C++第五讲(2):STL--string--string的模拟实现+知识加餐
爆炒脑仁 2024-10-08 12:35:01 阅读 84
C++第五讲(2):STL--string--string的模拟实现+知识加餐
1.string的模拟实现1.1string.h头文件 -- string类的声明1.2string.cpp源文件 -- string的具体实现1.3test.cpp源文件 -- string模拟实现的测试
2.知识补充1:swap3.知识补充2:拷贝构造函数优化4.知识补充3:=运算符重载优化5.知识补充4:引用计数--了解6.知识补充5:为什么创建string模板7.string题目解答7.1仅仅反转字符7.2字符串中第一个唯一字符7.3字符串最后一个单词的长度7.4字符串相加
1.string的模拟实现
string的模拟实现,不再详细阐述,具体都在代码中,我们直接上原码
1.1string.h头文件 – string类的声明
<code>#pragma once
#include <iostream>
using namespace std;
#include <string>
#include <assert.h>
//String的模拟实现
//为了与标准库中的string进行区分,我们可以定义一下属于自己的命名空间
namespace Mine
{ -- -->
//实行声明和定义分离
class string
{
public:
using iterator = char*;
using const_iterator = const char*;
构造函数
//string();
//析构函数
~string();
//传值构造函数
string(const char* str = "");
//string访问函数 -- []运算符重载
char& operator[](size_t i);
const char& operator[](size_t i) const;
//c_str函数,因为代码较少,所以直接在声明位置写
const char* c_str() const
{
return _str;
}
//预开辟空间函数
void reserve(size_t n = 0);
//尾插函数
void push_back(char c);
//追加函数
void append(const char* s);
//+=运算符重载
//追加字符
string& operator+=(char c);
//追加字符串
string& operator+=(const char* s);
//插入函数
void insert(size_t pos, char c);
void insert(size_t pos, const char* s);
//删除函数
void erase(size_t pos, size_t len = npos);
//查找函数
//查找字符
size_t find(char c, size_t pos = 0);
//查找字符串
size_t find(const char* s, size_t pos);
//生成字串
string substr(size_t pos = 0, size_t len = npos);
//拷贝构造函数
string(const string& str);
//迭代器:实现了begin和end的功能之后,就可以使用迭代器了
//using iterator = char*; //在最上面对迭代器返回值进行声明
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator begint() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
//返回_size的函数
size_t size() const
{
return _size;
}
//clear函数,不改变原来的空间大小
void clear();
private:
//string中会存储空间指针、空间大小和实际使用的空间大小
char* _str;
int _size;
int _capacity;
public:
对于静态const整数,编译器会做出一个特殊处理,使得它能够在声明时就初始化,但是尽量不要使用这种初始化,防止混乱
//static const size_t npos = -1;
static const size_t npos;
};
//运算符重载:运算符重载声明在类外面,称为全局函数,目的是为了匹配问题
//因为重载方法左边必须是this变量,这个问题之前在流插入<<运算符中提过
bool operator== (const string& s1, const string& s2);
bool operator!= (const string& s1, const string& s2);
bool operator>= (const string& s1, const string& s2);
bool operator<= (const string& s1, const string& s2);
bool operator> (const string& s1, const string& s2);
bool operator< (const string& s1, const string& s2);
//流插入和流提取运算符重载
ostream& operator<< (ostream& os, string& str);
istream& operator>> (istream& is, string& str);
//getline函数
istream& getline (istream& is, string& str, char delim = '\n');
}
1.2string.cpp源文件 – string的具体实现
#define _CRT_SECURE_NO_WARNINGS 1
#include "String.h"
//编译器会自动将命名空间名称相同的区域合并,所以我们可以在实现方法里也使用命名空间封装
namespace Mine
{
//设置npos的值
