Python 爬虫入门(一):从零开始学爬虫 「详细介绍」
blues_C 2024-08-24 08:05:02 阅读 81
Python 爬虫入门(一):从零开始学爬虫 「详细介绍」
前言1.爬虫概念1.1 什么是爬虫?1.2 爬虫的工作原理
2. HTTP 简述2.1 什么是 HTTP?2.2 HTTP 请求2.3 HTTP 响应2.4 常见的 HTTP 方法
3. 网页的组成3.1 HTML3.2 CSS3.3 JavaScript
4. 使用 Python 进行 Web 爬虫4.1 常用的 Python 库4.2 安装所需库4.3 编写一个简单的爬虫4.4 示例代码
5. 处理复杂的网页5.1 使用 Playwright 示例
6. 编写一个完整的爬虫项目6.1 项目要求6.2 项目步骤6.3 示例代码
7. robots.txt 文件是什么?8. 注意事项
总结
前言
欢迎来到“Python 爬虫入门”系列的第一篇文章。你有没有想过,怎么能从网页上自动抓取你需要的数据?比如,一次性下载所有喜欢的图片,或者获取最新的新闻资讯。其实,这就是网络爬虫能做的事情。Python 是一门非常受欢迎的编程语言,简单易学,而且有很多强大的库可以用来编写网络爬虫。即使你是编程新手,也不用担心,这个系列会从最基础的知识讲起,带你一步步掌握写爬虫的技能。在这篇文章里,我们会先聊聊什么是网络爬虫,它是怎么工作的,然后教你如何安装和配置开发环境、如何使用 Python 编写爬虫脚本。
1.爬虫概念
1.1 什么是爬虫?
网络爬虫,也称为网络蜘蛛、网络机器人,是一种自动化脚本或程序,用于自动浏览互联网并收集数据。
爬虫可以帮助我们从网页中提取信息,从而实现数据采集、信息检索、网站分析等功能。
1.2 爬虫的工作原理
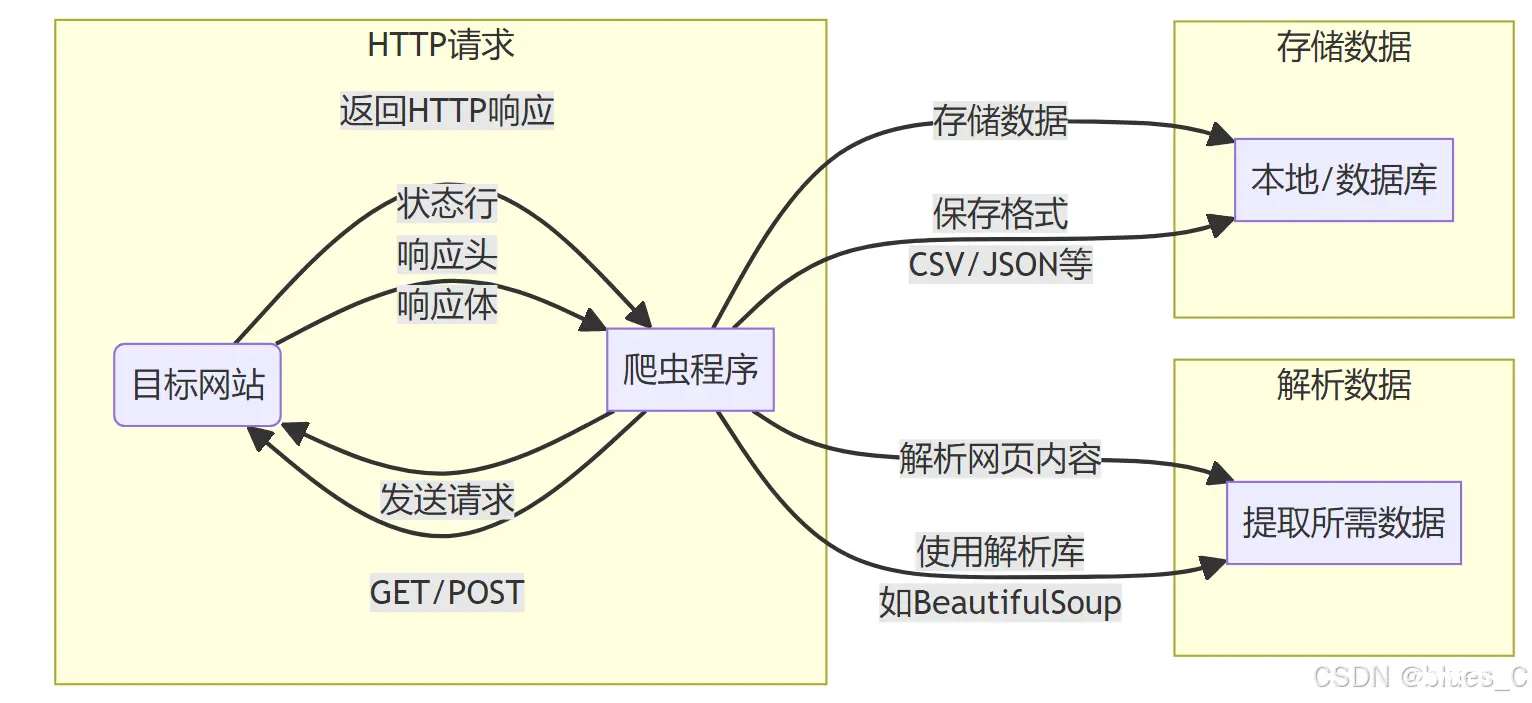
发送请求:爬虫向目标网站发送 HTTP 请求。获取响应:目标网站返回 HTTP 响应,包含请求的网页内容。解析数据:爬虫解析网页内容,提取所需数据。存储数据:将提取的数据存储在本地或数据库中。
2. HTTP 简述
2.1 什么是 HTTP?
HTTP(HyperText Transfer Protocol)是用于在 Web 浏览器和 Web服务器之间传递信息的协议。它是一种基于请求 - 响应模式的协议,客户端发送请求,服务器返回响应。
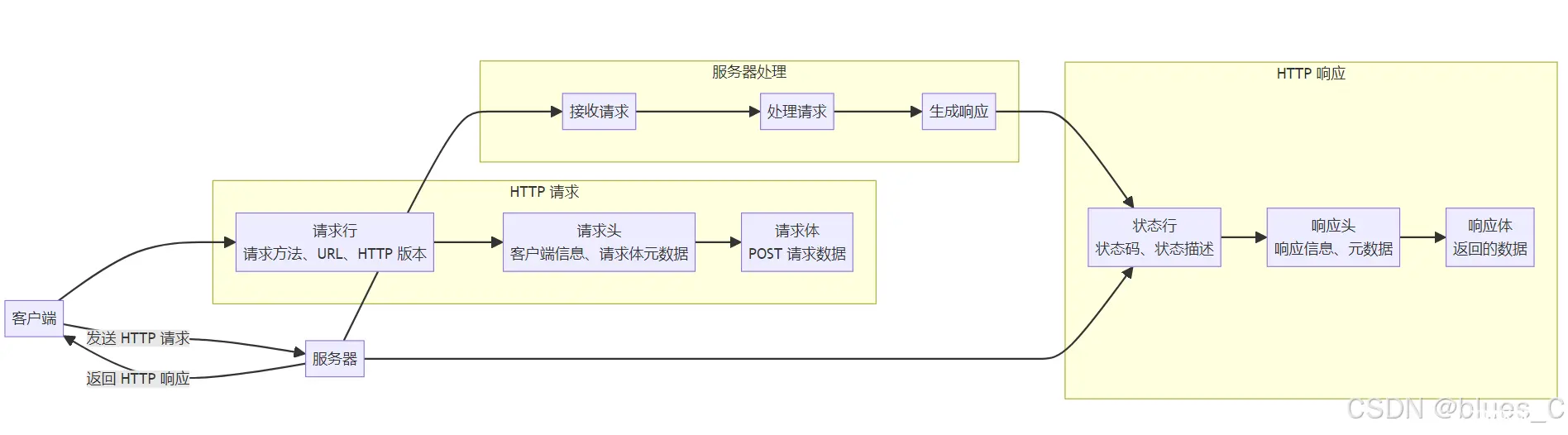
2.2 HTTP 请求
HTTP 请求由以下几个部分组成:
请求行:包括请求方法(如 GET、POST)、请求 URL 和 HTTP 版本。请求头:包含有关客户端环境的信息和请求体的元数据。请求体:在 POST 请求中,包含要发送到服务器的数据。
2.3 HTTP 响应
HTTP 响应由以下几个部分组成:
状态行:包括 HTTP 版本、状态码和状态描述。响应头:包含有关服务器环境的信息和响应体的元数据。响应体:包含实际的响应内容,如 HTML 文档、图像或其他数据。
