【网络】TCP/IP 五层网络模型:网络层
椰椰椰耶 2024-10-05 09:07:28 阅读 68
最核心的就是 IP 协议,是一个相当复杂的协议
TCP 详细展开讲解,是因为 TCP 确实在开发中非常关键,经常用到,IP 则不同,和普通程序猿联系比较浅。和专门开发网络的程序猿联系比较紧密(开发路由器,开发交换机,开发防火墙…)
IP 协议总览
网络层的 IP 协议,主要干两个事:
地址管理:需要指定一套规章制度,能够把互联网上的各种用来上网的设备所在的地址都管理起来==>IP 地址路由选择:在进行网络通信的时候,对数据报传输的路径进行的规划
IP 协议报头结构
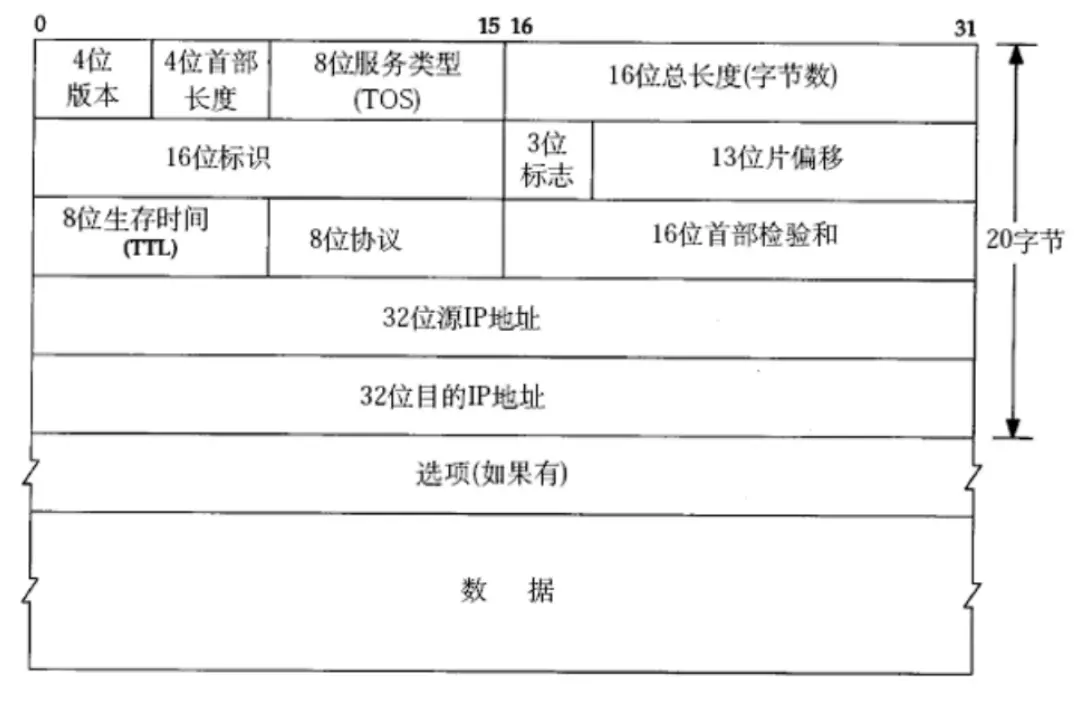
4位版本
实际上只有两个取值
<code>4 ==> IPv4(主流)6 ==> IPv6
IPv2,IPv5在实际中是没有的,可能是理论上/实验室中存在
4位首部长度
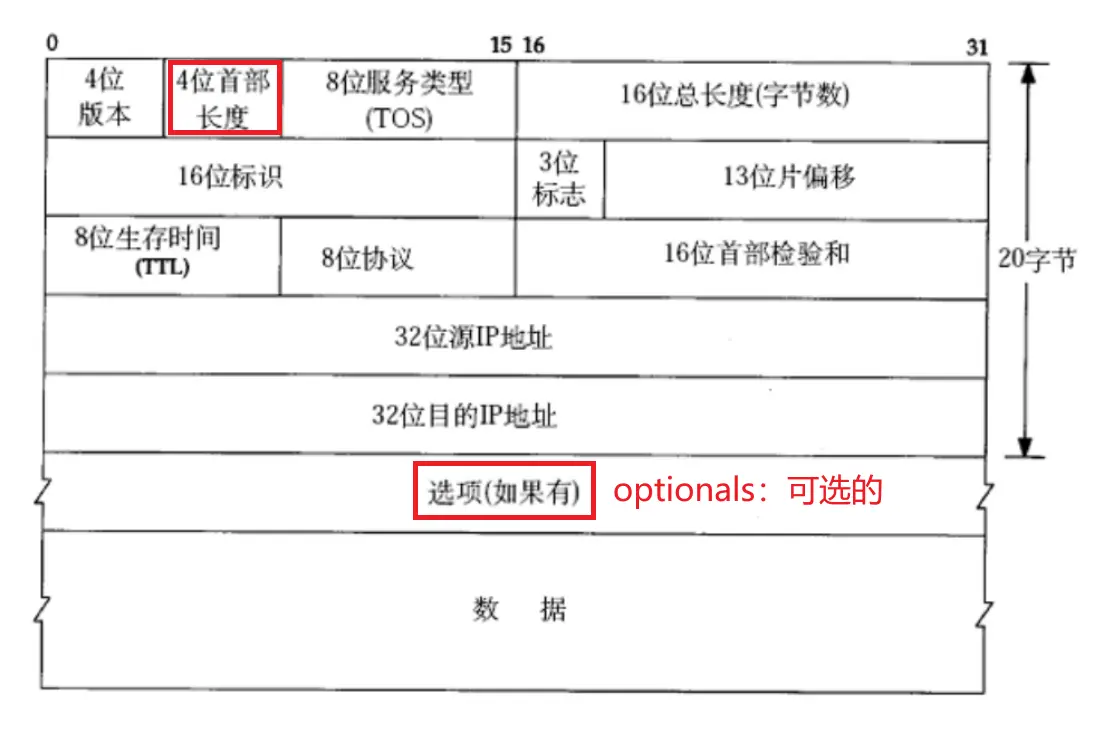
IP 协议报头也是变长的,因为选项个数不确定,所以报头长度也不确定。因此就需要使用 4 位首部长度进行区分
4 位首部长度范围:0~15,所以报头长度 <code>*4 才是实际的长度
当报头长度为 15,则实际报头长度为 15*4=60
8位服务类型
type of service

3位优先权字段(已经弃⽤),4位 <code>TOS 字段,和 1位保留字段(必须置为 0)。4位 TOS 分别表⽰:
最⼩延时:从 A 到 B 的时间消耗更少最⼤吞吐量:从 A 到 B,单位时间内传输的数量更多最⾼可靠性:数据丢包概率更小(IP 协议并不想 TCP 那样有严格的可靠性)最⼩成本:设备上消耗的资源更少
这四者相互冲突,只能选择⼀个。其中一个为 1,那么其他的都得为 0。IP 协议拥有变身技能!
