【Linux】线程同步
YoungMLet 2024-06-18 11:07:09 阅读 65
线程同步
一、条件变量1. 同步概念2. 条件变量概念3. 条件变量接口(1)pthread_cond_init()(2)pthread_cond_destroy()(3)pthread_cond_wait()(4)pthread_cond_signal()(5)pthread_cond_broadcast()(6)使用接口 二、生产者消费者模式1. 概念2. 生产者消费者模式优点3. 基于 BlockingQueue 的生产者消费者模型 三、POSIX 信号量1. 回顾信号量2. POSIX 信号量接口(1)sem_init()(2)sem_destroy()(3)sem_wait()(4)sem_post() 3. 基于环形队列的生产消费模型(1)环形队列(2)原理(3)代码实现 四、线程池五、其他常见的锁六、读者写者问题1. 读写锁2. 读写锁接口
一、条件变量
1. 同步概念
同步问题是保证数据安全的情况下,让线程访问资源具有一定的顺序性,从而有效避免饥饿问题,叫做同步。
2. 条件变量概念
所以怎么才能让线程按照一定的顺序去访问资源呢?也就是同步的解决方案是什么呢?这个解决方案在 Linux 中称为条件变量。
什么叫做条件变量呢?以前我们使用的纯加锁的时候,没有申请到加锁的线程,就直接阻塞挂起了,这个场景为纯互斥场景,也就是线程没有顺序地执行的,谁能申请到锁谁就能得到资源。而条件变量就是可以做到让线程在一个等待队列中按照顺序等待,按照它们到来的先后顺序进入队列等待,前提是这些线程都是申请锁失败的,因为是要保证资源安全的情况下。而且,在资源就绪的时候,也就是有线程释放锁后,这个条件变量还需要提供一种通知机制,唤醒一个或者全部队列中的线程,让队头的线程去访问资源。这就是条件变量。
例如一个线程访问队列时,该队列为共享资源,发现队列为空,它只能等待,直到其它线程将一个节点添加到队列中。这种情况就需要用到条件变量。
3. 条件变量接口
(1)pthread_cond_init()
初始化条件变量的接口:
int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr);
其中第一个参数类型,也是 pthread 库给我们提供的数据类型,我们先要定义一个这样类型的条件变量,也就是要初始化的条件变量。第二个参数是属性,我们设为空即可。
条件变量的初始化和互斥锁的初始化类似,也可以定义一个全局的条件变量,用法也一样,全局或静态的条件变量可以不用初始化和释放。定义全局的条件变量如下:
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
(2)pthread_cond_destroy()
释放条件变量:
int pthread_cond_destroy(pthread_cond_t *cond);
(3)pthread_cond_wait()
申请锁失败或者等待条件满足时,加入等待队列中:
int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex);
第一个参数就是我们初始化的条件变量;第二个参数是一把锁,我们后面再介绍。
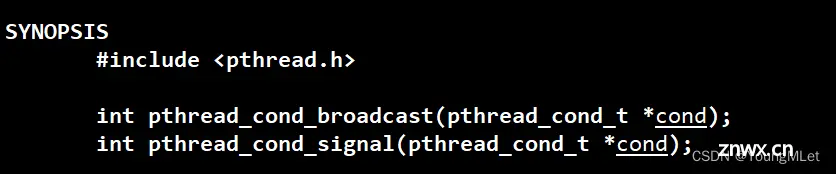
(4)pthread_cond_signal()
唤醒一个线程的接口:
int pthread_cond_signal(pthread_cond_t *cond);
(5)pthread_cond_broadcast()
唤醒所有线程:
int pthread_cond_broadcast(pthread_cond_t *cond);
(6)使用接口
下面我们将上面的接口和互斥接口一起使用起来。我们知道,当多个线程向显示器上打印时,其实就是多个线程访问同一个共享资源,此时如果不加锁,打印出来的信息就是乱的。现在我们就模拟这个场景,对显示器这个共享资源加锁,并添加条件变量实现同步。
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;pthread_cond_t cond = PTHREAD_COND_INITIALIZER;int cnt = 0;void* func(void* args){ pthread_detach(pthread_self()); uint64_t i = (uint64_t)args; while(1) { pthread_mutex_lock(&lock); // pthread_cond_wait 让线程加入等待队列的时候,会自动释放锁 pthread_cond_wait(&cond, &lock); cout << "pthread: " << i << ", cnt: " << cnt++ << endl; pthread_mutex_unlock(&lock); } return nullptr;}int main(){ for(uint64_t i = 0; i < 5; i++) { pthread_t tid; pthread_create(&tid, nullptr, func, (void*)i); } // 让主线程唤醒等待队列中的队头线程 while(1) { sleep(1); pthread_cond_signal(&cond); } return 0;}
结果如下,我们发现每一个线程都是按照顺序去访问资源的,即使是刚释放锁的线程,也会加入等待队列的队尾重新等待下一轮资源访问:
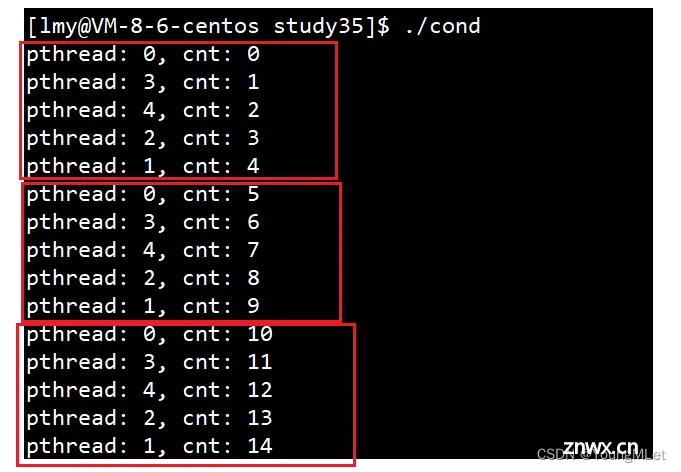
注意,条件变量的等待需要放在加锁的后面,因为需要保证数据安全的前提,那么加锁后加入等待队列,不会形成死锁吗?不会,因为 pthread_cond_wait(&cond, &lock); 也把锁传进来了,它会帮线程自动释放锁!
所以未来如果我们需要对共享资源加以判断条件判断资源是否就绪,我们就可以把 pthread_cond_wait(&cond, &lock); 放在判断条件里面,如果资源不就绪,就将线程加入等待队列中,再让正在访问资源的线程访问完资源后唤醒线程。
二、生产者消费者模式
1. 概念
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的,也就是将生产和消费的行为进行解耦!
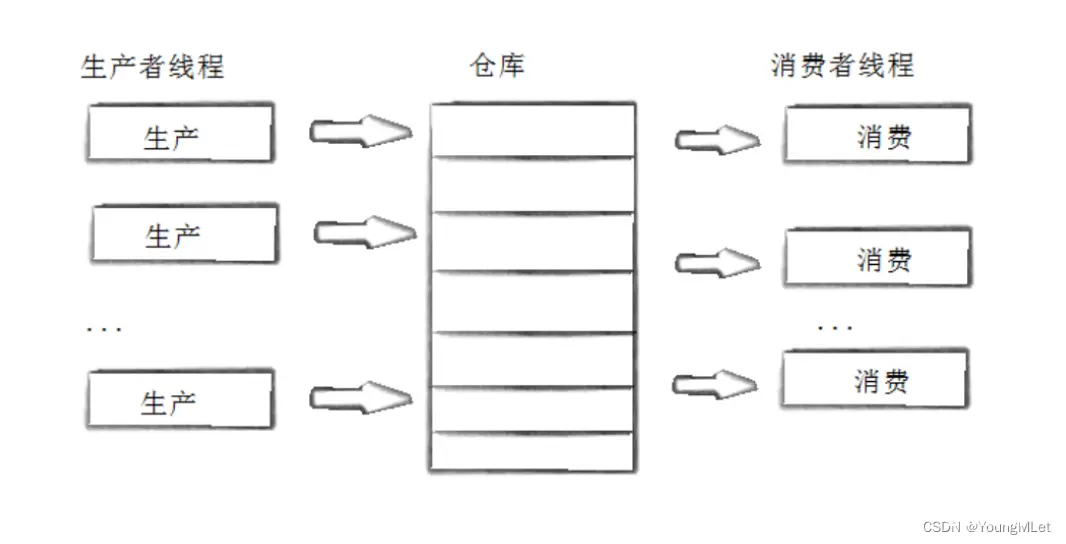
所以生产者消费者模型会有三种关系,分别是:
生产者和生产者,它们之间是互斥关系生产者和消费者,它们之间是互斥和同步的关系消费者和消费者,它们之间是互斥关系
除此之外,生产者消费者模型的两中角色分别是生产者和消费者,还有一个特定结构的内存空间。
2. 生产者消费者模式优点
生产者和消费者进行解耦支持并发支持忙闲不均,也就是可以将生产者的数据缓存起来,当消费者需要数据的时候直接去这个“仓库”拿即可3. 基于 BlockingQueue 的生产者消费者模型
在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)。
下面我们使用代码实现这个模型,代码链接:基于 BlockingQueue 的生产者消费者模型.
