【Linux】文件周边003之文件系统
樊梓慕 2024-07-21 14:37:01 阅读 91

👀樊梓慕:个人主页
🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》《C++》《Linux》《算法》
🌝每一个不曾起舞的日子,都是对生命的辜负
目录
1.磁盘引入
2.文件系统
2.1初识inode
2.2inode Table
2.3inode Bitmap
2.4Data Blocks
2.5Block Bitmap
2.6Group Descriptor Table
2.7超级块Super Block
2.8Boot Block
2.9有关文件名
如何知道文件在哪一个分区?
3.软链接与硬链接
3.1软链接
3.2硬链接
前言
系统中大部分的文件是没有被打开的,那么操作系统是如何管理这些没有被打开的文件呢,接下来我们就要开始学习Linux系统对于文件的管理。
欢迎大家📂收藏📂以便未来做题时可以快速找到思路,巧妙的方法可以事半功倍。
=========================================================================
GITEE相关代码:🌟樊飞 (fanfei_c) - Gitee.com🌟
=========================================================================
1.磁盘引入
为了辅助后续linux系统对文件的管理,我们可以从磁盘入手,虽然磁盘现在已经很少出现在个人计算机上了(固态硬盘\机械硬盘),但对磁盘的学习可以帮助我们后续对文件系统的认识。
为什么要学习磁盘呢?
主要是为了研究磁盘的寻址方式,就是如何快速定位到某个位置。
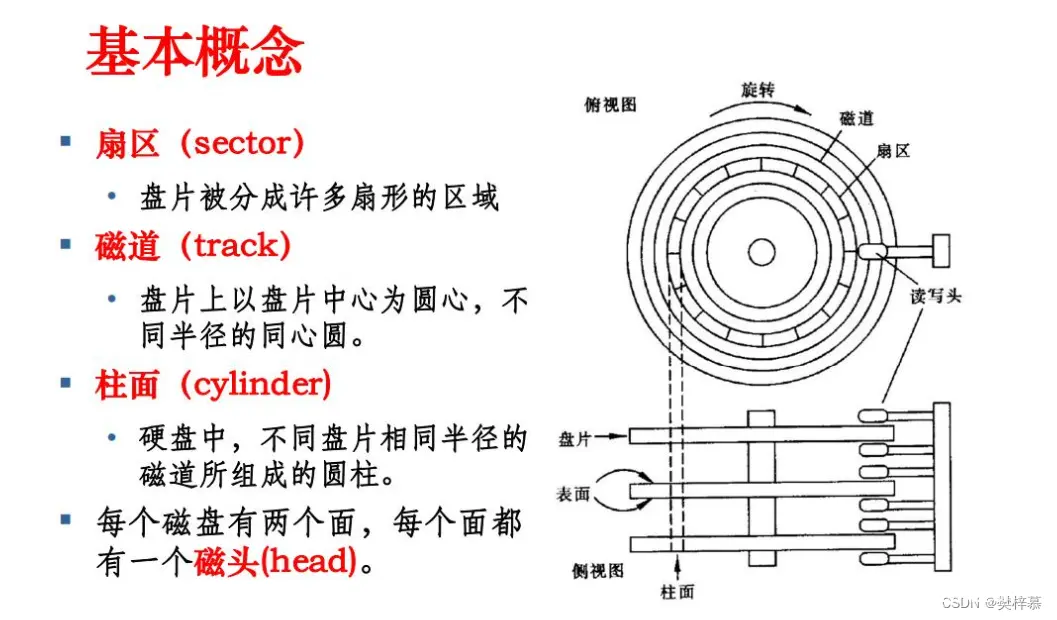
根据上图有关磁盘的基本概念,你可能对磁盘的寻址方式有了初步的猜测。
对磁盘进行读写操作时,一般有以下几个步骤:
确定读写信息在磁盘的哪个柱面。确定读写信息在磁盘的哪个盘面。确定读写信息在磁盘的哪个扇区。
所以通过以上三个步骤我们就可以快速定位到一个扇区,从而找到读写位置。
注意:扇区大小一般为512字节。
该寻址方式被称为『 CHS定位法 』。
C:cylinder 柱面H:head 磁头(通过不同的磁头确定不同的盘面)S:sector 扇区
2.文件系统
试想:如果我们把盘面拉直,是不是就得到了一个由n个扇区组成的“数组” ,这里可以联想到磁带。
那么该数组的基本单元是多大呢?
