从零实现本地知识库问答——实战基于OCR和文本解析器的新一代RAG引擎:RAGFlow(含源码剖析)
CSDN 2024-09-15 15:05:01 阅读 51
前言
我司RAG项目组每个月都会接到一些B端客户的项目需求,做的多了,会发现很多需求是大同小异的,所以我们准备做一个通用的产品,特别是对通用文档的处理
而在此之前,我们则想先学习一下目前市面上各种优秀的解决方法(且先只看开源的),于是便有了本文——剖析RAGFlow
相比langchain的冗余,RAGFlow的特点是一切从实用出发,怎么方便落地怎么来,包括搜索页直接用现成的Elasticsearch我的剖析RAGFlow的过程中并梳理写出来本文,花了一两天的时间,但大家有了此文,顶多1h便可以梳理清楚了
第一部分 InfiniFlow开源RAGFlow
继InfiniFlow于去年年底正式开源 AI 原生数据库 Infinity 之后,InfiniFlow的的端到端 RAG 解决方案 RAGFlow 也于近期正式开源(项目地址:https://github.com/infiniflow/ragflow,在线Demo:https://demo.ragflow.io)
对于 RAG 来说,最终依赖于LLM和RAG系统本身
对于LLM而言,其最基础的能力包括:摘要能力、翻译能力、可控性(是否听话)
而对于RAG 系统本身,其包含:
数据库的问题。多路召回对于 RAG还挺重要的。哪怕最简易的知识库,没有多路召回,也很难表现好。因此,RAG 系统的数据库,需要具备多路召回能力,而非简易的向量数据库
对于这第一点,InfiniFlow提供了 RAG 专用的数据库 Infinity 来缓解
数据的问题。拿现有的开源软件栈,包括各种向量数据库 ,RAG 编排工具例如LangChain, LlamaIndex 等,再搭配一个漂亮的 UI,就可以很容易的让一套 RAG 系统运行起来
类似的编排工具,在 Github 上已经有数万的 star
然而,所有这些工具,都没有很好地解决数据本身的问题,这导致复杂格式的文档是以混乱的方式进入到数据库中,必然导致 Garbage In Garbage Out
对于这第二点,InfiniFlow提供一款专用的 RAG 工具——RAGFlow
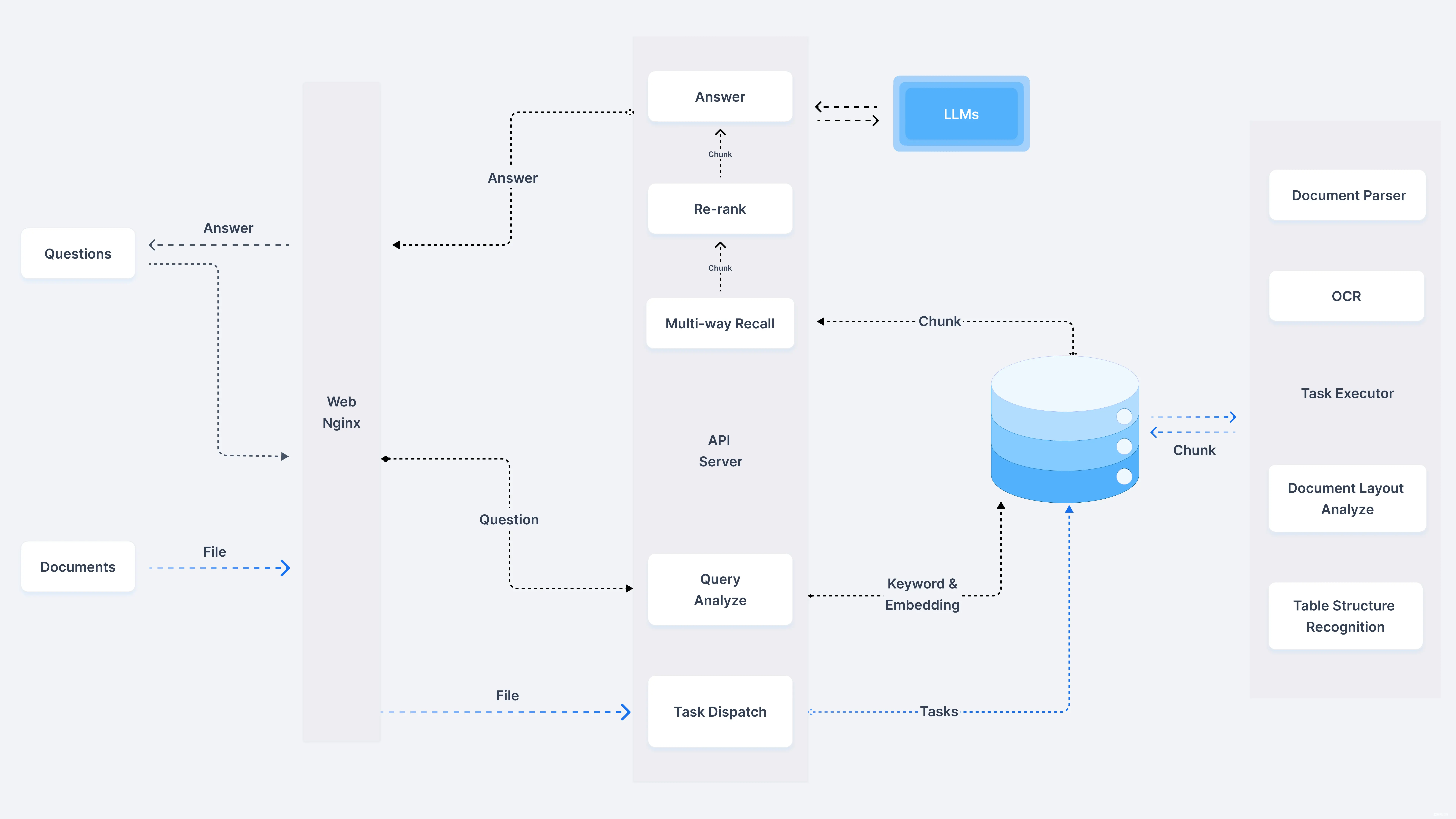
下边我们来看看 RAGFlow 这款产品,相比目前市面上已有的各类开源方案,都有哪些特点
1.1 允许用户上传并管理自己的文档(文档类型可以是任意类型)
首先, RAGFlow 是一款完整的 RAG 解决方案,它允许用户上传并管理自己的文档,文档类型可以是任意类型,例如 PDF、Word、PPT、Excel、当然也包含 TXT
在完成智能解析之后,让数据以正确地格式进入到数据库,然后用户可以采用任意大模型对自己上传的文档进行提问
也就是说,包含了如下完整的端到端流程
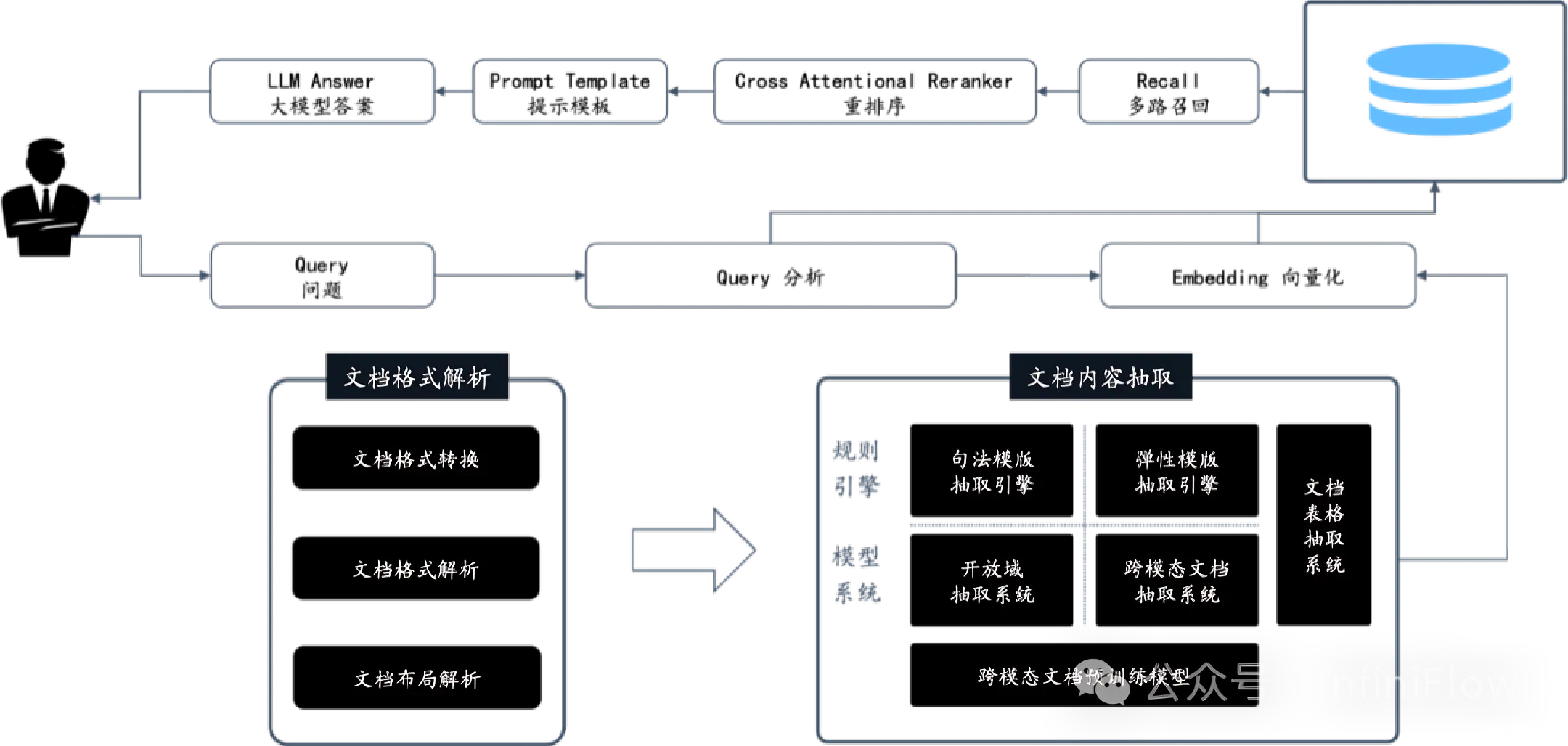
1.2 RAGFlow的4个特色
其次,RAGFlow 的最大特色,就是多样化的文档智能处理,保证用户的数据从 Garbage In Garbage Out 变为 Quality In Quality Out
为了做到这一点, RAGFlow 没有采用现成的 RAG 中间件,而是完全重新研发了一套智能文档理解系统,并以此为依托构建 RAG 任务编排体系
这个系统的特点包含以下4个点
1.2.1 AI 模型的智能文档处理系统
它是一套基于 AI 模型的智能文档处理系统:对于用户上传的文档,它需要自动识别文档的布局,包括标题,段落,换行等等,还包含难度很大的图片和表格。
对于表格来说,不仅仅要识别出文档中存在表格,还会针对表格的布局做进一步识别,包括内部每一个单元格,多行文字是否需要合并成一个单元格,等等,并且表格的内容还会结合表头信息处理,确保以合适的形式送到数据库,从而完成 RAG 针对这些细节数字的“大海捞针”
1.2.2 包含各种不同模板的智能文档处理系统
它是一套包含各种不同模板的智能文档处理系统:不同行业不同岗位所用到的文档不同,行文格式不同,对文档查阅的需求也不同。比如:
会计一般最常接触到的凭证,发票,Excel报表
查询的一般都是数字,如:看一下上月十五号发生哪些凭证,总额多少?上季度资产负债表里面净资产总额多少?合同台账中下个月有哪些应付应收?作为一个HR平时接触最庞杂的便是候选人简历
且查询最多的是列表查询,如:人才库中985/211的3到5年的算法工程师有哪些?985 硕士以上学历的人员有哪些?赵玉田的微信号多少?香秀哪个学校的来着?作为科研工作者接触到最多的可能是就是论文了,快速阅读和理解论文,梳理论文和引文之间的关系成了他们的痛点
这样看来凭证/报表、简历、论文的文档结构是不一样的,查询需求也是不一样的,那处理方式肯定是不一样
因此RAGFlow 在处理文档时,给了不少的选择:Q&A,Resume,Paper,Manual,Table,Book,Law,通用(当然,这些分类还在不断继续扩展中,处理过程还有待完善)...
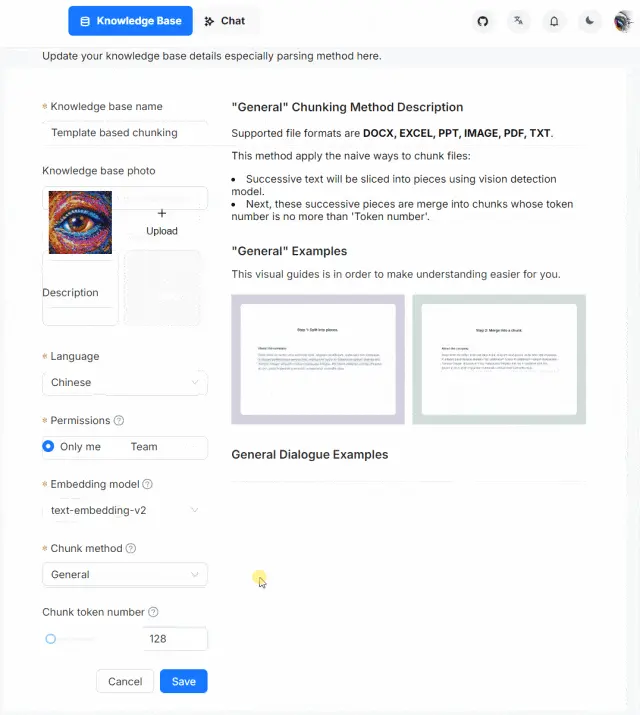
1.2.3 文档处理的可视化和可解释性——文本切片过程可视化,支持手动调整
智能文档处理的可视化和可解释性:用户上传的文档到底被处理成啥样了,如:分割了多少片,各种图表处理成啥样了,毕竟任何基于 AI 的系统只能保证大概率正确,作为系统有必要给出这样的空间让用户进行适当的干预,作为用户也有把控的需求
特别是对于 PDF,行文多种多样,变化多端,而且广泛流行于各行各业,对于它的把控尤为重要,RAGFlow不仅给出了处理结果,而且可以让用户查看文档解析结果并一次点击定位到原文,对比和原文的差异,可增、可减、可改、可查
1.2.4 让用户随时查看 LLM 是基于哪些原文来生成答案的
最后, RAGFlow 是一个完整的 RAG 系统,而目前开源的 RAG,大都忽视了 RAG 本身的最大优势之一:可以让 LLM 以可控的方式回答问题,或者换种说法:有理有据、消除幻觉
由于随着模型能力的不同,LLM 多少都会有概率会出现幻觉,在这种情况下, 一款 RAG 产品应该随时随地给用户以参考,让用户随时查看 LLM 是基于哪些原文来生成答案的,这需要同时生成原文的引用链接,并允许用户的鼠标 hover 上去即可调出原文的内容,甚至包含图表。如果还不能确定,再点一下便能定位到原文
一言以蔽之,答案提供关键引用的快照并支持追根溯源
1.3 RAGFlow 的核心 DeepDoc:视觉处理和解析器
RAGFlow 引擎的核心的是 DeepDoc,它由视觉处理和解析器两部分组成
1.3.1 视觉处理
模型在视觉层面具备以下能力
OCR(Optical Character Recognition,光学字符识别),由于许多文档都是以图像形式呈现的,或者至少能够转换为图像,因此OCR是文本提取的一个非常重要、基本,甚至通用的解决方案
<code>python deepdoc/vision/t_ocr.py --inputs=path_to_images_or_pdfs --output_dir=path_to_store_result
输入可以是图像或 PDF 的目录,或者单个图像、PDF文件,可以查看文件夹 path_to_store_result ,其中有演示结果位置的图像,以及包含 OCR 文本的 txt 文件

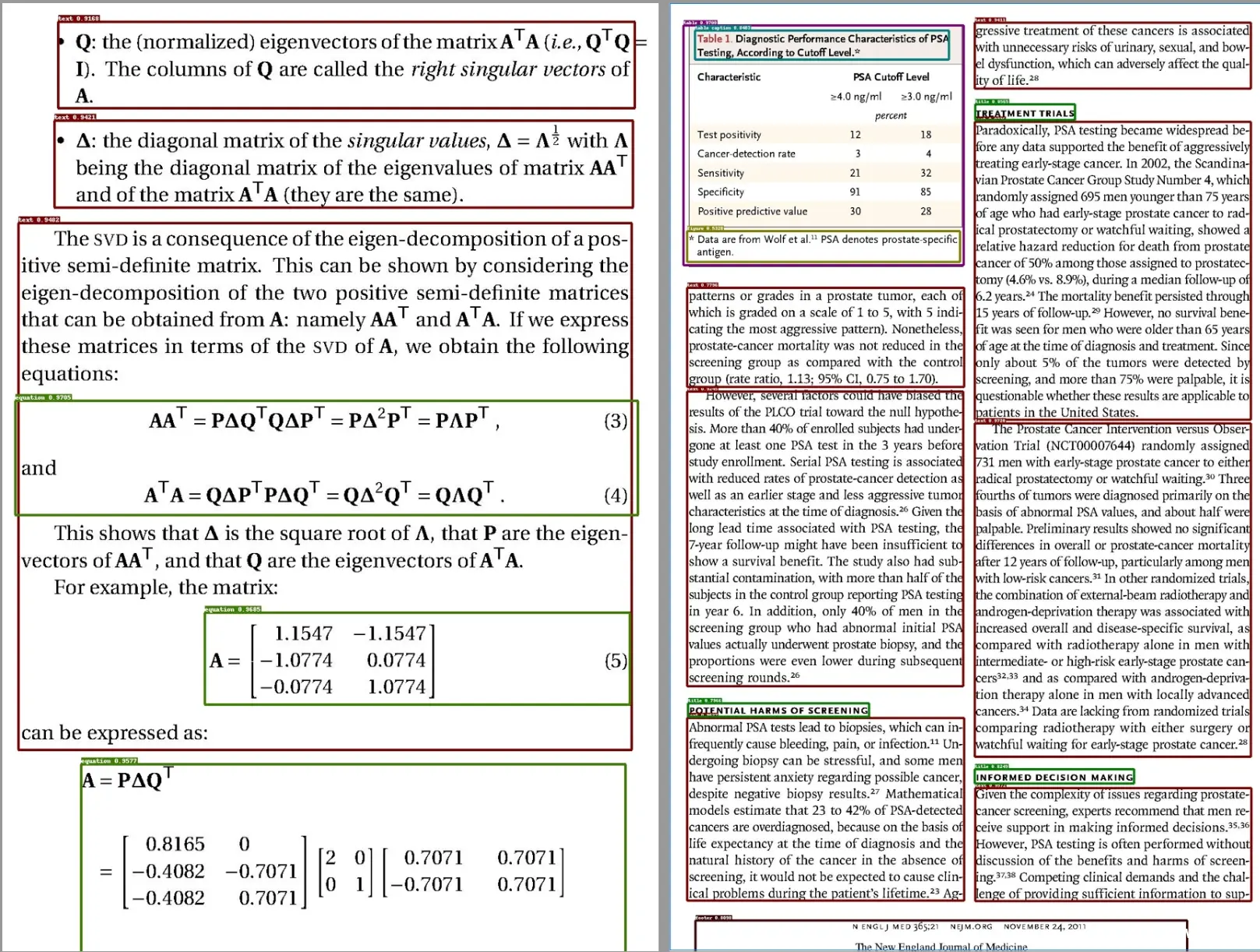
布局识别(Layout recognition)。来自不同领域的文件可能有不同的布局,如报纸、杂志、书籍和简历在布局方面是不同的。只有当机器有准确的布局分析时,它才能决定这些文本部分是连续的还是不连续的,或者这个部分需要表结构识别(Table Structure Recognition,TSR)来处理,或者这个部件是一个图形并用这个标题来描述。它包含 10 个基本布局组件,涵盖了大多数情况:
文本、标题
配图、配图标题
