开源模型应用落地-LangSmith试炼-入门初体验-监控和自动化(五)
开源技术探险家 2024-06-26 14:07:12 阅读 79
一、前言
在许多应用程序中,特别是在大型语言模型(LLM)应用程序中,收集用户反馈以了解应用程序在实际场景中的表现是非常重要的。
LangSmith可以轻松地将用户反馈附加到跟踪数据中。通常最好提供一个简单的机制(如赞成和反对按钮)来收集用户对应用程序响应的反馈。然后,再使用 LangSmith SDK 或 API 发送跟踪反馈。 本章学习Monitoring and automations功能,帮助开发者更好地管理和优化LangChain应用程序,提高其性能、可靠性和用户体验。
二、术语
2.1.Monitoring and automations
具体功能包括:
数据收集与分析:收集应用程序在运行过程中的各种数据,如输入、输出、响应时间等,并进行分析和统计,以了解应用程序的性能和行为。性能监控:实时监测应用程序的性能指标,如响应时间、吞吐量、资源利用率等,及时发现性能问题并进行预警。错误检测与预警:检测应用程序在运行过程中出现的错误、异常或故障,并及时发出预警信息,以便开发者及时采取措施进行修复。自动化测试:支持自动化测试,通过预设的测试用例对应用程序进行定期测试,以确保其功能的正确性和稳定性。报告与可视化:生成详细的监控报告和可视化图表,帮助开发者更好地理解应用程序的性能和问题,并为决策提供依据。
2.2.LangChain
