linux文本命令:文本处理工具awk详解
威迪斯特 2024-09-06 15:37:01 阅读 91
目录
一、概述
二、基本语法
1、awk 命令的基本语法
2、常用选项
3、获取帮助
三、工作原理
四、 功能特点
五、分割字段
六、 示例
1. 打印所有行
2. 计算总和
3. 过滤特定模式
4. 使用多个模式
5. 复杂的脚本
6. 自定义分隔符
7. 打印指定列
8. 使用 BEGIN 和 END 块
9. 内置变量
10. 使用外部变量
11. 复杂的条件表达式
七、进阶用法
1、记录匹配
2、数组
3、函数
一、概述
<code> awk 是 Linux 和 Unix 系统上一个非常强大的文本处理工具,它能够对文本和数据进行复杂的处理和分析。awk 的名称来源于其三位创始人的名字首字母:Alfred Aho、Peter Weinberger 和 Brian Kernighan。最初为 Unix 系统设计,后来被移植到包括 Linux 在内的多种操作系统中。它非常适合用于格式化输出、数据提取和简单的报告生成任务。
awk 设计之初是为了在文本文件中查找和替换文本,但它现在已经发展成为一个完整的编程语言,能够进行模式匹配和复杂的文本处理。
二、基本语法
1、awk 命令的基本语法
Awk [options] 'pattern {action}' [filename]
- pattern: 用于匹配输入行中的模式。可以是正则表达式、条件表达式或布尔表达式。
- {action}: 当模式匹配成功时,需要执行的命令或语句,可以是内置的 awk 命令,也可以是自定义的代码块。
- [filename]: 指定要处理的文件名。如果省略,则默认从标准输入读取。
2、常用选项
如下为常用选项:
-F fs 或 --field-separator=fs: 设置字段分隔符。-v var=val 或 --assign=var=val: 定义变量及其初始值。-f script-file 或 --file=script-file: 从文件中读取 awk 脚本。-i inplace 或 --inplace: 直接在原文件上修改。-n 或 --non-decimal-data: 允许非十进制数被识别。-W interactive 或 --interactive: 以交互模式运行。
3、获取帮助
在命令行中输入指令:
awk -h
出现如下图所示的帮助信息:
三、工作原理
awk 按行处理文本文件,默认使用空格作为字段分隔符,将每一行分割成多个字段,并使用 $1, $2, … $n 来引用这些字段。其中 $0 代表整行文本。
四、 功能特点
awk具有很多功能,主要有如下特点:
1. 模式匹配: awk 可以根据指定的模式来选择处理哪些行。
2. 字段分割: 输入行可以按照分隔符自动分割成多个字段。
3. 变量: awk 支持变量的定义和使用。
4. 流程控制: 包括条件语句(如 if, else)和循环语句(如 for, while)。
5. 数学函数和字符串函数: 提供了丰富的内置函数支持数学运算和字符串操作。
6. 用户自定义函数: 用户可以定义自己的函数以扩展 awk 的功能。
五、分割字段
awk 默认使用空格作为字段分隔符,但可以通过 -F 或 --field-separator 选项指定其他字符:
awk -F: '{print $1}' /etc/passwd
这会打印 /etc/passwd 文件中每个条目的第一个字段(用户名),其中字段是以冒号 : 分隔的。如下所示:
<code>[root@ecs-52a1 /]# awk -F: '{print $1}' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
games
ftp
nobody
systemd-network
dbus
polkitd
postfix
sshd
chrony
tcpdump
[root@ecs-52a1 /]#
六、 示例
1. 打印所有行
awk '{print}' file.txt
2. 计算总和
awk '{sum += $1} END {print sum}' numbers.txt
3. 过滤特定模式
awk '/pattern/ {print}' file.txt
4. 使用多个模式
awk '/pattern1/ || /pattern2/ {print}' file.txt
5. 复杂的脚本
如下为脚本代码:
awk '
BEGIN {print "Start of the file"}
/pattern1/ {print "Found pattern1"}
/pattern2/ {print "Found pattern2"}
END {print "End of the file"}
' file.txt
6. 自定义分隔符
awk -F, '{print $1, $3}' data.csv
7. 打印指定列
假设文件 data.txt 内容如下:
Name Age City
John 30 New York
Doe 25 Los Angeles
要打印每行的第二列(即年龄),使用如下命令:
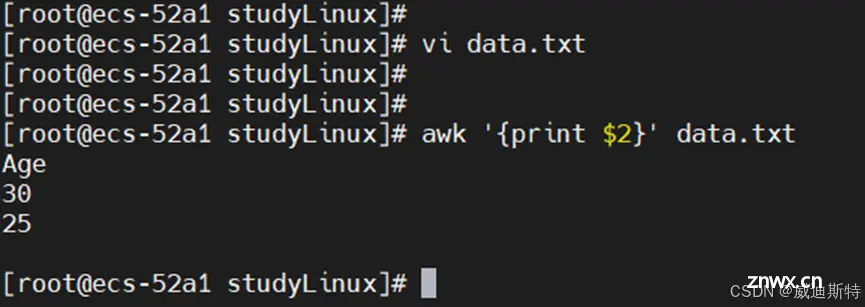
awk '{print $2}' data.txt
输出:
Age
30
25
注意,$0 表示整行,$1 表示第一列,以此类推。
实际操作如下图:

8. 使用 BEGIN 和 END 块
BEGIN 块在读取任何输入行之前执行,END 块在读取完所有输入行之后执行。
awk 'BEGIN {print "Start"} {print} END {print "End"}' filename
9. 内置变量
awk 有许多内置变量,如 NR(当前记录号,即行号)、NF(当前记录的字段数,即每行的列数)等。
打印每行的行号和每行的字段数:
awk '{print NR, $0, NF}' filename
10. 使用外部变量
可以在 awk 命令中通过 -v 选项设置外部变量。
awk -v var="Hello" 'BEGIN {print var}'
11. 复杂的条件表达式
awk 支持复杂的条件表达式,包括正则表达式匹配。
awk '/John/ {print $0}' filename
这会打印所有包含 "John" 的行。
七、进阶用法
1、记录匹配
使用 NR 记录总数,FNR 当前文件的记录数。
可以使用如下命令记录文件的行数
awk 'END{print NR}' file.txt
2、数组
可以使用数组存储和处理数据,可以进行复杂的数据处理。
awk '{name[$1] = $2} END {for (i in name) print i, name[i]}' filename
这个命令会创建一个以名字为键,年龄为值的数组,并在结束时遍历并打印它。
3、函数
可以定义和调用用户自定义函数。
文章正下方可以看到我的联系方式:鼠标“点击” 下面的 “威迪斯特-就是video system 微信名片”字样,就会出现我的二维码,欢迎沟通探讨。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。