Res2Net网络
@默然 2024-07-02 09:37:02 阅读 93
Res2Net网络
摘要Abstract1. Res2Net网络1.1 文献摘要1.2 背景1.3 创新点1.4 网络结构1.5 实验1.5.1 在ImageNet数据集上进行实验1.5.2 在CIFAR数据集上进行实验
2. Res2Net代码实现3. 总结
摘要
Res2Net是一种神经网络架构,旨在改善类似ResNet的网络在计算机视觉任务中的性能,特别是在图像分类方面,Res2Net的关键思想是改变网络中特征聚合的方式,从而实现更有效的不同部分之间的信息交换,在标准的ResNet块中,特征在空间维度(高度和宽度)和通道维度上独立地聚合。相比之下,Res2Net引入了一种新的特征图分割操作,沿着通道维度将输入特征图分成多个组。这样可以进行跨组特征聚合,使网络能够捕获更丰富的空间信息。本文将详细介绍Res2Net。
Abstract
Res2Net is a neural network architecture designed to improve the performance of ResNet-like networks in computer vision tasks, especially in image classification.The key idea of Res2Net is to change the way features are aggregated in the network to enable more efficient exchange of information between the different parts of the network.In standard ResNet blocks, features are aggregated in the spatial dimension (height and width) and the channel dimensions are aggregated independently. In contrast, Res2Net introduces a new feature map segmentation operation that divides the input feature map into groups along the channel dimension. This allows cross-group feature aggregation and enables the network to capture richer spatial information. In this paper, we describe in detail the Res2Net.
1. Res2Net网络
文献出处:Res2Net: A New Multi-Scale
Backbone Architecture
1.1 文献摘要
在多个尺度上表示特征对于许多视觉任务非常重要。主干卷积神经网络 (CNN) 的最新进展不断展现出更强的多尺度表示能力,从而在广泛的应用中实现一致的性能提升。 然而,大多数现有方法以分层方式表示多尺度特征。 在本文中,作者提出了一种新颖的 CNN 构建块,即 Res2Net,通过在单个残差块内构建分层的类残差连接,Res2Net 在粒度级别上表示多尺度特征,并增加了每个网络层的感受野范围。 所提出的 Res2Net 模块可以插入最先进的骨干 CNN 模型,例如 ResNet、ResNeXt 和 DLA。
