Python中用SpeechRecognition库和 vosk模型来识别语音
老菜鸟YDZ 2024-07-03 15:35:15 阅读 77
Python中的SpeechRecognition库是一个比较好用的语音识别模块,提供了将语音识别成文字的方法,支持中文识别。
一、SpeechRecognition库的安装
使用pip命令安装即可:
<code>pip install SpeechRecognition
当安装不成功时,可以强制:
pip install --force- SpeechRecognition
二、SpeechRecognition库的导入:
import speech_recognition as sr
r = sr.Recognizer()
注意:导入库的名称与安装名称的略有不同。
三、识别麦克风输入的语音:
# 麦克风录音
mic = sr.Microphone()
with mic as source:
print("请说话...")
r.adjust_for_ambient_noise(source)
audioData = r.listen(source)
# print(type(audioData))
四、或者直接识别语音文件:
# 识别语音文件
audioFile = sr.AudioFile("渔父.mp3")
with audioFile as source:
audioData = r.record(source)
注意语音文件“渔父.mp3”放在主程序同一文件夹中,故没有指明路径。
不管你是要识别通过麦克风现场输入的语音,还是识别现有的语音文件,最后都是通过
audioData = r.record(source)语句读取到audioData对象中,再通过语音识别模型来识别成文本。
语音识别的模型有很多,如Google Speech API,CMU Sphinx,Vosk等。我们以能线下使用的Vosk模型为例来说明使用方法。
五、安装vosk库
pip install vosk
speechrecognition提供了方便的使用vosk的函数
Recognizer.recognize_vosk(audioData)
虽然我们安装了Vosk的库,但好像其中没有包含Vosk语音模型,还需要单独下载。打开VOSK Models链接,可以看到各种语言的语音模型:

我们要识别中文,当然要下载中文语音模型:
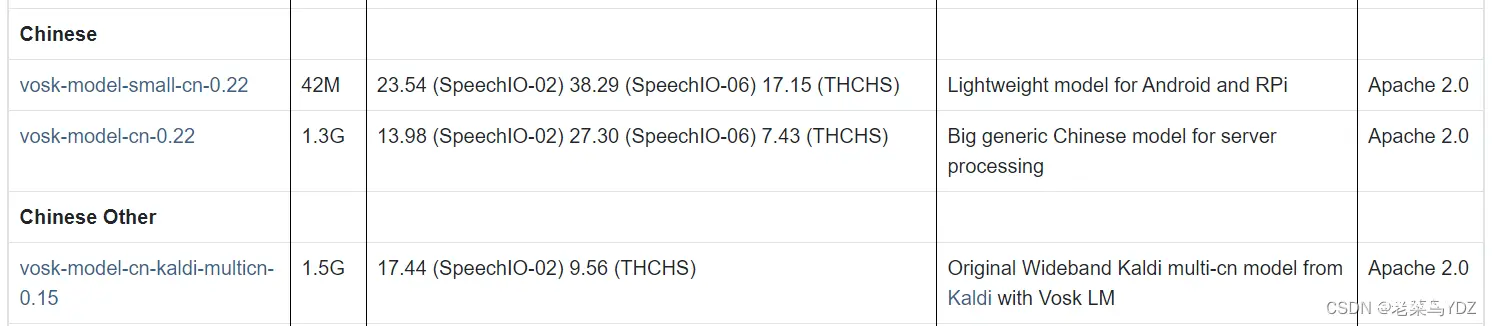
下载各个模型到主程序文件夹下,解压,将想要使用的语音模型文件名改为“model”
我试了42M和1.3G两个语音模型,好像识别效果差不多,唯一的区别是大的语音模型加载时间长。也许是我识别的古文的原因?
