【Linux】进程优先级、调度、命令行参数:从理论到实践(二)
Zfox_ 2024-10-06 14:07:03 阅读 88

🌈 个人主页:Zfox_
🔥 系列专栏:Linux

目录
🚀 前言一: 🔥 进程优先级 🍵 基本概念🍵 查看系统进程🍵 PRI and NI🍵 PRI vs NI🍵 用top命令更改已存在进程的nice:🍵 为什么Linux优先级调整会被限制?🍵 其他概念
二:🔥 进程调度切换 🍵 进程切换🍵 进程调度✈️ 位图判断✈️ 过期队列
📒✏️总结
三:🔥 命令行参数 四:🔥 共勉
🚀 前言
🐲 接着上一篇博客我们继续往下学习,点击跳转上一篇博客 【Linux】进程管理:从理论到实践(一)
一: 🔥 进程优先级
🍵 基本概念
🍊 cpu资源分配的先后顺序,就是指进程的优先级(priority)。🍊 优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。🍊 还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能。
🍵 查看系统进程
💦 在linux或者unix系统中,用 <code>ps –l 命令则会类似输出以下几个内容:

我们很容易注意到其中的几个重要信息,有下:
UID : 代表执行者的身份PID : 代表这个进程的代号PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号<code>PRI :
代表这个进程可被执行的优先级,其值越小越早被执行NI:代表这个进程的nice值Linux的默认优先级是80
🍵 PRI and NI
PRI 也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高。那 NI 呢? 就是我们所要说的 nice 值了,其表示进程可被执行的优先级的修正数值。PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:RI(new)=PRI(old)+nice。这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行。nice所以,调整进程优先级,在Linux下,就是调整进程nice值。nice其取值范围是-20至19,一共40个级别。
🍵 PRI vs NI
需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。 可以理解nice值是进程优先级的修正数据。
🍵 用top命令更改已存在进程的nice:
🎯 查看进程优先级指令:
ps -al / l
🎯 调整进程优先级
第一步:top
第二步:输入r
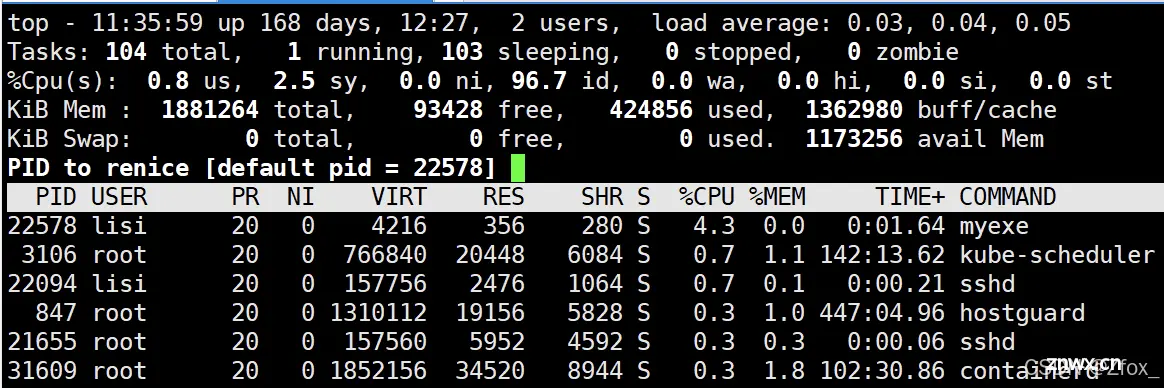
第三步:输入需要调整优先级的进程id
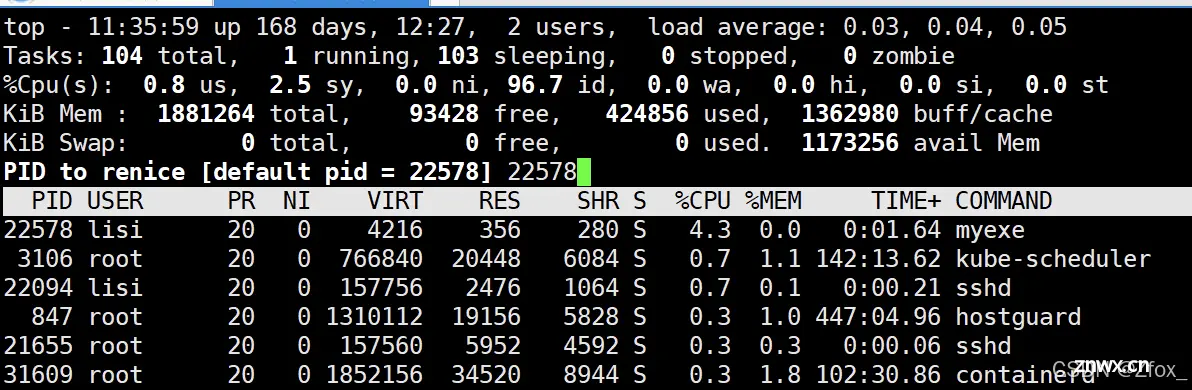
第四步:输入想要增加的优先级值(比如输入10,就是优先级就降低10,输入-10,就是优先级就升高10)
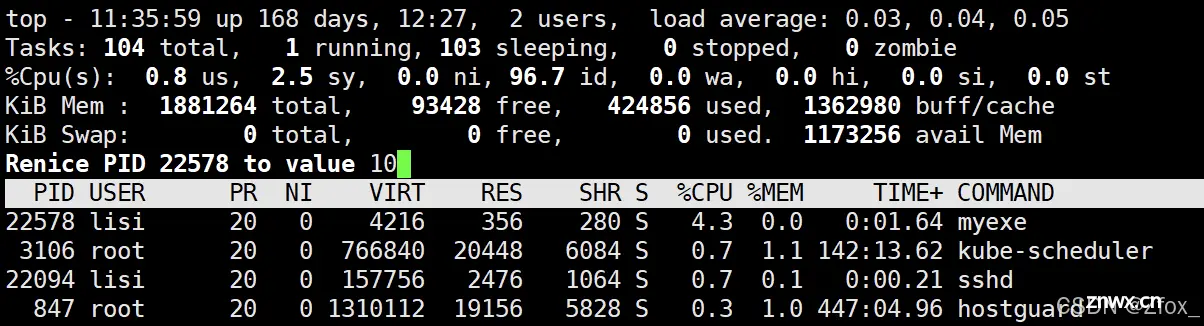
结果:使用ps -al 查看<code>myexe 的
PRI发现更改为 90了NI值更改为10。

🍵 为什么Linux优先级调整会被限制?
<code>如果不受限制,自己可以将自己的进程的优先级设置非常高,而系统的,或者别人的非常低,优先级较高的进程获得资源,后续还有很多今后曾源源不断产生,会导致常规进程享受不到资源。造成进程饥饿问题。
🍵 其他概念
竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级。独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰。并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行。并发: 多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发。
二:🔥 进程调度切换
🎯 进程在运行的时候,放在CPU上,并不是需要将该进程的代码全部执行完才会被拿下CPU,现代操作系统,都是基于时间片进行轮转执行,一个进程在CPU上有一个执行最大时间,即时间片,在CPU上执行了该时间,就会被拿下。
🍵 进程切换
🍊 CPU里面有大量的寄存器,比如:eax,ebx,ecx,edc,eds/ecs,eip… 等等,当一个进程在CPU 上被运行的时候,这些寄存器会围绕这个进程进行展开运算,保存相关的在执行该进程代码中的信息,临时数据,比如变量,函数等等。
其中 epi 也就是我们所说的 pc指针,记录进程执行到哪里了(比如PC记录的是一个进程代码的50行,则说明当前执行的是第49行)。这能保证进程在切换回来后还是继续往后执行。
当一个进程在CPU上的时间到了,要被拿下CPU时,需要将CPU上关于该进程的所有数据(大多是寄存器上的数据)(被称为进程的硬件上下文)全部保存带走,这些数据有些保存到进程的PCB中,有些保存在其他地方,较为复杂。这个过程叫 保护上下文。
这个进程被拿下后,CPU里面的寄存器的数据还是上一个进程的旧数据,当这些寄存器需要存储新的进程的相关数据时,直接覆盖式的写入即可。
