[Linux#62][TCP] 首位长度:封装与分用 | 序号:可靠性原理 | 滑动窗口:流量控制
lvy- 2024-10-17 08:37:06 阅读 79
目录
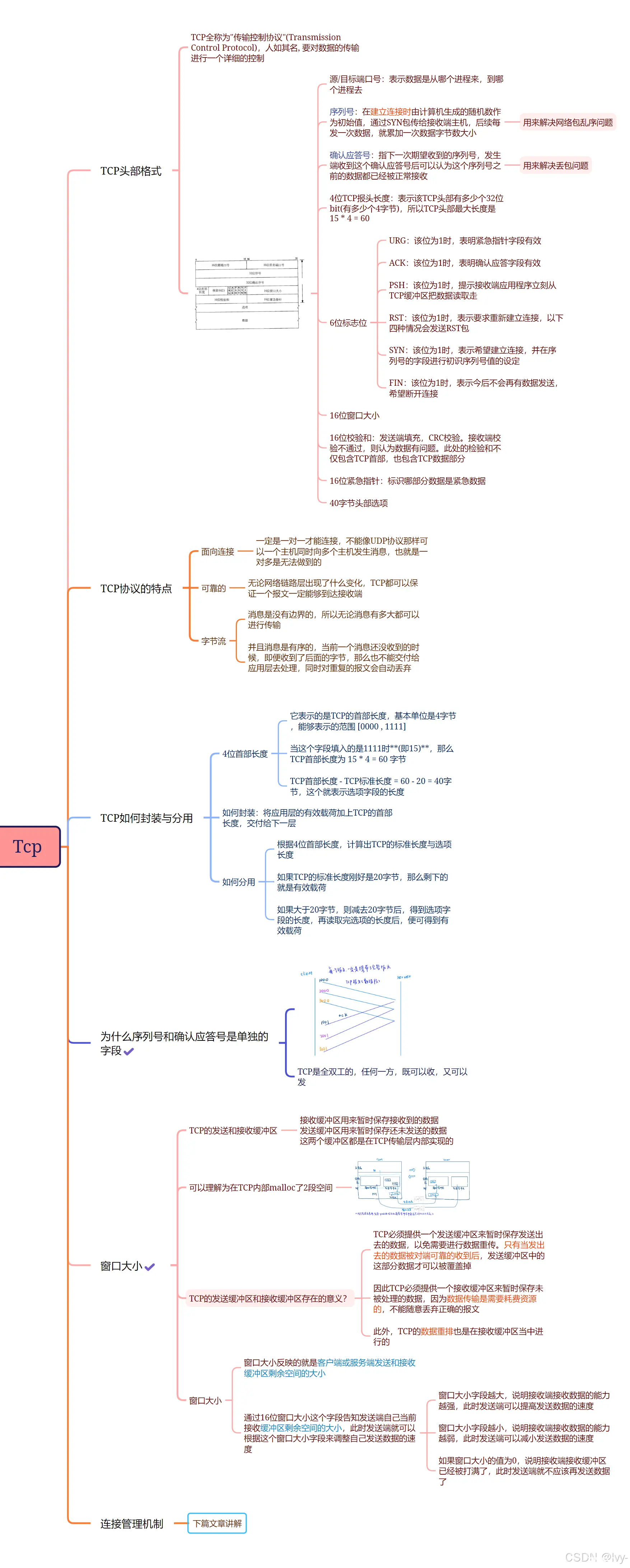
一. 认识TCP协议的报头
1.TCP头部格式
2. TCP协议的特点
二. TCP如何封装与分用
TCP 报文封装与解包
如何封装解包,如何分用
分离有效载荷
隐含问题:TCP 与 UDP 报头的区别
封装和解包的逆向过程
如何分用 TCP 报文
如何通过端口号找到绑定的进程?
数据交付给进程的过程
总结
三. TCP 的可靠性
学习 TCP 可靠性 (确认应答) && 提高传送效率
1. 网络传输中的不可靠问题
2. 网络传输中的不可靠性场景
3. TCP 可靠性的保证机制
4. TCP 收发消息的工作模式
5. 捎带应答机制
6. 批量确认的工作模式
四. 理解TCP的报头
1. 4位首位长度
2. 序号和确认序号:TCP 全双工通信与确认应答机制
2.1. TCP 真实工作模式
2.2. 问题分析
2.3. TCP 报文序号机制
2.4. 确认应答的机制
2.5. 丢包场景下的应答机制
2.6. 两组序号的必要性
2.7. 数据到达顺序与序号
3. 窗口大小:TCP缓冲区与流量控制
缓冲区的作用
数据传输过程
流量控制的必要性
流量控制机制
全双工通信
交换接收能力
TCP报头细节很多,我们打算这样开始
认识TCP协议的报头 — 字段如何理解TCP的报头如何封装解包,如何分用学习TCP可靠性(确认应答) && 提高传送效率
一. 认识TCP协议的报头
1.TCP头部格式
TCP全称“传输控制协议”(Transmission Control Protocol),它对数据传输进行了详细的控制。TCP头部包含多个字段,每个字段都有特定的功能,以确保数据能够可靠地从一个端点传输到另一个端点。
