C语言—单链表
孞㐑¥ 2024-10-08 11:35:01 阅读 91
目录
一、链表的概念及结构
二、单链表实现
(2.1)基本结构定义
(2.2)申请节点
(2.3)打印函数
(2.4)头部插入删除\尾部插入删除
(2.4.1)尾部插入
(2.4.2)头部插入
(2.4.3)尾部删除
(2.4.4)头部删除
(2.5)查找
(2.6)在指定位置之前插入数据
(2.7)删除pos节点
(2.8)在指定位置之后插入数据
(2.9)删除pos之后的节点
(2.10)销毁链表
三、链表的分类
一、链表的概念及结构
概念:链表是⼀种物理存储结构上⾮连续、⾮顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表的结构跟⽕⻋⻋厢相似,如图所示:

与顺序表不同的是,链表⾥的每节"⻋厢"都是独⽴申请下来的空间,我们称之为“结点/节点”。节点的组成主要有两个部分:当前节点要保存的数据和保存下⼀个节点的地址(指针变量)。图中指针变量 plist 保存的是第⼀个节点的地址,我们一般称之为头指针。链表中每个节点都是独⽴申请的(即需要插⼊数据时才去申请⼀块节点的空间),所以我们需要通过指针变量来保存下⼀个节点位置才能从当前节点找到下⼀个节点。
补充说明:
1、链式机构在逻辑上是连续的,在物理结构上不⼀定连续
2、节点⼀般是从堆上申请的
3、从堆上申请来的空间,是按照⼀定策略分配出来的,每次申请的空间可能连续,可能不连续
二、单链表实现
注意:这里的单链表指的是不带头单向不循环链表(后面会介绍链表的分类)
(2.1)基本结构定义

为了单链表的复用性,这里将 int 重命名为SLTDataType,单链表节点中包含一个数据域(data),一个指针域(next),数据域存放需要存放的数据,指针域存放下一个节点的地址。这里为了方便后续使用又将struct SListNode 重命名为SLTNode。
(2.2)申请节点
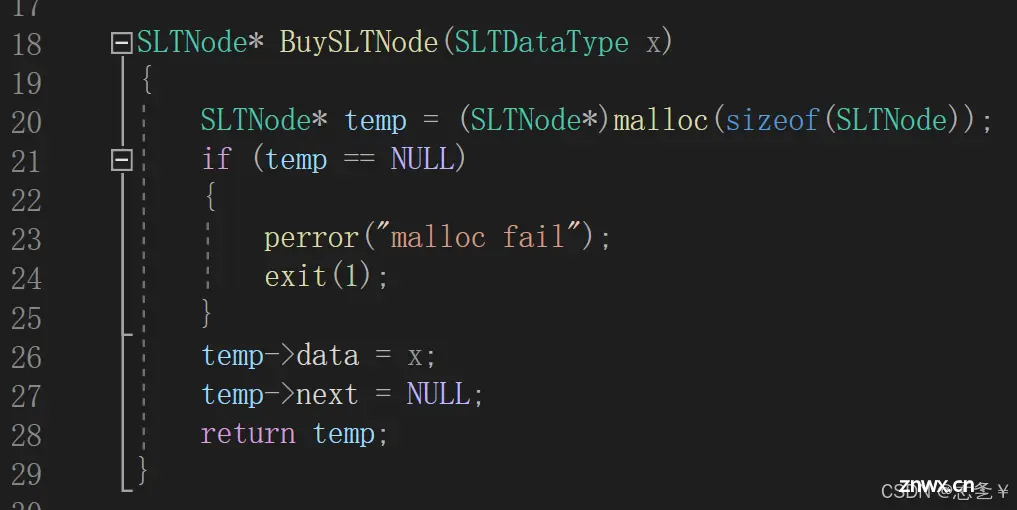
后续插入节点的函数都需要先申请节点,所以这里直接写一个申请节点的函数,方便后面使用,在该函数中,首先用malloc申请一块节点大小的空间,然后判断是否申请成功,如果申请失败,用perror函数报错,然后结束程序,如果申请成功,将数据插入,并将指针域置空,然后返回节点地址。(形参是要插入的数据)
(2.3)打印函数

为了后续测试中方便查看单链表中的数据,我们这里实现一个打印函数,功能是打印单链表中的所有数据。
具体实现:

解释:形参是指向整个单链表头部的指针,要打印单链表中的数据,首先单链表不能为空,如果是空表没有数据可打印,所以先断言头指针不为空,然后定义一个临时变量 cur 记录链表头部的地址(即将头指针赋给cur),然后以 cur 作为循环条件,每次进入循环,打印当前节点存储的数据,打印后将指针向后移动,当打印完最后一个节点数据后,指针移动到NULL,循环结束。最后可以再打印一个换行。
(2.4)头部插入删除\尾部插入删除

