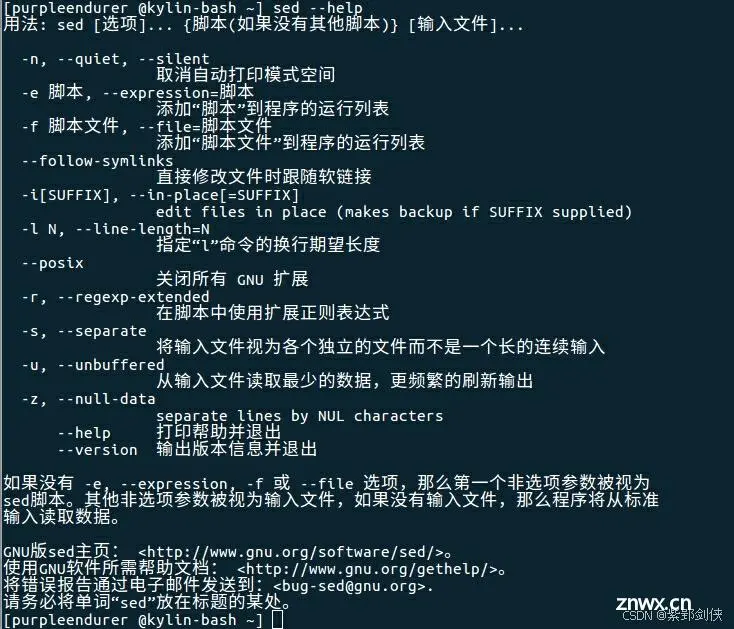
1.1.2 银河麒麟(kylin)系统中的sed帮助信息
<code>[purpleendurer @kylin-bash ~] sed --help
用法: sed [选项]... {脚本(如果没有其他脚本)} [输入文件]...
-n, --quiet, --silent
取消自动打印模式空间
-e 脚本, --expression=脚本
添加“脚本”到程序的运行列表
-f 脚本文件, --file=脚本文件
添加“脚本文件”到程序的运行列表
--follow-symlinks
直接修改文件时跟随软链接
-i[SUFFIX], --in-place[=SUFFIX]
edit files in place (makes backup if SUFFIX supplied)
-l N, --line-length=N
指定“l”命令的换行期望长度
--posix
关闭所有 GNU 扩展
-r, --regexp-extended
在脚本中使用扩展正则表达式
-s, --separate
将输入文件视为各个独立的文件而不是一个长的连续输入
-u, --unbuffered
从输入文件读取最少的数据,更频繁的刷新输出
-z, --null-data
separate lines by NUL characters
--help 打印帮助并退出
--version 输出版本信息并退出
如果没有 -e, --expression, -f 或 --file 选项,那么第一个非选项参数被视为
sed脚本。其他非选项参数被视为输入文件,如果没有输入文件,那么程序将从标准
输入读取数据。
GNU版sed主页: <http://www.gnu.org/software/sed/>。
使用GNU软件所需帮助文档: <http://www.gnu.org/gethelp/>。
将错误报告通过电子邮件发送到:<bug-sed@gnu.org>.
请务必将单词“sed”放在标题的某处。
[purpleendurer @kylin-bash ~]
1.2 sed的功能
sed命令源于stream editor(流编辑器),是一个非交互式命令行文本编辑器。
sed命令的功能主要是对文本进行过滤,例如,接受文本输入,对文本执行一些操作(或一组操作),并输出修改后的文本。
sed命令在处理文本时,会先把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾
sed命令的强大之处在于能够处理大文件,并使用正则表达式进行模式匹配和替换,这使其成为脚本编写和数据整理的必备工具。
sed命令通常用于使用模式匹配提取文件的一部分,或替换文件中多次出现的字符串。
当您需要在文件或流上高效地执行文本转换时,可以使用 sed。
1.3 sed的格式
sed [选项]... {脚本(如果没有其他脚本)} [输入文件]...
