Linux之ebpf(1)基础使用
CSDN 2024-06-17 11:07:03 阅读 72
Linux之ebpf(1)基础使用
Author: Once Day Date: 2024年4月20日
一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦…
漫漫长路,有人对你微笑过嘛…
全系列文章可以参考专栏:Linux基础知识_Once-Day的博客-CSDN博客。
参考文章:
eBPF 完全入门指南.pdf(万字长文) - 知乎 (zhihu.com)Linux新技术基石 |eBPF and XDP (qq.com)什么是 eBPF ? An Introduction and Deep Dive into the eBPF Technology聊聊最近很火的eBPF - 知乎 (zhihu.com)BPF and XDP Reference Guide — Cilium 1.15.4 documentationbpf-helpers(7) - Linux manual page (man7.org)
文章目录
Linux之ebpf(1)基础使用1. 概述1.1 eBPF背景介绍1.2 eBPF和cBPF的联系和区别1.3 eBPF架构和限制介绍1.4 eBPF在Linux内核中的应用 2. eBPF特性介绍2.1 eBPF钩子位点(hook)2.2 eBPF字节码验证2.3 eBPF即时编译JIT2.4 eBPF数据映射Maps2.5 eBPF辅助函数Helpers2.6 eBPF尾调用和函数调用2.7 eBPF对象固定(Object Pinning)2.9 eBPF安全增强功能 3. eBPF工具链介绍3.1 BCC(BPF Compiler Collection)3.2 bpftrace3.3 libbpf库 4. eBPF实践(hello world)4.1 eBPF环境搭建4.2 eBPF程序(kern)4.3 eBPF用户空间程序 5. 总结
1. 概述
1.1 eBPF背景介绍
eBPF (extended Berkeley Packet Filter) 是一种先进的技术,允许在无需更改内核源代码或加载内核模块的情况下,以安全的方式动态地在内核中执行预编译和沙箱化的程序。它最初是为了能够在内核层面高效地过滤网络包而设计的,但现在它的用途已经大大扩展,可以用于各种系统级编程任务。
eBPF 是 Berkeley Packet Filter (BPF) 的扩展,BPF 最初是在 1992 年为了提高网络包过滤的效率而引入的。2014 年,eBPF 被引入 Linux 内核,从那时起,它的能力和用途不断扩展。
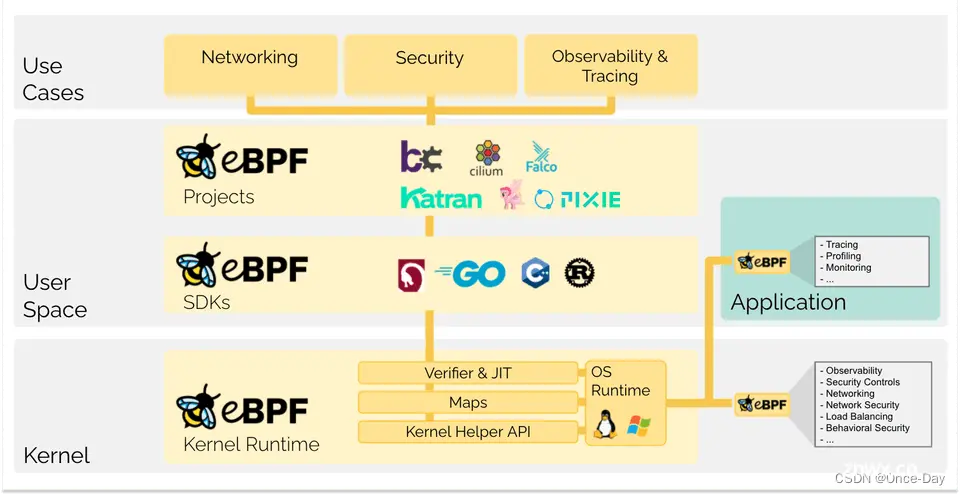
eBPF的核心特性:
性能高效:eBPF 程序运行在内核空间,避免了用户空间和内核空间之间的昂贵上下文切换。安全性:eBPF 程序在执行前会通过一个验证器,确保它们不会破坏系统稳定性或安全性(例如,避免死循环和内存访问错误)。灵活性:eBPF 支持各种类型的程序,包括网络相关的过滤和监控,系统调用的审计和监控,以及性能分析。可编程性:eBPF 提供了一种基础设施,可以在不改变内核代码的情况下,插入自定义的代码片段来扩展内核的功能。工具生态:随着 eBPF 的流行,出现了许多工具和项目(如 BCC, bpftrace, Cilium)来简化编写和部署 eBPF 程序的过程。
eBPF的工作流程:
编写 eBPF 程序:通常使用 C 语言编写,并针对 eBPF 虚拟机的指令集进行编译。加载到内核:编译后的 eBPF 程序通过特定的系统调用被加载到内核。验证:内核中的验证器检查程序是否安全执行(不会崩溃内核或访问不该访问的内存区域)。JIT 编译:为了提高执行效率,内核可以将 eBPF 字节码即时(JIT)编译成本机代码。附加到 Hook 点:eBPF 程序附加到内核的各种 hook 点,例如网络事件、系统调用或其他内核函数。运行:当相关的事件发生时,eBPF 程序将被执行。
eBPF的使用场景:
网络监控与安全:eBPF 可以用来构建高级的网络监控工具,提供防火墙功能,甚至实现高级路由和负载均衡。系统性能分析:eBPF 程序可以收集系统性能数据,帮助开发者进行性能调优。应用监控:可以监控和分析系统上运行的应用程序的行为,如系统调用的使用情况。安全审计:eBPF 可以用来记录系统活动,以便进行事后分析。
随着技术的发展,eBPF 正在成为 Linux 系统监控和管理中不可或缺的工具,它的重要性和应用范围只会不断增长。
1.2 eBPF和cBPF的联系和区别
BPF 最初代表伯克利包过滤器 (Berkeley Packet Filter),但是现在 eBPF(extended BPF) 可以做的不仅仅是包过滤,这个缩写不再有意义了。eBPF 现在被认为是一个独立的术语,不代表任何东西。在 Linux 源代码中,术语 BPF 持续存在,在工具和文档中,术语 BPF 和 eBPF 通常可以互换使用。最初的 BPF 有时被称为 cBPF(classic BPF),用以区别于 eBPF。(来自ebpf.io)
