系统调优助手,PyTorch Profiler TensorBoard 插件教程
just_sort 2024-06-29 10:05:02 阅读 53
0x1. 前言
使用PyTorch Profiler进行性能分析已经一段时间了,毕竟是PyTorch提供的原生profile工具,个人感觉做系统性能分析时感觉比Nsys更方便一些,并且画的图也比较直观。这里翻译一下PyTorch Profiler TensorBoard Plugin的教程并分享一些使用经验,我使用的时候也是按照这个教程来来的,有一点不一样的是可以在vscode里面直接安装TensorBoard插件,然后Command+Shift+P打开vscode的命令行窗口输入TensorBoard启用TensorBoard插件并把PyTorch Profiler输出的日志文件所在的文件夹路径传给它就可以直接在vscode里面查看可视化Profile结果了。
如果有时候出现下面这种TensorBoard启动超时的情况可以手动杀掉vscode里和tensorboard相关的进程,比如在linux上:pkill -f tensorboard

https://github.com/pytorch/kineto/blob/main/tb_plugin/examples/resnet50_profiler_api.py 和 https://github.com/pytorch/kineto/blob/main/tb_plugin/examples/resnet50_ddp_profiler.py 分别给出了单机和多机的ResNet50模型profile脚本,核心就是下面2个红框部分。
然后,我日常是使用 tensorboard --logdir=./samples --bind_all 这条命令来把可视化结果映射到本地浏览器里面(通过打开:http://localhost:6006/#pytorch_profiler )。然后我们也要利用好悬浮工具栏,也就是下面红色框部分,当我们点了第三个按钮之后可以通过你可以通过向上拖动鼠标并按住鼠标左键来放大。这个按钮是最常用的。
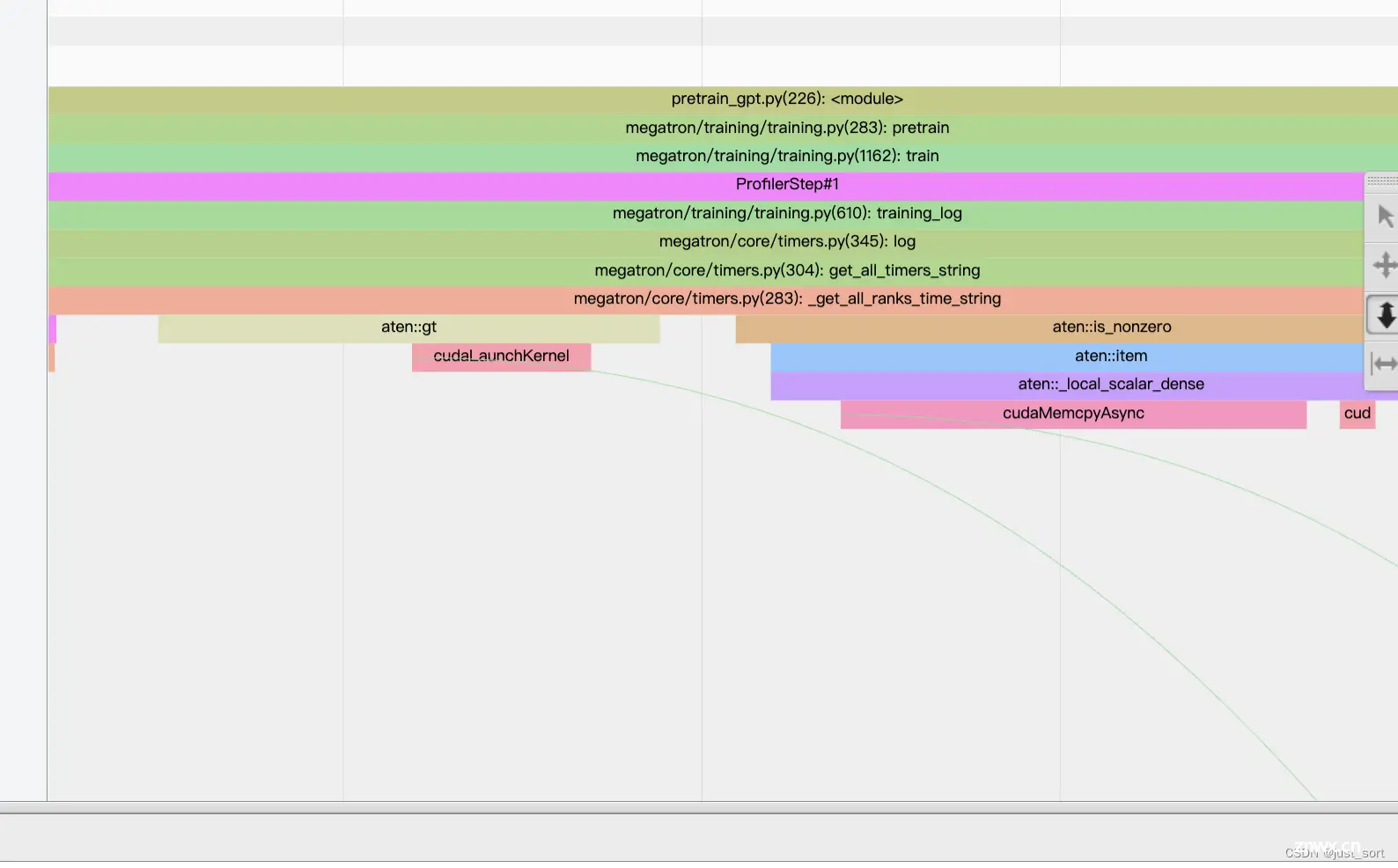
另外,在可视化界面的右上角有一个Flow Events按钮,有ac2g和fwdbwd两个按钮,前面这个按钮可以让我们获得CPU算子和CUDAKernel的映射关系。比如下图有一个aten::gt算子:
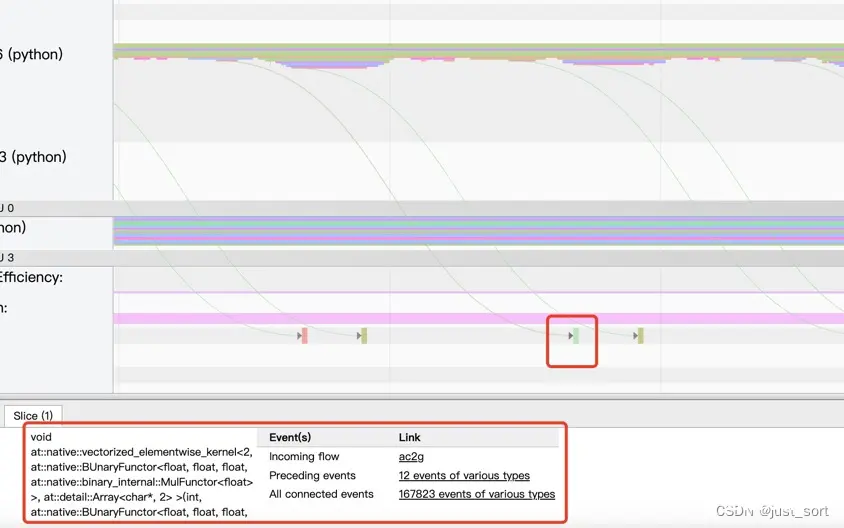
我们可以看到它对应了一个cuda的elementwise算子。
总之很强就是了,相比Nsight System可以直接看到一些分析结果。并且Trace功能非常有用,而Nsight System得肉眼去定位。
除了做训练系统的分析之外,PyTorch Profiler 同样可以用在单个算子或者推理的模型中。
我之后打算聊一些Megatron-LM的细节,其中重要的依据就是使用PyTorch Profiler 的结果,所以这里对PyTorch Profiler TensorBoard Plugin教程做一个翻译,利好初次使用的读者。
最后唠叨一句,PyTorch Profiler在渲染很大的网络的Trace图时需要的时间可能会比较久,以LLama7b为例,为了避免这个问题你可以控制Profile的step为1或者减少Transformer Block的层数为原始的1/4,这样就能很快的得到Trace视图了。如果有需要可以继续浏览0x2节的翻译,或者作为查阅的参考资料。
0x2. 翻译
PyTorch Profiler TensorBoard Plugin 教程地址见:https://github.com/pytorch/kineto/blob/main/tb_plugin/README.md
这是一个用于可视化 PyTorch 性能分析的 TensorBoard 插件。它可以解析、处理并可视化 PyTorch Profiler 导出的性能分析结果,并提供优化建议。
快速安装指南
从 pypi 安装
pip install torch-tb-profiler
若要安装支持 S3 / AzureBlob / GCS / HDFS 扩展的版本,请使用 pip install torch-tb-profiler[s3/blob/gs/hdfs],例如 pip install torch-tb-profiler[s3]
或者你可以从源代码安装
克隆 git 仓库:
git clone https://github.com/pytorch/kineto.git
导航到 kineto/tb_plugin 目录。
使用以下命令安装:
pip install .
