Linux shell编程学习笔记72:tr命令——集合转换工具
紫郢剑侠 2024-09-07 10:07:05 阅读 51

0 前言
在大数据时代,我们要面对大量数据,有时需要对数据进行整理和转换。
在Linux中,我们可以使用 tr命令来整理和转换数据,也可以进行简单的加解密。
1 tr命令 的帮助信息,功能,格式,选项和参数说明
我们可以使用命令cut--help来获取帮助信息。
1.1 tr命令 的帮助信息
1.1.1 csdn程序员研究院linux 中的tr命令帮助信息
<code>[purpleendurer @ bash ~] tr --help
Usage: tr [OPTION]... SET1 [SET2]
Translate, squeeze, and/or delete characters from standard input,
writing to standard output.
-c, -C, --complement use the complement of SET1
-d, --delete delete characters in SET1, do not translate
-s, --squeeze-repeats replace each input sequence of a repeated character
that is listed in SET1 with a single occurrence
of that character
-t, --truncate-set1 first truncate SET1 to length of SET2
--help display this help and exit
--version output version information and exit
SETs are specified as strings of characters. Most represent themselves.
Interpreted sequences are:
\NNN character with octal value NNN (1 to 3 octal digits)
\\ backslash
\a audible BEL
\b backspace
\f form feed
\n new line
\r return
\t horizontal tab
\v vertical tab
CHAR1-CHAR2 all characters from CHAR1 to CHAR2 in ascending order
[CHAR*] in SET2, copies of CHAR until length of SET1
[CHAR*REPEAT] REPEAT copies of CHAR, REPEAT octal if starting with 0
[:alnum:] all letters and digits
[:alpha:] all letters
[:blank:] all horizontal whitespace
[:cntrl:] all control characters
[:digit:] all digits
[:graph:] all printable characters, not including space
[:lower:] all lower case letters
[:print:] all printable characters, including space
[:punct:] all punctuation characters
[:space:] all horizontal or vertical whitespace
[:upper:] all upper case letters
[:xdigit:] all hexadecimal digits
[=CHAR=] all characters which are equivalent to CHAR
Translation occurs if -d is not given and both SET1 and SET2 appear.
-t may be used only when translating. SET2 is extended to length of
SET1 by repeating its last character as necessary. Excess characters
of SET2 are ignored. Only [:lower:] and [:upper:] are guaranteed to
expand in ascending order; used in SET2 while translating, they may
only be used in pairs to specify case conversion. -s uses SET1 if not
translating nor deleting; else squeezing uses SET2 and occurs after
translation or deletion.
GNU coreutils online help: <http://www.gnu.org/software/coreutils/>
Report tr translation bugs to <http://translationproject.org/team/>
For complete documentation, run: info coreutils 'tr invocation'
[purpleendurer @ bash ~]
1.1.2 银河麒麟(kylin)系统中的tr命令帮助信息
<code>[purpleenduer @ kylin ~ ] tr --help
用法:tr [选项]... SET1 [SET2]
Translate, squeeze, and/or delete characters from standard input,
writing to standard output.
-c, -C, --complement use the complement of SET1
-d, --delete delete characters in SET1, do not translate
-s, --squeeze-repeats replace each sequence of a repeated character
that is listed in the last specified SET,
with a single occurrence of that character
-t, --truncate-set1 first truncate SET1 to length of SET2
--help显示此帮助信息并退出
--version显示版本信息并退出
SET 是一组字符串,一般都可按照字面含义理解。解析序列如下:
\NNN八进制值为NNN 的字符(1 至3 个数位)
\\反斜杠
\a终端鸣响
\b退格
\f换页
\n换行
\r回车
\t水平制表符
\v垂直制表符
字符1-字符2从字符1 到字符2 的升序递增过程中经历的所有字符
[字符*]在SET2 中适用,指定字符会被连续复制直到吻合设置1 的长度
[字符*次数]对字符执行指定次数的复制,若次数以 0 开头则被视为八进制数
[:alnum:]所有的字母和数字
[:alpha:]所有的字母
[:blank:]所有呈水平排列的空白字符
[:cntrl:]所有的控制字符
[:digit:]所有的数字
[:graph:]所有的可打印字符,不包括空格
[:lower:]所有的小写字母
[:print:]所有的可打印字符,包括空格
[:punct:]所有的标点字符
[:space:]所有呈水平或垂直排列的空白字符
[:upper:]所有的大写字母
[:xdigit:]所有的十六进制数
[=字符=]所有和指定字符相等的字符
Translation occurs if -d is not given and both SET1 and SET2 appear.