下面我们对上面的代码中的几个细节分析一下:
判断临界资源条件是否满足,也是在访问临界资源,所以判断条件需要在加锁和解锁之间,即通过在临界区内部判断的。如果资源不就绪,就去条件变量中按顺序等待,在条件变量中等待时,会自动释放锁,当被唤醒时,就会重新持有锁!在多线程情况下,假设现在的 _capacity 是满的,然后有多个生产线程想要生产数据,发现资源不就绪,即现在 _q.size() == _capacity ,然后这批生产线程要去条件变量中等待,被释放锁。此时,一个消费线程消费了一个资源,然后唤醒生产线程,注意 pthread_cond_signal(&c_cond); 也不一定是只唤醒一个线程,有可能会唤醒多个!假设此时生产线程的条件变量中有多个线程被唤醒,此时它们的条件变量就被破环了,它们都要去申请锁,形成了互斥,而资源的空间只有一个,一个生产线程填上这个资源空间后,此时空间就满了,然后唤醒消费线程。如果剩下的被误唤醒的生产线程竞争锁的能力比较强的话,消费线程由于抢不到锁,导致生产线程继续生产数据,但是此时资源空间已经满了,继续生产的话会溢出资源!这就是伪唤醒的情况!所以我们在判断条件时,不能用 if 语句判断,要用 while 循环判断!我们实现的代码中,生产者的数据从哪里来的呢?生产者生产的数据是我们自己随便定义的,但是在实际场景中,生产数据是需要时间的!那么消费者拿到数据之后需要干嘛呢?需要处理数据!处理数据也是需要时间的!所以实际上,生产者消费者模型,生产者和消费者分别有两个步骤!如下图:
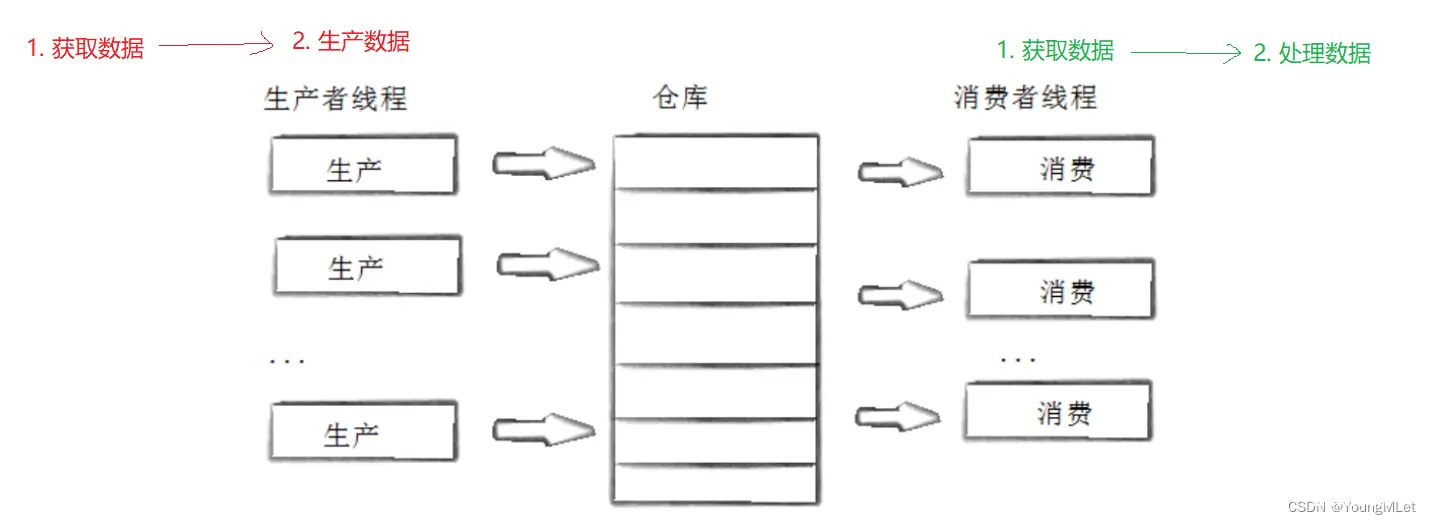
有人说生产者消费者模型是高效的,为什么高效呢?我们上面列的优点中并没有说高效呀。我们知道,生产和消费的过程是要加锁的,所以整个在访问这个“仓库”的时候,生产和消费本身就是串行的,如果我们单单看到这个过程,确实没有高效的体现。那么如何体现高效呢?如果消费者当前正在消费数据(获取数据),生产者虽然没有办法直接生产数据,但它可以正在获取数据!反过来,如果生产者当前持有锁,往“仓库”里生产数据,而消费者此时可以处理数据!所以我们在生产者消费者模型中,引入生产者生产数据需要时间,消费者处理数据也要花时间,那么就会存在非常大的概率,生产者正在生产数据,消费者不获取数据,而正在处理数据,反过来也一样!也就是说,一个正在访问临界区代码,一个正在访问非临界区代码,这时候生产和消费线程就是在高效并发访问!