构建wheel文件
python setup.py build_fe sdist bdist_wheel
注意:build_fe步骤需要设置 yarn 和 Node.jspython setup.py sdist bdist_wheel
快速启动指南
准备性能分析数据
我们已经准备了一些样本性能分析数据在 kineto/tb_plugin/samples(./samples)
你可以直接下载。
或者你可以通过运行 kineto/tb_plugin/examples/resnet50_profiler_api.py(./examples/resnet50_profiler_api.py) 来生成这些样本数据。
你还可以从 PyTorch Profiler(https://pytorch.org/tutorials/intermediate/tensorboard_profiler_tutorial.html?highlight=tensorboard) 学习如何对你的模型进行性能分析并生成性能分析数据。
注意:推荐的生成性能分析数据的方法是在创建 torch.profiler.profile 时,将 torch.profiler.tensorboard_trace_handler 分配给 on_trace_ready。
启动 TensorBoard
在 TensorBoard 中指定性能分析数据文件夹为 logdir。如果使用上述样本数据,启动 TensorBoard 命令为:
tensorboard --logdir=./samples
如果你的网络浏览器不在启动 TensorBoard 的同一台机器上,你可以添加 --bind_all 选项,如:
tensorboard --logdir=./samples --bind_all
注意:确保默认端口 6006 对浏览器的主机开放。
在 Chrome 浏览器中打开 TensorBoard
在浏览器中打开 URL http://localhost:6006。
如果你在启动 tensorboard 命令中使用了 --bind_all,主机名可能不是 ‘localhost’。你可能会在命令后打印的日志中找到它。
导航到 PYTORCH_PROFILER 标签页
如果 --logdir 下的文件太大或太多,请稍等一会儿并刷新浏览器以查看最新加载的结果。
从云端加载性能分析数据
这一堆就不翻译了,基本很难用到,感兴趣的可以查看原文。
快速使用指南
我们将每次启用分析器的运行视为一个“运行”。
在大多数情况下,一个运行是一个单独的进程。如果启用了分布式数据并行(DDP),那么一个运行将包括多个进程。
我们将每个进程称为一个“工作节点”。
每个运行对应于由 “–logdir” 指定的文件夹下的一个子文件夹。
每个子文件夹包含一个或多个 chrome 跟踪文件,每个进程一个。
kineto/tb_plugin/samples 是文件组织方式的一个示例。
你可以在TensorBoard左侧控制面板上选择运行的工作节点。
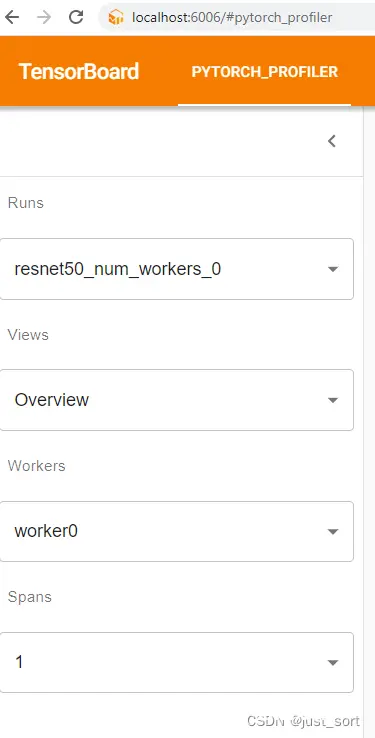
Runs:选择一个运行。每个运行是一次启用性能分析的 PyTorch 应用程序执行。
Views:我们将性能分析结果组织成多个视图,从粗粒度(概览级别)到细粒度(kernel级别)。