eBPF和cBPF都是Linux内核中用于数据包过滤和处理的技术,但eBPF是cBPF的增强升级版本。它们的主要区别和联系如下:
| eBPF | cBPF | |
|---|---|---|
| 起源 | 于2014年由Alexei Starovoitov实现,是cBPF的升级版。 | 起源于1992年,由Steven McCanne和Van Jacobson提出,旨在提高网络数据包过滤的效率。 |
| 性能优化 | eBPF针对现代硬件进行了优化,生成的指令集比cBPF的解释器生成的机器码执行速度更快。 eBPF将虚拟机中的寄存器数量从cBPF的2个32位寄存器增加到10个64位寄存器,使得开发人员可以更自由地交换信息,编写更复杂的程序。 | 原有实现,无进一步优化。 |
| 功能扩展 | eBPF不再局限于网络栈,已成为内核顶级子系统,可用于性能分析、软件定义网络等多种场景。 | cBPF主要用于网络数据包过滤。 |
| 内核支持 | eBPF最早出现在Linux 3.18内核中。 | 目前Linux内核只运行eBPF,加载的cBPF字节码会被透明地转换成eBPF再执行。 |
| 用户空间支持 | 2014年6月,eBPF扩展到用户空间,标志着BPF技术的重要转折点。 | 在tcpdump等报文过滤场景仍在使用。 |
目前可以使用tcpdump -d "icmp or arp"来查看tcpdump底层使用的cBPF字节码,这些字节码会在Linux内核中透明转换为eBPF表示。如下所示:
onceday->ease-shoot:# tcpdump -d "icmp or arp"Warning: assuming Ethernet(000) ldh [12](001) jeq #0x800 jt 2 jf 4(002) ldb [23](003) jeq #0x1 jt 5 jf 6(004) jeq #0x806 jt 5 jf 6(005) ret #262144(006) ret #0
1.3 eBPF架构和限制介绍
BPF 是一个通用目的 RISC 指令集,其最初的设计目标是:用 C 语言的一个子集编写程序,然后用一个编译器后端(例如 LLVM)将其编译成 BPF 指令,稍后内核再通过一个位于内核中的(in-kernel)即时编译器(JIT Compiler)将 BPF 指令映射成处理器的原生指令(opcode ),以取得在内核中的最佳执行性能。(来自Linux新技术基石 |eBPF and XDP (qq.com))
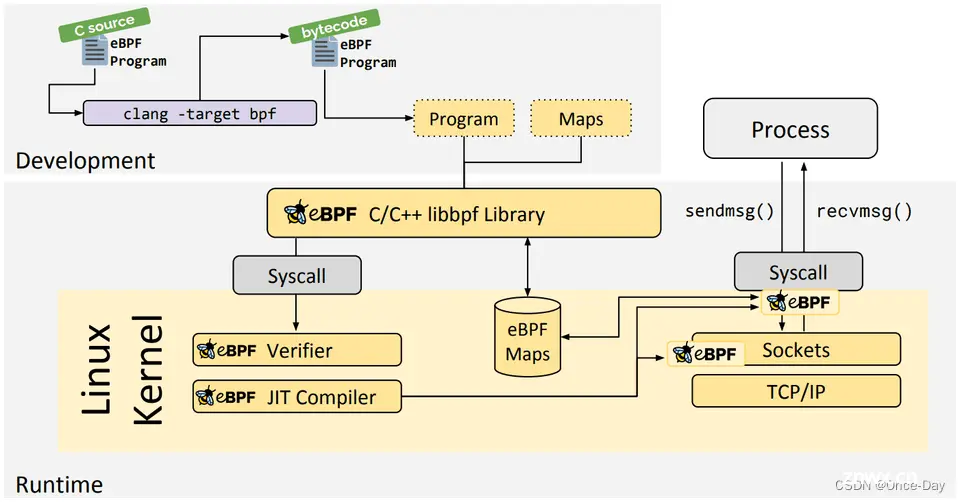
eBPF 的工作流程可以总结如下:
编写阶段:开发者使用 C 语言编写 BPF 程序,包括用户空间程序和内核中的 BPF 字节码程序。编译阶段:使用 LLVM 或 GCC 工具将编写的 BPF 代码编译成 BPF 字节码。加载阶段:用户空间程序使用加载程序(Loader)将编译好的 BPF 字节码加载到内核中。验证阶段:内核中的验证器(Verifier)组件会检查加载的 BPF 字节码的安全性,以确保它不会对内核造成危害。执行阶段:验证通过后,BPF 字节码程序会附加到内核的特定事件或函数上,当事件被触发时,BPF 程序就会在内核中执行。通信阶段:内核中运行的 BPF 程序可以通过两种方式与用户空间程序进行通信: 使用 maps 结构将内核中的统计信息、状态等数据传递给用户空间程序。通过 perf-event 将内核中的事件实时发送给用户空间程序进行分析。 分析阶段:用户空间程序可以读取和分析从内核中传递来的数据,实现对系统的监控、追踪、性能分析等功能。
上述过程中也有一些限制条件:
不能调用任意的内核参数,只限于内核模块中列出的 BPF Helper 函数。不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止。循环次数限制且必须在有限时间内结束,防止锁住整个系统。堆栈大小被限制在 MAX_BPF_STACK(include/linux/filter.h),一般为512字节。字节码大小最初被限制为BPF_COMPLEXITY_LIMIT_INSNS(include/linux/bpf.h)条指令,目前支持一百万条指令。
1.4 eBPF在Linux内核中的应用

eBPF 的设计思想可以总结如下:
灵活性和可编程性:eBPF 提供了一个独立的指令集,允许开发者编写自定义的内核级程序,可以在内核运行时动态加载和执行。
高效性:eBPF 程序在内核中执行,可以直接访问内核数据结构和函数,避免了用户态和内核态之间的上下文切换开销。
安全性:eBPF 引入了验证器机制,确保加载到内核中的 eBPF 程序是安全的,不会对内核造成危害。验证器会对 eBPF 程序进行严格的检查,例如防止无限循环、非法内存访问等。此外,eBPF 还提供了一些安全加固原语,如 helper 函数,用于与内核功能安全地交互。