1.2 背景
自然场景中的视觉图案以多尺度出现。
单个图像中的物体可能会出现不同的尺寸,例如沙发和杯子的尺寸不同。对象的基本上下文信息可能占据比对象本身大得多的区域。 例如,我们需要依靠大桌子作为上下文来更好地判断放在上面的黑色小斑点是杯子还是笔架。从不同尺度感知信息对于理解细粒度分类和语义分割等任务的部件和对象至关重要。
因此,为视觉认知任务的多尺度刺激设计良好的特征至关重要。在视觉任务中获得多尺度表示需要特征提取器使用大范围的感受野来描述不同尺度的对象/部分/上下文。 卷积神经网络(CNN)通过一堆卷积算子自然地学习从粗到细的多尺度特征,CNN 固有的多尺度特征提取能力可以有效地表示解决众多视觉任务。
1.3 创新点
在这项工作中,我们提出了一种简单而有效的多尺度处理方法,与大多数增强 CNN 分层多尺度表示强度的现有方法不同,我们在更细粒度的级别上提高了多尺度表示能力。
多尺度表示能力指的是一种能够捕捉和表达不同尺度或层次上特征或细节的能力。这种能力在处理复杂数据时尤为重要,因为它允许我们更全面地理解数据的结构和内容。以图像处理为例,一张图片通常包含从全局到局部的多种尺度的信息。全局尺度可能指的是整个图像的场景或布局,而局部尺度则可能涉及图像中的特定物体、纹理或细节。具有多尺度表示能力的模型或算法能够同时处理这些不同尺度的信息,从而更准确地分析和理解图像。具体来说,假设我们有一张包含不同大小物体的图像,如一张风景照,其中包含远处的山脉、中距离的树木和近处的花草。如果我们只关注全局尺度,可能会忽略掉近处的细节;而如果我们只关注局部尺度,则可能会失去对整体场景的理解。然而,具有多尺度表示能力的图像处理系统可以同时捕捉这些不同尺度的信息。它可以通过不同尺度的滤波器或特征提取器来提取图像中不同尺度的特征,并将这些特征融合起来以形成对图像的全面理解。
与通过利用不同分辨率的特征来提高多尺度能力不同,作者方法的多尺度是指更细粒度的多个可用感受野 。
作者用一组较小的滤波器组替换了 n 个通道的 3*3 个滤波器,每个滤波器组有 w 个通道。 如图 2 所示,这些较小的滤波器组以分层残差样式连接,以增加输出特征可以表示的尺度数量。
我们将输入特征图分为几组。 一组过滤器首先从一组输入特征图中提取特征。 然后,前一组的输出特征与另一组输入特征图一起发送到下一组过滤器。 这个过程重复几次,直到处理完所有输入特征图。 最后,来自所有组的特征图被连接并发送到另一组 11 过滤器以完全融合信息。 连同输入特征转换为输出特征的任何可能路径,每当通过 33 滤波器时,等效感受野都会增加,从而由于组合效应而产生许多等效特征尺度。如下图
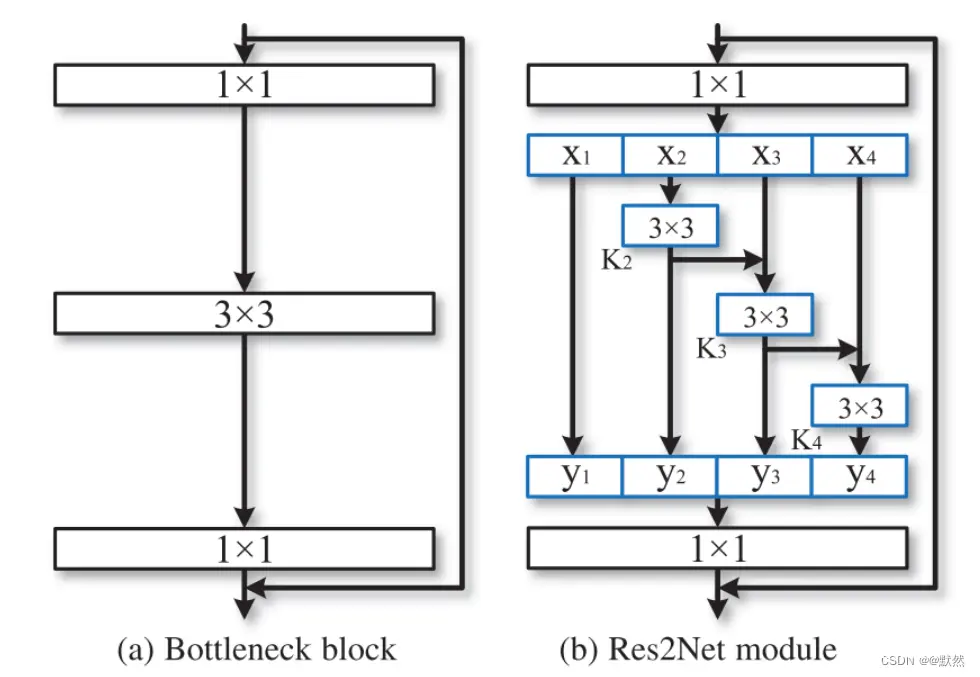
作者所提出的方法在更细粒度的级别上利用了多尺度潜力,Res2Net 模块可以轻松插入到许多现有的 CNN 架构中。
1.4 网络结构
上图显示了Bottleneck模块和所提出的 Res2Net 模块之间的差异。 经过 1 * 1 卷积后,将特征图均匀地分割为
s
s
s个特征图子集,用
x
i
x_i
xi 表示,其中
i
∈
{
1
,
2
,
.
.
.