(2.4.1)尾部插入
具体实现:
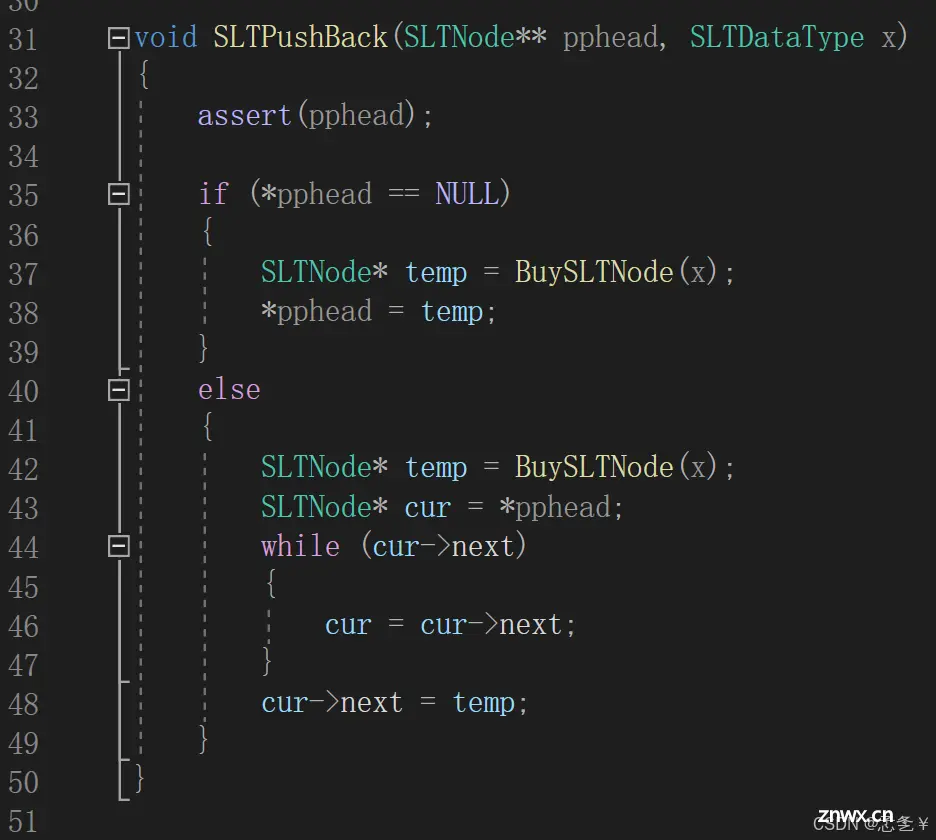
思路:遍历找到尾节点,然后将新节点连接上,如果链表为空,直接将新节点作为头。
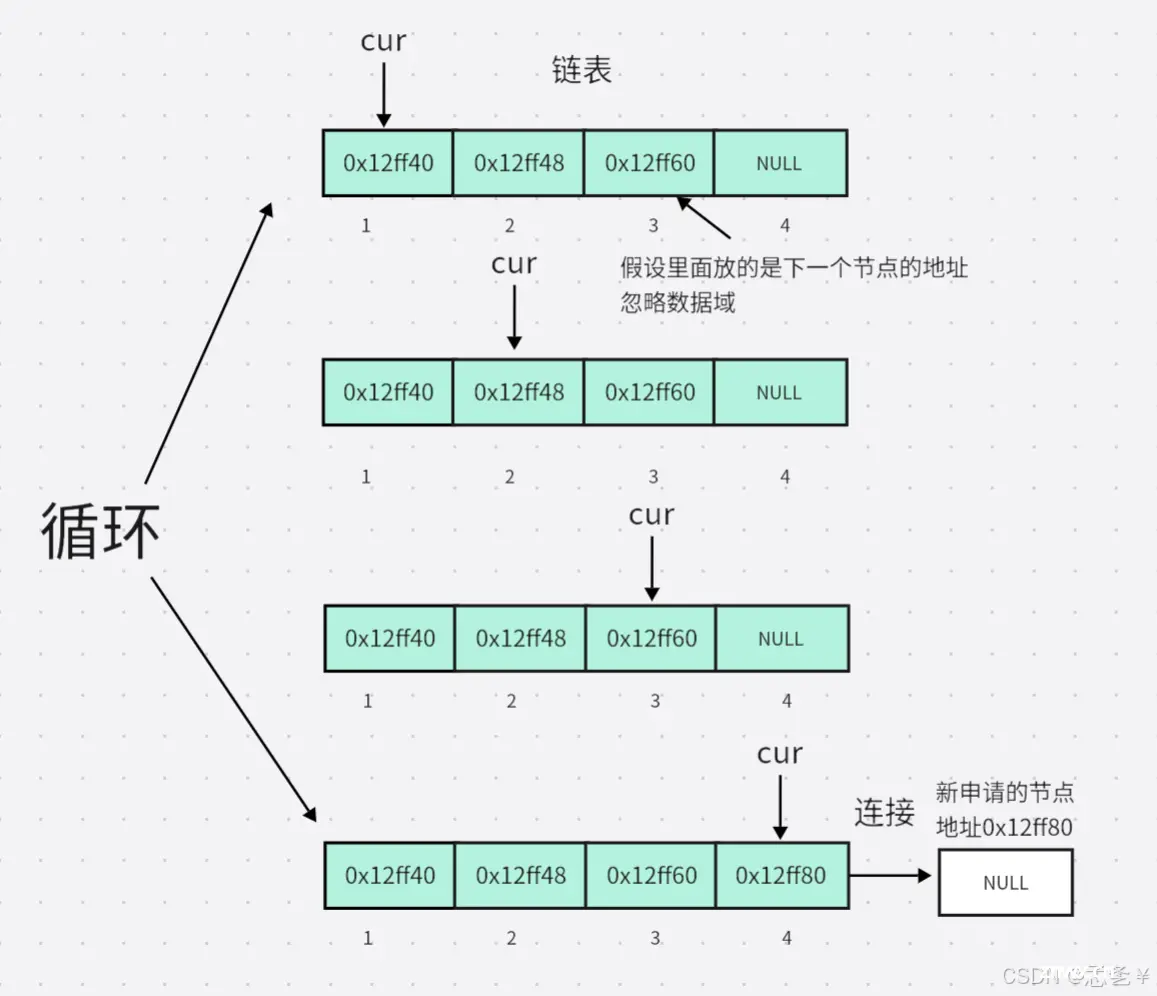
解释:该函数中有两个形参,一个是二级指针,指向单链表的头指针,一个是要插入的数据,首先这里的二级指针一定不可以为空,如果二级指针为空,我们将无法找到链表,所以先断言二级指针不为空,然后判断当前链表是否为空,如果链表为空,直接将新申请的节点置为表头(即直接让头指针指向该节点,注意这里的pphead是二级指针,要先解引用才是头指针),如果链表不为空,先定义一个临时指针指向链表头部,然后当 