保姆式介绍DDR5(比喻方法讲解)
CSDN 2024-08-27 17:37:01 阅读 90
引入 DDR5 的原因主要与现代计算需求和内存技术的进步密切相关。以下是对你提到的每个点的详细分析:
1. 多核 CPU 架构的普及
随着技术的进步,多核 CPU 架构成为主流。这意味着越来越多的计算任务能够并行处理,从而显著提高整体算力。
影响:虽然多核设计提高了计算能力,但也增加了对内存带宽的需求,因为每个核心都希望能够快速访问内存,以保持其性能。
2. CPU 核心数量的增加导致内存带宽的降低
随着 CPU 核心数量的增加,每个核心能够分配到的内存带宽变得相对较少。
现象:例如,在使用传统的内存架构时,如果内存带宽固定,而 CPU 核心数量增加,那么每个核心所获得的带宽将会下降。这种带宽的下降可能导致多核 CPU 的性能未能充分发挥,因为它们无法快速地获取所需的数据。
3. DDR4 达到极限
DDR4 已经在其设计中达到了一定的数据速率和带宽的上限。
问题:虽然 DDR4 提供了比前代内存(如 DDR3)更高的性能,但随着计算需求的增长,DDR4 在内存带宽和数据速率方面已无法满足现代应用的需求。
4. 新的内存架构需求
为了适应下一代 x86 CPU 的单核内存带宽需求,必须引入新的内存架构。
解决方案:DDR5 作为新一代内存技术应运而生,旨在解决现有内存技术无法满足日益增长的带宽需求的问题。它通过提高数据传输速率和带宽,为多核 CPU 提供更好的支持。
5. DDR5 的数据速率提升
DDR5 的数据速率达到了 DDR4 的 2 倍,这对于提升整体性能至关重要。
性能提升:DDR5 的最大数据速率可以达到 6400 MT/s(或更高),相较于 DDR4 的最高数据速率(最高可达 3200 MT/s),这意味着 DDR5 可以显著提高内存带宽。通过增加带宽,DDR5 能够为每个核心提供更多的内存访问能力,从而提升整体计算性能。
总结
引入 DDR5 的动因主要是为了应对以下挑战:
提升内存带宽:满足多核 CPU 对内存带宽的高需求,确保每个核心能够获得足够的内存资源,以维持其高效能。支持未来的应用:适应数据中心、高性能计算、人工智能和机器学习等领域对内存性能的需求。推动技术进步:推动内存技术的进一步发展,满足更复杂计算任务的需要,确保系统的整体性能和效率。
DDR5 的引入为计算机系统提供了更强大的内存支持,有助于提升整体性能,并适应未来技术发展的需求。
在讨论 SoC(系统级芯片)速率和内存带宽的关系时,以 8 核 Cortex-A76 处理器和 DDR5 内存为例,可以帮助我们理解这两者之间的相互影响。以下是详细分析和举例说明:
1. SoC 速率与内存带宽的定义
SoC 速率:指的是 SoC 内部处理器(如 Cortex-A76)的工作频率和其处理数据的能力。对于 8 核 Cortex-A76,其主频可以达到 2.6 GHz 或更高。
内存带宽:是指内存可以在单位时间内传输的数据量。内存带宽通常以 GB/s 表示。
2. 8 核 Cortex-A76 的性能
Cortex-A76 是 Arm 的高性能处理器,具有以下特点:
多核架构:8 个核心可以并行处理多个任务,从而提高整体性能。
每个核心的执行能力:假设每个 Cortex-A76 核心在其主频下(如 2.6 GHz)可以执行一定数量的指令(例如,每个周期可以执行 2 条指令),那么每个核心的计算能力可以通过以下公式计算:

4. SoC 速率与内存带宽的关系
数据吞吐量:SoC 的性能不仅依赖于处理器本身的计算能力,还依赖于内存带宽。内存带宽越高,处理器在每个时钟周期内可以获取的数据越多,从而提高整体系统性能。