,
s
}
i\in \left \{ 1,2,...,s \right \}
i∈{ 1,2,...,s}。 每个特征子集
x
i
x_i
xi 具有相同的空间大小,但与输入特征图相比,通道数为 1/s。 除
x
1
x_1
x1 外,每个
x
i
x_i
xi 都有对应的 3 * 3 卷积,记为
K
i
(
)
K_i()
Ki()。 我们用
y
i
y_i
yi 表示
K
i
(
)
K_i()
Ki() 的输出。 特征子集
x
i
x_i
xi 与
K
i
−
1
(
)
K_{i-1}()
Ki−1() 的输出相加,然后输入
K
i
(
)
K_{i}()
Ki()。 为了在增加 s 的同时减少参数,我们省略了
x
1
x_1
x1 的 3 * 3 卷积。
y
i
y_i
yi 可以写成
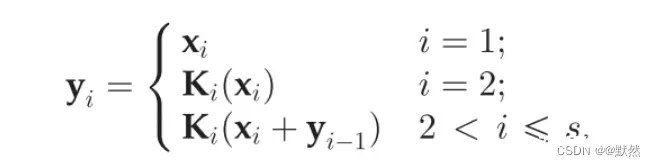
每个 3 * 3 卷积算子
K
i
(
)
K_i()
Ki() 都可能从所有特征分割
x
j
,
{
j
<
i
}
x_{j},\left \{ j<i \right \}
xj,{ j<i} 接收特征信息。 每次特征分割
x
j
x_j
xj 经过 3×3 卷积算子时,输出结果可以具有比
x
j
x_j
xj 更大的感受野。 由于组合爆炸效应,Res2Net模块的输出包含不同数量和不同组合的感受野大小/尺度。
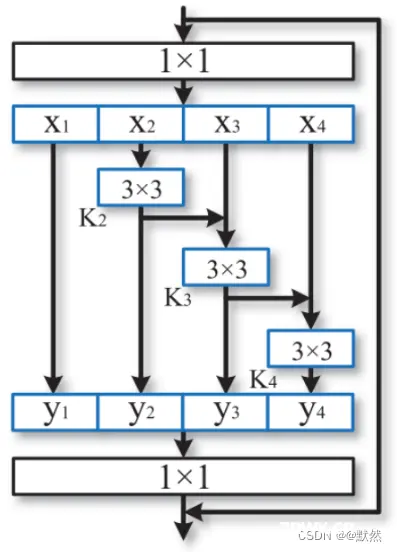
在Res2Net模块中,分割以多尺度方式处理,这有利于全局和局部信息的提取。 为了更好地融合不同尺度的信息,我们连接所有分割并将它们传递给 1 * 1 卷积。 分割和串联策略可以强制卷积以更有效地处理特征。 为了减少参数数量,作者省略了第一次分割的卷积,这也可以看作是特征重用的一种形式。
1.5 实验
作者使用 Pytorch 框架实现所提出的模型,使用 ResNet、ResNeXt、DLA 以及 bLResNet-50 的 Pytorch 实现,并且仅用提出的 Res2Net 模块替换原始瓶颈块。 与之前的工作类似,在 ImageNet 数据集上,每个图像都是从调整大小的图像中随机裁剪的 224 * 224 像素。使用 SGD 在 4 个 Titan Xp GPU 上训练网络,权重衰减为 0.0001,动量为 0.9,小批量为 256。 学习率最初设置为 0.1,每 30 个 epoch 除以 10。
ImageNet 的所有模型(包括基线模型和提出的模型)均使用相同的训练和数据论证策略训练 100 个 epoch。 在 CIFAR 数据集上,我们使用 ResNeXt-29 的实现。 对于所有任务,作者都使用基线的原始实现,并且仅用建议的 Res2Net 替换主干模型。
1.5.1 在ImageNet数据集上进行实验