Workers:选择一个工作节点。每个工作节点是一个进程。在使用 DDP 时可能有多个工作节点。
Spans:使用 torch.profiler.schedule(https://github.com/pytorch/pytorch/blob/master/torch/profiler/profiler.py#L24) 作为 torch.profiler 的schedule,可能会生成不同跨度的多个性能跟踪文件。你可以用这个选择框选择它们。
目前我们有以下性能诊断视图:
总览视图操作符视图kernel 视图跟踪视图内存视图分布式视图
我们将在下面描述每个视图。
总览视图
总览视图是你性能分析运行中过程的顶级视图。
它显示了包括主机和 GPU 设备在内的时间成本概览。
你可以在左侧面板的“工作节点”下拉菜单中选择当前工作节点。
总览视图的一个示例:
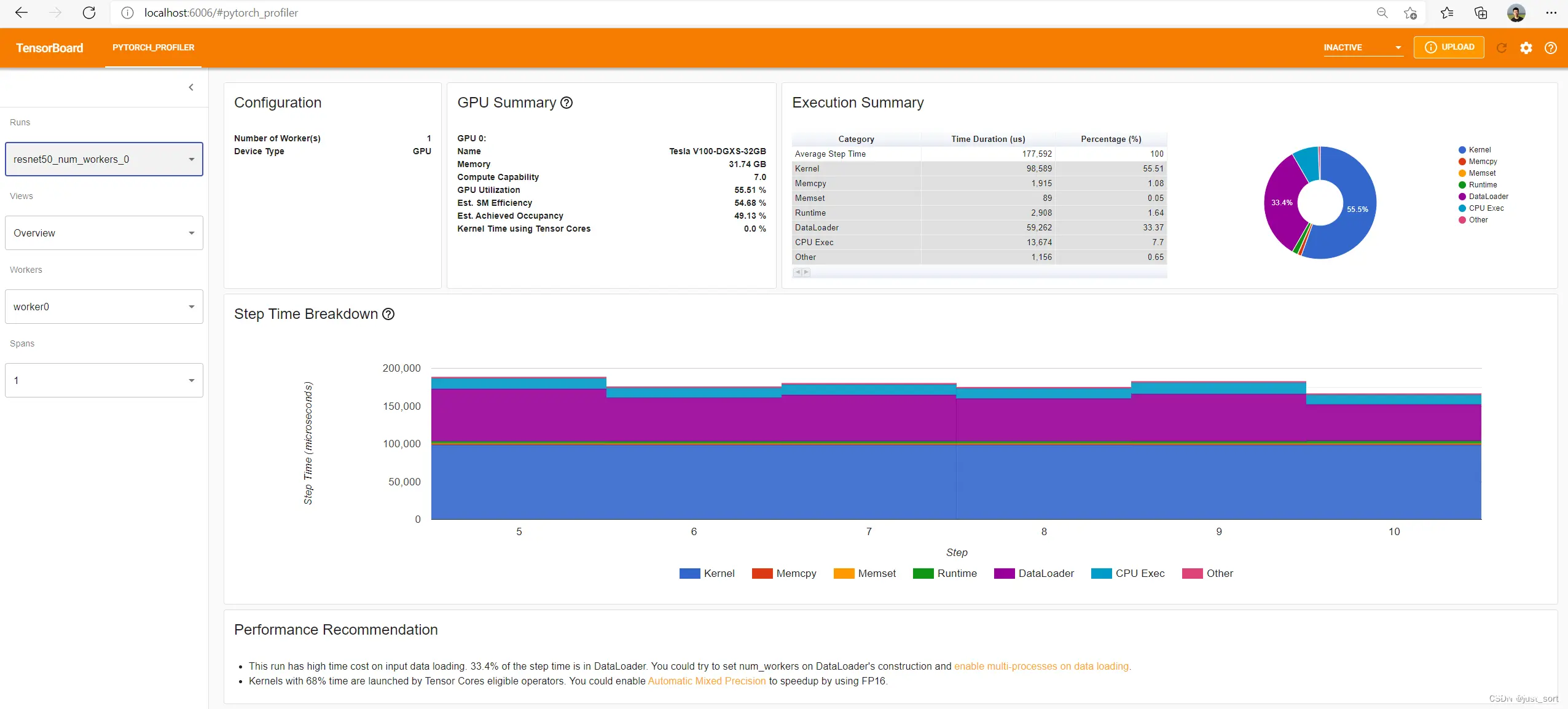
‘GPU Summary’ 面板显示了此次运行的 GPU 信息和使用指标,包括名称、全局内存、计算能力等。
‘GPU Utilization’、‘Est. SM Efficiency’ 和 ‘Est. Achieved Occupancy’ 显示了此次运行在不同级别的 GPU 使用效率。
‘Kernel Time using Tensor Cores’ 显示了 Tensor Core kernel激活的时间百分比。
以上四个指标的详细信息可以在 gpu_utilization(./docs/gpu_utilization.md) 中找到。
‘Step Time Breakdown’ 面板显示了性能概要。我们将每次迭代(通常是一个小批量)视为一个step。
每个步骤花费的时间分为以下几类:
kernel :GPU 设备上的kernel 执行时间;
Memcpy:涉及 GPU 的内存复制时间(D2D、D2H 或 H2D);
Memset:涉及 GPU 的内存设置时间;
通信:仅在 DDP 情况下出现的通信时间;
运行时:主机端的 CUDA 运行时执行时间;
例如 cudaLaunchKernel、cudaMemcpyAsync、cudaStreamSynchronize 等;
DataLoader:在 PyTorch DataLoader 对象中的数据加载时间;
CPU 执行:主机计算时间,包括每个 PyTorch 操作符的运行时间;
其他:未包含在上述任何类别中的时间。
注意:以上所有类别的总结是端到端的实际时间。
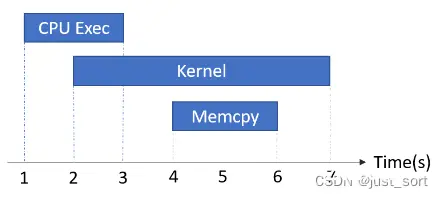
上述列表按优先级从高到低排列。我们按优先顺序计算时间。最高优先级类别(Kernel)的时间成本最先计算
,然后是 Memcpy,然后是 Memset,…,最后是其他。在以下示例中,“kernel ”首先被计为 7-2=5 秒;然后“Memcpy”被计为 0 秒,因为它完全被“Kernel”掩盖;然后“CPU 执行”被计为 2-1=1 秒,因为 [2,3] 时间间隔被“kernel ”掩盖,只有 [1,2] 时间间隔被计算。通过这种方式,一个step中所有 7 类别计算的时间总和将与该step的总实际时间相同。
Operator视图