理解TCP的报头:
Linux内核是C语言写的,在UDP说过报头是协议的表现,而协议本质就是结构体数据。所有tcp报头就是一个结构化或位段。
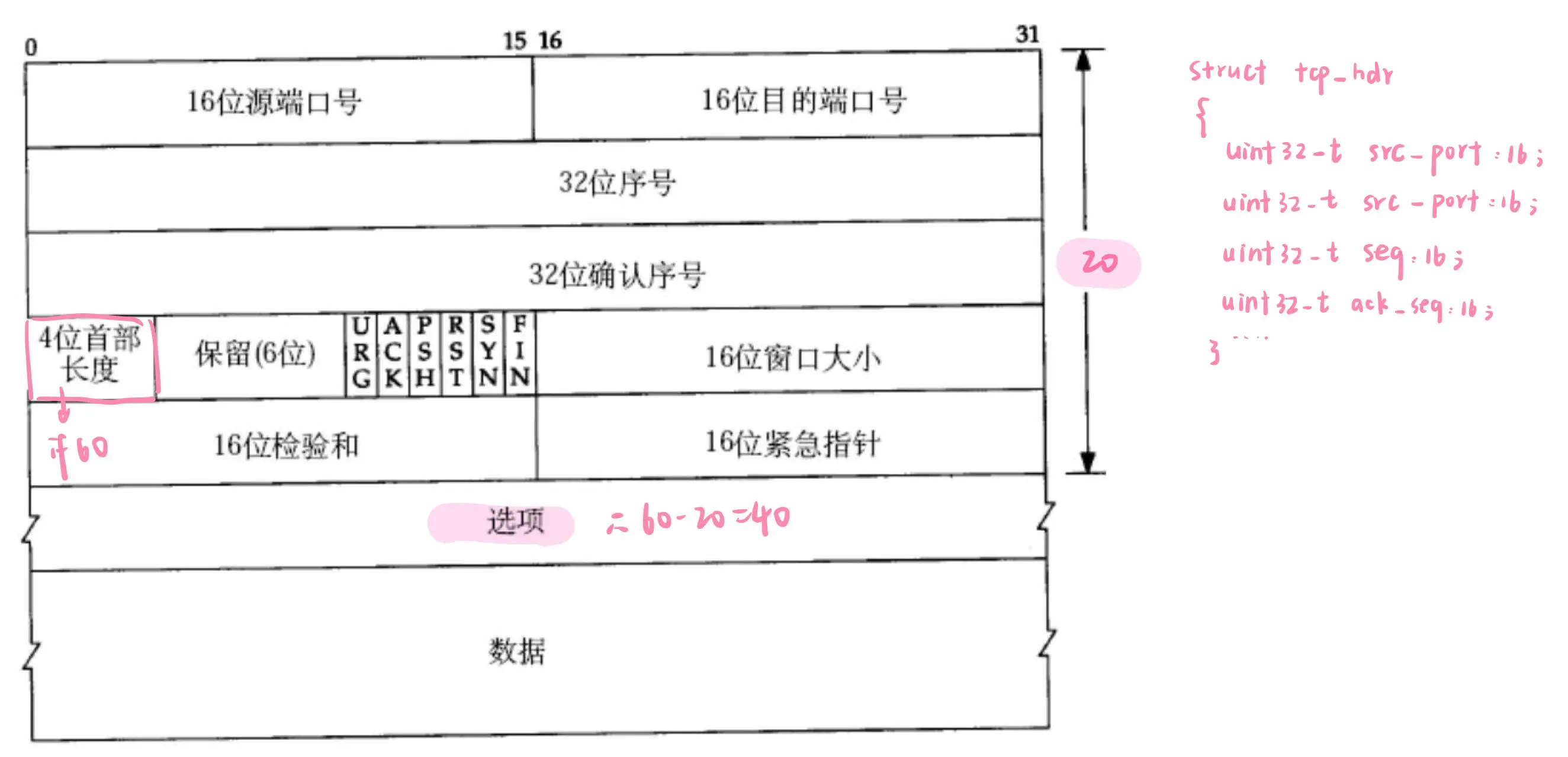
struct tcp_hdr这是一个类型,可以定义出一个对象。
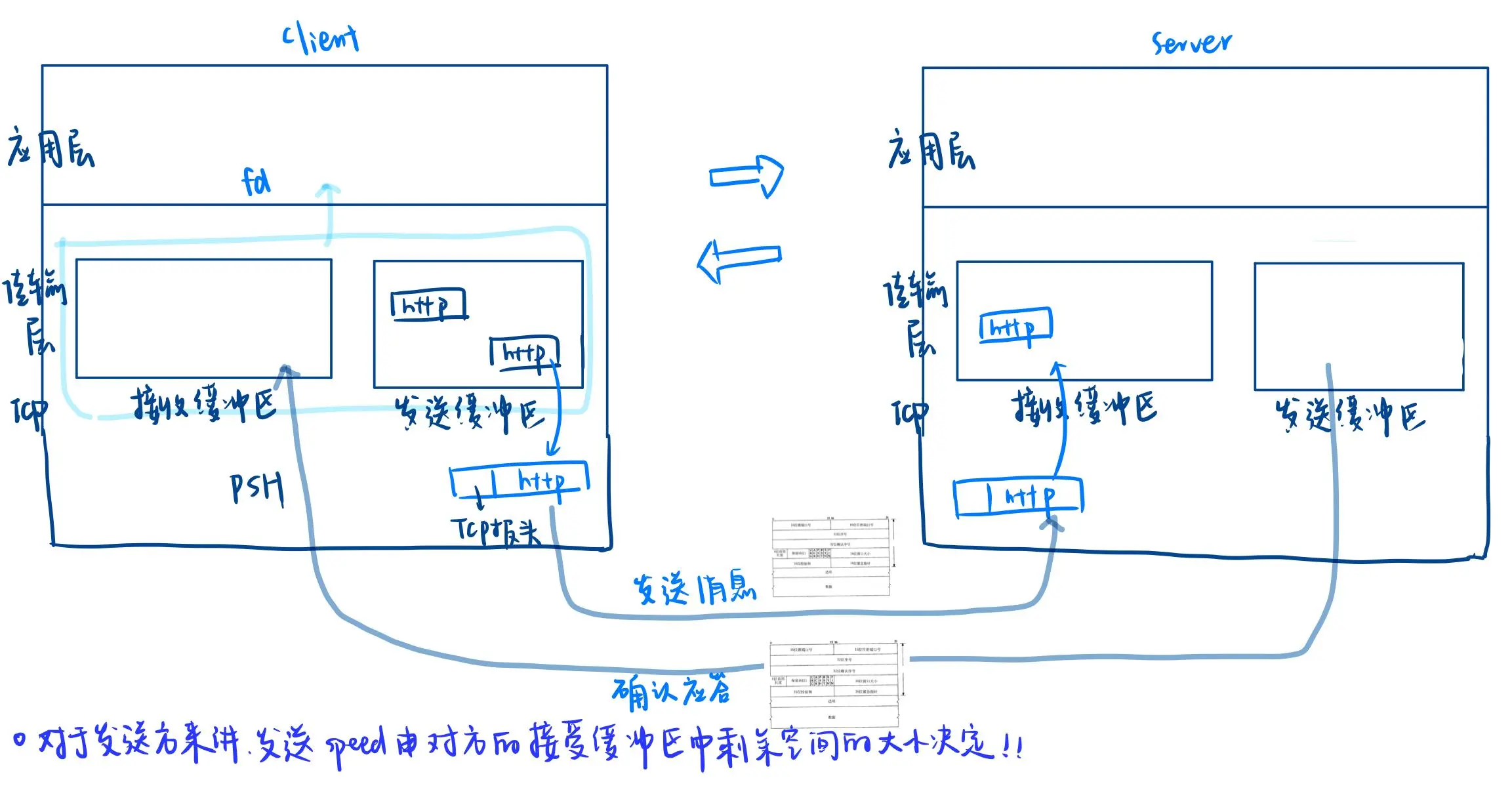
把应用层的数据拷贝到缓冲区里,然后把报头拷贝到前面,不就是添加报头吗~
TCP协议报文也有自己的报头+有效载荷,这个有效载荷是应用层的报文,当然包含应用层报头和有效载荷。
源/目的端口号: 表示数据是从哪个远端进程来, 到服务器哪个进程去序列号:用于解决网络包乱序问题,每次发送数据时累加数据字节数。确认应答号:指下一次期望收到的序列号,帮助解决丢包问题。4位TCP报头长度:表示该TCP头部有多少个32位比特,最大长度为60字节。
6位标志位:
SYN: 希望建立连接。ACK: 确认应答字段有效。FIN: 断开连接。PSH: 提示接收端应用程序立刻读取数据。RST: 要求重新建立连接。URG: 表示紧急指针字段有效。
16位窗口大小:表明接收缓冲区还能容纳多少数据。16位校验和:验证整个TCP段的完整性。16位紧急指针:标识紧急数据的位置。40字节头部选项:提供额外的信息或功能。
2. TCP协议的特点
面向连接:TCP必须先建立连接才能进行数据传输。可靠:无论网络状况如何变化,TCP都能保证数据的正确传递。字节流:消息无边界,可以传输任意大小的数据,并且保持顺序。
二. TCP如何封装与分用
4位首部长度:表示TCP头部的总长度。如何封装:将应用层的数据加上TCP头部后交付给IP层。如何分用:根据头部长度计算出有效载荷的位置并提取数据。
TCP 报文封装与解包
