循环神经网络系列-GRU原理、优化、改进及代码实现(时序预测/分类/回归拟合,Matlab)
KAU的云实验台 2024-09-05 09:05:03 阅读 56
前段时间的文章中KAU介绍了循环神经网络 (Recurrent Neural Network,RNN)的改进算法——长短期记忆神经网络 (Long Short-Term Memory,LSTM),LSTM诞生于1997年,其有效克服了RNN的梯度消失问题,在许多场合得到了应用。然而,LSTM网络的内部机制复杂,有很多参数需要控制,这导致其运算的时间成本相当大。
门控循环单元(Gated Recurrent Unit,GRU)于2014年由Cho等[1]提出,可以看作是LSTM的一个变种,其将LSTM的遗忘门和输入门结合为一个单一的更新门,去掉输出门,增加重置门,同时合并了单元状态和隐藏状态,使最终的模型比标准LSTM模型更简单,训练速度更快,并且在性能上与LSTM不分伯仲。两种网络的结构图如下:

(左LSTM,右GRU)
接下来KAU就将具体介绍GRU的原理、优化、改进及其代码实现。
并将GRU与优化的GRU应用于时序预测/回归拟合/分类三种问题中
00 目录
1 GRU模型
2 优化算法及其改进概述
3 XX-GRU预测模型
4 GRU模型的改进——几种变体
5 实验结果
6 源码获取
01 GRU模型
对LSTM有过了解的话,那GRU一定是轻而易举的,GRU可以看作是LSTM的简化版本,GRU的结构如图所示:
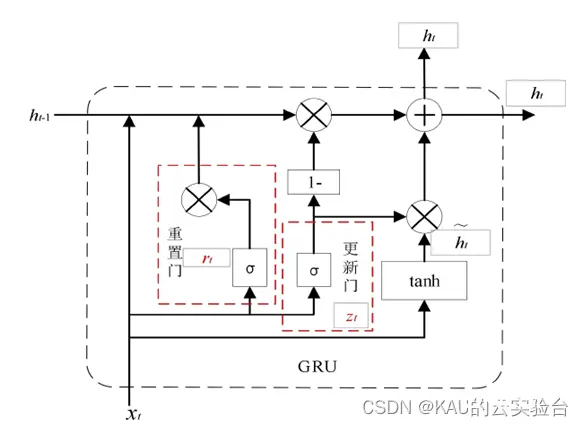