16位总长度
IP 数据报的长度

UDP 也是 16 位(2 个字节,<code>64KB)。但并非 IP 协议报头最多能携带的数据就是 64KB
IP 协议内置了拆包组包机制,单个 IP 数据报确实没法超过 64KB,但是不代表 IP 协议不能传输超过 64KB 的数据。IP 协议会自动把大的数据包,拆成多个 IP 数据报携带传输,在接收方再进行拼装
装修的时候,装柜子/床,进不了电梯,也进不了房门,怎么办?
厂家发的货就不是拼装好的柜子和床,而是零件我们就可以先把零件搬进去,然后再组装起来
16位标识、3位标志、13位片偏移

IP 协议会自动拆包,统一个载荷的数据,会被分成多分,交给多个 IP 数据报来携带。多个 IP 数据包之间:
16位标识 是相同的数值,
13位片偏移 决定组包时候数据报的位置
网络传输数据的时候会存在后发先至的情况,所以不能按照发送顺序就确定接受顺序
3位标志 只有两位有效(有一位是保留位,现在不用,以后可能用,先占个位置)
其中一个标识这个包是否需要组包(是否是拆包的一部分)另一个表示当前包是否是组包中的最后一个单位
最后组包的时候,根据 16 位标识 确定哪些数据包放在一组,然后根据 13位片偏移 决定顺序,最后根据 3位标志位 决定是不是最后一个
如果就是想使用 UDP 实现传输找过 64KB 的数据,该怎么做呢?
此处参考 IP 协议在应用层编写代码的时候
- 引入“标识”,约定标识相同的数据,就应该进行组包
- 引入“片偏移”,约定组包的时候的先后顺序
- 引入“标志位”,区分是否需要组包,标识最后一个包
8位生存时间

描述了一个数据包在网络上存活的最长时间
假设构造一个 IP 数据报,目的 IP 写错了(不存在的 IP 地址),结果这个数据包就在网络上传输了很久,也没有达到目的地。如果让这样的数据包无限传输的话,就会消耗很多网络资源这样的数据包存在一个两个还好,要是存在很多呢?总不能让这些数据包把路全部堵死了吧
<code>TTL 就是约定了一个传输时间的上限,当达到上限之后,数据包就会被自动丢弃掉
它的单位不是 s 或者 min,而是次数(经过路由器转发的次数)
发送一个 IP 数据报的时候,会有一个初识的 TTL 的值(32,64,128…)。数据包每次经过一个路由器转发,TTL 就会 -1(经过交换机不减)。一旦 TTL 减到 0 了,此时这个数据包就会被当前的路由器直接丢弃掉
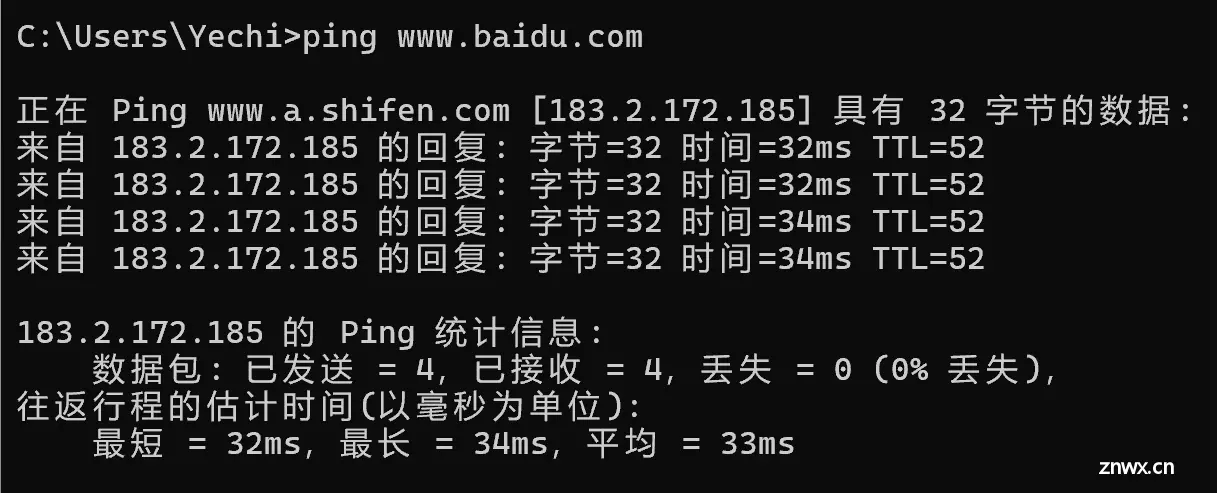
<code>ping命令:用来检测网络的连通性输入命令后,我们的电脑就会给百度发送一个数据包,百度收到这个 ping 命令的数据包之后,就会返回一个响应
我们发送了四次 32 字节的数据包几十毫秒,说明网络比较好;上百,上千毫秒说明网络比较卡咱们初始 TTL 应该是 64,中间经过了 12 个路由器的转发,最终到达了百度
64这样的TTL够用吗?