const size_t string::npos = -1;
构造函数
//string::string()
////如果string初始话为空的话,打印string操作是会报错的,但是库里的string不会,就是初始化时给了一个\0
//:_str(new char[1]{'\0'})
//,_size(0)
//,_capacity(0)
//{}
//析构函数
string::~string()
{
delete[] _str;
_str = nullptr;
_size = 0;
_capacity = 0;
}
//传值构造函数
//string::string(const char* s)
////这里三个strlen,如果构造一个string就使用三个strlen,消耗很大,尝试优化一下
//:_str(new char[strlen(s)+1])//因为\0,所以这里开辟的空间要+1
//,_size(strlen(s))
//,_capacity(strlen(s))
//{}
//
//string::string(const char* s)
////这样写的话要注意:初始化列表初始化顺序是按照声明顺序来初始化的,但是一般不会改声明顺序,不太保险
////因为会出现其它人因为不顺眼改声明顺序的情况
//:_size(strlen(s))
//,_str(new char[_size+1])
//,_capacity(_size)
//{}
//
string::string(const char* str)
//所以我们可以只初始化一个—_size
:_size(strlen(str))
{
_str = new char[_size + 1];
_capacity = _size;
strcpy(_str, str);
}
//string访问函数
char& string::operator[](size_t i)
{
//访问的必须是有效数据
assert(i < _size);
return _str[i];
}
const char& string::operator[](size_t i) const
{
//访问的必须是有效数据
assert(i < _size);
return _str[i];
}
//预开辟空间函数
void string::reserve(size_t n)
{
//只有当需要开辟的空间大于原来的空间时,才需要开辟空间
if (n > _capacity)
{
如果这样直接开辟空间的话,原本的空间得不到释放,会有问题
//_str = new char[n + 1];
//_capacity = n;
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
//尾插函数
void string::push_back(char c)
{
if (_size == _capacity)
{
//当空间不足时,需要开辟空间
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
//直接插入即可
_str[_size] = c;
_size++;
_str[_size] = '\0';
}
//追加函数
void string::append(const char* s)
{
//首先需要扩容,才能在后边追加
size_t len = strlen(s);
if (len + _size > _capacity)
{
size_t newcapacity = _capacity * 2;
if (newcapacity < _size+len)
{
//如果二倍空间还不够,就需要多少开多少
newcapacity = _size + len;
}
reserve(newcapacity);
_capacity = newcapacity;
}
//此时应该要在str的后边进行追加
strcpy(_str + _size, s);
_size += len;
}
//+=运算符重载
//追加一个字符
string& string::operator+=(char c)
{
push_back(c);
return *this;
}
//追加一个字符串
string& string::operator+=(const char* s)
{
append(s);
return *this;
}
//插入函数
void string::insert(size_t pos, char c)
{
//插入的位置应该合法
assert(pos <= _size);
//插入方法和顺序表有相似之处,都要将数据向后移动
//首先要检查空间是否充足
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);//reserve函数中存在着设置_capacity值的功能
}
//将pos位置之后的值都向后移动一位
for (size_t i = _size + 1; i > pos; i--)
{
_str[i] = _str[i - 1];
}
_str[pos] = c;
_size++;
}
void string::insert(size_t pos, const char* s)
{
//插入的位置应该合法
assert(pos <= _size);
//此时对于空间的检查应该加以改变
size_t len = strlen(s);
if (_size+len > _capacity)
{
size_t newcapacity = _capacity * 2;
if (_size + len > newcapacity)
{
newcapacity = _size + len;
}
reserve(newcapacity);
}
//将pos位置之后的字符还要进行移动,但是这时需要考虑条件
size_t end = _size + len;
while (end > pos+len-1)//注意是pos+len-1
{
_str[end] = _str[end - len];
--end;
}
for (size_t i = 0; i < len; i++)
{
_str[pos + i] = s[i];