如果是首次调度该进程,就直接从代码开头运行即可,如果不是首次调度,进程被放到CPU上运行时,则需要先把上次的硬件上下文数据进行恢复(恢复上下文),然后根据 eip寄存器 中保存的上次代码执行的位置继续执行。
CPU内的寄存器只有一套,虽然寄存器数据放在了共享的CPU是设备里面,但是所有的数据,其实都是被进程私有的。
🍵 进程调度
Linux实现进程调度的算法,考虑优先级,考虑饥饿,考虑效率。
🍊 我们来看看Linux的运行队列,如下图(runqueue):
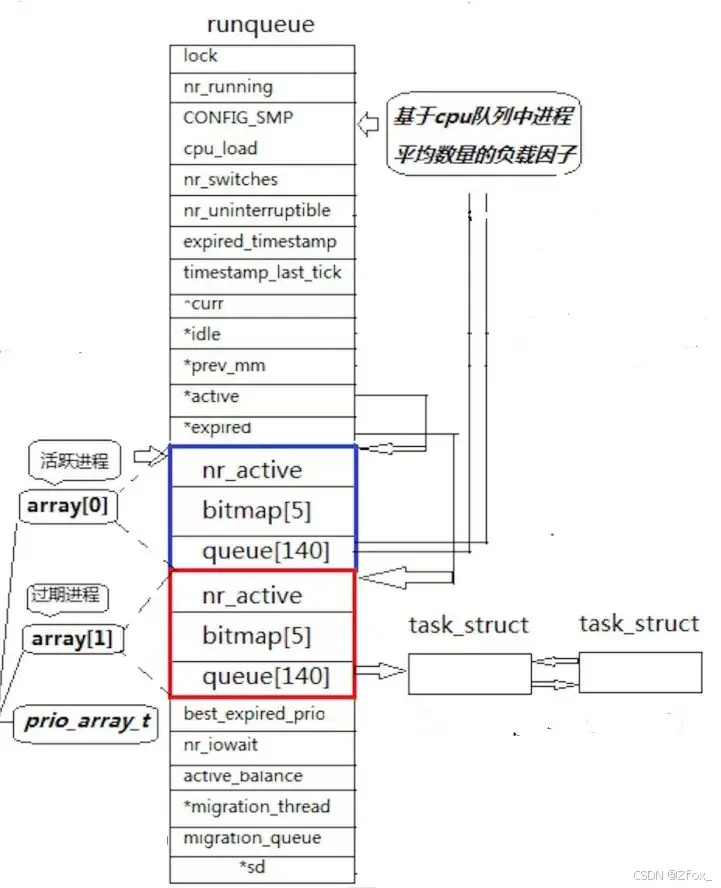
我们首先看蓝色框内的内容,有一个叫做 queue[140] 的数组,这里的 queue数组表示活动状态进程的进程队列。
其中在queue数组中,索引0~99号下标我们是不用的,这是因为0-99号下标对应的是 实时进程的优先级,实时进程是内核里更加重要的进程,放 在前100位由操作系统控制,避免系统抢占的情况。
所以我们只剩下 100-139 这个范围可操控,其实这也就和我们优先级的可控范围大小相同,正好对应队列的四十个空位,而OS通过某种映射关系,将可控优先级映射到数组 100-139的下标。
✈️ 位图判断
🍊 我们看蓝色框内还有一项 bitmap数组,类型为int,这个数组用来干嘛呢?只能存储5个整形变量。
数组的名字叫做bitmap已经很明显了,就是位图,5个整形元素有 32 * 5 = 160 个比特位,比特位的位置,表示哪一个队列。比特位的内容,表示该队列为不为空。
比如:0000 … 0000 ,如果最左侧0对应queue[100]的位置,那么如果该比特位为0表示在该下标映射的优先级下该队列为空,否则不为空。
有人会问:为什么要用位图?
遍历整个队列的时间开销要远大于查找位图。所以,bitmap是用来检测队列中是否有进程,检测对应的比特位是否为1!
而蓝色框内还有一个元素:nr_active,在Linux中,nr_active 是运行队列中用于表示活跃进程数量的计数器。nr_active 的值可以告诉内核有多少进程正在等待执行,从而帮助内核进行进程调度和资源分配。
✈️ 过期队列
🍊 在红色框中的三项属性与蓝色框中的三项属性完全相同,也就是另外一个队列,被称为——过期队列。
活跃队列表示当前CPU正在执行的运行队列,而 正在执行的运行队列(也就是活跃队列)是不可以增加新的进程的。
所以操作系统设置了一个 和活跃队列相同属性的过期队列,当活跃队列正在执行时如果有进程需要添加进运行队列,那么就会添加至过期队列当中,也就是说 活跃队列的进程一直在减少,而过期队列中的进程一直在增多!
