1panel+MaxKB+Ollama+Llama Linux部署指南
hf_hs_1 2024-06-22 11:37:38 阅读 54
目录
1.1panel安装
2.MaxKB
1.MaxKB登录
3.Ollama(gpu)安装
1.安装英伟达容器安装包
1.配置apt源
2.更新源
3.安装工具包
2.使用GPU运行Ollama
3.使用Ollama下载模型
1.修改Ollama下载路径
2.设置使用的显卡(如果想单张使用)
4.MaxKB应用配置
5.模型运行情况
6.本地环境版本
1.1panel安装
输入指令:
ubuntu:curl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start.sh && sudo bash quick_start.sh
RedHat/Centos:curl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start.sh && sh quick_start.sh
Debian:curl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start.sh && bash quick_start.sh
openEuler/其他:
第一步:安装 docker
bash <(curl -sSL https://linuxmirrors.cn/docker.sh)
第二步:安装 1Panel
curl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start.sh && sh quick_start.sh
安装成功后,控制台会打印面板访问信息,可通过浏览器访问 1Panel:
http://目标服务器 IP 地址:目标端口/安全入口
2.MaxKB
打开上面1panel地址,打开应用商城,点击MaxKB就可以安装了。这是docker方式安装的,安装前需要配置好docker。
如果出现docker安装失败,出现408,即配置docker源:
http://prod-reg.hydevops.com
https://reg.hydevops.com
https://docker.mirrors.ustc.edu.cn
https://hub-mirror.c.163.com
https://dockerproxy.com
https://mirror.baidubce.com
https://ccr.ccs.tecentyun.com
1.MaxKB登录
链接为http://ip+已配置好的端口,端口可以在此查看
首次登陆,账号密码为:
username:admin
password:MaxKB@123..
3.Ollama(gpu)安装
1.安装英伟达容器安装包
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