作者在 ImageNet 数据集上进行了实验,该数据集包含来自 1,000 个类别的 128 万张训练图像和 5 万张验证图像。 我们构建了大约 50 层的模型,用于根据最先进的方法进行性能评估。下表显示了 ImageNet 数据集上的
t
o
p
−
1
top^{-1}
top−1 和
t
o
p
−
5
top^{-5}
top−5 测试误差。
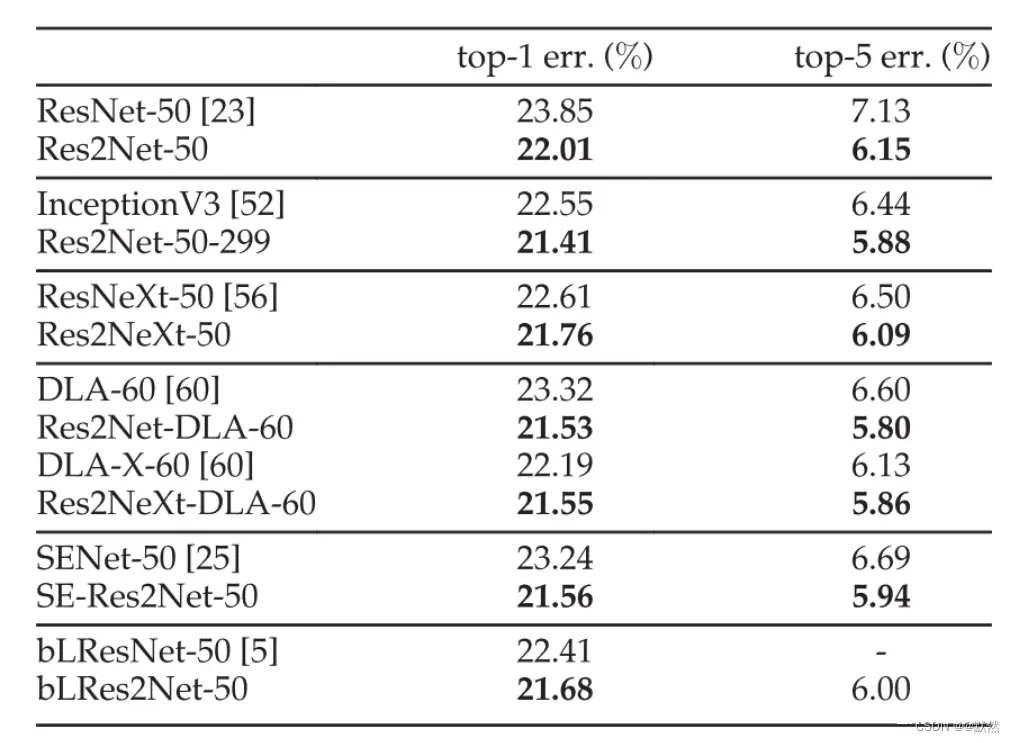
与 ResNet-50 相比,Res2Net-50 的
t
o
p
−
1
top^{-1}
top−1 误差降低了 1.84%。 与 ResNeXt-50 相比,Res2NeXt-50 在
t
o
p
−
1
top^{-1}
top−1 错误方面实现了 0.85% 的改进。 此外,Res2Net-DLA60 在
t
o
p
−
1
top^{-1}
top−1 错误方面比 DLA-60 高 1.27%。 就
t
o
p
−
1
top^{-1}
top−1 误差而言,Res2NeXt-DLA-60 的性能比 DLA-X-60 高出 0.64%。 SE-Res2Net-50 比 SENet-50 提高了 1.68%。 bLRes2Net-50 与 bLResNet-50 相比,
t
o
p
−
1
top^{-1}
top−1 错误率提高了 0.73%。
Res2Net 模块进一步增强了 bLResNet 在粒度级别的多尺度能力,即使 bLResNet 被设计为利用不同尺度的特征,ResNet、ResNeXt 、SE-Net 、bLResNet 和 DLA 是最先进的 CNN 模型。 与这些强大的基线相比,那些与 Res2Net 模块集成的模型仍然具有一致的性能增益。
1.5.2 在CIFAR数据集上进行实验
作者也在 CIFAR-100 数据集上进行了一些实验,其中包含 50k 训练图像和 10k 测试图像。
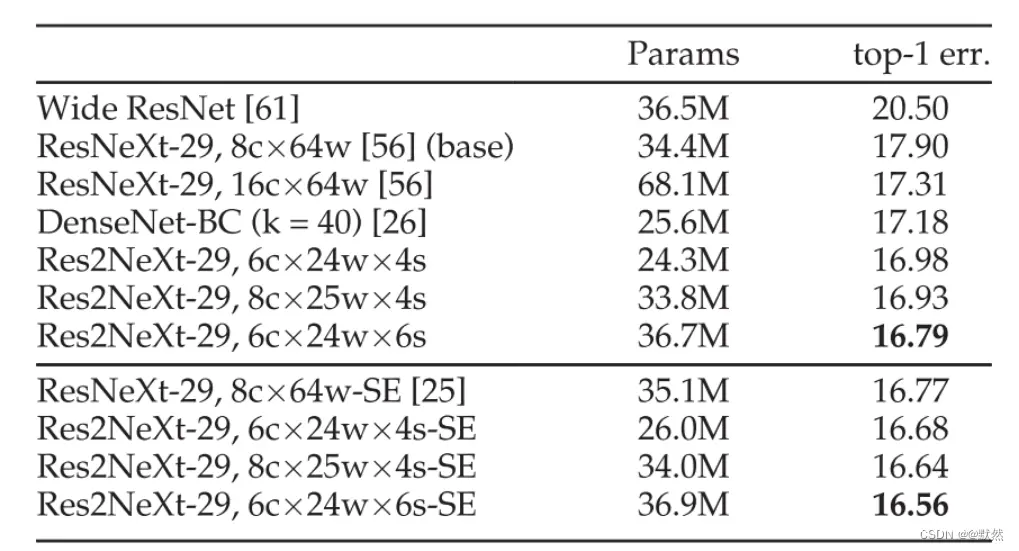
上表显示了 CIFAR-100 数据集上的
t
o
p
−
1
top^{-1}
top−1 测试误差和模型大小。 实验结果表明,我们的方法超越了基线和其他参数较少的方法。
2. Res2Net代码实现
import torch
import torch.nn as nn
import torch.nn.functional as function
class Res2NetBlock(nn.Module):
def __init__(self, inplanes, outplanes, scales=4):
super(Res2NetBlock, self).__init__()
if outplanes % scales != 0: # 输出通道数为4的倍数