可扩展性:eBPF 提供了多种机制来扩展其功能。例如,通过 helper 函数,eBPF 程序可以与内核功能交互并利用内核功能;通过尾调用,eBPF 程序可以调用其他 eBPF 程序,实现功能的组合和复用;通过伪文件系统,可以方便地管理 eBPF 对象(如 maps 和程序)。
工具链支持:eBPF 得到了 LLVM 编译器工具链的支持。开发者可以使用 C 语言编写 eBPF 程序,然后使用 clang 等工具将其编译为 BPF 目标文件,再加载到内核中执行。
内核集成:eBPF 与 Linux 内核紧密集成,eBPF 程序可以在不牺牲本机内核性能的情况下,实现完全可编程的功能扩展和优化。
硬件卸载:eBPF 还提供了将其功能卸载到网卡硬件的基础设施,可以进一步提高性能并减轻主机 CPU 的负担。
eBPF 的设计思想围绕着提供一个灵活、高效、安全、可扩展的内核级编程框架,与内核紧密集成,并得到了成熟的工具链支持。
2. eBPF特性介绍
2.1 eBPF钩子位点(hook)
钩子位点是内核中特定的点,eBPF程序可以在这些点“挂载”自己,以便在特定事件发生时执行。预定义的钩子包括系统调用、函数入口/退出、内核跟踪点、网络事件等。通过这些钩子,eBPF能够提供极高的灵活性和强大的监控能力,而且由于它的运行时效率,对系统性能的影响极小。
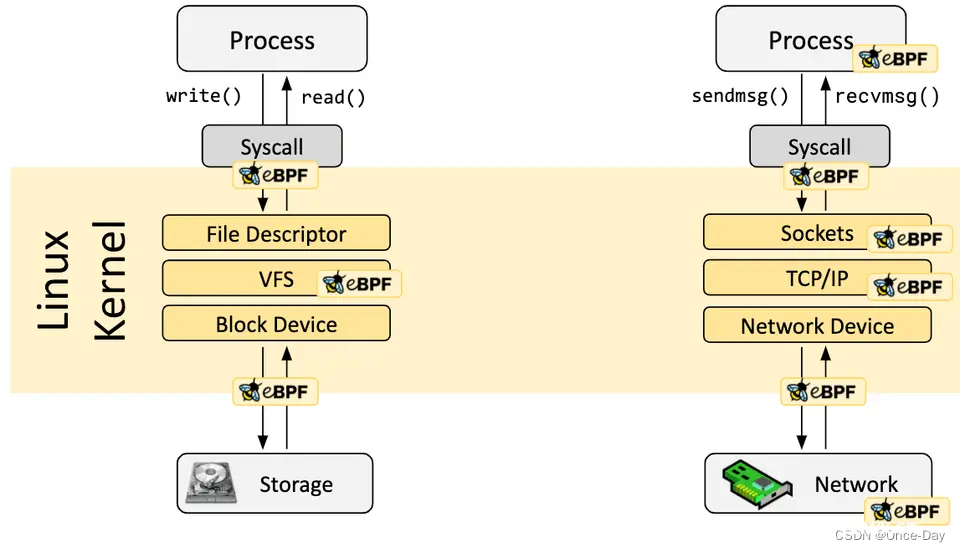
如果预定义的钩子不能满足特定需求,则可以创建内核探针(kprobe)或用户探针(uprobe),以便在内核或用户应用程序的几乎任何位置附加 eBPF 程序。
uprobe(user-level probe)是一种在用户空间程序中动态插入探测点的机制。eBPF 可以与 uprobe 技术结合使用,实现在用户空间程序中的过滤和处理功能:
在用户空间程序的特定位置插入 uprobe 钩子。这可以通过在程序的源代码中添加特殊的宏或标记,或者通过动态二进制插桩技术来实现。编写 eBPF 程序,定义在 uprobe 钩子触发时要执行的操作。eBPF 程序可以访问 uprobe 上下文,获取函数参数、返回值等信息,并根据这些信息进行过滤和处理。将 eBPF 程序加载到内核中,并将其附加到 uprobe 钩子上。当用户空间程序执行到 uprobe 位置时,eBPF 程序就会被触发执行。eBPF 程序在内核中执行,对用户空间程序的相关数据进行过滤和处理。它可以根据预定义的规则或条件对数据进行筛选、聚合、统计等操作,并将结果传递回用户空间或存储在内核的 map 中。用户空间程序可以通过与 eBPF 程序共享的 map 或其他通信机制获取 eBPF 程序处理的结果,并进行进一步的分析和利用。
kprobe(kernel probe)是一种内核探测机制,允许在内核函数的入口或返回点插入一个钩子(hook),eBPF 可以与 kprobe 技术协同工作,一般步骤如下:
确定要跟踪或监控的内核函数,并在其入口或返回点插入 kprobe 钩子。编写 eBPF 程序,定义在 kprobe 钩子触发时要执行的操作,如记录事件、过滤数据、更新统计信息等。将 eBPF 程序加载到内核中,并将其附加到 kprobe 钩子上。当内核函数被调用或返回时,kprobe 钩子会被触发,eBPF 程序就会执行相应的操作。通过与 eBPF 程序共享的数据结构(如 map)或其他通信机制,用户空间程序可以获取 eBPF 程序处理的结果,并进行进一步的分析和利用。
2.2 eBPF字节码验证
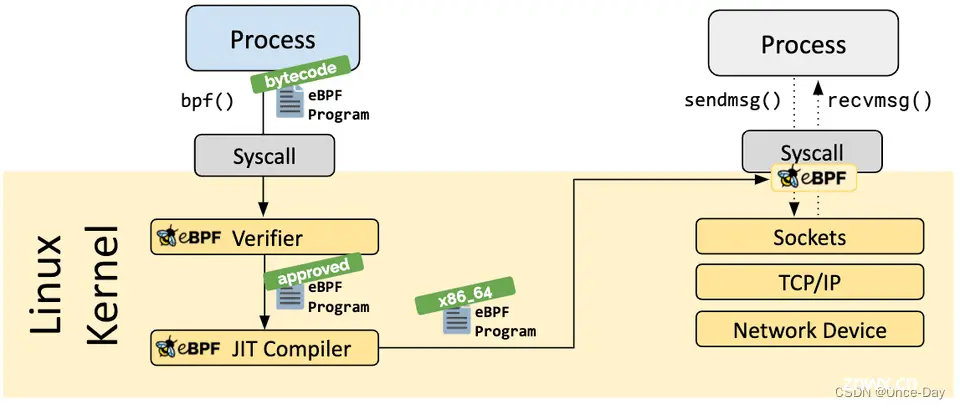
eBPF 程序在加载到内核之前,需要经过严格的验证(Verification)过程,以确保程序的安全性和可靠性。验证过程主要包括以下几个方面:
(1) 特权级检查:
默认情况下,只有具有特权级的进程才能加载 eBPF 程序,除非节点开启了 unprivileged 特性。内核提供了一个配置项 /proc/sys/kernel/unprivileged_bpf_disabled 来控制非特权用户是否能够使用 bpf(2) 系统调用。这个配置项是一次性开关(one-time kill switch),一旦将其设置为 1,就无法再改回 0,除非重启内核。当配置项被设置为 1 后,只有初始命名空间中具有 CAP_SYS_ADMIN 特权的进程才能调用 bpf(2) 系统调用。Cilium 等工具在启动后会将该配置项设置为 1,以限制非特权用户的访问。
(2) 程序的安全性检查:
验证器会分析 eBPF 程序的指令,确保程序不会导致内核崩溃或系统出现故障。验证器会检查 eBPF 程序是否存在无限循环或递归调用,确保程序能够在有限时间内完成执行(runs to completion)。验证器会检查 eBPF 程序的大小是否超过系统允许的限制,过大的程序将被拒绝加载。
(3) 程序复杂度分析:
验证器会评估 eBPF 程序的所有可能执行路径,以确定程序的复杂度。验证器需要在有限的时间内完成复杂度分析,如果超时,程序将被拒绝加载。复杂度分析确保了 eBPF 程序的行为是可预测和可控的,避免了程序对系统资源的过度消耗。
(4) 内存访问和资源限制:
验证器会检查 eBPF 程序对内存的访问是否合法,防止程序访问未授权的内存区域。eBPF 程序只能通过特定的 helper 函数来访问内核数据结构和资源,验证器会确保程序遵循这些规则。验证器会对 eBPF 程序使用的资源进行限制,如栈大小、指令数量等,以防止程序耗尽系统资源。
(5) 类型和参数检查:
验证器会对 eBPF 程序的类型和参数进行检查,确保类型匹配和参数使用正确。验证器会检查 eBPF 程序中的 map 类型、大小和键值对是否符合规范。验证器会检查 eBPF 程序调用的 helper 函数是否合法,并且参数类型和数量是否正确。
通过这些全面的验证措施,内核确保了 eBPF 程序的安全性和可靠性,防止了恶意或错误的程序对系统造成危害。
2.3 eBPF即时编译JIT
eBPF 的 JIT(Just-In-Time)编译器是一种动态编译技术,用于将通用的 eBPF 字节码实时转换为与机器相关的本地指令集。JIT 编译器极大地提高了 eBPF 程序的执行性能,相比解释器执行方式有以下优势:
(1) 降低指令开销:
JIT 编译器可以将 eBPF 指令直接映射为目标架构的本地指令,通常是 1:1 的映射关系。相比解释器逐条解释执行指令,JIT 编译后的本地指令可以直接在 CPU 上执行,减少了每条指令的执行开销。
(2) 减小可执行镜像大小:
JIT 编译器生成的本地指令通常比 eBPF 字节码更加紧凑,因此生成的可执行镜像大小更小。较小的可执行镜像对 CPU 的指令缓存更加友好,可以提高缓存命中率,进一步提升执行性能。
(3) 针对 CISC 指令集的优化:
对于 CISC(复杂指令集)架构,如 x86,JIT 编译器会进行特殊优化。JIT 编译器会为给定的 eBPF 指令生成尽可能短的操作码,以减少程序翻译过程所需的空间。这种优化可以进一步减小生成的本地指令的大小,提高执行效率。
目前,多个主流架构都内置了 in-kernel eBPF JIT 编译器,包括:
64 位架构:x86_64、arm64、ppc64、s390x、mips64、sparc6432 位架构:arm、x86_32
这些架构上的 eBPF JIT 编译器功能一致,可以通过以下方式启用:
$ echo 1 > /proc/sys/net/core/bpf_jit_enable
某些 32 位架构,如 mips、ppc 和 sparc,当前内置的是 cBPF JIT 编译器,而不是 eBPF JIT 编译器。对于这些只支持 cBPF JIT 编译器的架构,以及完全没有 BPF JIT 编译器的架构,需要通过内核中的解释器(in-kernel interpreter)来执行 eBPF 程序,性能相对较低。
可以通过在内核源代码中搜索 HAVE_EBPF_JIT 宏来判断哪些平台支持 eBPF JIT 编译器。
onceday->ease-shoot:# cat /boot/config-5.15.0-56-generic |grep HAVE_EBPF_JITCONFIG_HAVE_EBPF_JIT=y
2.4 eBPF数据映射Maps
eBPF Maps用于在内核空间和用户空间之间共享数据,以及在不同的eBPF程序之间传递数据。
BPF Map 的交互场景有以下几种:
内核空间与用户空间通信,用户空间程序可以通过Maps与内核中的eBPF程序进行数据交换。例如,用户空间程序可以将配置参数存储在Map中,供内核中的eBPF程序读取和使用。
不同eBPF程序之间的数据共享,多个eBPF程序可以通过Maps共享数据,实现协作和通信。例如,一个eBPF程序可以将处理结果写入Map,另一个eBPF程序可以从该Map中读取数据进行后续处理。
数据统计和监控,Maps可以用于统计和监控内核中的各种指标和事件。例如,可以使用Maps来统计网络数据包的数量、类型等信息,或者跟踪进程的资源使用情况。
数据缓存和加速,Maps可以充当缓存,存储频繁访问的数据,提高程序的性能。例如,可以将常用的路由表信息缓存在Map中,加速数据包的转发过程。
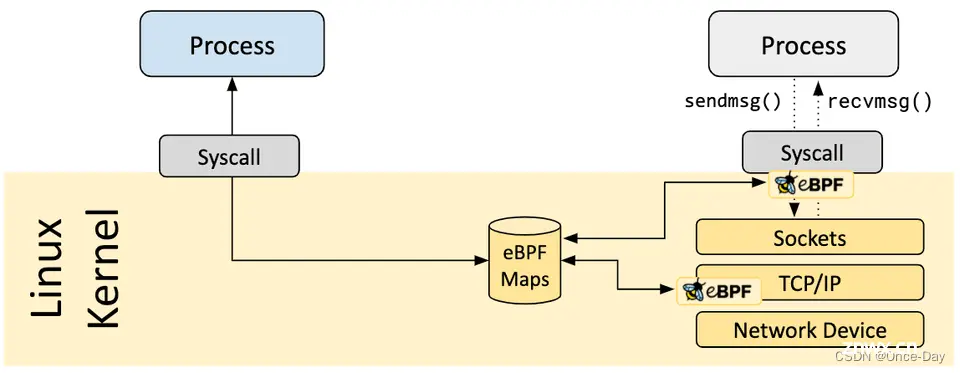
常见的Map类型如下所示:
Hash Map,哈希表结构,支持键值对的快速查找和更新。适用于需要频繁查找和更新的场景,如流量统计、路由表等。
Array Map,数组结构,通过索引访问元素。适用于固定大小的数据集合,如配置参数、统计计数器等。
LRU Map,基于Least Recently Used (LRU)算法的Map,自动淘汰最近最少使用的元素。适用于需要缓存和淘汰机制的场景,如连接跟踪、流量控制等。
Per-CPU Array Map,为每个CPU核心提供独立的数组副本,避免并发访问的竞争。适用于需要每个CPU核心独立统计和处理的场景,如网络数据包的接收和发送。
