【数据结构】初识数据结构之复杂度与链表
大白的编程日记. 2024-07-10 16:35:05 阅读 71
【数据结构】初识数据结构之复杂度与链表

🔥个人主页:大白的编程日记
🔥专栏:C语言学习之路
文章目录
【数据结构】初识数据结构之复杂度与链表前言一.数据结构和算法1.1数据结构1.2算法1.3数据结构和算法的重要性
二.时间与空间复杂度2.1算法效率2.2算法的复杂度2.3时间复杂度的概念2.4大O的渐进表示法2.5时间复杂度计算举例
三.空间复杂度四.链表4.1链表的概念及结构4.2链表的分类4.3单链表的实现
后言
前言
哈喽,各位小伙伴大家好!今天我们开启全新的篇章,数据结构。简单来说数据结构就是数据在内存中的管理。今天给大家带来的是数据结构中的复杂度和链表的知识。话不多说,咱们进入正题!向大厂冲锋!

一.数据结构和算法
1.1数据结构
数据结构(Data Structure)是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的 数据元素的集合。
1.2算法
算法(Algorithm):就是定义良好的计算过程,他取一个或一组的值为输入,并产生出一个或一组值作为
输出。简单来说算法就是一系列的计算步骤,用来将输入数据转化成输出结果。
1.3数据结构和算法的重要性
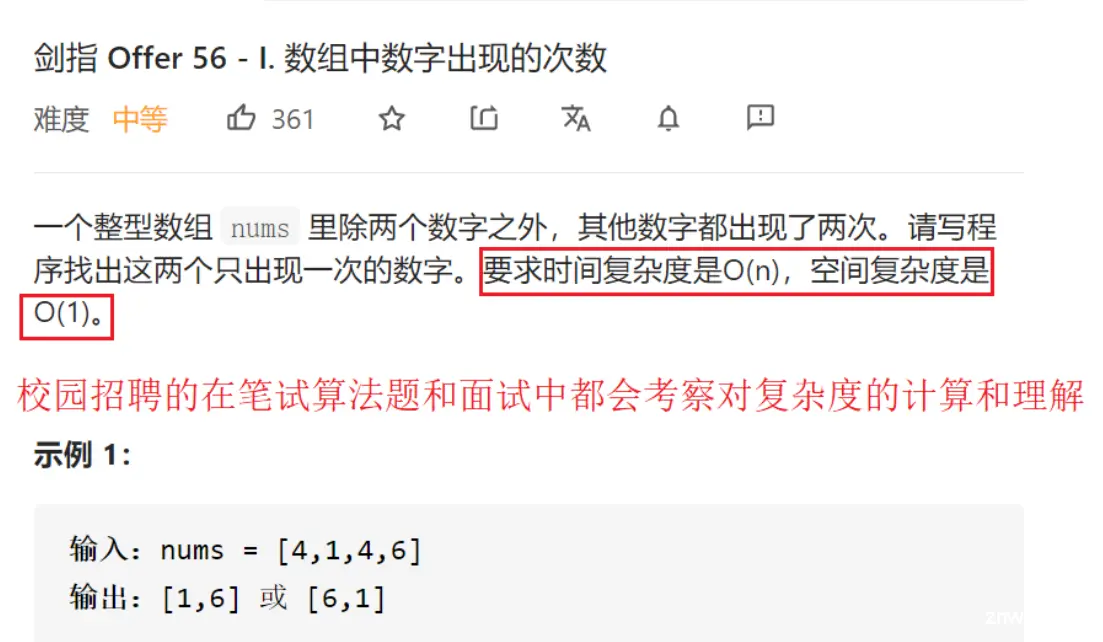
目前校园招聘笔试一般采用Online Judge形式, 一般都是20-30道选择题+2道编程题,或者3-4道编程题。
2020奇安信秋招C/C++
美团2021校招笔试
网易2021校招笔试C++开发工程师
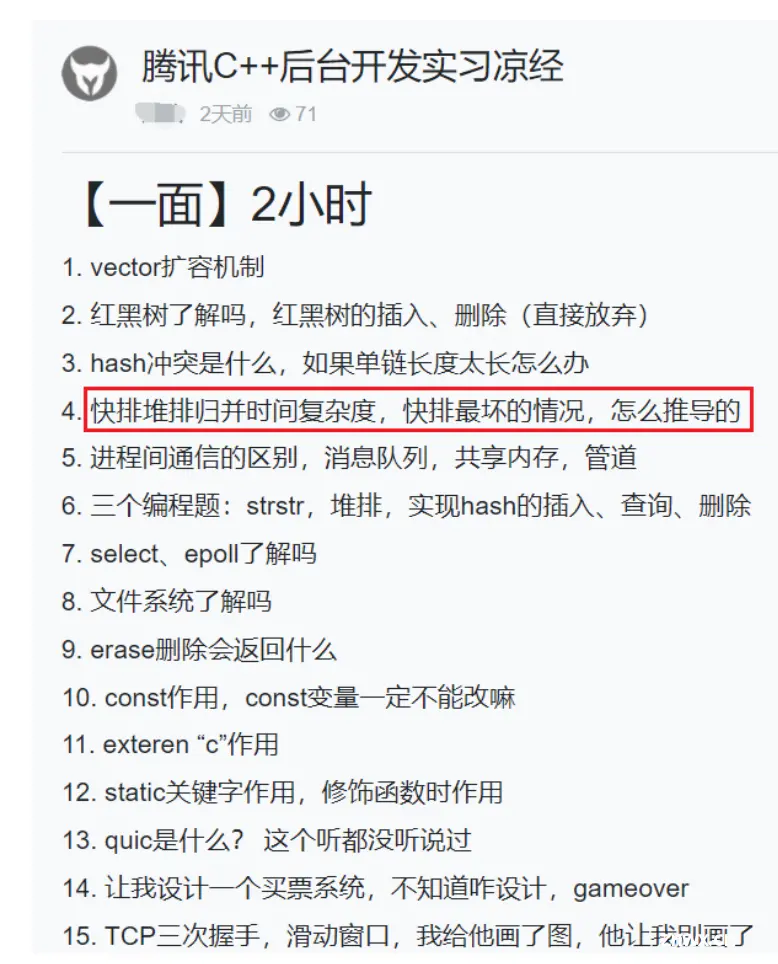
可以看出,现在公司对学生代码能力的要求是越来越高了,大厂笔试中几乎全是算法题而且难度大,中小长的笔试中才会有算法题。算法不仅笔试中考察,面试中面试官基本都会让现场写代码。而算法能力短期内无法快速提高了,至少需要持续半年以上算法训练积累,否则真正校招时笔试会很艰难,因此算法要早早准备。
二.时间与空间复杂度
2.1算法效率
如何衡量一个算法的好坏呢?比如对于以下斐波那契数列:
<code>long long Fib(int N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}