是一个全方位的、基于大语言模型这种预测能力的应用开发工具。LangChain的预构建链功能,就像乐高积木一样,无论你是新手还是经验丰富的开发者,都可以选择适合自己的部分快速构建项目。对于希望进行更深入工作的开发者,LangChain提供的模块化组件则允许你根据自己的需求定制和创建应用中的功能链条。
LangChain本质上就是对各种大模型提供的API的套壳,是为了方便我们使用这些 API,搭建起来的一些框架、模块和接口。
LangChain的主要特性:
1.可以连接多种数据源,比如网页链接、本地PDF文件、向量数据库等
2.允许语言模型与其环境交互
3.封装了Model I/O(输入/输出)、Retrieval(检索器)、Memory(记忆)、Agents(决策和调度)等核心组件
4.可以使用链的方式组装这些组件,以便最好地完成特定用例。
5.围绕以上设计原则,LangChain解决了现在开发人工智能应用的一些切实痛点。
2.3.LangSmith
是一个用于构建生产级 LLM 应用程序的平台,它提供了调试、测试、评估和监控基于任何 LLM 框架构建的链和智能代理的功能,并能与 LangChain 无缝集成。其主要作用包括:
调试与测试:通过记录langchain构建的大模型应用的中间过程,开发者可以更好地调整提示词等中间过程,优化模型响应。评估应用效果:langsmith可以量化评估基于大模型的系统的效果,帮助开发者发现潜在问题并进行优化。监控应用性能:实时监控应用程序的运行情况,及时发现异常和错误,确保其稳定性和可靠性。数据管理与分析:对大语言模型此次的运行的输入与输出进行存储和分析,以便开发者更好地理解模型行为和优化应用。团队协作:支持团队成员之间的协作,方便共享和讨论提示模板等。可扩展性与维护性:设计时考虑了应用程序的可扩展性和长期维护,允许开发者构建可成长的系统。