我们前面说一个扇区的大小为512字节,但是操作系统认为512字节太小了,访问效率太慢了,所以操作系统将连续的8个扇区作为一个基本数据块,即4KB, 所以这4KB就是IO的基本单位,也就是说只要需要修改数据,哪怕再小,操作系统也要将这4KB拿出来做修改再放回去,这就是所谓的基本单位。
注意:不同操作系统可能不同,这个是自己定义的,但大部分操作系统都是4KB。
所以每8个扇区组成一个新的基本单元(数据块),从而得到的一个新的数组。
通过数组的下标(该下标被称为『 LBA(logic block address)逻辑块地址』),我们只要知道『 每个磁道上的扇区数』和『 每个盘面上的扇区总数』,就可以通过计算得到对应的扇区位置。
这一转化过程是磁盘自动转化的,所以通过这样的方式,我们成功将『 对磁盘的管理』转化为了『 对数组的增删查改』。
假设我们总共有400GB的磁盘空间,那么我们可以将这400GB进行分区管理,假设每个区域有100GB,同样的对于每个区域来说,我们可以将这100GB再划分得到每10GB的数据块,这样只要管理好这10GB,就能管理好全部,即只要管理好局部,就能管理好全局,那么接下来我们来研究一下如何管理这10GB,下图为Linux ext2文件系统的方案:
2.1初识inode
文件=文件内容+文件属性。
文件内容就是文件当中存储的数据,文件属性就是文件的一些基本信息,例如文件大小、文件创建时间等信息都是文件属性,文件属性又被称为元信息。
注:文件名不属于文件属性。
那么一般来说文件内容大小是不确定的,而文件属性大小是固定大小,因为文件属性的类别都是一样的,只不过不同文件中对应类别存储内容不同,比如创建时间不同等。
注:在Linux操作系统中,文件的元信息和内容是分离存储的。
