[MySQL] MySQL复合查询(多表查询、子查询)
Ggggggtm 2024-10-07 09:37:01 阅读 68
前面我们学习了MySQL简单的单表查询。但是我们发现,在很多情况下单表查询并不能很好的满足我们的查询需求。本篇文章会重点讲解MySQL中的多表查询、子查询和一些复杂查询。希望本篇文章会对你有所帮助。
文章目录
一、基本查询回顾
二、多表查询
2、1 笛卡尔积
2、2 多表查询练习
三、自连接
四、子查询
4、1 单行子查询
4、2 多行子查询
4、3 多列子查询
4、4 在from子句中使用子查询
五、合并查询
🙋♂️ 作者:@Ggggggtm 🙋♂️
👀 专栏:MySQL 👀
💥 标题:MySQL复合查询💥
❣️ 寄语:与其忙着诉苦,不如低头赶路,奋路前行,终将遇到一番好风景 ❣️
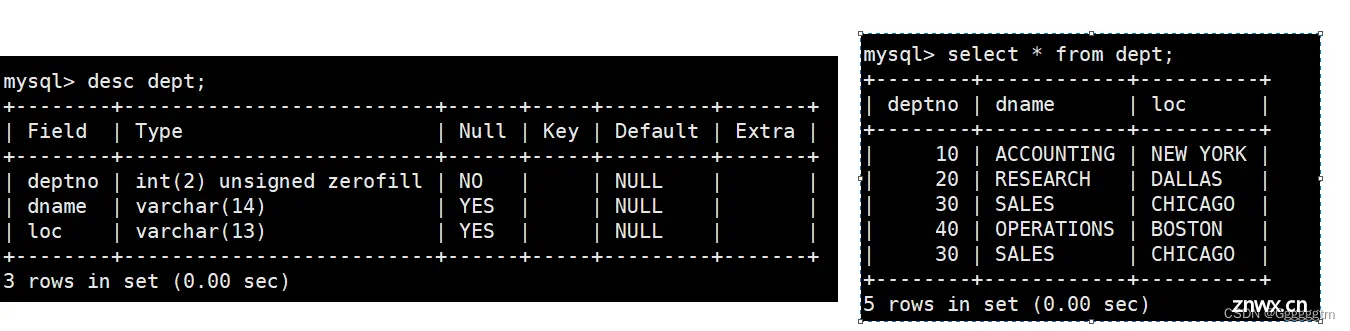
在对本篇文章学习之前,首先说明一下本篇文章所用到表的结构和内容。具体如下:
员工表emp:
部门表dept:
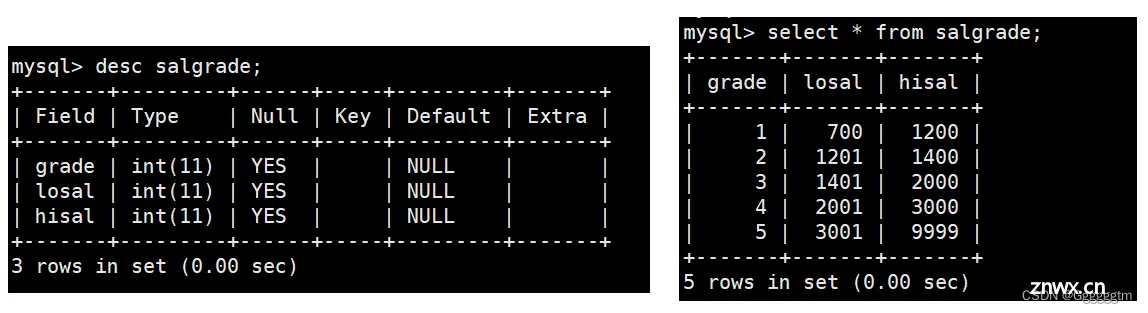
薪水表salgrade:
一、基本查询回顾
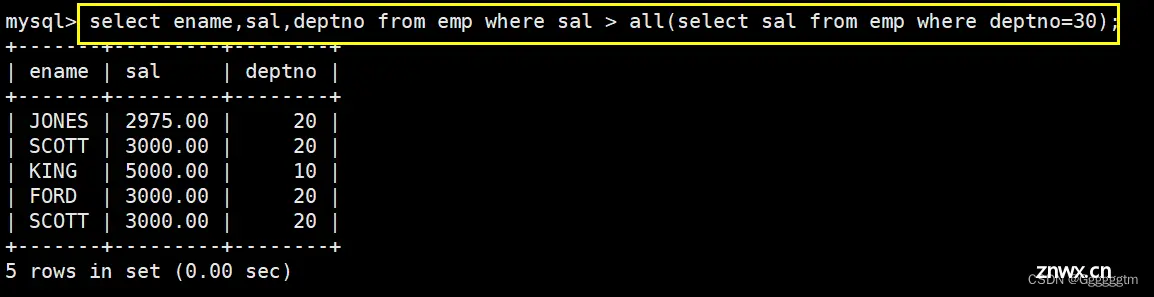
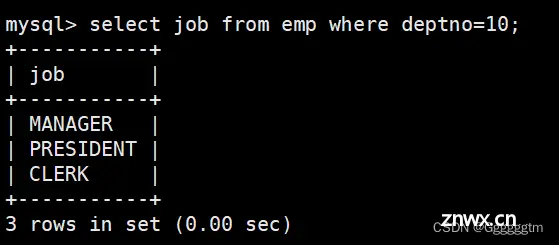
查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J
首先确定,上述所需筛选的信息都在一行表中。其次,分析出 工资 > 500 or job = MANAGER。我们先来查询出满足 工资 > 500 or job = MANAGER 的员工。具体如下:
同时,我们还需要满足所查询到的员工的姓名首字母为大写的J,很明显是模糊查询。具体如下图:


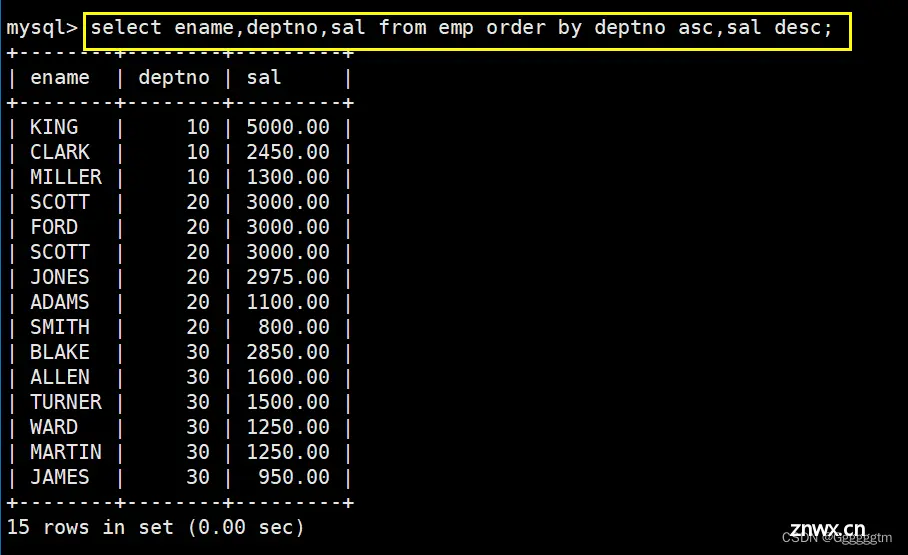
按照部门号升序而雇员的工资降序排序
这个需求就是简单的排序即可。注意所需排序的先后顺序。具体如下图:

使用年薪进行降序排序
首先我们需要计算出来年薪。年薪 = 月薪(sal)*12 + 年终奖(comm)。那么我们直接就对其进行排序即可。但是需要注意的是:NULL并不能参与计算,这时候需要内置函数ifnull来进行判断其是否为NULL,如果为NULL直接加0即可。 具体如下:
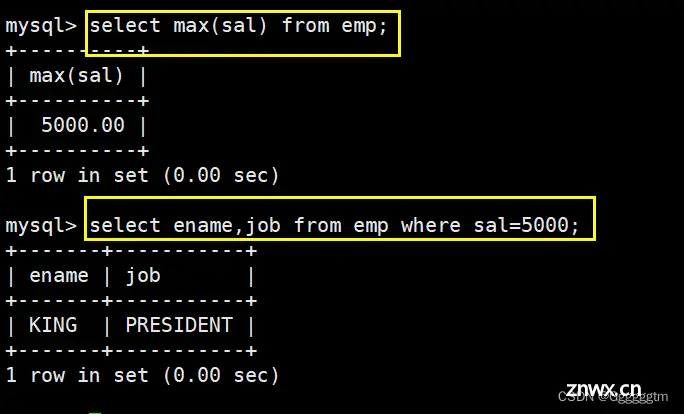
显示工资最高的员工的名字和工作岗位
我们可以很容易的查找到最高工资是多少,然后再根据最高工资去找对应的员工的名字和工作岗位。具体如下图:
上述用了两条SQL语句确实能够查询出我们想要的结果。但是好像不太优雅。能不能用一条语句将所需结果查询出来呢?答案是可以的。我们可以用子查询。什么是子查询呢?在 MySQL 中,子查询是指在一个查询语句中嵌套另一个查询语句。子查询可以用于过滤结果集、作为计算字段的数据源、与外部查询进行比较等多种情况。下面我们用子查询来解决这个需求。具体如下:

显示工资高于平均工资的员工信息
这个题目的需求与上一个题目的需求很相似。我们可以先获取平均工资,在查询比平均工资高的员工,一样是用子查询。具体如下:
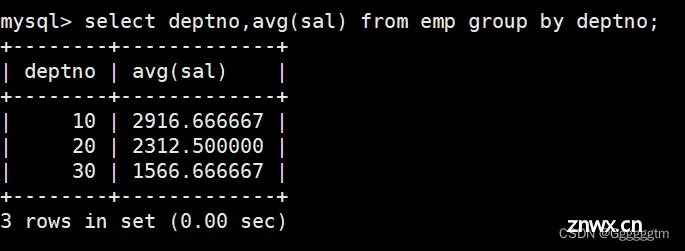
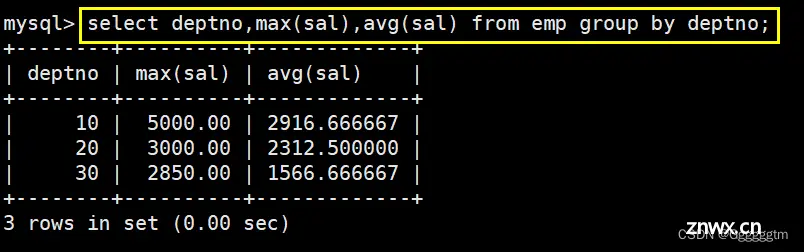
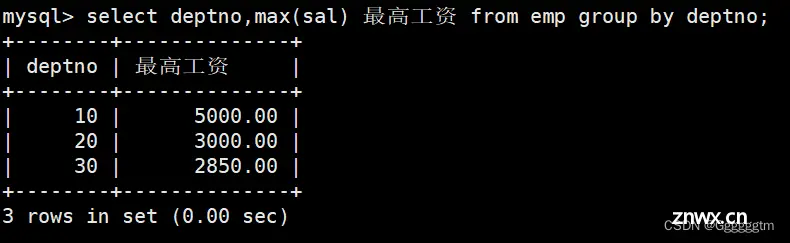
显示每个部门的平均工资和最高工资
