K8s 重设解决 “The connection to the server xxx:6443 was refused” 问题
SmallerFL 2024-09-02 13:07:11 阅读 59
文章目录
1. 引言2. 解决步骤2.1 查看 kubelet 状态2.2 查看 kubelet 日志2.3 kubeadm 重新初始化2.3.1 kubeadm 重新设置2.3.2 kubeadm 初始化2.3.3 配置 kubectl 工具,使其生效2.3.4 验证 kubectl 是否生效2.3.5 安装 flannel2.3.6 查看基础的 pod 状态2.3.7 其他节点加入
3. 参考
1. 引言
有时 kubectl 执行命令时出现问题,无法连接 kube-apiserver,报错如下:
<code>[root@master ~]# kubectl get no
The connection to the server 192.168.127.128:6443 was refused - did you specify the right host or port?
初步判断,kubelet 没有将 apiserver 拉起来。
2. 解决步骤
2.1 查看 kubelet 状态
[root@master manifests]# systemctl status kubelet.service
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; ena>
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: inactive (dead) (Result: exit-code) since Fri 2023-1>
Docs: https://kubernetes.io/docs/
Process: 122248 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFI>
Main PID: 122248 (code=exited, status=255)
上面报错说明 kubelet 没有正常启动。
2.2 查看 kubelet 日志
journalctl -xeu kubelet
日志如下:
12月 15 22:14:17 master.com kubelet[3845]: /workspace/anago-v1.19.4-rc.0.51+5f1e5cafd33a88/src/k8s.io/kubernetes/_output/>
12月 15 22:14:17 master.com kubelet[3845]: created by k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/server.SetupSignalContext
12月 15 22:14:17 master.com kubelet[3845]: /workspace/anago-v1.19.4-rc.0.51+5f1e5cafd33a88/src/k8s.io/kubernetes/_output/>
12月 15 22:14:17 master.com kubelet[3845]: goroutine 61 [select]:
12月 15 22:14:17 master.com kubelet[3845]: k8s.io/kubernetes/vendor/go.opencensus.io/stats/view.(*worker).start(0xc00048a910)
12月 15 22:14:17 master.com kubelet[3845]: /workspace/anago-v1.19.4-rc.0.51+5f1e5cafd33a88/src/k8s.io/kubernetes/_output/>
12月 15 22:14:17 master.com kubelet[3845]: created by k8s.io/kubernetes/vendor/go.opencensus.io/stats/view.init.0
12月 15 22:14:17 master.com kubelet[3845]: /workspace/anago-v1.19.4-rc.0.51+5f1e5cafd33a88/src/k8s.io/kubernetes/_output/>
12月 15 22:14:17 master.com kubelet[3845]: goroutine 90 [select]:
12月 15 22:14:17 master.com kubelet[3845]: k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.BackoffUntil(0x479a590, 0x4>
12月 15 22:14:17 master.com kubelet[3845]: /workspace/anago-v1.19.4-rc.0.51+5f1e5cafd33a88/src/k8s.io/kubernetes/_output/>
12月 15 22:14:17 master.com kubelet[3845]: k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.JitterUntil(0x479a590, 0x12>
12月 15 22:14:17 master.com kubelet[3845]: /workspace/anago-v1.19.4-rc.0.51+5f1e5cafd33a88/src/k8s.io/kubernetes/_output/>
12月 15 22:14:17 master.com kubelet[3845]: k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.Until(...)