正常情况下,
64这样的TTL是非常充裕的
六度空间理论(社会科学中的理论) 而且发送数据的时候,还有
128这样的TTL
8位协议

IP 数据包中,携带的载荷,是哪种传输层协议的数据包
通过这里的不同数值,感知到接下来要把数据给 TCP 解析,还是 UDP 解析,还是其他协议解析
类似于 TCP/UDP 报头中的“端口号”,决定要将这个数据交个哪个应用程序,也就是要将这个数据交给哪个应用层的具体协议进行处理
现在 IP 协议要先交给传输层,交给哪个传输层协议进行处理,就通过 8位协议 进行标识
具体的数值这里不谈,这里暂时只聊作用
16位首部校验和

验证数据在传输中是否出错(只是针对首部,IP 报头)
载荷部分 <code>TCP/UDP 都有自己的校验和,此处就不需要再次进行验证了
32源 IP 地址、32位目的 IP 地址

IP 数据报中最关键的信息:数据包从哪里来,到哪里去
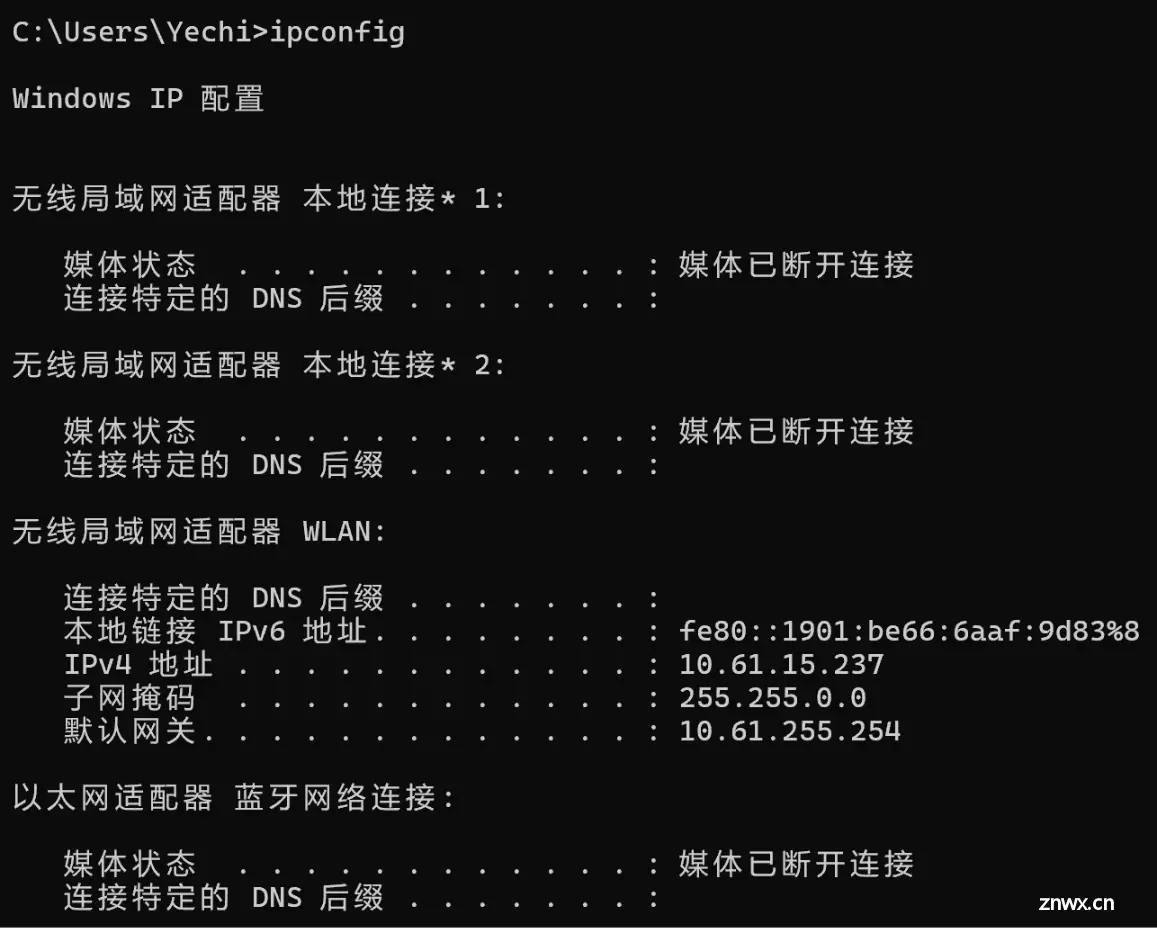
输入:<code>ipconfig,就可以看到当前机器的 ip 地址
IP 地址是 32 位的整数
这是一个很大的数字,不方便人进行阅读和理解就把 32 位(4 字节)通过 3 个圆点分隔开,每个部分是一个字节,范围 <code>0-255(只要有一个部分不在这个范围,就可以认为是一个非法/错误的 IP)这就是“点分十进制”写法但计算机在底层处理这些数据的时候,都是当成 32 位的 IP 地址来处理的
IP 地址,用来标识网络上的一个设备。期望 IP 地址是唯一的
32 位表示的范围:0—42亿9千万在现在的社会背景下,所存在的需要 IP 地址的设备肯定是超过了这个范围的
地址管理
就是为了解决 IP 不够用的问题
方案一、动态分配 IP 地址
一个设备上网就分配 IP,不上网就先不分配(权宜之计)
方案二、NAT
网络地址转换
以一当千,使用一个 IP,代表一大波设备
NAT 把 IP 地址分为两大类:
内网 IP / 私网 IP(重要)
10.*172.16~172.31.*192.168.*
外网 IP / 公网 IP:除了私网 IP 就都是公网 IP
要求公网 IP 必须是唯一的,但是私网 IP 在不同的局域网中是允许重复的
一台电脑上,有几个网卡就有几个 IP 地址,虚拟出来的网卡也算(软件模拟的网卡)一般笔记本都会有:有线网卡和无线网卡,具体哪个生效就看你当前是用网线上网还是 WiFi 上网
NAT 网络地址转换