并行处理:在 8 核 Cortex-A76 的情况下,如果内存带宽不足以支持所有核心的同时数据需求,可能会出现瓶颈现象,即处理器在处理数据时无法获得足够的内存支持,导致 CPU 等待内存操作完成,降低整体性能。
6. 小结
计算能力 vs. 内存带宽:多核 Cortex-A76 的强大计算能力需要与高带宽的内存相结合,以避免瓶颈。DDR5 的优势:引入 DDR5 内存的主要目的是提供更高的内存带宽,以支持现代多核处理器的需求,确保数据能够在处理器与内存之间迅速传递,从而提升整体系统性能。
通过上述分析,可以看到 SoC 速率和内存带宽之间的密切关系,以及为什么在现代计算架构中,确保充足的内存带宽是至关重要的。
GIPS(每秒十亿条指令)和 DMIPS(每秒每兆指令)都是用于衡量处理器性能的指标,但它们在含义和使用场景上有所不同。以下是对它们的详细解释以及为什么在某些情况下更倾向于使用 GIPS 而不是 DMIPS 的原因。
1. GIPS(Giga Instructions Per Second)
定义:GIPS 是衡量处理器每秒执行的十亿条指令的单位。它可以直接反映出处理器的执行能力。优点:
更简单直接,容易理解。在处理器架构和计算性能比较中常用。 缺点:
不考虑指令的复杂性和类型(即不区分简单指令与复杂指令的执行时间)。
2. DMIPS(Dhrystone MIPS)
定义:DMIPS 是 Dhrystone 基准测试的结果,通常用于衡量处理器的指令执行性能。Dhrystone 是一种合成基准测试,用于评估系统的整数计算性能。1 DMIPS 指的是处理器每秒能够执行一百万条 Dhrystone 指令。优点:
考虑了指令的复杂性和工作负载的实际应用场景,因此在一定程度上可以反映出处理器的实际性能。 缺点:
基准测试的结果依赖于特定的测试程序,可能无法全面代表处理器在所有任务中的性能。
3. 为什么在某些情况下更倾向于使用 GIPS 而不是 DMIPS
通用性:GIPS 是一个更通用的性能度量,适用于各种类型的处理器和计算场景,而 DMIPS 是基于特定基准测试(Dhrystone),在某些应用场景下可能不够全面。
简单直接:GIPS 更加简单易懂,可以直接反映出处理器的基本执行能力,而 DMIPS 需要对基准测试结果进行解释。
实际应用:在某些情况下,开发者更关注的是每秒执行的指令数量,而不单单是基于某一特定测试的性能评估。
性能对比:在多核和多线程处理器的情况下,使用 GIPS 可以更容易地进行对比,因为它直接与每个核心的指令执行能力相联系。
4. 小结
GIPS 和 DMIPS 各有优缺点,选择哪一个取决于具体的评估需求。对于一般的处理器性能评估,GIPS 更加简单直观;而在需要深入分析处理器性能的情况下,DMIPS 可能会提供更多的上下文信息。在实际应用中,工程师和开发者可能会根据需求选择使用 GIPS 或 DMIPS,或者结合两者的结果进行综合评估。


7. 小结
GIPS 是衡量处理器性能的单位,用于表示每秒执行的指令数。
Cortex-A76 每个核心的处理能力是由其主频和超标量能力决定的。
每核需求反映了处理每个任务时内存的需求,具体值可能根据实际应用而变化。
下面是 DDR5 内存时序参数的详细解释和图示,帮助理解每个参数及其对内存性能的影响。
1. CL(CAS Latency)
定义:CAS 延迟是指从内存控制器发出读取命令到数据开始传输所需的时钟周期数。影响:较低的 CL 值意味着更快的内存响应速度,但可能会增加内存控制器的负担。典型值:DDR5 中 CL 通常为 36、40、46。
图示:
命令发出 ----------- (CL) ----------- 数据开始传输
2. tAA(Address to First Data Access Time)
定义:从发出读取命令到第一个数据有效输出的延迟时间。影响:较低的 tAA 值可以缩短数据访问延迟,提高性能。典型值:在 DDR5 中,tAA 也通常与 CL 值相关。
图示:
读取命令 ----------- (tAA) ----------- 第一个数据
3. tRCD(RAS to CAS Delay)
定义:行地址选中后到列地址选中所需的时间。影响:较低的 tRCD 值可以加快内存的读取速度。典型值:DDR5 中 tRCD 一般为 18ns、20ns、22ns。
图示:
行地址选择 ------- (tRCD) ------- 列地址选择
4. tRP(Row Precharge Time)
定义:行被关闭后再次被激活所需的时间。影响:较低的 tRP 值可以提高内存的写入速度。典型值:DDR5 中 tRP 通常为 18ns、20ns、22ns。
图示:
行关闭 ------- (tRP) ------- 行激活
5. tRAS(Row Active Time)
定义:行被激活后,再次被关闭所需的时间。影响:较低的 tRAS 值可以提高效率,但也可能影响稳定性。典型值:DDR5 中 tRAS 一般为 36ns、40ns、44ns。
图示:
行激活 ------- (tRAS) ------- 行关闭
6. tRC(Row Cycle Time)
定义:完成一次行操作(包括行激活和行关闭)所需的时间。影响:较低的 tRC 值可以提高内存性能。典型值:DDR5 中 tRC 一般为 54ns、60ns、66ns。
图示:
行激活 ------- (tRC) ------- 行关闭
7. tWR(Write Recovery Time)
定义:完成一次写入操作后,再次进行写入所需的时间。影响:较低的 tWR 值可以提高写入速度。典型值:DDR5 中 tWR 一般为 30ns 左右。
图示:
写入操作 ------- (tWR) ------- 再次写入准备
8. tRFC(Refresh Cycle Time)
定义:完成一次刷新操作所需的时间。影响:较低的 tRFC 值可以提高内存的刷新效率,保持数据完整性。典型值:DDR5 中 tRFC 一般在 100-300ns 之间。
图示:
刷新操作 ------- (tRFC) ------- 完成刷新
9. 小结
| 参数 | 描述 | 典型值 |
|---|---|---|
| CL | CAS 延迟 | 36, 40, 46 |
| tAA | 地址到第一个数据访问的延迟时间 | 相关于 CL 值 |
| tRCD | RAS 到 CAS 的延迟 | 18ns, 20ns, 22ns |
| tRP | 行预充电时间 | 18ns, 20ns, 22ns |
| tRAS | 行激活时间 | 36ns, 40ns, 44ns |
| tRC | 行周期时间 | 54ns, 60ns, 66ns |
| tWR | 写入恢复时间 | 约 30ns |
| tRFC | 刷新周期时间 | 100-300ns |
10. 总结
通过这些时序参数的优化,DDR5 内存能够提供更高的性能和更低的延迟,满足现代计算需求的不断增长。在设计内存系统时,这些参数的选择与调整将直接影响系统的性能和稳定性。
下面将对黑芝麻智能驾驶芯片方案中的DDR5内存引脚定义进行逐个详细说明,并举例说明每个参数的实际应用。
1. CK_t 和 CK_c(时钟信号)
描述:时钟信号是DDR5内存工作的重要信号,用于同步数据传输。