我们看到需求是每个部门,那么首先肯定要按部门号进行分组。其次我们再查询每个部门的平均工资和最高工资。具体如下图:
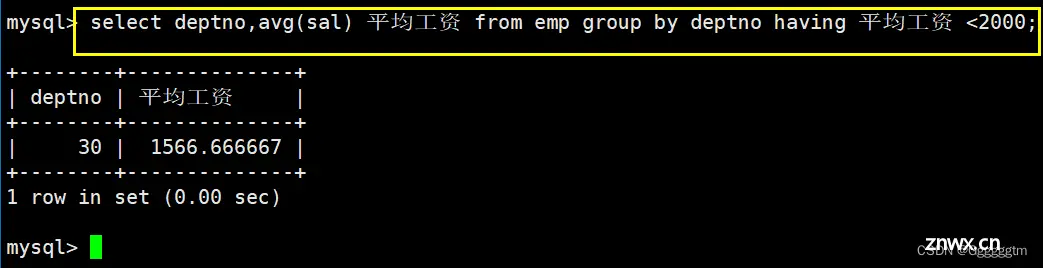
显示平均工资低于2000的部门号和它的平均工资
首先我们很容易可以找到各个部门的平均工资,然后只需要再增加一个条件判断即可。具体如下:

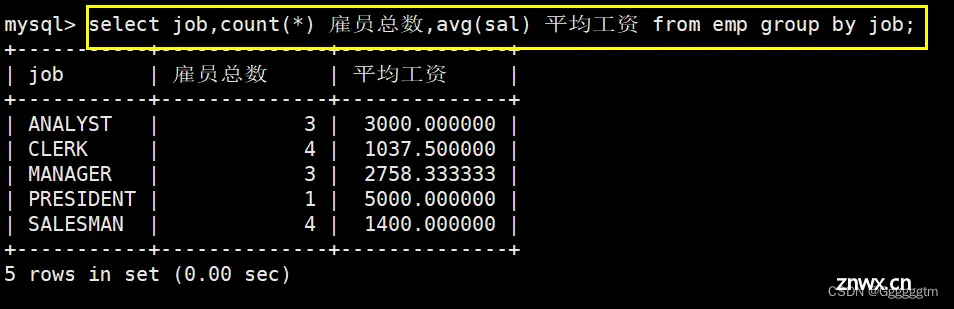
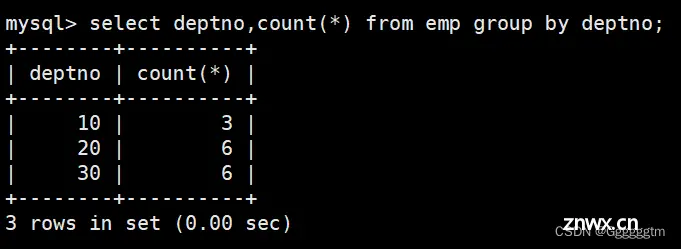
显示每种岗位的雇员总数,平均工资
注意是每种岗位,所以需要根据job进行分组查询。具体如下图:
二、多表查询
2、1 笛卡尔积
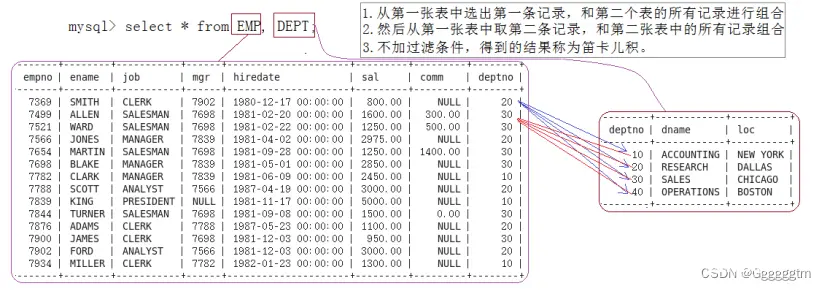
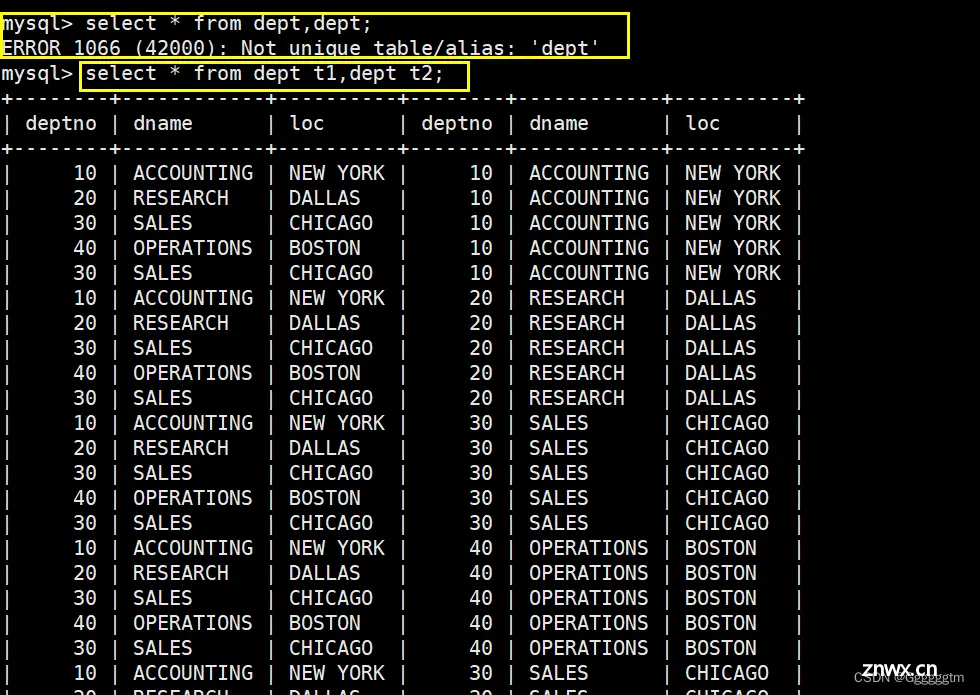
在MySQL中,多表查询的笛卡尔积(Cartesian Product)是指在没有使用任何条件或连接的情况下,将两个或多个表中的所有行进行组合的结果集。这种情况通常是在没有明确指定连接条件或者WHERE子句的情况下进行的查询,但在实际应用中,很少需要或者希望获得笛卡尔积结果。
以下是一个简单的说明以及一个示例来解释笛卡尔积:
笛卡尔积的性质: 笛卡尔积将参与查询的每个表的所有可能组合都返回,即第一个表的每一行都会与第二个表的每一行进行组合,生成的结果集的行数为各个表行数的乘积。
示例:我们现在将员工表和部门表进行笛卡尔积。具体如下:
其实我们也不难看出,规律就是如下图:

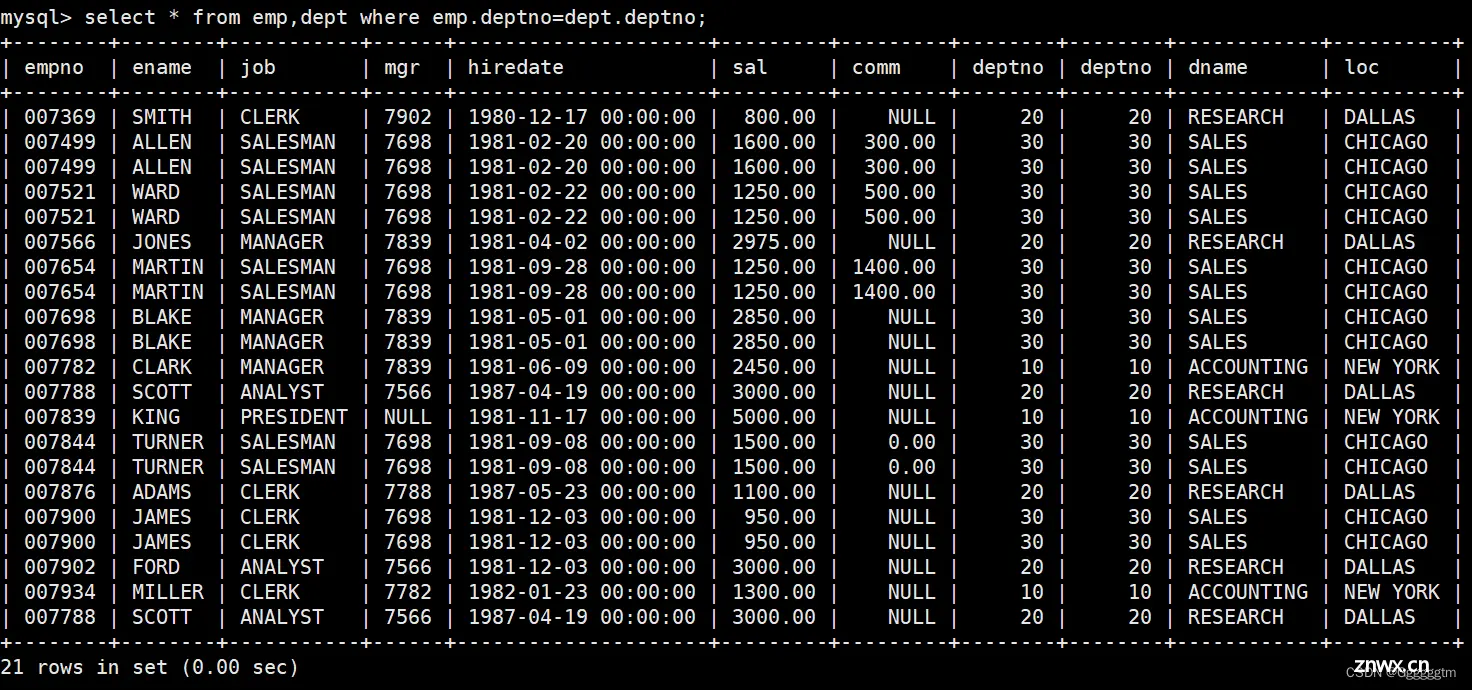