2.4.LangChain和LangSmith的关系
LangSmith是LangChain的一个子产品,是一个大模型应用开发平台。它提供了从原型到生产的全流程工具和服务,帮助开发者构建、测试、评估和监控基于LangChain或其他 LLM 框架的应用程序。
LangSmith与LangChain 的关系可以概括为:LangChain是一个开源集成开发框架,而 LangSmith是基于LangChain 构建的一个用于大模型应用开发的平台。
三、前提条件
3.1.安装虚拟环境
conda create --name langsmith python=3.10
conda activate langsmith
pip install -U langsmith -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple
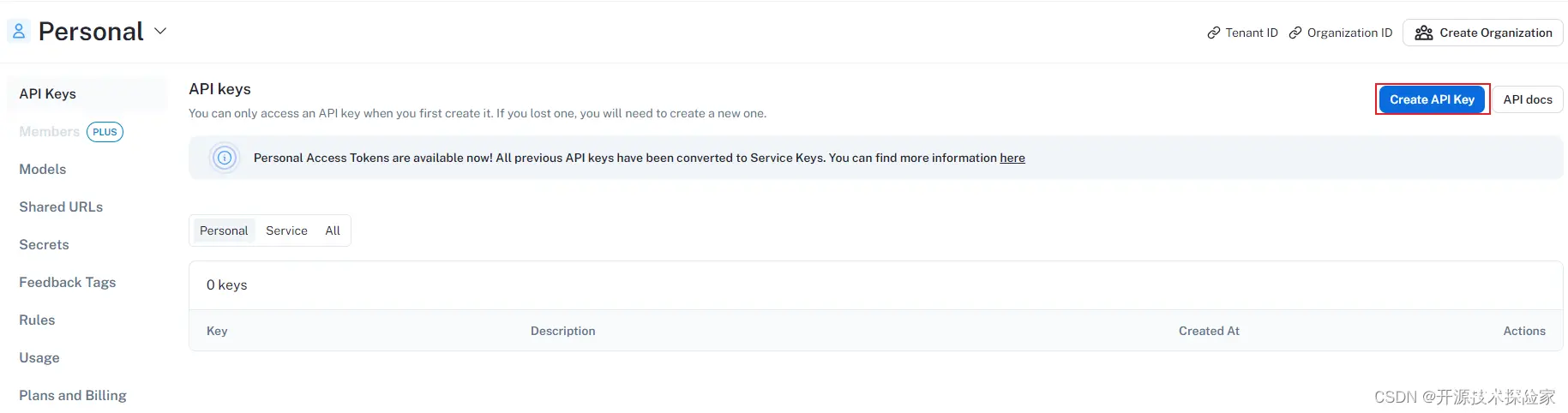
3.2.创建API key
操作入口:LangSmithhttps://smith.langchain.com/settings未登录的需要先进行登录:
登录成功:
点击Settings:

点击Create API Key:
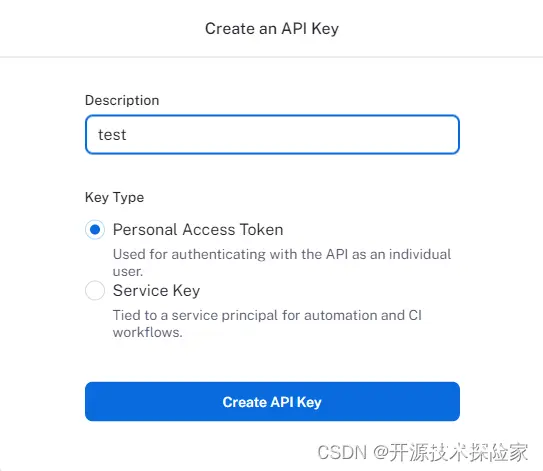
记录API Key:
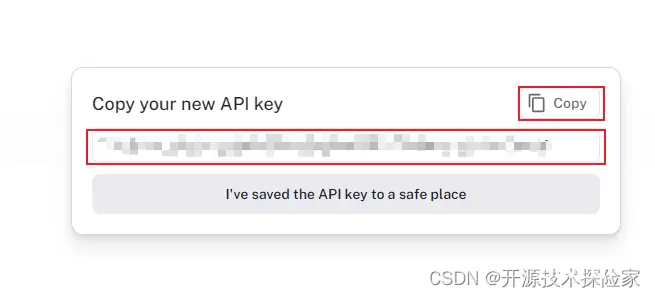
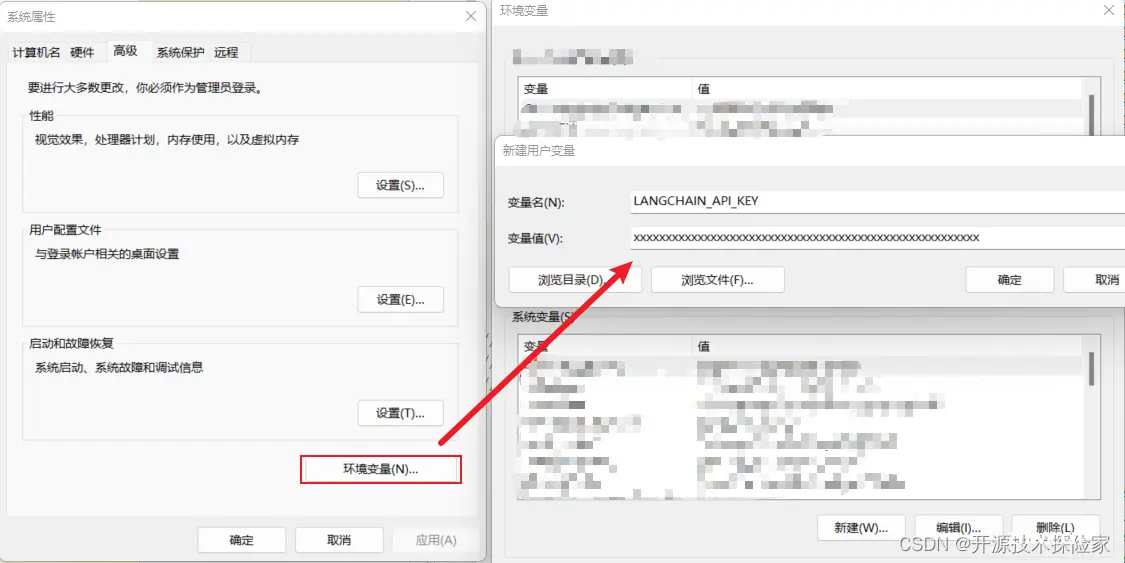
3.3.设置环境变量
windows:
linux:
export LANGCHAIN_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
ps:
1.需要替换3.2创建的API Key
四、技术实现
4.1.在应用程序中过滤数据
4.1.1.导航栏过滤

PS:默认情况下,会自动创建IsRoot为 true的过滤条件
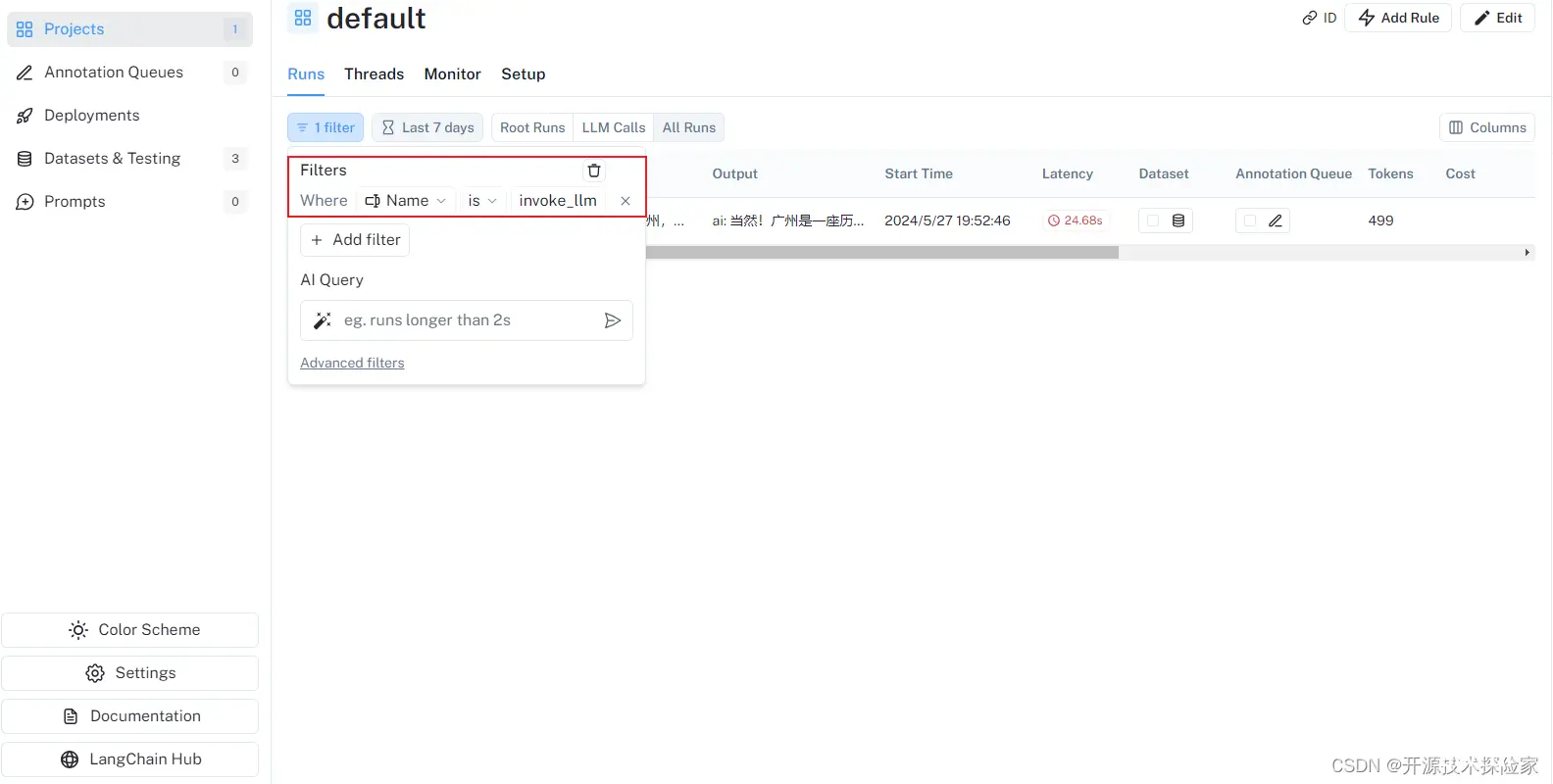
4.1.1.1.根据属性过滤
根据自定义条件过滤,例如:Name为invoke_llm
全文检索,例如:Full-Text Search为"导游"
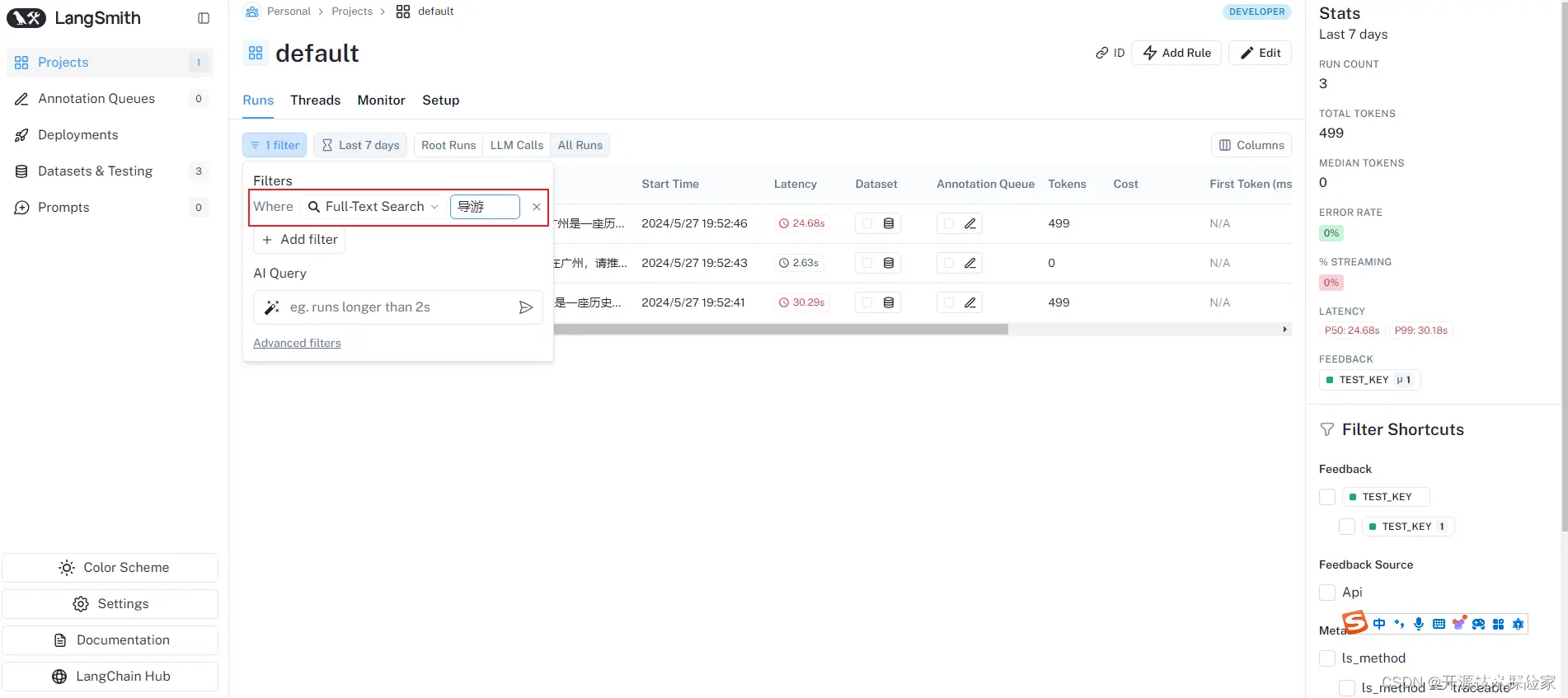
4.1.1.2.根据查询语言过滤
在Raw Query中输入:eq(feedback_key,"test_key")
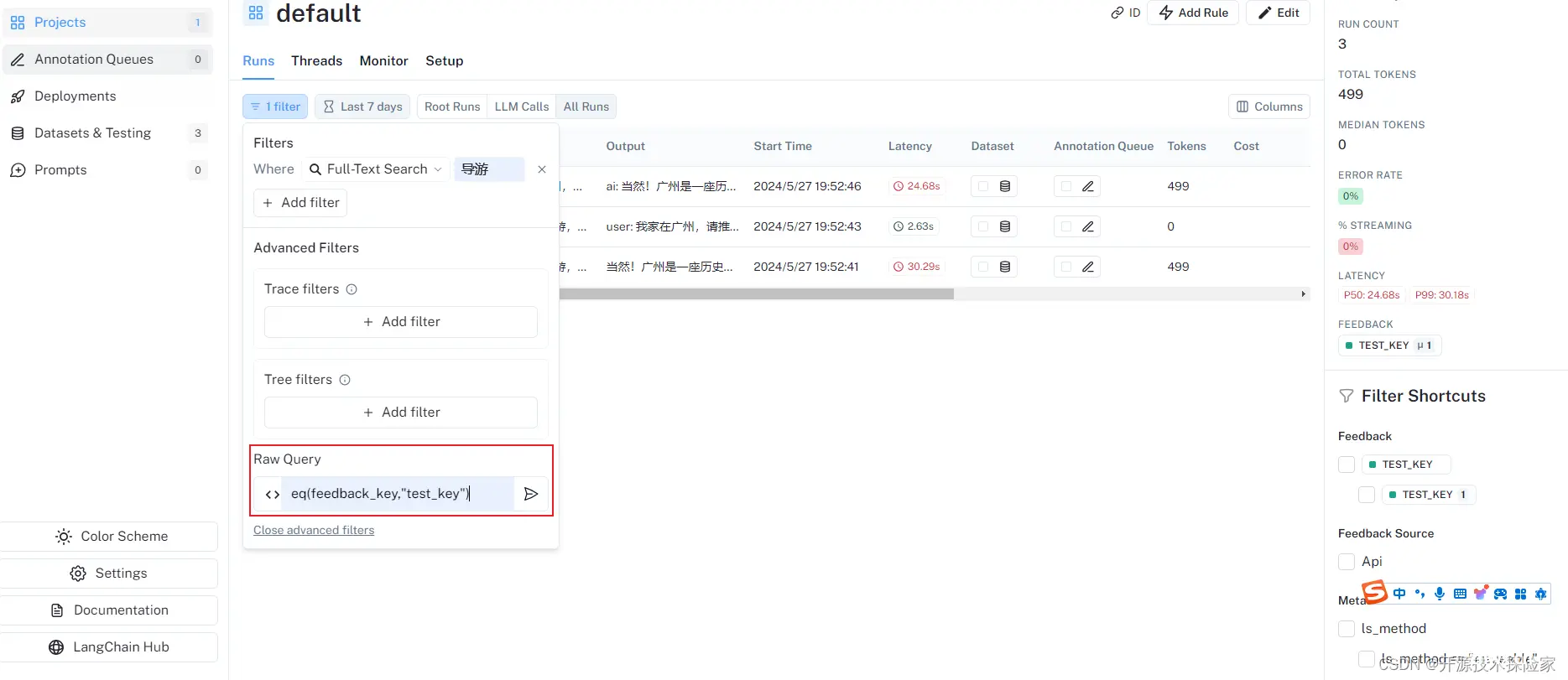
点击添加后,会把Raw查询添加到现有查询中(不是覆盖现有的查询条件)

4.1.1.3.根据AI自动生成过滤条件
在AI Query中输入“导游”
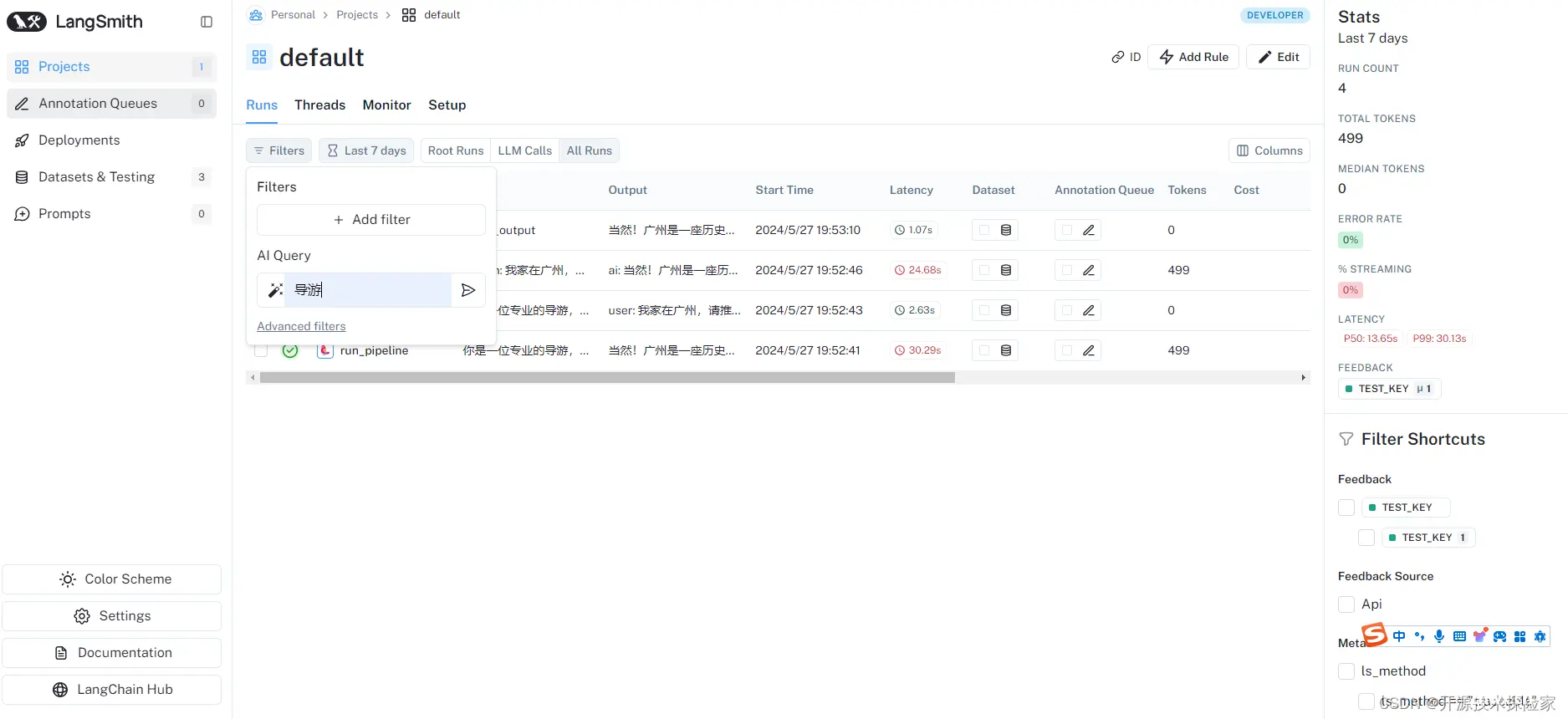
点击添加后,会自动生成Full-Text Search为"导游"的过滤条件