此视图显示了在主机或设备上执行的每个 PyTorch 操作符的性能。
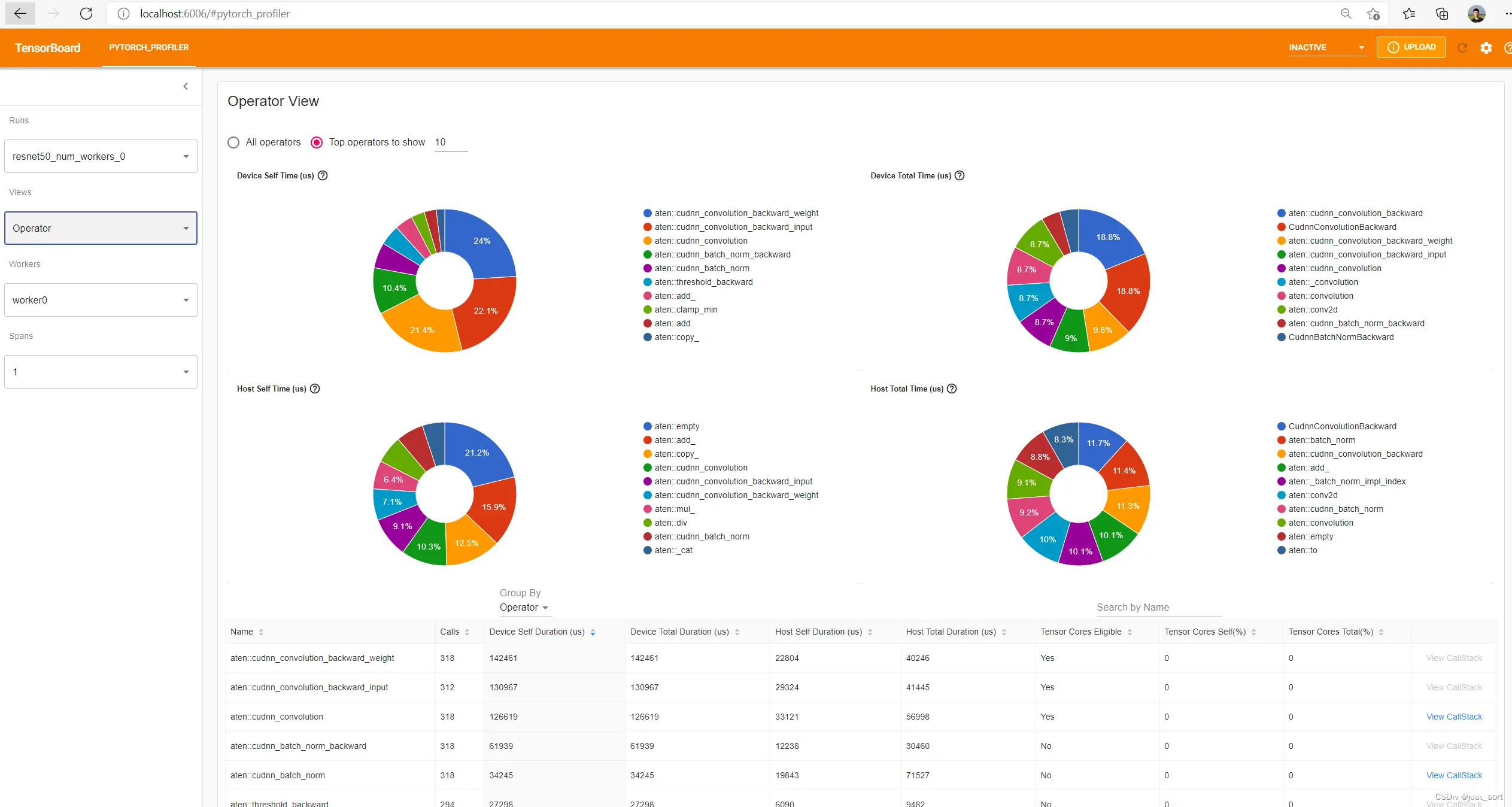
每个表格行都是一个 PyTorch 操作符,这是由 C++ 实现的计算操作符,例如 “aten::relu_”、“aten::convolution”。
调用次数:此运行中操作符被调用的次数。
设备自身持续时间:在 GPU 上累计花费的时间,不包括此操作符的子操作符。
设备总持续时间:在 GPU 上累计花费的时间,包括此操作符的子操作符。
主机自身持续时间:在主机上累计花费的时间,不包括此操作符的子操作符。
主机总持续时间:在主机上累计花费的时间,包括此操作符的子操作符。
Tensor Core适用性:此操作符是否适用于使用Tensor Core。
Tensor Core自身百分比:使用Tensor Core的自身kernel时间 / 自身kernel时间。
自身kernel不包括由此操作符的子操作符启动的kernel。
Tensor Core总百分比:使用Tensor Core的kernel时间 / kernel时间。
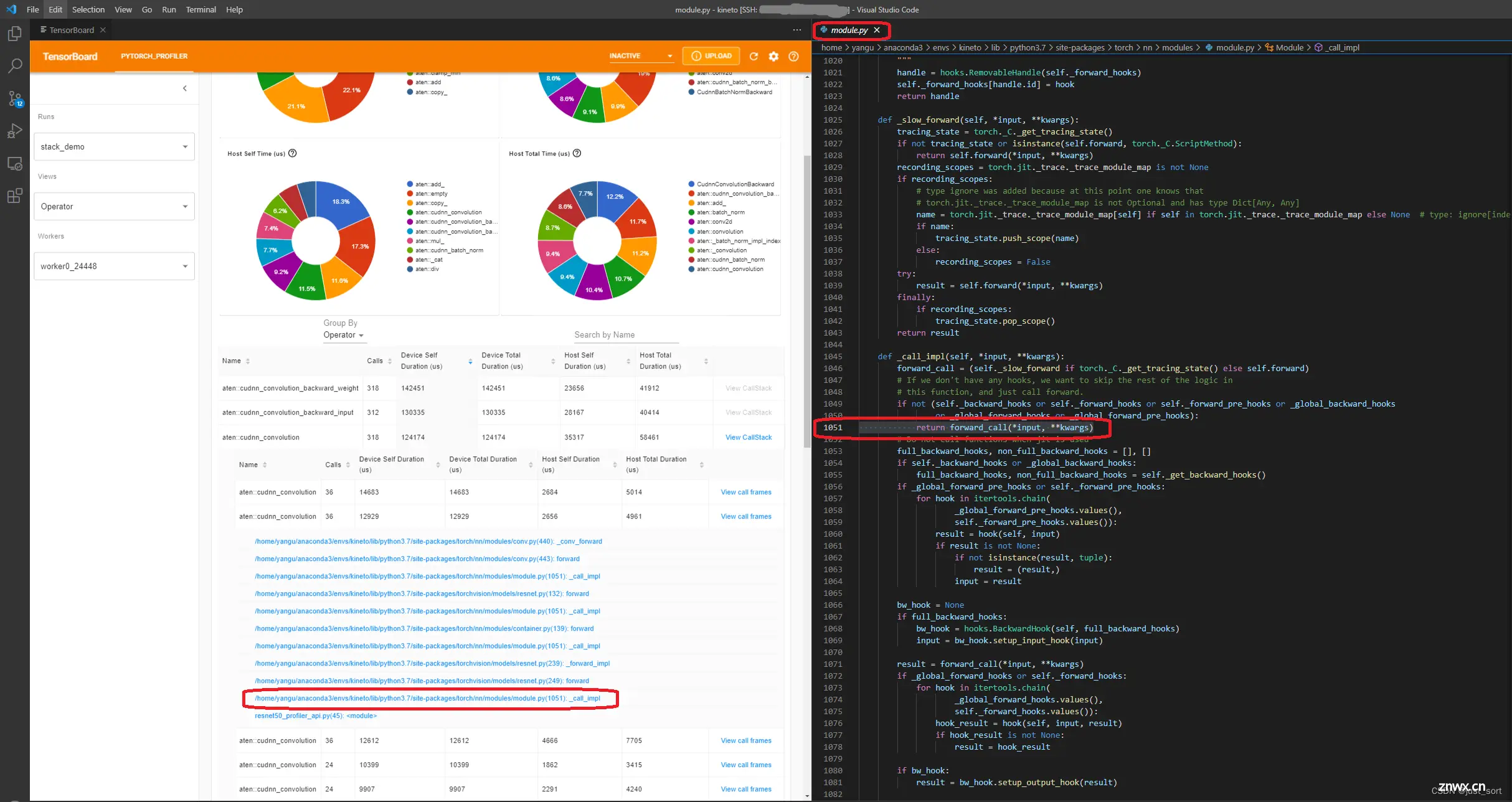
调用栈:如果已在性能分析跟踪文件中记录,则显示此操作符的所有调用栈。
要转储此调用栈信息,应在 torch.profiler API 中设置 ‘with_stack’ 参数。
如果在 VSCode 中启动 TensorBoard,点击此调用栈会转到源代码的相应行,如下图:
注意:上述每个持续时间都表示实际时间。这并不意味着在此期间 GPU 或 CPU 完全被利用。
前四个饼图是上述四列持续时间的可视化。它们使得细分在一瞥间就可见。饼图中将仅显示按持续时间排序的前 N 个操作符(在文本框中可配置)。
搜索框允许按名称搜索操作符。
“分组依据”可以选择“操作符”和“操作符 + 输入形状”。
“输入形状”是此操作符输入参数列表中的张量形状。
空的“[]”表示具有标量类型的参数。
例如,“[[32, 256, 14, 14], [1024, 256, 1, 1], [], [], [], [], [], [], []]”
表示此操作符有 9 个输入参数,
第一个是尺寸为 32*256*14*14 的张量,
第二个是尺寸为 1024*256*1*1 的张量,
接下来的七个是标量变量。

性能建议:利用性能分析结果自动突出可能的瓶颈,并给用户提供可行的优化建议。
kernel 视图
此视图显示在 GPU 上所有kernel 的时间花费。时间通过减去kernel 的开始时间和结束时间来计算。
注意:此视图不包括 cudaMemcpy 或 cudaMemset。因为它们不是kernel 。
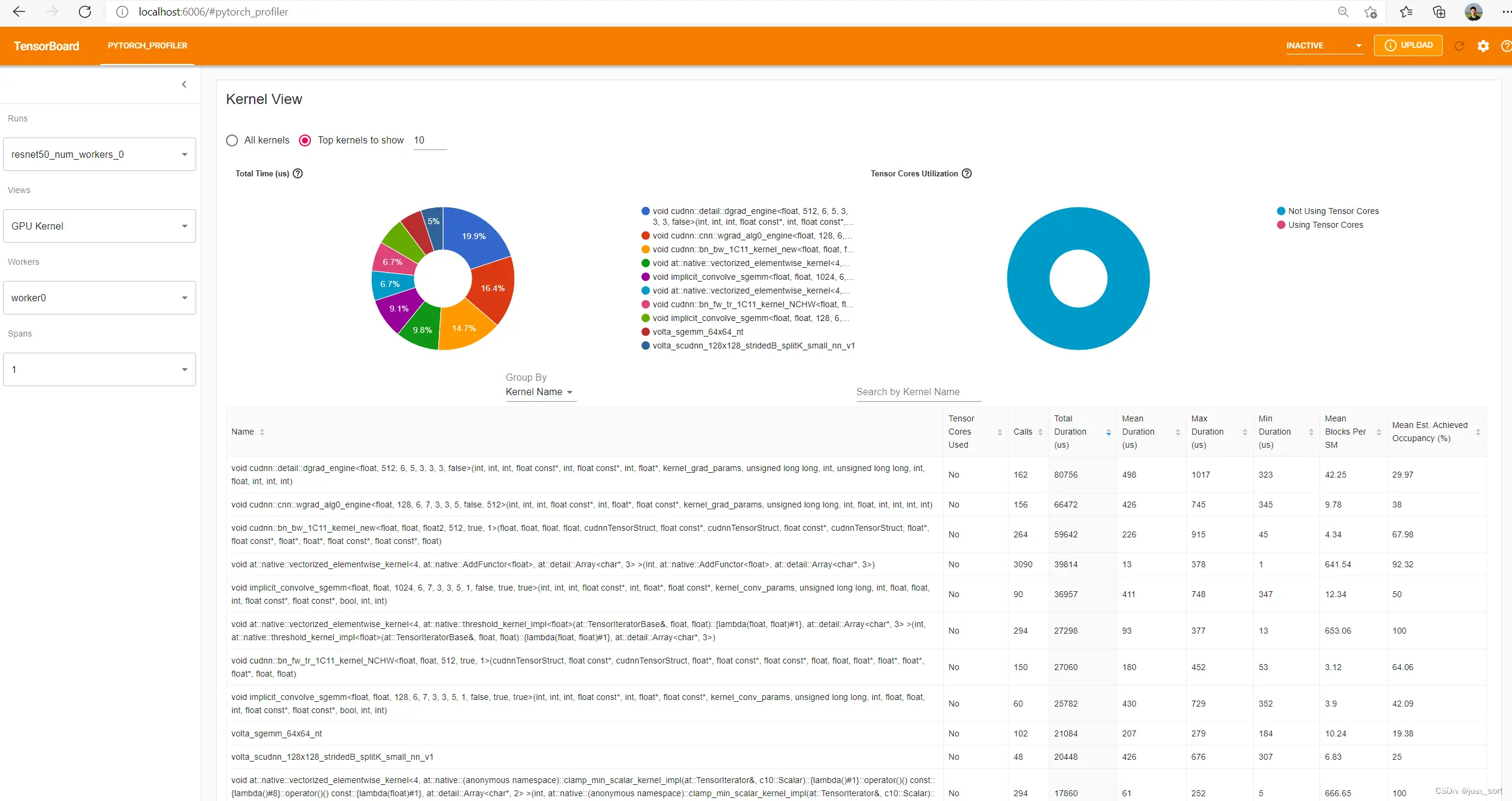
Tensor Core使用情况:此kernel 是否使用Tensor Core。
总持续时间:此kernel 所有调用的累计时间。
平均持续时间:所有调用的平均时间持续。即“总持续时间”除以“调用次数”。
最大持续时间:所有调用中的最长时间持续。
最小持续时间:所有调用中的最短时间持续。
