[Linux] Linux进程PCB内部信息的深入理解
水墨不写bug 2024-10-08 15:07:03 阅读 88
标题:[Linux] Linux进程PCB内部信息的深入理解
个人主页:@水墨不写bug
(图片来自网络)

目录
一.查看进程
二.认识并了解进程的关键信息
I,PID/PPID
II,exe
III,cwd
三、fork()创建进程
正文开始:
一.查看进程
进程的信息可以通过 /proc 系统文件夹查看。
proc目录介绍:
/proc这个目录下的文件数据是内存级别的数据,操作系统启动,操作系统会遍历进程的PCB,最终形成proc目录下的文件数据。
这些数据不是磁盘级别,而是内存级别的。
proc是实时更新的,运行一个进程,这个进程的PID就会出现在proc目录中。
如:要获取PID为1的进程信息,你需要查看 /proc/1 这个文件夹。
我们可以使用ls、top、ps等命令查看当前正在运行的进程:
ls:
命令:ls /proc
top:
命令:top
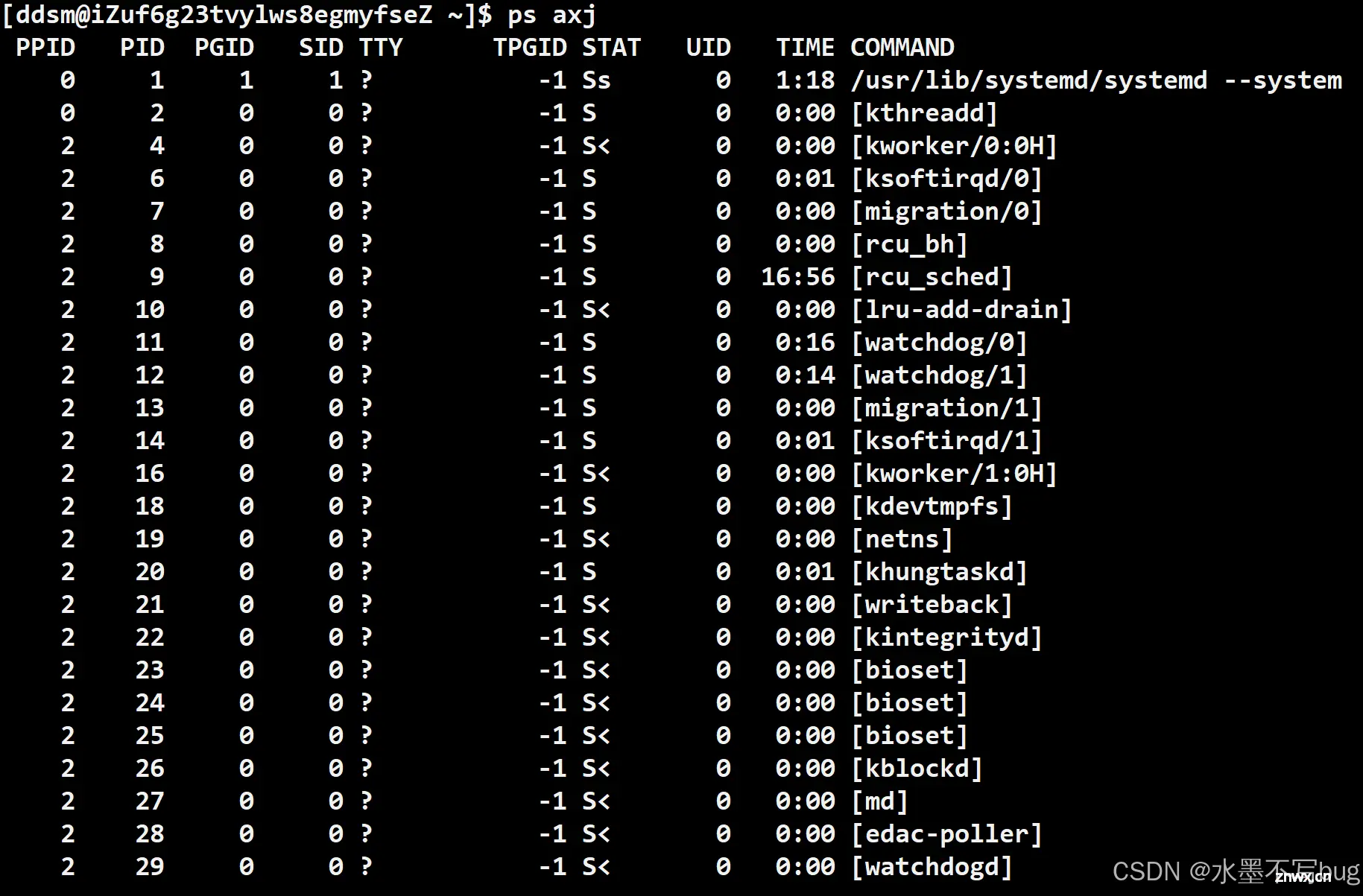
ps:
命令:ps axj
特别的,对于ps axj命令,我们如果知道进程的文件名,可以通过管道来获取关键名,进行更高效的搜索展示:
比如我们提前运行起来名字为mytest的程序,那么可以使用管道结合grep:
ps axj | grep mytest


二.认识并了解进程的关键信息
I,PID/PPID
进程id(PID):每一个进程都有自己的独特的标识自己的ID。
就像人的身份证,学生的学号一样,一个进程创建的时候会有自己的PID。进程的PID是一个大整数,一旦获取,在进程结束之前都是不变的。同一个可执行程序,在不同时间运行,PID不同,并且后面的PID较大。
父进程id(PPID):相对父辈的进程的PID;
我们可以通过 头文件<unistd.h> 的 getpid() 和 getppid() 函数来得到进程的PID和PPID:
<code>#include<unistd.h>
#include<sys/types.h>
using namespace std;
int main()
{
while(1)
{
int i = 1;
while(i != 1e9)
{
++i;
}
cout<<"-----------"<<endl;
cout<<"my pid:"<<getpid()<<endl;
cout<<"my ppid:"<<getppid()<<endl;
}
return 0;
}
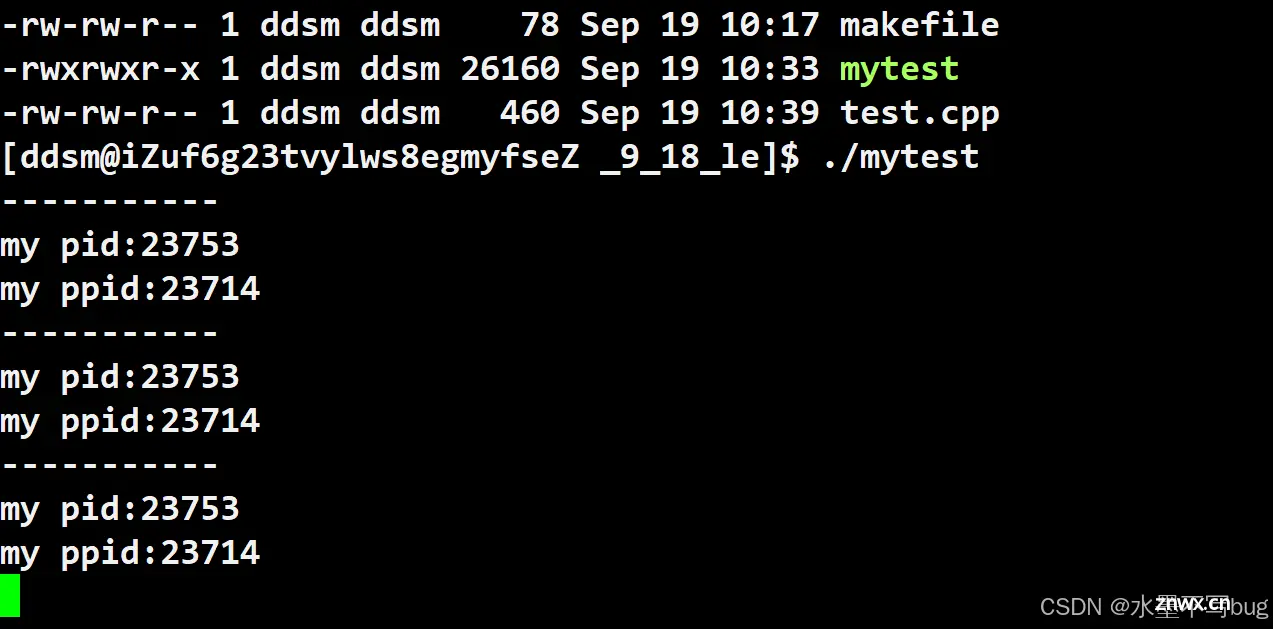