所以设计出了一个结构体用来描述文件属性,该结构体即为inode,大小一般为128字节,每个文件都有自己的inode和对应的inode编号,该inode编号在『 所处分区』内唯一。
所以系统中标识一个文件,用的不是文件名,而是inode编号。
注:无论是文件内容还是文件属性,它们都是存储在磁盘当中的。
所以我们可以猜想inode的结构可能如下:
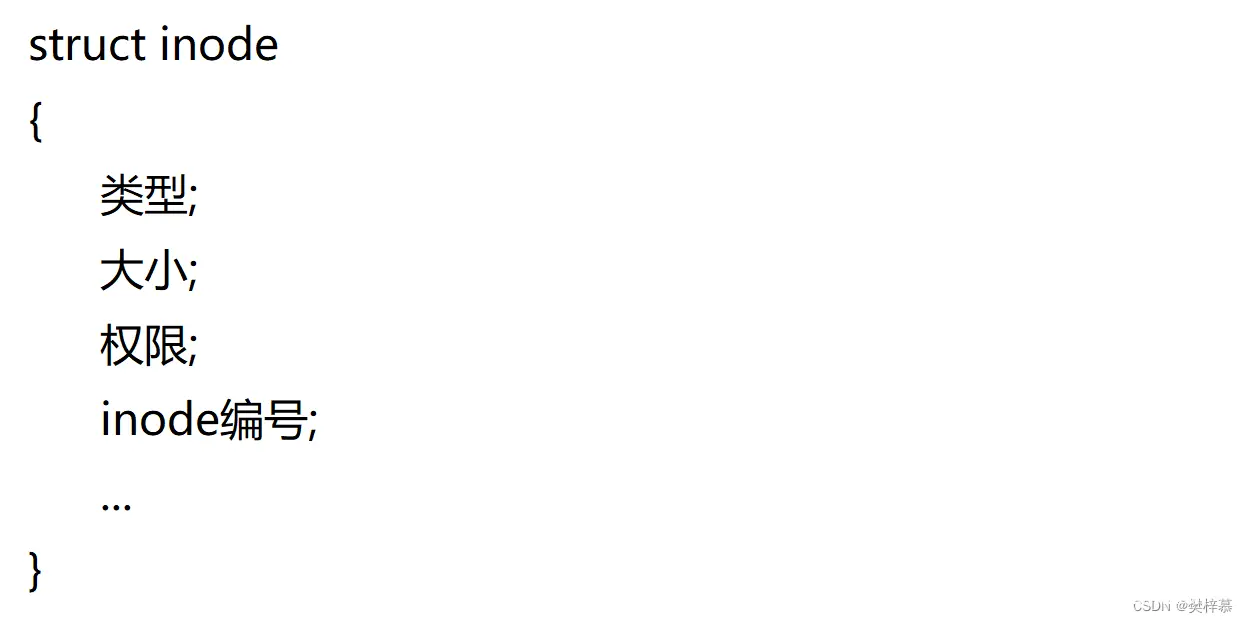
然后我们再来研究一下数据块组内其他成员:
2.2inode Table
inode Table中存储的是该块组内所有文件的inode结构体,组织方式类似数组。
2.3inode Bitmap
还记得位图么,没错,这里同样是位图的寻址方式,每个bit标识一个inode是否空闲可用。
比特位的位置:inode Table中第几个inode。比特位的内容:标识该inode是否被使用。
2.4Data Blocks
数据区,存储的是文件内容,内部由n个数据块构成,我们前面说每个数据块大小为4KB,由8个扇区构成。
2.5Block Bitmap
同样是位图,不过该位图记录着Data Blocks中哪个数据块已经占用,哪个数据块没有被占用。
比特位的位置:Data Blocks中第几个数据块。比特位的内容:标识该数据块是否被使用。
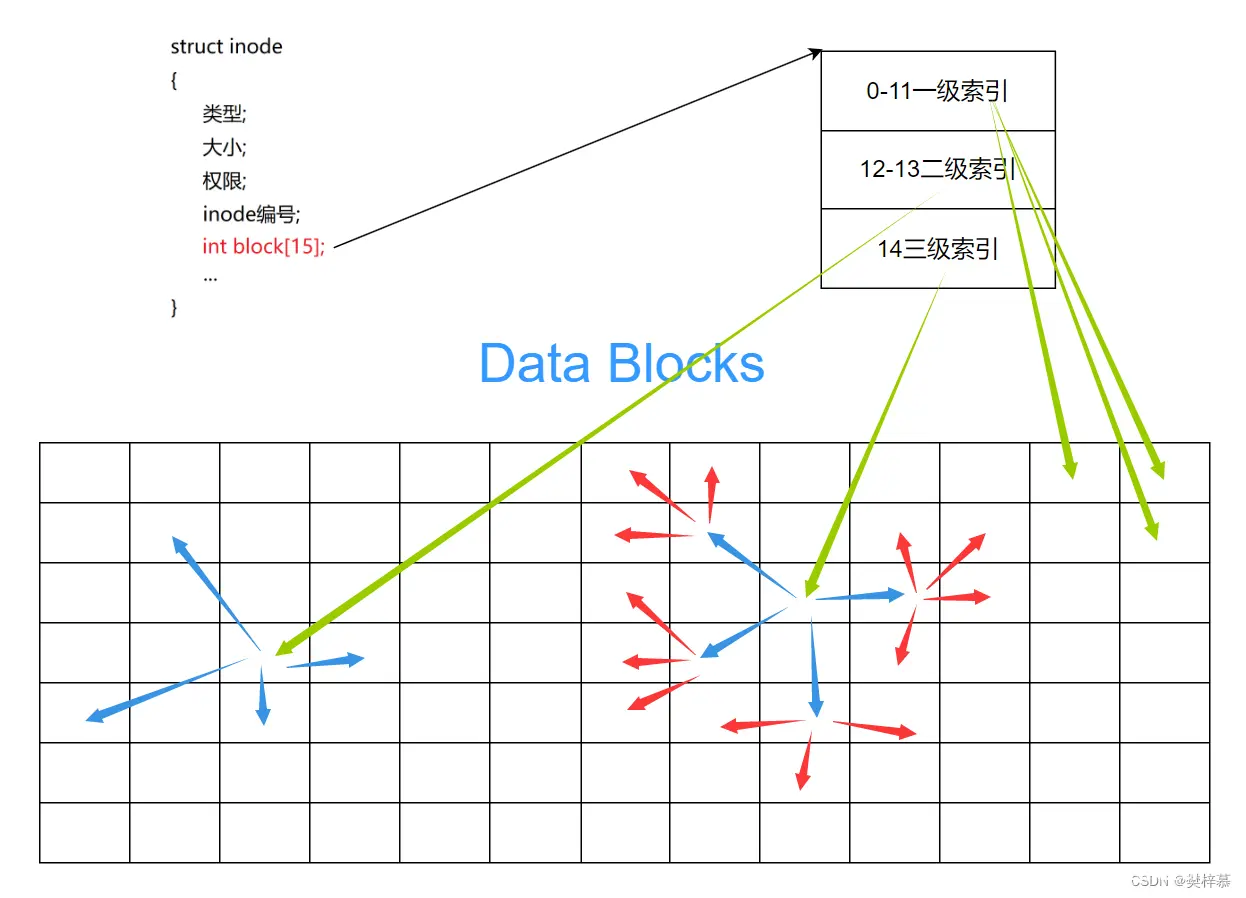
另外,由于每个数据块大小仅为4KB,而文件大小可能会高于4KB,即一个文件可能会占用多个数据块,所以inode结构体中还会有这样的一个设计:

该block数组是为了映射更多的数据块,那么此时你可能还会有疑问:那该数组大小为15,15*4KB=60KB,那更大的文件呢?