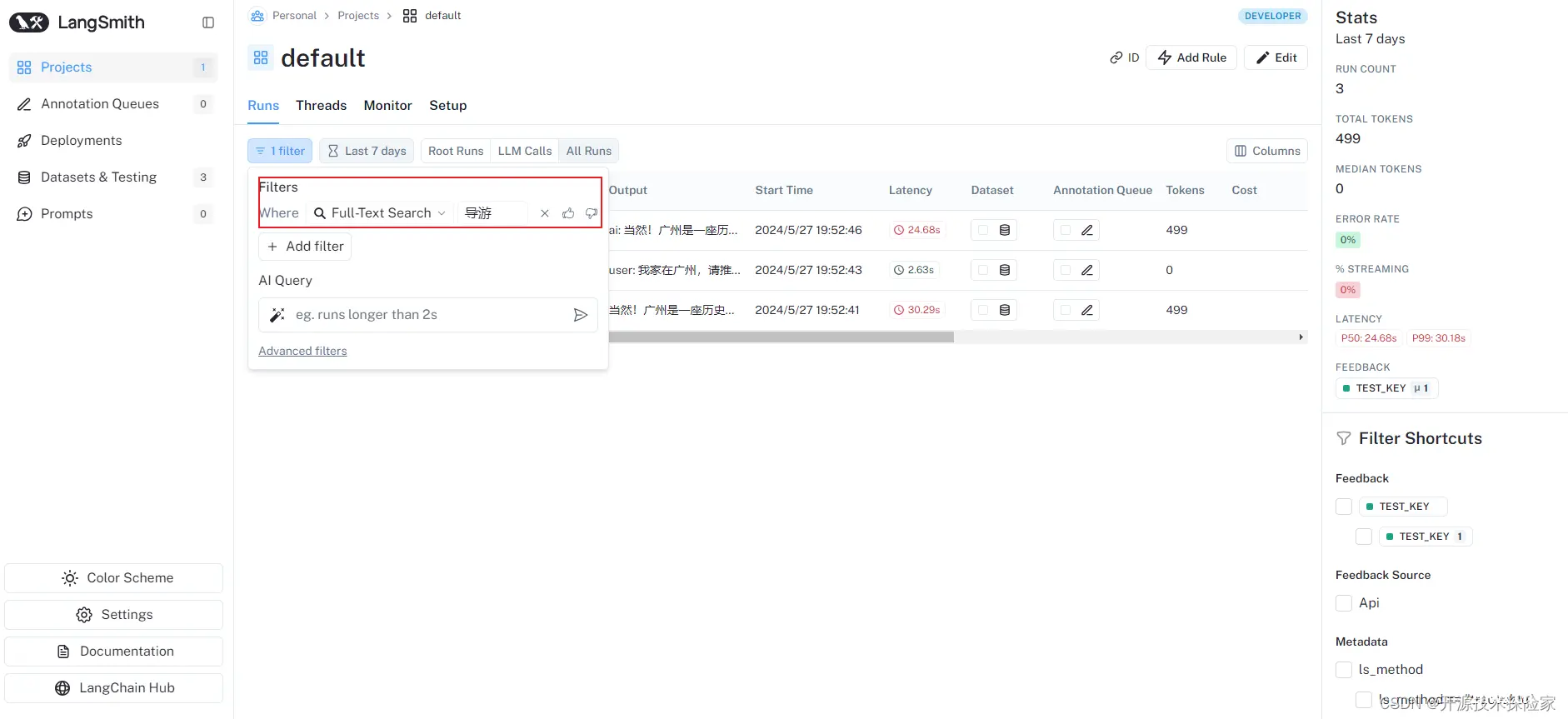
4.1.2.侧边栏过滤

4.2.使用监控图表
LangSmith 有一组可访问每个跟踪项目的监控图表。
过页面顶部的选项卡,可以查看不同时间段的监控,默认情况下,设置为七天。
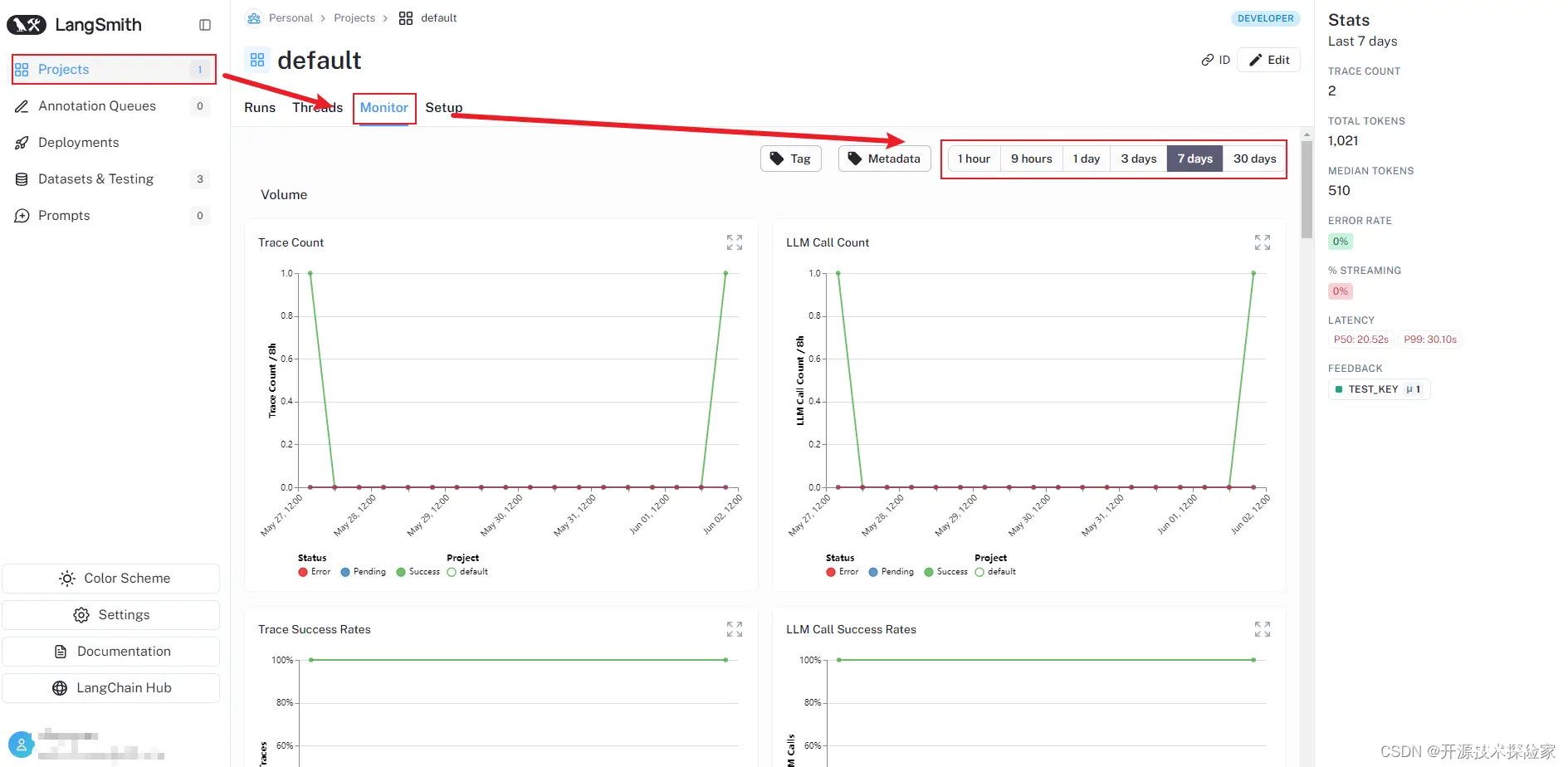
下面设置为三十天

4.3.设置自动化规则
LangSmith 提供了一项自动化记录功能,可让触发跟踪数据的某些操作。
4.3.1.导航至规则创建
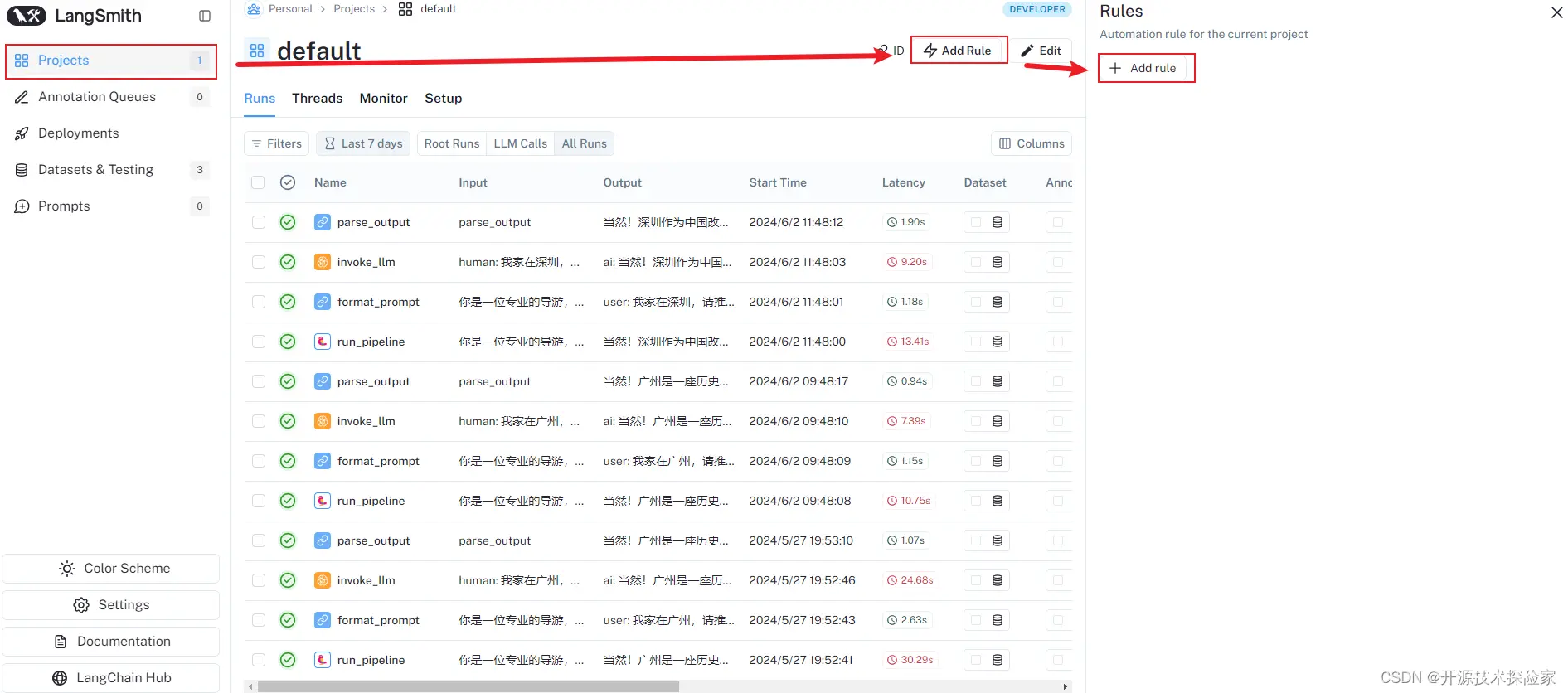
4.3.2.定义过滤器
创建一个过滤器来过滤项目中的记录。
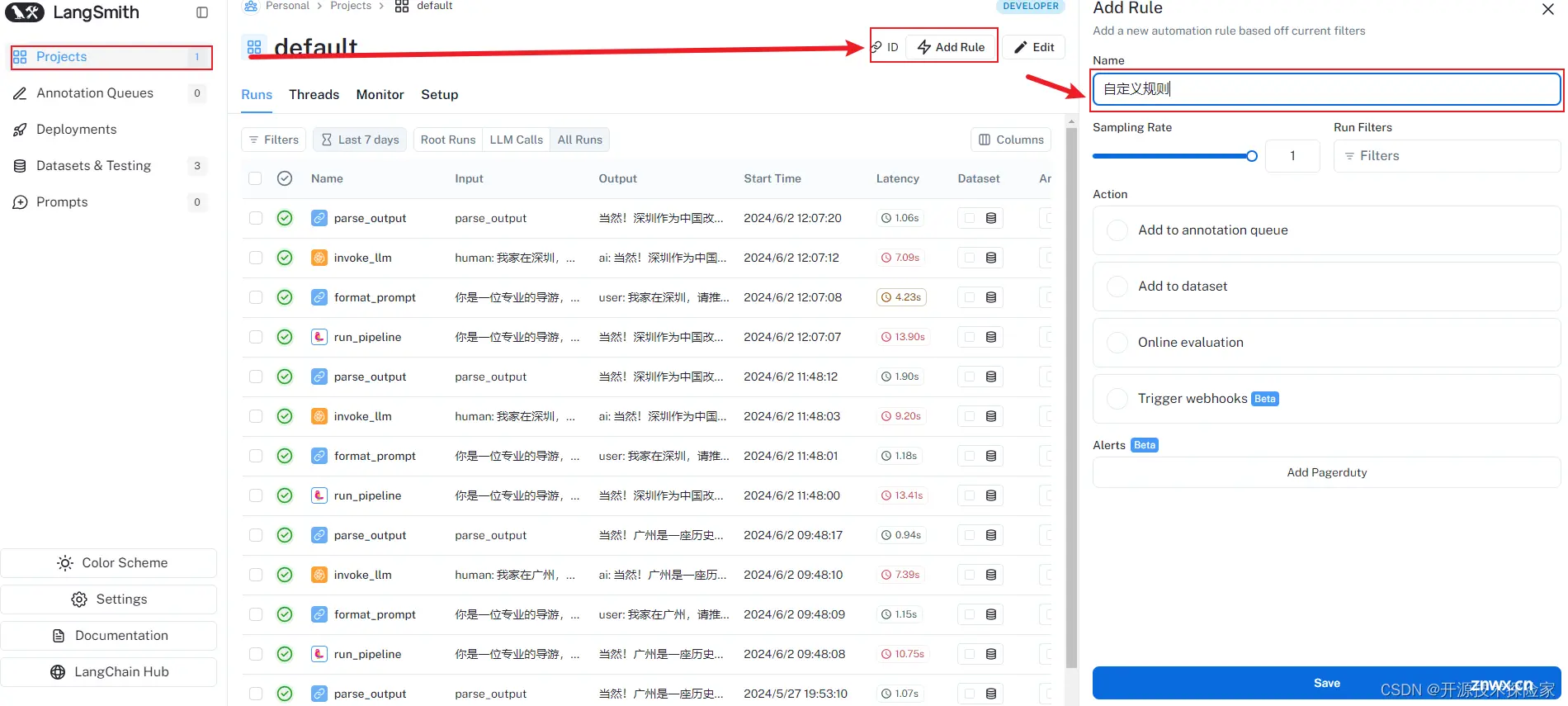
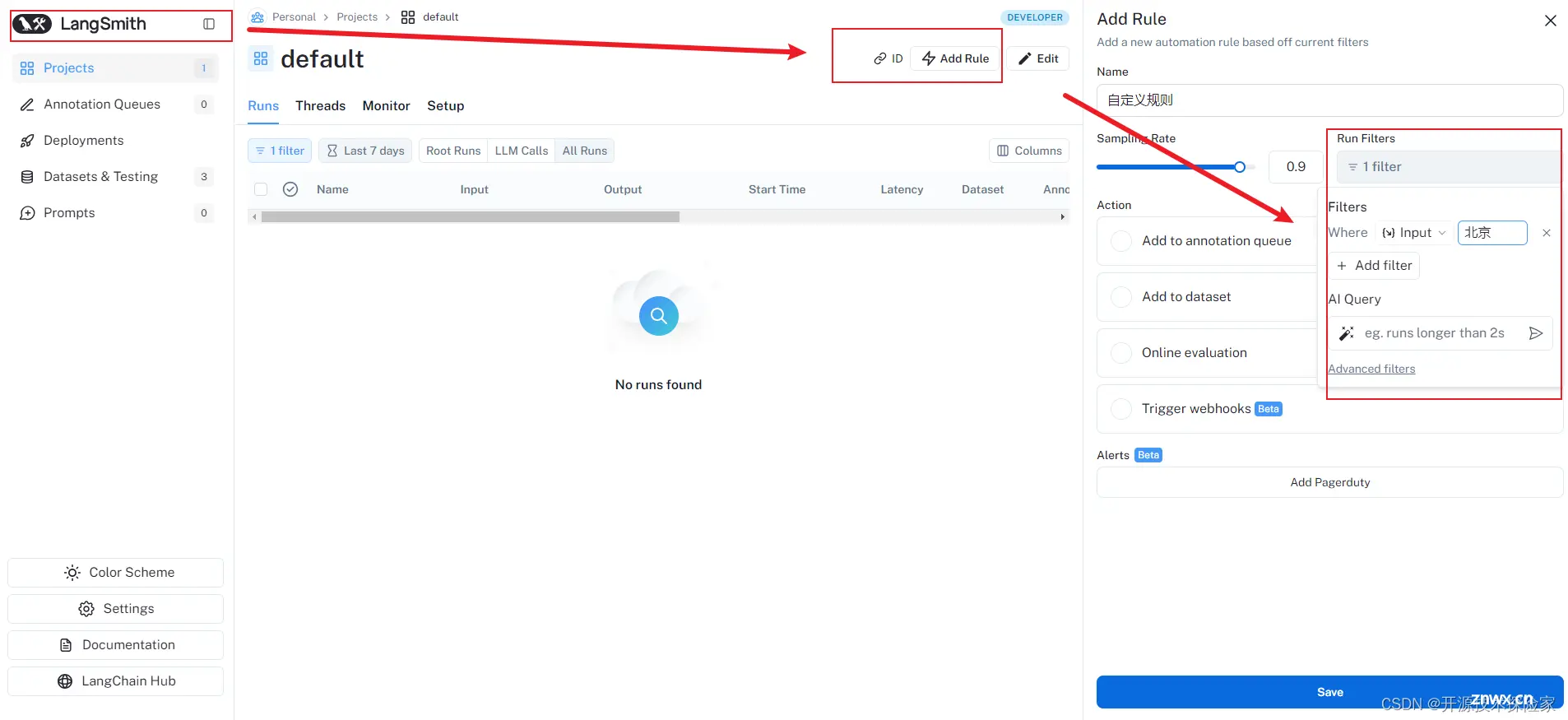
4.3.3.定义采样率
为自动化指定一个采样率(介于 0 和 1 之间),用于控制发送到自动化操作的记录的百分比。例如,将采样率设置为 0.5,则通过过滤器的 50% 的记录将被发送到该操作。
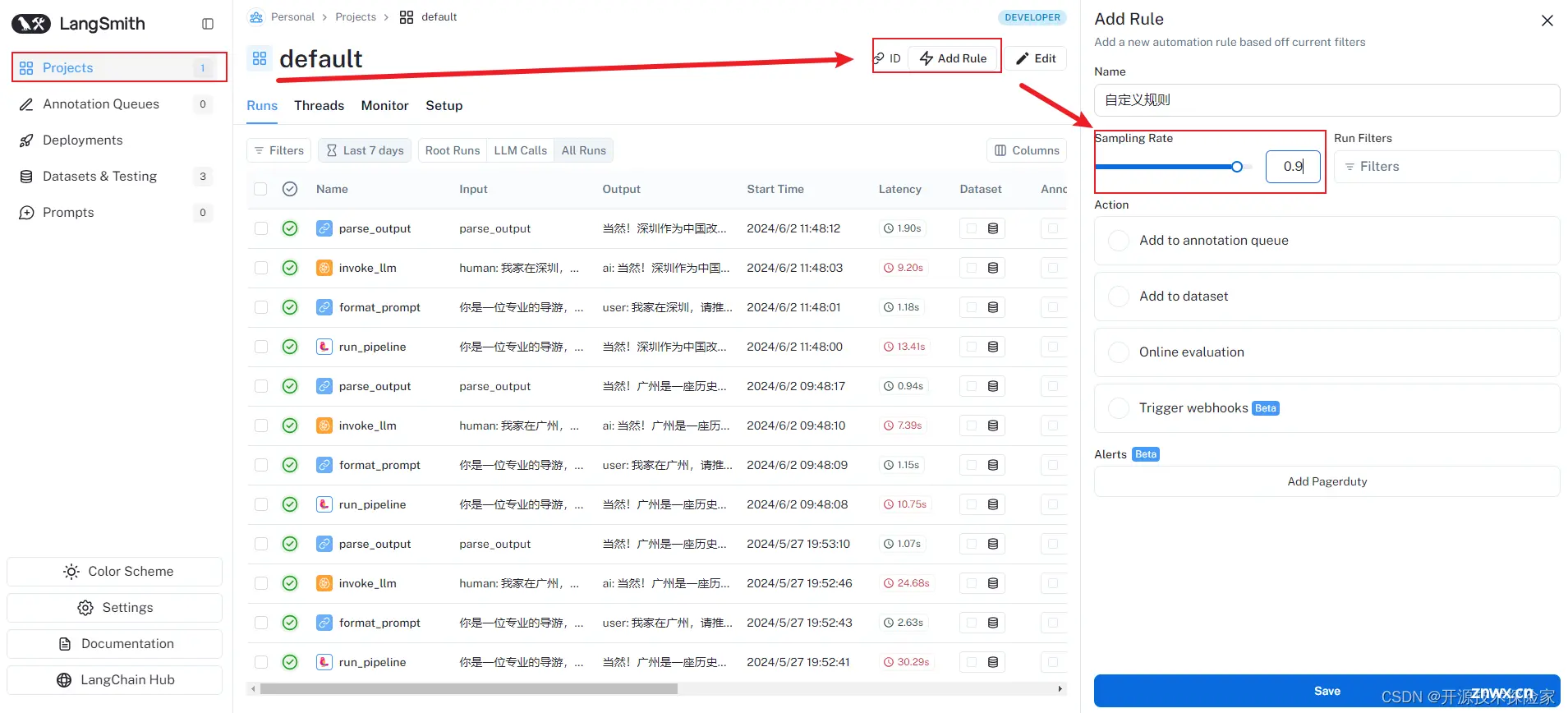
4.3.4.定义动作
Add to dataset: Add the inputs and outputs of the trace to a dataset.Add to annotation queue: Add the trace to an annotation queue.Run