cur 的 next 不为空的时候进行循环,出循环时 cur 一定指向尾节点,因为链表中每个节点(除尾节点)中的指针域存的都是下一个节点的地址,而最后一个节点后面已经没有节点了,所以它的指针域存的是NULL,而循环结束的条件就是 cur 指针域为NULL。找到尾节点后,将新申请的节点插入即可。
图解:
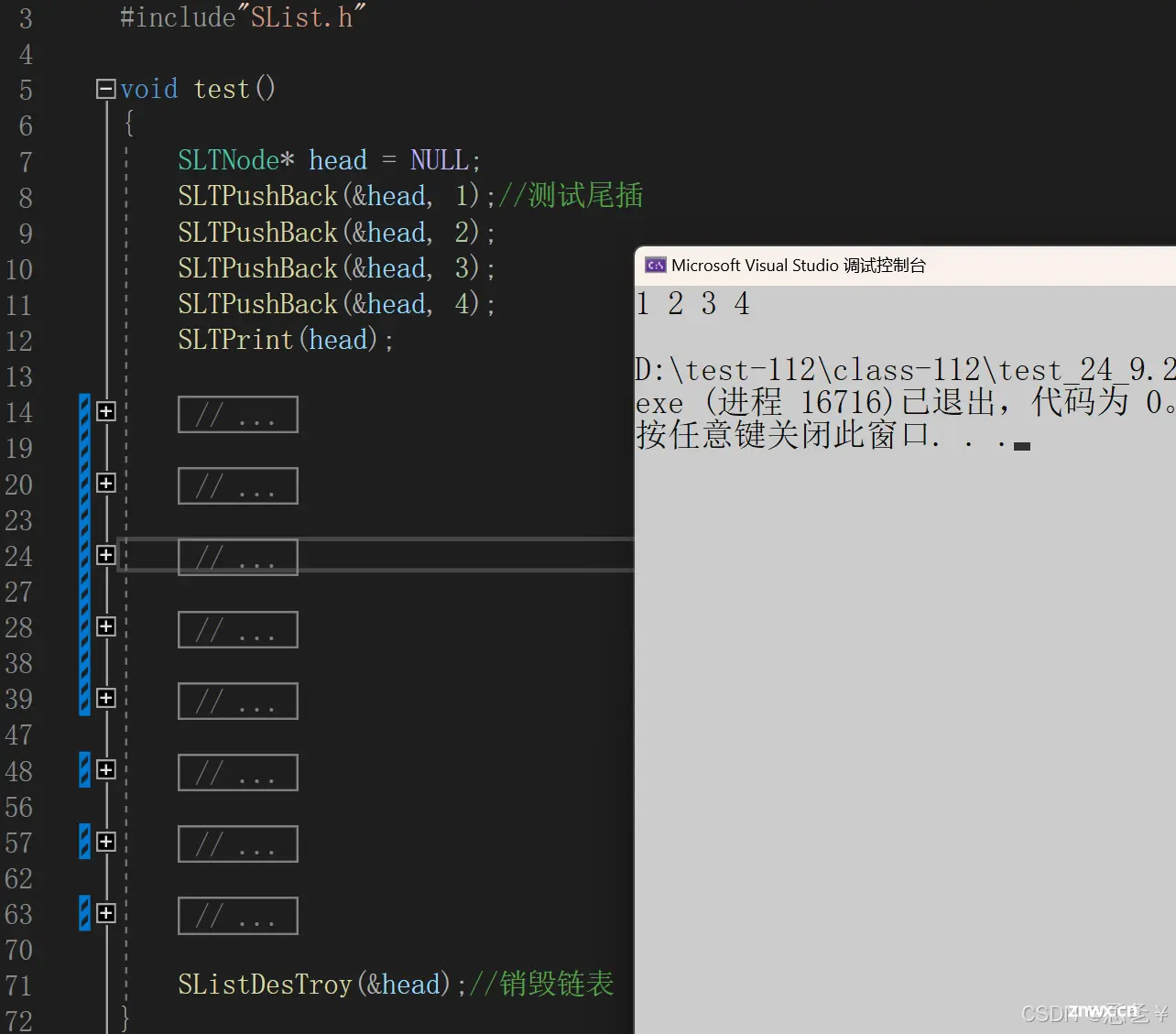
测试:
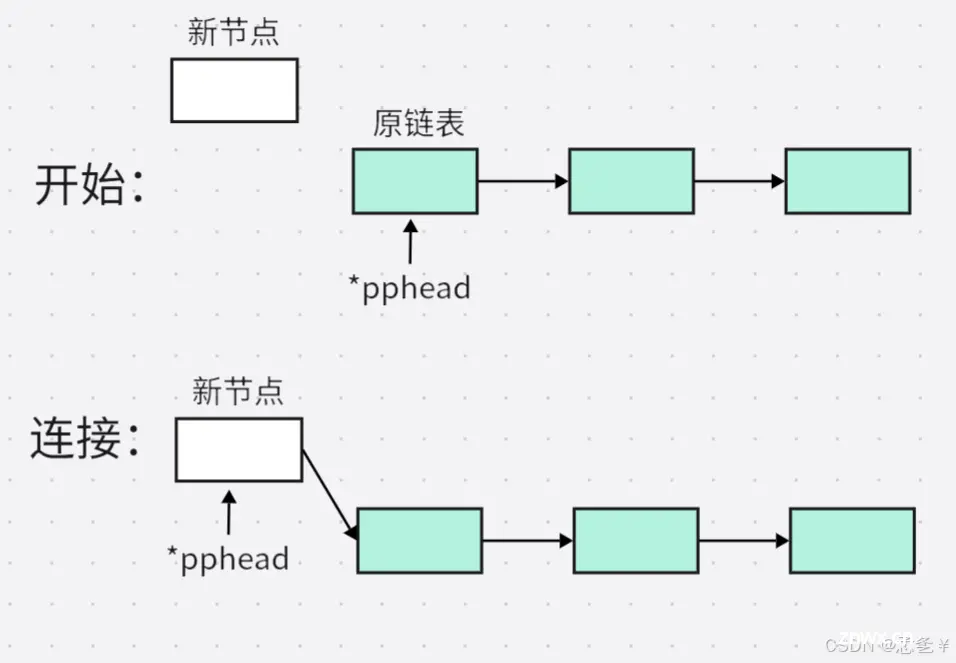
(2.4.2)头部插入
具体实现:

解释:该函数中有两个形参,一个是二级指针,指向单链表的头指针,一个是要插入的数据,首先这里的二级指针一定不可以为空,如果二级指针为空,我们将无法找到链表,所以先断言二级指针不为空,然后直接申请新节点,新节点的指针域存原链表的头,然后将新节点赋给头指针,这样新节点就插入到原链表的头部了并且成为新链表的头。
图解:
测试:

(2.4.3)尾部删除
具体实现:
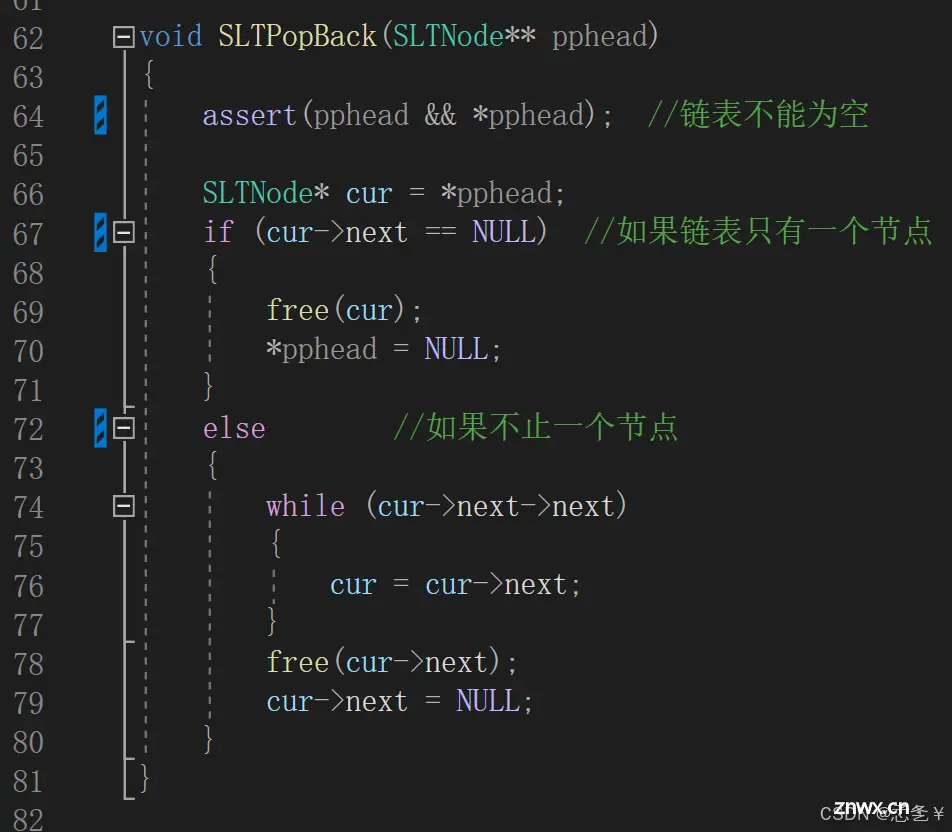
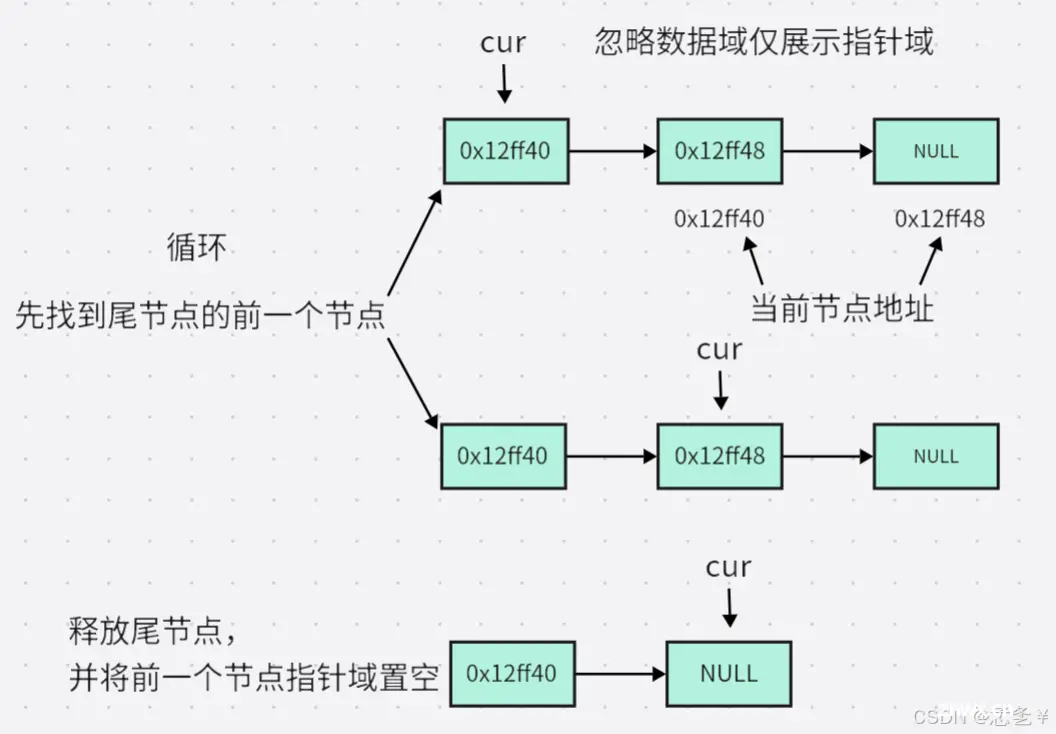
思路:遍历找到尾节点的前一个节点,释放尾节点,然后将尾节点的前一个节点指针域置空,如果链表只有一个节点,直接释放就行,但是要将头指针置空。
解释:该函数只有一个参数,即指向头指针的二级指针,这里和上面一样二级指针一定不可以为空,又因为是删除,链表一定要存在,所以头指针也不可以为空,所以先断言这两个指针不为空,尾删分为两种情况,当链表只有一个节点时,删除后链表为空,这时要将头指针置空,当链表不止一个节点时,通过循环找到尾节点的前一个节点,然后释放最后一个节点,因为尾节点已经被释放了(即将空间还给操作系统了),所以尾节点的前一个节点的 next 指针要置空,成为新的尾节点,这里之所以要找尾节点的前一个节点,而不直接找尾节点也是因为 next 指针置空的问题,如果直接找尾节点,因为是单链表,无法获得它的前驱节点,想要将前驱节点的 next 指针置空就会变麻烦。
图解:
测试:
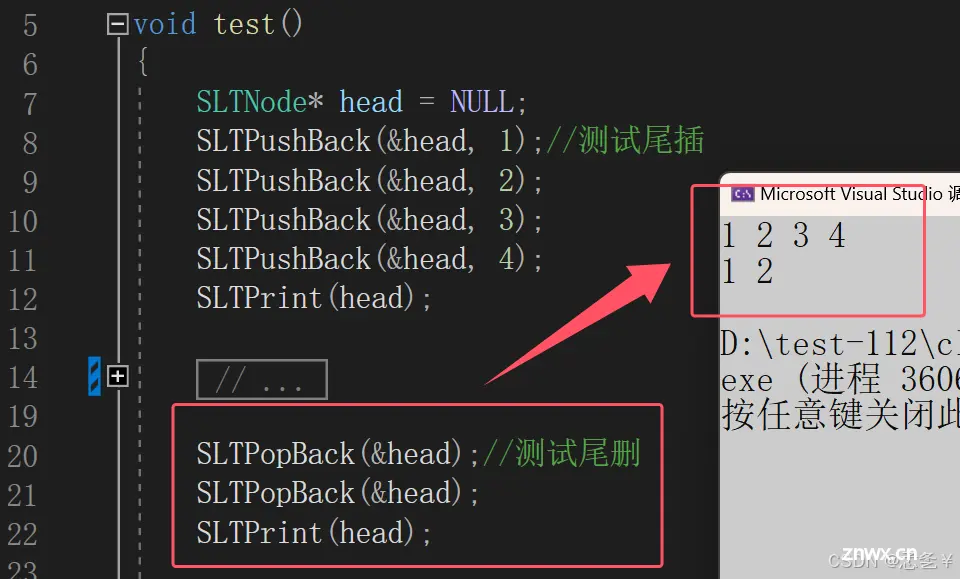
(2.4.4)头部删除
具体实现:

解释:该函数只有一个参数,即指向头指针的二级指针,和前面一样,二级指针一定不可以为空,又因为该函数的功能是删除,所以链表不可以为空,即头指针不可以为空,所以先断言这两个指针不为空,然后定义一个临时指针变量记录头节点的下一个节点的地址,释放当前头节点,将记录的后一个节点变为新的头节点,这里一定要先去记录后一个节点的位置,否则释放后就找不到了。如果当前链表只有一个节点也没事,因为它的指针域里存的是NULL,释放头节点后就将NULL给了头指针,这时链表就变为空链表了。
图解:
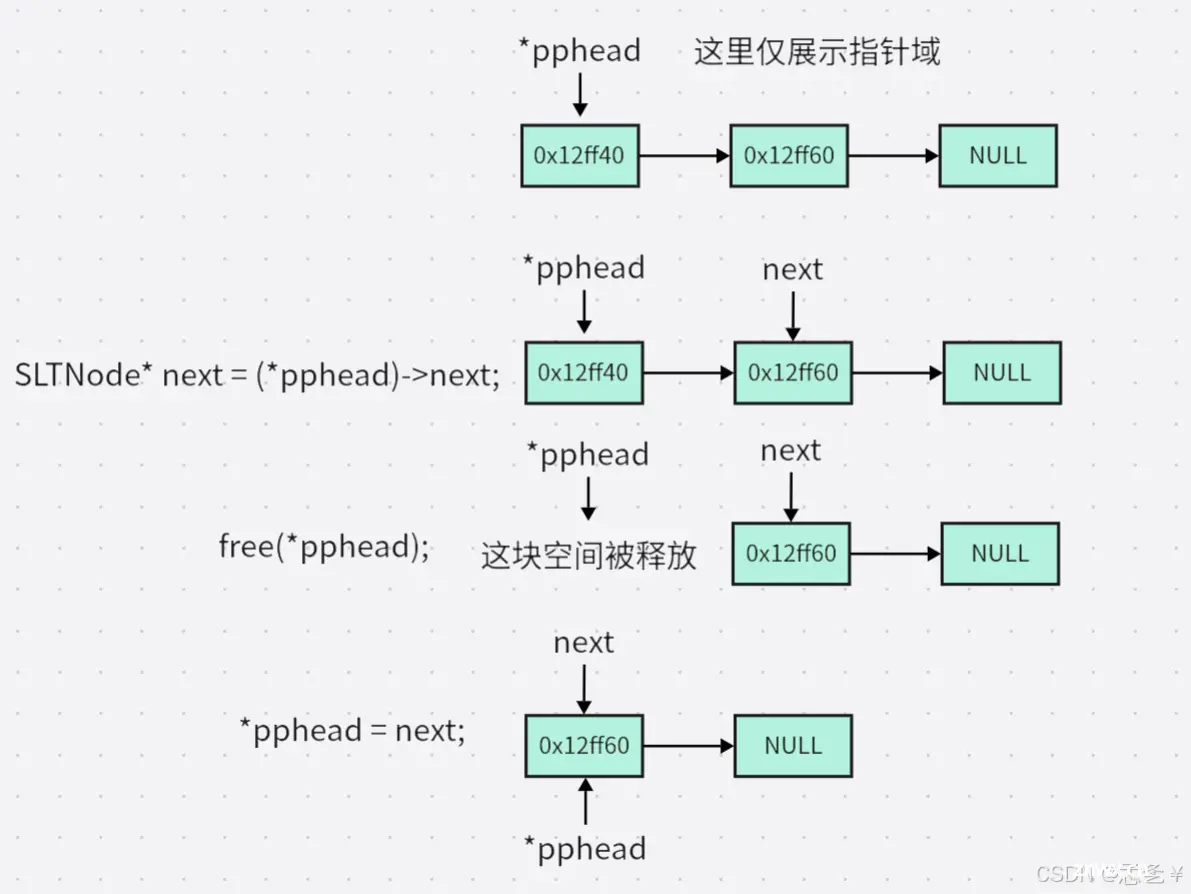
测试:
(2.5)查找