-t may be used only when translating. SET2 is extended to length of
SET1 by repeating its last character as necessary. Excess characters
of SET2 are ignored. Only [:lower:] and [:upper:] are guaranteed to
expand in ascending order; used in SET2 while translating, they may
only be used in pairs to specify case conversion. -s uses the last
specified SET, and occurs after translation or deletion.
GNU coreutils online help: <http://www.gnu.org/software/coreutils/>
请向<http://translationproject.org/team/zh_CN.html> 报告tr 的翻译错误
Full documentation at: <http://www.gnu.org/software/coreutils/tr>
or available locally via: info '(coreutils) tr invocation'
[purpleenduer @ kylin ~ ]
1.2 tr命令的功能
tr命令源于英文单词translate,其功能是从标准输入设备读取数据,进行字符转换、压缩和/或删除后,将结果输出到标准输出设备,或者重定向到文件。
1.3 tr命令的格式
tr [选项]... 字符集合1 [字符集合2]
1.4 tr命令的选项说明
| 选项 | 说明 |
|---|---|
| -c, -C, --complement | 使用 SET1 的补码。也就是符合 SET1 的部份不做处理,不符合的剩余部份才进行转换 |
| -d, --delete | 删除 SET1 中的字符,不转换 |
| -s, --squeeze-repeats | 将 SET1 中列出的重复字符缩减为单个字符 |
| -t, --truncate-set1 | 削减 SET1 指定范围,使之与 SET2 设定长度相等 |
| --help | 显示此帮助信息并退出 |
| --version | 显示版本信息并退出 |
1.5 tr命令的字符集合的说明
字符集合指定了字符串范围。
字符串集合1用于查询, 字符集合2用于处理各种转换。
tr刚执行时,字符集合1中的字符被映射到字符集合2中的字符,然后转换操作开始。
表达的序列是:
| 字符集合 | 说明 |
|---|---|
| \NNN | 八进制值为NNN 的字符(1 至3 个数位) |
| \\ | 反斜杠 |
| \a | 终端鸣响 |
| \b | 退格 |
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| 字符1-字符2 | 从字符1 到字符2 的升序递增过程中经历的所有字符 |
| [字符*] | 在SET2 中适用,指定字符会被连续复制直到吻合设置1 的长度 |
