Docker容器嵌入式开发:Ubuntu上配置Spark环境的基本步骤
源代码杀手 2024-06-27 13:37:02 阅读 78
目录
一、环境配置二、问题解决start-all.shtart-all.sh
三、集群操作
一、环境配置
以下是在Ubuntu上配置Spark环境的基本步骤:
下载Spark:
从提供的链接中下载Spark压缩包。您可以使用wget命令从命令行下载:
wget https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz
解压Spark:
使用以下命令解压下载的压缩包:
tar -xvf spark-3.5.1-bin-hadoop3.tgz
移动Spark文件夹:
将解压后的Spark文件夹移动到您想要安装的位置,例如/opt目录:
sudo mv spark-3.5.1-bin-hadoop3 /opt/spark-3.5.1
配置环境变量:
打开.bashrc文件以编辑环境变量配置:
vim ~/.bashrc
在文件末尾添加以下行以设置Spark的环境变量:
=
export SPARK_HOME=/opt/spark-3.5.1
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
保存并关闭文件。然后运行以下命令使更改生效:
source ~/.bashrc
配置Spark默认日志级别(可选操作):
您可以选择配置Spark的默认日志级别。编辑$SPARK_HOME/conf/log4j.properties文件,并将以下行的日志级别更改为您想要的级别:
log4j.rootCategory=INFO, console
例如,将其更改为ERROR可仅显示错误日志。
启动Spark集群:
使用以下命令启动Spark集群:
start-all.sh
这将启动Spark的Master和Worker节点。
验证Spark安装:
打开一个新的终端窗口,并运行以下命令以验证Spark是否正确安装:
spark-shell
如果一切顺利,将会打印出Spark的启动信息,并进入Spark的交互式Shell。您可以在Shell中运行简单的Spark命令以测试Spark的功能。
操作记录:
spark-3.5.1-bin-hadoop3/R/lib/SparkR/Meta/features.rds
spark-3.5.1-bin-hadoop3/R/lib/SparkR/doc/
spark-3.5.1-bin-hadoop3/R/lib/SparkR/doc/index.html
spark-3.5.1-bin-hadoop3/R/lib/SparkR/doc/sparkr-vignettes.html
spark-3.5.1-bin-hadoop3/R/lib/SparkR/doc/sparkr-vignettes.Rmd
spark-3.5.1-bin-hadoop3/R/lib/SparkR/doc/sparkr-vignettes.R
spark-3.5.1-bin-hadoop3/R/lib/SparkR/help/
spark-3.5.1-bin-hadoop3/R/lib/SparkR/help/SparkR.rdx
spark-3.5.1-bin-hadoop3/R/lib/SparkR/help/paths.rds
spark-3.5.1-bin-hadoop3/R/lib/SparkR/help/SparkR.rdb
spark-3.5.1-bin-hadoop3/R/lib/SparkR/help/AnIndex
spark-3.5.1-bin-hadoop3/R/lib/SparkR/help/aliases.rds
spark-3.5.1-bin-hadoop3/R/lib/SparkR/NAMESPACE
spark-3.5.1-bin-hadoop3/R/lib/SparkR/tests/
spark-3.5.1-bin-hadoop3/R/lib/SparkR/tests/testthat/
spark-3.5.1-bin-hadoop3/R/lib/SparkR/tests/testthat/test_basic.R
spark-3.5.1-bin-hadoop3/R/lib/SparkR/INDEX
spark-3.5.1-bin-hadoop3/R/lib/SparkR/DESCRIPTION
spark-3.5.1-bin-hadoop3/R/lib/SparkR/profile/
spark-3.5.1-bin-hadoop3/R/lib/SparkR/profile/general.R
spark-3.5.1-bin-hadoop3/R/lib/SparkR/profile/shell.R
spark-3.5.1-bin-hadoop3/R/lib/SparkR/worker/
spark-3.5.1-bin-hadoop3/R/lib/SparkR/worker/daemon.R
spark-3.5.1-bin-hadoop3/R/lib/SparkR/worker/worker.R
spark-3.5.1-bin-hadoop3/R/lib/SparkR/html/
spark-3.5.1-bin-hadoop3/R/lib/SparkR/html/00Index.html
spark-3.5.1-bin-hadoop3/R/lib/SparkR/html/R.css
spark-3.5.1-bin-hadoop3/R/lib/SparkR/R/
spark-3.5.1-bin-hadoop3/R/lib/SparkR/R/SparkR.rdx
spark-3.5.1-bin-hadoop3/R/lib/SparkR/R/SparkR.rdb
spark-3.5.1-bin-hadoop3/R/lib/SparkR/R/SparkR
spark-3.5.1-bin-hadoop3/R/lib/sparkr.zip
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# sudo mv spark-3.5.1-bin-hadoop3 /opt/spark-3.5.1
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# geidt ~/.bashrc
bash: geidt: command not found
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# gedit ~/.bashrc
(gedit:47848): dbind-WARNING **: 12:36:11.367: Couldn't connect to accessibility bus: Failed to connect to socket /run/user/1000/at-spi/bus_1: No such file or directory
(gedit:47848): GLib-GIO-CRITICAL **: 12:36:12.611: g_dbus_proxy_new_sync: assertion 'G_IS_DBUS_CONNECTION (connection)' failed
(gedit:47848): dconf-WARNING **: 12:36:13.481: failed to commit changes to dconf: Failed to execute child process “dbus-launch” (No such file or directory)
(gedit:47848): dconf-WARNING **: 12:36:13.513: failed to commit changes to dconf:
** (gedit:47848): WARNING **: 12:36:32.706: Set document metadata failed: Setting attribute metadata::gedit-spell-language not supported
** (gedit:47848): WARNING **: 12:36:32.706: Set document metadata failed: Setting attribute metadata::gedit-encoding not supported
** (gedit:47848): WARNING **: 12:36:33.149: Set document metadata failed: Setting attribute metadata::gedit-spell-language not supported
** (gedit:47848): WARNING **: 12:36:33.149: Set document metadata failed: Setting attribute metadata::gedit-encoding not supported
** (gedit:47848): WARNING **: 12:36:33.159: Could not load theme icon text-x-generic: Icon 'text-x-generic' not present in theme Yaru-magenta
** (gedit:47848): WARNING **: 12:36:33.209: Set document metadata failed: Setting attribute metadata::gedit-spell-language not supported
** (gedit:47848): WARNING **: 12:36:33.209: Set document metadata failed: Setting attribute metadata::gedit-encoding not supported
^C
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# ^C
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# source ~/.bashrc
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark-3.5.1/logs/spark--org.apache.spark.deploy.master.Master-1-98031e181845.out
localhost: ssh: connect to host localhost port 22: Connection refused
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# sudo service ssh status
* sshd is not running
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# sudo service ssh start
* Starting OpenBSD Secure Shell server sshd [ OK ]
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# start-all.sh
org.apache.spark.deploy.master.Master running as process 48691. Stop it first.
localhost: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
localhost: @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
localhost: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
localhost: IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
localhost: Someone could be eavesdropping on you right now (man-in-the-middle attack)!
localhost: It is also possible that a host key has just been changed.
localhost: The fingerprint for the ED25519 key sent by the remote host is
localhost: SHA256:rqXRWozShnlcYdzcZVX/VKCYTRWRbpW66Bb/7bTci0U.
localhost: Please contact your system administrator.
localhost: Add correct host key in /root/.ssh/known_hosts to get rid of this message.
localhost: Offending ED25519 key in /root/.ssh/known_hosts:1
localhost: remove with:
localhost: ssh-keygen -f "/root/.ssh/known_hosts" -R "localhost"
localhost: Password authentication is disabled to avoid man-in-the-middle attacks.
localhost: Keyboard-interactive authentication is disabled to avoid man-in-the-middle attacks.
localhost: root@localhost: Permission denied (publickey,password).
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# ssh-keygen -f "/root/.ssh/known_hosts" -R "localhost"
# Host localhost found: line 1
/root/.ssh/known_hosts updated.
Original contents retained as /root/.ssh/known_hosts.old
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# ssh-keygen -f "/root/.ssh/known_hosts" -R "localhost"
Host localhost not found in /root/.ssh/known_hosts
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# ssh-keygen -f "/root/.ssh/known_hosts" -R "localhost"
Host localhost not found in /root/.ssh/known_hosts
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# start-all.sh
org.apache.spark.deploy.master.Master running as process 48691. Stop it first.