表格、表格标题
页头、页尾
参考引用、公式
且可以通过以下命令查看布局检测结果:
<code>python deepdoc/vision/t_recognizer.py --inputs=path_to_images_or_pdfs --threshold=0.2 --mode=layout --output_dir=path_to_store_result
输入可以是图像或PDF的目录,或者单个图像、PDF 文件,可以查看文件夹 path_to_store_result,其中有显示检测结果的图像,如下所示:
TSR(Table Structure Recognition,表结构识别)。数据表是一种常用的结构,用于表示包括数字或文本在内的数据。表的结构可能非常复杂,比如层次结构标题、跨单元格和投影行标题。除了 TSR,我们还将内容重新组合成 LLM 可以很好理解的句子。TSR 任务有 5 个标签:
列、行
列标题、行标题
合并单元格
你可以通过以下命令查看表结构识别结果:
<code>python deepdoc/vision/t_recognizer.py --inputs=path_to_images_or_pdfs --threshold=0.2 --mode=tsr --output_dir=path_to_store_result
输入可以是图像或PDF的目录,或者单个图像、PDF 文件。您可以查看文件夹 path_to_store_result,其中包含图像和 html 页面,这些页面展示了以下检测结果:
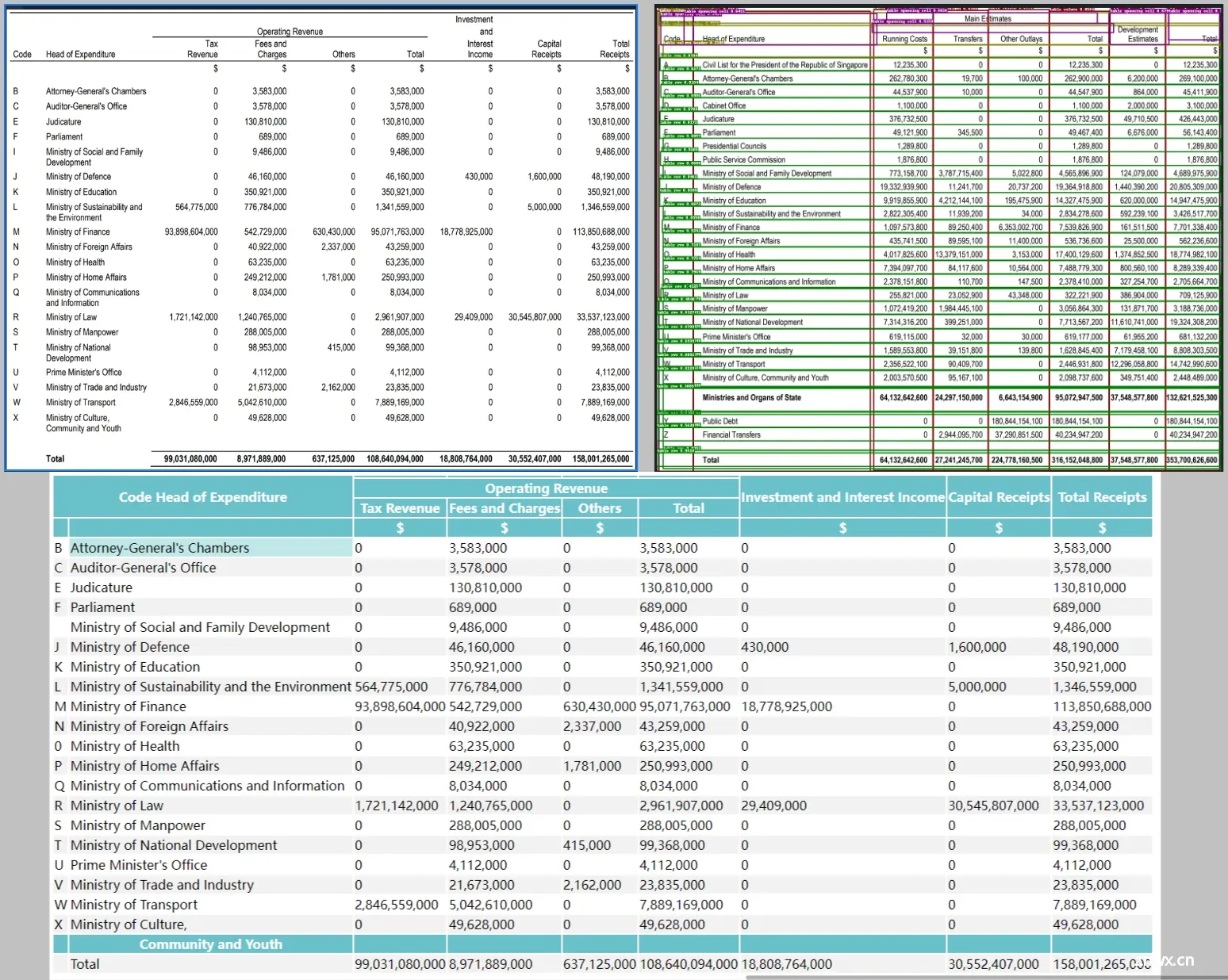
1.3.2 文本解析器
PDF、DOCX、EXCEL 和 PPT 4种文档格式都有相应的解析器。最复杂的是 PDF 解析器,因为 PDF 具有灵活性。PDF 解析器的输出包括:
在 PDF 中有自己位置的文本块(页码和矩形位置)。带有 PDF 裁剪图像的表格,以及已经翻译成自然语言句子的内容。图中带标题和文字的图
// 待更
第二部分 对ragflow-main/deepdoc的源码剖析
2.1 ragflow-main/deepdoc/vision
2.1.1 deepdoc/vision/ocr.py
总的来讲,OCR 类整合了文本检测和识别功能。在初始化时,它会尝试从本地或远程下载模型,并实例化TextRecognizer 和 TextDetector
首先,transform 西数用于对数据进行一系列操作
<code>def transform(data, ops=None):
""" transform """
if ops is None:
ops = []
for op in ops:
data = op(data)
if data is None:
return None
return data create_operators 函数根据配置创建操作符列表
Load model 函数加载ONNX模型,并根据设备类型选择合适的推理提供者(CPU或GPU)TextRecognizer 类用于识别文本框中的文宇
它在初始化时加载模型,并定义了多种图像预处理方法,如
resize_norm_img,用于调整和标准化输入图像,最终填充到一个固定大小的张量中
resizenorm_img-VL,类似于上面的resize_norm_img,但它直接将图像调整为制定的形状,并进行归一化处理
resize_norm_img_srn
srn_other_inputs
process_image_srn
resize_norm_img_sar
resize_norm_img_spin
resize_norm_img_svtr
resize_norm_img_abinet
norm_img_can
这些方法根据不同的图像形状和需求对图像进行调整和归一化处理
最后的__call__方法则是识别的入口,处理输入图像并返回识别结果TextDetector 类用于检测图像中的文本框
它在初始化时加载模型,并定义了图像预处理和后处理的方法,如 order_points_clockwise、clip_det-res 等,__call__方法是检测的入口,处理输入图像并返回检测结果
2.1.2 deepdoc/vision/recognizer.py
上述代码定义了一个名为 Recognizer 的类,该类用于处理图像识别任务。它包含多个静态方法和实例方法,用于对输入圈像进行预处理、排序、重登区域计算以及后处理。
首先,Recognizer 类的构造两数__init__初始化了模型的路径和 ONNX 推理会话。如果没有提供模型目录,它会尝试从 HuggingFace下载模型然后,它会根据设备类型(CPU 或 GPU)创建 ONNX 推理会话,并获取横型的输入和输出名称以及输入形状sort_Y_Firstly 和 sort_X_firstly 方法分别根据 top 和 x0 属性对输入数组进行排序,并在一定阔值内调整顺序
@staticmethod
def sort_Y_firstly(arr, threashold):
# sort using y1 first and then x1
arr = sorted(arr, key=lambda r: (r["top"], r["x0"]))
for i in range(len(arr) - 1):
for j in range(i, -1, -1):
# restore the order using th
if abs(arr[j + 1]["top"] - arr[j]["top"]) < threashold \
and arr[j + 1]["x0"] < arr[j]["x0"]:
tmp = deepcopy(arr[j])
arr[j] = deepcopy(arr[j + 1])
arr[j + 1] = deepcopy(tmp)
return arr sort_C_firstly和 sort_R_firstly 方法则在排序时考志了 C 和R 属性overlapped_area 方法计算两个矩形区域的重叠面积,并可以选择返回重叠面积的比例Layouts_cleanup 方法用于清理布局,删除重叠面积小于阈值的布局create_inputs 方法根据输入圈像和图像信息生成模型的输入。find_overlapped 和 find_horizontalLy-tightest_fit 方法用于查找与给定矩形重監或水平最紧密匹配的矩形preprocess 方法对输入图像进行预处理,包括调整图像大小、标准化和转置等操作。postprocess方法对模型输出进行后处理,过滤低置信度的检测结果,并应用非极大值抑制 (NMS) 来去除重疊的检测框最后,__call__方法是类的入口点,它接受一个图像列表,进行批量处理,并返回识别结果
2.2 ragflow-main/deepdoc/parser/pdf_parser.py
2.2.1 pdf_parser.py中对RAGFlowPdfParser类的实现——偏OCR
`RAGFlowPdfParser` 类提供了多种方法来处理 PDF 文件,特别是通过 OCR(光学字符识别)和布局识别来提取和处理文本和表格数据
以下是对几个关键函数的解释:
2.2.1.1 对字符宽度、高度的计算
首先,定义4个方法分别用于计算字符宽度、字符高度、以及两个对象之间的水平和垂直距离
1.__char_width(self, c)方法计算宇符的宽度
它通过减去字符的起始x坐标c["x0"]和结束x坐标 c["x1"] 来得到宇符的总宽度,然后除以字符文本的长度(至少为 1,以避免除以零的错误)
def __char_width(self, c):
return (c["x1"] - c["x0"]) // max(len(c["text"]), 1) 这种计算方式确保了即使宇符文本为空,宽度计算也不会出错
2.__height(self, c)方法计算对象的高度