斐波那契数列的递归实现方式非常简洁,但简洁一定好吗?那该如何衡量其好与坏呢?这就涉及到算法的复杂度了。
2.2算法的复杂度
复杂度分为空间复杂度和时间复杂度。算法在编写成可执行程序后,运行时需要耗费时间资源和空间(内存)资源 。
因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的,即时间复杂度和空间复杂度。
时间复杂度
时间复杂度主要衡量一个算法的运行快慢
空间复杂度
空间复杂度主要衡量一个算法运行所需要的额外空间。
在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。所以我们现在更关注算法的时间复杂度。
复杂度在校招中的考察
2.3时间复杂度的概念
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。一
个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知道。但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
运行时间衡量
为啥不用运行时间衡量。因为算法运行的环境不同,跑出来的时间性能自然不同。我的电脑性能更好,相同因素下,表现的性能自然更好,但是我们衡量的是代码本身。
即:找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度。
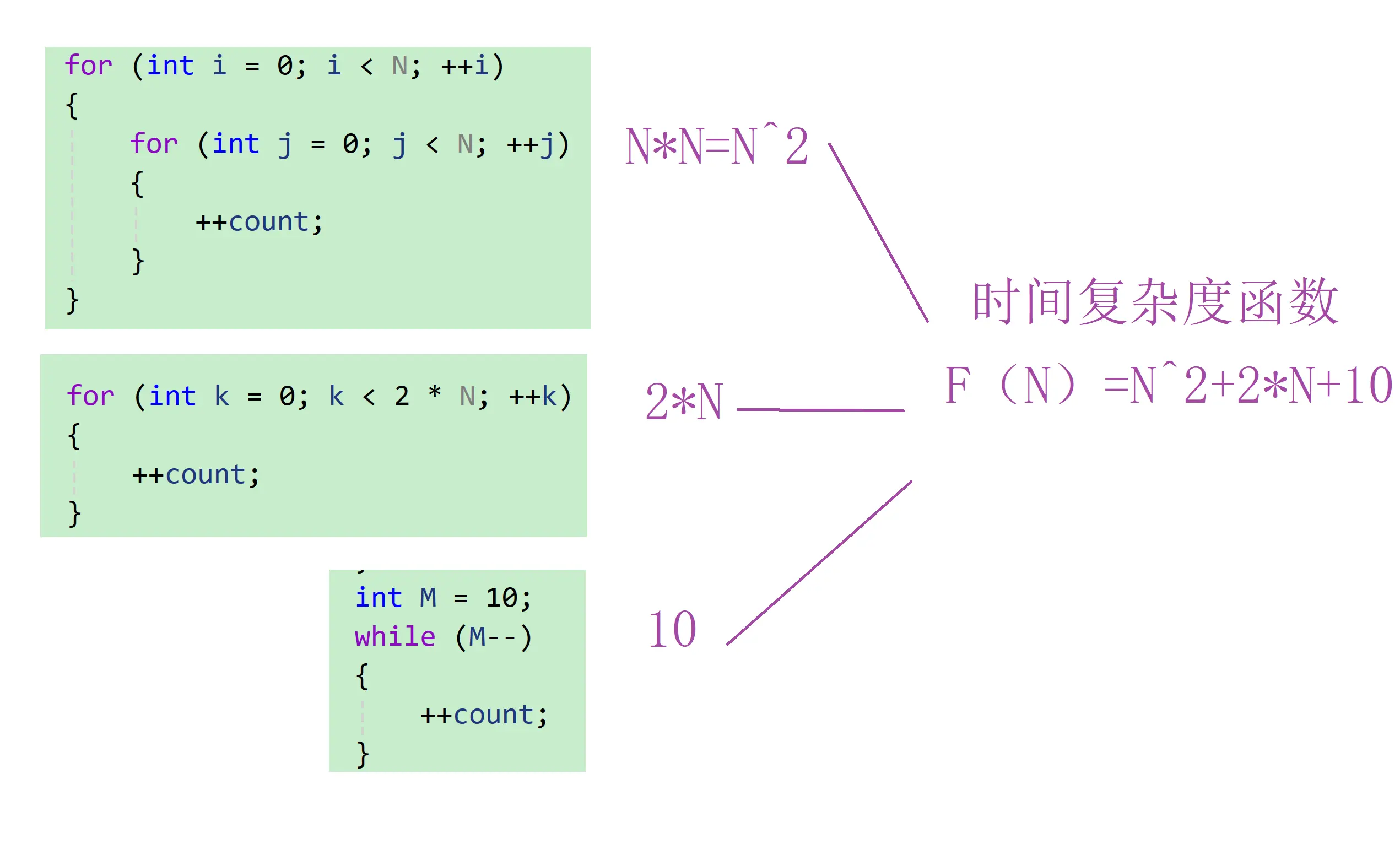
<code>// 请计算一下Func1中++count语句总共执行了多少次?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N ; ++ i)
{
for (int j = 0; j < N ; ++ j)
{
++count;
}
}
for (int k = 0; k < 2 * N ; ++ k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
我们计算出来的函数就是:

那如果现在我们要比较这三个算法的优略,该怎么比呢?