}
_size += len;
}
//删除函数
void string::erase(size_t pos, size_t len)
{
assert(pos < _size);
//如果传入的参数特别大时,将pos之后的值都删了
if (len >= _size - pos)
{
//直接修改\0的位置即可
_str[pos] = '\0';
_size = pos;
}
else
{
//当传入的参数不大时,需要将数据向前移动
size_t end = pos + len;
while (end <= _size)
{
_str[end - len] = _str[end];
++end;
}
_size -= len;
}
}
//查找函数
//查找字符
size_t string::find(char c, size_t pos)
{
assert(pos < _size);
//这里我们直接使用暴力查找方式
//从pos位置开始查找
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == c)
{
return i;
}
}
return npos;
}
//查找字符串
size_t string::find(const char* s, size_t pos)
{
assert(pos < _size);
//这里直接使用库里面的函数进行处理
//strstr函数:成功返回指向第一个字符的指针,失败返回null
const char* ptr = strstr(_str + pos, s);
if (ptr == nullptr)
{
//如果没有找到,返回npos
return npos;
}
else
{
//找到了,返回下标
return ptr - _str;
}
}
//生成字串
string string::substr(size_t pos, size_t len)
{
assert(pos < _size);
//如果传入的len太大,那么直接取完字符串
if (len > _size - pos)
{
len = _size - pos;
}
Mine::string ret;
ret.reserve(len);
for (size_t i = 0; i < len; i++)
{
//这里需要+=,因为+=才能够处理\0的情况
ret += _str[i + pos];
}
//这里返回的是一个string类,传值返回会调用拷贝构造,如果不实现拷贝构造的话
//自己提供的拷贝构造会进行浅拷贝,直接拷贝地址的行为是十分不正确的,所以如果
//想要该函数正常运行,还需要自己实现一个拷贝构造函数
return ret;
}
//拷贝构造函数
string::string(const string& str)
{
//开辟空间 + 拷贝值
_str = new char[str._capacity + 1];
strcpy(_str, str._str);
_size = str._size;
_capacity = str._capacity;
}
//运算符重载
bool operator==(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) == 0;
}
bool operator!=(const string& s1, const string& s2)
{
return !(s1 == s2);
}
bool operator>=(const string& s1, const string& s2)
{
return !(s1 < s2);
}
bool operator<=(const string& s1, const string& s2)
{
return (s1 < s2) || (s1 == s2);
}
bool operator>(const string& s1, const string& s2)
{
return !(s1 <= s2);
}
bool operator<(const string& s1, const string& s2)
{
return strcmp(s1.c_str(), s2.c_str()) < 0;
}
//流插入和流提取运算符重载
ostream& operator<< (ostream& os, string& str)
{
//os<< '"';//在这个函数中,我们可以自定义输出一些自己想要输出的东西
//os<< "xx\"xx";
//这里直接使用c_str()函数会出现一些问题,这个之后会说
//所以这里我们需要逐个进行打印
for (size_t i = 0; i < str.size(); i++)
{
os << str[i];
}
//os<< '"';
return os;
}
//istream& operator>> (istream& is, string& str)
//{
////对于流提取,我们知道,如果遇到空格或者\n就会取消读取
//使用is进行输入会出现问题,因为cin遇到空格或\n就会取消读取,这就意味着ch一直无法读取空格和\n,那么之后检查
//ch是否是空格或\n就会出现一直查询的问题
////char ch;
////is >> ch;
//str.clear();
//char ch = is.get();//get函数:是流输入中的一个函数,该函数可以接受一切char字符,包括空格和\n
//while(ch != ' ' && ch != '\n')
//{
////因为是+=,所以str中要清理一下内存,使用clear函数,防止输出时输出了原来的数据
////而且+=就不用考虑开辟空间的问题了,+=实现时就有开辟空间的操作
//str += ch;
//ch = is.get();
//}
//return is;
//}
istream& operator>> (istream& is, string& str)
{
str.clear();
//上面的流提取运算符重载,我们不够满意,因为+=需要一直开辟空间,效率很低,所以我们要进行优化:
//创建一个数据buff,先将数据保存到buff中