2.4 常见的 HTTP 方法
GET:请求指定的资源。一般用于请求数据。POST:向指定的资源提交数据进行处理。PUT:向指定资源位置上传最新内容。DELETE:请求删除指定的资源。HEAD:类似于 GET,但只返回响应头,不返回响应体。
3. 网页的组成
一个典型的网页由以下几个部分组成:
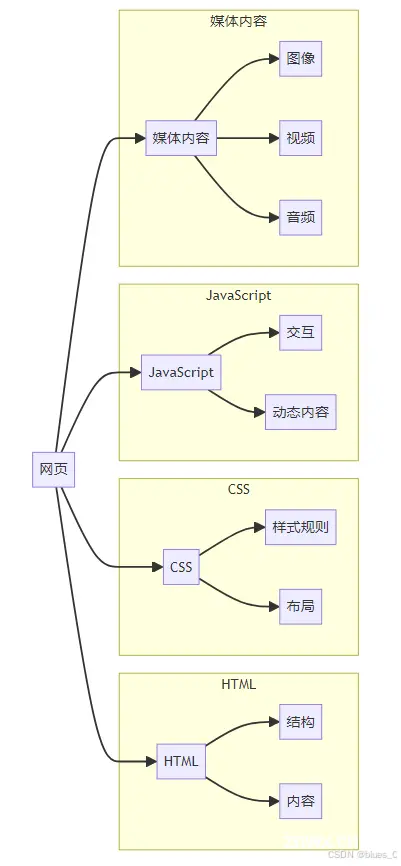
3.1 HTML
HTML(HyperText Markup Language)是用于创建和结构化网页内容的标准标记语言。HTML 使用标签来标记不同类型的内容,如文本、图像、链接等。
HTML 基础结构示例如下:
<code><!DOCTYPE html>
<html lang="en">code>
<head>
<meta charset="UTF-8">code>
<meta name="viewport" content="width=device-width, initial-scale=1.0">code>
<title>Document</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>Welcome to my website.</p>
</body>
</html>
3.2 CSS
CSS(Cascading Style Sheets)是一种样式表语言,用于描述 HTML 文档的外观和格式。CSS 可以控制网页的布局、颜色、字体等。
CSS 示例如下:
body {
font-family: Arial, sans-serif;
}
h1 {
color: blue;
}
p {
font-size: 16px;
}
3.3 JavaScript
JavaScript 是一种高效的编程语言,通常用于网页开发,可以使网页具有动态交互功能。JavaScript 可以操作 HTML 和 CSS,响应用户事件,创建动态效果等。
JavaScript 示例如下:
document.addEventListener('DOMContentLoaded', function() {
const button = document.getElementById('myButton');
button.addEventListener('click', function() {
alert('Button clicked!');
});
});
4. 使用 Python 进行 Web 爬虫
4.1 常用的 Python 库
requests:用于发送 HTTP 请求。BeautifulSoup:用于解析 HTML 和 XML 文档。Scrapy:一个功能强大的爬虫框架。Playwright:用于模拟浏览器操作,支持多种浏览器。
4.2 安装所需库
使用 pip 安装下列库:
pip install requests
pip install beautifulsoup4
pip install scrapy