其实这里block数组中:
0-11下标对应内容才为直接映射;12-13下标对应的数据块并不直接保存数据,而保存指向其他数据块的编号(二级索引);14下标对应的数据块保存指向其他数据块的编号,而这些其他数据块也不直接保存数据,他们保存指向另外更多其他数据块的编号(三级索引);
所以存储文件的量级还是非常可观的。
如何根据inode编号在不同块组中快速定位到inode呢?
其实每个分组都有对应的『 起始inode编号』,我们可以首先根据每个分组的起始编号,判别在哪个组,然后减去该分组的起始编号,就能得到一个偏移量,该偏移量就是inode位图位置和inode表的下标索引。
你有没有发现计算机删除文件的速度一般很快?
其实这就是因为位图的设计方式,删除文件只需要将两个位图中对应的映射关系修改即可,其实就是相当于删除了映射,而存储在Data Blocks中的属性和数据都没有改动,所以删除文件的速度往往很快。
2.6Group Descriptor Table
描述整个块组的属性信息,诸如该块组有多少个inode,多少个数据块等等。
2.7超级块Super Block
存放文件系统本身的结构信息。记录的信息主要有:block 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。
Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。
一般一个分区内会有少数几个块组内存在,存储相同的内容,主要目的是备份,防止文件系统结构被破坏。
操作系统对文件系统的管理:不同分区的Super Block构建成对象用链表的结构链接起来。
2.8Boot Block
一般仅在0号盘面的0号扇区存在,也就是最开始的位置,它主要作用是为了辅助开机,加载操作系统等,这里感兴趣的大家可以自行学习。
2.9有关文件名
在linux操作系统中,我们之前对文件的操作从未利用过inode寻找文件位置,而是利用文件名,那文件名与inode编号又有什么样的联系呢?
这里就要从目录说起了。
目录(文件夹)也是文件,只要是文件就有自己的inode和文件内容,那目录文件的文件内容存储的是什么呢?
其实目录文件的文件内容为目录内文件名与对应文件inode编号的映射关系。
所以这里我们就可以重新认识一下对文件的增删查改操作了。
为什么之前我们说当前用户如果没有目录的写权限,那么就无法对目录内的文件进行操作呢?
其实原因就在这里,因为你不能写入目录文件的内容(即映射关系)。
读权限等也是一样的道理。
目录文件与inode编号的映射关系存储在上级目录。
所以查找一个文件,在内核中,都要逆向地递归般得到映射关系,直到根目录,然后从根目录开始进行路径解析(根目录的inode是确定的)。
这样就一定会存在一种数据结构用来缓存对应路径的映射关系,这种数据结构被称为dentry(路径缓存、dentry缓存)。
<code>struct dentry {
atomic_t d_count;
unsigned long d_vfs_flags;/* moved here to be on same cacheline */
spinlock_t d_lock;/* per dentry lock */
struct inode * d_inode;/* Where the name belongs to - NULL is negative */
struct list_head d_lru;/* LRU list */
struct list_head d_child;/* child of parent list */
struct list_head d_subdirs;/* our children */
struct list_head d_alias;/* inode alias list */
unsigned long d_time;/* used by d_revalidate */
struct dentry_operations *d_op;
struct super_block * d_sb;/* The root of the dentry tree */
unsigned int d_flags;
int d_mounted;
void * d_fsdata;/* fs-specific data */
struct rcu_head d_rcu;
struct dcookie_struct * d_cookie; /* cookie, if any */
unsigned long d_move_count;/* to indicated moved dentry while lockless lookup */
struct qstr * d_qstr;/* quick str ptr used in lockless lookup and concurrent d_move */
struct dentry * d_parent;/* parent directory */
struct qstr d_name;
struct hlist_node d_hash;/* lookup hash list */
struct hlist_head * d_bucket;/* lookup hash bucket */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
}
这里dentry具体的结构我们不作研究,只需要知道每个『 打开的文件』的dentry里面存储了inode属性和路径属性,当然不止目录文件这样存储,普通文件也是一样的。
如何知道文件在哪一个分区?