但是往往我们用笛卡尔积所获取的表有很多的数据冗余。因为它会产生大量的冗余数据并且效率低下。为了避免得到笛卡尔积,我们需要正确地使用连接条件(例如使用where条件来筛选掉无用信息)来明确指定表之间的关联关系。例如,在对上述的员工表和部门表进行笛卡尔积时,一个员工不可能会有多个部门号,所以只有部门号相同的才算是有效的信息。最终有效结果如下图:

2、2 多表查询练习
显示部门号为
10
的部门名,员工名和工资
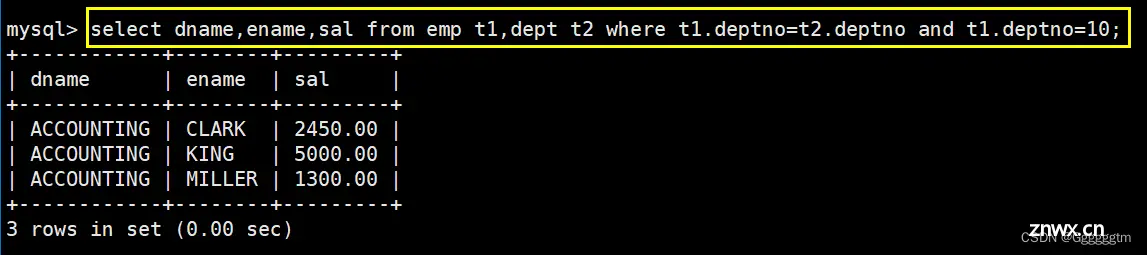
我们发现员工表中并没有我们想要的部门名,所以我们需要进行多表查询。需要将员工表和部门表进行合并查询。然后在查询部门号为10的部门名、员工名和工资。具体如下:
这里再说明一下:上述
SQL语句中 from 后 的 t1 和 t2 是对 emp 和 dept 表进行了重命名,后续都可以
用我们重命名的名字去代替表名字。其次是当我们将两张表拼接到一块后,表中会有
两个deptno,所以我们在使用deptno时,需要指定是那个表的。

显示各个员工的姓名,工资,及工资级别
我们发现工资等级只有在薪资表中有,所以我们需要进行多表查询。当我们将员工表与薪水表进行笛卡尔积后,发现很多数据是冗余的。只有薪资符合它所在的等级区间才是有效的。所以我们的查寻结果如下:
三、自连接
我们上述讲解的是两张不同的表进行连接。那么可以自己与自己的表进行连接吗?答案是可以的!MySQL中的自连接是指在同一张表中进行连接操作。这种连接通常用于将表中的数据与自身进行比较或者组合。自连接可以通过将表与自身进行别名来实现,从而使得查询可以使用表中的不同行进行比较和操作。 我们看如下例子:
通过上图我们发现,当进行自连接时,如果不对表进行取别名,那么将不能够进行自连接。必须对表进行取别名。自连接的使用场景是什么呢?我们看如下例子。