报文宽度:0-31 bit 是这个报文的宽度。每行4个字节,总共5行,因此标准 TCP 报文的长度是20字节,选项部分暂不考虑。TCP 报文标准长度:标准 TCP 报文长度是20字节。
如何封装解包,如何分用
作为接收方,如何保证把一个 TCP 报文全部读完呢?其实很简单,具体步骤如下:
读取 TCP 标准报头:
TCP 协议有标准长度:20字节。因此,先读取前 20 字节。这 20 字节转换为结构化数据后,立刻提取报头中的 4 位首部长度字段。
计算 TCP 报头总长度:
4 位首部长度字段表示的 TCP 报头总长度。其值范围为 0000-1111,即 [0,15]。4 位首部长度字段单位为 4 字节,因此 TCP 报头总长度 = 4 位首部长度 * 4 字节。报头长度范围为 [0,60] 字节。由于标准报头长度是 20 字节,因此最终 TCP 报头长度范围为 [20,60] 字节。
确定报头长度的计算:
若报头长度是 20 字节,则 4 位首部长度应填写为:x * 4 = 20,因此 x = 5,即 0101。
计算选项长度:
如果 TCP 报头长度为 x * 4,则减去 20 字节的标准长度后,剩下的即是选项的长度字节数。若无选项,则 x * 4 - 20 = 0;若有选项,则继续读取选项部分长度。
分离有效载荷
一旦读取完 TCP 报头,剩下的数据即为有效载荷,将其放入 TCP 接收缓冲区供上层继续读取。
隐含问题:TCP 与 UDP 报头的区别
UDP 报头:包含了 UDP 报文的长度,因此很容易确定 UDP 有效载荷的长度。TCP 报头:仅包含 TCP 报头长度,但并未明确有效载荷长度。这是因为 TCP 是面向字节流的协议。
封装和解包的逆向过程
解包完成后,封装的过程也可以反向推导出来。只要能解包,就可以逆向封装报文。
如何分用 TCP 报文
在 TCP 报头中有 目的端口号,通过该端口号可以定位应用层的进程,将数据交付给相应进程。
如何通过端口号找到绑定的进程?