一个设备在进行上网的时候,IP 数据报中的 IP 地址,就会被 NAT 设备(通常就是路由器)进行自动修改
同一个局域网内,主机 A 访问主机 B
不会涉及到 NAT 机制
公网上的设备 A,访问公网上的设备 B
不会涉及到 NAT 机制
不同局域网中的主机 A 访问另一个局域网的主机 B
NAT 机制中,是不允许的
之前写
UDP回服务器的时候,我这台电脑上启动UDP服务器,你使用UDP客户端是不能访问的
因为我处于我这里的局域网,你处于你们那的局域网在
NAT机制下,一个局域网中的主机 A 是无法访问领一个主机
局域网内部的设备 A,访问公网上的设备 B
NAT 机制主要就是针对这个情况进行生效
但凡是搭建一个服务器给别人使用,都是需要公网 IP 的
单个设备
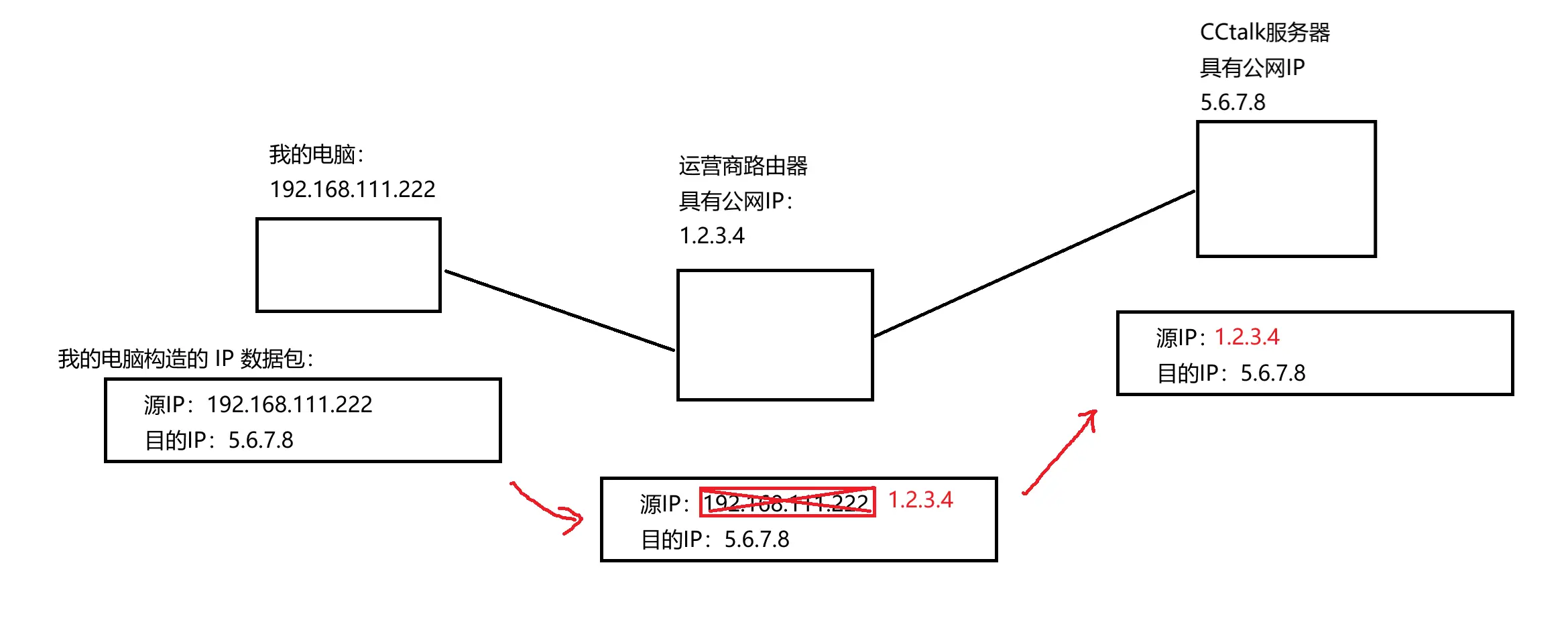
此时我的电脑要想访问 <code>CCtalk 这个服务器,就要构造一个 IP 数据报数据包到达运营商路由器(NAT 设备)之后,就会进行网络地址转换
将源 IP 地址由我的 IP 地址变为运营商公网 IP 地址所以 CCtalk 看到的数据包,源 IP 不是 192.168.111.222,而是 1.2.3.4
为什么进行这样的 IP 地址的替换就能提高 IP 地址的利用率呢?
其实日常上网的设备:手机、电脑、电视、空调等绝大部分都是在不同的局域网中此时就相当于一个公网 IP 就可以代表一大批设备
运营商的公网 IP,不是服务一个设备,而是服务一个片区,可能有上万个设备。此时一个 IP 就代表了上万个设备,此时 IP 的利用率就大大提高了
就相当与你在网上买东西,写的收货地址是:北京市海淀区清华园清华大学这个地址对应着几万个人,而不是你一个人
CCtalk 的响应如何正确地返回到我的电脑上呢?
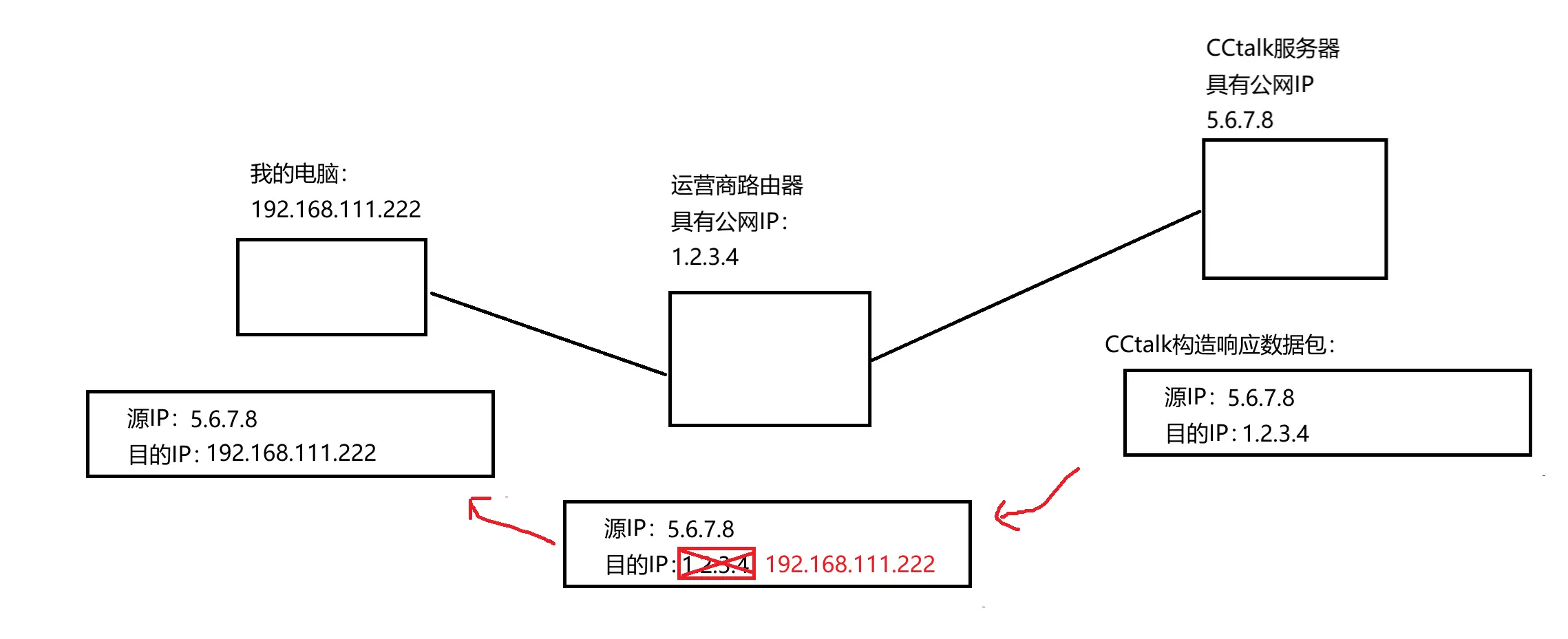
CCtalk 要构造一个响应数据包达到运营商路由器之后,里面的目的 IP 就会被替换回我的电脑 IP之后就能顺利达到我的电脑
运营商路由器这样的 <code>NAT 设备能在发出和收回的时候都进行 IP 替换,就能使内网设备和外网设备进行连接
多个设备(同一个局域网内)
在网络通信中,不仅仅只有 IP 信息,还有一个关键的是端口号
端口号本来是来区分同一个主机上不同的应用程序的在 NAT 中,就可以用于区分不同主机上不同的应用程序