注意:这些持续时间只包括 GPU 设备上kernel 的经过时间。这并不意味着 GPU 在此时间间隔内忙于执行指令。由于诸如内存访问延迟或并行度不足等原因,一些 GPU 核心可能处于空闲状态。
例如,每个 SM 可用的 warps 数量可能不足以有效地隐藏内存访问延迟,或者一些 SM 可能因为块数量不足而完全空闲。请参阅 Nvidia 的最佳实践指南(https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/index.html)。为了研究每个kernel 的效率,我们计算并显示了最后两列的’Mean Blocks Per SM’ 和 ‘Mean Est. Achieved Occupancy’ 。
Mean Blocks Per SM:每个 SM 的Block数 = 此kernel的块数 / 此 GPU 的 SM 数量。如果这个数字小于 1,表明 GPU 多处理器未被充分利用。“平均每 SM 块数” 是使用每次运行的持续时间作为权重的所有此kernel名称运行的加权平均值。
Mean Est. Achieved Occupancy:估计实现占用率的定义可以参考 gpu_utilization(https://github.com/pytorch/kineto/blob/main/tb_plugin/docs/gpu_utilization.md),它是使用每次运行的持续时间作为权重的所有此kernel名称运行的加权平均值。
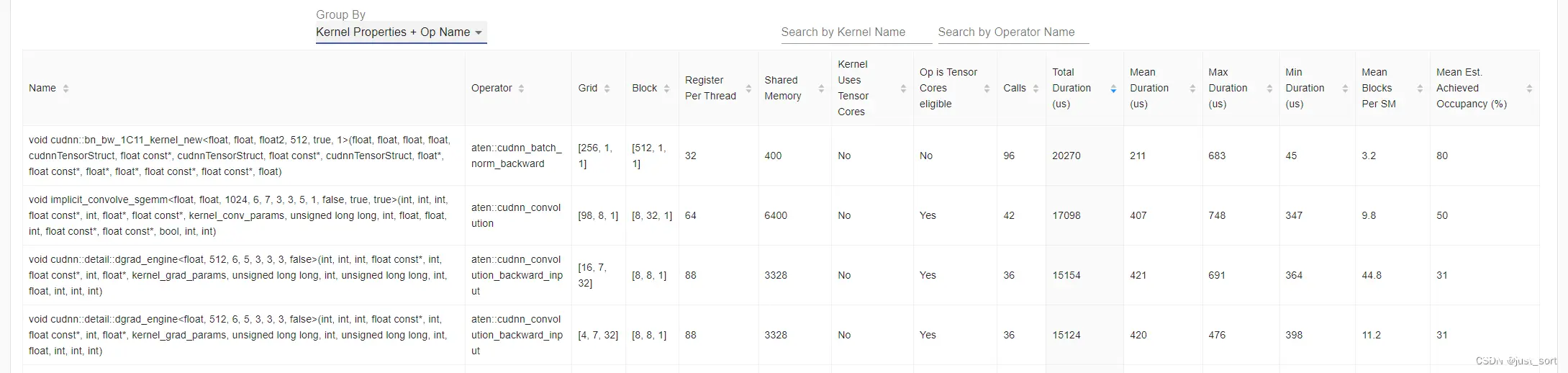
左上角的饼图是“总持续时间”列的可视化。它使得细分在一瞥间就可见。饼图中将仅显示按累计时间排序的前 N 个kernel(在文本框中可配置)。右上角的饼图是使用和未使用Tensor Core的kernel时间百分比。搜索框允许按名称搜索kernel。“分组依据”可以选择“kernel名称”和“kernel属性 + 操作符名称”。“内kernel名称”将按kernel名称分组kernel。“kernel属性 + 操作符名称”将按kernel名称、启动操作符名称、网格、块、每线程寄存器数和共享内存的组合分组kernel。
跟踪视图
此视图使用 chrome 跟踪插件显示时间线。每个水平区域代表一个线程或一个 CUDA 流。
每个彩色矩形代表一个操作符、一个 CUDA 运行时或在 GPU 上执行的 GPU 操作
(如kernel、CUDA 内存复制、CUDA 内存设置等)
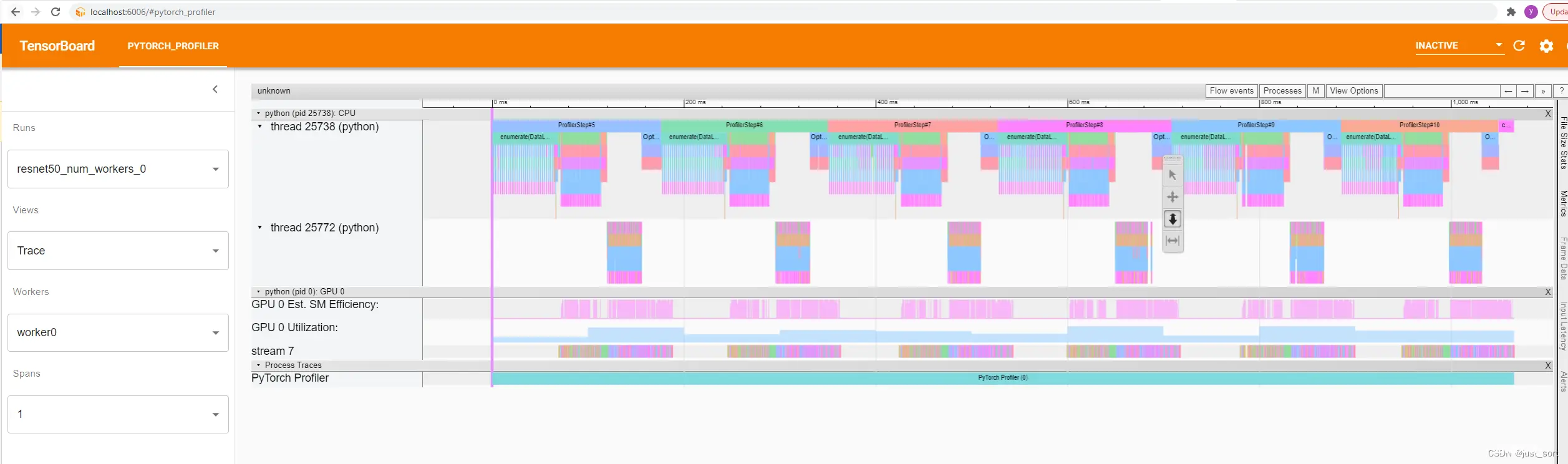
在上述示例中:
“thread 25772”是执行神经网络“反向”操作的 CPU 线程。
“thread 25738”是主 CPU 线程,主要进行数据加载、神经网络的前向操作和模型更新。
“stream 7”是一个 CUDA stream,显示此stream的所有kernel。
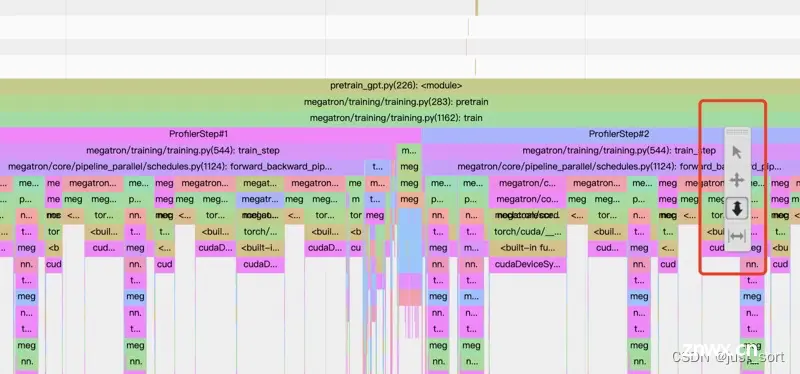
你可以看到在“线程 1”的顶部有 6 个“ProfilerStep”。每个“ProfilerStep”代表一个小批量步骤。
悬浮工具栏具有帮助查看跟踪线的功能。例如,当启用上下箭头时,你可以通过向上拖动鼠标并按住鼠标左键来放大。
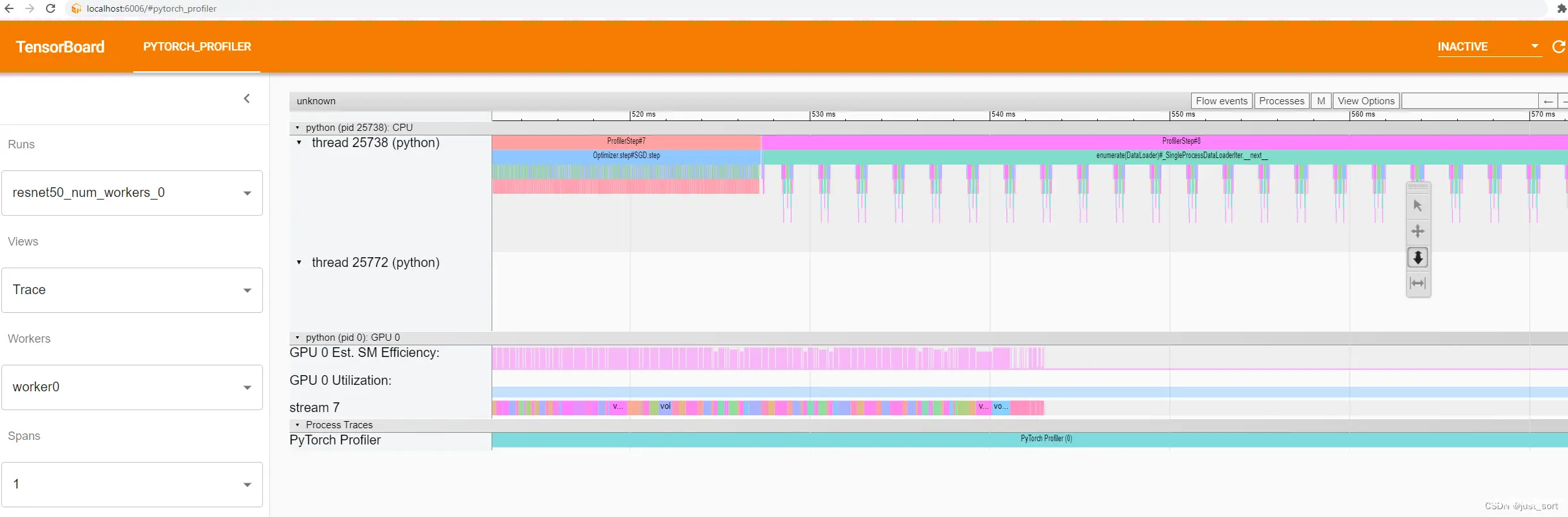