12月 15 22:14:17 master.com kubelet[3845]: /workspace/anago-v1.19.4-rc.0.51+5f1e5cafd33a88/src/k8s.io/kubernetes/_output/>
12月 15 22:14:17 master.com kubelet[3845]: k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/util/wait.Forever(0x479a590, 0x12a05f>
12月 15 22:14:17 master.com kubelet[3845]: /workspace/anago-v1.19.4-rc.0.51+5f1e5cafd33a88/src/k8s.io/kubernetes/_output/>
12月 15 22:14:17 master.com kubelet[3845]: created by k8s.io/kubernetes/vendor/k8s.io/component-base/logs.InitLogs
12月 15 22:14:17 master.com kubelet[3845]: /workspace/anago-v1.19.4-rc.0.51+5f1e5cafd33a88/src/k8s.io/kubernetes/_output/>
12月 15 22:14:17 master.com kubelet[3845]: goroutine 93 [syscall]:
12月 15 22:14:17 master.com kubelet[3845]: os/signal.signal_recv(0x0)
12月 15 22:14:17 master.com kubelet[3845]: /usr/local/go/src/runtime/sigqueue.go:147 +0x9d
12月 15 22:14:17 master.com kubelet[3845]: os/signal.loop()
12月 15 22:14:17 master.com kubelet[3845]: /usr/local/go/src/os/signal/signal_unix.go:23 +0x25
12月 15 22:14:17 master.com kubelet[3845]: created by os/signal.Notify.func1.1
12月 15 22:14:17 master.com kubelet[3845]: /usr/local/go/src/os/signal/signal.go:150 +0x45
12月 15 22:14:17 master.com systemd[1]: kubelet.service: Main process exited, code=exited, status=255/n/a
12月 15 22:14:17 master.com systemd[1]: kubelet.service: Failed with result 'exit-code'.
-- Subject: Unit failed
-- Defined-By: systemd
-- Support: https://access.redhat.com/support
--
-- The unit kubelet.service has entered the 'failed' state with result 'exit-code'.
2.3 kubeadm 重新初始化
注意,在生产环境谨慎执行,在测试环境可以考虑使用。注意,在 master 节点上操作。
这部分详细的可以参考 K8s 的 kubeadm 巨细安装,亲操可行!! 的第三、四章。
2.3.1 kubeadm 重新设置
[root@master ~]# kubeadm reset
[reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted.
[reset] Are you sure you want to proceed? [y/N]: y
[preflight] Running pre-flight checks
W1215 22:32:16.656391 123091 removeetcdmember.go:79] [reset] No kubeadm config, using etcd pod spec to get data directory
[reset] No etcd config found. Assuming external etcd
[reset] Please, manually reset etcd to prevent further issues
[reset] Stopping the kubelet service
[reset] Unmounting mounted directories in "/var/lib/kubelet"
[reset] Deleting contents of config directories: [/etc/kubernetes/manifests /etc/kubernetes/pki]
[reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf]
[reset] Deleting contents of stateful directories: [/var/lib/kubelet /var/lib/dockershim /var/run/kubernetes /var/lib/cni]
The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually by using the "iptables" command.
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar)
to reset your system's IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually.
Please, check the contents of the $HOME/.kube/config file.
2.3.2 kubeadm 初始化
apiserver-advertise-address 填成自己的实际主机 ipkubernetes-version 填成自己之前布置的 K8s 版本号
kubeadm init \
--apiserver-advertise-address=192.168.127.128 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.19.4 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16
如果报错如下:
[root@master ~]# kubeadm init \
> --apiserver-advertise-address=192.168.127.128 \
> --image-repository registry.aliyuncs.com/google_containers \
> --kubernetes-version v1.19.4 \
> --service-cidr=10.1.0.0/16 \
> --pod-network-cidr=10.244.0.0/16
W1215 22:31:51.064534 122982 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.19.4
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING FileExisting-tc]: tc not found in system path
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 24.0.7. Latest validated version: 19.03
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
则可以增加 --ignore-preflight-errors=DirAvailable--var-lib-etcd 参数
kubeadm init \
--apiserver-advertise-address=192.168.127.128 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.19.4 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=DirAvailable--var-lib-etcd
执行如下:
W1215 22:33:27.885578 123213 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.19.4
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING FileExisting-tc]: tc not found in system path
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 24.0.7. Latest validated version: 19.03
[WARNING DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
[preflight] Pulling images required for setting up a Kubernetes cluster
...