Stack Trace Map,用于存储函数调用栈信息,方便进行性能分析和故障排查。配合其他工具如bpftrace,可以实现高效的内核级别调试。
Sockmap/Sockhash Map,用于实现高效的数据包转发和负载均衡。Sockmap以索引的方式访问socket,Sockhash以哈希的方式访问socket。
Ringbuf Map,环形缓冲区,支持在eBPF程序和用户空间之间高效传输数据。适用于需要连续不断地将数据从内核传输到用户空间的场景,如事件记录、日志采集等。
eBPF Maps提供了灵活而强大的数据交互和共享机制,使得eBPF程序能够与内核和用户空间进行高效的通信和协作。
2.5 eBPF辅助函数Helpers
eBPF 程序不直接调用内核函数。这样做会将 eBPF 程序绑定到特定的内核版本,会使程序的兼容性复杂化。而对应地,eBPF 程序改为调用 helper 函数达到效果,这是内核提供的通用且稳定的 API。(来自ebpf.io)
eBPF Helpers的功能和作用:
数据包处理,访问和操作数据包的元数据,如网络接口、协议头等。示例Helpers:bpf_skb_load_bytes()、bpf_skb_store_bytes()、bpf_clone_redirect()。追踪和事件处理,跟踪内核函数的调用和返回,发送和接收自定义事件。示例Helpers:bpf_probe_read()、bpf_perf_event_output()、bpf_get_current_comm()。网络协议解析,解析和访问各种网络协议头,如IP、TCP、UDP等。示例Helpers:bpf_skb_load_bytes()、bpf_l3_csum_replace()、bpf_l4_csum_replace()。安全性和访问控制,进行权限检查和访问控制。示例Helpers:bpf_get_current_uid_gid()、bpf_get_cgroup_classid()。时间戳和计时器,获取当前时间,设置和管理计时器。示例Helpers:bpf_ktime_get_ns()、bpf_timer_init()、bpf_timer_set_callback()。Maps操作,对Maps进行查找、更新、删除等操作。示例Helpers:bpf_map_lookup_elem()、bpf_map_update_elem()、bpf_map_delete_elem()
使用Helpers的注意事项:
内核版本依赖,不同的内核版本可能支持不同的Helpers集合,需要确保目标内核版本支持所使用的Helpers。
安全性考虑,需要谨慎使用Helpers,避免不当操作导致内核崩溃或安全漏洞。
性能影响,过度使用Helpers可能对性能产生影响,需要权衡功能需求和性能影响,适度使用Helpers。
上下文限制,某些Helpers只能在特定的上下文中调用,如网络数据包处理程序。所以不同类型的 BPF 程序能够使用的辅助函数可能是不同的。
参数合法性,传递给Helpers的参数需要合法且与预期一致。
所有的 BPF 辅助函数都是核心内核的一部分,无法通过内核模块来扩展或添加。可以在 bpf-helpers(7) - Linux manual page (man7.org) 看到当前 Linux 支持的 Helper functions。
2.6 eBPF尾调用和函数调用
eBPF 程序可以通过尾调用和函数调用的概念来组合。
函数调用允许在 eBPF 程序内部完成定义和调用函数。尾调用可以调用和执行另一个 eBPF 程序并替换执行上下文,类似于 execve() 系统调用对常规进程的操作方式。
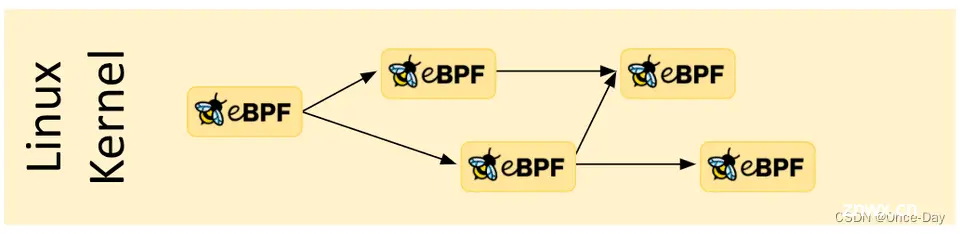
Tail Calls尾调用是一种特殊的函数调用方式,它允许一个eBPF程序在结束时直接跳转到另一个eBPF程序,而不是返回到调用方:
在尾调用中,当前eBPF程序的执行环境和堆栈状态会被销毁,直接跳转到目标eBPF程序。避免单个eBPF程序过大:由于eBPF程序的大小限制,可以通过尾调用将逻辑拆分为多个程序。
使用方法,使用bpf_tail_call()辅助函数进行尾调用。需要预先定义一个存储eBPF程序引用的prog_array Map,并将目标程序的索引作为参数传递给bpf_tail_call()。尾调用的深度有限制,通常为32层,超过限制会导致程序终止。
BPF调用BPF是指在一个eBPF程序中直接调用另一个eBPF程序,类似于函数调用。与尾调用不同,BPF调用BPF允许被调用的程序返回到调用方,并继续执行后续的代码,被调用的eBPF程序可以访问调用方的上下文和参数。
在BPF调用BPF特性引入内核之前,典型的 BPF C 程序必须将所有需要复用的代码进行 always_inline处理。当 LLVM 编译和生成 BPF 对象文件时,会在生成的对象文件中重复多次相同代码,导致指令数尺寸膨胀。