char buff[256];
int i = 0;
char ch = is.get();
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 255)
{
//当buff数组满了时,才执行+=操作,然后让i=0,直到取完
buff[i] = '\0';
str += buff;
i = 0;
}
ch = is.get();
}
if (i > 0)
{
//注意这里要存一个\0
buff[i] = '\0';
str += buff;
}
return is;
}
//clear函数,不改变原来的空间大小
void string::clear()
{
_str[0] = '\0';
_size = 0;
}
//getline函数
//与流提取运算符重载不同的时,该函数可以自己指定结束字符
istream& getline(istream& is, string& str, char delim)
{
str.clear();
//和上面的操作一样,只是while循环条件改变一下
char buff[256];
int i = 0;
char ch = is.get();
while (ch != delim)
{
buff[i++] = ch;
if (i == 255)
{
buff[i] = '\0';
str += buff;
i = 0;
}
ch = is.get();
}
if (i > 0)
{
buff[i] = '\0';
str += buff;
}
return is;
}
}
1.3test.cpp源文件 – string模拟实现的测试
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
#include <string>
#include "String.h"
//int main()
//{
//string name;
//
////使用1:不指定结束字符
//cout << "Please, enter your full name: ";
//getline(std::cin, name);//hello world
//cout << name << endl;;//hello world
//
////使用2:指定结束符
//getline(cin, name, 'a');
//cout << name << endl;
//return 0;
//}
int main()
{
//Mine::string s1("hello world");
//cout << s1.c_str() << endl;
//s1[0] = 'x';
//cout << s1.c_str() << endl;
//s1.reserve(20);
//cout << s1.c_str() << endl;
//s1.push_back('x');
//s1.push_back('x');
//s1.push_back('x');
//s1.push_back('x');
//cout << s1.c_str() << endl;
//s1.append("hello xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx1");
//cout << s1.c_str() << endl;
//s1 += 's';
//cout << s1.c_str() << endl;
//s1 += "hello";
//cout << s1.c_str() << endl;
//s1.insert(0, 'x');
//cout << s1.c_str() << endl;
//s1.insert(0, "hello");
//cout << s1.c_str() << endl;
//s1.erase(0, 7);
//cout << s1.c_str() << endl;
//s1.erase(27, 7);
//cout << s1.c_str() << endl;
查找一个字符
//cout << s1.find('x', 0) << endl;
查找字符串
//Mine::string s2 = "https://legacy.cplusplus.com/reference/string/string/substr/";
//size_t pos1 = s2.find(':');
//size_t pos2 = s2.find('/', pos1 + 3);
//if (pos1 != string::npos && pos2 != string::npos)
//{
//Mine::string domain = s2.substr(pos1 + 3, pos2 - (pos1 + 3));//legacy.cplusplus.com
//cout << domain.c_str() << endl;
//Mine::string uri = s2.substr(pos2 + 1);//reference/string/string/substr/
//cout << uri.c_str() << endl;
//}
运算符重载
//Mine::string s1("hello world");
//Mine::string s2("hello wor");
//cout << (s1 == s2) << endl;//0
//cout << (s1 != s2) << endl;//1
//cout << (s1 > s2) << endl;//1
//cout << (s1 < s2) << endl;//0
Mine::string s1("hello world");
cout << s1 << endl;
cin >> s1;
cout << s1 << endl;
cin >> s1;
cout << s1 << endl;
Mine::getline(cin, s1, '!');
cout << s1 << endl;
return 0;
}
2.知识补充1:swap
在string类中,有着两个swap方法,而在C++标准库中,又有一个swap方法,实现这么多swap的用处是什么呢?

