彻底搞懂ScheduledThreadPoolExecutor
cnblogs 2024-10-24 08:39:00 阅读 82
前言
项目中经常会遇到一些非分布式的调度任务,需要在未来的某个时刻周期性执行。实现这样的功能,我们有多种方式可以选择:
- <code>Timer类, jdk1.3引入,不推荐。
它所有任务都是串行执行的,同一时间只能有一个任务在执行,而且前一个任务的延迟或异常都将会影响到之后的任务。可能会出现任务执行时间过长而导致任务相互阻塞的情况
- Spring的<code>@Scheduled注解,不是很推荐
这种方式底层虽然是用线程池实现,但是有个最大的问题,所有的任务都使用的同一个线程池,可能会导致长周期的任务运行影响短周期任务运行,造成线程池"饥饿",更加推荐的做法是同种类型的任务使用同一个线程池。
这也是本文重点讲解的方式,通过自定义ScheduledThreadPoolExecutor调度线程池,提交调度任务才是最优解。
基本介绍
ScheduledThreadPoolExecutor继承自 ThreadPoolExecutor,为任务提供延迟或周期执行,属于线程池的一种。和 ThreadPoolExecutor 相比,它还具有以下几种特性:
使用专门的任务类型—ScheduledFutureTask 来执行周期任务,也可以接收不需要时间调度的任务(这些任务通过 ExecutorService 来执行)。
使用专门的存储队列—DelayedWorkQueue 来存储任务,DelayedWorkQueue 是无界延迟队列DelayQueue 的一种。相比ThreadPoolExecutor也简化了执行机制(delayedExecute方法,后面单独分析)。
支持可选的run-after-shutdown参数,在池被关闭(shutdown)之后支持可选的逻辑来决定是否继续运行周期或延迟任务。并且当任务(重新)提交操作与 shutdown 操作重叠时,复查逻辑也不相同。
基本使用
ScheduledThreadPoolExecutor 最常见的应用场景就是实现调度任务,
创建方式
创建ScheduledThreadPoolExecutor方式一共有两种,第一种是通过自定义参数,第二种通过Executors工厂方法创建。 根据阿里巴巴代码规范中的建议,更加推荐使用第一种方式创建。
- 自定义参数创建
ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory, RejectedExecutionHandler handler)
corePoolSize:核心工作的线程数量threadFactory:线程工厂,用来创建线程handler: 拒绝策略,饱和策略
- <code>Executors工厂方法创建
static ScheduledExecutorService newScheduledThreadPool(int corePoolSize):根据核心线程数创建调度线程池。static ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory):根据核心线程数和线程工厂创建调度线程池。
核心API
schedule(Runnable command, long delay, TimeUnit unit):创建并执行在给定延迟后启用的一次性操作
command: 执行的任务delay:延迟的时间unit: 单位
- <code>scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit):定时执行周期任务,任务执行完成后,延迟delay时间执行
command: 执行的任务initialDelay: 初始延迟的时间delay: 上次执行结束,延迟多久执行unit:单位
@Test
public void testScheduleWithFixedDelay() throws InterruptedException {
// 创建调度任务线程池
ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1);
// 按照上次执行完成后固定延迟时间调度
scheduledExecutorService.scheduleWithFixedDelay(() -> {
try {
log.info("scheduleWithFixedDelay ...");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, 1, 2, TimeUnit.SECONDS);
Thread.sleep(10000);
}
- <code>scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit):按照固定的评率定时执行周期任务,不受任务运行时间影响。
command: 执行的任务initialDelay: 初始延迟的时间period: 周期unit:单位
@Test
public void testScheduleAtFixedRate() throws InterruptedException {
// 创建调度任务线程池
ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1);
// 按照固定2秒时间执行
scheduledExecutorService.scheduleAtFixedRate(() -> {
try {
log.info("scheduleWithFixedDelay ...");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, 1, 2, TimeUnit.SECONDS);