三、POSIX 信号量
1. 回顾信号量
我们上面生产者消费者模型的代码中,我们的 queue 是一个共享资源,它被当作一个整体来使用,这个 queue 只有一份,所以需要加锁。但是共享资源也可以被看作多份的!
其实 POSIX 信号量 和我们以前学的 SystemV 信号量 是一样的。它们的作用相同,都是用于同步操作,达到无冲突的访问共享资源目的。 但 POSIX 可以用于线程间同步。
我们一句话总结以前学的信号量,信号量是一个保证 PV 操作的原子性的一把计数器。那么这把计数器的本质是什么呢?是临界资源的数量!所以,有了 PV 操作,就不需要在临界区之间判断临界资源是否就绪了!因为只要一个线程 P 操作申请成功了,这个线程就一定能访问资源,因为 P 操作就是对资源的预定机制!如果申请不成功的,就要去信号量中去等待了!
2. POSIX 信号量接口
(1)sem_init()
初始化信号量:
int sem_init(sem_t *sem, int pshared, unsigned int value);
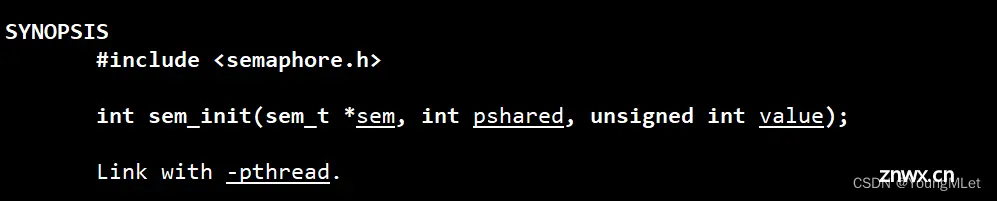
其中,sem_t 是给我们提供的类型;第一个参数 pshared,表示线程还是进程共享,0 表示线程间共享,非零表示进程间共享;第二个参数 value 表示信号量初始值。
(2)sem_destroy()
销毁信号量:
int sem_destroy(sem_t *sem);