xt代表当前t时刻的输入数据,ht-1代表历史 t-1 时刻的隐含状态输出。σ和tanh分别表示 sigmoid 函数与双曲正切函数。GRU 网络结构为了精简内部结构,提升运算效率,将LSTM 中的输入门、遗忘门、输出门结构整合为更新门和重置门,且使用一个更新门控就可以实现神经网络的遗忘和选择记忆,这样使得参数大大减少,GRU原理如下:
更新门决定使用多少历史信息和当前信息来更新当前隐含状态。第t时刻的更新门为:
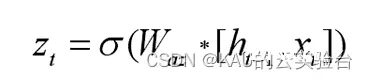
其中,Zt是门控更新信号,Zt 的大小决定了候选隐含状态的记忆的程度,ht-1为历史隐含状态,xt代表 t 时刻的输入数据,Wz为权重矩阵,σ是sigmoid函数。
重置门决定保留多少历史信息。第t时刻的重置门为:

其中,rt为重置信号,重置信号值越大说明需要记住的历史信息量越多,Wr为权重矩阵。
在更新门zt和重置门rt的作用下,当前时刻候选隐含状态,隐含输出状态ht可更新为:
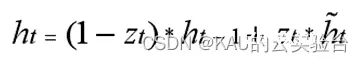
其中,候选隐含状态:
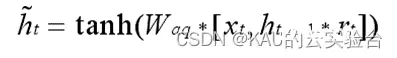
上式中,候选隐含状态负责融合输入数据和历史数据的信息特征,该操作与重置门得到的重置信号rt有关。而ht代表当前时刻最终单元状态,其包括遗忘和记忆两个过程,(1-Zt)与上时刻隐含状态ht-1的乘积表示遗忘过程,Zt越接近1,则将遗忘上时刻越多信息。Zt与候选隐含状态的乘积表示记忆过程,Zt大小决定了候选隐含状态的记忆程度,也就是保留之前多少的隐含状态。以上过程也即加入多少新记忆,就要忘记多少老记忆。
不过以上过程落实到代码其实也就几行就能调用实现,确实也更方便我们的研究了。
02 优化算法及其改进概述