| [字符*次数] | 对字符执行指定次数的复制,若次数以 0 开头则被视为八进制数 |
| [:alnum:] | 所有的字母和数字 |
| [:alpha:] | 所有的字母 |
| [:blank:] | 所有呈水平排列的空白字符 |
| [:cntrl:] | 所有的控制字符 |
| [:digit:] | 所有的数字 |
| [:graph:] | 所有的可打印字符,不包括空格 |
| [:lower:] | 所有的小写字母 |
| [:print:] | 所有的可打印字符,包括空格 |
| [:punct:] | 所有的标点字符 |
| [:space:] | 所有呈水平或垂直排列的空白字符 |
| [:upper:] | 所有的大写字母 |
| [:xdigit:] | 所有的十六进制数 |
| [=字符=] | 所有和指定字符相等的字符 |
一些
| 速记符 | 含义 | 八进制方式 |
| \a Ctrl-G | 铃声 | \007 |
| \b Ctrl-H | 退格符 | \010 |
| \f Ctrl-L | 走行换页 | \014 |
| \n Ctrl-J | 新行 | \012 |
| \r Ctrl-M | 回车 | \015 |
| \t Ctrl-I | tab键 | \011 |
| \v Ctrl-X | \030 |
如果未给出 -d 并且 字符集合1 和 字符集合2 都出现,则会发生转换。
-t 只能在转换时使用。
字符集合2 通过根据需要重复其最后一个字符来扩展到 字符集合1 的长度。
字符集合2 的多余字符将被忽略。
只有 [:lower:] 和 [:upper:] 保证按升序扩展;在翻译时在 字符集合2 中使用,他们可能会
仅成对使用以指定大小写转换。
-s 使用最后指定的 字符集合,并在转换或删除后出现。
2 tr命令的使用实例
2.0 创建演示文件
为了演示tr命令的用法,我们先创建一个测试文件t.txt。
<code>[purpleendurer @ bash ~] echo -e "Windows95 1995 June\nWindows98 1998 August\nDOS 1981 May" > t.txt
[purpleendurer @ bash ~] cat t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
[purpleendurer @ bash ~]
2.1 文件中的英文大小写字母转换
2.1.1使用a-z和 A-Z
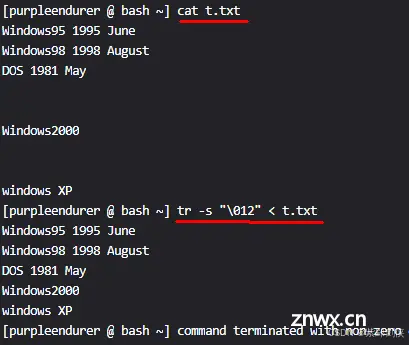
我们要把文件t.txt中的英文小写字母转换为大写字母再显示出来,可以使用两种方式来实现:
1.管道操作:cat t.txt | tr a-z A-Z
2.输入重定向:tr a-z A-Z < t.txt
<code>[purpleendurer @ bash ~] cat t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
[purpleendurer @ bash ~] cat t.txt | tr a-z A-Z
WINDOWS95 1995 JUNE
WINDOWS98 1998 AUGUST
DOS 1981 MAY
[purpleendurer @ bash ~] tr a-z A-Z < t.txt