Thread.sleep(10000);
}
综合案例
通过ScheduledThreadPoolExecutor实现每周四 18:00:00 定时执行任务。
// 通过ScheduledThreadPoolExecutor实现每周四 18:00:00 定时执行任务
@Test
public void test() {
// 获取当前时间
LocalDateTime now = LocalDateTime.now();
System.out.println(now);
// 获取周四时间
LocalDateTime time = now.withHour(18).withMinute(0).withSecond(0).withNano(0).with(DayOfWeek.THURSDAY);
// 如果 当前时间 > 本周周四,必须找到下周周四
if(now.compareTo(time) > 0) {
time = time.plusWeeks(1);
}
System.out.println(time);
// initailDelay 代表当前时间和周四的时间差
// period 一周的间隔时间
long initailDelay = Duration.between(now, time).toMillis();
long period = 1000 * 60 * 60 * 24 * 7;
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
pool.scheduleAtFixedRate(() -> {
System.out.println("running...");
}, initailDelay, period, TimeUnit.MILLISECONDS);
}
底层源码解析
接下来一起看看 ScheduledThreadPool 的底层源码
数据结构
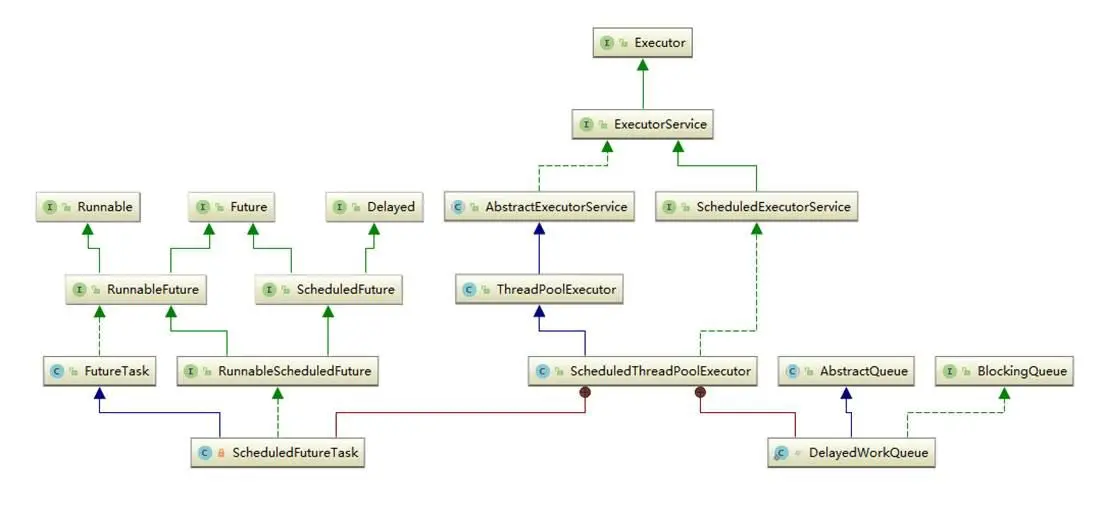
ScheduledThreadPoolExecutor继承自 ThreadPoolExecutor:
ScheduledThreadPoolExecutor 内部构造了两个内部类 ScheduledFutureTask 和 DelayedWorkQueue:
ScheduledFutureTask: 继承了FutureTask,说明是一个异步运算任务;最上层分别实现了Runnable、Future、Delayed接口,说明它是一个可以延迟执行的异步运算任务。
DelayedWorkQueue: 这是 ScheduledThreadPoolExecutor 为存储周期或延迟任务专门定义的一个延迟队列,继承了 AbstractQueue,为了契合 ThreadPoolExecutor 也实现了 BlockingQueue 接口。它内部只允许存储 RunnableScheduledFuture 类型的任务。与 DelayQueue 的不同之处就是它只允许存放 RunnableScheduledFuture 对象,并且自己实现了二叉堆(DelayQueue 是利用了 PriorityQueue 的二叉堆结构)。
内部类ScheduledFutureTask
属性
<code>//为相同延时任务提供的顺序编号
private final long sequenceNumber;
//任务可以执行的时间,纳秒级
private long time;
//重复任务的执行周期时间,纳秒级。
private final long period;
//重新入队的任务
RunnableScheduledFuture<V> outerTask = this;
//延迟队列的索引,以支持更快的取消操作
int heapIndex;
sequenceNumber: 当两个任务有相同的延迟时间时,按照 FIFO 的顺序入队。sequenceNumber 就是为相同延时任务提供的顺序编号。
time: 任务可以执行时的时间,纳秒级,通过triggerTime方法计算得出。
period: 任务的执行周期时间,纳秒级。正数表示固定速率执行(为scheduleAtFixedRate提供服务),负数表示固定延迟执行(为scheduleWithFixedDelay提供服务),0表示不重复任务。
outerTask: 重新入队的任务,通过reExecutePeriodic方法入队重新排序。
核心方法run()
public void run() {
boolean periodic = isPeriodic();//是否为周期任务
if (!canRunInCurrentRunState(periodic))//当前状态是否可以执行
cancel(false);
else if (!periodic)
//不是周期任务,直接执行
ScheduledFutureTask.super.run();
else if (ScheduledFutureTask.super.runAndReset()) {
setNextRunTime();//设置下一次运行时间
reExecutePeriodic(outerTask);//重排序一个周期任务
}
}
说明: ScheduledFutureTask 的run方法重写了 FutureTask 的版本,以便执行周期任务时重置/重排序任务。任务的执行通过父类 FutureTask 的run实现。内部有两个针对周期任务的方法:
- setNextRunTime(): 用来设置下一次运行的时间,源码如下:
//设置下一次执行任务的时间
private void setNextRunTime() {
long p = period;
if (p > 0) //固定速率执行,scheduleAtFixedRate
time += p;
else