这个问题很关键,因为inode是在分区内唯一的,不同分区可能会存在相同inode。
其实,一个文件系统所对应的分区,都挂载在指定的目录中。
也就是说我们可以通过路径分析出文件在哪一个分区,路径的本质其实就是字符串,我们可以通过字符串前缀分析得到路径,然后根据该路径识别当前文件所处的分区即可。
一个被写入文件系统的分区,要被linux使用,必须先把这个具有文件系统的分区进行挂载。
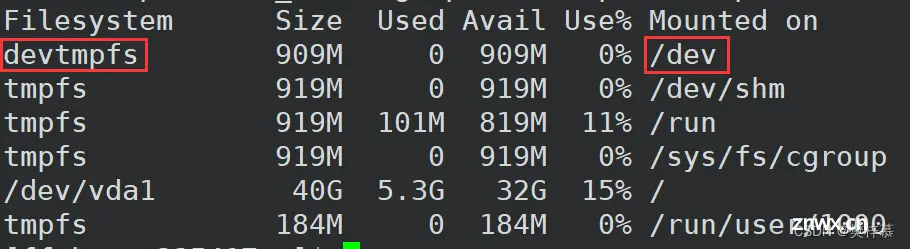
可以通过『 df -h』命令查看文件系统和路径之间的联系:
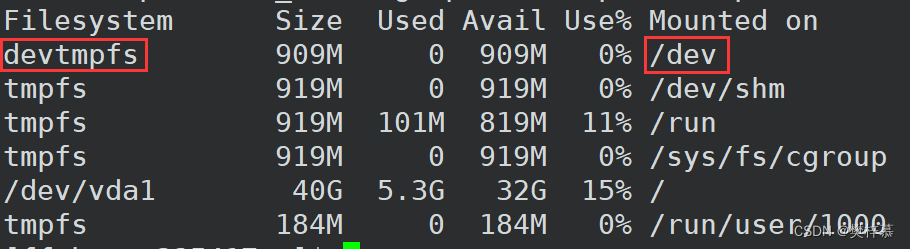
挂载在内核中就是将两种数据结构产生某种联系,分别是文件系统的数据结构和路径缓存dentry的数据结构。
3.软链接与硬链接
3.1软链接
我们可以通过『 ln -s 文件名 软链接名』命令创建软链接。
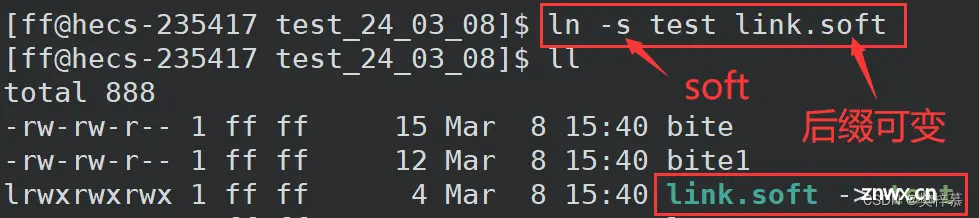
软链接的本质是文件,拥有独立的inode。
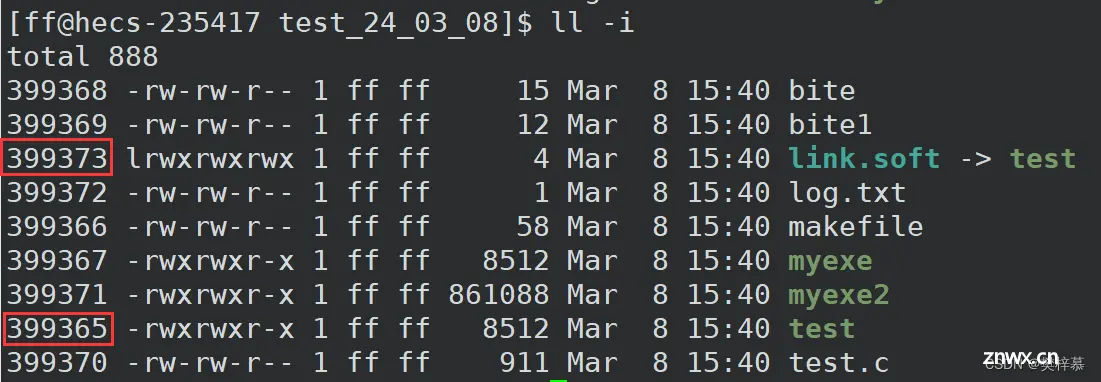