1.4 sed的选项说明
| 选项 | 说明 |
|---|---|
| -n, --quiet, --silent | 取消自动打印模式空间 |
| -e 脚本, --expression=脚本 | 将脚本添加到要执行的命令中。
即:直接在命令行模式上进行sed动作编辑,此为默认选项
|
| -f 脚本文件, --file=脚本文件 | 将指定脚本文件的内容添加到要执行的命令中。
即:将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作
|
| --follow-symlinks | 直接修改文件时跟随软链接 |
| -i[SUFFIX], --in-place[=SUFFIX] | 就地编辑文件(如果提供了 SUFFIX,则进行备份)
当使用-i选项时,要注意它可能对文件进行不可逆的修改。
在处理重要数据时,务必确保进行备份。
|
| -c, --copy | 在 -i 模式下随机播放文件时,使用复制而不是重命名 |
| -b, --binary | 什么都不做;与 WIN32/CYGWIN/MSDOS/EMX 兼容(以二进制模式打开文件(CR+LF 未得到特殊处理)) |
| -l N, --line-length=N | 为 'l' 命令指定所期望的换行长度 |
| --posix | 关闭所有 GNU 扩展 |
| -r, --regexp-extended | 在脚本中使用扩展正则表达式 |
| -s, --separate | 将输入文件视为各个独立的文件而不是一个长的连续输入 |
| -u, --unbuffered | 从输入文件加载最少的数据量,并更频繁地刷新输出缓冲区 |
| -z, --null-data | 用 NUL 字符来分隔行 |
| --help | 打印帮助并退出 |
| --version | 输出版本信息并退出 |
1.5 sed的参数
如果没有给出 -e、--expression、-f 或 --file 选项,则第一个非选项 参数作为要解释的 sed 脚本。
如果在处理上述操作后仍有任何命令行参数,则这些参数将被解释为要处理的输入文件的名称。
文件名“-”是指标准输入流。如果未指定文件名,则将处理标准输入。
1.6 sed的退出状态
退出状态为零表示成功,非零值表示失败。
GNU sed 返回以下退出状态值:
| 退出码 | 说明 |
|---|---|
| 0 | 成功完成。 |
| 1 | 无效的命令、无效的语法、无效的正则表达式或与 --posix 一起使用的 GNU sed 扩展命令。 |
| 2 | 无法打开命令行上指定的一个或多个输入文件(例如,如果找不到文件,或读取权限被拒绝)。
继续处理其他文件。
|
| 4 | 如果出现 I/O 错误,或者在运行时出现严重的处理错误,GNU sed 会立即中止。 |
此外,命令 q 和 Q 可用于使用自定义退出代码值终止 sed(这是一个 GNU sed 扩展),详见2.1。
2 sed的脚本
sed 脚本程序由一个或多个 sed 命令组成,这些命令由 -e、-f、--expression 和 --file 选项中的一个或多个传入,如果不存在以上这些选项,则由第一个非选项参数传入。
sed命令的脚本命令格式如下:
[地址]X[选项]
其中:
1.X :是一个单字母的 sed 文本处理命令。
2.[地址] :是可选的行地址。如果指定了 [地址],则命令 X 将仅在匹配的行上执行。[地址] 可以是单行号、正则表达式或一系列行。
3. [选项]: 用于某些 sed 命令。
3 sed命令
3.1 sed命令说明
| 命令 | 说明 |
|---|---|
| a\ | 在当前行下面插入文本 |
| i\ | 在当前行上面插入文本 |
| c\ | 把选定的行改为新的文本 |
| d | 删除,删除选择的行 |
| D | 删除模板块的第一行 |
| s | 替换指定字符 |
| h | 拷贝模板块的内容到内存中的缓冲区 |
| H | 追加模板块的内容到内存中的缓冲区 |
| g | 获得内存缓冲区的内容,并替代当前模板块中的文本 |
| G | 获得内存缓冲区的内容,并追加到当前模板块文本的后面 |
| l | 列表不能打印字符的清单 |
| n | 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令 |
| N | 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码 |
| p | 打印模板块的行 |
| P | 打印模板块的第一行 |
| q[exit-code] | 退出 sed,而不处理任何其他命令或输入。 |
| Q[exit-code] | 此命令与 q 相同,但不会打印模式空间的内容。
与 q 一样,它提供了向调用者返回退出代码的功能。
|
| b lable | 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾 |
| r file | 从file中读行 |
| t label | if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾 |
| T label | 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾 |
| w file | 写并追加模板块到file末尾 |
| W file | 写并追加模板块的第一行到file末尾 |
| ! | 表示后面的命令对所有没有被选定的行发生作用 |
| = | 打印当前行号 |
| # | 把注释扩展到下一个换行符以前; |
3.2 替换标记
| 替换标记 | 说明 |
|---|---|
| g | 表示行内全面替换 |
| p | 表示打印行 |
| w | 表示把行写入一个文件 |