上面的进程运行起来之后:

通过分析,当前运行进程的pid=23654,没什么问题。
为了方便演示进程,我们故意写了一个死循环;如果想要结束这个进程,我们可以采取如下的方式:
杀进程:ctrl + C 或者 kill -9 + 进程PID
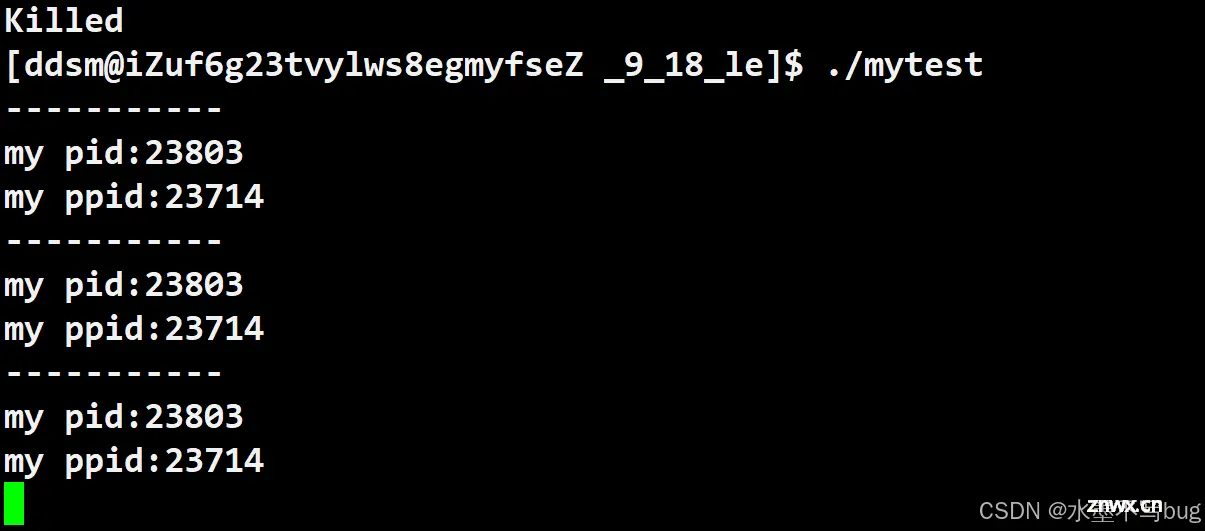
当我们杀掉进程后,再次运行起来,发现pid=变大了,没问题。 但是问题是两次运行的ppid是相同的!通过查询我们发现 ppid=23714的进程正是Bash(命令行解释器)
在命令行中,执行命令/执行程序的,本质是Bash的进程创建子进程,由子进程执行我们的代码。(Bash是Linux下常用的 shell 外壳)
II,exe
exe链接到可执行程序的位置
进程在运行起来时,exe记录了当前这个运行的程序的位置;是当前程序的固有属性,不变的。
III,cwd
cwd(current work directory)当前工作目录
cwd记录了当前工作目录:是我们进行操作的目录,是可指定的。一般而言,我们的工作目录就是当前所处的目录。
这也就解释了在C语言阶段时,当我们在源码中使用fopen时,为什么默认创建的文件的位置是当前文件夹。因为cwd会存储当前程序运行的目录位置,并自动拼接在我们创建的文件名称之前,于是创建的文件默认是在当前路径。如果想要指定路径,则需要写绝对路径。