pip install openpyxl
pip install playwright
python -m playwright install
4.3 编写一个简单的爬虫
下面是一个使用 requests 编写的简单爬虫示例。
4.4 示例代码
import requests
# 发送请求
url = 'https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total'
response = requests.get(url)
# 解析JSON数据
data = response.json()
if 'data' in data:
# 遍历数据
for item in data['data']:
if 'target' in item and 'title' in item['target']:
print(item['target']['title'])
else:
print("没有获取到数据")
执行结果如下:
5. 处理复杂的网页
对于一些动态加载内容的网页,仅靠 requests 和 BeautifulSoup 可能无法获取所有数据。这时可以使用 Playwright 模拟浏览器操作。
5.1 使用 Playwright 示例
<code>import asyncio
from bs4 import BeautifulSoup
from playwright.async_api import async_playwright
async def run(playwright: async_playwright) -> None:
browser = await playwright.chromium.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()
# 访问网页
await page.goto('https://nba.hupu.com/')
# 获取页面内容
content = await page.content()
# 解析 HTML(同样使用 BeautifulSoup)
soup = BeautifulSoup(content, 'html.parser')
# 提取页面标题
title = soup.title.string
print('Title:', title)
# 提取推荐文章的标题及链接
links = await page.locator('.list-recommend a, .list-container a').all()
for link in links:
title = await link.inner_text()
href = await link.get_attribute('href')
print(title, href)
# 关闭浏览器和上下文
await context.close()
await browser.close()