WINDOWS95 1995 JUNE
WINDOWS98 1998 AUGUST
DOS 1981 MAY
[purpleendurer @ bash ~]
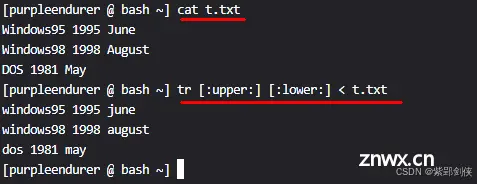
2.1.2 使用[:lower:]和 [:upper:]
我们要把文件t.txt中的英文大写字母转换为小写字母再显示出来,这里只演示 输入重定向 的方法,即:
tr [:upper:] [:lower:] < t.txt
<code>[purpleendurer @ bash ~] cat t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
[purpleendurer @ bash ~] tr [:upper:] [:lower:] < t.txt
windows95 1995 june
windows98 1998 august
dos 1981 may
[purpleendurer @ bash ~]
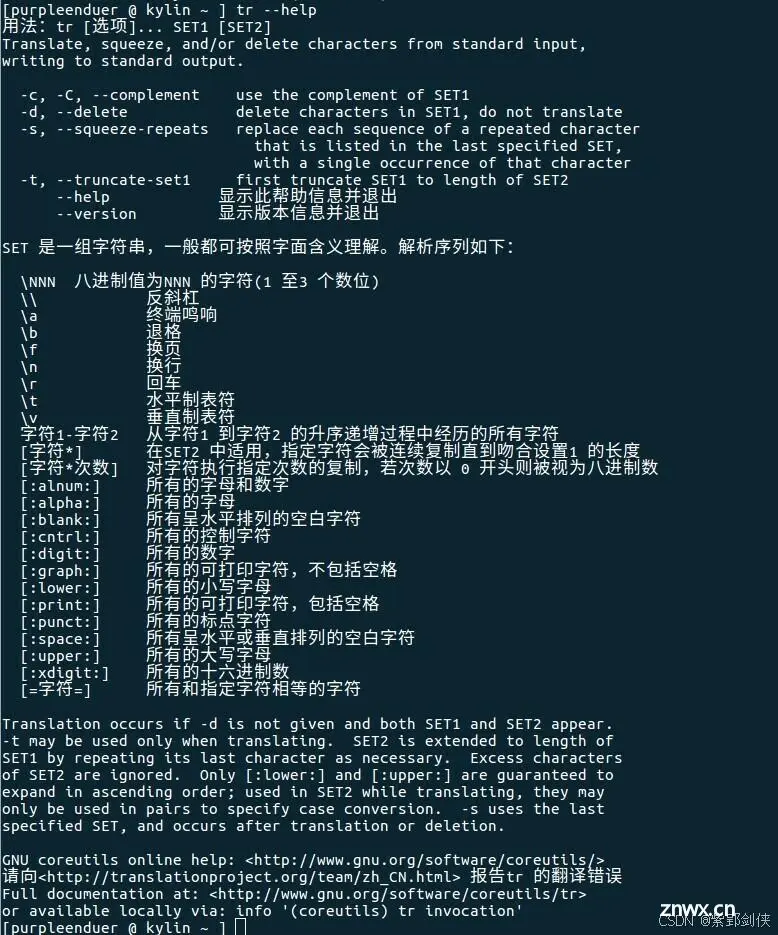
2.2 去除文件中的重复字符
我们要去除文件t.txt内容中的重复数字9再显示,这里只演示 输入重定向 的方法,即:
tr -s "9" < t.txt
<code>[purpleendurer @ bash ~] cat t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
[purpleendurer @ bash ~] tr -s "9" < t.txt
Windows95 195 June
Windows98 198 August
DOS 1981 May
[purpleendurer @ bash ~]

可以看到 第1行中的1995变成了 195,第2行中的1998 变成了 198。
2.3 将数字转换为字母再从字母转换回数字(加密和解密)
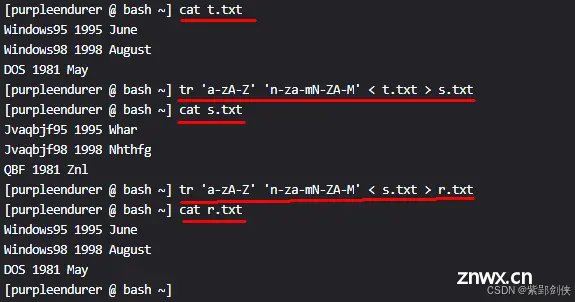
2.3.1 简单的转换
将文件t.txt中的数字0-9转换为大写英文字母F-L,存储到文件s.txt,即:
tr "0-9" "C-L" < t.txt > s.txt
再将文件s.txt中的大写英文字母F-L转换为数字0-9存储到文件r.txt,即:
tr "C-L" "0-9" < s.txt > r.txt
<code>[purpleendurer @ bash ~] cat t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
[purpleendurer @ bash ~] tr "0-9" "C-L" < t.txt > s.txt
[purpleendurer @ bash ~] cat s.txt
WindowsLH DLLH June
WindowsLK DLLK August
DOS DLKD May
[purpleendurer @ bash ~] tr "C-L" "0-9" < s.txt > r.txt
[purpleendurer @ bash ~] cat r.txt
Windows95 1995 7une
Windows98 1998 August
1OS 1981 May
[purpleendurer @ bash ~]