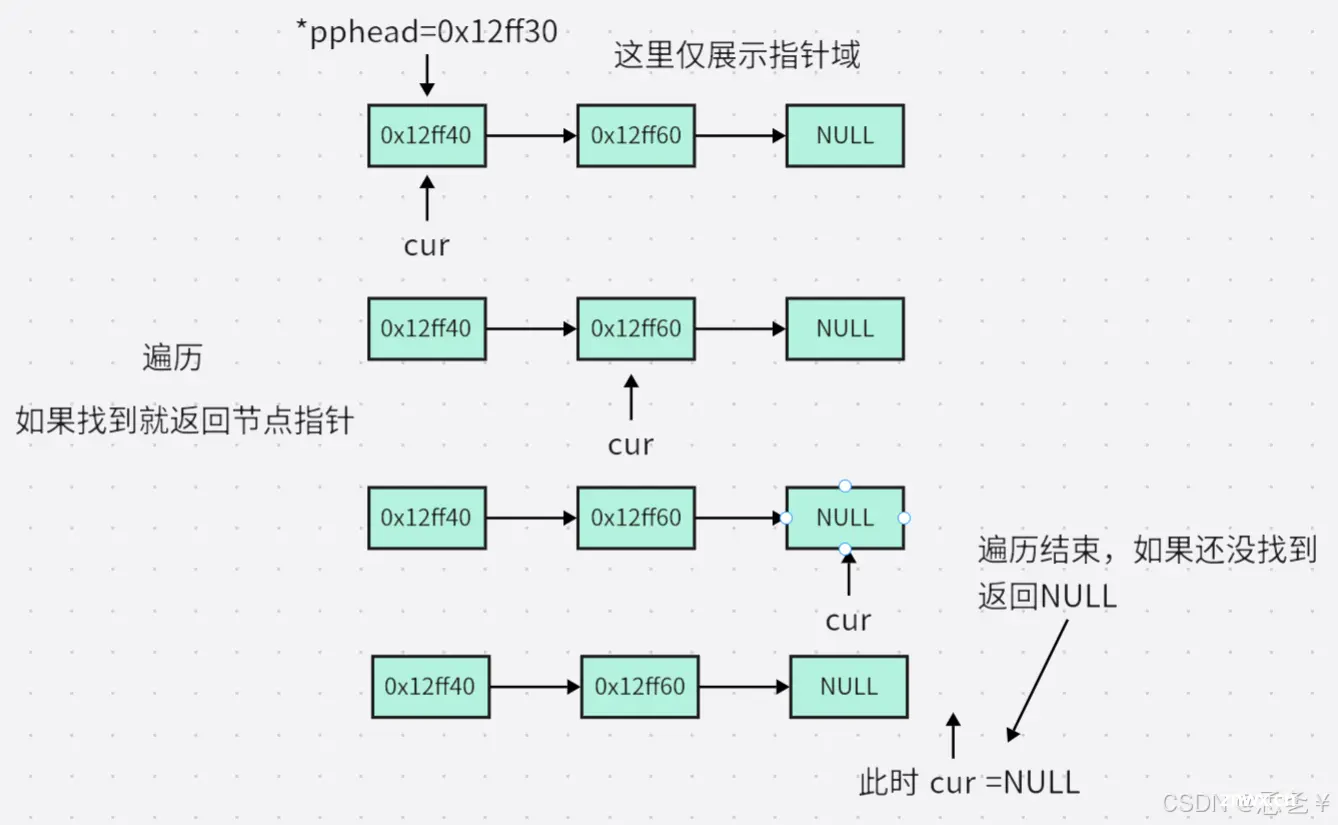
思路:遍历链表,对比数据域,如果相同则找到,返回节点地址,如果遍历结束还没有找到,则链表中没有该数据,返回空。
功能:给出链表的头指针和要查找的数据,该函数会在该链表中进行查找,如果找到,返回存储该数据的节点,如果没找到,返回NULL。
具体实现:

解释:该函数一共两个形参,第一个是链表的头指针,第二个是要查找的数据,因为后面要进行遍历链表,而头指针要始终指向链表头部,不能随意移动,所以先定义一个临时变量记录头指针,然后作为循环条件进行遍历,对比数据,一样就找到了,返回节点,结束函数,不一样就向后移动,访问下一个节点,如果遍历结束还没有找到说明链表中没有该数据,返回NULL。
图解:
测试:
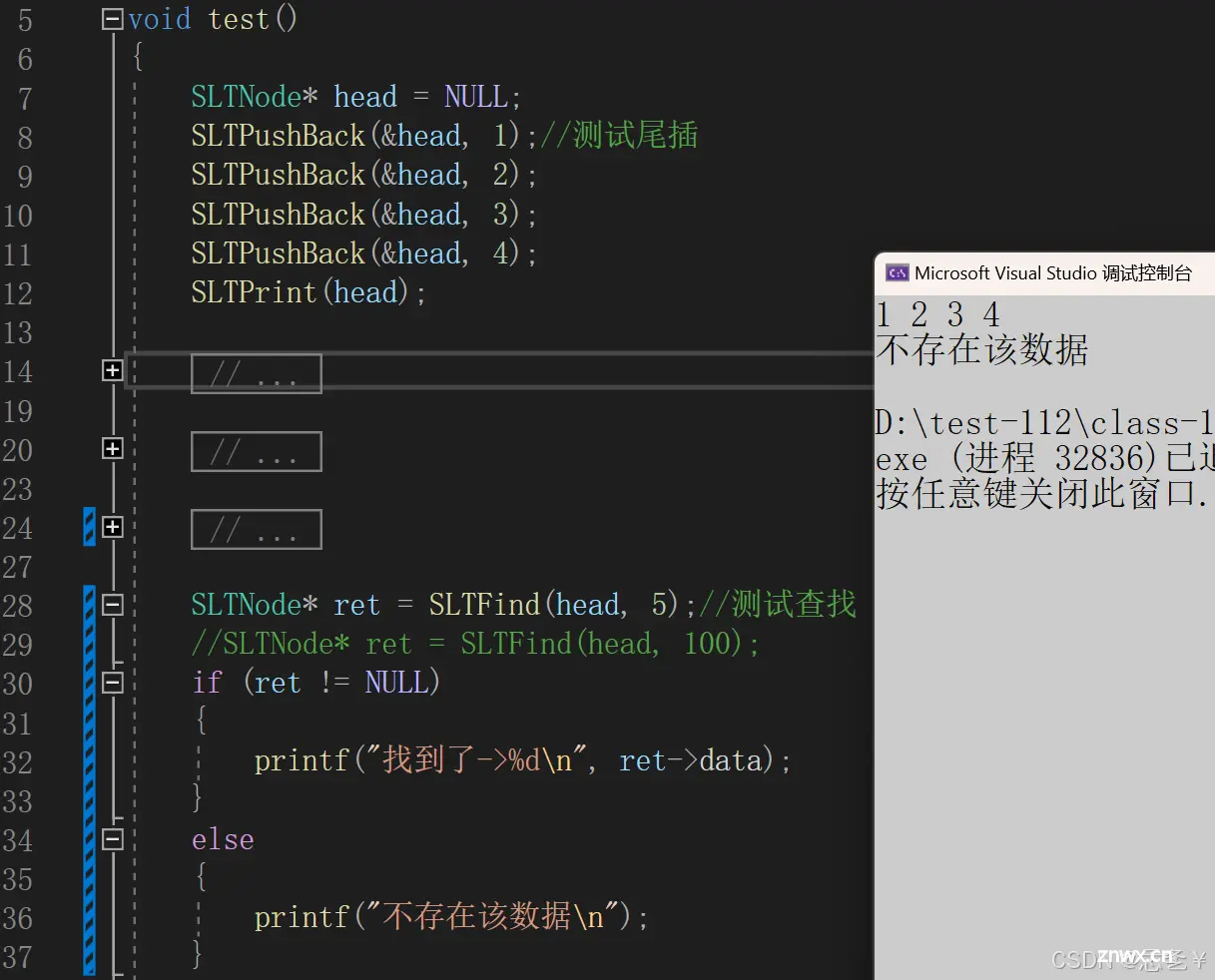
(2.6)在指定位置之前插入数据