从 Linux 4.16 和 LLVM 6.0 开始,BPF支持函数函数调用,BPF 程序也不再需要到处使用 always_inline 声明,减小了生成的 BPF 代码大小,因此对CPU指令缓存(instruction cache,i-cache)更友好。
2.7 eBPF对象固定(Object Pinning)
对象固定(Object Pinning)允许将eBPF对象(如Maps和Programs)固定到文件系统中,使其能够在不同的进程、程序或系统重启之间共享和持久化。
通过将对象固定到文件系统,可以实现以下功能:
持久化,固定的对象可以在系统重启后继续存在,并能够被其他进程访问。
共享,固定的对象可以在不同的进程之间共享,实现进程间通信和数据交换。
全局可见性,固定的对象在整个系统范围内可见,可以被其他eBPF程序和用户空间程序访问。
对象固定通过bpf()系统调用和BPF_OBJ_PIN命令来实现。以下是固定Maps和Programs的基本步骤:
创建eBPF对象(Map或Program)。使用bpf()系统调用的BPF_OBJ_PIN命令将对象固定到指定的文件系统路径。
bpf(BPF_OBJ_PIN, &attr, sizeof(attr)); 其中,attr是一个bpf_attr结构体,包含了要固定的对象文件描述符和目标文件系统路径。其他进程或程序可以使用bpf()系统调用的BPF_OBJ_GET命令从指定路径获取固定的对象。
bpf(BPF_OBJ_GET, &attr, sizeof(attr)); 其中,attr包含了要获取的对象的文件系统路径。
2.9 eBPF安全增强功能
在成功完成验证后,eBPF 程序将根据程序是从特权进程还是非特权进程加载而运行一个加固过程。这一步包括:
程序执行保护(Protection Execution Protection), 内核中保存 eBPF 程序的内存受到保护并变为只读。如果出于任何原因,无论是内核错误还是恶意操作,试图修改 eBPF 程序,内核将会崩溃,而不是允许它继续执行损坏/被操纵的程序。
缓解Spectre漏洞(Mitigation Against Spectre): 根据推断,CPU 可能会错误地预测分支并留下可观察到的副作用,这些副作用可以通过旁路(side channel)提取。
例如,eBPF 程序可以屏蔽内存访问,以便在临时指令下将访问重定向到受控区域,验证器也遵循仅在推测执行(speculative execution)下可访问的程序路径,JIT 编译器在尾调用不能转换为直接调用的情况下发出 Retpoline。
常量盲化(Constant blinding):代码中的所有常量都是盲化的,以防止JIT spraying 攻击。这可以防止攻击者将可执行代码作为常量注入,在存在另一个内核错误的情况下,这可能允许攻击者跳转到 eBPF 程序的内存部分来执行代码。
将
/proc/sys/net/core/bpf_jit_harden设置为1会为非特权用户的 JIT 编译做一些额外的加固工作。这些额外加固会稍微降低程序的性能,但在有非受信用户在系统上进行操作的情况下,能够有效地减小潜在的受攻击面。但与完全切换到解释器相比,这些性能损失还是比较小的。(来自eBPF 完全入门指南.pdf(万字长文) - 知乎 (zhihu.com))
盲化 JIT 常量通过对真实指令进行随机化(randomizing the actual instruction)实现 。在这种方式中,通过对指令进行重写,将原来基于立即数的操作转换成基于寄存器的操作,指令重写将加载值的过程分解为两部分:
加载一个盲化后的(blinded)立即数 rnd ^ imm 到寄存器将寄存器和 rnd 进行异或操作(xor)
3. eBPF工具链介绍
3.1 BCC(BPF Compiler Collection)
BCC 是 BPF 的编译工具集合,前端提供 Python/Lua API,本身通过 C/C++ 语言实现,集成 LLVM/Clang 对 BPF 程序进行重写、编译和加载等功能, 提供一些更人性化的函数给用户使用。
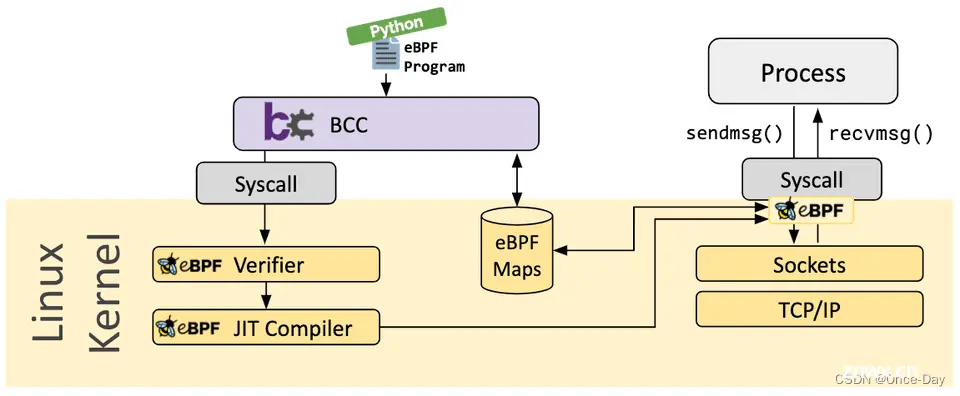
BCC工具优点如下:
简化了 BPF 程序的编写和使用,提供了高级语言绑定和工具集。
可以实时、动态地对内核和应用程序进行监控和分析,无需重启系统或修改源代码。
相比传统的内核工具和调试方法,BCC 提供了更低的开销和更高的性能。
社区活跃,提供了大量现成的工具和示例,方便用户快速上手和使用。
虽然 BCC 简化了 BPF 程序的编写,但仍然需要一定的内核知识和编程技能,并且BCC 的某些功能和工具可能依赖于特定的内核版本和配置,跨平台和兼容性方面有一定限制。
3.2 bpftrace
bpftrace是一款基于eBPF(Extended Berkeley Packet Filter)技术的Linux系统性能分析和跟踪工具。它允许用户编写简单而强大的脚本,以动态地跟踪内核和应用程序的行为,而无需修改源代码或重新编译内核。