六、语音识别
<code>said = r.recognize_vosk(audioData) # 下载的语音模型解压后须改文件夹名为“model”
print("you said:", formulateResult(said))
七、运行结果:
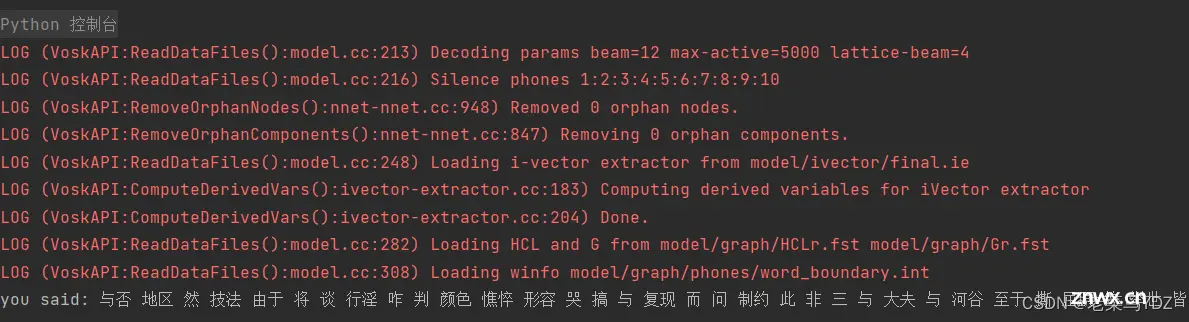
我是用现成的语音文件“渔父.mp3”来识别的。根据程序运行顺序,应是先读取“渔父.mp3”到audioData中,再加载同一文件夹下“model”中的Vosk语音模型,然后识别并显示出识别结果。
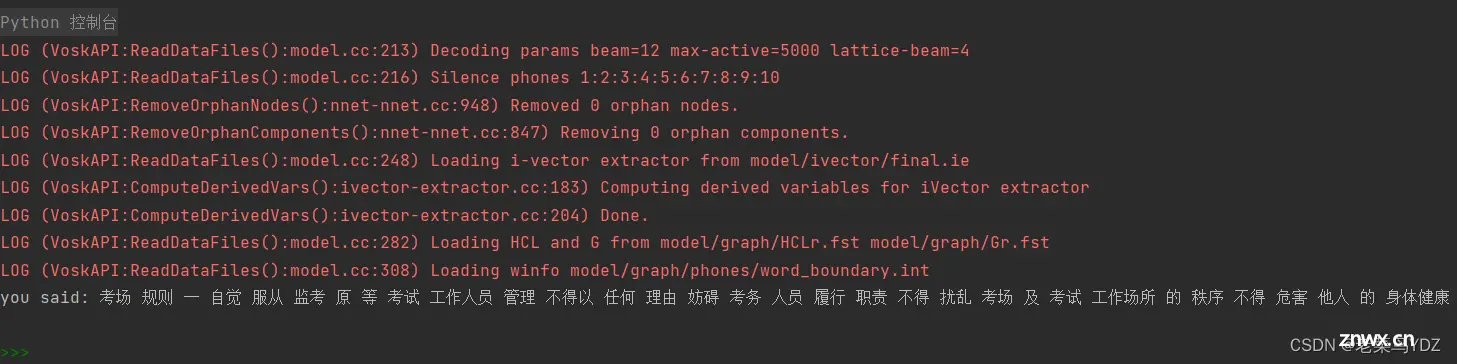
为了测试识别效果,我又用一段现代文“考场须知.mp3”来测试,识别效果还是好很多:
全文代码:
<code>import speech_recognition as sr
import vosk
import pyaudio
r = sr.Recognizer()
# model = vosk.Model("model") # 在录音后自动加载,前期加载无效
# pip install SpeechRecognition
'''
# 直接录音
mic = sr.Microphone()
with mic as source:
print("请说话...")
r.adjust_for_ambient_noise(source)
audioData = r.listen(source)
# print(type(audioData))
'''
# 使用语音文件
audioFile = sr.AudioFile("考场须知.mp3")
with audioFile as source:
audioData = r.record(source)
def formulateResult(resu):
start = resu.index('"', resu.index('"', resu.index('"') + 1) + 1) + 1
end = resu.index('"', start)
return resu[start:end]
# pip install vosk;模型网站 https://alphacephei.com/vosk/models,两个模型一大一小,大的也不见得就识别准确
# said = r.recognizer_instance.recognize_vosk(audioData)
said = r.recognize_vosk(audioData) # 下载的语音模型解压后须改文件夹名为“model”
# said = r.rec(audioData)
print("you said:", formulateResult(said))
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。