# 异步运行函数
async def main():
async with async_playwright() as playwright:
await run(playwright)
# 运行主函数
asyncio.run(main())

6. 编写一个完整的爬虫项目
下面,我们将编写一个完整的爬虫项目,从一个网站中提取数据并保存到本地文件。
6.1 项目要求
从一个演出票务网站中提取演出信息;将演出数据保存到 Excel 文件中。
6.2 项目步骤
发送请求并获取响应解析响应内容创建 Excel 工作簿、Sheet将遍历数据保存到 Excel 文件
6.3 示例代码
下面是一个使用 requests 和 BeautifulSoup 编写的爬虫示例。
<code>import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
from pathlib import Path
def showStart(city_code):
# 发送请求获取网页内容
url = f'https://www.showstart.com/event/list?pageNo=1&pageSize=99999&cityCode={ city_code}'
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
items = soup.find_all('a', class_='show-item item')code>
# 创建Excel工作簿
wb = Workbook()
sheet = wb.active
# 添加标题行
sheet.append(['标题', '艺人', '价格', '时间', '地址', '链接'])
for item in items:
title = item.find('div', class_='title').text.strip()code>
artist = item.find('div', class_='artist').text.strip()code>
price = item.find('div', class_='price').text.strip()code>
time = item.find('div', class_='time').text.strip()code>
addr = item.find('div', class_='addr').text.strip()code>
href = 'https://www.showstart.com' + item['href']
# 将数据写入Excel
sheet.append([title, artist, price, time, addr, href])
# 保存Excel文件
root_dir = Path(__file__).resolve().parent
file_path = root_dir / f'showstart_{ city_code}.xlsx'