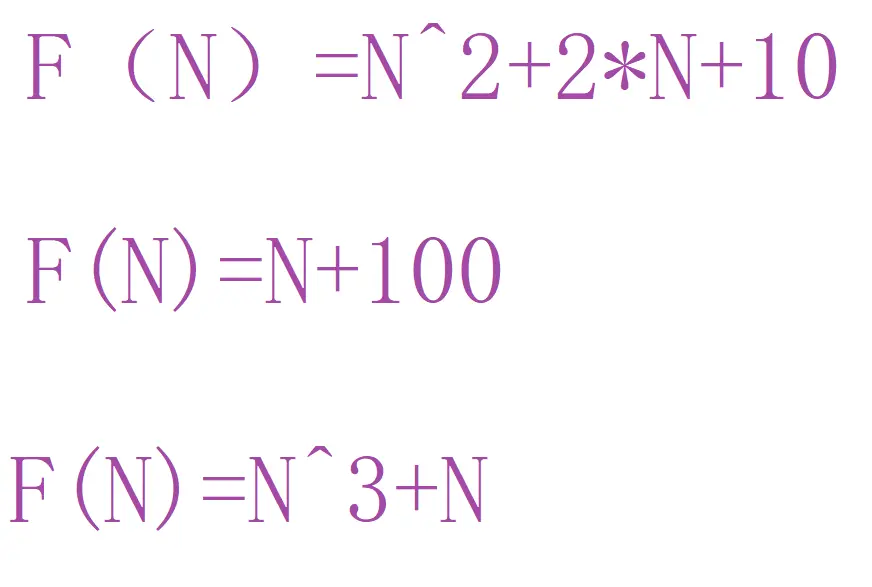
大家发现其实不太好比较,因为除了N可能还有一些系数和常数。那咋办呢? 这时就可以用我们的大O的渐进表示法进行函数简化。
2.4大O的渐进表示法
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
推导大O阶方法:
用常数1取代运行时间中的所有加法常数。
我们想对函数进行大概的估算,那我们就需要保留影响最大的项,所以我们对常数项进行忽略。因为当N很大时,常数项对整个函数式结果的影响不大。
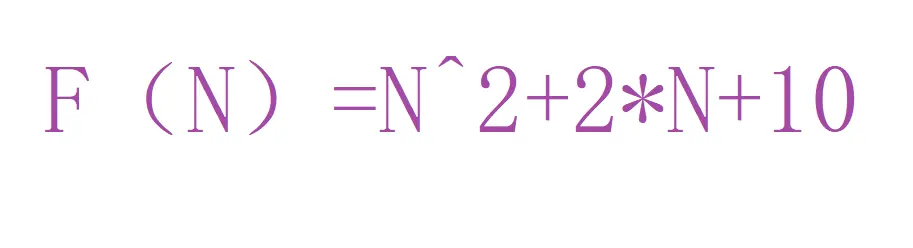
可是当N很小时,常数项的影响反而时更大的。
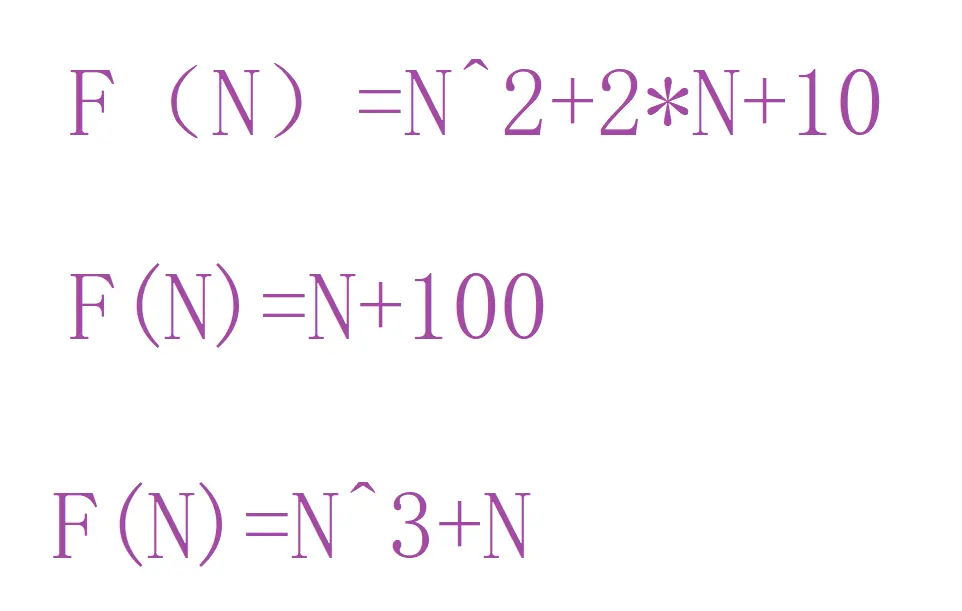
但是当N很小时,我们认为这三个的性能时一样的,因为CPU的运算速度太快了。每秒至少在上亿次。所以当 N很小时,我们认为他们的性能都一样,所以我们只关注影响最大的一项。忽略常数项。
验证:
clock函数可以捕捉程序启动到某处执行的时间,单位时毫秒。
<code>#include<stdio.h>
#include<time.h>
int main()
{
int sum = 0;
int begin = clock();//程序启动开始执行到这里的时间,单位时毫秒
for (int i = 0; i < 100000000; i++)
{
sum++;
}
int end = clock();
printf("%d time:%d", sum,end-begin);
}
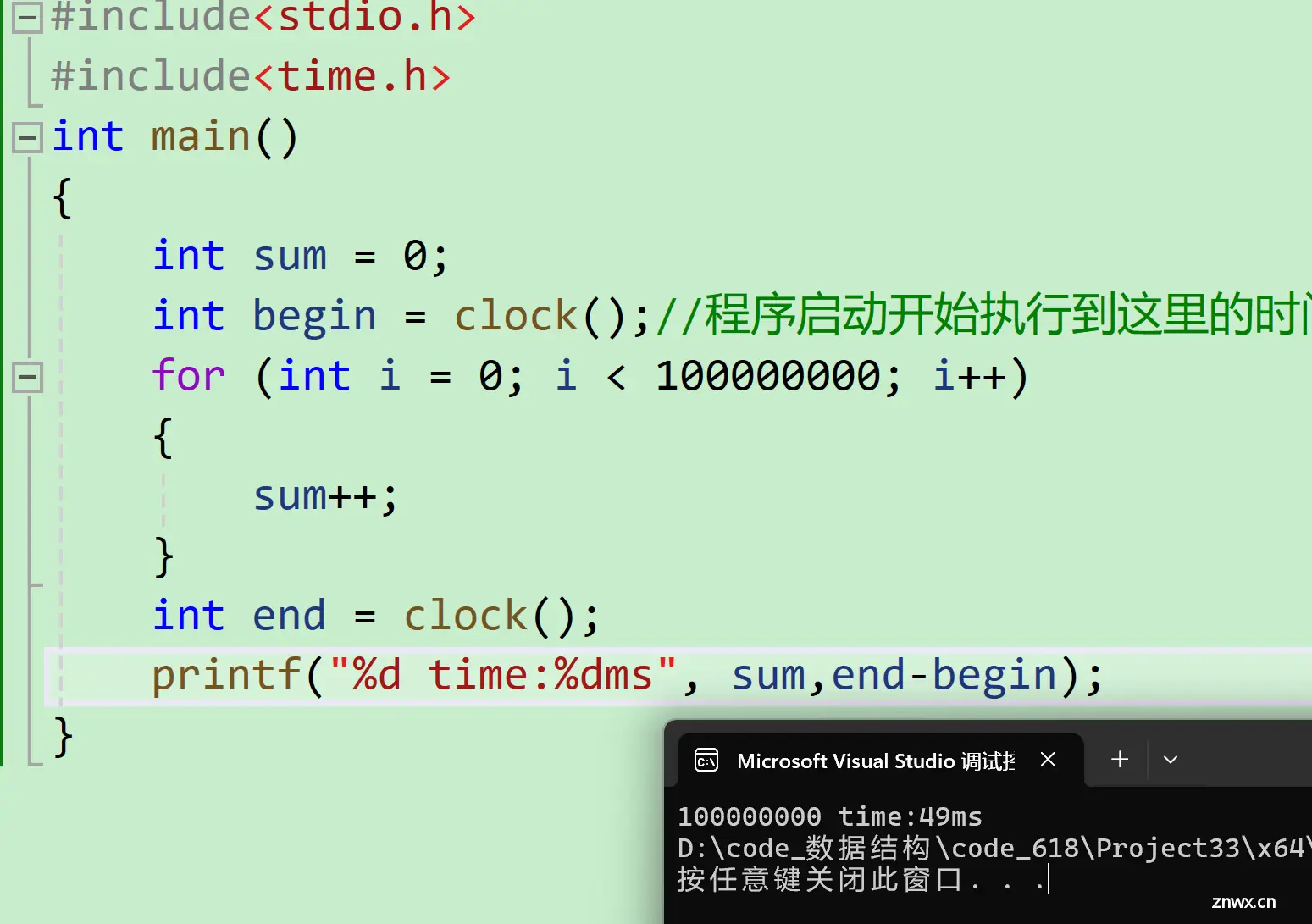
大家发现我们循环一亿次只用了40ms。
在修改后的运行次数函数中,只保留最高阶项。
忽略常数项后,我们只保留最高阶的项,也就是影响最大的项。
如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
因为当N趋向于无穷大的时候,系数可以忽略。我们只关注N很大的情况,N很小的时候没有意义,因为CUP运算速度太快了。可以理解为无穷的倍数还是无穷大。
通过上面我们会发现大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
另外有些算法的时间复杂度存在最好、平均和最坏情况:
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界)
在一个长度为N数组中搜索一个数据x
最好情况:1次找到
最坏情况:N次找到
平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)
2.5时间复杂度计算举例
题目一
<code>// 计算Func3的时间复杂度?
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++ k)
{
++count;
}
for (int k = 0; k < N ; ++ k)
{
++count;
}
printf("%d\n", count);
}
这里我们看两个循环分别是N和M次,所以用大O的渐进表示法就是O(N+M).如果一个远远小于另外一个未知数,可以忽略掉。
题目二:
// 计算Func4的时间复杂度?
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++ k)
{
++count;
}
printf("%d\n", count);
}
基本操作执行了10次,通过推导大O阶方法,时间复杂度为 O(1)。注意O(1)不是代表一次,代表常数次。
题目三:
// 计算BubbleSort的时间复杂度?