同样,GRU也存在一定可进行优化选择的超参数,若采取经验法或试错法,则有不能获取最优取值组合、时间成本高等问题。优化算法通过对超参数组合的随机生成与更新,能够更快速地获取优解,不失为一种应用方法。
前面的文章中KAU已经介绍过很多种优化算法及其改进策略,本文中我也会应用这些算法优化GRU
03 XX-GRU预测模型
对于GRU而言,神经元数量、迭代次数、学习率、dropoutrate等都可作为待优化的参数,本文主要选取神经元数量、迭代次数、学习率作为待优化参数。
神经元数量:
神经元的数量直接影响模型的学习能力和网络的复杂性,过多的节点会增加网络的训练时间,而节点太少会损害网络性能。
迭代次数:
表示模型迭代整个训练数据集的次数。
学习率:
选择太小的学习率可能会延长训练周期,而太大的学习率可能会阻碍收敛。
对于时序数据来说,时间步长也可作为优化参数中的一个,以GWO为例,GWO优化GRU的流程如下:
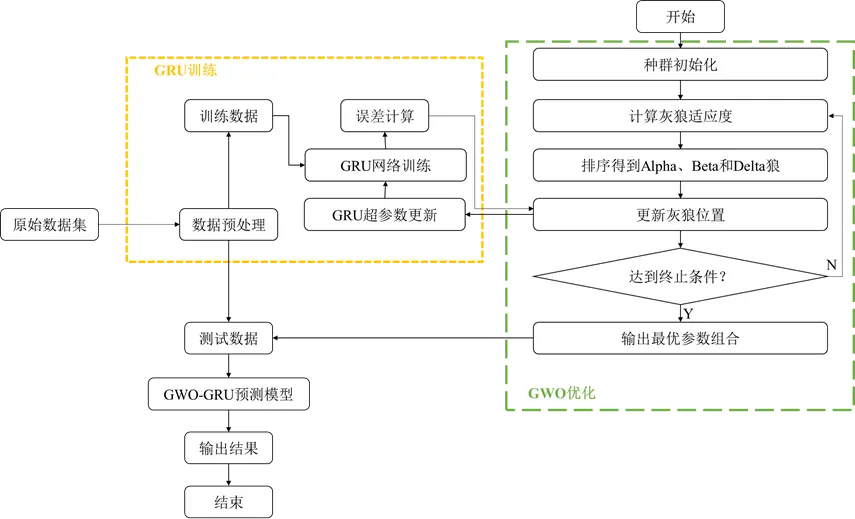
04 GRU模型的改进——几种变体
4.1 双向RNN
在经典的RNN中,神经元状态是从前向后单向传播的, 然而,有些任务当前时刻的输出不仅与之前状态有关,也与后续状态相关。比如,要预测一个句子中缺失的词语,我们必须考虑上下文才能做出正确预测,这时就需要双向的RNN( Bidirectional RNN,BiRNN) 来综合前后文信息。
将传统的RNN单元替换为LSTM单元或者GRU结构,则BiRNN就变成了双向LSTM ( Bi-directional LSTM,BiLSTM)网络或者双向GRU ( Bi-directional GRU,BiGRU)网络。
4.2 CNN-RNN