具体实现:
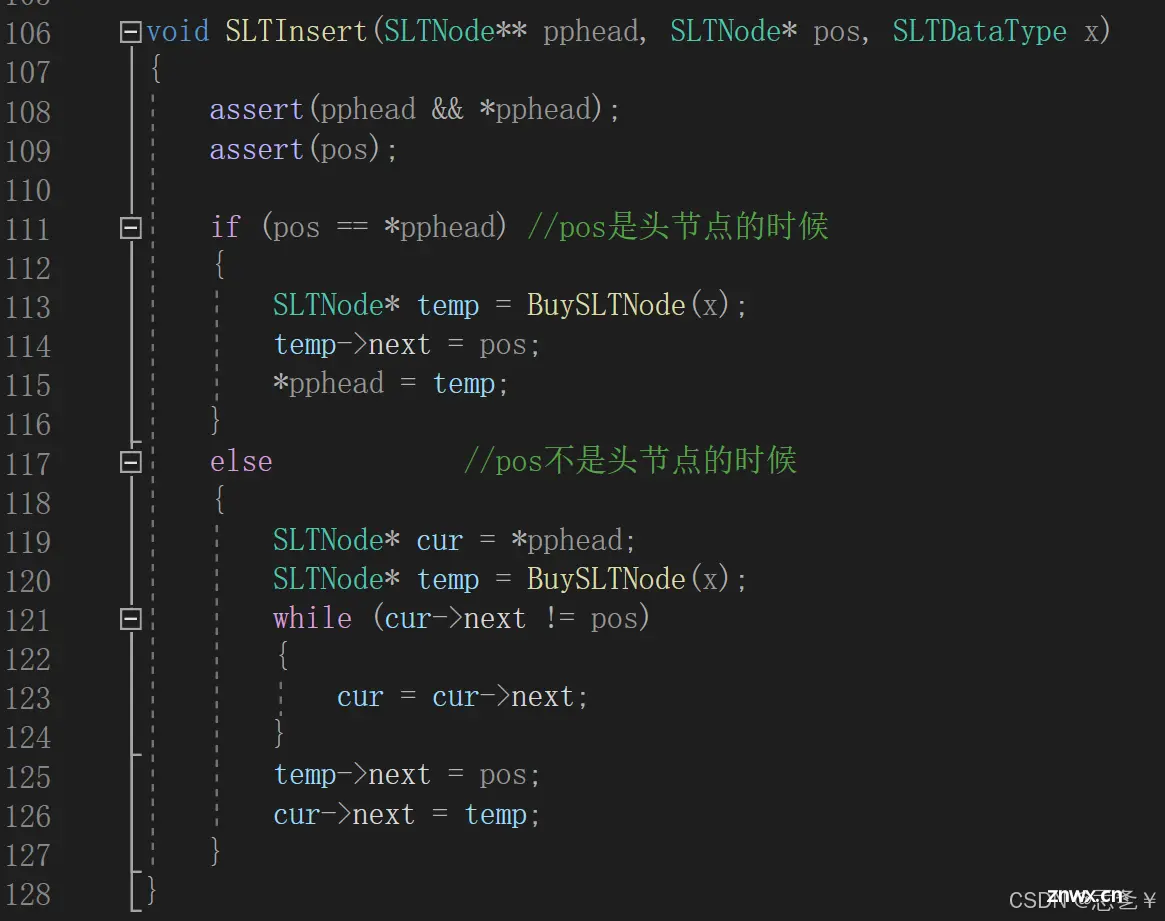
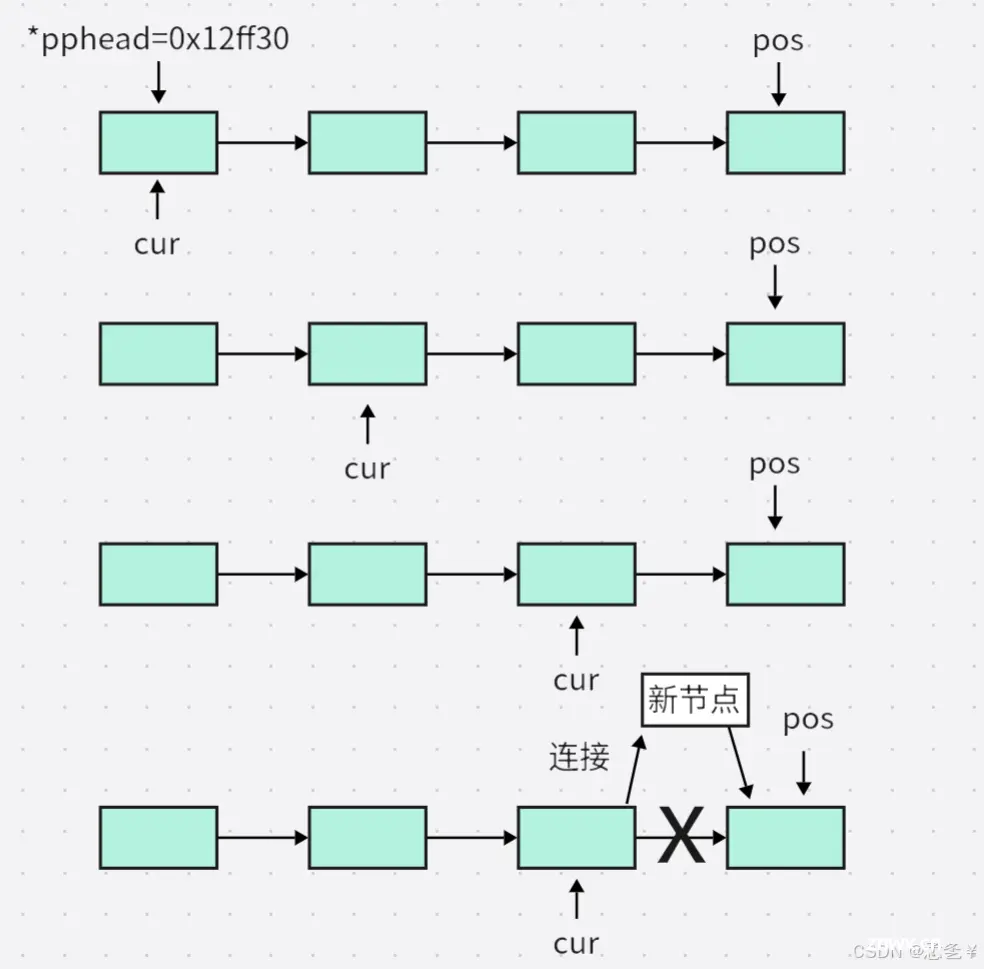
解释:该函数有三个参数,第一个是指向头指针的二级指针,第二个是指定节点位置(可以配合查找函数确定),第三个要存储的数据。二级指针和前面一样,还是不可以为空,否则找不到链表,指定位置之前插入,其实就是指定节点之前插入,所以这个节点必须存在,又因为这个节点的存在,所以链表一定不为空,所以先进行这三个条件的断言,这里插入分为两种情况,第一种情况,当pos是头节点的时候,在头节点之前插节点,其实就是前面的头插法,这里可以调用前面写好的头插函数(SLTPushFront),也可以像我一样自己写一下,第二种情况,当pos不是头节点的时候,我们需要遍历链表,找到pos的前驱节点,然后将新节点插入,因为这是单链表,所以我们没法通过pos节点向前插入节点,必须找到他的前驱节点。
图解:
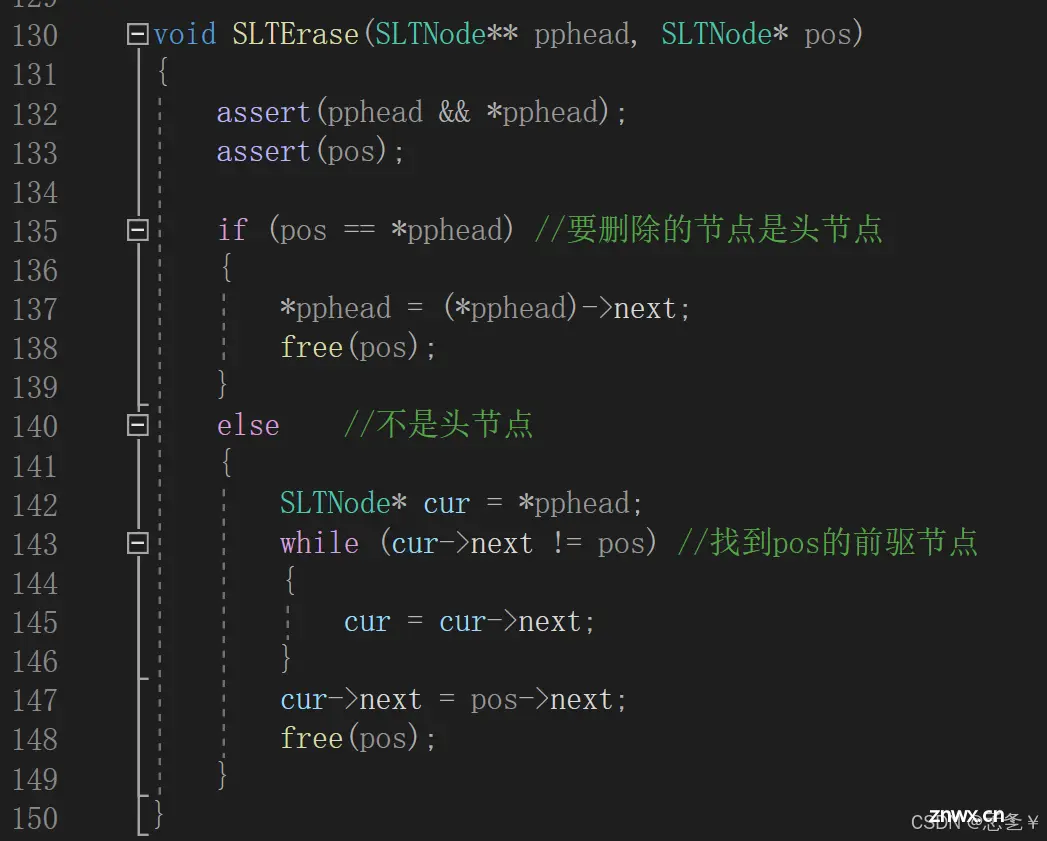
(2.7)删除pos节点