online evaluation: Run an online evaluation on the trace. Trigger webhook: Trigger a webhook with the trace data.
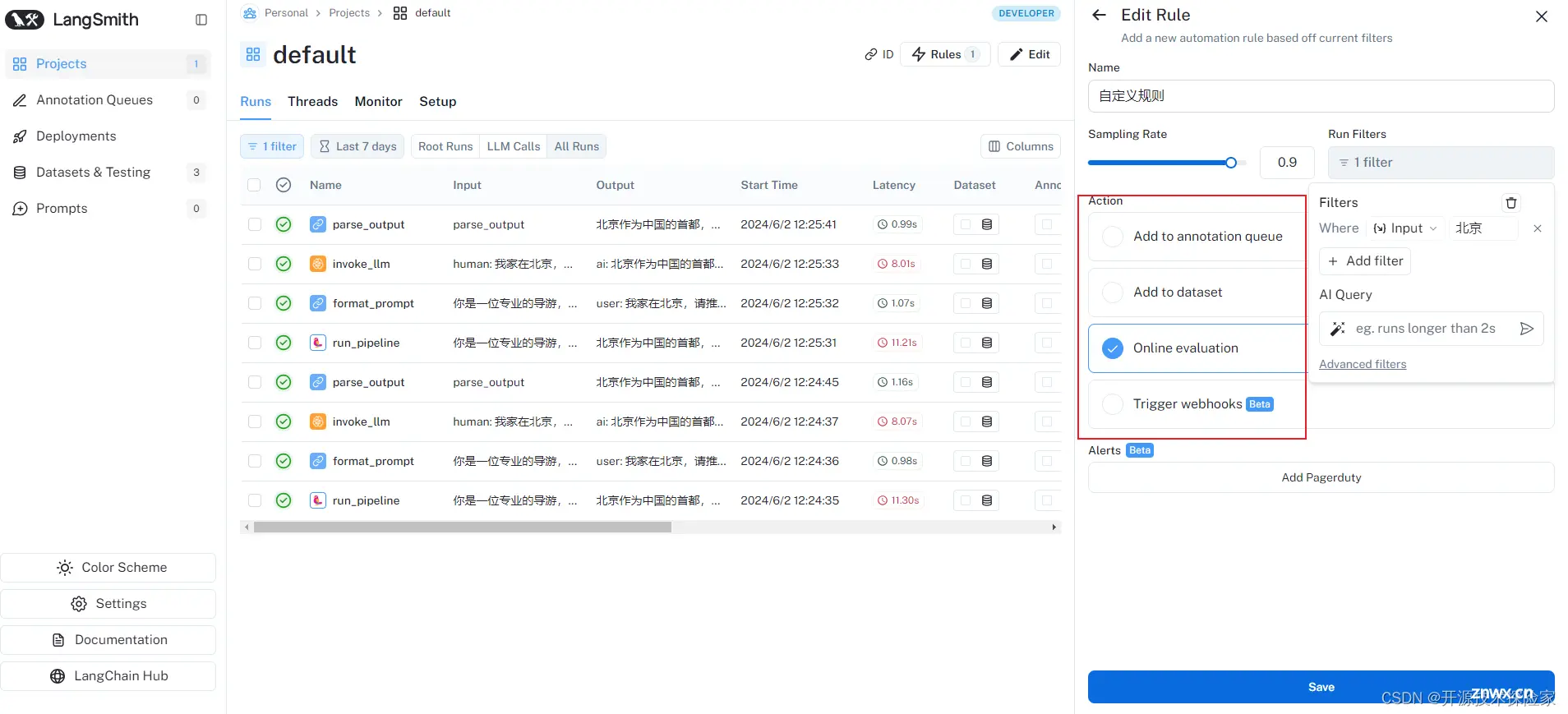
4.3.5.查看自动化日志
未调用程序,自动化日志为空

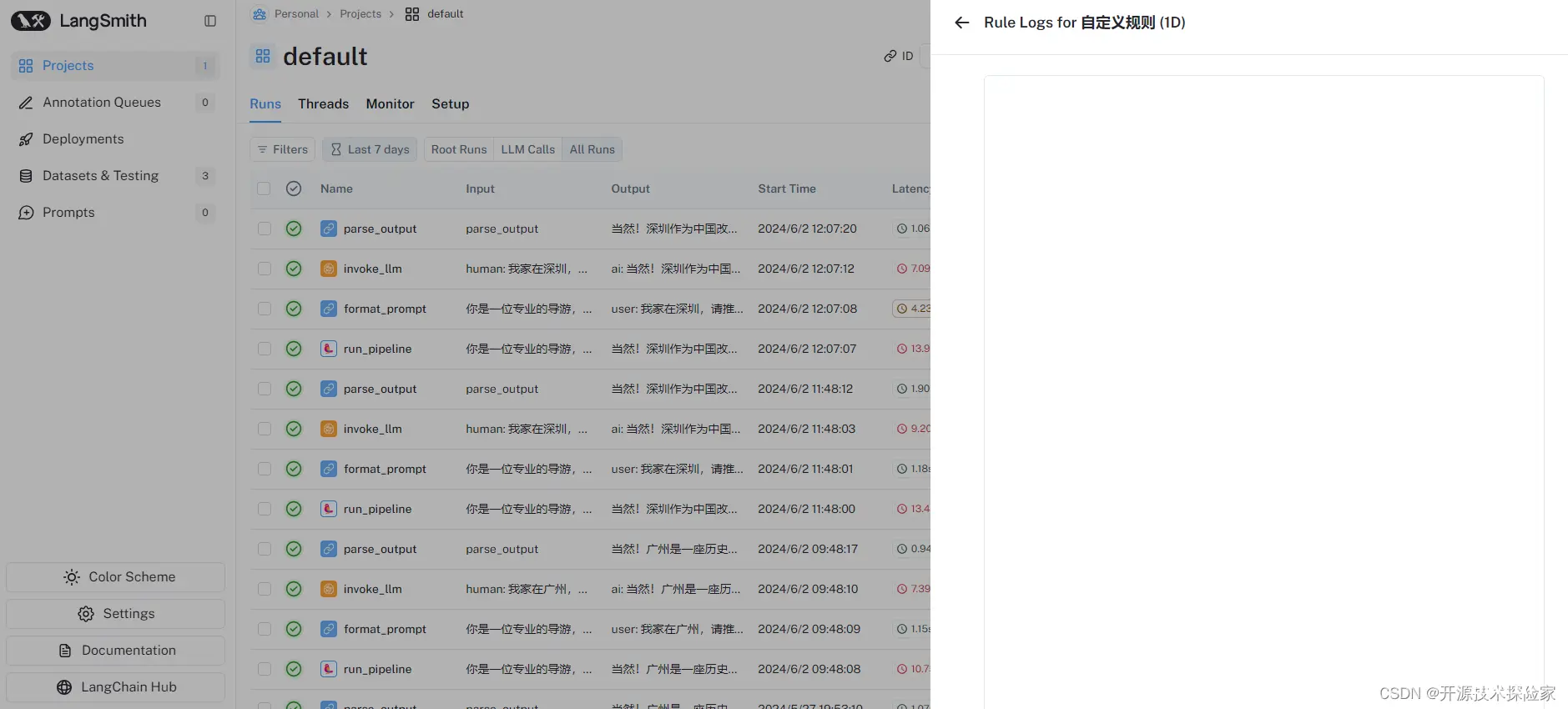
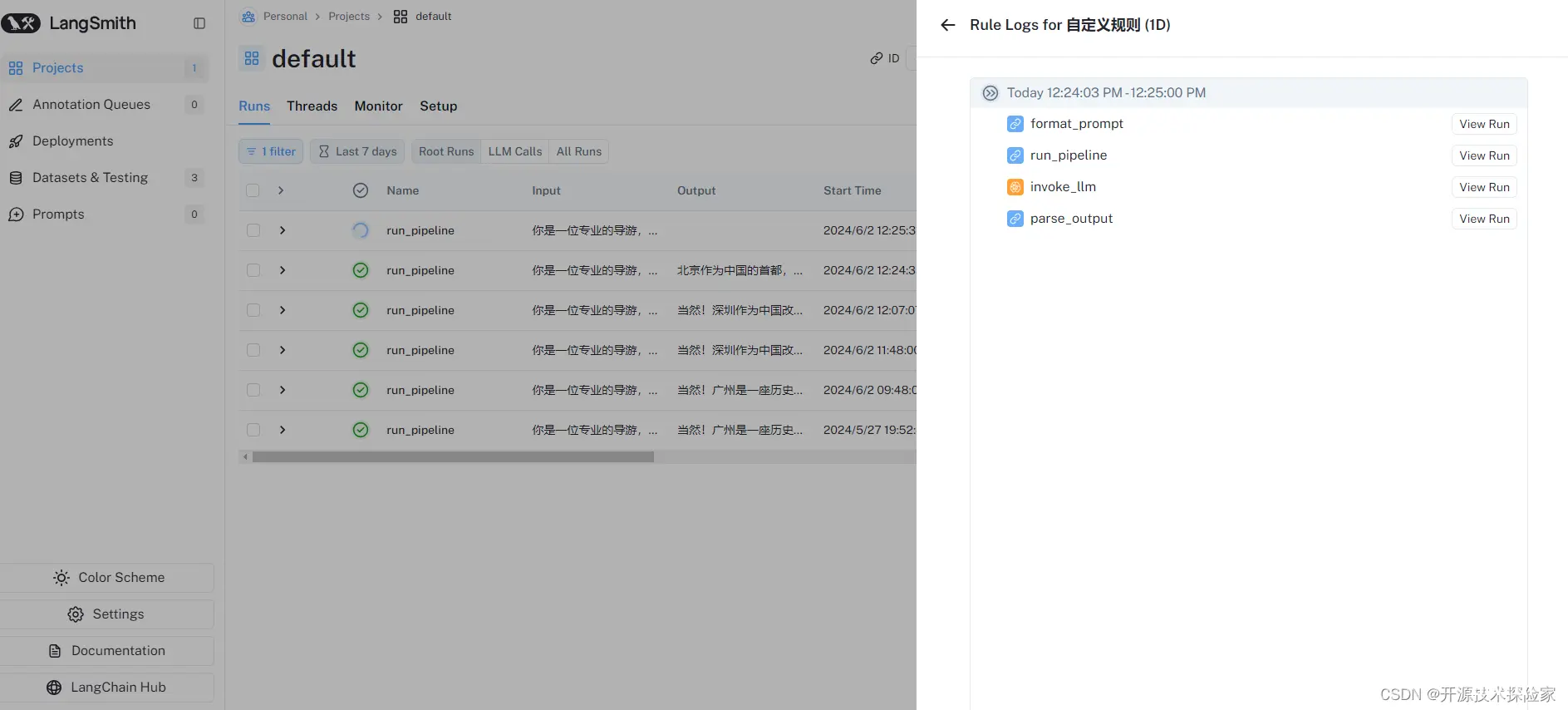
调用程序,让模型进行推理:我家在北京,请推荐一下特色景点?

五、附带说明
5.1.测试代码
# -*- coding = utf-8 -*-
import os
from langsmith import traceable
from langsmith.run_helpers import get_current_run_tree
from langsmith import run_trees
from openai import Client
os.environ["OPENAI_API_KEY"] = 'sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_API_KEY'] = 'lsv2_pt_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
key = 'test_key'