软链接文件内容存放的是文件所在的路径信息,相当于windows系统的『 快捷方式』。
3.2硬链接
我们可以通过『 ln 文件名 软链接名』命令创建硬链接。
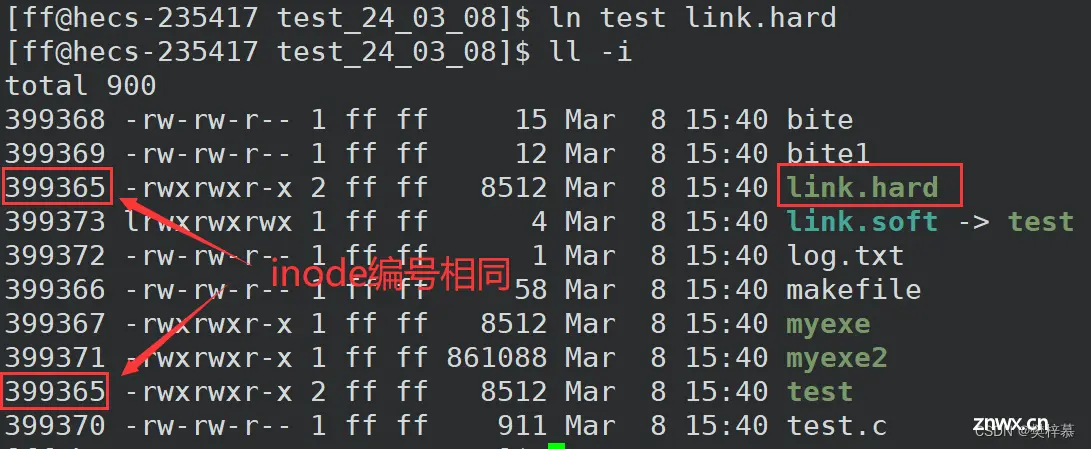
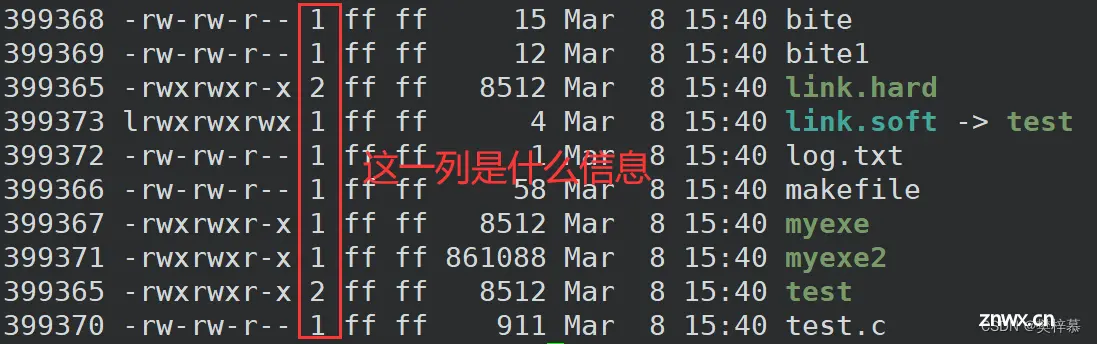
通过上图我们发现硬链接与被链接文件的inode编号相同,也就是说硬链接本身并不是文件。
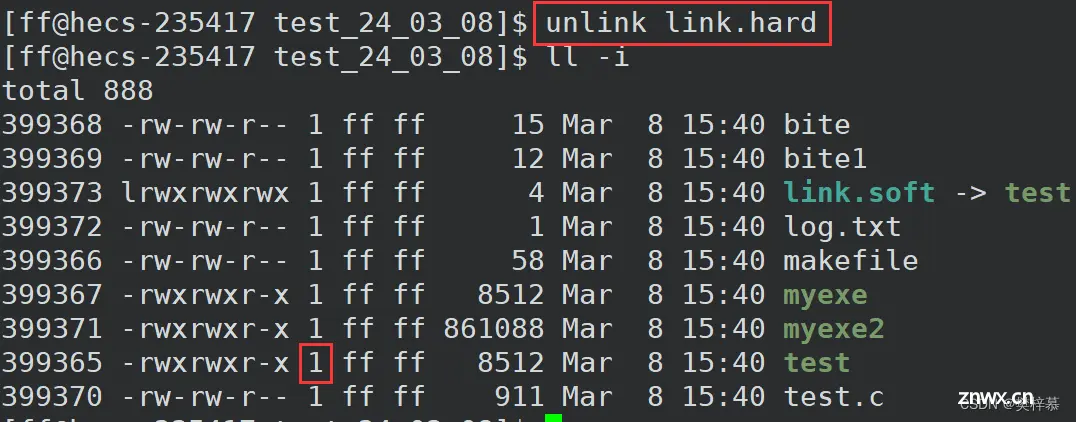
我们之前从未提到过如上图所示的数字代表什么意思。
其实这就与硬链接有关。
它反映的是硬链接数,或者说是inode的引用计数,即当前文件的inode被多少文件所映射。
当建立硬链接后,我们发现test文件的硬链接数++变为2了。
当我们删除掉硬链接link.hard,利用unlink命令或rm命令都可以。

发现硬链接数--变为1。
普通文件硬链接数初始为1:因为文件的目录中就存储这一份文件名和inode的映射关系。
目录文件硬链接数初始为2,为什么呢?