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
root@localhost's password:
localhost: Permission denied, please try again.
root@localhost's password:
localhost: Permission denied, please try again.
root@localhost's password:
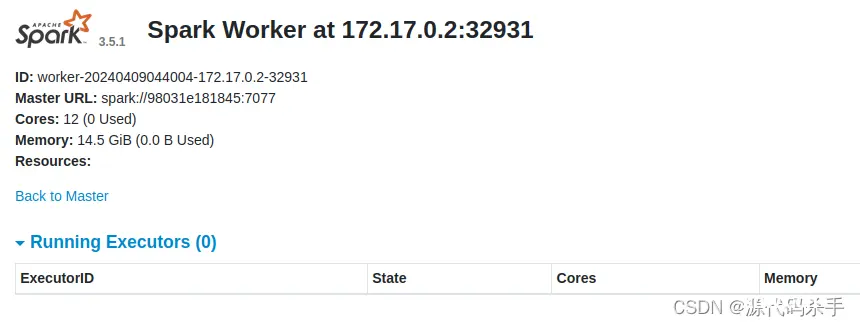
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-3.5.1/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-98031e181845.out
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
24/04/09 04:40:54 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://98031e181845:4040
Spark context available as 'sc' (master = local[*], app id = local-1712637656564).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.1
/_/
Using Scala version 2.12.18 (OpenJDK 64-Bit Server VM, Java 11.0.19)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
二、问题解决
start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark-3.5.1/logs/spark--org.apache.spark.deploy.master.Master-1-98031e181845.out
localhost: ssh: connect to host localhost port 22: Connection refused
您遇到的错误表明在启动Spark时出现了SSH连接被拒绝的问题。这通常是由于SSH服务未启动或者防火墙设置导致的。以下是一些可能的解决方法:
确保SSH服务正在运行:
使用以下命令检查SSH服务的状态:
sudo service ssh status
如果SSH服务未运行,请使用以下命令启动它:
sudo service ssh start
检查防火墙设置:
如果您的系统上启用了防火墙,可能会阻止SSH连接。您可以尝试临时关闭防火墙并重新启动Spark,然后查看是否仍然出现连接问题。但请记住,在生产环境中,安全性是至关重要的,关闭防火墙可能会带来安全风险。
检查SSH端口:
默认情况下,SSH服务使用22端口。确保您的系统上的SSH服务正在监听端口22,并且未被其他进程占用。
检查主机名:
确保您的主机名配置正确,以便SSH能够正确地连接到localhost。
检查Spark配置:
检查Spark的配置文件,确保其中的master节点配置正确。您可以在$SPARK_HOME/conf/spark-defaults.conf中指定master节点的地址。
尝试以上解决方法中的一种或多种,并重新启动Spark,以查看是否解决了连接问题。
tart-all.sh
org.apache.spark.deploy.master.Master running as process 48691. Stop it first.
localhost: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
localhost: @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
localhost: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
localhost: IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
localhost: Someone could be eavesdropping on you right now (man-in-the-middle attack)!
localhost: It is also possible that a host key has just been changed.
localhost: The fingerprint for the ED25519 key sent by the remote host is
localhost: SHA256:rqXRWozShnlcYdzcZVX/VKCYTRWRbpW66Bb/7bTci0U.
localhost: Please contact your system administrator.
localhost: Add correct host key in /root/.ssh/known_hosts to get rid of this message.
localhost: Offending ED25519 key in /root/.ssh/known_hosts:1
localhost: remove with:
localhost: ssh-keygen -f "/root/.ssh/known_hosts" -R "localhost"
localhost: Password authentication is disabled to avoid man-in-the-middle attacks.
localhost: Keyboard-interactive authentication is disabled to avoid man-in-the-middle attacks.
localhost: root@localhost: Permission denied (publickey,password).