当接收到一个报文,如何找到绑定了特定端口的进程呢?以下是过程解析:
网络协议栈与文件的关系:
虽然 PCB(协议控制块)通过双链表进行组织和管理,但为了快速定位进程,系统将每个 PCB 添加到一个数据结构中——哈希表。系统中,bind 绑定一个端口时,会在 OS 中以端口号作为 key 维护一张哈希表。
通过哈希表定位进程:
当收到一个目的端口号 8080 的报头时,OS 会使用端口号查找哈希表,迅速找到与该端口绑定的进程 PCB。
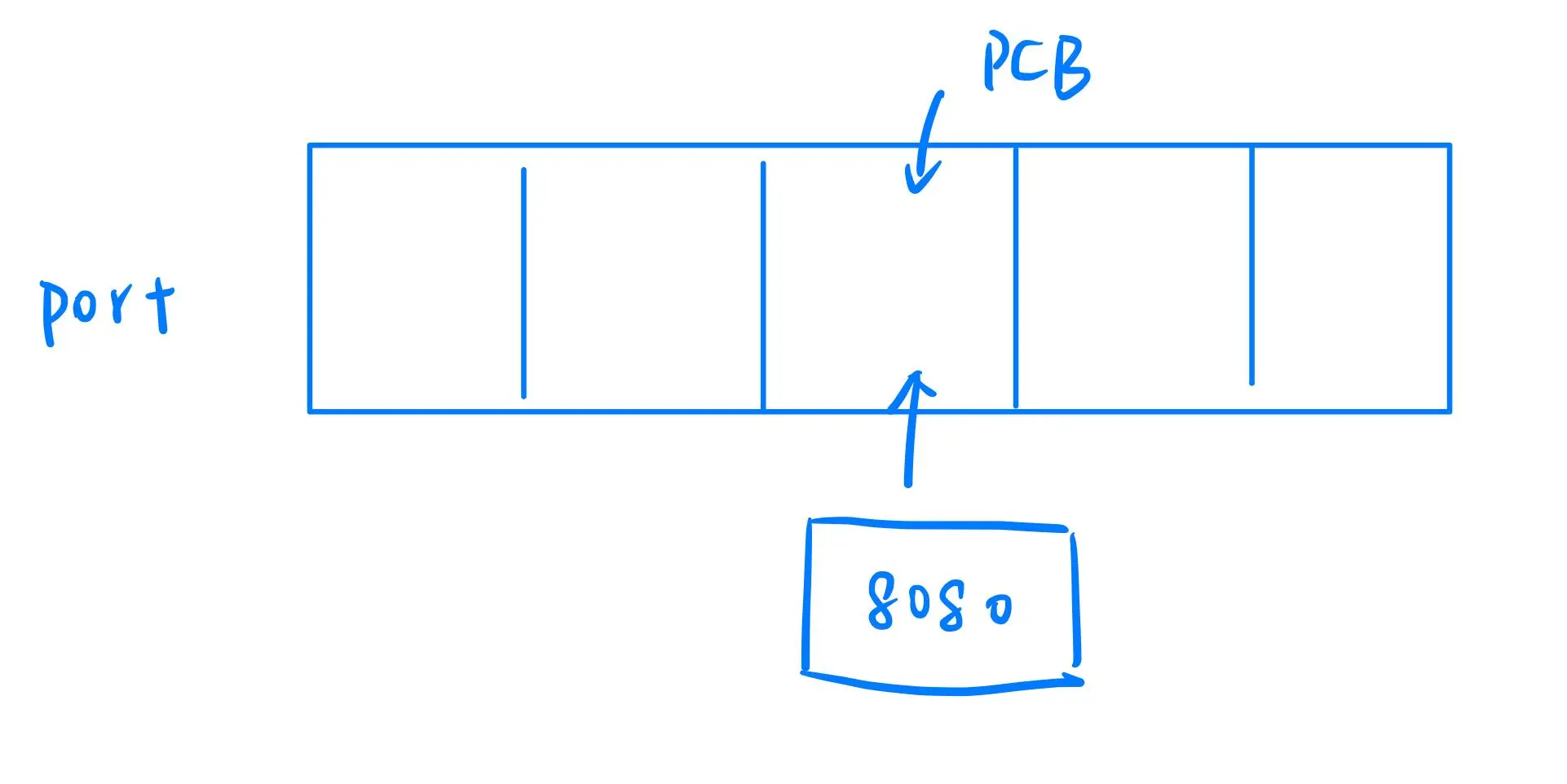
数据交付给进程的过程
找到进程后如何交付数据?
每个进程的 PCB 都维护有一个文件描述符表。文件描述符表的 0、1、2 是默认占用的,假设进程打开的文件描述符是 3,此时 socket 对应的就是 3。
Linux 文件系统与网络协议栈的关系:
在 Linux 下,一切皆文件。OS 为了维护文件,创建了一个 struct file 结构,内含许多读写方法的函数指针。Linux 下文件的读写方法通过函数指针实现,对应文件的读写方法实际是传输层的读写方法。文件还有自己的缓冲区,用于存放数据。
读写过程:
当传输层收到 TCP 报文后,会将报头和有效载荷分离。有效载荷被放入文件的缓冲区中,上层应用通过文件描述符读取缓冲区,即可获取数据。
总结
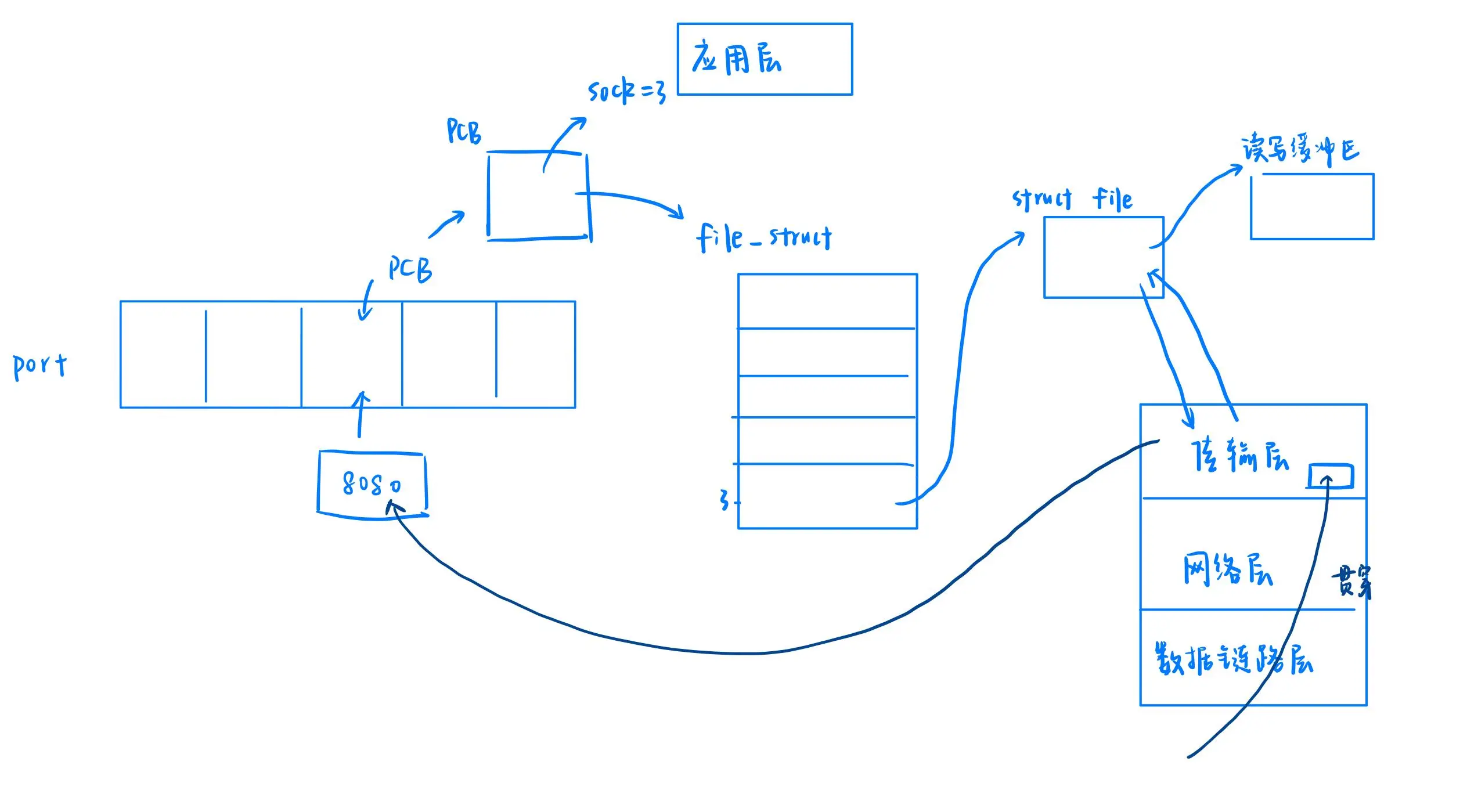