它通过减去对象的顶部坐标c["top"]和底部坐标 c["bottom"]来得到对象的总高度。这种方法直接反映了对象在垂直方向上的跨度
def __height(self, c):
return c["bottom"] - c["top"] 3._x_dis(self, a, b)方法计算两个对象之间的水平距离
它通过计算三个值的最小值来实现:
def _x_dis(self, a, b):
return min(abs(a["x1"] - b["x0"]), abs(a["x0"] - b["x1"]),
abs(a["x0"] + a["x1"] - b["x0"] - b["x1"]) / 2) 第一个对象的结束x坐标与第二个对象的起始x 坐标之问的绝对差值
两个对象的起始x坐标与结束× 坐标之间的绝对差值
以及两个对象的中心点之间的水平距离的一半
4. _y_dis(self, a, b)方法计算两个对象之问的垂直距离
它通过计算两个对象的顶部和底部
坐标的平均值之间的差值来实现。这种方法确保了在不同情况下都能得到合理的垂直距离
def _y_dis(
self, a, b):
return (
b["top"] + b["bottom"] - a["top"] - a["bottom"]) / 2 _updown_concat_features方法用于计算两个文本块up和down之间的特征,这些特征将用于判断这两个文本块是否应该连接到一起
1. 宽度和高度计算
首先,方法计算了两个文本块的最大宽度和高度。w 是两个文本块中较大宽度的值,h 是较大高度的值
ef _updown_concat_features(self, up, down):
w = max(self.__char_width(up), self.__char_width(down))
h = max(self.__height(up), self.__height(down)) 2. 垂直距离计算:y_dis是两个文本块之问的垂直距离
y_dis = self._y_dis(up, down) 3. 文本分割:LEN 被设置为6,用手限制文本块的长度
tkS_down 和tks_up分别是down 和 u 文本块的前6个字符和后 6 个字符,经过raa_tokenizer 分词后的结果
LEN = 6
tks_down = rag_tokenizer.tokenize(down["text"][:LEN]).split(" ")
tks_up = rag_tokenizer.tokenize(up["text"][-LEN:]).split(" ")
tks_all = up["text"][-LEN:].strip() \
+ (" " if re.match(r"[a-zA-Z0-9]+",
up["text"][-1] + down["text"][0]) else "") \
+ down["text"][:LEN].strip()
tks_all = rag_tokenizer.tokenize(tks_all).split(" ") tks_all 是 up文本块的后6个字符和 down 文本块的前6个字符的组合,经过rag_tokenizer 分词后的结果
4.特征列表:fea 是一个包含多个布尔值和数值的列表,这些值表示了 u 和down 文本块之间的各种特征。例如:up和down的"R”属性是否相同。
。垂直距离与高度的比值
。页码差异
。布局类型是否相同
。文本块是否为 "text" 或"table" 类型
。文本块是否以特定字符结尾或开头
。文本块是否匹配特定的正则表达式模式
。文本块的x 坐标是否有重叠
。文本块的高度差异
。文本块的x坐标差异
。文本块的长度差异
。分词后的文本块长度差异
。文本块是否在同一行
5.返回特征:最后,方法返回计算sort_X_by_page
用于对一个包含字典的列表进行排序,每个字典代表一个页面元素,包含page_number、x_0、top等键
@staticmethod
def sort_X_by_page(arr, threashold):
# sort using y1 first and then x1
arr = sorted(arr, key=lambda r: (r["page_number"], r["x0"], r["top"]))
for i in range(len(arr) - 1):
for j in range(i, -1, -1):
# restore the order using th
if abs(arr[j + 1]["x0"] - arr[j]["x0"]) < threashold \
and arr[j + 1]["top"] < arr[j]["top"] \
and arr[j + 1]["page_number"] == arr[j]["page_number"]:
tmp = arr[j]
arr[j] = arr[j + 1]
arr[j + 1] = tmp
return arr 首先,函数使用sorted函数按page_number、x_0、top等键对列表进行初步排序,然后通过嵌套的for循环进一步调整顺序,以确保在同一页面上且x_0值相近的元素按top值从上到下排列
2.2.1.2 对表格的处理——_table_transformer_job
在pdf_parser.py 文件中,_table_transformer_job 方法负责处理 PDF 文档中的表格
该方法首先初始化一些变量,如imgs、pos和 tbent,并设置一个边距常量MARGIN
def _table_transformer_job(self, ZM):
logging.info("Table processing...")
imgs, pos = [], []
tbcnt = [0]
MARGIN = 10
self.tb_cpns = []
assert len(self.page_layout) == len(self.page_images) 然后,它遍历每一页的布局,筛选出类型为"table" 的元素,并计算这些表格的边界坐标
for p, tbls in enumerate(self.page_layout): # for page
tbls = [f for f in tbls if f["type"] == "table"]
tbcnt.append(len(tbls))
if not tbls:
continue
for tb in tbls: # for table
left, top, right, bott = tb["x0"] - MARGIN, tb["top"] - MARGIN, \
tb["x1"] + MARGIN, tb["bottom"] + MARGIN
left *= ZM
top *= ZM
right *= ZM
bott *= ZM
pos.append((left, top))
imgs.append(self.page_images[p].crop((left, top, right, bott))) 接着,它将这些坐标按比例缩放,并裁剪出相应的图像片段,存储在imgs 列表中
assert len(self.page_images) == len(tbcnt) - 1
if not imgs:
return
recos = self.tbl_det(imgs)
tbcnt = np.cumsum(tbcnt) 在处理完所有页面后,方法调用 self.tbL-detCimgs)对这些圈像进行表格检测,并将结果存储在recos 中
for i in range(len(tbcnt) - 1): # for page
pg = []
for j, tb_items in enumerate(
recos[tbcnt[i]: tbcnt[i + 1]]): # for table