bpftrace 是一种用于 Linux eBPF 的高级跟踪语言,可在较新的 Linux 内核(4.x)中使用。bpftrace 使用 LLVM 作为后端,将脚本编译为 eBPF 字节码,并利用 BCC 与 Linux eBPF 子系统以及现有的 Linux 跟踪功能(内核动态跟踪(kprobes)、用户级动态跟踪(uprobes)和跟踪点)进行交互。bpftrace 语言的灵感来自于 awk、C 和之前的跟踪程序,如 DTrace 和 SystemTap。
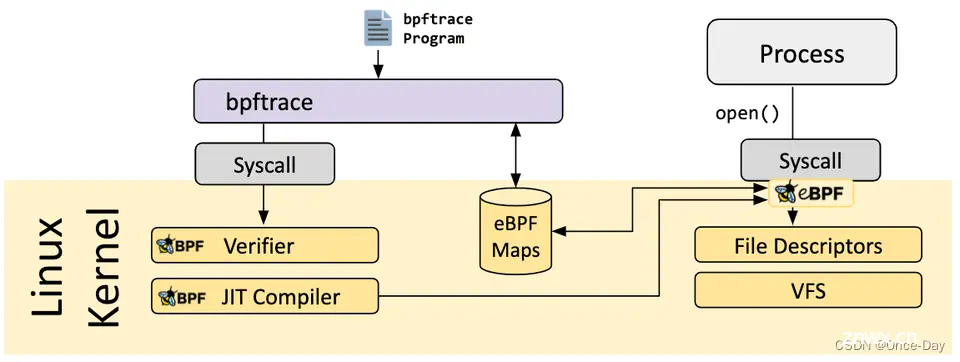
bpftrace的主要特点包括:
简洁的语法,bpftrace使用类似于awk和C语言的语法,易于学习和使用。
内核级别的跟踪,通过eBPF技术,bpftrace可以跟踪内核函数、系统调用、跟踪点(tracepoints)等,提供低开销、高精度的性能分析。
用户级别的跟踪,bpftrace也支持跟踪用户空间的函数和库调用,实现全面的系统性能分析。
动态插装,bpftrace可以在运行时动态地插入跟踪代码,无需重启系统或应用程序。
灵活的输出格式,bpftrace支持多种输出格式,如表格、直方图、火焰图等,方便用户分析和可视化数据。
bpftrace常用场景如下:
识别系统瓶颈,跟踪关键系统调用、内核函数的执行时间和频率,发现性能瓶颈。
分析应用程序行为,跟踪应用程序的函数调用、库函数使用情况,优化应用性能。
诊断系统问题,通过跟踪异常事件、错误信息,快速定位系统问题的根因。
安全监控,实时监控系统调用、网络活动等,发现可疑行为和潜在威胁。
3.3 libbpf库
libbpf 库是一个基于 C/ c++ 的通用 eBPF 库,它可以帮助解耦将 clang/LLVM 编译器生成的 eBPF 对象文件的加载到内核中的这个过程,并通过为应用程序提供易于使用的库 API 来抽象与 BPF 系统调用的交互。
也有一个基于Go语言实现的eBPF库,支持在Go语言下管理eBPF程序。
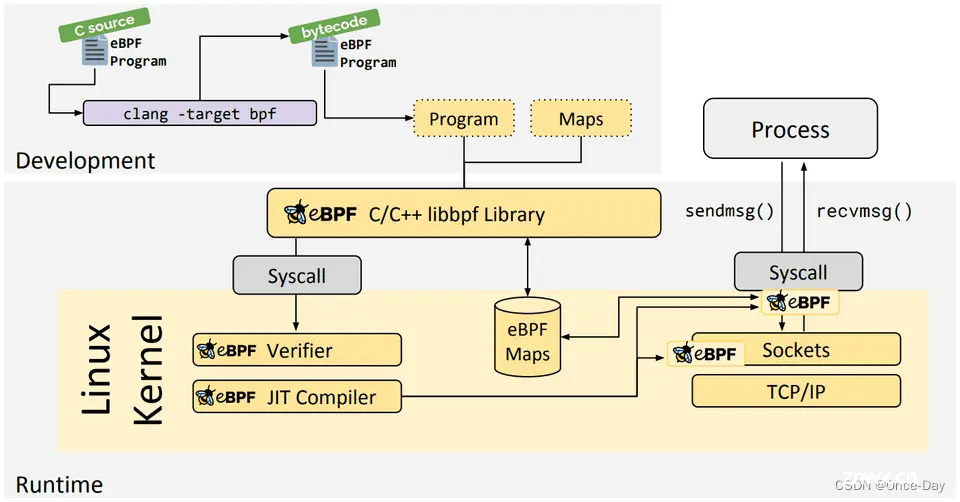
libbpf的主要特点和优势包括:
简化eBPF程序开发,libbpf提供了一组高层次的API,封装了与eBPF程序加载、验证、附加到内核探针等相关的底层细节,使得开发人员可以更专注于eBPF程序的逻辑。
与内核交互,libbpf处理了与内核的通信,包括eBPF程序的加载、卸载、参数传递和数据读取等,简化了用户空间和内核空间的交互。
封装eBPF Maps,eBPF Maps是内核空间和用户空间共享数据的重要机制,libbpf提供了一组API来创建、更新、删除和查询eBPF Maps,方便数据的存储和交换。
CO-RE(Compile Once – Run Everywhere)支持,libbpf支持CO-RE特性,允许eBPF程序在编译时与内核相关的数据结构解耦,使得编译后的eBPF程序可以在不同版本的内核上运行,提高了可移植性。
与bpftrace和BCC等工具集成,libbpf是bpftrace和BCC(BPF Compiler Collection)等高层次eBPF工具的基础库,这些工具在libbpf的基础上提供了更加易用和专业的eBPF开发环境。
使用libbpf的一般步骤如下:
编写eBPF程序,使用C语言编写eBPF程序,定义数据结构、Maps和程序逻辑。
加载eBPF程序,使用libbpf提供的API将eBPF程序加载到内核中,并进行验证和优化。
附加到内核探针,将加载的eBPF程序附加到内核的探针(如kprobes、tracepoints等)上,以便在特定的事件发生时执行。
与eBPF Maps交互,通过libbpf提供的API与eBPF Maps进行数据交换,如存储统计信息、配置参数等。
读取和分析数据,从eBPF Maps中读取数据,并在用户空间进行分析和处理,生成性能报告、日志等。
4. eBPF实践(hello world)
4.1 eBPF环境搭建
首先需要根据当前使用的Linux内核版本下载源码,如下所示:
onceday->~:# uname -aLinux VM-4-17-ubuntu 5.15.0-56-generic #62-Ubuntu SMP Tue Nov 22 19:54:14 UTC 2022 x86_64 x86_64 x86_64 GNU/Linuxonceday->~:# apt search linux-sourceSorting... DoneFull Text Search... Donelinux-source/jammy-updates 5.15.0.105.102 all Linux kernel source with Ubuntu patcheslinux-source-5.15.0/jammy-updates 5.15.0-105.115 all Linux kernel source for version 5.15.0 with Ubuntu patches......