可以利用卷积神经网络良好的特征提取能力与循环神经网络良好的时序学习能力进行组合预测,其中的RNN单元同样可以用LSTM或GRU替换,同时双向的RNN同样可以作为替换。
4.3 注意力机制
注意力机制(Attention)诞生于20世纪90年代,在2014年火起来的,目前已经成为主流的一个模型概念。注意力机制其实就是基于人的注意力机制诞生的,比方说,在观察一个人类的照片的时候﹐会更加注意人的脸部;在观察一个句子的时候,更多注意力会放在谓语动词上;
例如,LSTM可以对动态序列数据建模并且保持数据中的依赖,但是在动作分析中并不需要所有的关节点,不相关的关节点反而会带来很多噪声,Attention机制可以更多地关注提供有用信息的关节点。
不过以上改进网络的方法在Matlab里实现起来似乎特别简单,比如BiLSTM只需要在layers里面加上下面这个语句就行了
bilstmLayer(numHiddenUnits,‘OutputMode’,‘last’)
除以上改进之外,还存在许多改进方法,KAU也会在循环神经网络系列中持续更新这些改进的原理和代码实现。
05 实验结果
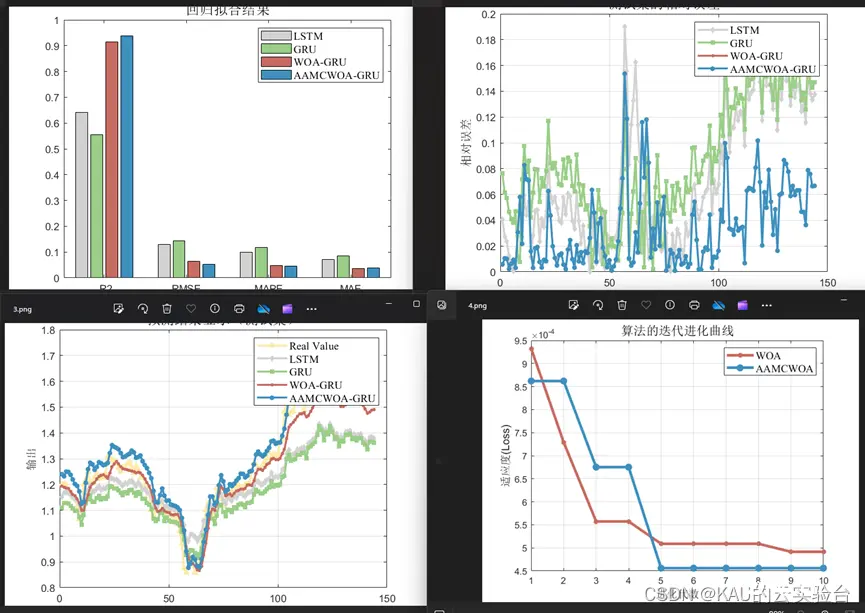
本文针对时序预测、分类和回归拟合问题进行实验,优化参数为隐层1神经元数,隐层2神经元数,迭代次数,学习率。
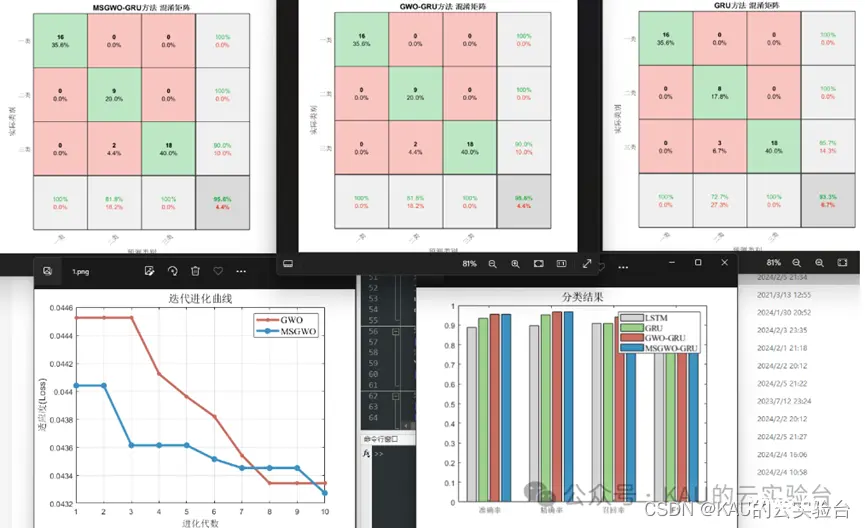
为量化预测质量,针对分类问题,本文采用混淆矩阵、准确率、精确率、召回率、F1-score进行评价。针对时序预测和回归拟合问题,本文采用均方根差、平均绝对百分误差、平均绝对值误差和可决系数进行评价。
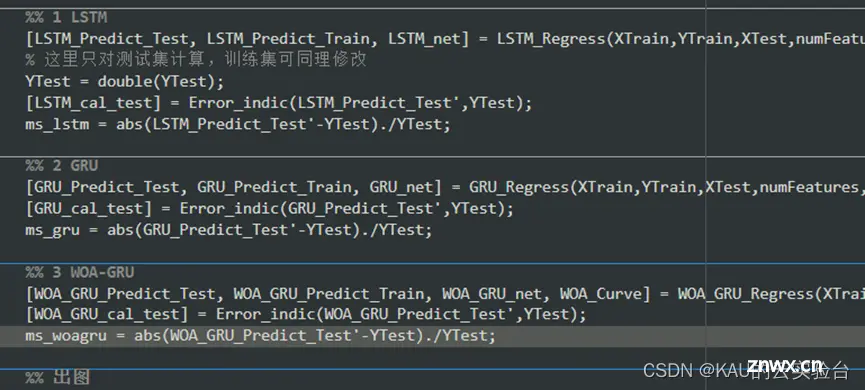