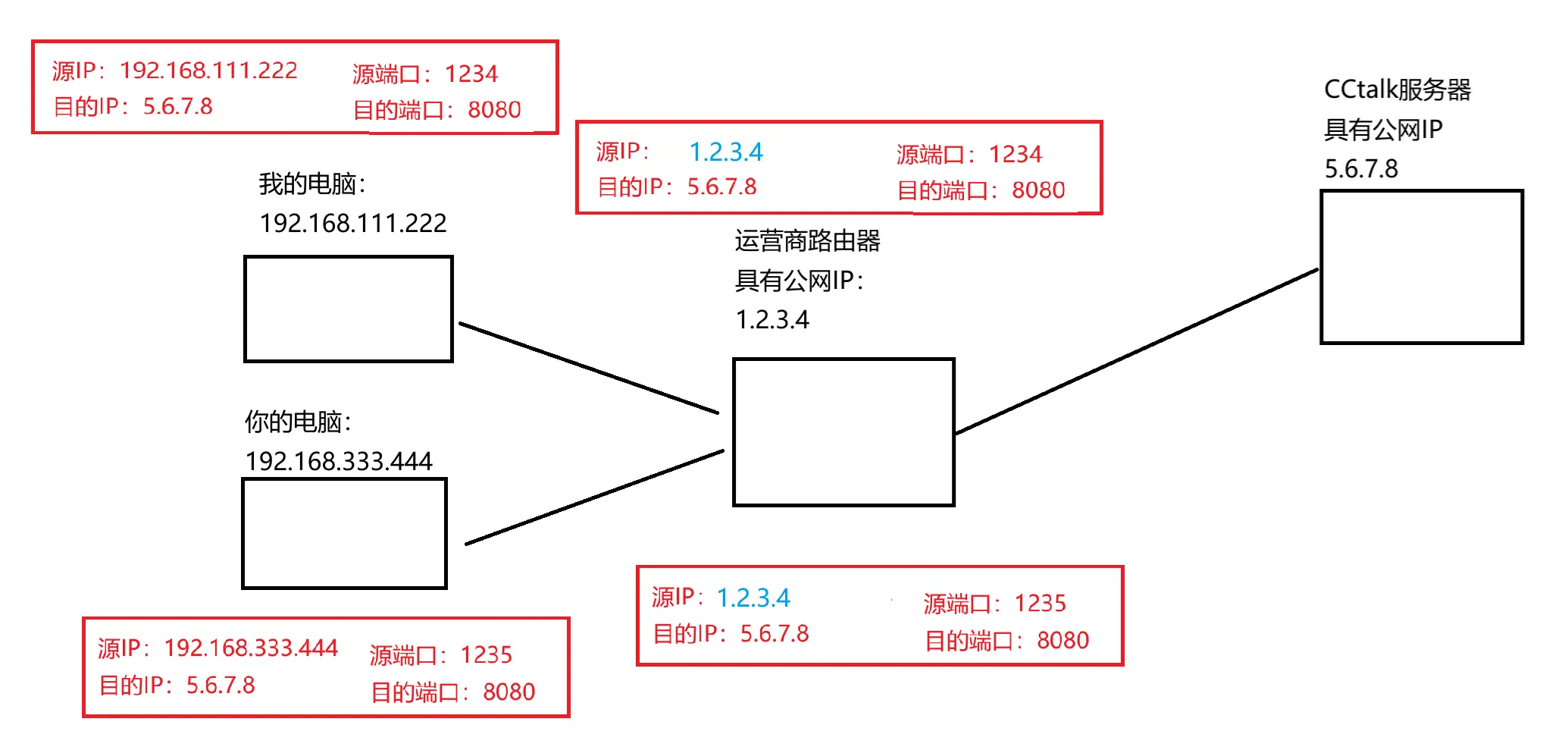
在我的和你的数据包到达运营商路由器之后,要进行 IP 替换。同时运营商路由器会记录一个映射关系:
| 旧 IP | 旧端口 | 新 IP | 新端口 | |
|---|---|---|---|---|
| 192.168.111.222 | 1234 | 1.2.3.4 | 1234 | |
| 192.168.333.444 | 1235 | 1.2.3.4 | 1235 |
返回数据包的时候
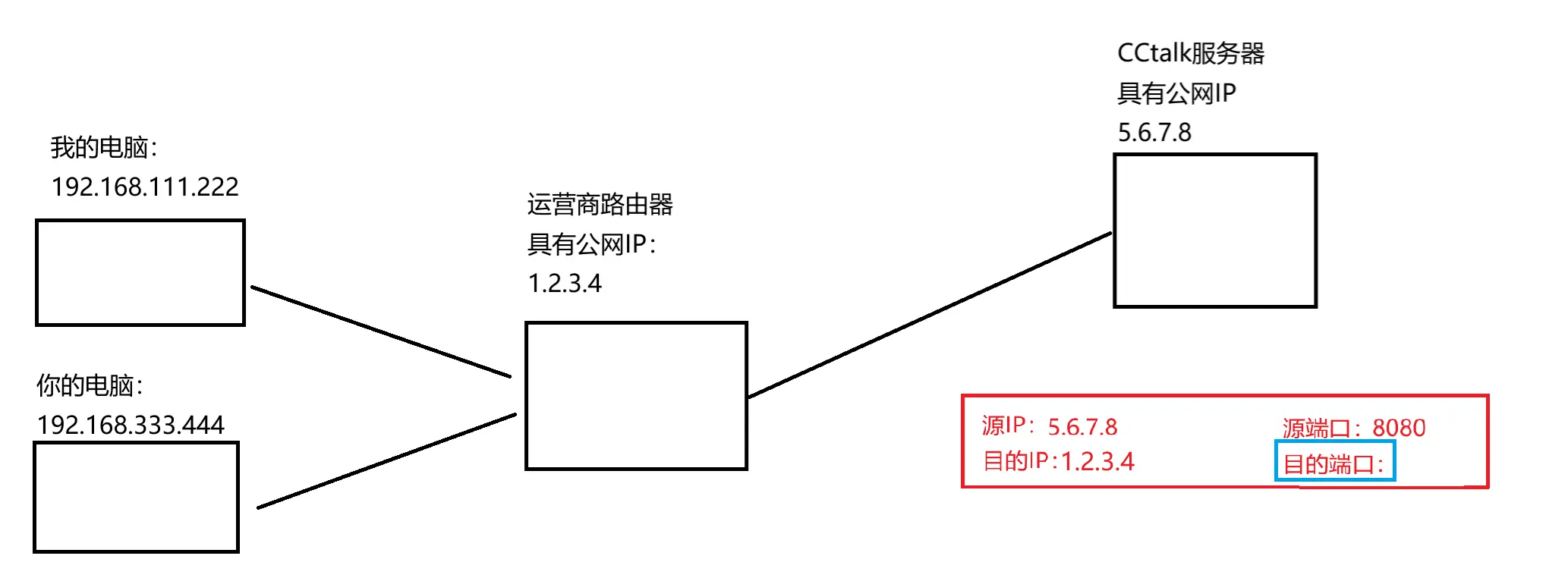
此时,CCtalk 服务器返回的响应数据也是有 IP,也是有端口端口就决定这个返回值是给我还是给你
运营商路由器收到这个目的端口后,就会看原来记录的映射关系根据传过来的目的端口,运营商路由器可以知道是哪个 IP 传过来的之后再将这个目的端口对应的 IP 替换上去就可以传到对应的设备了 目的端口是 <code>1234,就是传给我目的端口是 1235,就是传给你
此处就是通过端口号,来区分不同主机的不同程序
是否可能出现:你和我的电脑上 CCtalk 源端口恰好是一样的?
这个概率非常小;客户端这里的源端口,是操作系统随机分配的空闲端口就算你的端口号也是 1234,但是路由器建立映射关系表的时候,可以把端口号也替换成不重复的其他端口
NAT既能替换IP中的IP,也能替换TCP/UDP中的端口。这个就是NAPT
我们当前的网络世界,主要就是 NAT 机制的支撑
NAT 机制的缺点
网络环境太复杂了替换过程中,每一层路由器都需要维护映射关系每次转发数据,都要查询映射关系每个步骤都是开销
方案三、IPv6
从根本上解决了 IP 地址不够用的问题
IPv4 使用 32 位 4 个字节表示 IP 地址IPv6 使用 128 位 16 个字节表示 IP 地址
16 个字节表示的 IP 地址数目,比 4 个字节的 IP 地址大:
2
128
−
2
32
2^{128}-2^{32}
2128−232。这个地址空间非常大,大到可以给地球上的每一粒沙子都分配一个唯一的 IPv6 地址
IPv6 提出的时间是在上个世纪 90 年代,时间上和 NAT 其实是差不多的。之所以 IPv6 举步维艰,因为 IPv6 和 IPv4 不兼容!
要想使用 IPv6,就要更换新的设备(能支持 IPv6 的设备)在 IPv6 提出的当年,显然是不具备这样的条件的。换设备就得花钱,但花钱了网速又不会变快(用户感知不到好处)