| x | 表示互换模板块中的文本和缓冲区中的文本 |
| y | 表示把一个字符翻译为另外的字符(但是不用于正则表达式) |
| \1 | 子串匹配标记 |
| & | 已匹配字符串标记 |
3.3 元字符
| 元字符 | 说明 |
|---|---|
| ^ | 匹配行开始,如:/^sed/匹配所有以sed开头的行 |
| $ | 匹配行结束,如:/sed$/匹配所有以sed结尾的行 |
| . | 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d |
| * | 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行 |
| [] | 匹配一个指定范围内的字符,如/[ss]ed/匹配sed和Sed |
| [^] | 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行 |
| \(..\) | 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers |
| & | 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love** |
| \< | 匹配单词的开始,如:/\ |
| \> | 匹配单词的结束,如/love\>/匹配包含以love结尾的单词的行 |
| x\{m\} | 重复字符x,m次,如:/0\{5\}/匹配包含5个0的行 |
| x\{m,\} | 重复字符x,至少m次,如:/0\{5,\}/匹配至少有5个0的行 |
| x\{m,n\} | 重复字符x,至少m次,不多于n次,如:/0\{5,10\}/匹配5~10个0的行 |
4 sed命令中的地址
sed命令中的地址用于决定对流入模式空间的哪些行进行编辑。
如果没有指定地址,sed将处理流入模式空间的所有行。
地址可以使用以下方式指定。
4.1 数字
sed 脚本中的地址可以采用以下任何形式:
| 表达式 | 说明 |
| 行号 | 指定行号将仅匹配输入中的该行。
请注意,除非指定了 -i 或 -s 选项,否则 sed 会连续计算所有输入文件的行数。
|
| $ | 此地址与最后一个输入文件的最后一行匹配,或者在指定 -i 或 -s 选项时匹配每个文件的最后一行。 |
| 第一步~步长 | 这个 GNU 扩展匹配从第一行开始的每一步行。特别是,当存在非负 n 时,将选择行,使得当前行号等于第一个 + (n * 步长)。
因此,我们可以使用 1~2 来选择奇数行,使用 0~2 来选择偶数行;
要选择从第二行开始的每三行,将使用“2~3”;
要选择从第十行开始的每五行,请使用“10~5”;
而“50~0”只是50的一种晦涩难懂的说法。
|
4.2 文本匹配(正则表达式)
sed 支持以下正则表达式地址。默认正则表达式为基本正则表达式 (BRE)。
如果使用 -E 或 -r 选项,则正则表达式应采用扩展正则表达式 (ERE) 语法。
| 表达式 | 说明 |
| /正则表达式/ | 这将选择与正则表达式正则表达式匹配的任何行。
如果正则表达式本身包含任何 / 字符,则每个字符都必须通过反斜杠 (\) 进行转义。
空正则表达式 '//' 重复上次正则表达式匹配(如果将空正则表达式传递给 s 命令,则同样适用)。请注意,正则表达式的修饰符是在编译正则表达式时计算的,因此将它们与空正则表达式一起指定是无效的。
|
| \%regexp% | % 可以替换为任何其他单个字符。
这也与正则表达式正则表达式匹配,但允许使用与 / 不同的分隔符。
如果正则表达式本身包含大量斜杠,这将特别有用,因为它避免了每个 / 的繁琐转义。
如果正则表达式本身包含任何分隔符,则每个分隔符都必须用反斜杠 (\) 进行转义。
|
| <code>/regexp/I
| 正则表达式匹配的 I 修饰符是一个 GNU 扩展,它使正则表达式以不区分大小写的方式进行匹配。
在许多其他编程语言中,小写字母 i 用于不区分大小写的正则表达式匹配。但是,在 sed 中,i 用于插入命令
|
|
| 正则表达式匹配的 M 修饰符是一个 GNU sed 扩展,它指示 GNU sed 在多行模式下匹配正则表达式。修饰符使 ^ 和 $ 分别匹配(除了正常行为)换行符之后的空字符串和换行符之前的空字符串。有一些特殊字符序列(\' 和 \')始终与缓冲区的开头或结尾匹配。此外,在多行模式下,句点字符与换行符不匹配。
|
| 0,/regexp/ | 可以在地址规范中使用 0 的行号,例如 0,/regexp/,以便 sed 也将尝试匹配第一输入行中的正则表达式。换句话说,0,/regexp/ 类似于 1,/regexp/,不同之处在于,如果 addr2 匹配输入的第一行,则 0,/regexp/ 形式将认为它结束范围,而 1,/regexp/ 形式将匹配其范围的开头,从而使范围跨度直到正则表达式的第二次出现。
请注意,这是 0 地址唯一有意义的地方;没有第 0 行,以任何其他方式给出 0 地址的命令都会产生错误。
|
|
| 匹配 addr1 和 addr1 后面的 N 行。 |
|
| 匹配 addr1 和 addr1 后面的行,直到输入行号是 N 的倍数的下一行。 |
正则表达式地址对当前模式空间的内容进行操作。如果模式空间发生变化(例如,使用 s/// 命令),则正则表达式匹配将对更改的文本进行操作。
4.3 范围地址
可以通过指定两个用逗号 (,) 分隔的地址来指定地址范围。
5 参考资料
sed, a stream editorsed, a stream editor

https://www.gnu.org/software/sed/manual/sed.html
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。