数据报文经过 OS 各层处理,最终将有效载荷存放到文件的缓冲区中。上层应用可以通过文件的方式统一读取网络数据,实现了网络数据的封装与解包。
三. TCP 的可靠性
32位序列号:对每个字节的数据编号,确保按序到达。32位确认应答号:响应历史数据,确保数据被正确接收。确认机制:通过序列号和确认应答号来保证数据的可靠性。
学习 TCP 可靠性 (确认应答) && 提高传送效率
1. 网络传输中的不可靠问题
❓ 谈 TCP 必谈可靠性,但在讨论可靠性之前,先考虑几个问题:
为什么网络传输时会存在不可靠的问题?不可靠问题常见的场景有哪些?TCP 的可靠性如何保证?
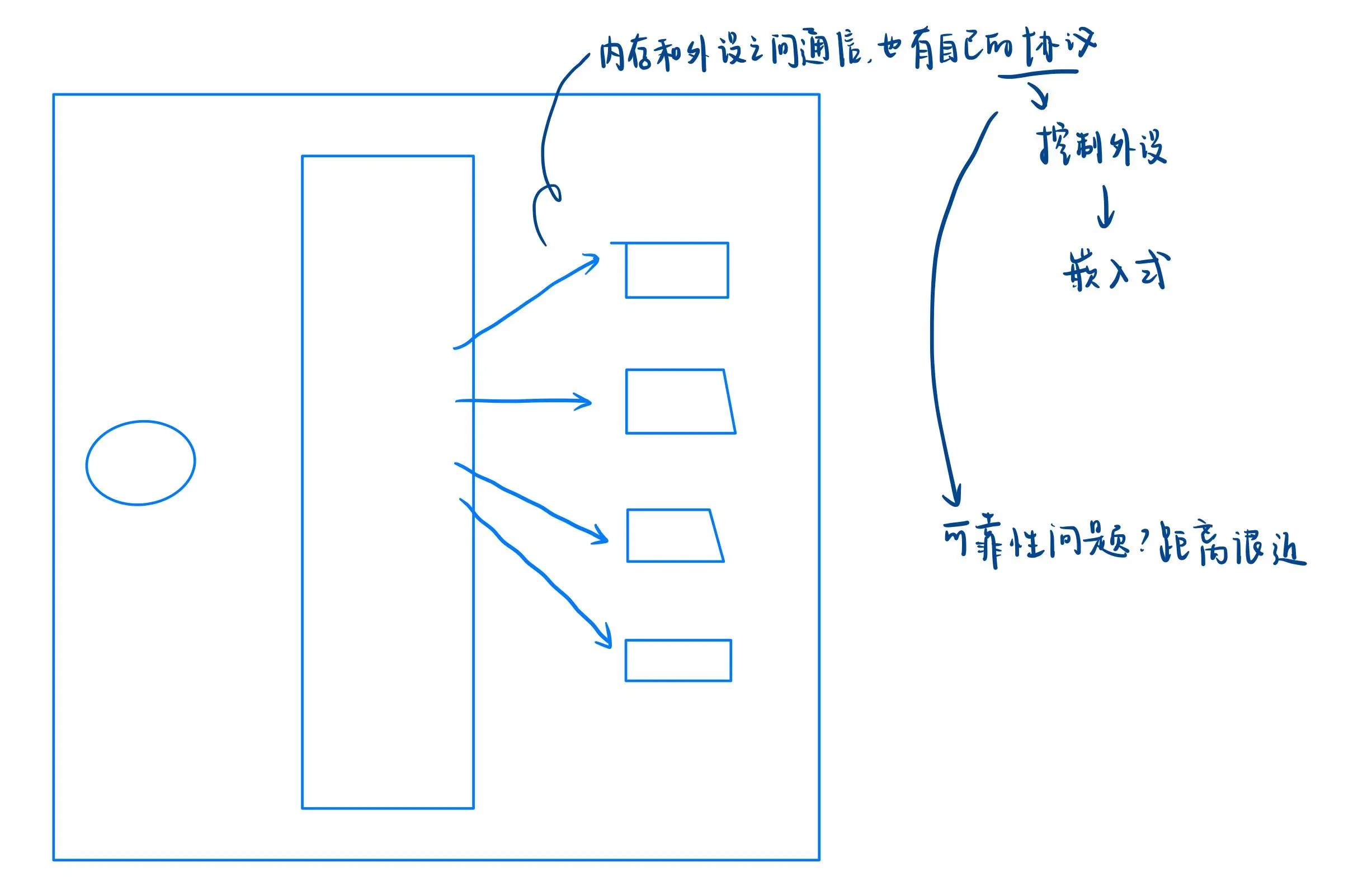
以前我们学过冯诺依曼体系结构,里面包括 CPU、内存、外设(如显示器、键盘、鼠标、磁盘等),这些设备都是独立的。但我们可以将键盘的数据放入内存,也可以将内存中的数据传送到 CPU,这说明各个硬件并非孤立的,它们之间是有联系的。这些设备通过计算机中的“线”连接。
内存和外设之间通信:通过 I/O 总线。内存和 CPU 之间通信:通过 系统总线。
内存和外设之间的通信也有自己的协议。因为有协议,所以可以控制外设。而这类协议的开发者通常属于“嵌入式”领域。
虽然内存和外设之间有通信协议,但我们并未讨论它们之间的可靠性问题。原因在于它们之间的距离很近,不存在网络传输中的可靠性问题。
2. 网络传输中的不可靠性场景
为什么网络传输时会存在不可靠的问题?