poss = pos[tbcnt[i]: tbcnt[i + 1]] 接下来,方法通过累加tbcnt 来计算每页表格的数量,并遍历这些检测结果,将表格组件的坐标转换回原始比例,并调整它们在页面中的位置
for it in tb_items: # for table components
it["x0"] = (it["x0"] + poss[j][0])
it["x1"] = (it["x1"] + poss[j][0])
it["top"] = (it["top"] + poss[j][1])
it["bottom"] = (it["bottom"] + poss[j][1])
for n in ["x0", "x1", "top", "bottom"]:
it[n] /= ZM
it["top"] += self.page_cum_height[i]
it["bottom"] += self.page_cum_height[i]
it["pn"] = i
it["layoutno"] = j
pg.append(it)
self.tb_cpns.extend(pg) 最终,这些表格组件被添加到 self.tb_cpns 列表中此外,方法定义了一个内部函数gather,用于根据关键词筛选表格组件,并对这些组件进行排序和清理。然后,方法通过调用 gather 函数,获取表格中的标题、行、跨列单元格和列信息,井对这些信息进行进一步处理
def gather(kwd, fzy=10, ption=0.6):
eles = Recognizer.sort_Y_firstly(
[r for r in self.tb_cpns if re.match(kwd, r["label"])], fzy)
eles = Recognizer.layouts_cleanup(self.boxes, eles, 5, ption)
return Recognizer.sort_Y_firstly(eles, 0)
# add R,H,C,SP tag to boxes within table layout
headers = gather(r".*header$")
rows = gather(r".* (row|header)")
spans = gather(r".*spanning")
clmns = sorted([r for r in self.tb_cpns if re.match(
r"table column$", r["label"])], key=lambda x: (x["pn"], x["layoutno"], x["x0"]))
clmns = Recognizer.layouts_cleanup(self.boxes, clmns, 5, 0.5) 最后,方法遍历所有的盒子 (self.boxes),根据它们与表格组件的重盤情况,添加相应的标签,如"R"(行)、"H"(标题)、"C"(列)和"SP"(跨列单元格)
for b in self.boxes:
if b.get("layout_type", "") != "table":
continue
ii = Recognizer.find_overlapped_with_threashold(b, rows, thr=0.3)
if ii is not None:
b["R"] = ii
b["R_top"] = rows[ii]["top"]
b["R_bott"] = rows[ii]["bottom"]
ii = Recognizer.find_overlapped_with_threashold(
b, headers, thr=0.3)
if ii is not None:
b["H_top"] = headers[ii]["top"]
b["H_bott"] = headers[ii]["bottom"]
b["H_left"] = headers[ii]["x0"]
b["H_right"] = headers[ii]["x1"]
b["H"] = ii
ii = Recognizer.find_horizontally_tightest_fit(b, clmns)
if ii is not None:
b["C"] = ii
b["C_left"] = clmns[ii]["x0"]
b["C_right"] = clmns[ii]["x1"]
ii = Recognizer.find_overlapped_with_threashold(b, spans, thr=0.3)
if ii is not None:
b["H_top"] = spans[ii]["top"]
b["H_bott"] = spans[ii]["bottom"]
b["H_left"] = spans[ii]["x0"]
b["H_right"] = spans[ii]["x1"]
b["SP"] = ii
在其他文件中,如 book.py 、manual.py、naive.py、one.py 和 paper.py,--call-—方法都会调用_table_transformer_job方法来处理表格
这些文件中的 _cal1__方法通常会先进行 OCR 处理然后进行布局分析,接着调用_table_transformer_job方法进行表格分析最后进行文本合并和其他后续处理
这些方法的主要目的是从 PDF 文档中提取结构化信息,如表格、文本和图像,并將这些信息进行整理和输出
2.2.1.3 __ocr(self, pagenum, img, chars, ZM=3)
这个__ocr方法是一个私有方法,用于处理光学字符识别 (OCR) 任务。它接受四个参数:pagenum (页码)、img(图像)、chars(宇符)和一个可选参数 ZM (缩放因子,默认为3)
首先,该方法调用 self.ocr.detect 方法对图像进行检测,返回检测到的文本框(bxs)
如果没有检测到任何文本框,则在self.boxes 中添加一个空列表并返回
def __ocr(self, pagenum, img, chars, ZM=3):
bxs = self.ocr.detect(np.array(img))
if not bxs:
self.boxes.append([])
return 接下来,bxs 被处理成一个包含文本框坐标和文本内容的列表,并通过 Recognizer.sort_Y_firstly方法按 丫 坐标进行排序
bxs = [(line[0], line[1][0]) for line in bxs]
bxs = Recognizer.sort_Y_firstly(
[{"x0": b[0][0] / ZM, "x1": b[1][0] / ZM,
"top": b[0][1] / ZM, "text": "", "txt": t,
"bottom": b[-1][1] / ZM,
"page_number": pagenum} for b, t in bxs if b[0][0] <= b[1][0] and b[0][1] <= b[-1][1]],
self.mean_height[-1] / 3
) 排序后的文本框被标准化(除以 ZM)并存储在一个新的列表中然后,方法過历传入的宇符列表Chars,井再次使用 Recognizer.sort_Y_firstly 方法按 丫坐标排序。对于每个宇符,调用Recognizer.find_overlapped 方法查找与之重整的文本框
# merge chars in the same rect
for c in Recognizer.sort_Y_firstly(
chars, self.mean_height[pagenum - 1] // 4):
ii = Recognizer.find_overlapped(c, bxs) 如果没有找到重叠的文本框,则將宇符添加到 self. lefted_chars 列表中。否则,比较宇符高度和文本框高度,如果高度差异较大且字符不是空格,则将宇符添加到 self.lefted_chars 列表中