当活跃队列的进程执行完毕后,就会和过期队列进行交换,它们交换的方式是通过两个结构体指针:
就是 active 和 expired 结构体指针,它们分别指向活跃队列和过期队列,而活跃队列与过期队列由于属性完全相同,于是被放在了一个叫做 prio_arry_t[2] 的数组里,prio_arry_t[0]指向活跃队列,prio_arry_t[1]指向过期队列:
当活跃队列被CPU执行完毕后,我们 只需要交换两个指针的内容即可,这样仅仅是指向的内容变了,活跃队列变为过期队列,过期队列变活跃队列,并且时间复杂度为 O(1):
新增进程在过期队列里插入,此时正在执行的是活跃队列,所以这个时候在过期队列里就有时间处理竞争饥饿的问题了。
这样,我们竞争饥饿,优先级,以及进程效率都解决了。
📒✏️总结
进程切换最重要的部分就是进程上下文的保护和恢复。进程调度的优先级问题由 活跃进程数组的下标与进程优先级形成一种映射关系 解决。进程调度的时间复杂度问题由 位图和两个结构体指针 解决,时间复杂度控制在了O(1)。进程调度的进程饥饿问题由活跃队列和过期队列 解决。
三:🔥 命令行参数
🚀 关于命令行参数,在C/C++中,我们main函数能不能带参数?实际上是可以的:
<code>#include <stdio.h>
int main(int argc, char *argv[]) //main函数的形参
{
return 0;
}
main函数参数其中两个参数为 int argc 和 char *argv[],其中 argv是指针数组,里面存的全是指针变量,这里我告诉你 argc 是 argv 数组的元素个数,那么 argv 数组究竟存着什么东西?我们不妨做个实验:
[lisi@hcss-ecs-a9ee work]$ cat tmp.cpp
#include<stdio.h>
#include<stdlib.h>
int main(int argc, char *argv[])
{
for(int i = 0 ; i < argc ; ++i)
{
printf("argv[%d]:%s\n",i ,argv[i]);
}
return 0;
}
[lisi@hcss-ecs-a9ee work]$ g++ tmp.cpp -o tmp -std=c++11
[lisi@hcss-ecs-a9ee work]$ ./tmp
argv[0]:./tmp
我们发现,argv保存的内容恰好是我们向命令行解释器输入的内容,我们不妨在命令后多加几个选项:
[lisi@hcss-ecs-a9ee work]$ ./tmp -a -l
argv[0]:./tmp
argv[1]:-a
argv[2]:-l
这里的结果就很明显了,bash 将我们命令行参数以空格为分隔符转化为一个个的子串,并且 argv里的每一个指针按照顺序指向不同的子串。
说到字符串,我们无论实在Linux还是Windows或者其他系统,都有命令行提示符,他们是怎么构成的?我们输入的命令被转化成了一整个字符串,以空格作为分隔符,将整个字符串转化为一个一个的子串。
所以这样也能获取到我们的命令行参数。现在我们知道了C语言 main函数中两个参数是由bash维护并创建和传参的。但是为什么要这么做?
我们以下面一段代码来帮助理解:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
//实现不同的算数功能
int main(int argc, char* argv[])
{
if (argc != 4)
{
printf("Usage:\n\t%s -[add|sub|mul|div] x y\n\n", argv[0]);
}
int x = atoi(argv[2]);
int y = atoi(argv[3]);
if (strcmp("-add", argv[1]) == 0)
{
printf("%d + %d = %d\n", x, y, x + y);
}
else if (strcmp("-sub", argv[1]) == 0)
{
printf("%d - %d = %d\n", x, y, x - y);
}
else if (strcmp("-mul", argv[1]) == 0)
{
printf("%d * %d = %d\n", x, y, x * y);
}
else if (strcmp("-div", argv[1]) == 0)
{
printf("%d / %d = %d\n", x, y, x / y);
}
else
{
printf("unknown!\n");
}
return 0;
}
上面是我们根据输入的命令行参数的选项来做不同功能的函数:
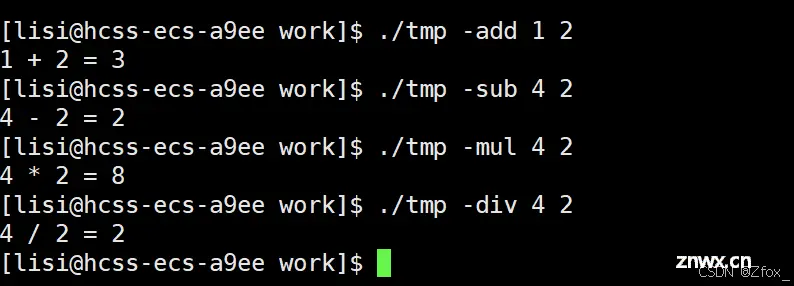
这样我们就可以通过不同的选项,让我们同一个程序执行它内部不同的功能。
这个功能是不是很像我们的指令?(比如:ls 指令)为什么我们指令可以根据不同的选项而做出不同的动作?原因就在于我们的选项传递到main函数中的 argc 和 argv当中,所以能够完成同一个指令根据不同选项做出对应的功能,所以,选项的本质就是命令行参数!
四:🔥 共勉
以上就是我对 <code>【Linux】进程优先级、调度、命令行参数:从理论到实践(二) 的理解,会立刻更新下一篇的,觉得这篇博客对你有帮助的,可以点赞收藏关注支持一波~😉

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。