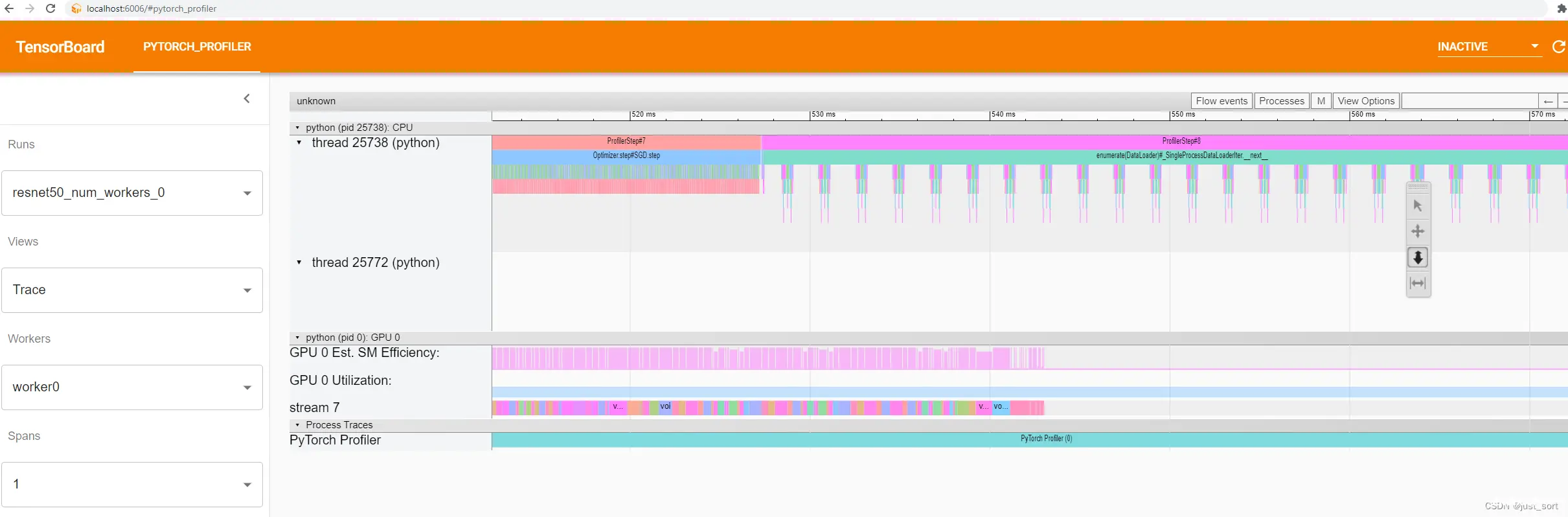
“Optimizer.step#SGD.step”和“enumerate(DataLoader)#_SingleProcessDataLoaderIter.next”
是高级 Python 端函数。
当你在右上角选择“流事件”为“异步”时,你可以看到操作符及其启动的kernel之间的关系。
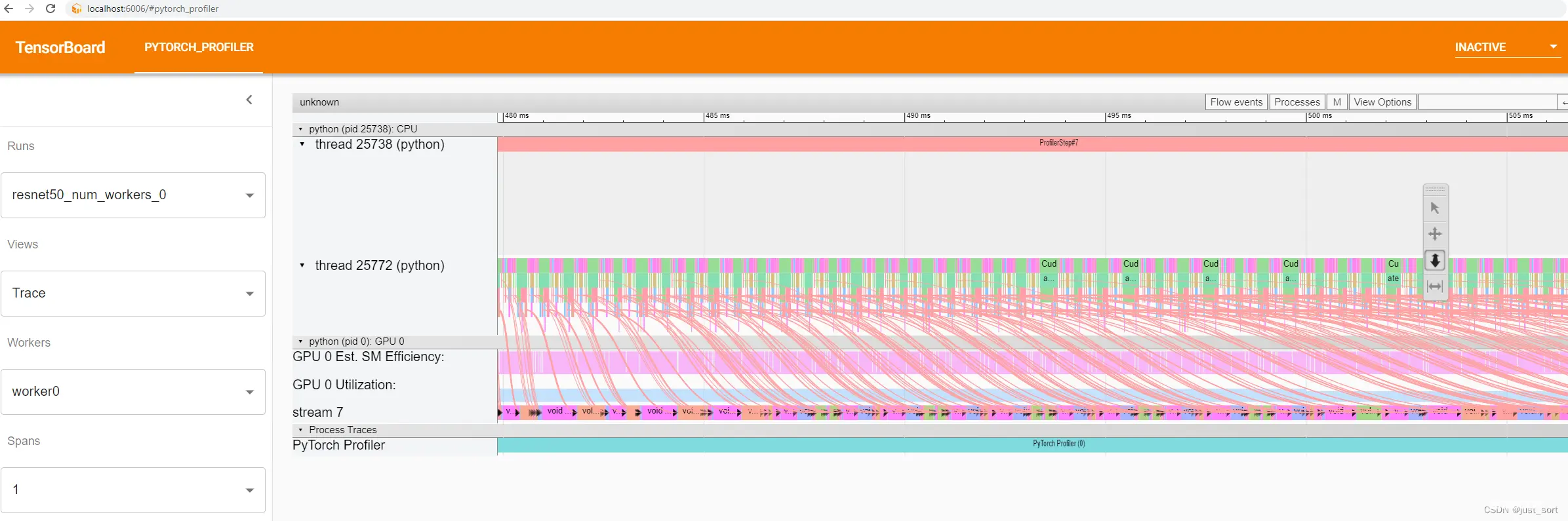
你还可以在跟踪视图中查看 GPU 利用率和估计的 SM 效率。它们沿着时间线绘制:
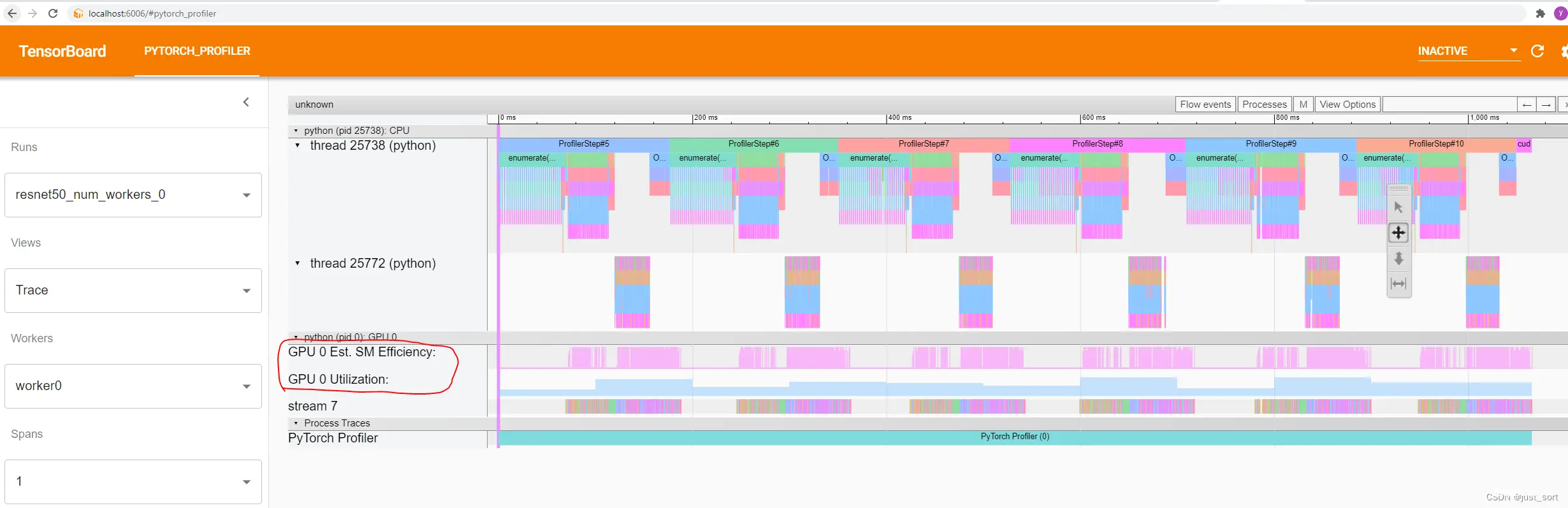
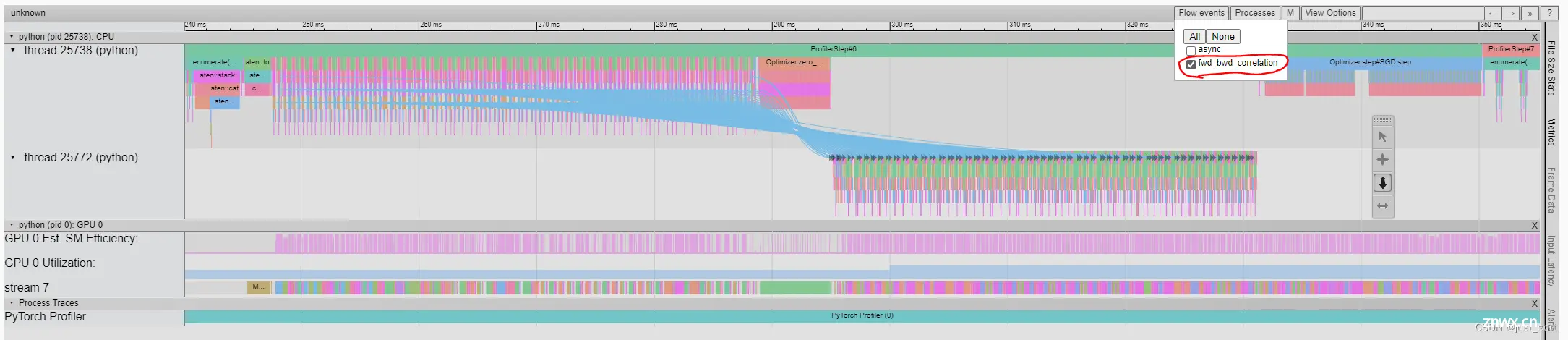
当你在右上角选择“Flow events”为“fwd_bwd_correlation”时,你可以看到前向操作符及其启动的反向操作符之间的关系。注意:只有直接启动的反向操作符的前向操作符将通过线连接,调用此操作符为子操作符的祖先操作符不会被连接。
内存视图
Pytorch 分析器记录了分析期间的所有内存分配/释放事件和分配器的内部状态。对于每个操作符,插件会聚合其生命周期内的所有事件。
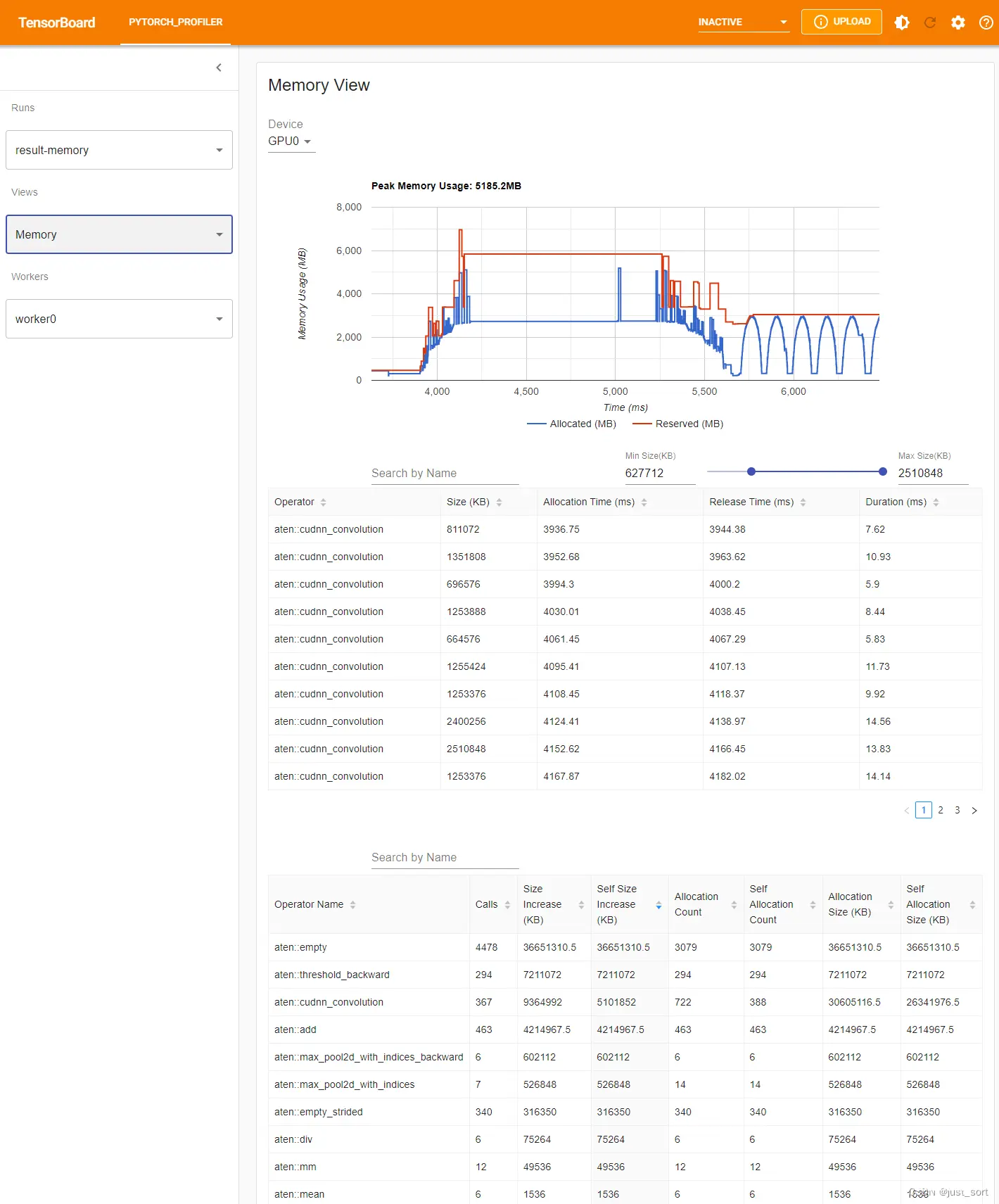
内存种类可以在“设备”选择框中选择。例如,“GPU0”表示接下来的图表和表格只显示每个操作符在 GPU 0 上的内存使用情况,不包括 CPU 或其他 GPU。
内存曲线
内存曲线显示了内存使用趋势。它帮助用户了解内存消耗的概览。“已分配”曲线是从分配器请求的总内存,例如,由张量使用的内存。“保留”曲线只在底层分配器使用缓存机制时有意义。它代表分配器从操作系统分配的总内存。
用户可以在内存曲线图上选择并通过按下左键并在曲线上拖动来放大选定范围。右键单击将重置图表到初始状态。选择将影响下文提到的“内存事件”表和“内存统计”表。
内存事件
内存事件表显示内存分配和释放事件对。表中每个字段的定义:
操作符:导致从分配器进行分配的直接操作符。在 Pytorch 中,一些操作符如 aten::empty 常用作张量创建的 API,在这种情况下,我们显示为 <parent-op> (<op>)。
大小:分配的内存大小。
分配时间:相对于分析器启动的内存分配时间点。如果分配事件不包括在选定范围内,则可能从表中缺失。
释放时间:相对于分析器启动的内存释放时间点。如果释放事件不包括在选定范围内,则可能从表中缺失。注意,释放的内存块可能仍被底层分配器缓存。
持续时间:分配内存的生命周期。如果缺少分配时间或释放时间,则可能从表中缺失。
内存统计
表中每个字段的定义:
调用次数:此操作符在此运行中被调用的次数。
增加的大小:包括所有子操作符的内存增加大小。它将所有分配的字节总和减去所有释放的内存字节。
自身增加的大小:与操作符本身相关的内存增加大小,不包括其子操作符。它将所有分配的字节总和减去所有释放的内存字节。
分配次数:包括所有子操作符的分配次数。
自身分配次数:仅属于操作符本身的分配次数,不包括其子操作符。
分配大小:包括所有子操作符的分配大小。它将所有分配的字节总和,不考虑内存释放。
自身分配大小:仅属于操作符本身的分配大小。它将所有分配的字节总和,不考虑内存释放。