原因:传输距离变长了。
常见的不可靠场景有哪些?
丢包乱序重复校验错误
3. TCP 可靠性的保证机制
如何理解 TCP 的可靠性?
假设两个人 A 和 B 之间相隔 500 米,A 问 B:“你吃饭了吗?” A 不能确定 B 听到了,除非 A 收到 B 的应答。所以,只有在收到应答的情况下,A 才能确认 B 听到了这句话。
但当 B 给 A 回复“我吃了”时,B 也无法确定 A 是否收到了这条信息。同样,只有当 A 回应后,B 才能确定 A 收到了“我吃了”这条信息。
这个例子说明了以下两点:
只有收到了应答,才能100%确认对方收到了之前的信息。
—— 确认应答后,消息才算可靠。通信中总会存在最新消息没有得到应答的情况。
—— 最新消息一般无法保证可靠性。
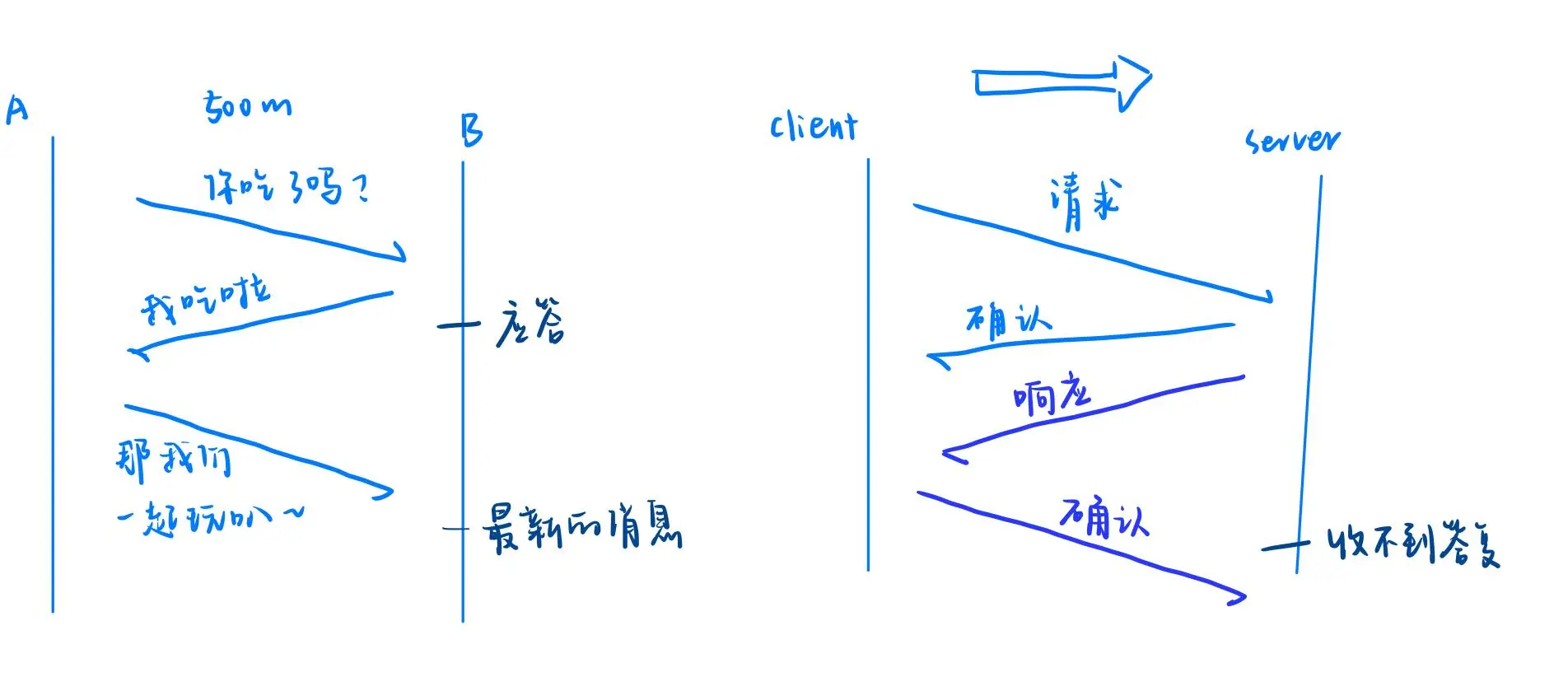
因此,传输距离变长后,不可能存在绝对可靠性,只能保证相对可靠性。只要收到应答,就能保证该报文的可靠性。这就是 TCP 可靠性的基础:确认应答机制。
4. TCP 收发消息的工作模式
在学习 TCP 时,需要理解两种工作模式:
理论上的便捷理解方式。实际工作中的 TCP 工作模式。
实际通信过程:
Client 发起请求,Server 必须给确认。
由于应答的存在,Client 可以确认 Server 100% 收到了请求,因此可以保证 Client->Server 的可靠性。Server 回应 Client,Client 也必须给确认。
同理,这也保证了 Server->Client 的可靠性。
因此,通过确认应答机制,双方的数据传输都能保证可靠性。这些请求和应答是通过封装成 TCP 报文进行发送的。在实际通信中,除了正常的数据段,通信时也包含确认数据段。
5. 捎带应答机制
在实际工作模式中,确认应答可以与对请求的响应一起打包发送。以 A 和 B 的例子为例,A 问 B “你吃饭了吗?” B 本来应先确认收到消息,再回复“我吃了”。但 B 可以直接回复“我吃了”,这一条消息既是对 A 的确认应答,也是 B 给 A 的新消息。这就是所谓的 捎带应答。
6. 批量确认的工作模式
另一种工作模式是 批量确认。Client 可以一次性给 Server 发出多个请求,Server 则可以批量确认这些请求,而非逐条应答。这种模式下,请求和应答是并发的。
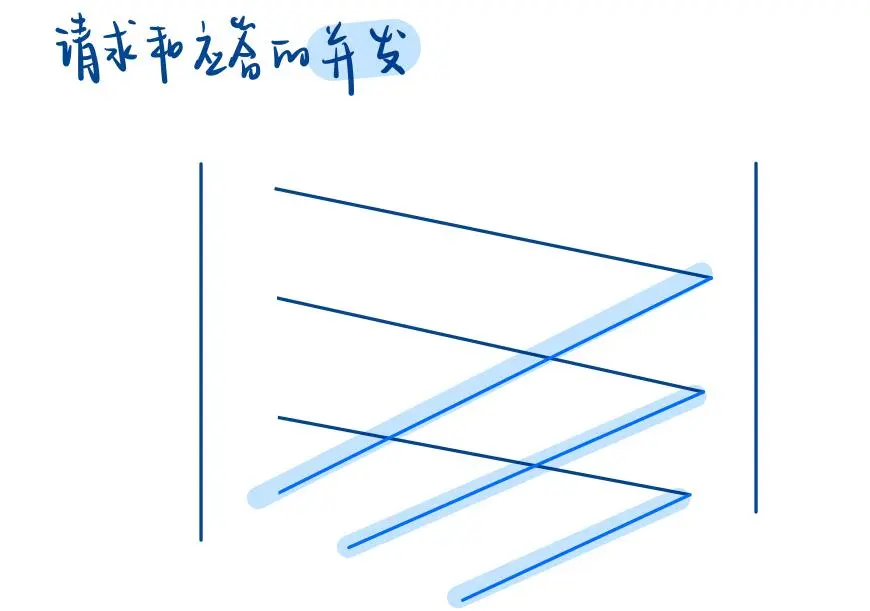
不管是串行确认还是批量确认,原则上,无论是 C->S 还是 S->C,每个正常的数据段都需要应答来保证可靠性。但最新的一条消息是没有的
明确了上面的理论知识,可以帮助接下来我们谈tcp报头里序号和确认序号
四. 理解TCP的报头
16位校验和+选项我们不考虑,接下来学习tcp报头剩余字段以及背后的知识。
1. 4位首位长度
序号和确认序号等会谈,先谈4位首位长度
上面其实已经提到了,概述如下:
4位TCP报头长度:表示该TCP头部有多少个32位bit(有多少个4字节),所以TCP头部最大长度是15 * 4 = 60
2. 序号和确认序号:TCP 全双工通信与确认应答机制
今天,客户端 (c) 可能向服务器 (s) 发送信息,也可能是服务器向客户端发送信息。由于双方都使用 TCP 协议,所以 TCP 的双方地位是对等的。要了解 TCP,只需要搞清楚一个方向的通信过程,反过来,另一个方向的通信也是一样的。
2.1. TCP 真实工作模式
Client 可能一次给 Server 发送多个请求报文,而 Server 也可以一次给 Client 发送多个确认应答。
2.2. 问题分析
数据的顺序问题:
如果客户端一次给服务器发送多个请求,数据到达对方的顺序是否和发送顺序一样?
答案是不一定!数据在网络传输中可能乱序到达。确认与请求的对应关系:
当 Server 连续收到多个请求后,要对请求进行确认。那么,Client 如何知道这些确认是对应哪个请求的呢?
假设客户端发了4个请求,服务器只回了3个确认,那客户端必须知道自己发了4个请求,且只收到了3个确认,这样才能判断哪个报文丢失了。
2.3. TCP 报文序号机制
为了保证每个请求和应答可以对应上,TCP 请求报文(数据段)需要有方式标识数据段本身,因此每个数据段都有自己的 32位序号。
每一个请求和确认应答都是一个 TCP 报文,有数据的包含有效载荷,没数据的只包含 TCP 报头。每个 TCP 报文都会填充一个序号,确保报文有序。
2.4. 确认应答的机制
Server 给 Client 的应答报文中,需要和请求报文一一对应。因此,应答报文的报头中会包含确认序号,这样 Client 可以知道应答是对哪个请求的。
序号与确认序号的对应规则:
假设 Client 发送了序号为 1000 的报文,Server 的确认序号将是 1001。如果 Client 发送了序号为 2000 的报文,Server 的确认序号则为 2001。也就是说,你发过来的报文序号是多少,确认序号就是发过来的序号 + 1。
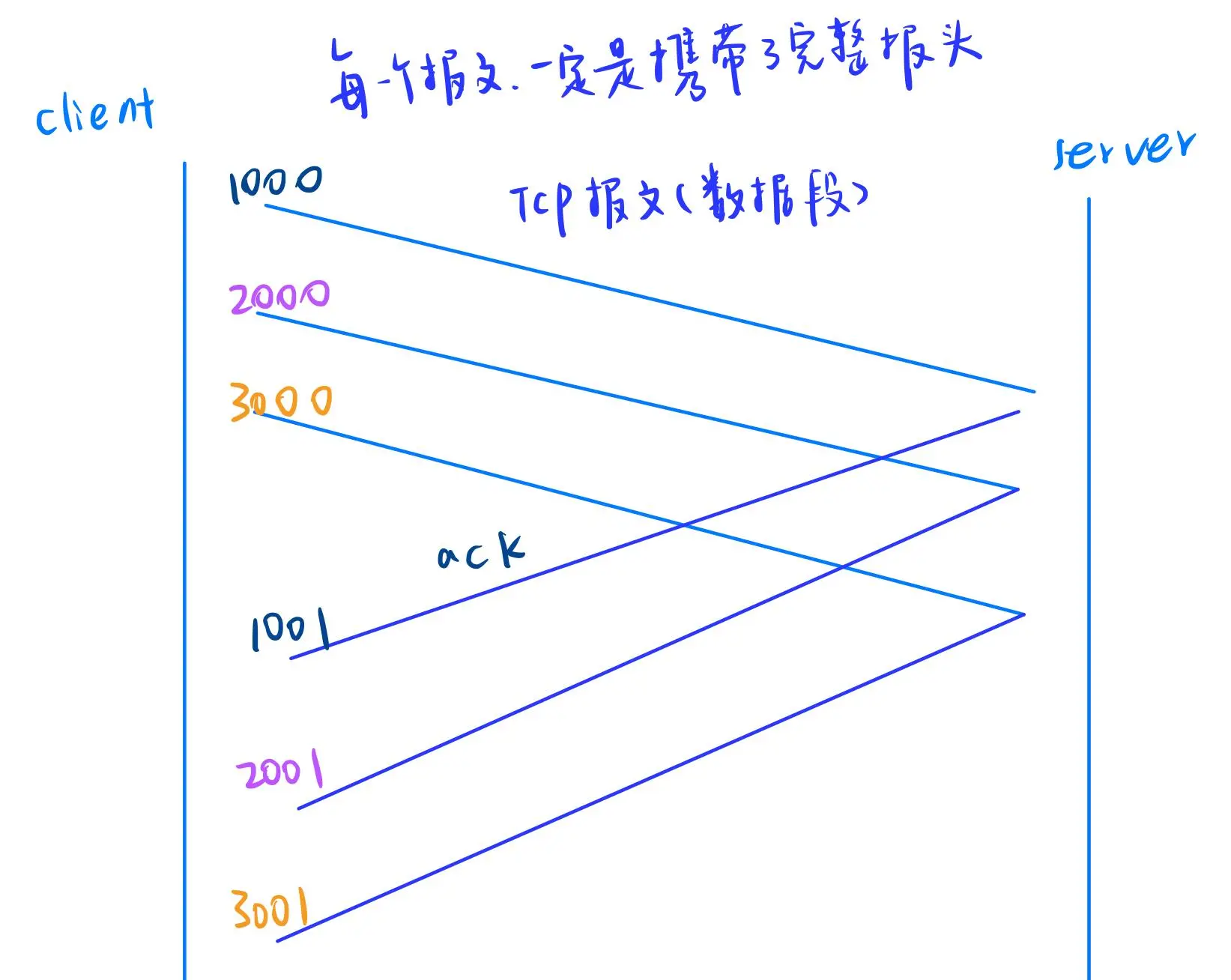
确认序号的含义:
确认序号表示接收方已经收到了该序号之前的所有报文(连续且无遗漏),并告知对方下次发送从该确认序号开始。
2.5. 丢包场景下的应答机制
如果某个报文丢失了,比如:
Client 发送了序号为 2000 的报文丢失了,Server 只收到了序号为 1000 和 3000 的报文。Server 对序号为 1000 的报文返回确认序号 1001,但由于 2000 丢失了,即使收到了 3000 号报文,确认序号依然是 1001,因为 2000 之前的报文不是连续的。为什么这样设计?
这是为了支持 TCP 的滑动窗口机制,使得确认序号可以线性右移,从而保持可靠的数据传输。
2.6. 两组序号的必要性