显示员工FORD的上级领导的编号和姓名(mgr是员工领导的编号--empno)
员工是在emp表中,上级领导也是员工,也在emp表中。我们可能首先会想到用子查询来解决,相对简单。具体如下:
但是我们也不难发现,要查询的两个条件都是在emp表中,那么我们就可以对emp表进行自连接。我们现在把两张表想象成一张表是员工表,另一张表是领导表。我们现在需要的有效信息是:员工表中的mgr = 领导表中的empno即可。筛选出有效信息后在选择员工表中的员工为FORD。具体如下:
四、子查询
子查询的概念在上文中已经解释过,这里就不再解释。在子查询的子句中,子句查询出的结果可能不止是一行记录,也有可能是多行记录,还有就是多列的情况。下面我们一一来分析一下。
4、1 单行子查询
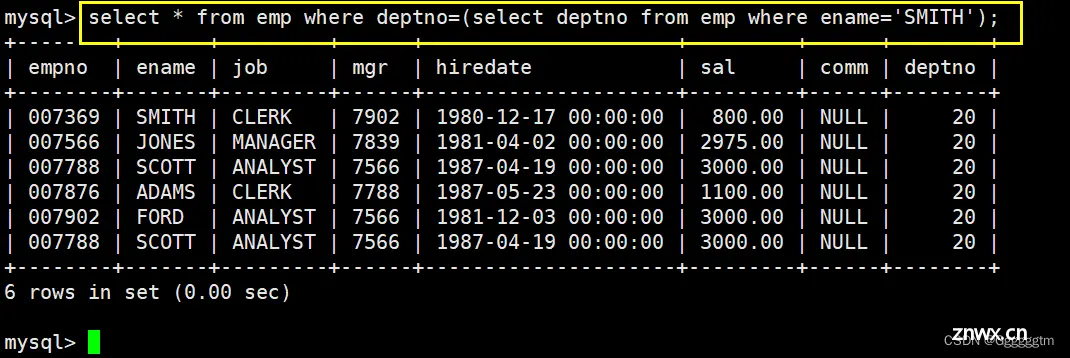
显示
SMITH
同一部门的员工
首先将SMITH的部门号查出,然后再将该部门的所有员工筛选出即可。具体如下:
4、2 多行子查询
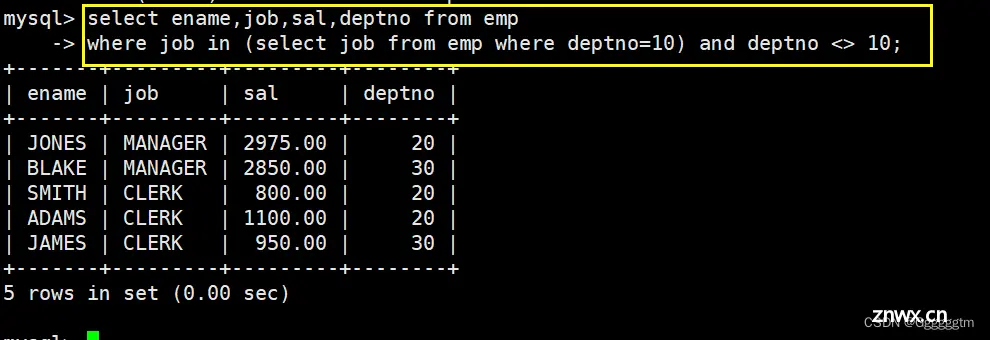
查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的
我们可以先查询出10号部门的工作岗位,具体如下:
然后我们再进行筛选与上图中岗位相同的雇员的信息。当我们想用子查询时,发现上图的岗位并不是一个,那该怎么办呢?这时候可以用到 in关键字。in关键字用于检查某个值是否在一组值中。刚好符合我们的需求。具体如下:
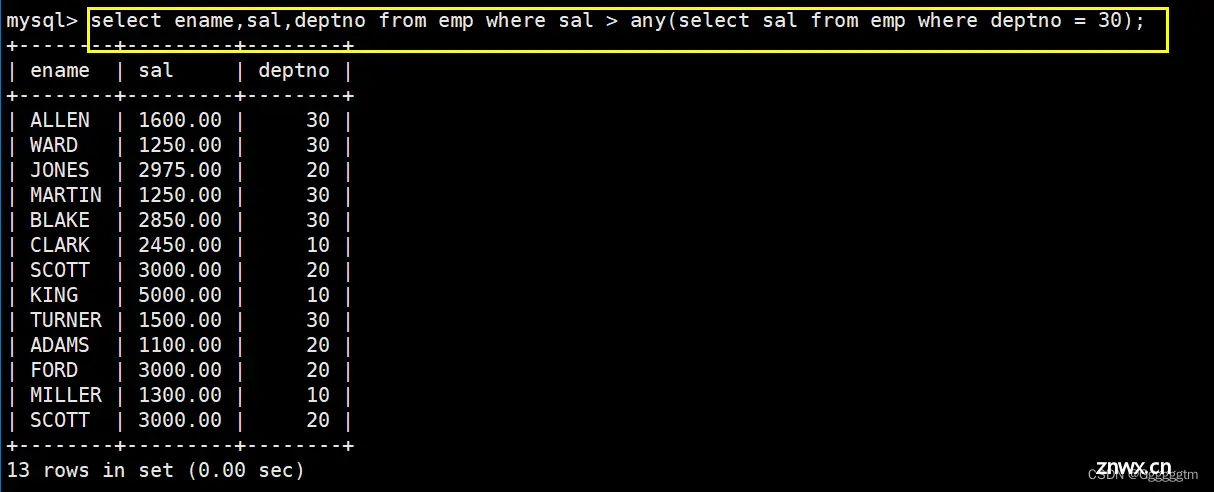
显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