分布式视图
此视图仅在使用 nccl 进行通信的 DDP 作业中自动出现。此视图中有四个面板:
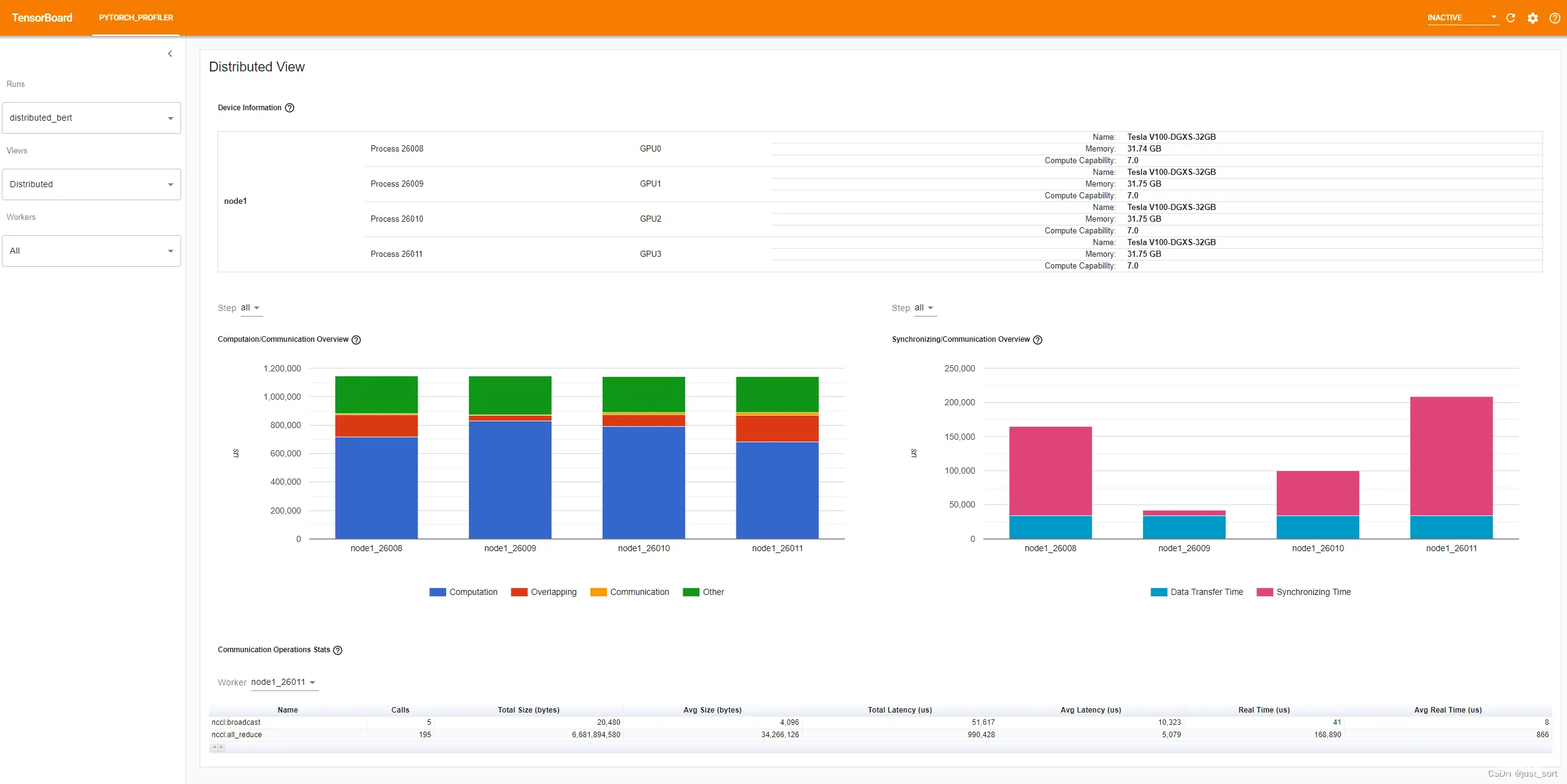
顶部面板显示此作业的节点/进程/GPU层次结构的信息。
中间左侧面板是“计算/通信概览”。每个图例的定义:
计算:GPU上kernel时间的总和减去重叠时间。重叠:计算和通信的重叠时间。更多的重叠代表计算和通信之间更好的并行性。理想情况下,通信将完全与计算重叠。通信:总通信时间减去重叠时间。其它:步骤时间减去计算和通信时间。可能包括初始化、数据加载、CPU计算等。
从这个视图中,你可以了解每个工作节点的计算到通信比率和工作节点之间的负载平衡。例如,如果一个工作节点的计算+重叠时间远大于其他节点,可能存在负载平衡问题,或者这个工作节点可能是一个落后者。
中间右侧面板是“同步/通信概览”。每个图例的定义:
数据传输时间:总通信时间中用于实际数据交换的部分。同步时间:总通信时间中用于等待和与其他工作节点同步的部分。
从这个视图中,你可以了解通信的效率(总通信时间中实际用于交换数据的比例有多少,以及有多少时间只是等待其他工作节点的数据)
“Communication Operations Stats”总结了每个工作节点中所有通信操作的详细统计信息。每个字段的定义:
调用次数:此操作符在此运行中被调用的次数。总大小(字节):此类型操作符中传输的总数据大小。平均大小(字节):此类型操作符中每次操作传输的平均数据大小。总延迟(微秒):此类型操作符的总延迟。平均延迟(微秒):此类型操作符的平均延迟。数据传输时间(微秒):此类型操作符的实际数据传输总时间。平均数据传输时间(微秒):此类型操作符的实际数据传输平均时间。
模块视图
如果 torch.nn.Module 信息被 Pytorch 分析器导出到结果的 Chrome 跟踪文件中,插件可以显示 nn.Module 的层次结构和摘要。
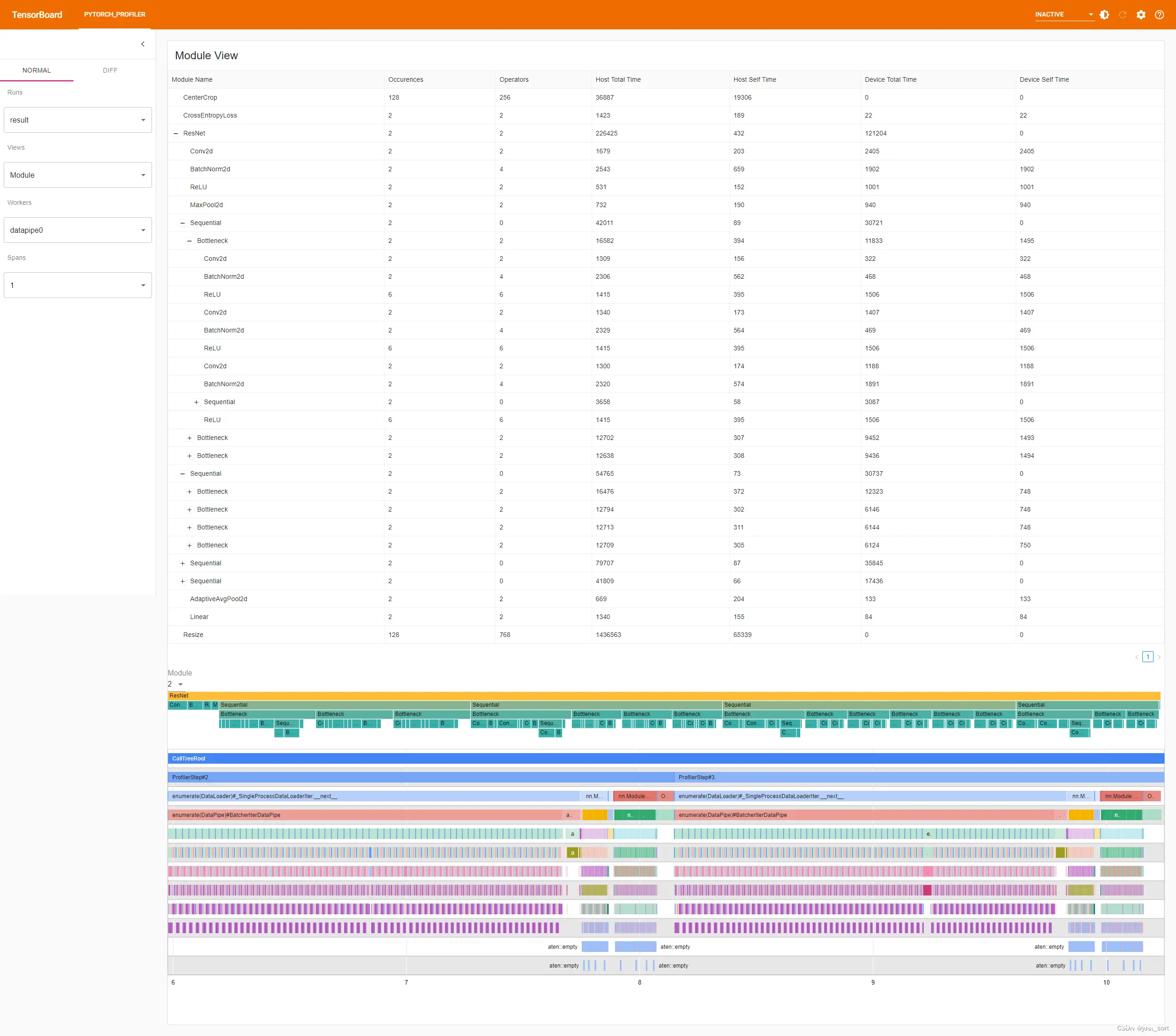
顶部表格显示了每个 torch.nn.Module 的统计信息,包括:
出现次数:模块在训练过程中被调用的次数。操作符:模块调用的操作符数量。主机总时间:在主机上花费的累积时间,包括子模块。主机自身时间:在主机上花费的累积时间,不包括子模块。设备总时间:包含在模块中的操作符在 GPU 上花费的累积时间,包括子模块。设备自身时间:包含在模块中的操作符在 GPU 上花费的累积时间,不包括子模块。中间的火焰图显示了 torch.nn.Module 的层次结构信息。
底部图表显示了主线程操作符树。
0x3. PyTorch Profiler涉及的GPU利用率指标说明
主要涉及到 GPU Utilization,Est. SM Efficiency,Est. Achieved Occupancy,Kernel Time using Tensor Cores 这几个概念。文档:https://github.com/pytorch/kineto/blob/main/tb_plugin/docs/gpu_utilization.md
GPU Utilization:GPU 繁忙时间 / 所有步骤时间。数值越高越好。所有步骤时间是所有分析步骤(或称为迭代)的总时间。