NAT 机制,只要给路由器设备更新升级软件即可,硬件不需要改变(成本非常低)
网段划分(组网)
组网的时候,就需要我们针对每个上网设备 IP 地址(包括路由器的 IP)进行设置
我没设置过,好像插上网线就能上网,这是为什么呢?
对于家庭网络这种比较简单的网络结构来说,路由器都有“自动分配 IP”的功能(
DHCP)。但在公司、学校、商场、宾馆… 这些更复杂的场景,网络需求更复杂,就需要进行手动设置了。
子网掩码
IP 地址,32 位整数,一分为二
左半部分:网络号右半部分:主机号
只看 IP 地址是看不出来的,需要通过“子网掩码”区分出那里是网络号,哪里是主机号

子网掩码也是 32 位整数。左半部分都是 <code>1,右半部分都是 0(二进制数)
在这里 255.255.0.0 就是 11111111.11111111.00000000.00000000所以上面 IP 地址中,10.61 就是网络号,15.237 就是主机号
网络中规定:
同一个局域网中的设备,网络号必须相同,主机号必须不同
在这个局域网中,某个设备号不相同的话,就无法上网;某个设备的网络号虽然相同,但主机号和别的设备重复,也无法上网
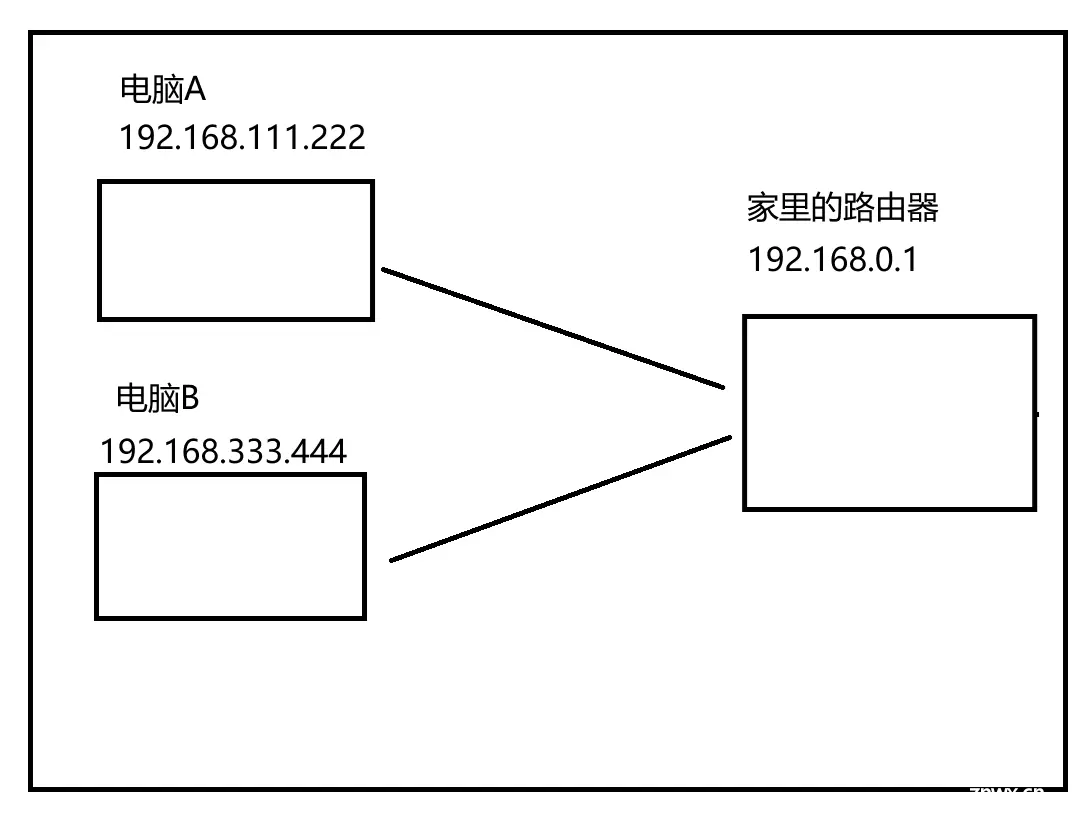
两个相邻的局域网,网络号必须不同
路由器上有两种网络接口:
<code>LAN 口WAN 口
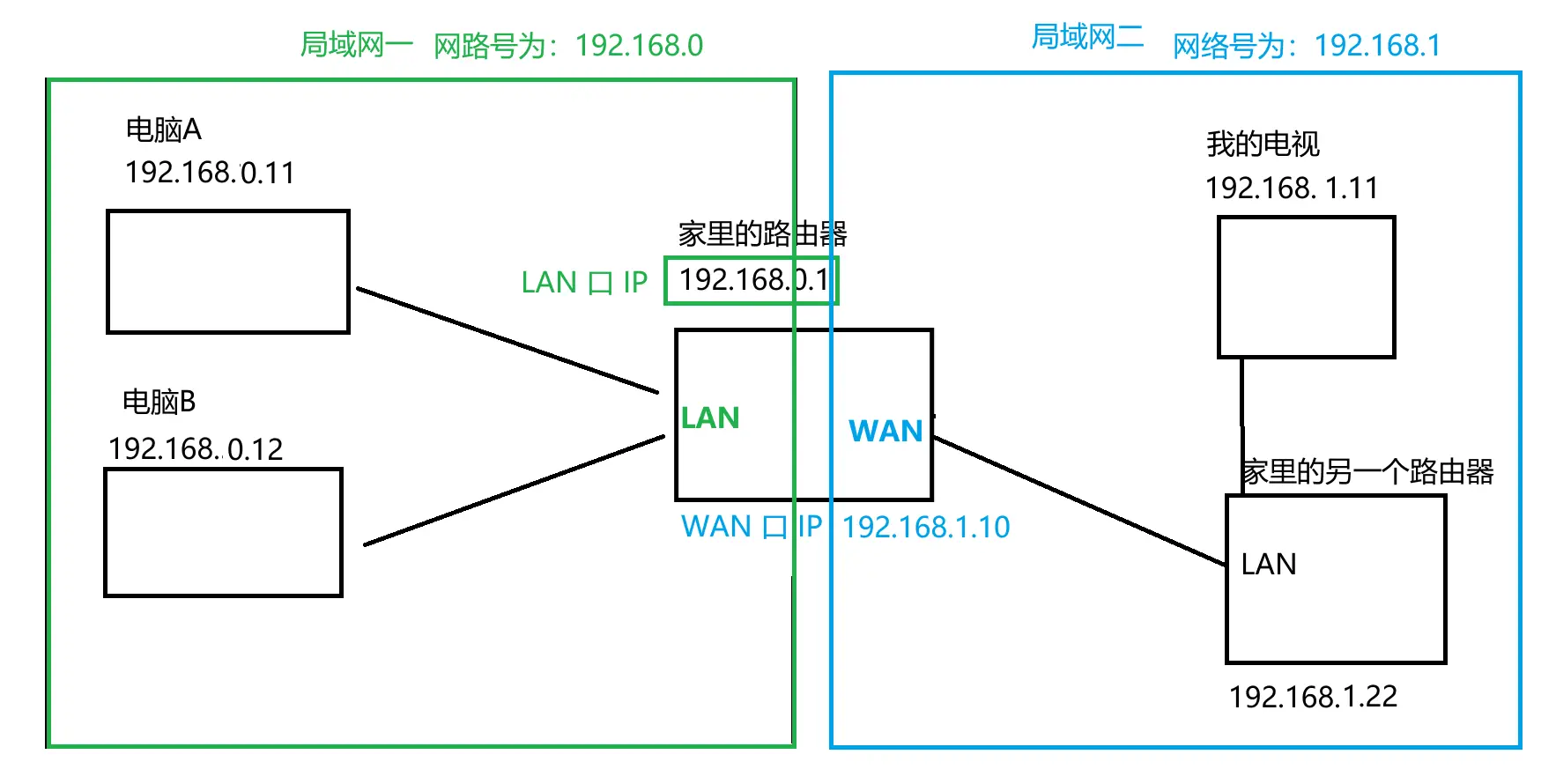
此时这个路由器就连接了两个局域网。这两个局域网的 IP 网络号是不能重复的。一旦重复,也上不了网
同一个路由器连接的两个局域网,就叫相邻局域网
<code>LAN 口接设备(你的电脑、电视…),
WAN口接上层路由器
ABCDE 五类网络
AB 类,主机号太多了,实际上一般没有这么大的局域网IP 地址浪费的比较多
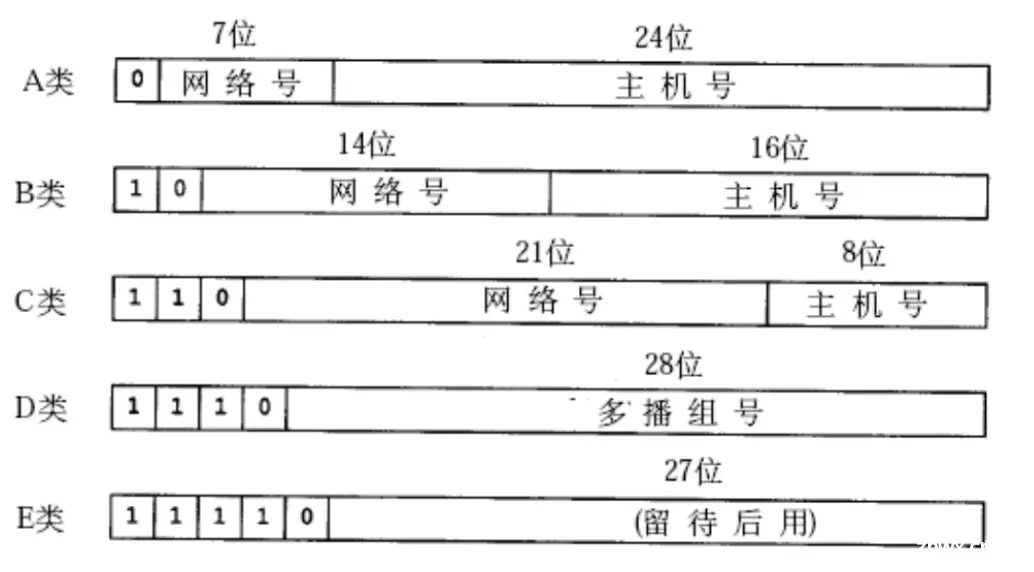
A类:<code>0.0.0.0~127.255.255.255B类:128.0.0.0~191.255.255.255C类:192.0.0.0~223.255.255.255D类:224.0.0.0~239.255.255.255E类:240.0.0.0~247.255.255.255
特殊的 IP 地址
1. 主机号位全 0(二进制)
此时这个 IP 就是表示当前网段(相当于网络号)