if ii is None:
self.lefted_chars.append(c)
continue
ch = c["bottom"] - c["top"]
bh = bxs[ii]["bottom"] - bxs[ii]["top"]
if abs(ch - bh) / max(ch, bh) >= 0.7 and c["text"] != ' ':
self.lefted_chars.append(c)
continue 如果字符是空格且文本框已有文本,则在文本框的文本未尾添加一个空格。否则,将字符的文本内容添加到文本框的文本中
if c["text"] == " " and bxs[ii]["text"]:
if re.match(r"[0-9a-zA-Z,.?;:!%%]", bxs[ii]["text"][-1]):
bxs[ii]["text"] += " "
else:
bxs[ii]["text"] += c["text"] 对于没有文本内容的文本框,方法会调用 self.ocr.recognize 方法对文本框区域进行 OCR 识别,并将识别结果赋值给文本框的 text屈性
接着,删除文本框的txt 属性,并过滤掉没有文本内容的文本框
for b in bxs:
if not b["text"]:
left, right, top, bott = b["x0"] * ZM, b["x1"] * \
ZM, b["top"] * ZM, b["bottom"] * ZM
b["text"] = self.ocr.recognize(np.array(img),
np.array([[left, top], [right, top], [right, bott], [left, bott]],
dtype=np.float32))
del b["txt"] 如果 self.mean_height 的最后一个元泰为 0,则计算所有文本框高度的中位数并赋值给 self.mean_height 的最后一个元素
bxs = [b for b in bxs if b["text"]]
if self.mean_height[-1] == 0:
self.mean_height[-1] = np.median([b["bottom"] - b["top"]
for b in bxs])
self.boxes.append(bxs) 最后,将处理后的文本框列表添加到 self.boxes 中
2.2.1.4 _text_merge:合井相邻的文本框
这个代码片段定义了一个名为 -text_merge 的方法,用于合并文本框。该方法主要用于处理 PDF 文档中的文本框,将相邻且布局相同的文本框合井成一个
首先,方法从 self.boxes 中获取所有的文本框,并定义了两个辅助函数end_with 和 start_with
def _text_merge(self):
# merge adjusted boxes
bxs = self.boxes
def end_with(b, txt):
txt = txt.strip()
tt = b.get("text", "").strip()
return tt and tt.find(txt) == len(tt) - len(txt)
def start_with(b, txts):
tt = b.get("text", "").strip()
return tt and any([tt.find(t.strip()) == 0 for t in txts]) end_with 函数用于检查文本框的文本是否以指定的宇符串结尾,而 start_with 函数用于检查文本框的文本是否以指定的宇符串开头接下来,方法进入一个while 循环,遍历所有的文本框。对于每一对相邻的文本框 b 和b_,如果它们的布局编号不同,或者它们的布局类型是"table"'、"figure” 或"equation",则跳过这些文本框,继续检查下一对
# horizontally merge adjacent box with the same layout
i = 0
while i < len(bxs) - 1:
b = bxs[i]
b_ = bxs[i + 1]
if b.get("layoutno", "0") != b_.get("layoutno", "1") or b.get("layout_type", "") in ["table", "figure",
"equation"]:
i += 1
continue 如果两个文本框的垂直距离小于某个國值(由 self.mean_height 决定),则将它们合并。合并操作包括更新 b 的x1、top和bottom 属性,并将 b_的文本追加到 b 的文本中
if abs(self._y_dis(b, b_)
) < self.mean_height[bxs[i]["page_number"] - 1] / 3:
# merge
bxs[i]["x1"] = b_["x1"]
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
bxs[i]["bottom"] = (b["bottom"] + b_["bottom"]) / 2
bxs[i]["text"] += b_["text"]
bxs.pop(i + 1)
continue
i += 1
continue 然后从列表中移除 b_1。如果两个文本框的布局类型不是“text"',则进一步检查它们的文本是否以特定宇符结尾或开头。如果满足条件,则调整合并的距离阅值 dis_thr
dis_thr = 1
dis = b["x1"] - b_["x0"]
if b.get("layout_type", "") != "text" or b_.get(
"layout_type", "") != "text":
if end_with(b, ",") or start_with(b_, "(,"):
dis_thr = -8
else:
i += 1
continue
if abs(self._y_dis(b, b_)) < self.mean_height[bxs[i]["page_number"] - 1] / 5 \
and dis >= dis_thr and b["x1"] < b_["x1"]:
# merge
bxs[i]["x1"] = b_["x1"]
bxs[i]["top"] = (b["top"] + b_["top"]) / 2
bxs[i]["bottom"] = (b["bottom"] + b_["bottom"]) / 2
bxs[i]["text"] += b_["text"]
bxs.pop(i + 1)
continue
i += 1 最后,方法更新 self.boxes,将合井后的文本框列表保存回去
self.boxes = bxs
上面是合并相邻的,还有垂直合并文本框的
_naive_ventical_merge 是一个用于垂直合并文本框的函数
首先,它调用 Recognizer.sort_Y_firstly 方法对 self.boxes进行排序,排序的依据是每个文本框的顶部坐标(top))和左边坐标(x0),并用 np.mediancse lf.mean_height)/3 作为阙值来调整排序顺序排序完成后,函数进入一个while 储环,遍历排序后的文本框列表 bxs
在循环中,函数首先检查当前文本框 6 和下一个文本框 b_是否在不同的页面上,井且 b的文本是否匹配特定的正则表达式模式
如果满足条件,函数会移除当前文 本框 b 并继续下一次香环
如果 b的文本为空,函数也会移除当前文本框井继续下一次循环接下来,函数定义了一个 concatting_feats列表,包含一些用于判断是否需要合并文本框的特征,例如 b 的文本是否以特定标点符号结尾,或者 b_ 的文本是否以特定标点符号开头