def feedback(run_id,key,value):
from langsmith import Client
client = Client()
client.create_feedback(
run_id,
key=key,
value=value,
score=1.0,
comment="comment",
)
if __name__ == '__main__':
@traceable
def format_prompt(system_prompt,prompt,value="format_prompt"):
run = get_current_run_tree()
run_id = run.id
feedback(run_id, key,value)
return [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": prompt
}
]
@traceable(run_type="llm")
def invoke_llm(messages,value="invoke_llm"):
run = get_current_run_tree()
run_id = run.id
feedback(run_id, key,value)
openai = Client()
return openai.chat.completions.create(
messages=messages, model="gpt-3.5-turbo", temperature=0
)
@traceable
def parse_output(response,value="parse_output"):
run = get_current_run_tree()
run_id = run.id
feedback(run_id, key,value)
return response.choices[0].message.content
@traceable
def run_pipeline(system_prompt,prompt,value='run_pipeline'):
run:run_trees.RunTree = get_current_run_tree()
run_id = run.id
feedback(run_id, key,value)
# 格式化prompt
messages = format_prompt(system_prompt,prompt)
# 调用GPT进行推理
response = invoke_llm(messages)
# 解析输出
result = parse_output(response)
return result
system_prompt = "你是一位专业的导游,对历史文化、自然地理、艺术风光等方面都有丰富的知识积累。"
prompt = "我家在北京,请推荐一下特色景点?"
result = run_pipeline(system_prompt,prompt)
print(result)
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。