这里选择当前内核版本的源码(linux-source-5.15.0),然后下载:
onceday->~:# apt install linux-source-5.15.0
源码在/usr/src目录下面,直接解压即可:
onceday->~:# cd /usr/src/onceday->~:# tar -jxvf linux-source-5.15.0.tar.bz2onceday->~:# cd linux-source-5.15.0/
然后拷贝当前系统的config配置到目录下面,并且完成初始编译测试:
onceday->linux-source-5.15.0:# cp /boot/config-5.15.0-56-generic .configonceday->linux-source-5.15.0:# make scriptsonceday->linux-source-5.15.0:# make headers_installonceday->linux-source-5.15.0:# make scripts
然后是准备编译bpf相关的文件和代码:
onceday->linux-source-5.15.0:# apt install llvm clang libcap-dev libbpf-devonceday->linux-source-5.15.0:# make M=samples/bpf
编译eBPF相关的示例程序时,错误还是非常多的,例如缺少库依赖,路径错误等等,需要逐一寻找解决方案。
4.2 eBPF程序(kern)
eBPF 通常由内核空间程序和用户空间程序两部分组成,内核空间程序以 _kern.c 结尾,用户空间程序以 _user.c 结尾。
首先写一个内核中运行的eBPF程序,如下(hello_kern.c):
#include <linux/bpf.h>#include <bpf/bpf_helpers.h>#define SEC(NAME) __attribute__((section(NAME), used))SEC("tracepoint/syscalls/sys_enter_execve")int bpf_prog(void *ctx){ char msg[] = "Hello BPF from onceday!\n"; bpf_trace_printk(msg, sizeof(msg)); return 0;}char _license[] SEC("license") = "GPL";
(1) 头文件包含:
<linux/bpf.h>: 这个头文件包含了 BPF 程序所需的基本定义和结构体。<bpf/bpf_helpers.h>: 这个头文件包含了 BPF 程序可以使用的辅助函数,如 bpf_trace_printk。
(2) SEC 宏定义:
这个宏用于指定 BPF 程序的代码段(section)和属性。在这个例子中,SEC("tracepoint/syscalls/sys_enter_execve") 表示这个 BPF 程序将附加到 execve 系统调用的入口点。
(3) bpf_prog 函数:
这是 BPF 程序的主函数,当 execve 系统调用被调用时,这个函数将被执行。函数的参数 void *ctx 表示 BPF 上下文,可以用于获取系统调用的参数和其他信息。在这个例子中,函数体只是简单地打印一条消息。
(4) 打印消息:
使用 bpf_trace_printk 函数打印一条消息到跟踪输出。消息内容为Hello BPF from onceday!\n,包括换行符。sizeof(msg) 用于指定消息的长度,包括空字符。
(5) 返回值:
BPF 程序必须返回一个整数值。在这个例子中,返回值为 0,表示允许系统调用继续执行。
(6) 许可声明:
char _license[] SEC("license") = "GPL"; 用于声明 BPF 程序的许可证。这个声明是必需的,否则 BPF 程序将无法加载到内核中。在这个例子中,许可证为 “GPL”(GNU General Public License)。
要使用这个 BPF 程序,需要将其编译为 BPF 字节码,并使用 BPF 加载器(如 bpftool 或 libbpf)将其加载到内核中。加载后,每当 execve 系统调用被调用时,就会在跟踪输出中看到这条消息。
4.3 eBPF用户空间程序
用户空间代码主要使用libbpf来加载bpf程序,然后读取输出,退出时也要卸载bpf程序。
#include <bpf/libbpf.h>#include <signal.h>#include <stdio.h>#include <unistd.h>static struct bpf_object *local_obj;static struct bpf_link *local_link = NULL;/* 收到signal时, 主动卸载bpf程序 */static void signal_handler(int signo) { if (signo == SIGINT) { printf("Unload bpf program\n"); bpf_link__destroy(local_link); bpf_object__close(local_obj); exit(0); }}int main(int ac, char **argv) { struct bpf_program *prog; char filename[256]; FILE *f; signal(SIGINT, signal_handler); snprintf(filename, sizeof(filename), "hello_kern.o"); local_obj = bpf_object__open_file(filename, NULL); if (libbpf_get_error(local_obj)) { fprintf(stderr, "ERROR: opening BPF object file failed\n"); return 0; } prog = bpf_object__find_program_by_name(local_obj, "bpf_prog"); if (!prog) { fprintf(stderr, "ERROR: finding a prog in obj file failed\n"); goto cleanup; } /* load BPF program */ if (bpf_object__load(local_obj)) { fprintf(stderr, "ERROR: loading BPF object file failed\n"); goto cleanup; } local_link = bpf_program__attach(prog); if (libbpf_get_error(local_link)) { fprintf(stderr, "ERROR: bpf_program__attach failed\n"); local_link = NULL; goto cleanup; } read_trace_pipe();cleanup: bpf_link__destroy(local_link); bpf_object__close(local_obj); return 0;}
这段代码是一个用户空间程序,用于加载和管理 BPF 程序。它使用 libbpf 库与 BPF 程序交互。下面是对这段代码的简要介绍:
<bpf/libbpf.h>: libbpf 库的头文件,提供了与 BPF 程序交互的函数和结构体。
全局变量,local_obj: 表示 BPF 对象文件,local_link: 表示 BPF 程序与内核的链接。
信号处理函数 signal_handler,当接收到 SIGINT 信号(如按下 Ctrl+C)时,会执行此函数。函数内部会卸载 BPF 程序,关闭 BPF 对象文件,并退出程序。
设置信号处理函数,打开 BPF 对象文件 “hello_kern.o”,在 BPF 对象文件中查找名为 “bpf_prog” 的 BPF 程序。
加载 BPF 程序到内核中,将 BPF 程序附加到内核的跟踪点上。
调用 read_trace_pipe 函数(代码中未提供实现)读取跟踪输出。
清理资源,卸载 BPF 程序,关闭 BPF 对象文件。
在samples/bpf/Makefile文件里面添加三行配置即可:
tprogs-y += hellohello-objs := hello_user.o $(TRACE_HELPERS)always-y += hello_kern.o
然后重新编译并运行用户空间程序:
onceday->bpf:# make M=samples/bpf onceday->bpf:# ./hellolibbpf: elf: skipping unrecognized data section(4) .rodata.str1.16 <...>-490371 [002] d...1 8467660.788803: bpf_trace_printk: Hello BPF from onceday! barad_agent-490372 [000] d...1 8467660.791449: bpf_trace_printk: Hello BPF from onceday! sh-490394 [002] d...1 8467664.792088: bpf_trace_printk: Hello BPF from onceday!......
可以看到,部分程序触发execve系统调用后,便会打印一个消息,该消息可以在下述管道直接读取:
sudo cat /sys/kernel/debug/tracing/trace_pipe
5. 总结
本文简单总结和介绍了eBPF技术历史背景和发展现状,以及几种重要的特性,最终在Linux内核环境下进行了一个hello world的小实验。 eBPF技术对于网络领域开发者来说,学习价值很大,能够提升网络流量的可观测性,在不侵入内核的情况下,提供高性能的过滤和处理能力。这里只是一个开始,eBPF学习还是不能浮在表面,必须基于内核源码深入分析,了解流程和思想,才能掌握精髓。
一起开始这趟旅程吧!

Once Day
也信美人终作土,不堪幽梦太匆匆......
如果这篇文章为您带来了帮助或启发,不妨点个赞👍和关注,再加上一个小小的收藏⭐!
(。◕‿◕。)感谢您的阅读与支持~~~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。