同时,函数还定义了一个 feats 列表.包含一些用于判断是否不需要合并文本框的特征,例如b 和b-的布局编号是否不同,b 的文本是否以句号或问号结尾等。此外,函数还定义了一个 detach_feats 列表,用于判断两个文本框是否应该分离,例如口 的右边坐标小于 b_的左边坐标,或者 6的左边坐标大于 b_的右边坐标。如果feats 列表中的任何一个特征为真且 concatting_feats 列表中的所有特征为假,或者detach_feats 列表中的任何一个特征为真,函数会打印一些调试信息井继续下一次循环如果没有触发上述条件,西数会将口 和 b_合井,更新 口 的底部坐标(bottom )、文本内容(text)、左边坐标(x0) 和右边坐标(x1),然后移除 b-。循环结束后,函数将更新后的文本框列表赋值给 self.boxes
2.2.1.5 _extract_table_figure
这个函数 Lextract_table_figure主要用手从文档中提取表格和圈形,并根据需要返回相应的图像和位置信息。函数接受四个参数:need_image 表示是否需要提取图像,ZM 是缩放比例return_html 表示是否返回HTML 格式的表格,need_position 表示是否需要返回位置信息
首先,函数初始化了两个字典 tables 和figures,分别用于存储表格和图形的信息
def _extract_table_figure(self, need_image, ZM,
return_html, need_position):
tables = {}
figures = {} 接着,通过遍历 self.boxes 来提取表格和图形的框。对于每个框,如果其类型是表格或图形,并且不包含特定的文本模式(如"数据来源”),则将其添加到相应的字典中,并从 self.boxes 中移除
# extract figure and table boxes
i = 0
lst_lout_no = ""
nomerge_lout_no = []
while i < len(self.boxes):
if "layoutno" not in self.boxes[i]:
i += 1
continue
lout_no = str(self.boxes[i]["page_number"]) + \
"-" + str(self.boxes[i]["layoutno"])
if TableStructureRecognizer.is_caption(self.boxes[i]) or self.boxes[i]["layout_type"] in ["table caption",
"title",
"figure caption",
"reference"]:
nomerge_lout_no.append(lst_lout_no)
if self.boxes[i]["layout_type"] == "table":
if re.match(r"(数据|资料|图表)*来源[:: ]", self.boxes[i]["text"]):
self.boxes.pop(i)
continue
if lout_no not in tables:
tables[lout_no] = []
tables[lout_no].append(self.boxes[i])
self.boxes.pop(i)
lst_lout_no = lout_no
continue
if need_image and self.boxes[i]["layout_type"] == "figure":
if re.match(r"(数据|资料|图表)*来源[:: ]", self.boxes[i]["text"]):
self.boxes.pop(i)
continue
if lout_no not in figures:
figures[lout_no] = []
figures[lout_no].append(self.boxes[i])
self.boxes.pop(i)
lst_lout_no = lout_no
continue
i += 1 在提取完表格和圈形框后,函数会尝试合井路页的表格。通过计算相邻表格框之间的垂直距离,如果距离小于某个阙值,则认为它们是同一个表格,并进行合井
# merge table on different pages
nomerge_lout_no = set(nomerge_lout_no)
tbls = sorted([(k, bxs) for k, bxs in tables.items()],
key=lambda x: (x[1][0]["top"], x[1][0]["x0"]))
i = len(tbls) - 1
while i - 1 >= 0:
k0, bxs0 = tbls[i - 1]
k, bxs = tbls[i]
i -= 1
if k0 in nomerge_lout_no:
continue
if bxs[0]["page_number"] == bxs0[0]["page_number"]:
continue
if bxs[0]["page_number"] - bxs0[0]["page_number"] > 1:
continue
mh = self.mean_height[bxs[0]["page_number"] - 1]
if self._y_dis(bxs0[-1], bxs[0]) > mh * 23:
continue
tables[k0].extend(tables[k])
del tables[k]
def x_overlapped(a, b):
return not any([a["x1"] < b["x0"], a["x0"] > b["x1"]]) 接下来,函数会查找井提取表格和图形的标题。通过计算标题框与表格或圈形框之问的距离,找到最近的表格或图形,井将标题框插入到相应的位置随后,函数定义了一个内部函数 cropout,用于裁剪图像并返回裁剪后的圈像和位置信息。对于每个表格和图形,函数会调用cropout 来生成最终的图像,并将其与相应的文本或表格数据一起存储在res 列表中。如果需要位置信息,则返回包含图像和位置信息的列表;否则,仅返回图像列表
2.2.2 pdf_parser.py中对PlainParser类的实现——偏文本解析器
PlainParser 类的主要功能是解析 PDF文件并提取文本和大纲信息。它实现了--call--方法,使得类实例可以像函数一样被调用。该方法接受一个文件名(或文件内容的字节流)、起始页码和结束页码,并返回提取的文本行和一个空列表
在-call--方法中,首先初始化了self.outlines 和lines 两个列表。然后,通过 pdf2_read 函数读取 PDF 文件。如果 Filename 是宇符串类型,则直接读取文件;否则,将其视为字节流井使用BytesIo 进行处理
class PlainParser(object):
def __call__(self, filename, from_page=0, to_page=100000, **kwargs):
self.outlines = []
lines = []
try:
self.pdf = pdf2_read(
filename if isinstance(
filename, str) else BytesIO(filename)) 接着,遍历指定页码范围内的每一页,提取文本并按行分割,存入Lines 列表中。对于大纲信息,使用了一个深度优先搜索(DFS) 算法来遍历大纲树结构。dfs 函数递归地处理大纲条目,如果条目是字典类型,则将其标题和深度添加到self.outlines 中;否则,继续递归处理子条目
for page in self.pdf.pages[from_page:to_page]:
lines.extend([t for t in page.extract_text().split("\n")])