可以看到,将文件t.txt中的数字0-9转换为大写英文字母F-L,这个加密过程没有问题。
在将文件s.txt中的大写英文字母F-L转换为数字0-9,这个解密过程出现了问题,就是第1行中June的J被转换为7,第3行中DOS的D被转换为1。
所以加解密算法还是有讲究,需要精心设计的。
2.3.2 ROT13加密算法
ROT13(Rotate by 13 Places)是一个著名的对称加密算法,它的加密算法就是通过将字母表中的每个字母向后移动13个位置来加密文本。
ROT13是一种对称加密算法,这意味着加密和解密过程是相同的,因此解密的方法就是将加密后的文本再次使用ROT13进行加密,这样就会得到原始的文本。
下面我们使用ROT13加密算法对文件t.txt进行加密,储存到文件s.txt,使用ROT13加密算法对文件s.txt进行加密,储存到文件r.txt,那么文件r.txt 的内容应该是和文件t.txt一样的。
<code>[purpleendurer @ bash ~] cat t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
[purpleendurer @ bash ~] tr 'a-zA-Z' 'n-za-mN-ZA-M' < t.txt > s.txt
[purpleendurer @ bash ~] cat s.txt
Jvaqbjf95 1995 Whar
Jvaqbjf98 1998 Nhthfg
QBF 1981 Znl
[purpleendurer @ bash ~] tr 'a-zA-Z' 'n-za-mN-ZA-M' < s.txt > r.txt
[purpleendurer @ bash ~] cat r.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
[purpleendurer @ bash ~]

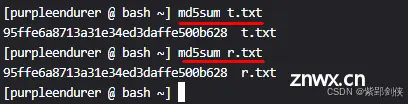
我们可以进一步使用md5sum命令来看看文件r.txt 和文件t.txt的内容是不是一样的。
<code>[purpleendurer @ bash ~] md5sum t.txt
95ffe6a8713a31e34ed3daffe500b628 t.txt
[purpleendurer @ bash ~] md5sum r.txt
95ffe6a8713a31e34ed3daffe500b628 r.txt
[purpleendurer @ bash ~]
文件r.txt 和文件t.txt的MD5值都是95ffe6a8713a31e34ed3daffe500b628,说明二者的内容是一样的。
关于md5sum命令的用法,可以参考:
Linux shell编程学习笔记42:md5sum-CSDN博客
![]()
https://blog.csdn.net/Purpleendurer/article/details/137125672Linux shell编程学习笔记44:编写一个脚本,将md5sum命令执行结果保存到变量中,进而比较两个文件内容是否相同_md5sum -c 值赋给变量-CSDN博客
![]()
https://blog.csdn.net/Purpleendurer/article/details/137128034