GPU 繁忙时间是在“所有步骤时间”中至少有一个 GPU kernel在此 GPU 上运行的时间。
然而,这个高级别的利用率指标是粗糙的。它不能显示有多少个流多处理器(SM)正在使用。
例如,一个持续运行单线程的kernel将获得 100% 的 GPU 利用率。
Est. SM Efficiency:预估SM效率。数值越高越好。此指标为kernel的 SM 效率,SM_Eff_K = min(该kernel的block数 / 该 GPU 的 SM 数,100%)。
这个总数是所有kernel的 SM_Eff_K 乘以kernel执行持续时间后的总和,然后除以“所有步骤时间”。
它显示了 GPU 流多处理器的利用率。
虽然它比上面的“GPU 利用率”更精细,但它仍然不能完全展示全部情况。
例如,每个块只有一个线程的kernel无法完全利用每个 SM。
Est. Achieved Occupancy:对于大多数情况,如内存带宽受限的kernel,更高的值通常意味着更好的性能,特别是当初始值非常低时。参考资料(http://developer.download.nvidia.com/GTC/PDF/GTC2012/PresentationPDF/S0514-GTC2012-GPU-Performance-Analysis.pdf)。占用率的定义在此处(https://docs.nvidia.com/gameworks/content/developertools/desktop/analysis/report/cudaexperiments/kernellevel/achievedoccupancy.htm)。
Occupancy是一个 SM 上活跃 warps 的比率与该 SM 支持的最大活跃 warps 数的比率。kernel的理论Occupancy是该kernel的上限占用率,受多种因素限制,如kernel形状、kernel使用的资源和 GPU 的计算能力。
kernel的预估实现Occupancy,OCC_K = min(kernel的线程数 / SM 数 / 每 SM 最大线程数,kernel的理论Occupancy)。
这个总数是所有kernel的 OCC_K 使用kernel执行持续时间作为权重的加权和。它显示了细粒度的低级 GPU 利用率。
Kernel Time using Tensor Cores:用于Tensor Core kernel的总 GPU 时间 / 所有kernel的总 GPU 时间。数值越高越好。
Tensor Core是 Volta GPU(如 Titan V)及以后 GPU 提供的混合精度浮点运算操作。
cuDNN 和 cuBLAS 库包含了多数卷积和 GEMM 操作的几个启用了张量核心的 GPU kernel。
这个数字显示了 GPU 上所有kernel中使用张量核心的时间比例。
上一篇: Python搭建自己的VPN
下一篇: 解决ideatomcatUnrecognized option:--add-opens=java.base/java.lang=ALL-UNNAMEDError:Could not create th
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。