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.127.128:6443 --token okvbpe.muz4keyu1odq7v1w \
--discovery-token-ca-cert-hash sha256:f372aa35f464f2c25e5fb2d750878748c58e318706787a0ae8d6e5aceecfa523
上面最后出现的 kubeadm join 192.168.127.128:6443 --token ... 这段命令需要保留下,后面其他节点加入集群还需要执行。
2.3.3 配置 kubectl 工具,使其生效
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
2.3.4 验证 kubectl 是否生效
kubectl get node

2.3.5 安装 flannel
<code>kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
2.3.6 查看基础的 pod 状态
kubectl get pod -n kube-system
期间如果发现 coredns 的 pod 出现 crash 的问题,如图:
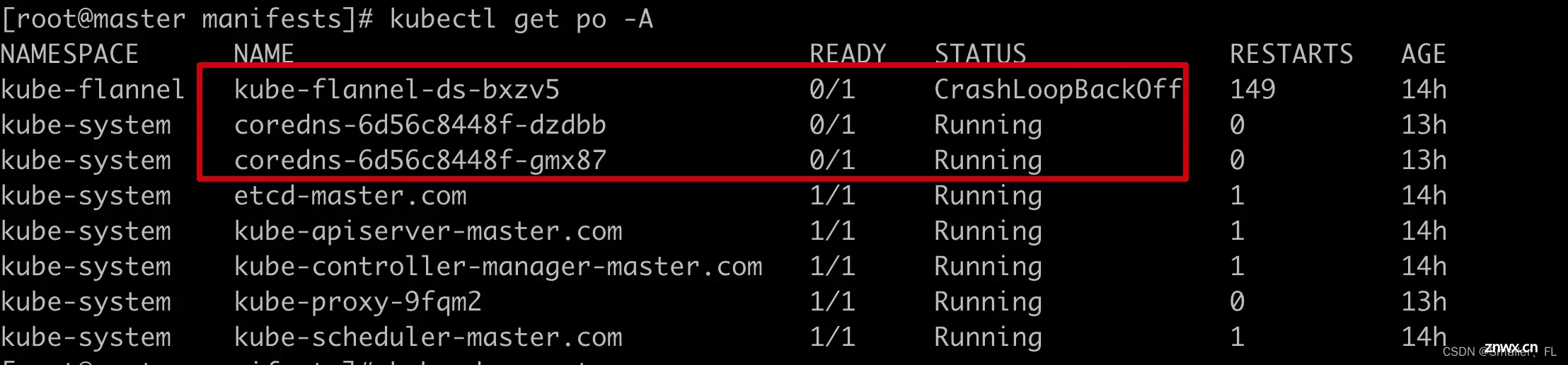
执行 <code>kubectl logs {pod name} -n kube-system 查看日志,发现似乎访问 apiserver 超时了,日志如下:
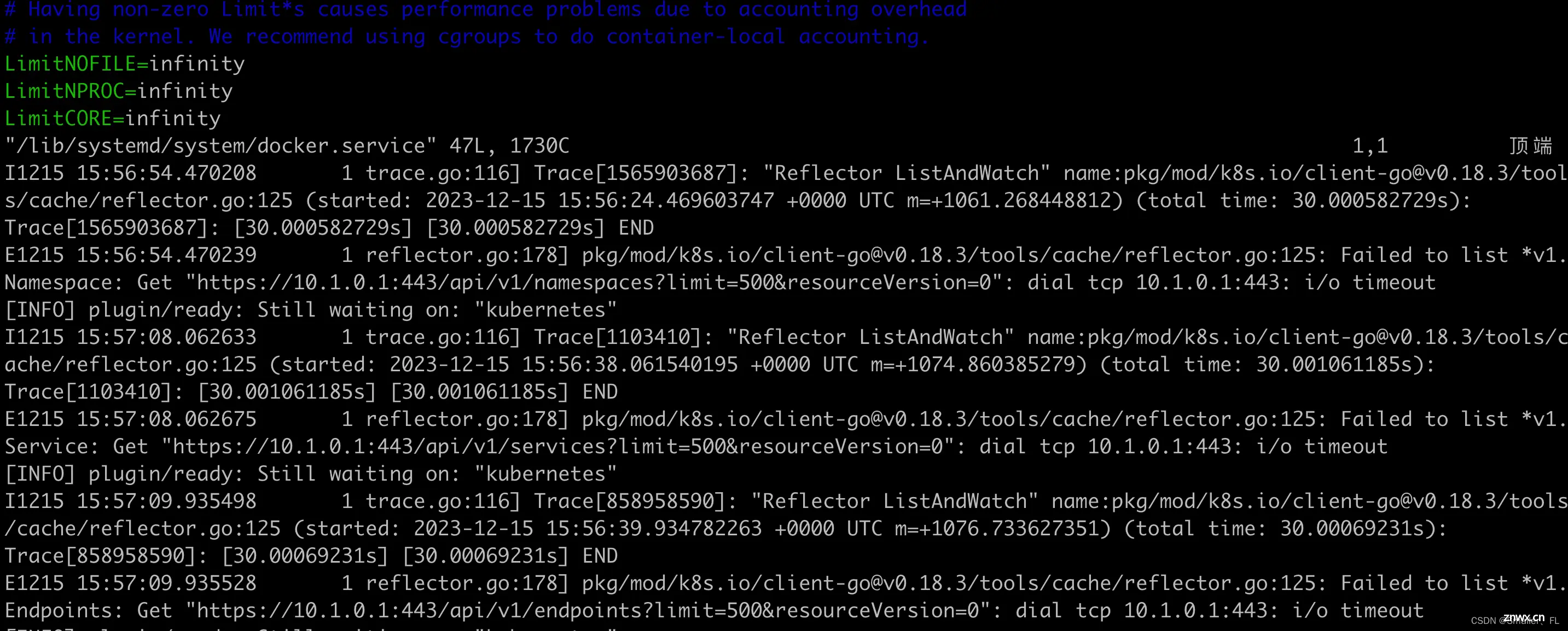
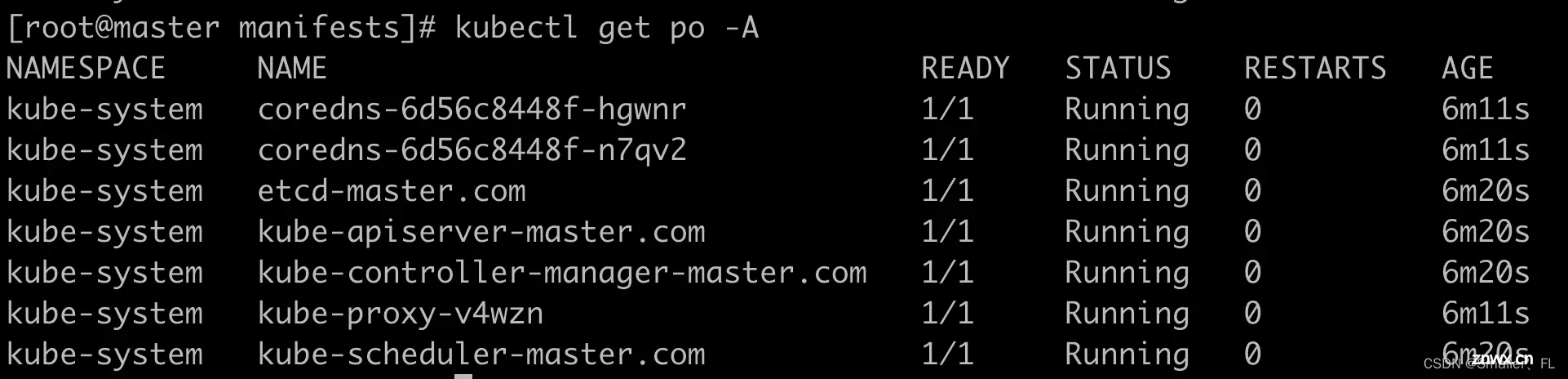
建议可以重新执行下<code>kubeadm reset,即回到之前第一步重新来一遍完整流程。重新配置后正常:
2.3.7 其他节点加入
如果仅一个节点的话,则恭喜您已经 ok。 如果有其他节点,则还需加入到当前 K8s 集群中,
当前只是 master 节点配置完毕,但是 node 节点尚未加入集群。进入到 node 节点中,执行:
<code>kubeadm join 192.168.127.128:6443 --token okvbpe.muz4keyu1odq7v1w \
--discovery-token-ca-cert-hash sha256:f372aa35f464f2c25e5fb2d750878748c58e318706787a0ae8d6e5aceecfa523
(1)如果出现这种问题 certificate has expired or is not yet valid: current time xxx is before xxx,说明当前机器的时间已经落后 master 机器了,校验不通过,需要更新时间。
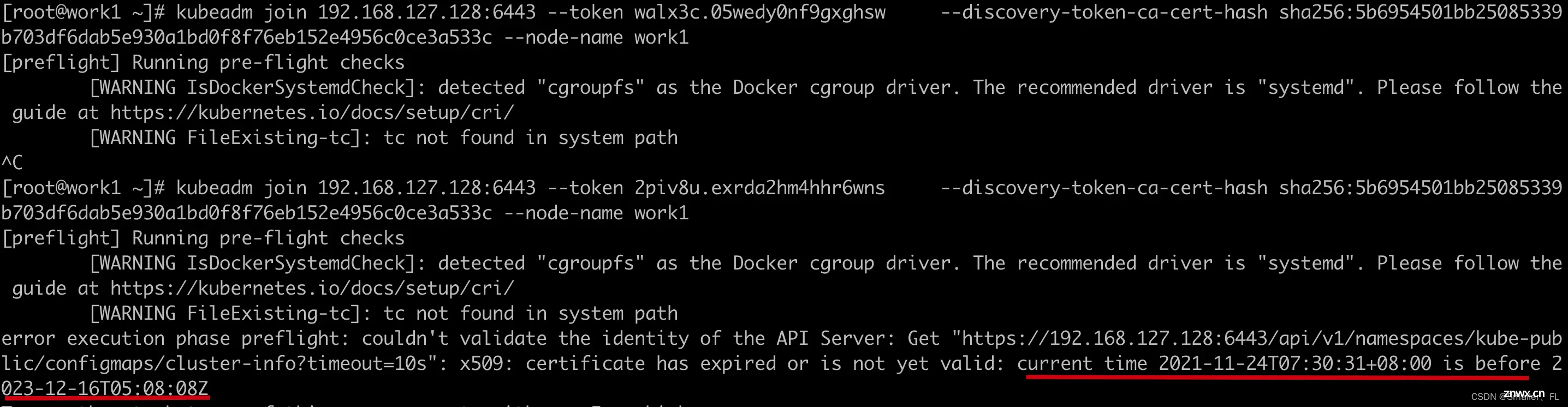
简单的设置系统时间方法:
<code># 以下时间需要写入当前 master 机器的实际时间,差不太多都可以
date -s "20231216 14:51:39 CST"
# 查询时间的方法
date
然后再重新执行上述的 kubeadm join... 命令。
(2)其他情况,可以尝试在 master 重新创建 token
[root@master yum.repos.d]# kubeadm token create --print-join-command
W1216 15:01:30.863248 820010 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
kubeadm join 192.168.127.128:6443 --token ma8zuv.na1ll39dj8cuvwca --discovery-token-ca-cert-hash sha256:5b6954501bb25085339b703df6dab5e930a1bd0f8f76eb152e4956c0ce3a533c
将上面的输出在 node 节点再执行一次
3. 参考
K8s 的 kubeadm 巨细安装,亲操可行!!
K8s 使用 kubectl 访问 api-server 失败,node “XXX“ not found
上一篇: vue项目 部署到nginx 上刷新页面显示404
下一篇: 【Linux高性能服务器编程】——高性能服务器框架
本文标签
K8s 重设解决 “The connection to the server xxx:6443 was refused” 问题
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。