举例:假设黑芝麻芯片在处理来自四个摄像头的视频流时,每个摄像头的输出频率为30 FPS(帧每秒)。时钟信号CK可以设定为2.6 GHz,使得每个时钟周期可以同步处理数据,确保在每个时钟周期内,视频帧的数据能够被正确地读取和写入。
2. CS_n(片选信号)
描述:片选信号用于启用或禁用内存芯片。
举例:在多Rank设计中,黑芝麻芯片可能会有多个DDR5模块。CS_n信号用于控制特定的内存模块。例如,当CS_n为低电平时,控制器选择使用Rank 0的DDR5模块进行数据处理,当CS_n为高电平时,该模块不响应。这样可以在多模块环境中灵活地选择内存。
3. DM_n, DMU_n, DML_n(输入数据掩码)
描述:数据掩码信号用于在写数据时忽略特定的数据位。
举例:在一次写操作中,如果只需要更新某个数据字的前四个比特,而后四个比特保持不变,可以将DM信号设置为低电平(如“00001111”)。在这种情况下,只有前四个比特会被写入内存,其余比特会被忽略。
4. CA[13:0](命令地址输入信号)
描述:命令地址信号用于传输内存命令和地址信息。
举例:假设需要访问内存地址0x0000000A的数据,CA信号会编码这个地址。当黑芝麻芯片需要读取此地址的数据时,控制器将相应的CA信号发送给DDR5内存,内存模块就可以根据地址返回正确的数据。
5. RESET_n(复位信号)
描述:复位信号用于初始化内存状态。
举例:在系统启动时,RESET_n信号被拉低,DDR5内存会被复位,所有内部寄存器和状态将被清空,以确保系统以已知状态启动。这可以避免因先前操作留下的状态影响新任务的执行。
6. DQ(数据信号)
描述:数据信号用于数据的双向传输,宽度取决于芯片配置(如x4、x8、x16)。
举例:如果黑芝麻芯片的DDR5内存配置为x8(每次传输8位数据),那么DQ信号将包括8条数据线。在一次数据传输中,芯片可能会通过DQ信号将8位数据(如一个像素的RGB值)发送给控制器。
7. DQS_t, DQS_c(数据选通信号)
描述:数据选通信号用于标记数据的有效传输。
举例:在黑芝麻芯片的DDR5内存中,对于每8位数据,会有一条DQS信号。例如,在一个时钟周期中,DQS信号为高电平时,表示DQ数据线上的数据有效,可以进行读取或写入操作。
8. TDQS_t, TDQS_c(终结数据选信号)
描述:对于多条DQS信号,TDQS用于处理多余的DQS信号。
举例:在黑芝麻芯片中,如果配置为x16模式(16位数据),则需要两个DQS信号。多余的TDQS信号将被用于结束某些不再需要的DQS信号,从而优化内存的信号完整性。
9. ALERT_n(告警信号)
描述:用于通知内存控制器发生错误或状态变化。
举例:如果在传输过程中启用了CRC校验并检测到错误,ALERT_n信号将被拉低,通知黑芝麻芯片的内存控制器进行错误处理。这可以确保系统的可靠性。
10. MIR(地址引脚镜像功能)
描述:用于实现命令地址引脚的互换,方便布局布线。
举例:在设计黑芝麻芯片的PCB时,可能由于空间限制需要将某些地址引脚互换。通过MIR引脚,用户可以选择是否使用这个功能,从而灵活设计硬件。
11. CAI(命令地址信号翻转)
描述:用于优化信号传输的电流消耗。
举例:如果黑芝麻芯片在某个操作中主要传输逻辑0,CAI引脚将被拉高,指示系统翻转信号,减少总线的电流消耗。这可以提升能效,延长电池寿命。
12. CA_ODT(命令地址信号ODT引脚)
描述:控制内存的ODT(On-Die Termination)功能。
举例:在黑芝麻芯片的DDR5内存中,CA_ODT引脚可以通过高电平激活ODT功能,优化数据传输的稳定性和速度。在读取大量数据时,这能降低信号反射,提高数据传输的完整性。