您遇到的错误提示表明SSH连接出现了一些问题,可能是由于SSH密钥变化或配置问题导致的。以下是可能的解决方法:
已更改的远程主机标识:
错误消息中提到远程主机标识已更改。这可能是由于您重新安装了系统或者进行了某种更改而导致SSH密钥不匹配。您可以尝试按照错误消息中提供的方法解决此问题:
ssh-keygen -f "/root/.ssh/known_hosts" -R "localhost"
密码验证被禁用:
错误消息中还提到密码验证被禁用。这可能是因为您的SSH配置不允许使用密码进行身份验证。您可以尝试通过修改SSH配置文件来启用密码验证。
检查SSH密钥:
确保您的SSH密钥配置正确,并且可以与localhost进行正常的密钥交换。
检查主机名:
确保您的主机名配置正确,并且localhost可以正确地映射到您的主机。
检查权限:
您可能没有足够的权限来启动Spark服务。请确保您有足够的权限运行start-all.sh脚本。
尝试以上方法中的一种或多种,并确保您的SSH连接和配置是正确的,以解决连接问题。
ssh-keygen -f "/root/.ssh/known_hosts" -R "localhost"
# Host localhost found: line 1
/root/.ssh/known_hosts updated.
Original contents retained as /root/.ssh/known_hosts.old
执行 ssh-keygen -f “/root/.ssh/known_hosts” -R “localhost” 命令后,已成功删除了 known_hosts 文件中关于 localhost 主机的条目。这样,下次再次连接到 localhost 主机时,SSH 将重新生成相应的密钥信息,并且不再出现之前的警告信息
要解决上述问题,您可以按照以下步骤操作:
清除已更改的远程主机标识:
运行以下命令以清除已更改的远程主机标识:
ssh-keygen -f "/root/.ssh/known_hosts" -R "localhost"
这将删除 known_hosts 文件中关于 localhost 主机的条目,并重置与 localhost 主机的连接。
启用密码验证:
如果密码验证被禁用,您可以通过编辑SSH服务器的配置文件来启用密码验证。打开SSH服务器的配置文件(通常位于 /etc/ssh/sshd_config),找到并将 PasswordAuthentication 选项设置为 yes,然后重新启动SSH服务。
检查SSH密钥:
确保您的SSH密钥配置正确,并且您的计算机的公钥已添加到 authorized_keys 文件中,以便可以成功进行密钥交换。
检查主机名:
确保您的主机名配置正确,并且 localhost 可以正确地映射到您的主机。您可以使用 hostname 命令检查主机名,并确保它与您预期的主机名一致。
检查权限:
确保您有足够的权限来启动Spark服务。尝试使用具有更高权限的用户(如root用户)运行 start-all.sh 脚本。
操作记录:
ssh-keygen -f "/root/.ssh/known_hosts" -R "localhost"
Host localhost not found in /root/.ssh/known_hosts
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# start-all.sh
org.apache.spark.deploy.master.Master running as process 48691. Stop it first.
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
root@localhost's password:
localhost: Permission denied, please try again.
root@localhost's password:
localhost: Permission denied, please try again.
root@localhost's password:
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-3.5.1/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-98031e181845.out
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
24/04/09 04:40:54 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://98031e181845:4040
Spark context available as 'sc' (master = local[*], app id = local-1712637656564).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.1
/_/
Using Scala version 2.12.18 (OpenJDK 64-Bit Server VM, Java 11.0.19)
Type in expressions to have them evaluated.
Type :help for more information.
您已成功删除了 known_hosts 文件中关于 localhost 主机的条目,并且成功连接到 localhost 主机。但是,您遇到了密码验证失败的问题。以下是解决此问题的步骤:
密码验证失败:
您尝试使用SSH连接到 localhost 主机时出现了密码验证失败的问题。这可能是因为您输入的密码不正确或者SSH配置不正确导致的。请确保您输入了正确的密码,并且SSH服务器的配置允许使用密码进行验证。
检查SSH服务器配置:
检查SSH服务器的配置文件(通常位于 /etc/ssh/sshd_config),确保以下配置项设置正确:
PasswordAuthentication yes
PermitRootLogin yes
请注意,为了安全起见,应仅允许必要的用户进行root登录,并且密码验证应仅在必要时启用。
重启SSH服务:
在更改了SSH服务器的配置后,确保重新启动SSH服务以使更改生效:
sudo service ssh restart
检查用户权限:
确保您有足够的权限来进行Spark服务的启动。您可以尝试以具有更高权限的用户(如root用户)身份运行 start-all.sh 脚本。
检查密码:
如果您确认密码是正确的,并且仍然遇到密码验证失败的问题,您可能需要重置您的密码或者检查其他可能导致密码验证失败的因素。
尝试执行上述步骤中的一种或多种,以解决密码验证失败的问题。
三、集群操作
操作记录:
$SPARK_HOME/sbin/start-master.sh
org.apache.spark.deploy.master.Master running as process 60899. Stop it first.