因此,给局域网中的某个设备分配 IP 地址的时候,不能把主机号全设为 0
2. 主机号为全 1
比如子网掩码为 255.255.255.0,IP 地址为 192.169.0.255。这里我们可以看到,IP 地址前三个字节为网络号,后一个字节 255 为主机号(11111111)
主机号为 11111111 就是广播 IP,往这个 IP 地址上发送数据包,就相当与给整个局域网中所有设备都发了一次数据包(针对一个局域网中的对象)。我们很多看到的“业务上的广播”,都是通过应用层编写代码来实现的,而不是借助广播 IP
以 CCtalk 为例,CCtalk 会维护出很多的“教室信息”,你上课的时候就是在其中一个教室,一个教室会涉及到很多同学(教室数据中就包含所有同学的数据)。此时,老师进行直播的时候,老师那边的画面和声音就会发送给 CCtalk 服务器对应的教室那里,CCtalk 服务器就会根据教室中同学的列表,依次遍历每个列表元素,把数据发送出去
机房上课、地震预警大概率都是这样的实现原理
什么时候是真用到广播 IP?(手机,电视投屏)
手机视频有一个投屏按钮(TV),按下按钮,弹出来一个设备列表,选择投屏到哪个设备上(要求手机和电视得在同一个局域网中)
手机上如何知道局域网中有多少设备允许投屏,这样的功能就可以基于广播 IP 实现
手机触发投屏按钮的时候,往对应的广播 IP 上发送一个数据包(UDP)(TCP 不支持广播,只能一对一)如果收到这个数据包的设备不具有投屏功能,就不吱声;如果支持,就会返回一个响应,告知我是什么设备,我的 IP 是什么
3. 环回 IP(loopback)
127.*
自发自收,给这个 IP 发送一个数据,设备就会从这个 IP 上再收到同一个数据(自己发给自己)
你踢球的时候,自己射门又自己补射(自射自补)
使用环回 IP 一般进行测试。写的网络程序,大多数情况都是为了跨主机通信。但在此之前,往往需要先自行测试,一台测试客户端和服务器之间能否正常交互
一般使用的环回 IP 是
127.0.0.1,虽然其他的127开头的 IP 也是可以的,但是很少见
路由选择
网络是复杂的网状结构,从一个节点到另一个节点之间,可能会存在很多条线路(交通网)
你想从北京去上海,你打开高德地图,会给你提供很多条路线让你选择
高德地图的路由选择和 IP 协议的路由选择是有本质区别的高德地图知道路线的全貌,给你计算出来的路线就是“最优解”(用时最短/成本最低/最少换乘)IP 协议的路由选择,每个路由器是无法知道网络结构的全貌,只能知道其中的一小部分(每个路由器只知道它附近的设备都是怎样的情况),只能得到“较优解”