13. LBDQ 和 LBDQS(环回数据输出信号)
描述:用于测试或训练功能的环回输出。
举例:在芯片的测试模式下,LBDQ将输出接收到的数据信号状态,而LBDQS则输出对应的DQS信号状态。这可以帮助工程师验证信号的完整性和时序,确保内存正常工作。
14. TEN(互联测试模式的使能引脚)
描述:用于启用互联测试模式。
举例:在芯片测试过程中,通过将TEN引脚拉高,黑芝麻芯片将进入互联测试模式,工程师可以测试不同的信号传输和功能是否正常,以确保芯片的可靠性。
15. RFU 和 NC(保留信号和未使用信号)
描述:RFU(保留信号)用于未来扩展,NC(未使用信号)是未连接的信号。
举例:在设计时,RFU可以留作未来可能需要的功能,而NC引脚在电路板上未连接,也不影响当前的功能实现。
16. VDDQ、VSSQ、VDD、VSS、VPP、ZQ(电源和地信号)
VDDQ:数据信号供电(1.1V),提供DQ信号的电源。
VSSQ:数据信号地,提供DQ信号的接地。
VDD:内存供电(1.1V),为整个DDR5模块供电。
VSS:内存地,连接到系统地。
VPP:DRAM激活电源(1.8V),用于激活内存芯片。
ZQ:用于内部电阻校准,以确保信号的稳定性。
举例:在黑芝麻芯片的电源管理设计中,所有这些电源和地引脚需要按照规格连接,以确保内存模块正常工作。VDDQ和VDD提供稳定的电源,有助于降低延迟和提高内存性能。
总结
通过以上详细的引脚定义和实际应用示例,我们可以看到DDR5内存在黑芝麻智能驾驶芯片方案中的重要性。每个引脚和参数的功能都对整体系统性能和可靠性至关重要。这种设计确保了高效的内存访问和数据处理能力,以满足现代智能驾驶和自动驾驶应用的需求。
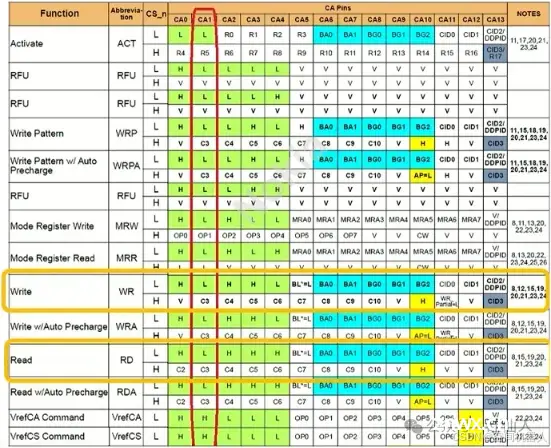
DDR5内存的双周期命令(2-cycle command)是该标准的一项重要新特性,显著提升了命令和地址线的使用效率。以下是对这一特性的详细说明及其带来的好处。
DDR5双周期命令的特点
命令时序优化:
在DDR5中,命令可以分为单周期命令和双周期命令。单周期命令通常只需要一个时钟周期,而双周期命令则需要两个时钟周期来完成。由于DDR5的时钟频率是DDR4的两倍,双周期命令的执行时间与DDR4的单周期命令大致相同,这种设计使得DDR5在命令效率上得到了很好的平衡。
地址线使用效率:
DDR5引入了14根命令地址线(CA[13:0]),可以通过双周期命令的方式将这些线的有效位扩展到28位。这意味着DDR5可以在相同数量的引脚上提供更丰富的命令集,减少了对额外引脚的需求。例如,在执行复杂命令(如刷新、写入等)时,DDR5可以利用双周期命令传输更多的信息,减少了总线占用率。
双周期命令的指示:
DDR5使用CA1引脚来区分单周期命令和双周期命令。当CA1信号为低电平时,表示接下来的命令为双周期命令;当CA1为高电平时,表示为单周期命令。这种机制可以确保内存控制器准确识别命令类型,从而正确处理命令。
双周期命令示例
以下是一些双周期命令的示例及其操作:
刷新命令(REFRESH):
双周期命令可以有效处理内存的刷新操作,以确保数据的持久性。在命令序列中,第一周期CA1为低,指示内存控制器准备执行刷新操作,而第二周期则实际执行该操作。
写入命令(WRITE):
使用双周期命令,用户可以在第一次命令中指定目标地址,在第二次命令中传输数据。这种方式减少了数据传输的延迟,并提高了效率。
读取命令(READ):
读取操作同样可以采用双周期命令,在第一次命令中指定地址,第二次命令传输数据。这使得内存能够在高频率下快速响应读取请求。
