Python批量提取Word文档表格数据
Eiceblue 2024-06-16 14:05:04 阅读 71
在大数据处理与信息抽取领域中,Word文档是各类机构和个人普遍采用的一种信息存储格式,其中包含了大量的结构化和半结构化数据,如各类报告、调查问卷结果、项目计划等。这些文档中的表格往往承载了关键的数据信息,如统计数据、项目进度、研究成果等。然而,手动从大量的Word文档中逐一摘取并整理这些表格不仅耗时费力,且易出错,无法满足高效、准确的数据利用需求。因此,利用编程实现批量提取Word文档中的表格成为了一种必要且高效的解决方案。Python作为一种功能强大、易学易用的编程语言,可以有效地实现这一目标,极大地提升数据采集和预处理的工作效率,同时也为后续的数据分析和应用提供强有力的支持。本文将介绍如何使用Python实现对Word文档中表格的提取。
文章目录
提取Word文档表格并保存为Excel工作表提取Word文档表格并保存为CSV文件
本文所使用的方法需要用到Spire.Doc for Python,pip:pip install Spire.Doc。如果是将表格保存到Excel工作表,则还需要用到Spire.XLS for Python,pip:pip install Spire.XLS。
提取Word文档表格并保存为Excel工作表
读取Word文档中的表格并写入Excel工作簿需要同时用到这两个库。以下是操作步骤:
创建 Document 和 Workbook 对象。使用 Document 类的 LoadFromFile() 方法载入指定路径下的 Word 文档。清除 Workbook 中的所有工作表。遍历加载的 Word 文档中的所有节(Sections)。在每个节中,遍历其包含的所有表格(Tables)。对于每一个表格,创建一个新的 Excel 工作表,并根据表格索引为其命名。遍历表格中的每一行(Rows),并获取当前行对象。再次遍历该行中的所有单元格(Cells),获取单元格对象。对于每个单元格,将其包含的段落内容合并为一个字符串(cellText)。使用 Workbook 的工作表对象的 SetCellValue() 方法将合并后的单元格文本内容写入到对应的工作表中。完成所有表格数据的写入后,使用 Workbook 的 SaveToFile() 方法将 Excel 数据保存到指定路径。
代码示例:
from spire.doc import *from spire.doc.common import *from spire.xls import *from spire.xls.common import *# 创建Document对象doc = Document()# 载入Word文档doc.LoadFromFile("示例.docx")# 创建Workbook对象wb = Workbook()wb.Worksheets.Clear()# 遍历文档中的节for i in range(doc.Sections.Count): # 获取一个节 section = doc.Sections.get_Item(i) # 遍历节中的表格 for j in range(section.Tables.Count): # 获取一个表格 table = section.Tables.get_Item(j) # 创建一个工作表 ws = wb.Worksheets.Add(f"表 { (j + 1)}") # 将表格数据写入工作表 for row in range(table.Rows.Count): # 获取一行 tableRow = table.Rows.get_Item(row) # 遍历一行中的单元格 for cell in range(tableRow.Cells.Count): # 获取一个单元格 tableCell = tableRow.Cells.get_Item(cell) # 获取单元格的内容 cellText = "" for paragraph in range(tableCell.Paragraphs.Count): paragraph = tableCell.Paragraphs.get_Item(paragraph) cellText = cellText + paragraph.Text # 将单元格的内容写入工作表 ws.SetCellValue(row + 1, cell + 1, cellText)wb.SaveToFile("output/Word表格写入Excel.xlsx", FileFormat.Version2016)doc.Close()wb.Dispose()