三、fork()创建进程
父进程的概念:在Linux中, 程序启动之后,新建任何进程的时候,都是由自己的父进程创建的。
父进程id(PPID):相对父辈的进程的PID;
父子进程的关系满足树状结构:一个父进程可以有多个子进程;而一个子进程只有唯一的父进程。
fork函数的man手册解释:
通过查看man手册,我们发现fork函数的解释是十分费解的。

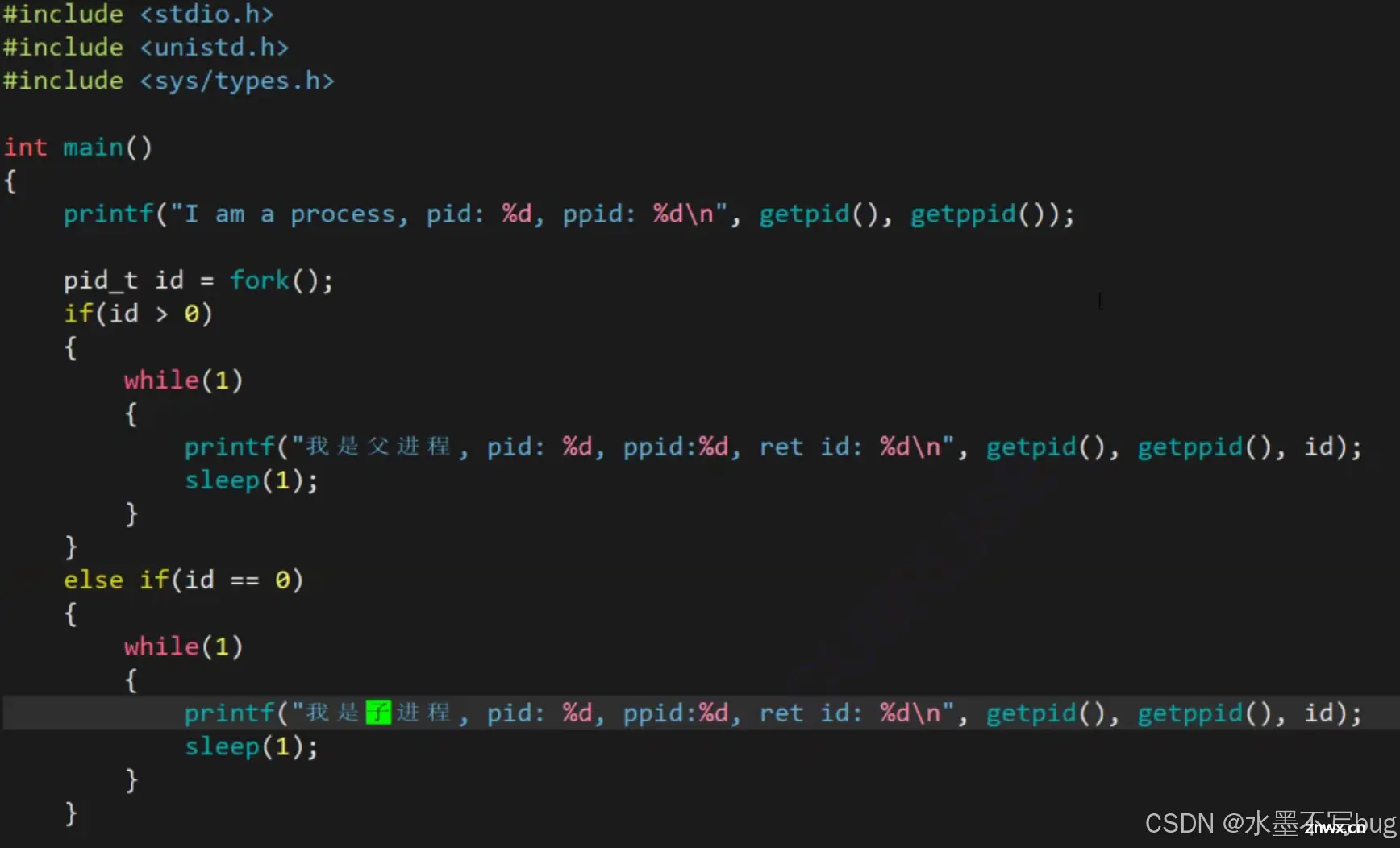
想要理解fork()函数,仅仅看解释还不够,需要理解下面这一段代码并解释清楚运行情况才可以:
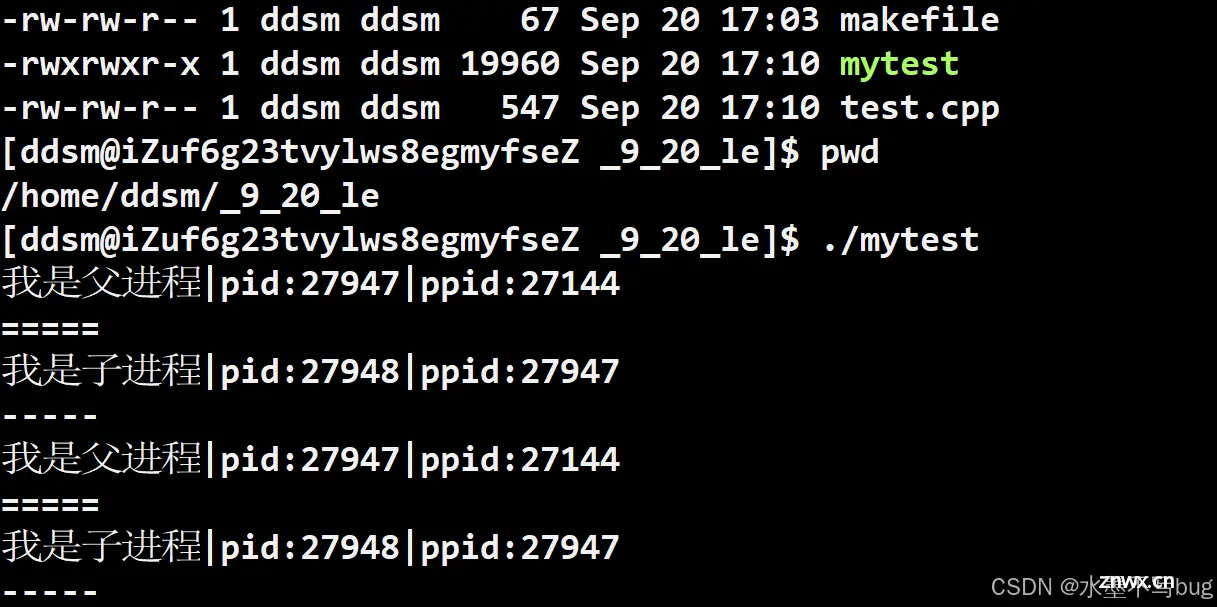
当我们运行起来这一个程序,我们会发现这样的现象:
我们会发现if和else的语句同时被执行了,一般而言这是不可能发生的事情!
原因在于,在fork创建一个子进程之后,这个进程的执行分支就不再是一个执行分支了,而是两个执行分支。一个分支的id满足if的条件,而另一个分支的id满足else的条件,所以整体上表现出if和else同时被执行的错觉。
在前面的讲解中,我们知道:
进程 = 内核数据结构 + 代码和数据
当我们在进程A中创建一个进程a1时,a1可以拥有内核数据结构,但是a1到哪里去加载代码和数据呢?
于是,进程A创建的子进程a1就加载了进程A的代码和数据,但是两份代码和数据是相互独立的。也就是说,进程A中的全局变量glo = 0,在fork之后,子进程修改glo,修改的是自己的glo,而不是进程A的glo,进程A的glo仍=0;
fork:fork创建子进程之后,父子进程的代码共享。但是数据各自独自私有一份,数据独立。
为什么?
进程具有很强的独立性,多个进程之间,运行时,互不影响。包括父子进程之间。
(就比如你在VS上写一个代码,编译出的可执行程序运行时出现野指针,崩了,但是VS不会挂。这就是因为VS进程和你写的进程是两个进程,进程之间具有很强的独立性)
fork总结:
1.id的返回值,给父进程(pid),子进程(0);
2.fork会有两个返回值--为什么?
因为子进程加载了父进程的代码和数据,自己单独返回了id给自己的那一份数据赋值。
3.接收fork的返回值只有一个变量,怎么会有不同的值?
本质上与2是相同的问题,此外也是为了保持进程之间的独立性。
怎么做到的?
--进程地址空间
fork之后哪一个进程先运行?
由操作系统的调度器自主决定。
完·~
未经作者同意禁止转载
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。