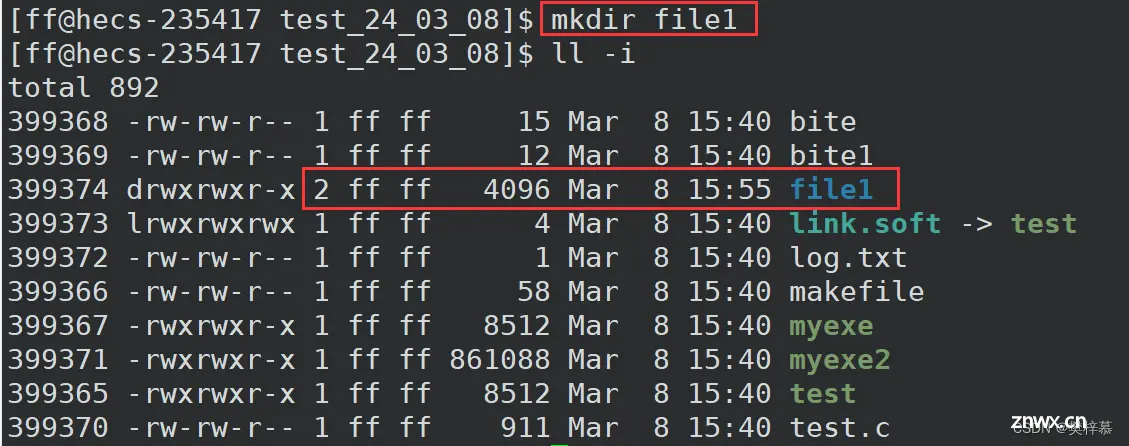
还记得 『 . 和 .. 』么?
没错 『 . 』和『 .. 』就是硬链接的实际应用。

注意
可以给目录文件建立软连接;
不能给目录文件建立硬链接:目的是为了防止无穷递归,形成路径环路。
那为什么『 . 』和『 .. 』建立了与目录文件的硬链接呢?
因为系统自己可以给目录建立硬链接,而用户不能。
主要是linux系统自己设计的可以做特殊区分,防止形成路径环路。
=========================================================================
如果你对该系列文章有兴趣的话,欢迎持续关注博主动态,博主会持续输出优质内容
🍎博主很需要大家的支持,你的支持是我创作的不竭动力🍎
🌟~ 点赞收藏+关注 ~🌟
=========================================================================
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。