我们通过画图来直观地感受感受:
<code>//这是下面画图时解析swap需要使用的代码:
Mine::string s1("hello world");
Mine::string s2("xxxxxxxxxxxxxxxxxxxxxx");
swap(s1, s2);
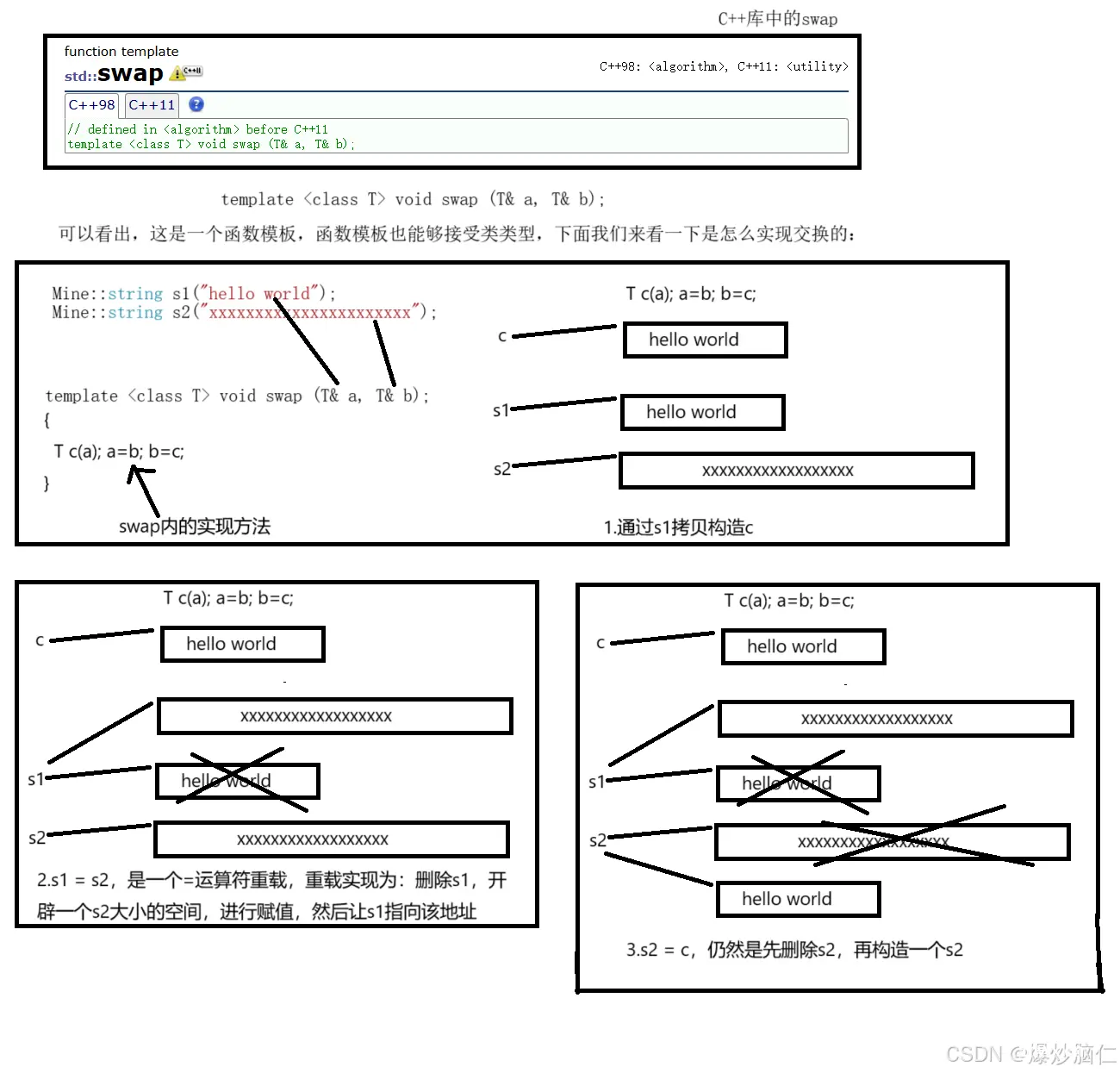
可以看出,C++库中的swap函数使用起来非常复杂,我们再看string类中swap的实现:
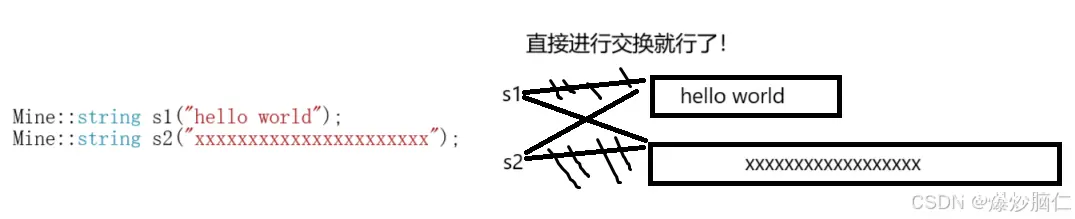
也就是说,实现方法为:
<code>//交换函数
void string::swap(string& s)
{ -- -->
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
而最后一个swap为一个全局函数,它的声明和定义为:
//交换函数声明
void swap(string& s1, string& s2);
void swap(string& s1, string& s2)
{
s1.swap(s2);
}
里面其实是对类swap的一个封装,这样实现的目的为:
int main()
{
Mine::string s1("hello world");
Mine::string s2("xxxxxxxxxxxxxxxxxxxxxx");
s1.swap(s2);
cout << s1 << endl;
cout << s2 << endl;
swap(s1, s2);//此时就会调用类里的swap函数,而不是标准库中的交换函数了,而且对于int或内置类型的交换,还会使用适合它的交换函数
cout << s1 << endl;