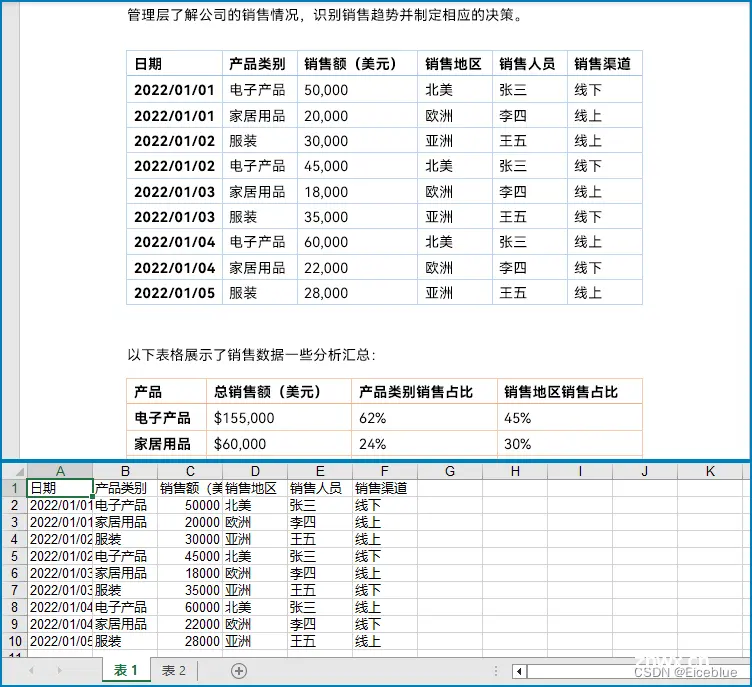
提取结果
提取Word文档表格并保存为CSV文件
CSV文件以文本的文件的形式储存表格数据,因此,我们可以直接使用Spire.Doc for Python提取Word文档中的表格数据并写入到CSV文件。以下是操作步骤:
创建 Document 对象。使用 Document 类的 LoadFromFile() 方法载入指定路径下的 Word 文档。遍历载入的 Word 文档中的所有节(Sections)。在每个节内,进一步遍历其包含的所有表格(Tables)。对于每个表格,生成对应的 CSV 文件名,并以写模式打开这个文件,设置编码为 UTF-8 并开启新行模式。创建 csv.writer 对象用于写入 CSV 文件内容。根据表格的列数动态生成 CSV 文件的标题行(列名),并用 writerow() 方法写入到CSV文件中。遍历当前表格的每一行(Rows),获取当前行对象。对于每一行中的每个单元格,只提取第一个段落的文本内容,形成一行的数据列表。使用 csv.writer 对象的 writerow() 方法将这一行的数据列表写入到对应的 CSV 文件中。在完成一个表格的所有数据写入后,关闭已打开的 CSV 文件。继续处理下一个表格,直至遍历完所有表格。
import csvfrom spire.doc import *# 创建Document对象doc = Document()# 载入Word文档doc.LoadFromFile("示例.docx")# 遍历文档中的节for i in range(doc.Sections.Count): # 获取一个节 section = doc.Sections.get_Item(i) # 遍历节中的表格 for j in range(section.Tables.Count): # 获取一个表格 table = section.Tables.get_Item(j) # 创建CSV文件名并打开文件 csv_file_name = f"output/CSV/表_{ (j + 1)}.csv" with open(csv_file_name, 'w', newline='', encoding='utf-8') as csvfile: writer = csv.writer(csvfile) # 遍历表格中的每一行 for row in range(table.Rows.Count): # 获取一行 tableRow = table.Rows.get_Item(row) # 读取一行中的单元格内容,只取每个单元格的第一个段落 row_data = [tableRow.Cells.get_Item(cell).Paragraphs[0].Text for cell in range(tableRow.Cells.Count)] # 将单元格内容写入CSV文件 writer.writerow(row_data)doc.Close()
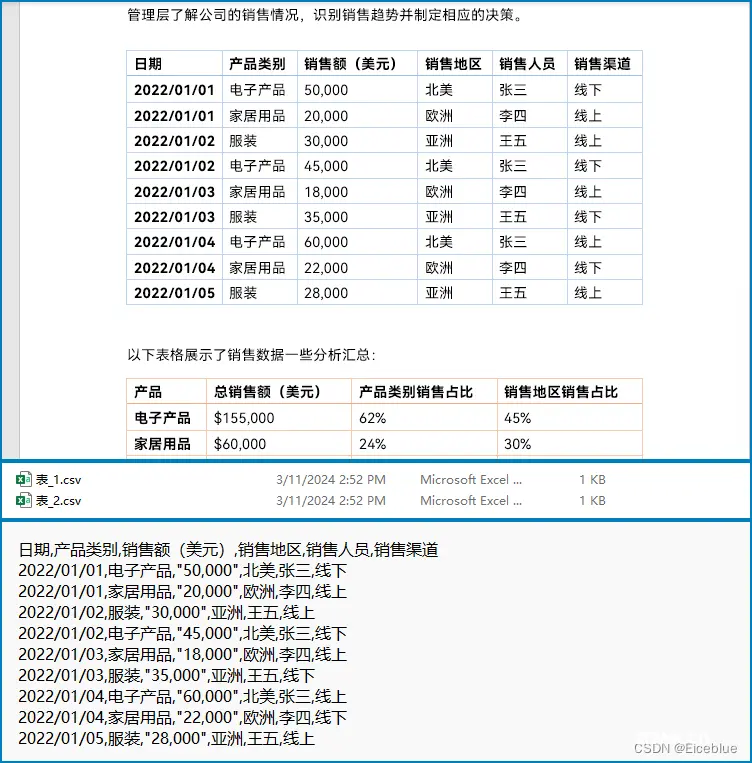
提取结果:
以上内容讲述了如何通过Python提取Word文档中的表格,并转换为Excel工作表或CSV文件。
Spire.Doc for Python还支持许多其他功能,请前往Spire.Doc for Python教程查看。
申请免费许可
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。