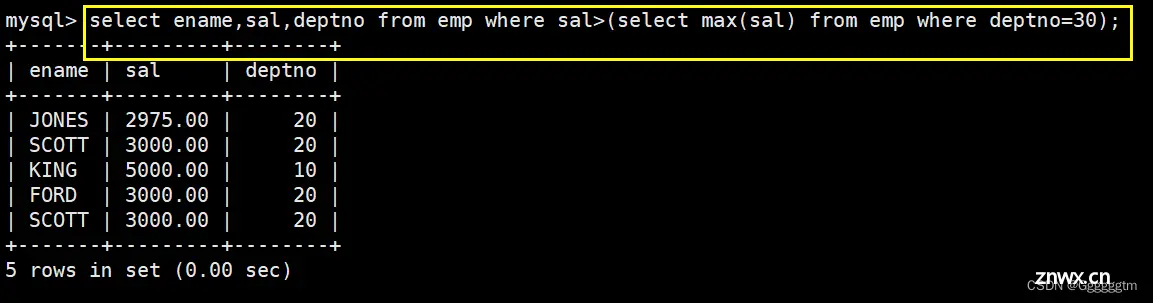
题目的要求:找出比30号部门所有员工工资都好的员工信息。也就是比30号部门最高工资还要高的部门。我们首先找出30号部门的员工最高工资,再筛选出薪资比它大的即可。具体如下:
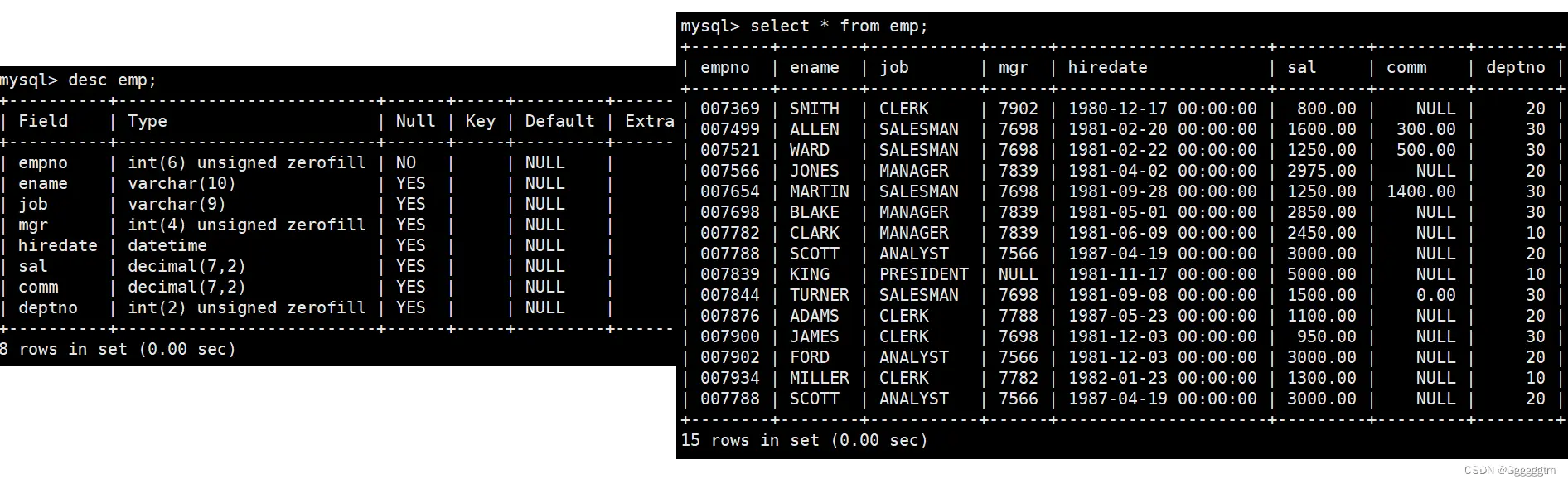
我们也可以使用all关键字。all关键字用于比较外部查询和子查询返回的所有值。当使用 all关键字时,外部查询的值必须满足子查询返回的所有值的条件才会被选中。具体如下:
显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
注意:题目中的任意员工,是指的只要有比部门30中的员工工资高的即满足条件。通俗理解:找出比 部门号30的员工中最低工资 高的员工。这时可以用any关键字。
any关键字用于比较外部查询和子查询返回的任意一个值。
当使用 any
时,外部查询的值只需要满足子查询返回的任意一个值的条件即可被选中。具体如下:
4、3 多列子查询
单行子查询是指子查询只返回单列,单行数据;多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子查询则是指查询返回多个列数据的子查询语句。下面我们来看一个例子。
查询和
SMITH
的部门和岗位完全相同的所有雇员,不含
SMITH
本人
我们可以先查询出来SMITH的部门和岗位。如下图:
我们发现,要和SMITH的部门和岗位完全相同,是多列的情况。这该怎么办呢?我们看如下:
但是题目中还要求了不能包含SMITH本人。所以再把SMITH本人去掉即可。结果如下:
4、4 在from子句中使用子查询