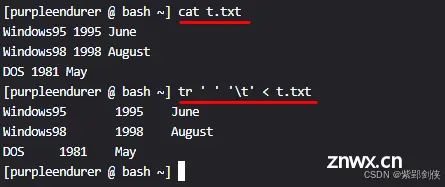
2.4 将文件中的空格转换为tab键
将文件t.txt中的空格转换为tab键(\t)。
<code>[purpleendurer @ bash ~] cat t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
[purpleendurer @ bash ~] tr ' ' '\t' < t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
[purpleendurer @ bash ~]
可以看到,文件t.txt中的空格转换为tab键(\t)后,各字段之间显示的距离更宽了。
2.5 删除文件中的空行
我们先使用命令
echo -e "Windows95 1995 June\nWindows98 1998 August\nDOS 1981 May" > t.txt
给t.txt 增加一些空行。
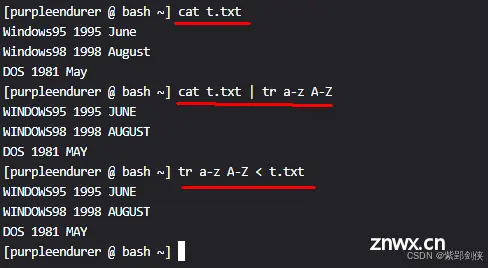
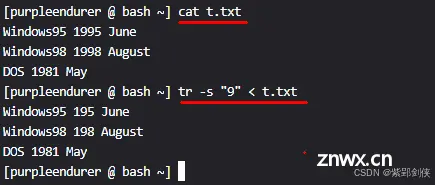
<code>[purpleendurer @ bash ~] echo -e "\n\nWindows2000\n\n\nwindows XP" >> t.txt
[purpleendurer @ bash ~] cat t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
Windows2000
windows XP
[purpleendurer @ bash ~]
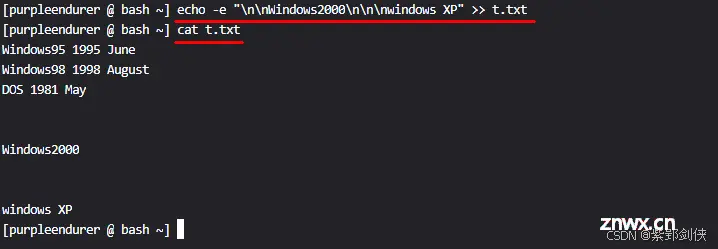
然后我们使用命令
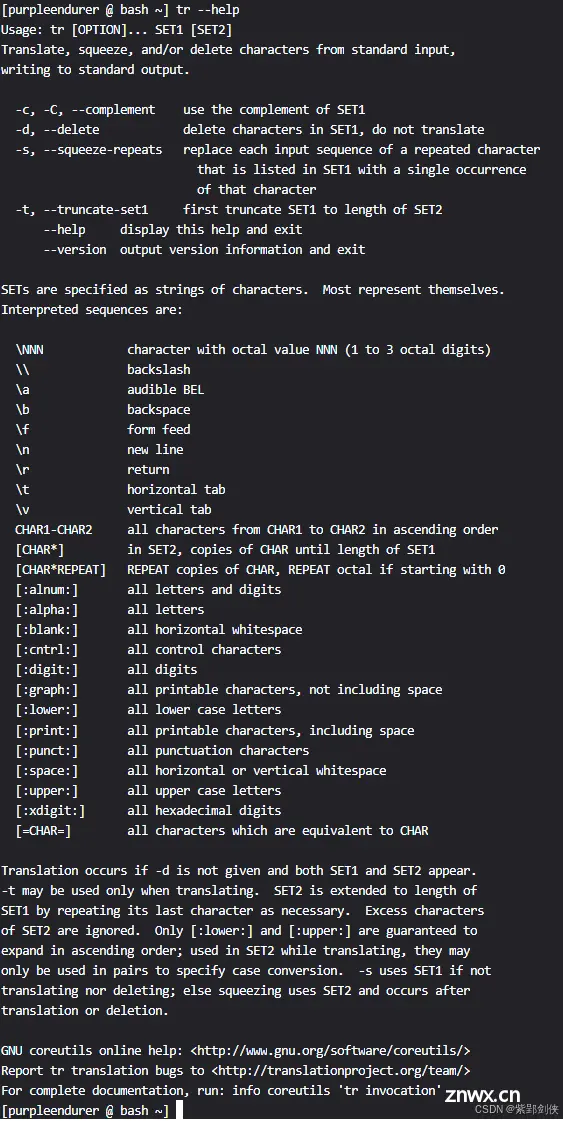
tr -s "\012" < t.txt
或
tr -s "\n" < t.txt
来删除文件中的空行。具体如下:
<code>[purpleendurer @ bash ~] cat t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
Windows2000
windows XP
[purpleendurer @ bash ~] tr -s "\012" < t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
Windows2000
windows XP
[purpleendurer @ bash ~]
<code>[purpleendurer @ bash ~] cat t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
Windows2000
windows XP
[purpleendurer @ bash ~] tr -s "\n" < t.txt
Windows95 1995 June
Windows98 1998 August
DOS 1981 May
Windows2000
windows XP
[purpleendurer @ bash ~]
以上两条命令都可删除文件中的空行。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。