raise ValueError('Planes must be divisible by scales')
self.scales = scales
# 1*1的卷积层
self.inconv = nn.Sequential(
nn.Conv2d(inplanes, 32, 1, 1, 0),
nn.BatchNorm2d(32)
)
# 3*3的卷积层,一共有3个卷积层和3个BN层
self.conv1 = nn.Sequential(
nn.Conv2d(8, 8, 3, 1, 1),
nn.BatchNorm2d(8)
)
self.conv2 = nn.Sequential(
nn.Conv2d(8, 8, 3, 1, 1),
nn.BatchNorm2d(8)
)
self.conv3 = nn.Sequential(
nn.Conv2d(8, 8, 3, 1, 1),
nn.BatchNorm2d(8)
)
# 1*1的卷积层
self.outconv = nn.Sequential(
nn.Conv2d(32, 32, 1, 1, 0),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True)
)
def forward(self, x):
input = x
x = self.inconv(x)
# scales个部分
xs = torch.chunk(x, self.scales, 1)
ys = []
ys.append(xs[0])
ys.append(function.relu(self.conv1(xs[1])))
ys.append(function.relu(self.conv2(xs[2]) + ys[1]))
ys.append(function.relu(self.conv2(xs[3]) + ys[2]))
y = torch.cat(ys, 1)
y = self.outconv(y)
output = function.relu(y + input)
return output
3. 总结
本文提出了一个简单而高效的模块,即 Res2Net,以在更细粒度的级别上进一步探索 CNN 的多尺度能力。 Res2Net暴露了一个新的维度,即“尺度”,它是除了现有的深度、宽度和基数维度之外的一个重要且更有效的因素。Res2Net 模块可以毫不费力地与现有的最先进的方法集成。 CIFAR-100 和 ImageNet 基准的图像分类结果表明,这个新的主干网络始终优于最先进的竞争对手,包括 ResNet、ResNeXt、DLA 等。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。