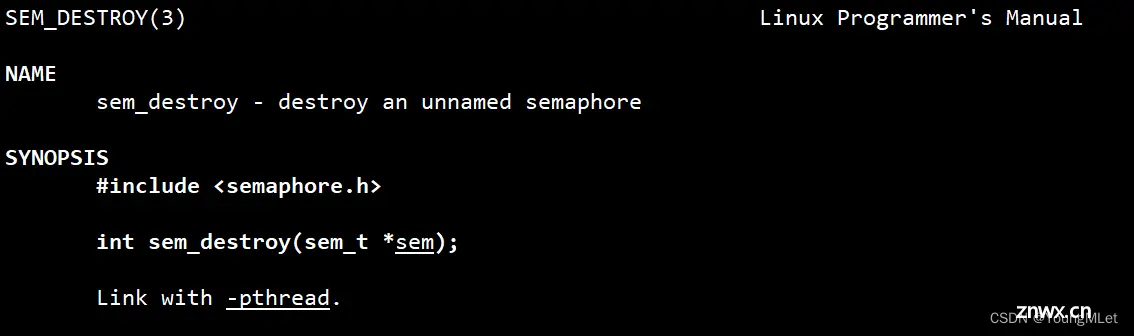
(3)sem_wait()
等待信号量,会将信号量的值减1,即 P() 操作:
int sem_wait(sem_t *sem);
(4)sem_post()
发布信号量,表示资源使用完毕,可以归还资源了,将信号量值加1;即 V() 操作:
int sem_post(sem_t *sem);
3. 基于环形队列的生产消费模型
(1)环形队列
环形结构起始状态和结束状态都是一样的,不好判断为空或者为满,也就是空或者满的时候,head 和 tail 都是指向同一个位置。
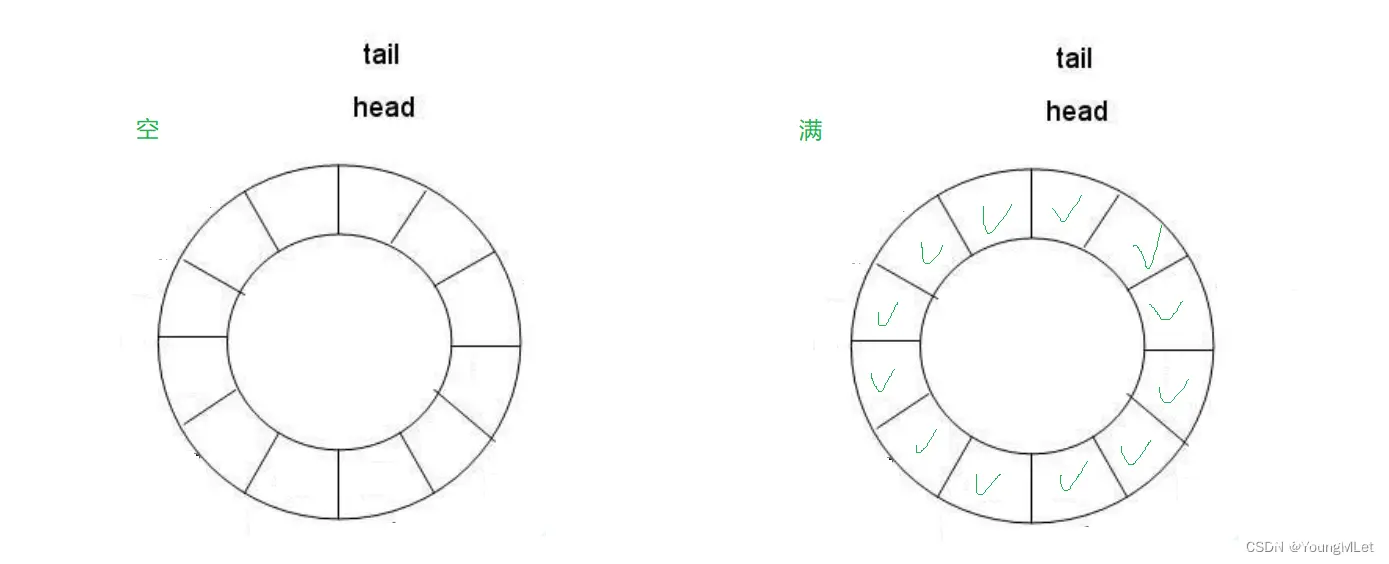
所以可以通过加计数器或者标记位来判断满或者空。另外也可以预留一个空的位置,作为满的状态。例如使用第二种方法判空还是满:
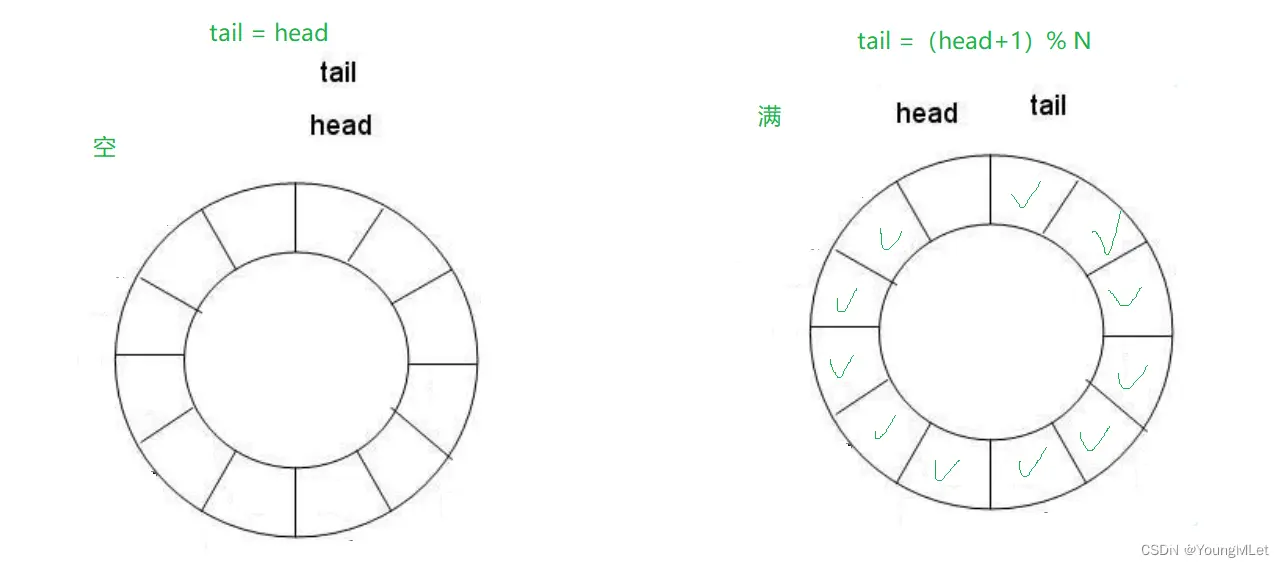
(2)原理
但是我们现在有信号量这个计数器,就很简单的进行多线程间的同步过程,就不需要进行判空还是判满了。
我们在环形队列中引入生产者和消费者模型,这些多线程就要在一个环形队列中进行生产和消费的动作,所以生产者和生产者,消费者和消费者,必须都是各自互斥,生产和消费也必须有互斥和同步的关系。当生产者线程和消费者线程在访问环形队列的时候,只要生产和消费线程不访问同一个格子资源,那么生产的同时也在消费,消费的同时也在生产!