outlines = self.pdf.outline
def dfs(arr, depth):
for a in arr:
if isinstance(a, dict):
self.outlines.append((a["/Title"], depth))
continue
dfs(a, depth + 1)
dfs(outlines, 0) 在处理过程中,如果发生任何异常,都会记录營告日志。最后,如果没有提取到大纲信息,也会记录相应的警告。该方法返回提取的文本行和一个空列表
except Exception as e:
logging.warning(f"Outlines exception: {e}")
if not self.outlines:
logging.warning(f"Miss outlines")
return [(l, "") for l in lines], [] 此外,PlainParser 类还定义了两个未实现的方法:crop 和 remove_tag。 crop方法用于裁剪文本,remove_tag 方法用于移除文本中的标签。这两个方法目前都拋NotImplementedError 异常,表示尚未实现
第三部分 对ragflow-main/rag的拆解
3.1 ragflow-main/rag/app
3.1.1 app/paper.py中pdf(侧重OCR方法)、chunk(侧重文本解析器)的实现
在 paper.py 文件中,主要就两个主要实现
一个pdf的类——即class Pdf(PdfParser),侧重用OCR的方法一个chunk函数——详见上文2.2.2 pdf_parser.py中对PlainParser类的实现
对于前者class Pdf(PdfParser),call_方法是一个主要的入口点,用于处理OCR(光学字符识别) 和布局分析
该方法首先调用 callback 函数通知OCR 开始,然后调用self.--images__方法处理图像
<code> def __call__(self, filename, binary=None, from_page=0,
to_page=100000, zoomin=3, callback=None):
callback(msg="OCR is running...")code>
self.__images__(
filename if not binary else binary,
zoomin,
from_page,
to_page,
callback
)
callback(msg="OCR finished.")code> 接下来,使用timer 记录布局分析的时问,并调用_layouts_rec方法进行布局分析
from timeit import default_timer as timer
start = timer()
self._layouts_rec(zoomin)
callback(0.63, "Layout analysis finished")
print("layouts:", timer() - start) 随后,调用_table_transformer_job 方法处理表格(其具体实现,详见2.2.1 pdf_parser.py中对RAGFlowPdfParser类的实现——偏OCR中2.2.1.2 对表格的处理——_table_transformer_job)
并调用 _text_merge 方法合井文本(其具体实现,详见2.2.1 pdf_parser.py中对RAGFlowPdfParser类的实现——偏OCR中2.2.1.4 _text_merge:合井相邻的文本框)
self._table_transformer_job(zoomin)
callback(0.68, "Table analysis finished")
self._text_merge() 在处理完文本合井后,代码调用_extract_table_figure 方法提取表格和图形(其具体实现,详见2.2.1 pdf_parser.py中对RAGFlowPdfParser类的实现——偏OCR中2.2.1.5 _extract_table_figure),并计算列宽度
tbls = self._extract_table_figure(True, zoomin, True, True)
column_width = np.median([b["x1"] - b["x0"] for b in self.boxes])
self._concat_downward()
self._filter_forpages()
callback(0.75, "Text merging finished.") 如果列宽度小于页面宽度的一半,则调用sort_X_by_page 方法对self.boxes 进行排序
# clean mess
if column_width < self.page_images[0].size[0] / zoomin / 2:
print("two_column...................", column_width,
self.page_images[0].size[0] / zoomin / 2)
self.boxes = self.sort_X_by_page(self.boxes, column_width / 2) 排序完成后,代码对每个 box 的文本进行清理,去除多余的空格和制表符
for b in self.boxes:
b["text"] = re.sub(r"([\t ]|\u3000){2,}", " ", b["text"].strip()) 接下来,代码定义了一个 _begin函数,用于匹配文本是否包含特定的关键词
def _begin(txt):
return re.match(
"[0-9. 一、i]*(introduction|abstract|摘要|引言|keywords|key words|关键词|background|背景|目录|前言|contents)",
txt.lower().strip()) 如果from_page大于0,则返回包含标题、作者、摘要、章节和表格的字典
if from_page > 0:
return {
"title": "",
"authors": "",
"abstract": "",
"sections": [(b["text"] + self._line_tag(b, zoomin), b.get("layoutno", "")) for b in self.boxes if
re.match(r"(text|title)", b.get("layoutno", "text"))],
"tables": tbls
} 否则,代码继续提取标题和作者信息,并在 self.boxes中查找包含"abstract" 或 "摘要"的文本作为摘要最后,代码调用 cal1back 函数通知文本合并完成,并打印每个 box 的文本和布局编号最终返回一个包含标题、作者、摘要、章节和表格的宇典
对于后者def chunk,这个函数chunk 主要用于处理PDF 文件,将其内容分块并进行标记化处理,函数接受多个参数,包括文件名、二进制数据、起始页和结束页、语言、回调西数等
函数首先检查文件名是否以.pdf 结尾,如果是,则根据 parser_config 的配置选择不同的PDF 解析器
要么PlainParser,这个函数的实现在deepdoc/parser/pdf_parser.py中,侧重用文本解析器的方法
要么Pdf,这个函数就是上面实现的pdf类,侧重用OCR的方法
<code>def chunk(filename, binary=None, from_page=0, to_page=100000,
lang="Chinese", callback=None, **kwargs):code>
"""
Only pdf is supported.