cout << s2 << endl;
return 0;
}
3.知识补充2:拷贝构造函数优化
拷贝构造函数
传统写法:自己分配空间,自己赋值
//string::string(const string& str)
//{
////开辟空间 + 拷贝值
//_str = new char[str._capacity + 1];
//strcpy(_str, str._str);
//
//_size = str._size;
//_capacity = str._capacity;
//}
//
//现代写法:
string::string(const string& str)
{
string tmp(str.c_str());//通过字符串直接构造一个tmp
swap(tmp);//然后将this与tmp进行交换,就实现了拷贝构造的功能
}
但是要注意的是:现代写法只是看起来变得简洁了,但是效率并没有提高
4.知识补充3:=运算符重载优化
传统写法
//string& string::operator=(const string& s)
//{
//if (this != &s)//需要处理自己给自己赋值的情况
//{
//delete[] _str;
//_str = new char[s._capacity + 1];
//strcpy(_str, s._str);
//_size = s._size;
//_capacity = s._capacity;
//}
//return *this;
//}
//
优化写法
//string& string::operator=(string& s)
//{
//if(this != &s)
//{
////和上面一样,进行交换
//string tmp(s.c_str());
//swap(tmp);
//}
//return *this;
//}
//
//现代写法:
string& string::operator=(string s)//这里是拷贝构造接受string传入的值
{
swap(s);//然后进行交换
//这里不用考虑析构问题,因为交换了之后,s是拷贝构造,会自己析构
return *this;
}
5.知识补充4:引用计数–了解
该方法在之前使用广泛,但是现在好像不怎么用了,所以作为了解
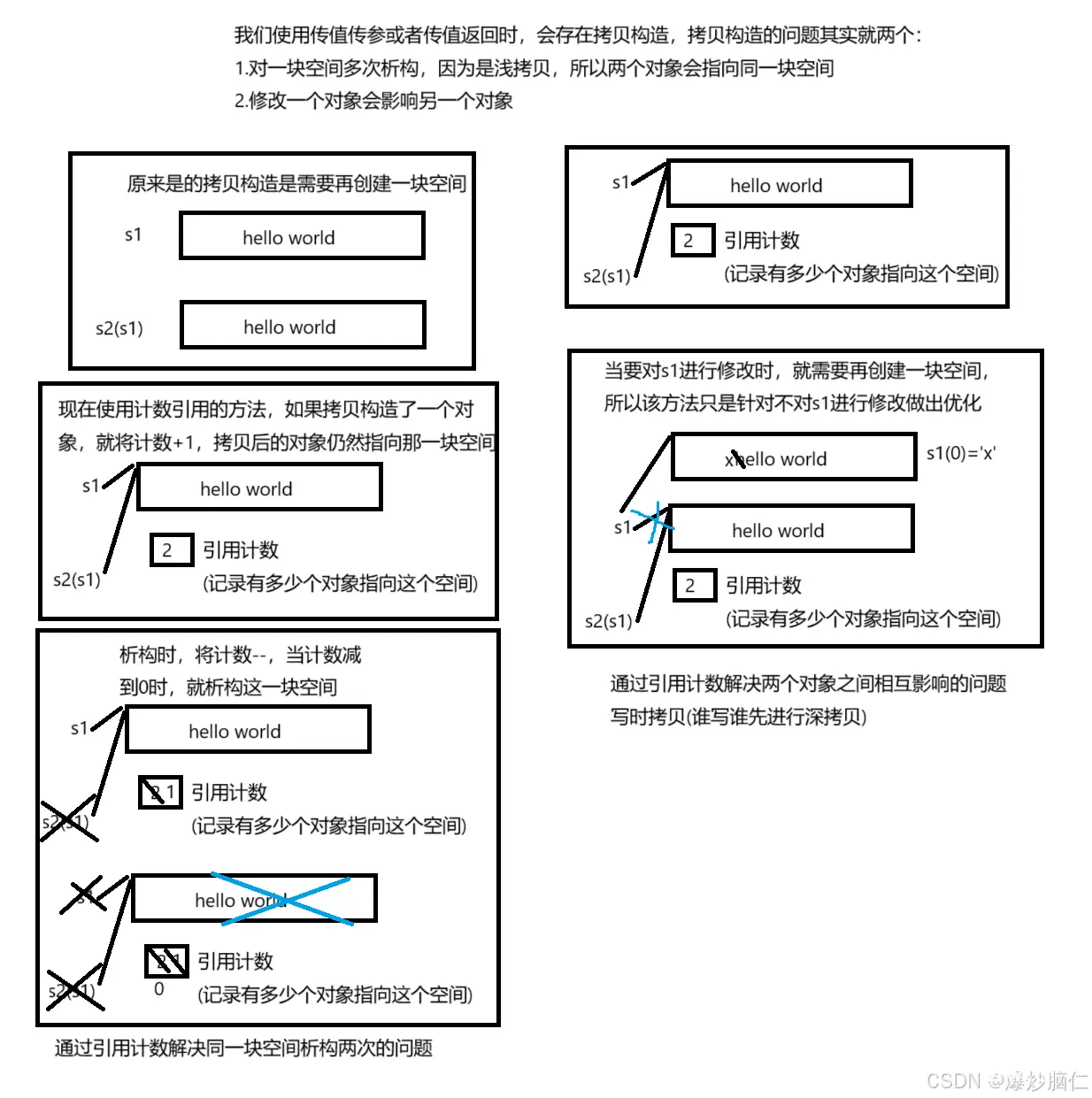
6.知识补充5:为什么创建string模板
计算机只能够识别0和1,那么计算机是如何将比特值转换成我们的文字符号的呢,其实是映射的关系,在计算机初期,美国计算机发展迅速,所以就针对于计算机编制了一套编码系统:ascii,英文字符较少,所以使用一个字节来存储:
后来随着计算机的推广,一个字节已经难以存储广大的字符了,比如汉字就有着10万余个,所以就推出了统一码(万国码)的概念,其中UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案,UTF后边跟的数字就是比特位,UTF-16就是两个字节存储,显然难以存储很多的汉字,而UTF-32能够存储亿单位的汉字,显然多了,所以我们一般使用UTF-8编码方案,UTF-8的好处也有:同时兼容了ascii,所以能够在编码英文的状态下同时编码中文,它的编码方式为:
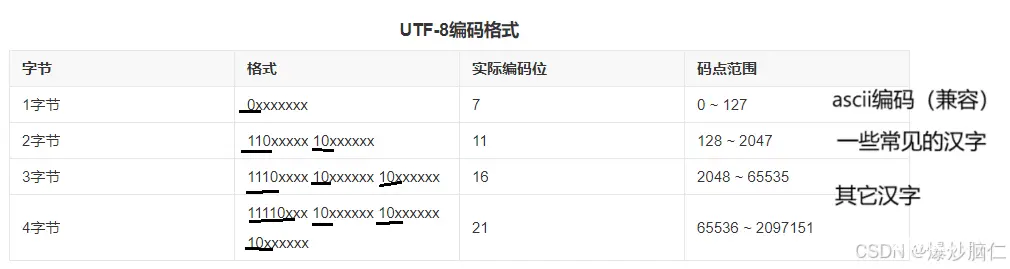

而string其实是basic_string模板中char的实例化
如果使用其它编码格式的话,就需要实例化其它参数,所以说string有模板是很正确的~!