我们之前学到的from后都是跟的表的名字。在from子句中使用子查询怎么理解呢?使用子查询无非就是一个查询语句中嵌套了一个语句。我们就称之为子句。那么子句查询出来的结果我们也可看成一张表,可与其他物理上实力存在的表进行连接。这就是在from子句中使用子查询的意思。下面我们结合实际例子来理解一下。
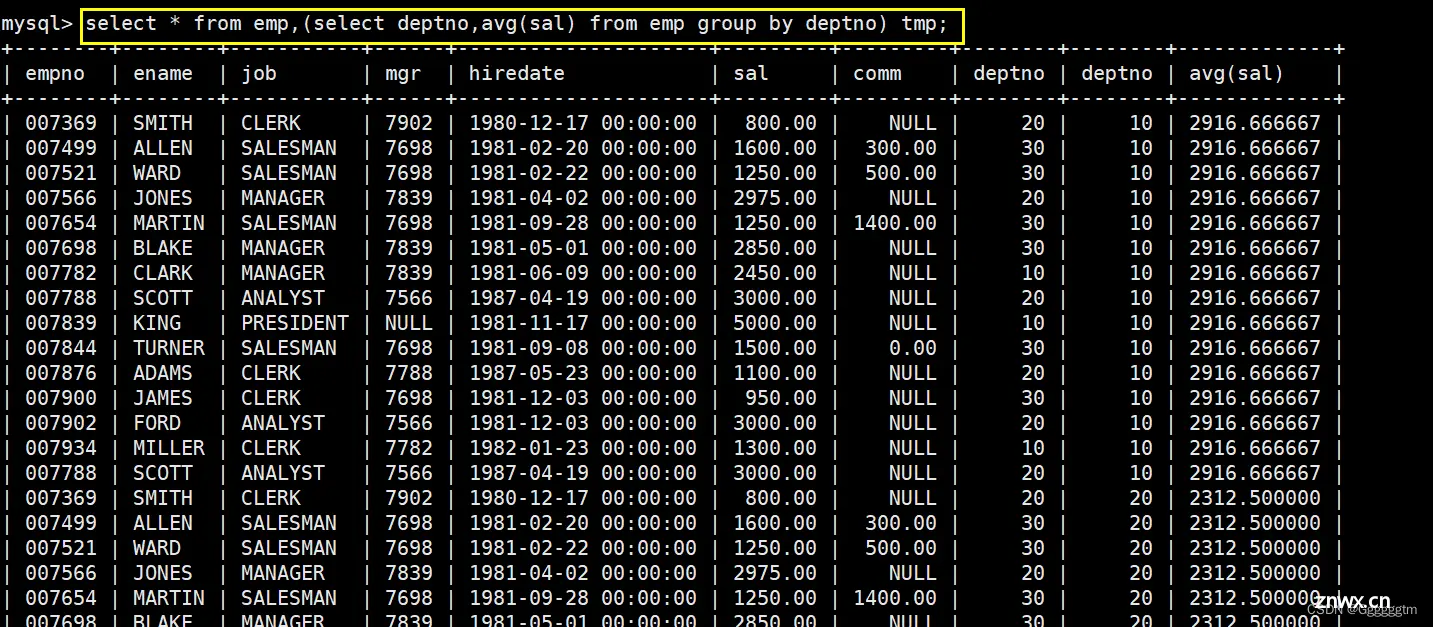
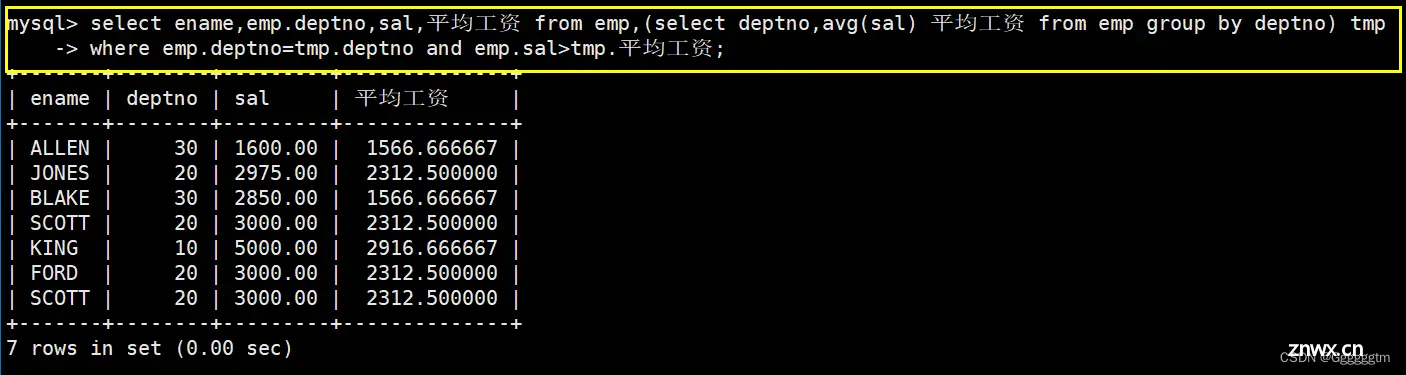
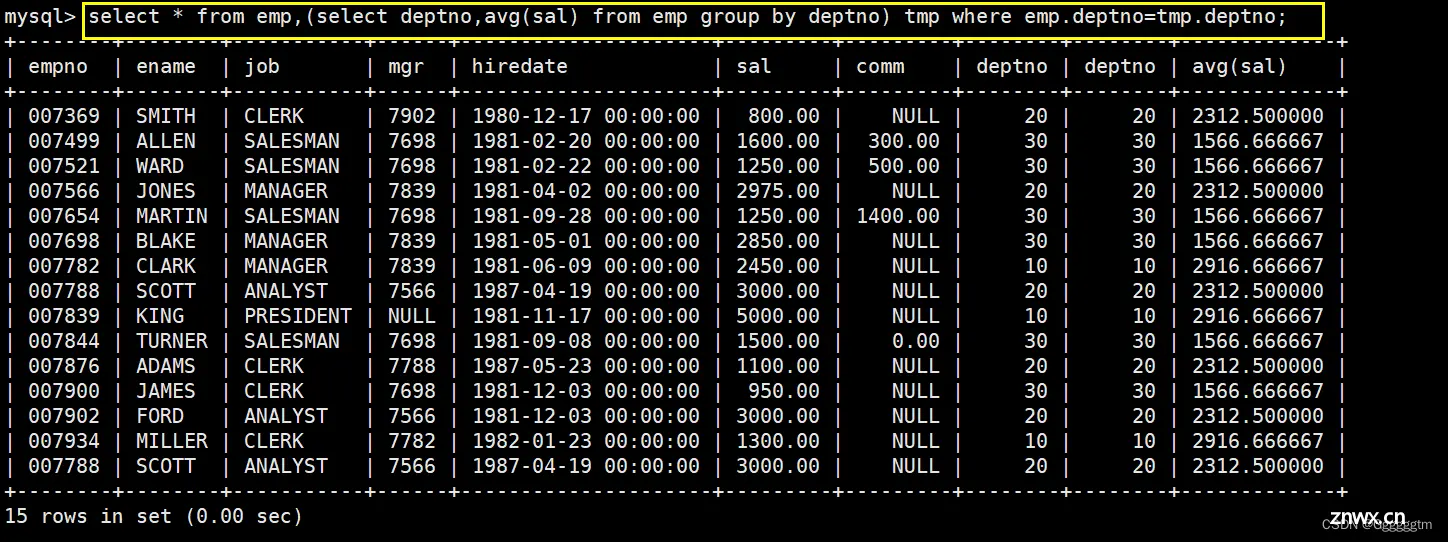
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
我们可以很容易得到每个部门的平均工资,具体如下:
我们可以把上述所查询出来的结果当作一个表,再与emp表进行连接即可。具体如下:
对我们来说,有用的信息就是emp.deptno = tmp.deptno。那么查询出来的结果如下:
现在我们只需要emp.sal > tmp.平均工资( avg(sal)) 即可,就是题目所要求的答案,具体如下:



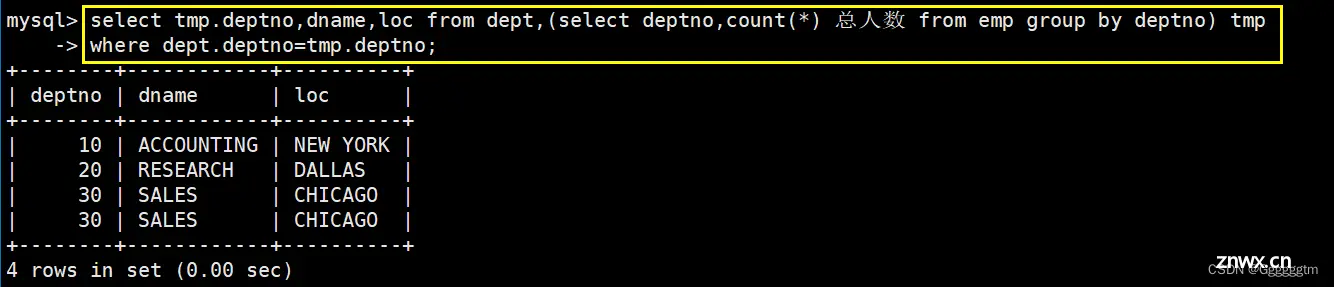
显示每个部门的信息(部门名,编号,地址)和人员数量
我们发现,部门名和地址都在部门表中,而我们想要统计每个部门的人员数量还需要在emp表中统计。我们先来统计每个部门的人员数量,具体如下:
我们再将上述查询的结果与部门dept表进行连接,得到有用信息如下图:
此时,我们在获取题目中的所需要的信息就相当容易了。具体如下图:


查找每个部门工资最高的人的姓名、工资、部门、最高工资
首先,我们可以很容易的得到每个部门的最高工资,如下图:
但是怎么获取工资最高的人的信息呢?这时候可以将我们查询的结果与emp表连接,再获取该人的信息就可以了。具体如下:
五、合并查询
在MySQL中,合并查询指的是将多个查询结果合并成一个结果集的操作。这可以通过使用union、union all等操作符来实现。以下是对每种操作符的详细解释:
union:union操作符用于将两个或多个select语句的结果合并为一个结果集,并自动去重。
union all:与union类似,但不会自动去重。
下面我们来看几个实际例子来理解一下。
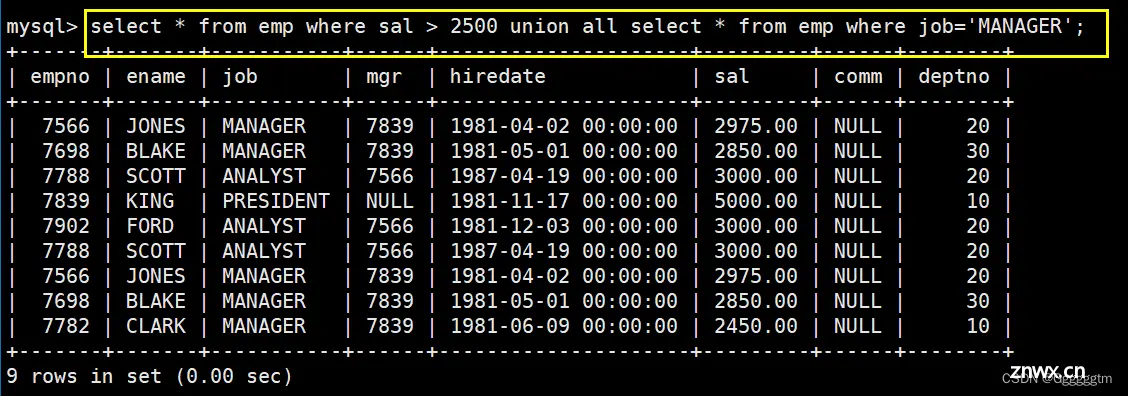
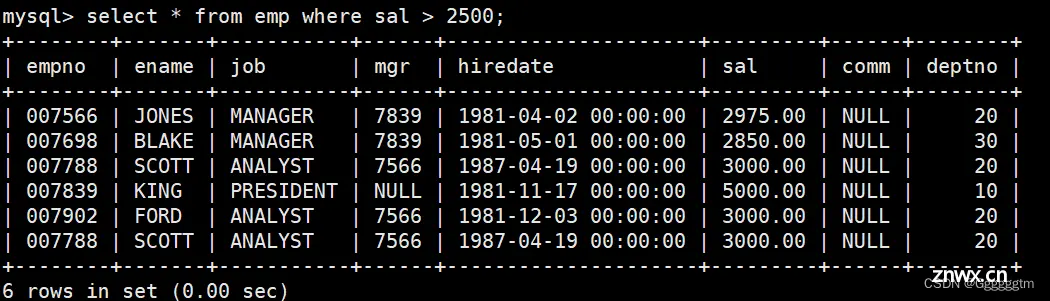
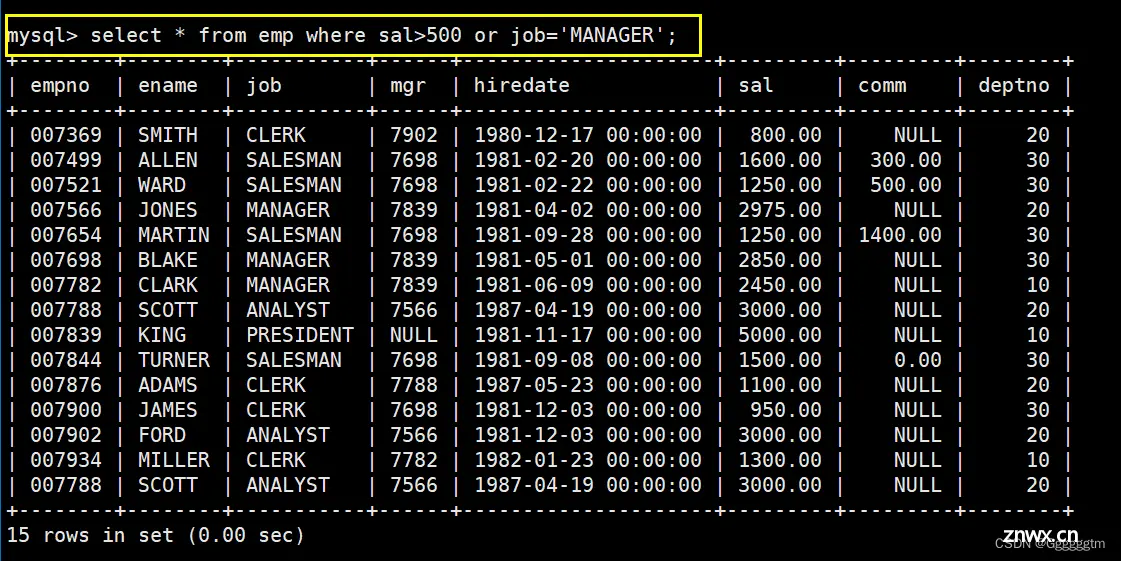
将工资大于
2500
或职位是
MANAGER
的人找出来
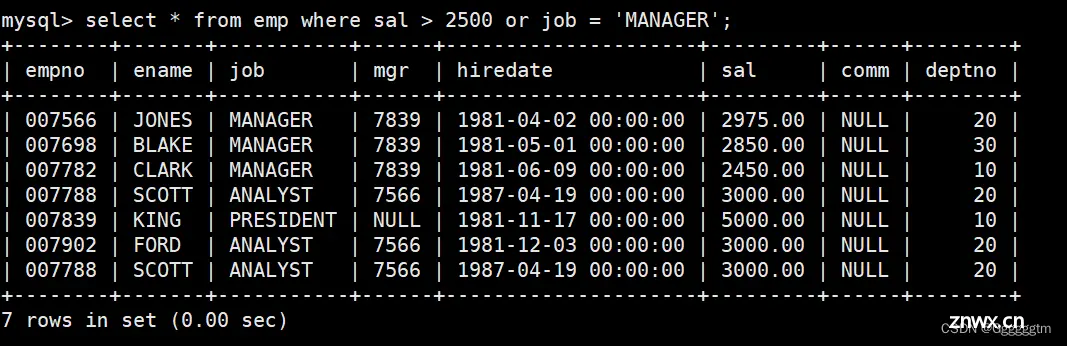
这个例子我们前面已经做过类似的,不再过多解释,直接看下图:
我们也可以先将工资大于2500的人找出来,如下:
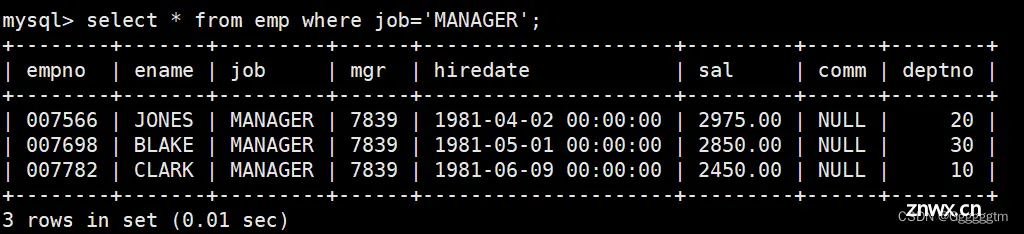
再找出来职位是MANAGER的。如下图:
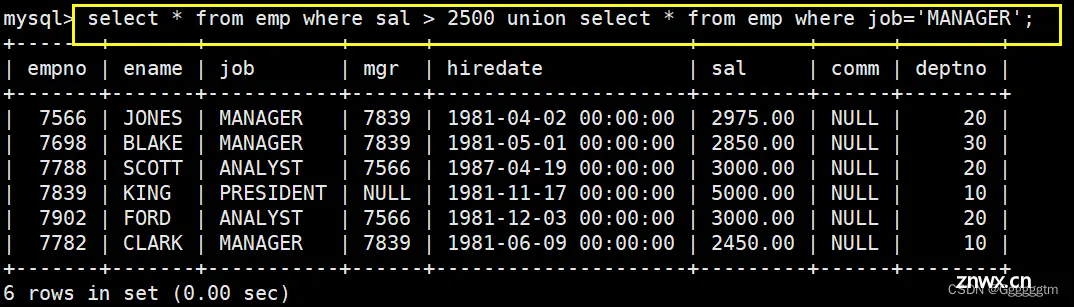
最后用union将他们两个合并即可。具体如下:
我们再来用union all 将他们合并试试。具体如下图:
从上述的对比中,我们也能看出来union是合并并且去重,union all就只是合并。注意:两个select合并的前提是必须所查询出来的列数是相同的。实际中,union并不常用,我们只是了解一下即可。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。