引脚镜像的考虑
在引脚镜像设计中,由于命令地址引脚的互换必须遵循特定的规则,因此在设计PCB时,需要确保引脚的布局和连接符合DDR5的要求,尤其是在处理双周期命令时。这样可以避免因引脚位置互换而引发的信号干扰和时序问题,确保内存的稳定性和可靠性。
总结
DDR5的双周期命令特性显著提高了内存控制的灵活性和效率,特别是在高数据吞吐量的应用场景下。这种设计不仅优化了引脚的使用,还充分利用了DDR5更高的时钟频率,从而提高了系统整体性能。这一特性在智能驾驶、深度学习等对内存性能要求极高的应用中尤为重要,能有效支持黑芝麻等智能芯片的需求。
DDR5新特性:Channel 和 Rank
1. Channel 的定义和结构
Channel:DDR5内存控制器的结构分为两个子通道(Channel),每个Channel的位宽为32位。这种设计允许内存控制器更高效地管理数据流,提高数据传输速率。位宽与ECC:
如果支持边带ECC(Error Correction Code),每个子通道可以扩展到40位宽,具体为32位数据+8位ECC校验码。尽管32位数据需要6位校验码,但由于DDR芯片的位宽必须是4的倍数,因此ECC使用8位来提高容错能力。
2. Rank 的定义
Rank:Rank是指内存芯片的逻辑分组。一个Rank可以视为一个独立的内存阵列,内存控制器通过片选信号(CS)选择特定的Rank进行读写操作。时钟信号:不同的Rank使用不同的时钟信号(CK),这意味着在同一Channel中,如果有多个Rank,每个Rank的操作可以在其专用的时钟信号下进行。
示例说明
64位DDR5内存控制器:
这个控制器被分为两个32位的Channel(Channel A和Channel B)。每个Channel独立处理其数据和控制信号。假设每个Channel连接了两个Rank(Rank 0和Rank 1),则在内存控制器中会有两个片选信号(CS0和CS1)和两个时钟信号(CK0和CK1)。这种设计提高了内存带宽和访问速度。
ECC功能:
如果启用边带ECC,则整个系统需要80位的位宽(64位数据+16位ECC),这意味着在进行数据传输时,不仅要考虑数据位,还要考虑ECC位。
DDR5新特性:Prefetch/Burst Length
1. 预取(Prefetch)
Prefetch 增加:
DDR5的预取长度提高到了16N,而DDR3和DDR4的预取长度均为8N。这意味着DDR5在每个读取周期中可以预取更多的数据,从而提高内存的吞吐量。
2. 突发长度(Burst Length)
Burst Length:
DDR5的默认突发长度为16(BL16),允许在单个内存访问中读取16个数据单元。为了适应不同的应用需求,DDR5还支持可选的突发长度:
BC8 OTF(On The Fly):允许在运行时动态改变突发长度。BL32:可选择使用32位的突发长度。BL32 OTF:同样支持动态改变到32位的突发长度。
模式寄存器配置:
突发长度可以通过模式寄存器MR0中的OP0和OP1位进行配置,以便适应不同的系统需求和性能要求。
总结
DDR5通过引入Channel和Rank的结构,使内存控制器能够更高效地管理数据传输,同时支持边带ECC来增强数据可靠性。此外,提升的预取和突发长度特性也大幅提高了内存带宽和访问速度,使其更适合高性能计算和智能驾驶等领域的应用。例如,在黑芝麻智能驾驶芯片方案中,这些特性可以确保快速且可靠的数据处理,从而满足实时处理和决策的要求。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。