7.string题目解答
7.1仅仅反转字符
链接: link
<code>class Solution { -- -->
public:
bool Check(char ch)
{
if(ch >= 'a' && ch <= 'z')
return true;
if(ch >= 'A' && ch <= 'Z')
return true;
return false;
}
string reverseOnlyLetters(string s) {
int left = 0;
int right = s.size()-1;
while(left < right)
{
while(left<right && !Check(s[left]))
{
left++;
}
while(left < right && !Check(s[right]))
{
right--;
}
if(left < right)
{
swap(s[left], s[right]);
left++;
right--;
}
}
return s;
}
};
7.2字符串中第一个唯一字符
链接: link
class Solution {
public:
int firstUniqChar(string s) {
//26个英文字母
int arr[27] = { 0};
for(int i = 0; i<s.size(); i++)
{
int pos = s[i]-'a';
arr[pos] += 1;
}
for(int i = 0; i<s.size(); i++)
{
int pos = s[i]-'a';
if(arr[pos] == 1)
return i;
}
return -1;
}
};
class Solution {
public:
int firstUniqChar(string s) {
// 统计每个字符出现的次数
int count[256] = { 0 };
int size = s.size();
for (int i = 0; i < size; ++i)
count[s[i]] += 1;
// 按照字符次序从前往后找只出现一次的字符
for (int i = 0; i < size; ++i)
if (1 == count[s[i]])
return i;
return -1;
}
};
7.3字符串最后一个单词的长度
链接: link
int main() {
string s;
while (getline(cin, s)) {
//最后一个单词前为空格,那么我们就可以寻找空格的位置
size_t pos = s.rfind(' ');
//假如s中没有空格,s=ABCDE,pos为size_t-1,而pos+1=0,所以返回的就是
//s.size(),直接就将没有空格的情况进行了处理,十分方便!
cout << s.size()-pos-1 << endl;
}
}
7.4字符串相加
链接: link
class Solution {
public:
string addStrings(string num1, string num2) {
int end1 = num1.size()-1;
int end2 = num2.size()-1;
int sum = 0;
int next = 0;
int valu1, valu2;
string newnum;
while(end1 >= 0 || end2 >= 0)
{
if(end1 >= 0)
valu1 = num1[end1--]-'0';
else
valu1 = 0;
if(end2 >= 0)
valu2 = num2[end2--]-'0';
else
valu2 = 0;
sum = valu1+valu2+next;
if(sum >= 10)
{
next = 1;
sum -= 10;
}
else
{
next = 0;
}
newnum.insert(newnum.begin(), sum+'0');
}
if(next == 1)
{
newnum.insert(newnum.begin(), '1');
}
return newnum;
}
};
下一篇: 【C++】深度解析C++的四种强制转换类型(小白一看就懂!!)
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。