1.配置apt源
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
2.更新源
sudo apt-get update
3.安装工具包
sudo apt-get install -y nvidia-container-toolkit
2.使用GPU运行Ollama
docker run --gpus all -d -v /opt/ai/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
需要注意的:其中-p后面的的第一个11434是连接时的端口号,如果有端口冲突可以改变,若没有,则可默认。
3.使用Ollama下载模型
llama3:70b可以替换为你需要下载模型的名称。
docker exec -it ollama ollama run llama3:70b
如果在pull过程中出现EOF问题,可以再次输入该指令继续下载。
1.修改Ollama下载路径
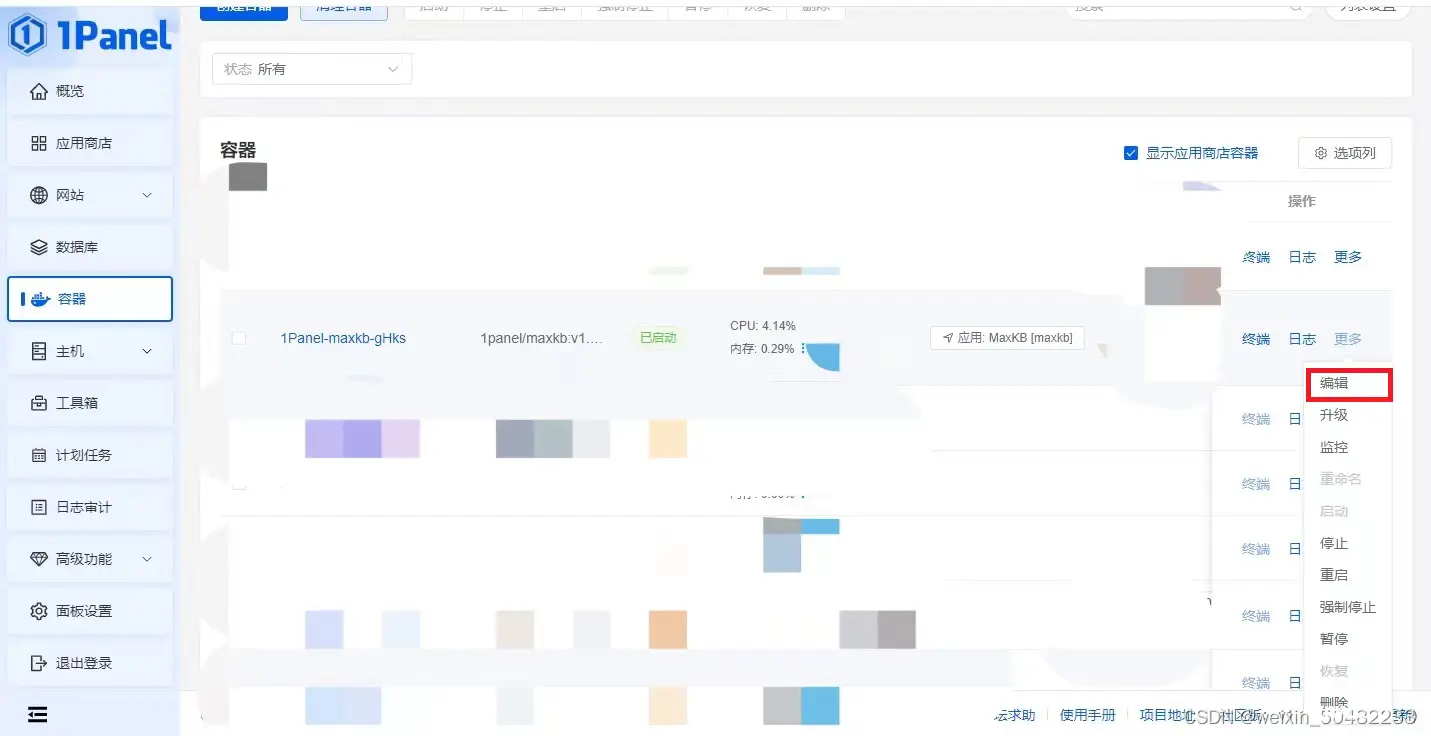
打开1panel,打开容器,点击ollama,先将ollama暂停。
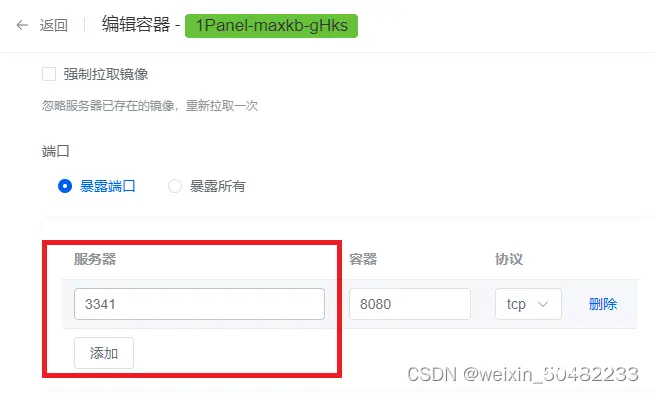
打开编辑,可以直接修改文件保存的路径 ,即本机目录。这样就缓解了本地硬盘存储空间不足的问题。

2.设置使用的显卡(如果想单张使用)
同样是在编辑中,可在NVIDIA_VISIBLE_DEVICES中更改使用的显卡参数。可以在linux中使用nvidia-smi查看你想使用显卡的编号。

4.MaxKB应用配置
最主要是api域名要写正确 ,使用的是docker安装定义的端口,http://ip+端口,如果没有改变,则默认为11434。API Key可以随便写。
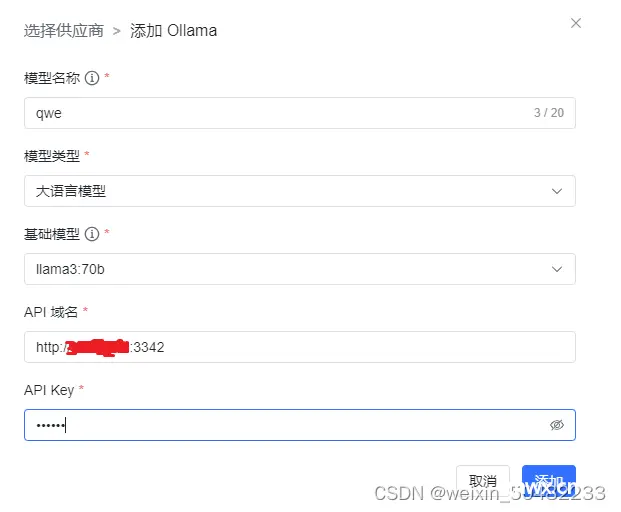
需要注意:这不是在线安装,需要你事先在本地中下载好模型,若忘记,可以返回查看3.3如何下载模型。
之后可以添加应用了,也可以加入自己的知识库,选择好模型,点击创建,就完成了。
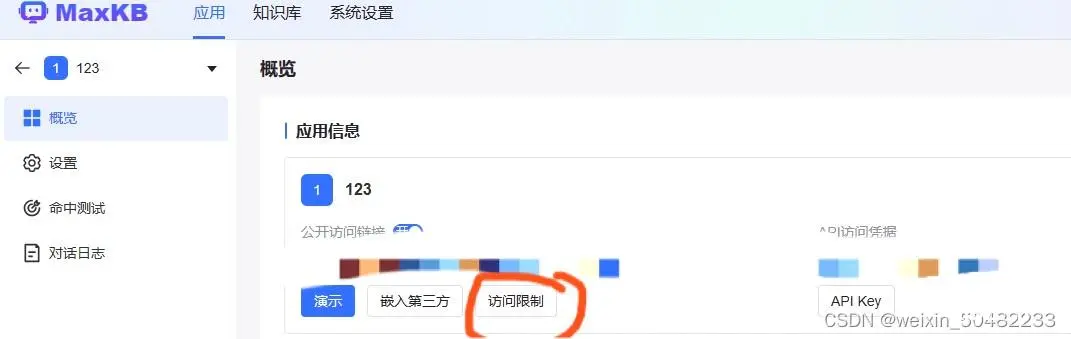
如果在演示中,出现限制次数问题,可以在应用中,点击应用设置,选择访问限制,可以调到10000。
5.模型运行情况
本地运行的llama3:8b,一张2080ti就可以运行起来(本地有2张2080ti+3080),该显卡情况(32G显存)运行不起来llama3:70b。
llama3:70b,一张A100(80G显存)可以运行起来,45G显存就可以运行,但能不能推理没尝试过。
6.本地环境版本
ubuntu:20.04.6 LTS
docker:24.0.5
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。