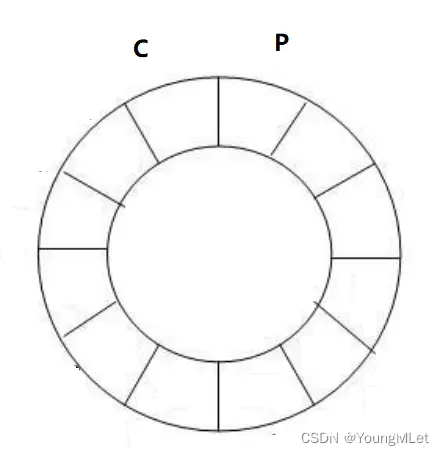
那么什么情况才会指向同一个位置呢?空或者满!也就是说,在不空和不满的时候,它们一定指向不同的位置,它们可以同时访问!所以为空的时候,只能由生产者线程运行,满的时候,只能由消费者线程运行。而且当消费者不消费的时候,生产者不能超过消费者一圈!反过来,生产者不生产的时候,消费者不能超过生产者!
那么怎么用代码的方式保证上面的方式正常运行呢?下面就需要引入信号量了。信号量的本质是用来描述它所关注的资源的数量的,作为生产者线程,它关注的是环形队列中还有多少剩余空间;作为消费者线程,它关注的是环形队列中还有多少剩余数据。所以我们可以定义两个信号量,一个叫做空间资源信号量:SpaceSem,初始值也就是环形队列的大小 N;另一个叫做数据资源信号量:DataSem,因为一开始环形队列没有数据,所以初始值为 0.
接下来生产者和消费者开始并发运行了,生产者想要生产数据,必须先要进行 P(SpaceSem) 操作,再进行生产;对于消费者线程来说,先要申请数据,进行 P(DataSem) 操作,申请到了就可以消费。在一开始队列为空时,一定是生产者先执行 P(SpaceSem) 操作!因为消费者申请不了数据资源,此时为0;所以即便消费者先被调度,也会因为申请失败会被挂起。那么当一个生产者把数据生产完了,那么数据资源就多了一个,此时生产者线程就可以进行 V(DataSem) 操作,此时生产者已经指向下一个位置了,就可以让消费者来消费!那么当消费者把数据消费了,数据资源就必定少了一个,也就是空间资源就多了一个,此时消费者线程就可以进行 V(SpaceSem) 操作!本质就是申请自己的资源,释放对方的资源,进行并发访问!
(3)代码实现
代码实现的链接:基于环形队列的生产消费模型.
其中代码中的几个细节:
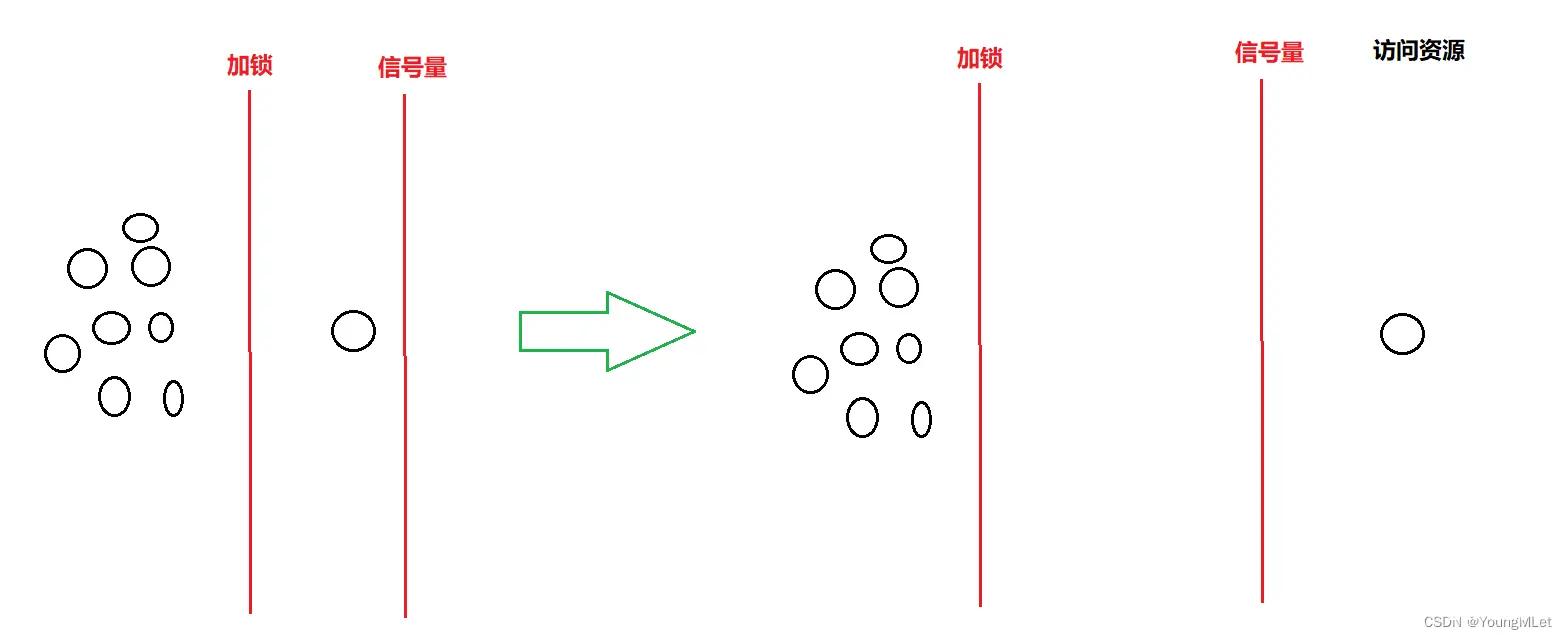
在执行生产线程和消费线程时,它们都是无序的,可能生产线程先调度,可能消费线程先调度,但真正进入代码执行的时候,一开始时,一定只能是生产者先运行!因为一开始只有生产者线程可以 P() 操作成功!只有为空或者为满的情况,生产者和消费者线程指向同一个下标,但是只能有一个线程能够进入环形队列里进行生产或消费!所以,这就是在为空或者为满的时候,表现出来局部性的互斥!为空的时候,代码会维护让生产者先运行;为满的时候,代码会维护让消费者先运行,这就是在指向同一个位置时,在不同的情况下,让生产和消费具有一定的顺序性,这就是局部性的同步!如果不为空而且不为满,那么生产者和消费者的下标一定不一样,所以生产和消费互不影响,它们之间并没有表现出互斥,也就是它们此时正在并发运行。由于生产者和消费者之间的互斥关系已经由信号量维护了,那么在多线程情况下,生产者和生产者之间的互斥关系,消费者和消费者之间的互斥关系,怎么维护呢?由于下标只有一个,所以当多线程申请到信号量时,必然会导致多个线程对一个下标进行访问,所以会引发数据不一致问题,所以这时候需要对下标访问加锁!一共要使用两把锁,一把维护生产者线程之间的互斥关系,另一把维护消费者线程之间的互斥关系!那么加锁是在申请信号量之前还是之后呢?在申请信号量之后!首先,信号量资源是不需要被保护的,因为它的申请是原子的,所以我们不需要给申请信号量加锁。而且,如果我们把加锁放在申请信号量之前,那么申请锁和申请信号量就是串行的,也就是说,只有申请到加锁的线程,才能申请信号量,也就是申请信号量的线程永远都只有一个!在该线程访问资源期间,其它线程也只能在外面等着!如下图:
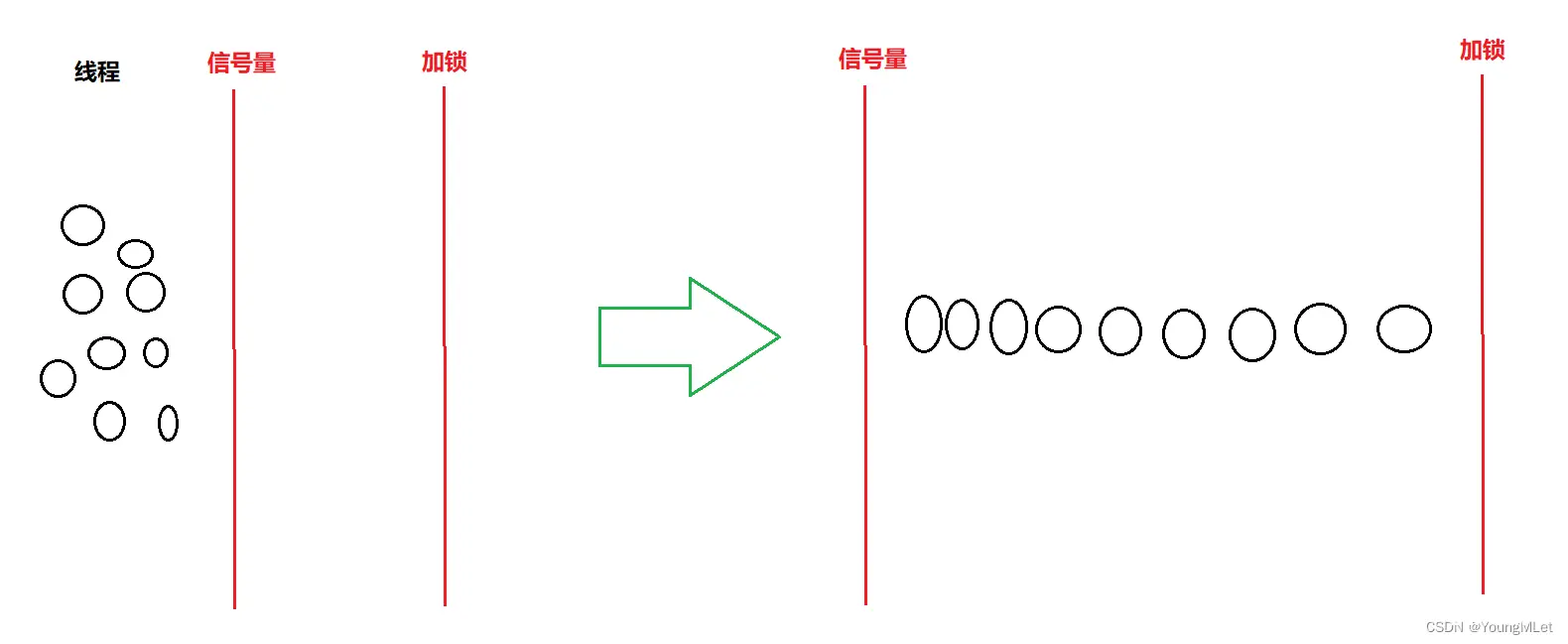
但是如果把加锁放在申请信号量之后,可以在一定程度上,在多线程申请时,在一个线程申请到锁访问期间,其它线程可以申请信号量,让申请信号量和申请锁变成并行的!如下图:
四、线程池
线程池:一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络 sockets 等的数量。
接下来我们简单写一个线程池,示例:创建固定数量线程池,循环从任务队列中获取任务对象;获取到任务对象后,执行任务对象中的任务接口。代码链接:线程池.
五、其他常见的锁
悲观锁:在每次取数据时,总是担心数据会被其他线程修改,所以会在取数据前先加锁(读锁,写锁,行锁等),当其他线程想要访问数据时,被阻塞挂起。也就是互斥锁。乐观锁:每次取数据时候,总是乐观的认为数据不会被其他线程修改,因此不上锁。但是在更新数据前,会判断其他数据在更新前有没有对数据进行修改。主要采用两种方式:版本号机制和CAS操作。CAS操作:当需要更新数据时,判断当前内存值和之前取得的值是否相等。如果相等则用新值更新。若不等则失败,失败则重试,一般是一个自旋的过程,即不断重试。自旋锁:与悲观锁相反,当一个线程在访问资源时,其它线程反复申请锁,直到该线程访问完资源释放锁。所以使用自旋锁一般需要临界资源的访问比较快。自旋锁接口:
初始化和销毁:

加锁

释放锁

六、读者写者问题
1. 读写锁
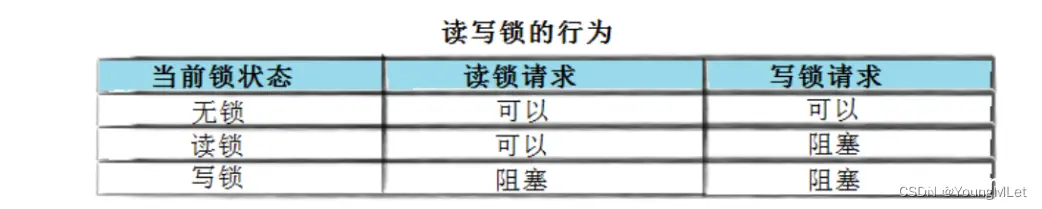
在编写多线程的时候,有一种情况是十分常见的。那就是,有些公共数据修改的机会比较少。相比较改写,它们读的机会反而高的多。通常而言,在读的过程中,往往伴随着查找的操作,中间耗时很长。给这种代码段加锁,会极大地降低我们程序的效率。那么有没有一种方法,可以专门处理这种多读少写的情况呢? 有,那就是读写锁。
2. 读写锁接口
初始化和销毁
加锁

释放锁

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。