wb.save(file_path)
print(f'数据已保存到 { file_path}')
else:
print(f'请求失败,状态码:{ response.status_code}')
if __name__ == "__main__":
city_code = input("请输入城市编码:")
showStart(city_code)
打开Excel 文件,内容如下:
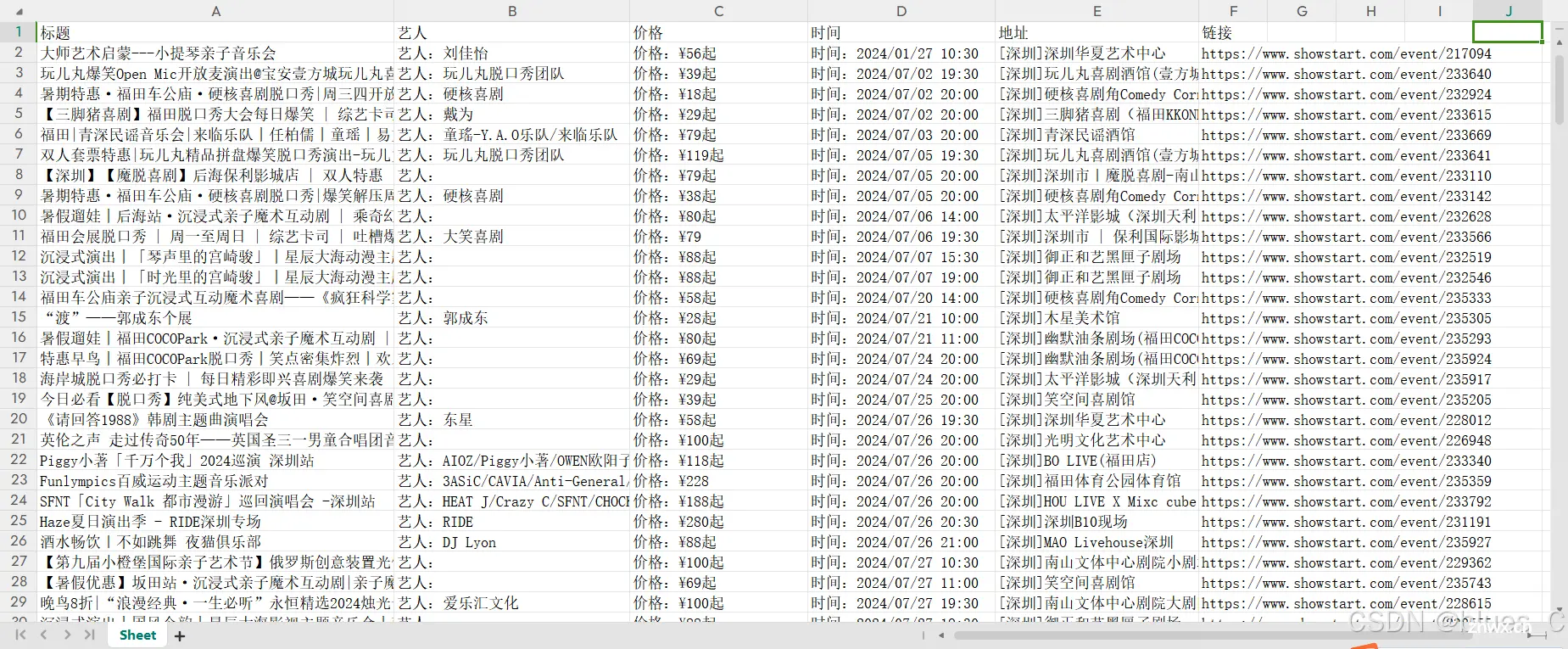
7. robots.txt 文件是什么?
robots.txt 文件是一个文本文件,通常放置在网站的根目录下。
它用来告诉搜索引擎的爬虫(spider)哪些页面可以抓取,哪些页面不可以抓取。
要找到网站的 robots.txt 文件,在浏览器的地址栏输入以下格式的URL:
http://www.xxx.com/robots.txt
如果访问的是不带www的域名:
http://xxx.com/robots.txt
这里的 xxx.com 替换成想要查找 robots.txt 的网站域名。如果该网站有 robots.txt 文件,将能够直接在浏览器中看到它的内容。如果不存在,可能会看到404错误页面或者其他错误信息。此外,有些网站可能会使用 robots.txt 文件来提供关于网站地图(sitemap)的信息,这可以帮助搜索引擎更快地发现和索引网站上的新内容。
8. 注意事项
尊重网站的 robots.txt 文件:大多数网站都有一个 robots.txt 文件,告知爬虫哪些页面可以抓取,哪些页面不可以。一定要遵守这些规则,避免抓取被禁止的内容。避免过度抓取:频繁的请求可能会给目标网站的服务器带来负担,甚至导致服务器宕机。请合理设置抓取的频率,避免对服务器造成过大的压力;尊重网站的使用条款:有些网站的使用条款中明确禁止未经授权的数据抓取。在抓取数据前,一定要仔细阅读并遵守网站的使用条款和隐私政策。处理敏感数据:在抓取和处理数据时,要特别注意保护个人隐私和敏感信息。避免抓取和存储敏感数据,确保数据的合法性和安全性。合法合规:在进行数据抓取时,要确保自己的行为合法合规。不同国家和地区对数据抓取的法律规定不同,务必了解并遵守相关法律法规。正确识别身份:在请求头中使用合理的 User-Agent,明确表明自己的身份,避免被误认为恶意爬虫。
总结
希望你通过本文,对 Python 爬虫有了一个全面的了解。我们从 Python 爬虫的基本概念、HTTP 基础知识以及网页的基本组成部分讲起,逐步学习了如何使用 Python 编写简单的爬虫,以及如何处理动态加载内容的网页。最后,我们用一个完整的爬虫项目,把学到的知识都串联起来,实战演练了一遍。相信通过这次学习,你对爬虫的工作流程和技术细节都有了更深入的理解。
如果你有任何问题或者好的想法,欢迎随时和我交流。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。