思路:两种情况,第一种:要删除的是头节点时,因为头节点被删除,所以头指针要进行移动。第二种:删除的不是头节点,头指针不需要移动,如果先删除pos节点,我们就没有办法找到pos节点后面的节点了,所以先找到pos节点的前驱节点,然后将pos节点的前驱节点和后面的节点连接起来,再去删除pos节点。
具体实现:
(2.8)在指定位置之后插入数据

思路:首先想在pos位置之后插入数据,pos节点一定要存在,然后先让新节点的指针域存pos节点后面节点的地址,然后再让pos节点的指针域存新节点的地址,顺序不能颠倒,如果先让pos节点指针域存新节点,那么就无法找到pos后面的节点。
具体实现:

(2.9)删除pos之后的节点

思路:删除pos节点之后的节点,pos节点必须存在,正常情况下,pos后面那个要删的节点也必须存在,所以可以对这两个节点都断言一下,这里我用了 if 语句,允许pos后面没有节点,当没有节点时,函数不会做任何事,直接结束,如果有,先将要删除的节点记录下来,然后将pos和要删除的节点的后面的节点连接起来,如果前面没有记录要删除的节点,这里连接后就找不到要删除的节点了。然后释放要删除的节点就可以了。
具体实现:

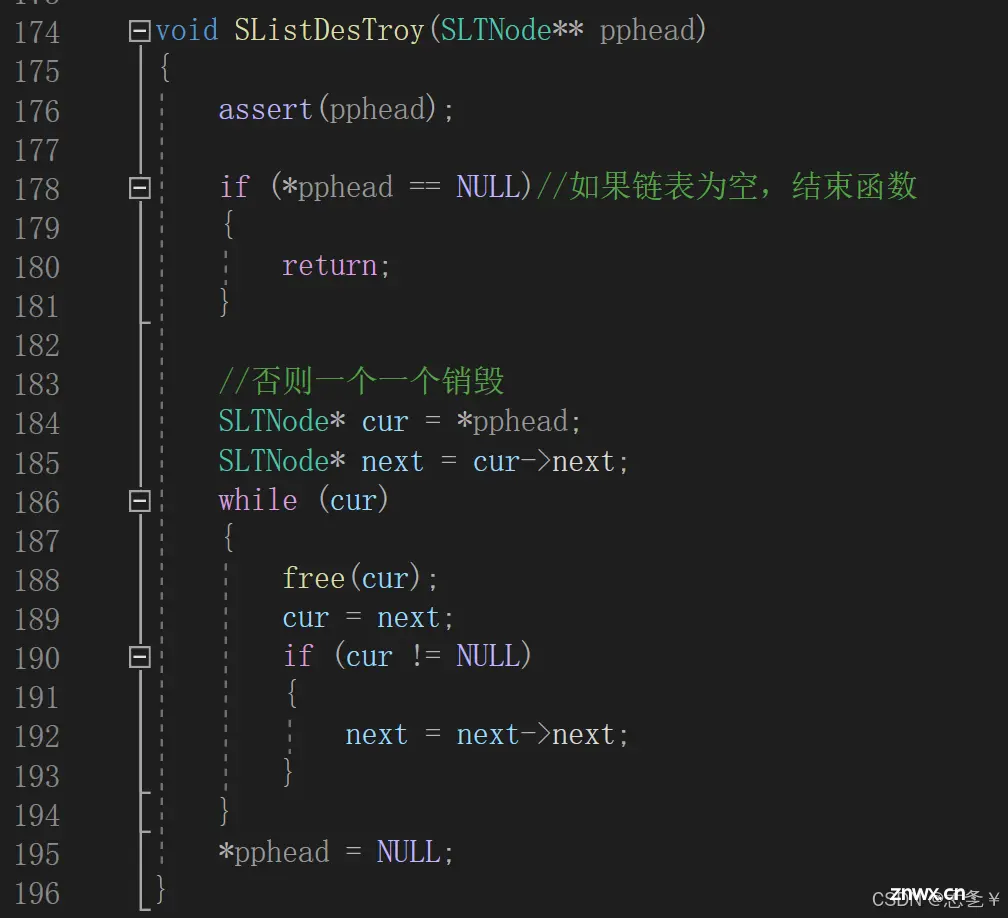
(2.10)销毁链表

思路:要找到链表,二级指针不能为空,如果当前链表已经为空了,函数结束,不会做任何事;如果链表不为空,定义两个指针,一个记录当前要释放的节点,一个记录释放的节点后面的节点,因为释放后就无法找到它后面的节点了,这里先记录下来,这样就可以在删除节点后将记录要释放节点的指针移动到链表的下一个节点,然后继续释放,直到循环到所有节点都被释放,这里当cur为空时,已经释放了所有节点,next 此时也为空,没必要再向后移动了,所以用 if 判断一下。
具体实现:
三、链表的分类
链表的结构⾮常多样,以下情况组合起来就有8种(2x2x2)链表结构:
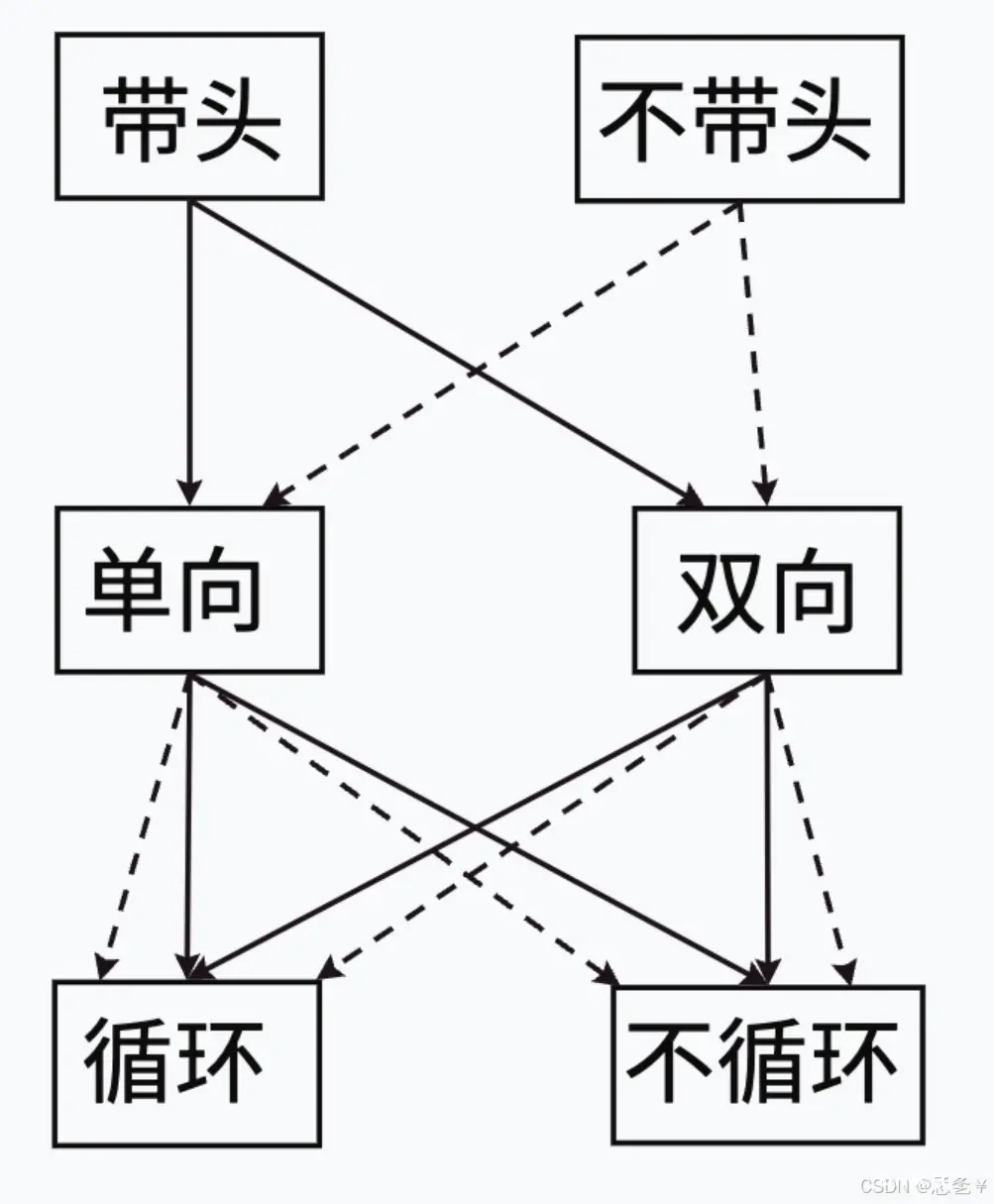
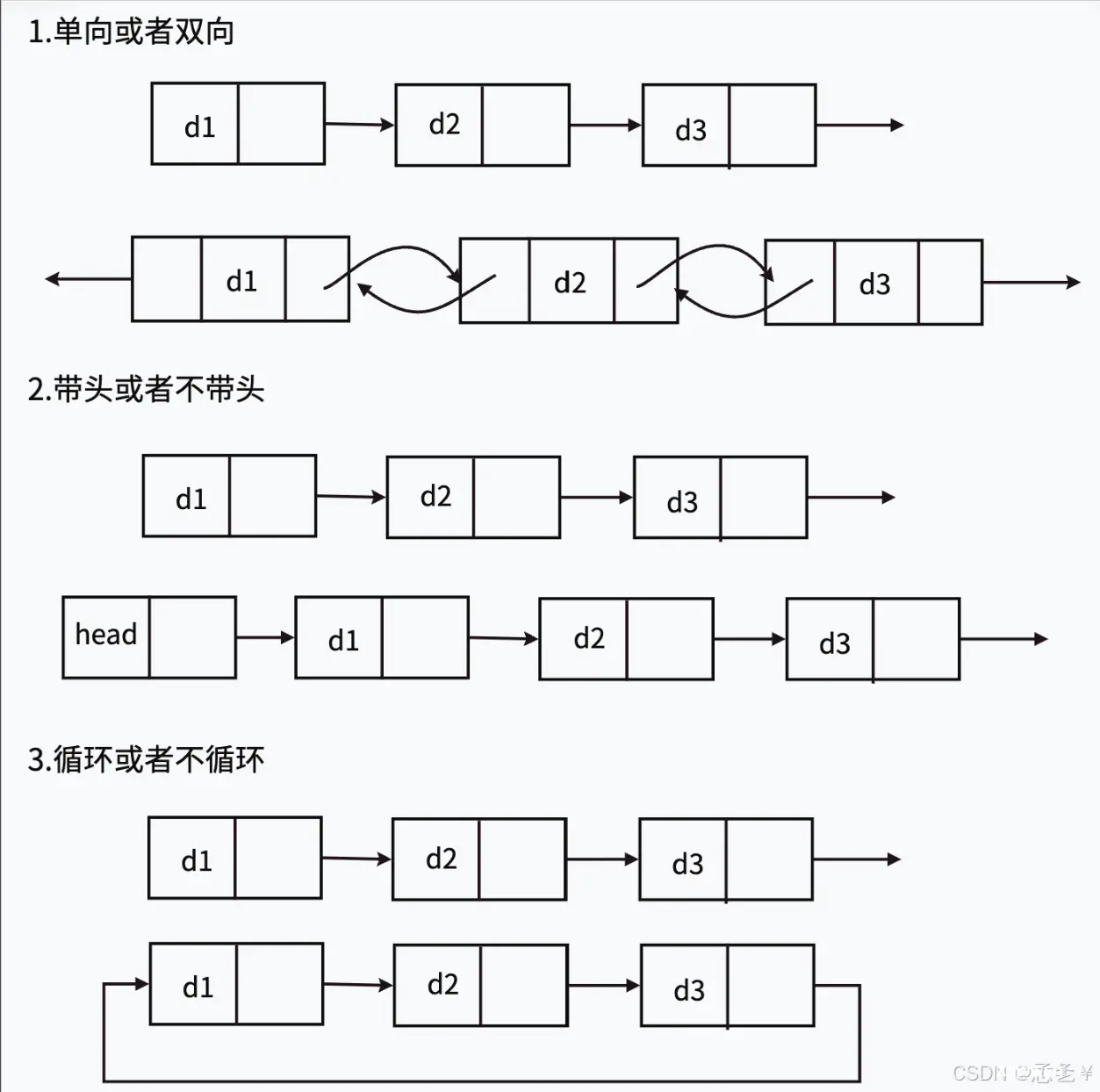
虽然有这么多的链表的结构,但是我们实际中最常⽤还是两种结构:单链表和双向带头循环链表。
1.⽆头单向⾮循环链表:结构简单,⼀般不会单独⽤来存数据。实际中更多是作为其他数据结构的⼦结构,如哈希桶、图的邻接表等等。另外这种结构在笔试⾯试中出现很多。
2.带头双向循环链表:结构最复杂,⼀般⽤在单独存储数据。实际中使⽤的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使⽤代码实现以后会发现结构会带来很多优势,实现反⽽简单了。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。