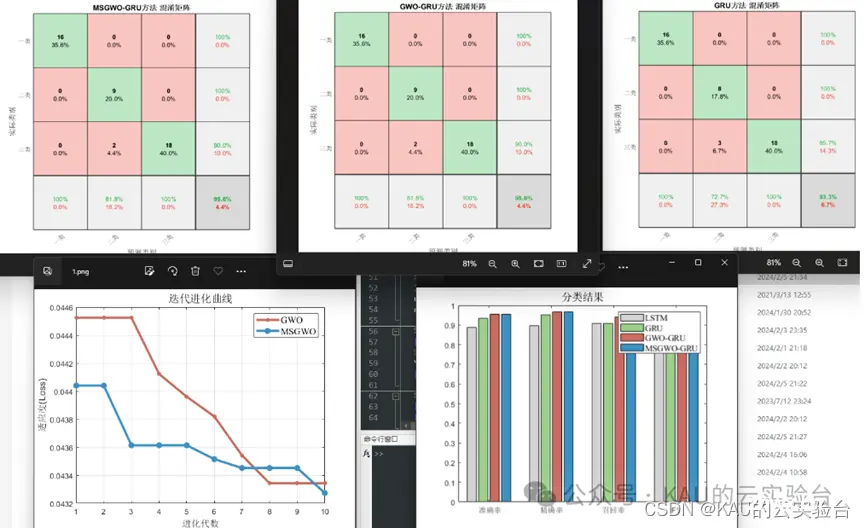
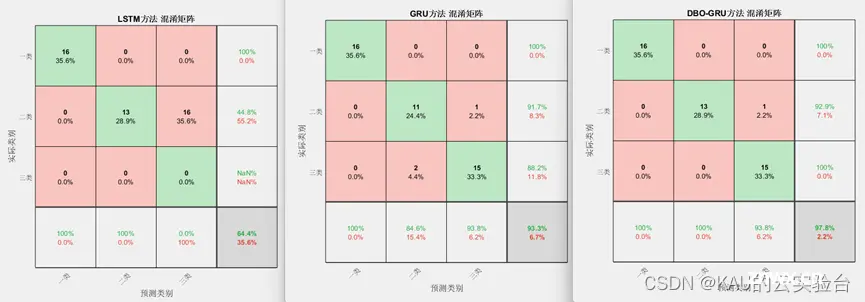
分类:(以DBO为例,数据集为多输入单输出)
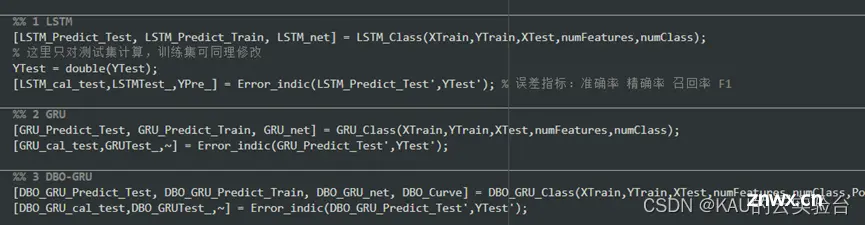
时序预测:(以GWO为例)
时序预测较之回归拟合,多了时间步长作为优化参数
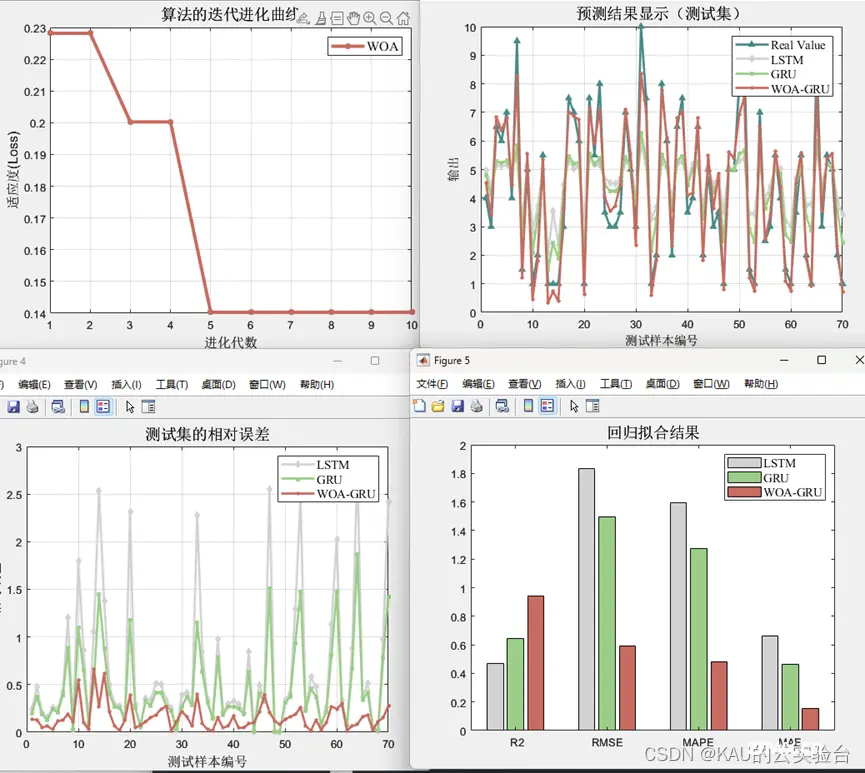
回归拟合:(以WOA为例,数据集为多输入单输出)
06 源码获取
代码注释详细,数据都用的excel,只需要替换数据集就行了,非常方便,针对分类、时序预测、回归拟合,采用MATLAB编码,本文源码提供3个版本:
1.免费版
主要是GRU模型,并且同时包含分类、时序预测、回归拟合3种应用,对于需要进行一些简单预测或者是想学习GRU算法的同学足够了。
获取方式——GZH(KAU的云实验台)后台回复:GRU
2.版本2
主要是各类优化算法(如:HHO、WOA、DBO、GWO)优化GRU模型,并有LSTM、GRU对比。针对分类、时序预测、回归拟合3种应用都各有代码。程序的注释详细,易于替换,KAU之前介绍过的智能优化算法都可以进行替换。
获取方式——
时序预测类问题
获取方式——GZH(KAU的云实验台)后台回复:GRUT
程序目录(以GWO为例)

分类问题
获取方式——GZH(KAU的云实验台)后台回复:GRC
程序目录(以DBO为例)

回归拟合问题
获取方式——GZH(KAU的云实验台)后台回复:GRUR
程序目录(以WOA为例)
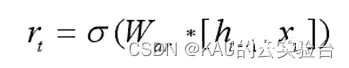