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# hostname -I
172.17.0.2
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# spark://172.17.0.2:7077
bash: spark://172.17.0.2:7077: No such file or directory
(tfv1) root@98031e181845:/data/myapp2024/myBigDataApplicationDevelopment# spark-shell --master spark://172.17.0.2:7077
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
24/04/09 05:03:25 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://98031e181845:4040
Spark context available as 'sc' (master = spark://172.17.0.2:7077, app id = app-20240409050327-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.1
/_/
Using Scala version 2.12.18 (OpenJDK 64-Bit Server VM, Java 11.0.19)
Type in expressions to have them evaluated.
Type :help for more information.
上述操作展示了如何在一个Spark集群中启动主节点(Master)并连接到它,然后在集群中启动一个Spark Shell。以下是这些操作的详细解释和技术原理:
启动Spark主节点(Master):
$SPARK_HOME/sbin/start-master.sh
这个命令用于在当前节点上启动Spark的主节点。主节点负责管理整个Spark集群,包括任务调度、资源分配等。
获取主机IP地址:
hostname -I # 这个命令用于获取当前节点的IP地址。在这个示例中,IP地址为172.17.0.2。
启动Spark Shell并连接到主节点:
spark-shell --master spark://172.17.0.2:7077
这个命令用于启动一个Spark Shell,并将其连接到指定的主节点。Spark Shell是一个交互式的工具,允许用户在Spark集群中编写和执行Spark代码。
查看Spark Web界面:
在启动Spark Shell后,会显示Spark Web界面的URL,例如:
Spark context Web UI available at http://98031e181845:4040
这个界面提供了有关Spark应用程序和集群状态的详细信息,包括正在运行的作业、任务、RDDs等。
Spark上下文和会话:
在启动Spark Shell后,会创建一个Spark上下文(Spark Context,简称sc)和一个Spark会话(Spark Session,简称spark)。Spark上下文是与集群交互的主要入口点,而Spark会话则是与数据交互的入口点,可以用于创建DataFrame、执行SQL查询等。
打开的页面(http://localhost:4040/)内容如下:
Jobs(作业):
这个页面显示了当前正在运行的Spark作业的相关信息,包括作业的ID、状态、任务数量、运行时间等。您可以在这里查看每个作业的执行情况,并查看作业的详细信息和日志。
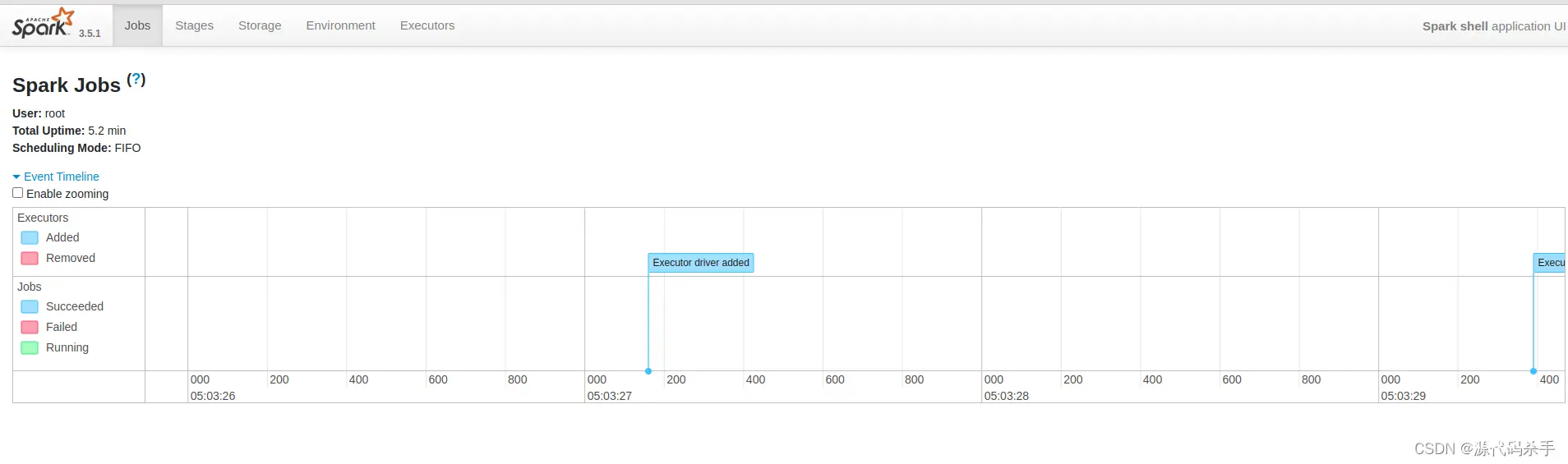
Stages(阶段):
这个页面显示了当前作业中的各个阶段(Stage)的相关信息。每个阶段代表了一组可以并行执行的任务,通常由RDD的转换操作(例如map、reduce等)组成。您可以在这里查看每个阶段的详细信息,包括任务数量、运行时间、数据大小等。