基本情况
你想从陕科大去邮电大学
我从陕科大出发,在校门口问 A:邮电大学怎么走?A 表示他也不知道。
但虽然他不知道,但是他大概清楚邮电在南郊,而我们现在在北郊,得先往南走
A 就建议我们先去校门口坐 336 公交,往南先走一段再说
上了 336 之后,我又问 B:邮电怎么走?B 表示他也不知道
B 也大概清楚,邮电在南郊
B 建议我继续坐 336 ,到运动公园下车,换乘地铁二号线
到了运动公园,坐上地铁了,又问 C:邮电怎么走?
C 表示他也不太清楚,大概知道邮电在很南的地方
C 就建议我继续坐二号线往南走,坐到小寨(相当于二号线的中点),之后再问问
到了小寨,又问 D:邮电怎么走?
D 表示他也不太知道,大概知道,应该继续坐二号线,到航天城,让我到了航天城再说
到了航天城,又问 E:邮电怎么走?
E 就告诉我,往西走大概两条街,然后再往北拐半条街就到了
最终到达邮电
每次在进行问路的时候,每个人都是没法知道西安市的完整地图详细信息的,只能知道其中的一部分信息。但他能给我指出一个方向,我按照这个方向走,就会越来越接近,当足够接近的时候,总是可以遇到一个人能告诉我精确目标地点的。
这就和 IP 协议路由选择非常相似。
上述 ABCDE 这几个问路的人,就相当于路由器。每个路由器都不知道整体网络结构的全貌,但是能够知道其中的一部分。知道的这一部分信息,被称为“路由表”,路由器内部维护的重要的数据结构,类似于 hash,key 就相当于 IP 地址(网络号),value 就是对应的网络接口(往哪个方向走)IP 数据报达到路由器,就要进行路由查表操作:查一查 IP 数据报中的目的 IP 在路由表中是否存在
如果查到了,就是按照路由表指定的方向继续转发即可如果没有查到,路由表会有一个“默认的表项”(下一跳)“下一跳“指定了一个更高层级的路由器(认识的设备范围更广)这个路由器要是还找不到,就继续“下一跳”,找到更高层级的路由器(认识的设备范围更广)
真是的转发过程,会更加复杂
路由表里面的东西是怎么来的?
自动获取的(路由表生成算法)手工配置(网络管理员,手动设置)
真实的网络结构(尤其是广域网的网络结构是怎样的)
感兴趣可以去 B 站搜一下,中国电信/中国移动/中国联通网络架构
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。