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
Swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
这里我们要分最好情况和最坏情况看:

最好遍历一遍,最坏遍历n-1遍。而我们只关注最坏情况,所以就是(n-1)*n/2。再用大O的渐进表示法即可。
题目四:
<code>// 计算BinarySearch的时间复杂度?
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n - 1;
// [begin, end]:begin和end是左闭右闭区间,因此有=号
while (begin <= end)
{
int mid = begin + ((end - begin) >> 1);
if (a[mid] < x)
begin = mid + 1;
else if (a[mid] > x)
end = mid - 1;
else
return mid;
}
return -1;
}

三.空间复杂度
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 。
空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。
空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定。
空间复杂度练习:
题目一:
<code>// 计算BubbleSort的空间复杂度?
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}

使用了常数个额外空间,所以空间复杂度为 O(1)
题目二:
<code>// 计算Fibonacci的空间复杂度?
// 返回斐波那契数列的前n项
long long* Fibonacci(size_t n)
{
if (n == 0)
return NULL;
long long* fibArray = (long long*)malloc((n + 1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray[i - 2];
}
return fibArray;
}
动态开辟了N个空间,空间复杂度为 O(N)
题目三:
// 计算阶乘递归Fac的空间复杂度?
long long Fac(size_t N)
{
if(N == 0)
return 1;
return Fac(N-1)*N;
}
递归调用了N次,开辟了N个栈帧,每个栈帧使用了常数个空间。空间复杂度为O(N)
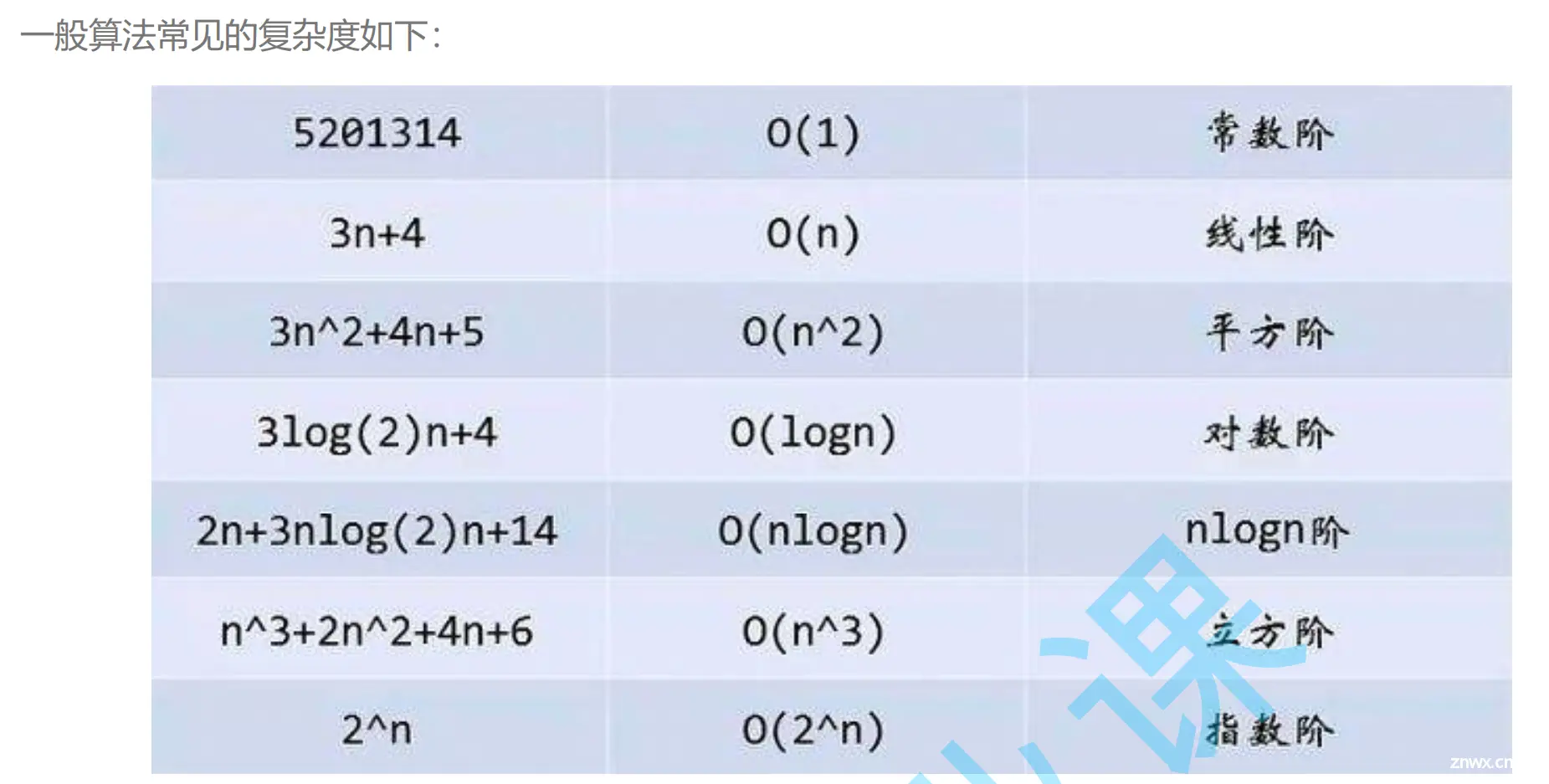
常见复杂度对比:
四.链表
4.1链表的概念及结构
概念:链表是⼀种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
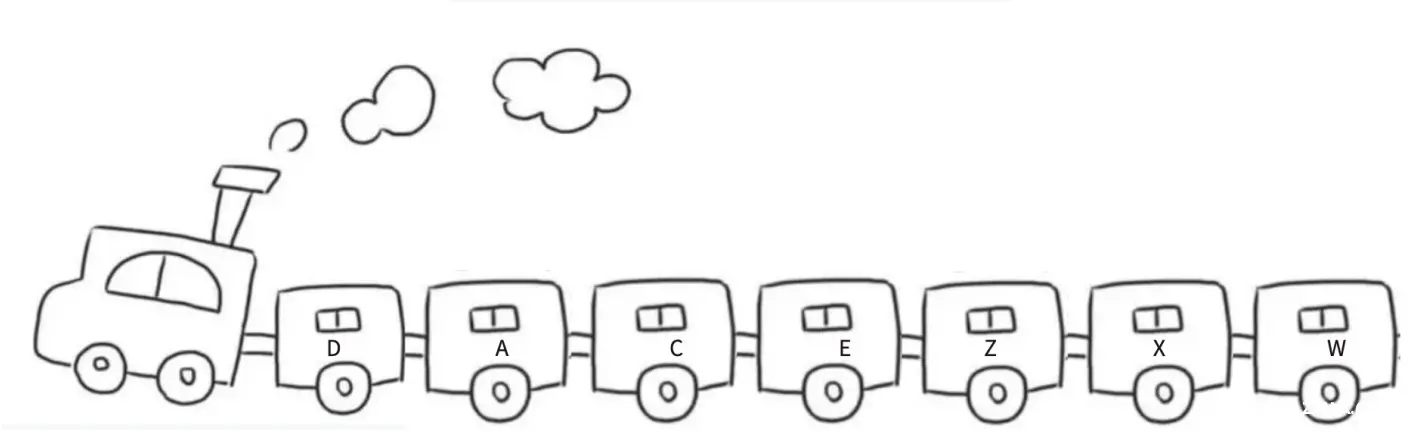
链表的结构跟火车车厢相似,淡季时车次的车厢会相应减少,旺季时车次的车厢会额外增加⼏节。只需要将火车里的某节车厢去掉/加上,不会影响其他车厢,每节车厢都是独力存在的。
车厢是独立存在的,且每节车厢都有车门。想象⼀下这样的场景,假设每节⻋厢的车门都是锁上的状态,需要不同的钥匙才能解锁,每次只能携带⼀把钥匙的情况下如何从车头走到车尾?
最简单的做法:每节车厢里都放⼀把下⼀节车厢的钥匙。
在链表里,每节“车厢”是什么样的呢?
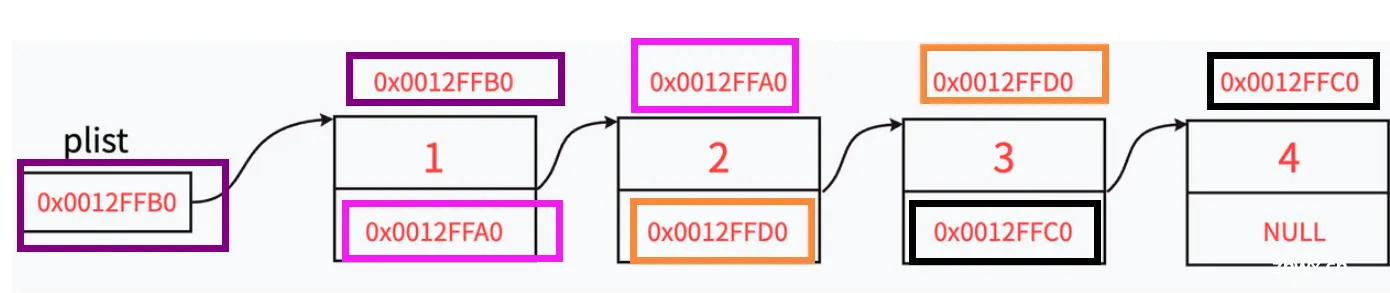
与顺序表不同的是,链表里的每节"车厢"都是独立申请下来的空间,我们称之为“结点/节点”节点的组成主要有两个部分:当前节点要保存的数据和保存下⼀个节点的地址(指针变量)。图中指针变量 plist保存的是第⼀个节点的地址,我们称plist此时“指向”第⼀个节点,如果我们希望plist“指向”第二个节点时,只需要修改plist保存的内容为0x0012FFA0。
为什么还需要指针变量来保存下⼀个节点的位置?