3.版本3
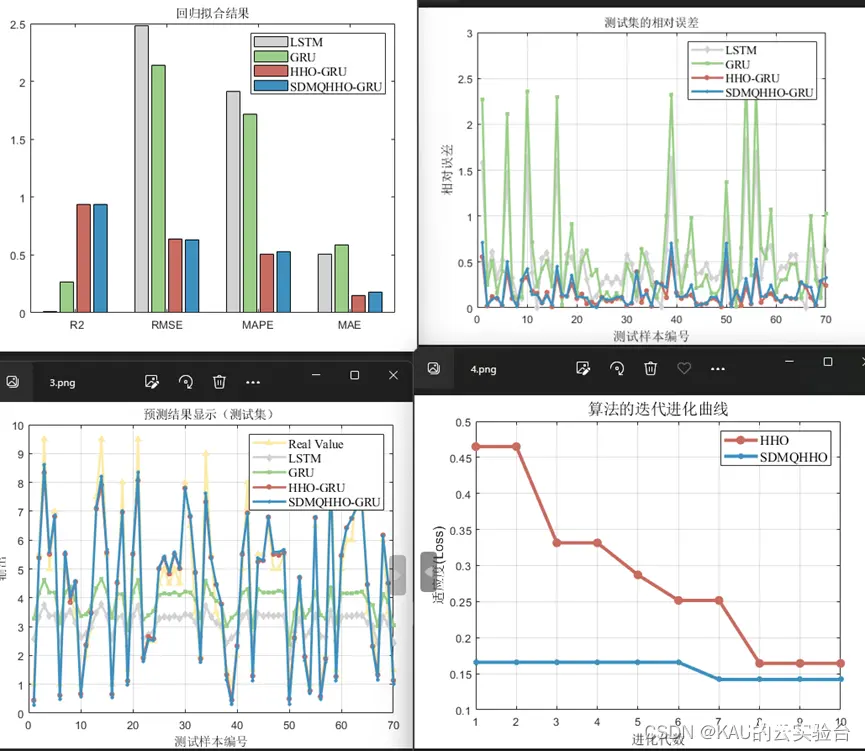
在付费版1的基础上,此版本引入了KAU前面提出的一系列原创改进算法进行对比,如MSIDBO、SDMQHHO、AAMCWOA、MSGWO。这部分程序包含了函数测试、预测模型对比两个部分,可以用来发这类方向的文章,当然你也可以在KAU算法的基础上再作创新改进,比如预测模型上可以再对预测误差做一个预测模型进行级联,或者对KAU的原创改进再引入新的修改策略等等。
(若前面已经购买了KAU的原创改进,想买付费版2,可以联系我给你减免)
获取方式——
时序预测类问题
获取方式——GZH(KAU的云实验台)后台回复:GRUT
程序目录(以AAMCWOA为例)

分类问题
获取方式——GZH(KAU的云实验台)后台回复:GRUC
程序目录(以MSGWO为例)
回归拟合问题
获取方式——GZH(KAU的云实验台)后台回复:GRUR
程序目录(以SDMQHHO为例)
参考文献
[1] CHO K,van MERRIENBOER B,GULCEHRE C,et al.Leamingphrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv Preprint,2014,2014: arXiv: 1406.1078.
另:如果有伙伴有待解决的优化问题(各种领域都可),可以发我,我会选择性的更新利用优化算法解决这些问题的文章。
如果这篇文章对你有帮助或启发,可以点击右下角的赞/在看(ง •̀_•́)ง(不点也行)。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。