❓ TCP 报文为什么要有两组序号?

请求和应答的序号不能共享吗?
不能。因为 TCP 是全双工通信,双方可以同时发送和接收数据。
当 Client 给 Server 发信息时,Client 使用自己的序号,Server 给出确认序号。同时,Server 也可能给 Client 发送信息,这时 Server 需要自己的序号,Client 也需要给出对应的确认序号。
因此,TCP 报头必须有两组独立的序号:一组用于发送方的数据序号,另一组用于接收方的确认序号。
捎带应答:
当发送应答时,可能同时捎带发送给对方的数据,因此需要同时包含序号和确认序号。这是 TCP 通信中的常见模式。
2.7. 数据到达顺序与序号
如果客户端一次给服务器发送多个请求,数据的到达顺序可能与发送顺序不同。但是,由于报文中携带了序号,可以通过序号对乱序报文进行排序,保证数据的完整性和可靠性。
3. 窗口大小:TCP缓冲区与流量控制
缓冲区的作用
发送缓冲区:用于暂时保存应用层通过IO接口拷贝过来的数据,等待通过网络发送。接收缓冲区:用于暂时保存从网络接收到的数据,直到被应用层读取。
数据传输过程
客户端(Client)将数据从应用层拷贝到其发送缓冲区。数据通过网络传输到服务器(Server)的接收缓冲区。服务器同样将响应数据从其应用层拷贝到发送缓冲区,并通过网络发送回客户端的接收缓冲区。
流量控制的必要性
地理位置远近:客户端与服务器可能相隔很远。发送速度不匹配:
如果客户端发送数据过快,而服务器来不及处理,会导致服务器接收缓冲区溢出,后续到达的数据包将被丢弃。反之,如果发送速度过慢,则会影响对方上层业务的正常处理速度。
合适的速度:为了确保数据传输既不过快也不过慢,需要一种机制来调节发送速率。
流量控制机制
反馈机制:发送方需要知道接收方的接收缓冲区剩余空间大小,以调整自己的发送速率。16位窗口大小:TCP头部中的16位窗口大小字段表示的是接收方当前接收缓冲区的剩余空间大小。
发送方根据这个窗口大小调整其发送速率。这个字段填入的是接收方的接收缓冲区剩余空间大小,而不是发送方的。
全双工通信
双向控制:在全双工通信中,双方都需要知道对方的接收缓冲区剩余空间大小。
客户端和服务器都需要保证对方能够以适当的速度接收数据。因此,每个方向上的TCP报文都包含一个16位窗口大小字段,表示自己的接收缓冲区剩余空间大小。
交换接收能力
双向流量控制:这套规则对客户端和服务器同样适用,实现了双方在两个方向上的流量控制。目的:确保双方都能以合适的速度进行数据交换,避免缓冲区溢出或处理速度跟不上。
通过这种方式,TCP协议不仅确保了数据的可靠传输,还有效地管理了网络带宽的使用,提高了整体的通信效率。
下篇文章讲继续讲解 6 个标记位,结合应用层和传输层的角度,解释三次握手四次挥手~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。