链表中每个节点都是独立申请的(即需要插入数据时才去申请⼀块节点的空间),我们需要通过指针变量来保存下⼀个节点位置才能从当前节点找到下⼀个节点。
结合前面学到的结构体知识,我们可以给出每个节点对应的结构体代码:
<code>struct SListNode
{
int data; //节点数据假设当前保存的节点为整型:
struct SListNode* next; //指针变量⽤保存下⼀个节点的地址
};
当我们想要保存⼀个整型数据时,实际是向操作系统申请了⼀块内存,这个内存不仅要保存整型数据,也需要保存下⼀个节点的地址(当下⼀个节点为空时保存的地址为空)。
当我们想要从第⼀个节点⾛到最后⼀个节点时,只需要在前⼀个节点拿上下⼀个节点的地址(下⼀个节点的钥匙)就可以了。这就是链表的遍历。
链表在逻辑上是连续的,在物理结构上不⼀定连续节点⼀般是从堆上申请的,动态开辟的。从堆上申请来的空间,是按照⼀定策略分配出来的,每次申请的空间可能连续,可能不连续哨兵位节点
哨兵位时一个链表的节点,但是这个链表什么也不用做,相当于一个放哨的,可以方便我们头插。
4.2链表的分类
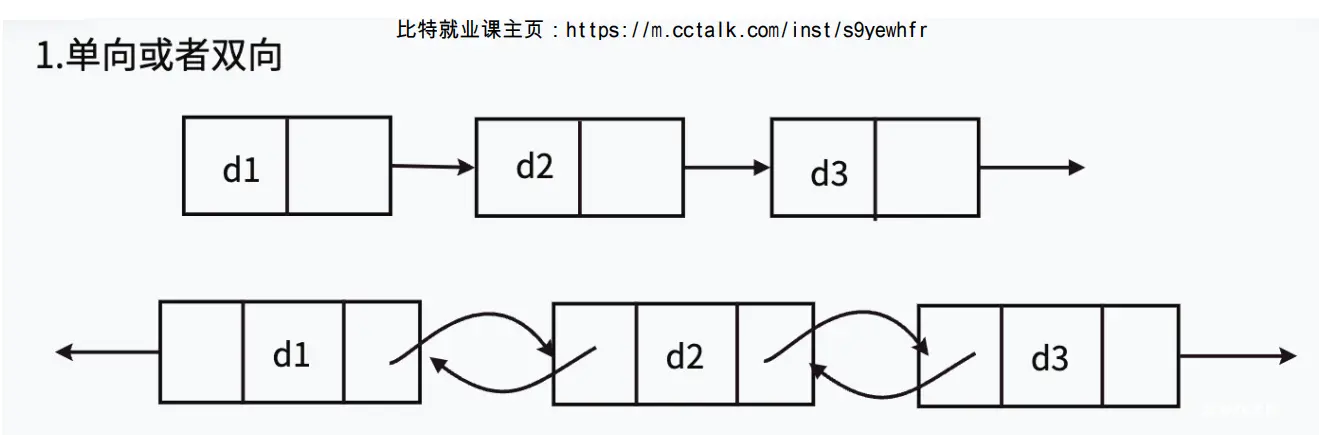
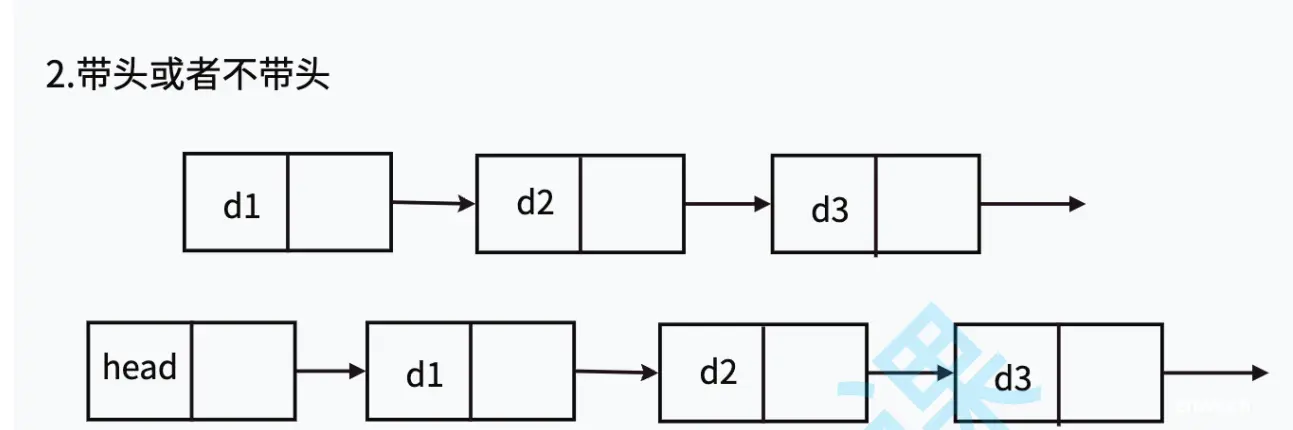
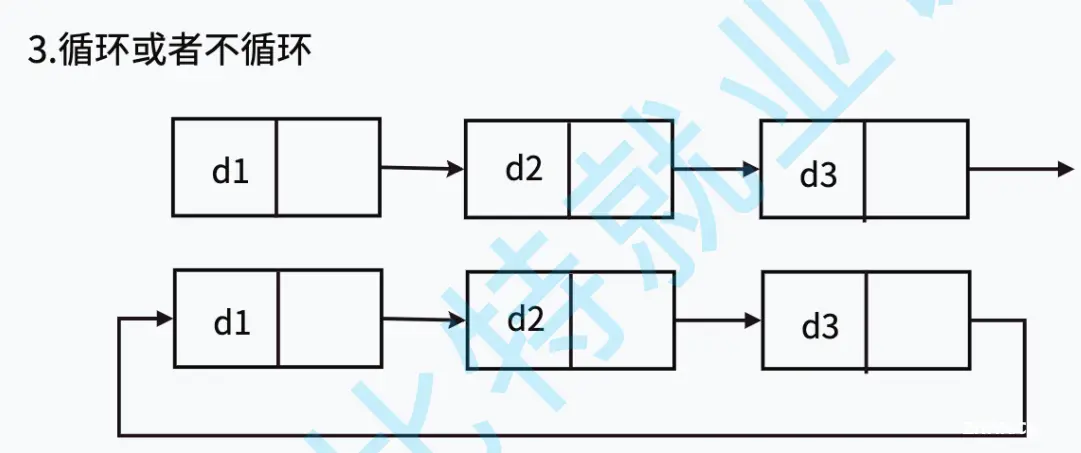
链表的结构非常多样,以下情况组合起来就有8种(2 x 2 x 2)链表结构:

单向或双向
带头或不带头
循环不循环
虽然有这么多的链表的结构,但是我们实际中最常⽤还是两种结构:
单链表和双向带头循环链表
无头单向非循环链表:结构简单,⼀般不会单独⽤来存数据。实际中更多是作为其他数据结
构的⼦结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。带头双向循环链表:结构最复杂,⼀般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使⽤代码实现以后会发现结构会带 来很多优势,实现反而简单了,后⾯我们代码实现了就知道了。
4.3单链表的实现
定义链表节点
定义链表节点,同时重命名节点结构体和数据类型。
<code>typedef int SLDataType;
typedef struct SListNode
{
int SLDataType;
struct SListNode* next;
}SLTNode;
链表节点开辟
我们malloc开辟一个节点,然后判空。
SLTNode* SLTBuyNode(SLDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//创建新节点
if (newnode)//判断是否为空
{
newnode->next = NULL;//置空
newnode->SLDataType = x;//赋值
return newnode;
}
else
{
perror("malloc fail!");//开辟空间失败
exit(1);
}
链表尾插
我们开辟一个节点后,对链表判空。
如果链表为空,则让新链表成为头节点。
否则遍历链表找到尾节点,然后让尾节点对接新节点。
void SLTPushbak(SLTNode** phead, SLDataType x)
{
assert(phead);//断言
SLTNode* newnode = SLTBuyNode(x);//创建节点
if (*phead == NULL)//头节点为空
*phead = newnode;//新节点就是头节点
else//头节点不为空
{
SLTNode* pcur = *phead;//保存头节点
while (pcur->next)//找尾
{
pcur = pcur->next;
}
pcur->next = newnode;//尾节点对接
}
}
链表头插
开辟新节点,让新节点指针指向头节点。修改新节点为头节点。
void SLTPushPrin(SLTNode** phead, SLDataType x)
{
assert(phead);//断言
SLTNode* newnode = SLTBuyNode(x);//开辟新结点
newnode->next = *phead;//指向头节点
*phead = newnode;//成为新结点
}
链表指定位置之后插入
开辟新节点,让新节点指向pos位置后的节点,
再让pos节点指向新节点。
void STLInserafter(SLTNode* pos, SLDataType x)
{
assert(pos);//断言
SLTNode* newnode = SLTBuyNode(x);//开辟新空间
newnode->next = pos->next;//新节点指向pos后的节点