Storage(存储):
这个页面显示了Spark应用程序中缓存的数据的相关信息。在Spark中,您可以使用cache或persist方法将RDD或DataFrame数据缓存到内存中,以便重复使用。在这个页面中,您可以查看缓存的数据的存储级别、占用的内存和磁盘空间等信息。
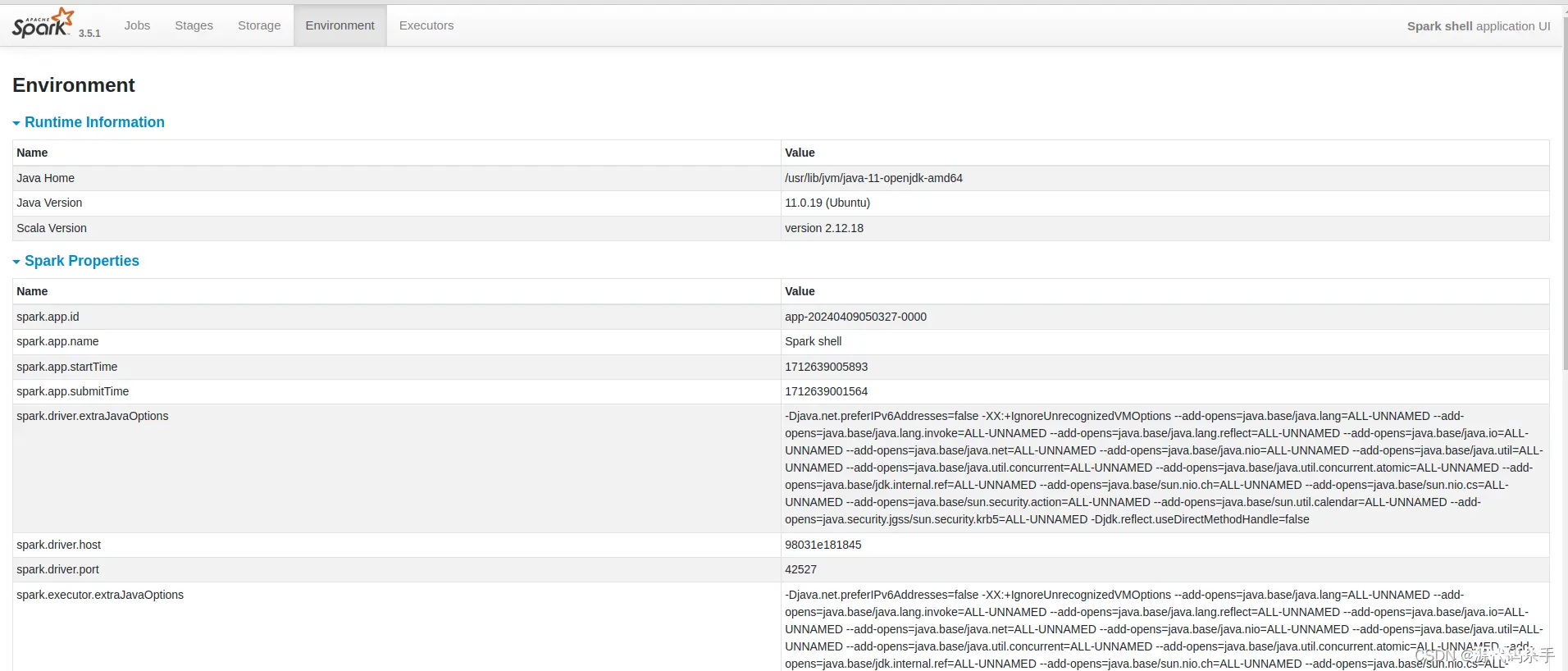
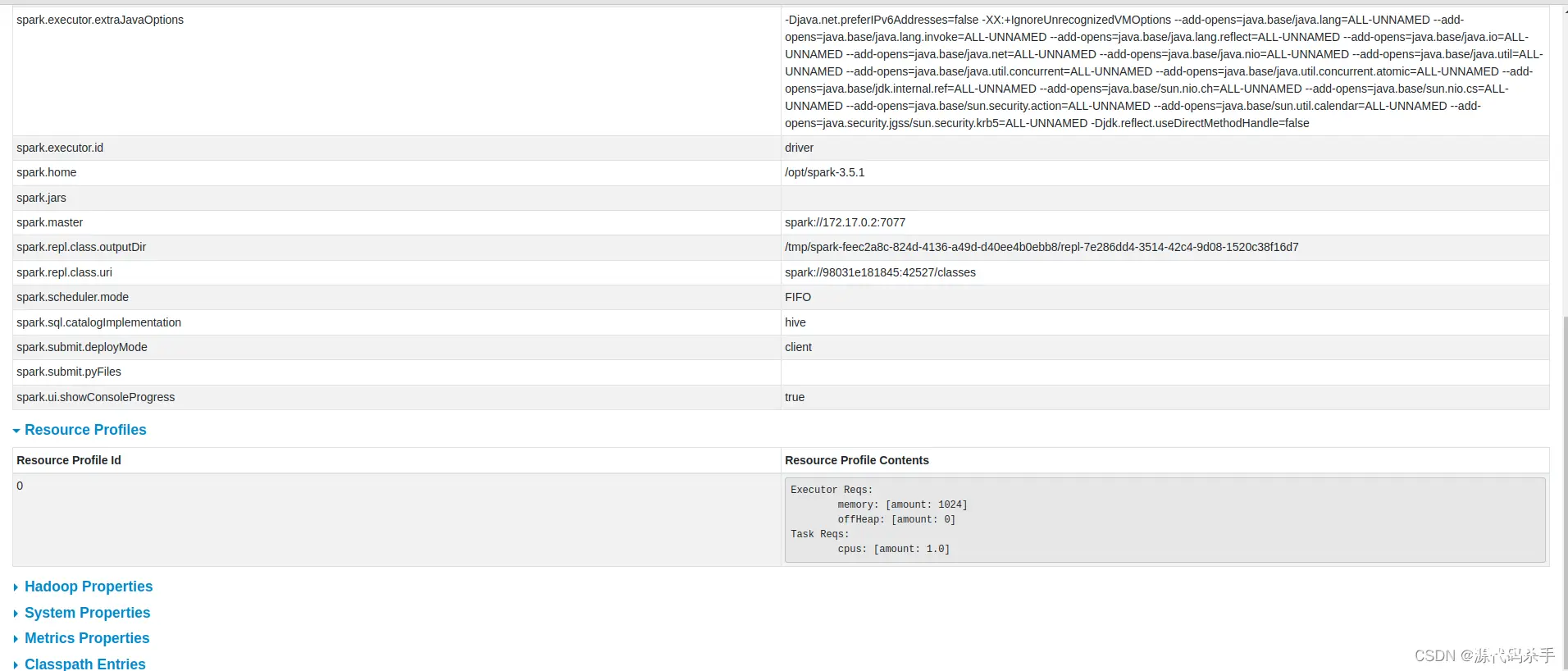
Environment(环境):
这个页面显示了Spark应用程序的运行环境的相关信息,包括Spark配置、系统属性、环境变量等。您可以在这里查看Spark应用程序的配置信息,并根据需要进行调整。
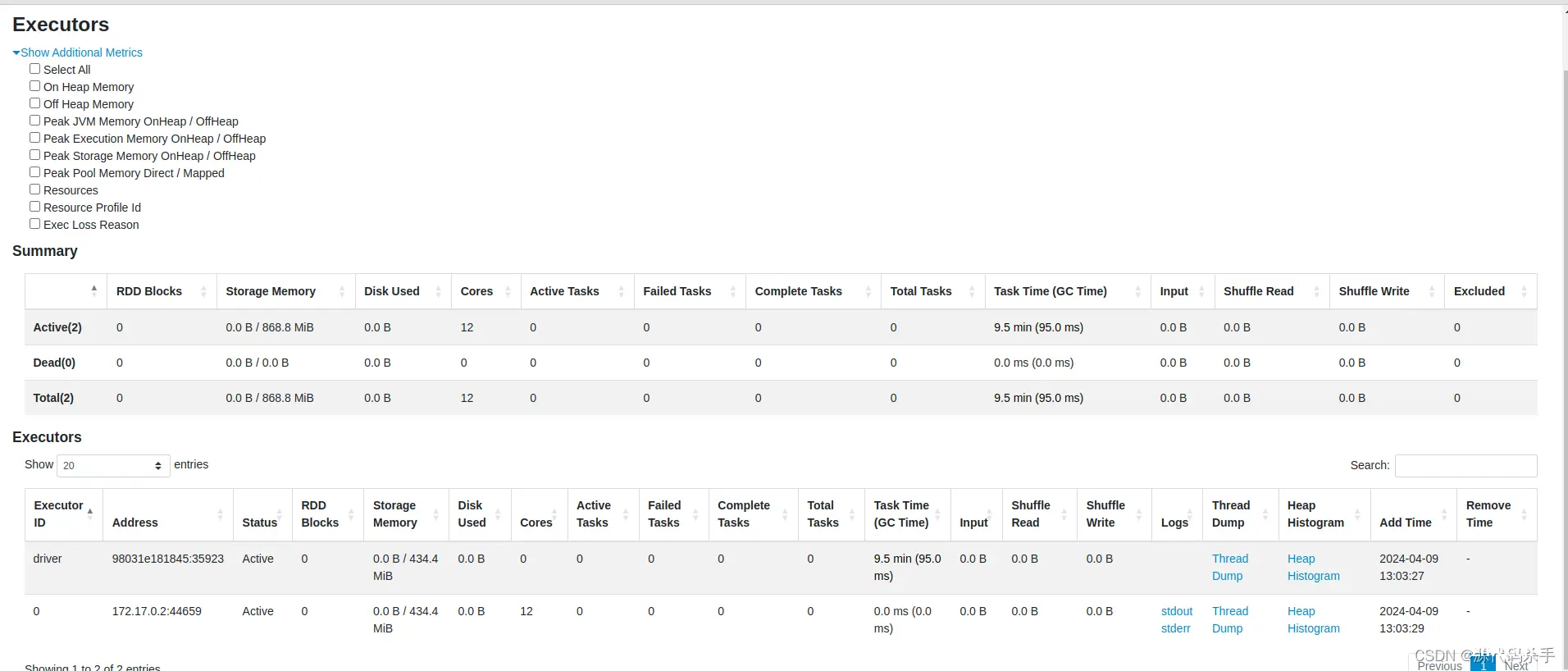
Executors(执行器):
这个页面显示了当前正在运行的Spark应用程序中的各个执行器(Executor)的相关信息。执行器是Spark集群中负责执行任务的节点,每个执行器可以运行多个任务。在这个页面中,您可以查看每个执行器的状态、资源使用情况、运行的任务数量等信息。
下一篇: [Linux初阶]which-find-grep-wc-管道符命令
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。