The abstract of the paper will be sliced as an entire chunk, and will not be sliced partly.
"""
pdf_parser = None
if re.search(r"\.pdf$", filename, re.IGNORECASE):
if not kwargs.get("parser_config", {}).get("layout_recognize", True):
pdf_parser = PlainParser()
paper = {
"title": filename,
"authors": " ",
"abstract": "",
"sections": pdf_parser(filename if not binary else binary, from_page=from_page, to_page=to_page)[0],
"tables": []
}
else:
pdf_parser = Pdf()
paper = pdf_parser(filename if not binary else binary,
from_page=from_page, to_page=to_page, callback=callback)
else:
raise NotImplementedError("file type not supported yet(pdf supported)") 如果文件类型不支持,则抛出NotImplementedError 异常在解析 PDF 文件后,函数会创建一个包含文档名称和作者信息的字典 doc,并对这些信息进行标记化处理接着,函数会调用tokenize_table 对表格内容进行标记化处理。如果论文包含摘要,函数会对摘要进行特殊处理,包括去除标签、 添加重要关键词和位置标记等函数还会对论文的各个部分进行排序和分块处理,通过计算标题的频率来确定分块的边界最后,函数将这些分块内容进行标记化处理,并返回处理后的结果
3.1.2 app/qa.py
3.1.3 app/table.py
// 待更
3.2 ragflow-main/rag/llm
3.2.1 llm/embedding_model.py
OpenAIEmbed 类继承自 Base 抽象基类,并实现了两个方法:encode 和 encode_queries
在初始化方法 -init-_中,类接受三个参数:key、 model-name 和 base_url。key 是用于认证的 AP1 密钥,model-name 默认为 "text-embedding-ada-002", base-url 默认为"https://api.openai.com/v1"
class OpenAIEmbed(Base):
def __init__(self, key, model_name="text-embedding-ada-002",code>
base_url="https://api.openai.com/v1"):code> 如果没有提供 base_url,则使用默认值。然后,使用这些参数创建一个OpenAI 客户端实例,并将其存储在 self.client 中,同时将模型名称存储在self.model_name中
if not base_url:
base_url = "https://api.openai.com/v1"
self.client = OpenAI(api_key=key, base_url=base_url)
self.model_name = model_name encode 方法接受一个文本列表texts 和一个可选的批处理大小 batch_size
首先,它会将每个文本截断到最大长度 8196 字符,然后调用 self.client.embeddings.create 方法生成嵌入
def encode(self, texts: list, batch_size=32):
texts = [truncate(t, 8196) for t in texts]
res = self.client.embeddings.create(input=texts,
model=self.model_name)
return np.array([d.embedding for d in res.data]
), res.usage.total_tokens 返回值是一个包含嵌入向量的 NumPy 数组和使用的总 token数
当然,还可以用其他的embedding模型
3.2.2 llm/rerank_model.py
DefaultRerank 类继承自 Base 类,并实现了一个用于重新排序的模型
该类使用了类变量 -model 和-model-1ock 来确保模型的单例模式,即在整个应用程序生命周期中只加载一次榄型
class DefaultRerank(Base):
_model = None
_model_lock = threading.Lock()
枸造函数--init-1接受 key 和 model-name 作为参数,并通过检查Lmodel 是否为 None 来决定是否需要加载模型
加载模型时,首先尝试从本地缓存目录加载,如果失败,则从远程仓库下载模型在模型加载过程中,使用了 threading. Lock 来确保线程安全,避免多线程环境下重复加载模型。横型加载成功后,赋值给类变量_model,并在实例变量 self._model 中引用
该模型similarity 方法用于计算查询文本与一组文本之间的相似度
首先,将查询文本与每个文本配对,并截断文本长度以确保不超过 2048 个字符
def similarity(self, query: str, texts: list):
pairs = [(query,truncate(t, 2048)) for t in texts]
token_count = 0 然后,计算所有文本的总 token数
for _, t in pairs:
token_count += num_tokens_from_string(t) 接下来,按批次处理文本对,每批次大小为 4096。调用模型的 compute_score 方法计算相似度分数,并使用 sigmoid 西数将分数转换为概率值
batch_size = 4096
res = []
for i in range(0, len(pairs), batch_size):
scores = self._model.compute_score(pairs[i:i + batch_size], max_length=2048)
scores = sigmoid(np.array(scores)).tolist()
if isinstance(scores, float): res.append(scores)
else: res.extend(scores)
return np.array(res), token_count 最后,返回相似度分数数组和总 token 数
3.3 ragflow-main/rag/nlp
这个类主要用于处理Elasticsearch 相关的查询和数据处理
以下是对几个关键函数的详细解释:
index_name Cuid):这个西数接受一个用户 D(uid),并返回一个宇符串,格式为ragflow_tuids
def index_name(uid): return f"ragflow_{uid}" _vector(self, txt, emb_mdl, sim=0.8, topk=10):这个方法用于生成查询向量
它接受文本(txt)、嵌入模型(emb_mdl)、相似度(sim) 和返回結果的数量(topk)作为参数
def _vector(self, txt, emb_mdl, sim=0.8, topk=10):
qv, c = emb_mdl.encode_queries(txt)
return {
"field": "q_%d_vec" % len(qv),
"k": topk,
"similarity": sim,
"num_candidates": topk * 2,
"query_vector": [float(v) for v in qv]
} 方法内部调用嵌入模型的 encode_queries 方法生成查询向量,并返回一个包含查询向量和其他参数的字典_add_filters(self, bqry, req):这个方法用于向基本查询(bqry) 添加过滤条件
它根据清求(req) 中的不同字段(如 kb_ids、doc_ids、knowledge_graph_kwd等)添加相应的过滤条件。最后返回修改后的查询对象
更多,详见《大模型项目开发线上营 第二期》
参考文献与推荐阅读
端到端 RAG 解决方案 RAGFlow 正式开源
通用文档理解新SOTA,多模态大模型TextMonkey来了
阿里7B多模态文档理解大模型拿下新SOTA|开源...
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。