pos->next = newnode;//pos节点指向新节点
}
链表尾删
断言检测链表时否为空。
如果只有一个节点,直接free删除后让头节点指向空
否则遍历链表找到倒数第二个节点,free删除尾节点,
再让倒数第二个节点指向空。
void STLPopback(SLTNode** phead)
{
assert(phead && *phead);//断言,链表不能为空
SLTNode* pcur = *phead;//复制头节点
if ((pcur)->next == NULL)//只有一个节点
{
free(pcur);
*phead= NULL;//删除节点
}
else
{
while (pcur->next->next)//找尾的前一个结点
{
pcur = pcur->next;
}
free(pcur->next);//删除尾节点
pcur->next = NULL;//置空
pcur = NULL;
}
}
链表头删
断言检测链表为空。
先保存当前头节点。
先让头节点的下一个节点成为头节点。
再free释放保存的头节点
void STLPopPrin(SLTNode** phead)
{
assert(phead&&*phead);//断言
SLTNode** pcur = *phead;//复制头节点
*phead = (*phead)->next;//指向下一个节点
free(pcur);//删除头节点
pcur = NULL;//置空
}
链表指定位置删除
断言检测链表是否为空
如果pos位置时头节点,直接头删。
否则遍历找到pos的前节点,让pos前节点指向pos后节点,free删除pos节点
void STLErase(SLTNode** phead, SLTNode* pos)
{
assert(phead && *phead);//断言
assert(pos);
SLTNode* pcur = *phead;//复制头节点
if (pcur== pos)//pos节点就是头节点
{
STLPopPrin(phead);//头删
}
else
{
while (pcur->next != pos)//找pos前节点
{
pcur = pcur->next;
}
pcur->next = pos->next;//pos前节点指向pos后节点
free(pos);//删除pos节点
pos = NULL;//置空
}
}
链表指定位置之后删除
断言检测链表是否为空
保存pos后的节点,让pos节点指向pos的后后节点
free删除保存的pos后节点。
void STLEraseafter(SLTNode* pos)
{
assert(pos && pos->next);//断言
SLTNode* pcur = pos->next;//保存pos后节点
pos->next = pcur->next;//pos指向pos后后节点
free(pcur);//删除pos后节点
pcur=NULL;
}
链表指定位置前插入
断言检测链表是否为空,开辟新结点
如果pos位置时头节点,直接头插
否则遍历找到pos前节点,让新节点指向pos节点
让pos前节点指向新节点。
void STLInser(SLTNode** phead, SLTNode* pos, SLDataType x)
{
assert(phead&&*phead);//断言
assert(pos);//断言
SLTNode* newnode = SLTBuyNode(x);//开辟空间
SLTNode* pcur = *phead;//复制头节点
if (pos == pcur)//头节点位前插
{
SLTPushPrin(phead, x);//头插
}
else
{
while (pcur->next != pos)//找pos前节点
{
pcur = pcur->next;//移动
}
newnode->next = pos;//新节点指向pos节点
pcur->next = newnode;//pos前节点指向新节点
}
}
链表的查找
遍历链表每次判断是否要查找的节点即可。
SLTNode* STLFind(SLTNode* phead, SLDataType x)
{
SLTNode* pcur = phead;//复制头节点
while (pcur)//循环遍历
{
if (pcur->SLDataType == x)//判断是否为目标值
return pcur;//返回目标节点
pcur = pcur->next;//不是继续遍历
}
return NULL;
}
后言
这就是数据结构中的的复杂度和链表,这些是数据结构的基础,正所谓“基础不牢 地动山摇”。我们要对这些基础多加巩固。今天就分享到这里!感谢各位小伙伴垂阅!咱们下期见!拜拜~

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。