time = triggerTime(-p); //固定延迟执行,scheduleWithFixedDelay
}
//计算固定延迟任务的执行时间
long triggerTime(long delay) {
return now() +
((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));
}
- reExecutePeriodic(): 周期任务重新入队等待下一次执行,源码如下:
//重排序一个周期任务
void reExecutePeriodic(RunnableScheduledFuture<?> task) {
if (canRunInCurrentRunState(true)) {//池关闭后可继续执行
super.getQueue().add(task);//任务入列
//重新检查run-after-shutdown参数,如果不能继续运行就移除队列任务,并取消任务的执行
if (!canRunInCurrentRunState(true) && remove(task))
task.cancel(false);
else
ensurePrestart();//启动一个新的线程等待任务
}
}
reExecutePeriodic与delayedExecute的执行策略一致,只不过reExecutePeriodic不会执行拒绝策略而是直接丢掉任务。
cancel方法
public boolean cancel(boolean mayInterruptIfRunning) {
boolean cancelled = super.cancel(mayInterruptIfRunning);
if (cancelled && removeOnCancel && heapIndex >= 0)
remove(this);
return cancelled;
}
ScheduledFutureTask.cancel本质上由其父类 FutureTask.cancel 实现。取消任务成功后会根据removeOnCancel参数决定是否从队列中移除此任务。
核心属性
//关闭后继续执行已经存在的周期任务
private volatile boolean continueExistingPeriodicTasksAfterShutdown;
//关闭后继续执行已经存在的延时任务
private volatile boolean executeExistingDelayedTasksAfterShutdown = true;
//取消任务后移除
private volatile boolean removeOnCancel = false;
//为相同延时的任务提供的顺序编号,保证任务之间的FIFO顺序
private static final AtomicLong sequencer = new AtomicLong();
continueExistingPeriodicTasksAfterShutdown:和executeExistingDelayedTasksAfterShutdown是 ScheduledThreadPoolExecutor 定义的 run-after-shutdown 参数,用来控制池关闭之后的任务执行逻辑。
removeOnCancel:用来控制任务取消后是否从队列中移除。当一个已经提交的周期或延迟任务在运行之前被取消,那么它之后将不会运行。默认配置下,这种已经取消的任务在届期之前不会被移除。 通过这种机制,可以方便检查和监控线程池状态,但也可能导致已经取消的任务无限滞留。为了避免这种情况的发生,我们可以通过setRemoveOnCancelPolicy方法设置移除策略,把参数removeOnCancel设为true可以在任务取消后立即从队列中移除。
sequencer:是为相同延时的任务提供的顺序编号,保证任务之间的 FIFO 顺序。与 ScheduledFutureTask 内部的sequenceNumber参数作用一致。
构造函数
首先看下构造函数,ScheduledThreadPoolExecutor 内部有四个构造函数,这里我们只看这个最大构造灵活度的:
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
构造函数都是通过super调用了ThreadPoolExecutor的构造,并且使用特定等待队列DelayedWorkQueue。
Schedule
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay,
TimeUnit unit) {
if (callable == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<V> t = decorateTask(callable,
new ScheduledFutureTask<V>(callable, triggerTime(delay, unit)));//构造ScheduledFutureTask任务
delayedExecute(t);//任务执行主方法
return t;
}
说明: schedule主要用于执行一次性(延迟)任务。函数执行逻辑分两步:
- 封装 Callable/Runnable
protected <V> RunnableScheduledFuture<V> decorateTask(
Runnable runnable, RunnableScheduledFuture<V> task) {
return task;
}
- 执行任务
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);//池已关闭,执行拒绝策略
else {
super.getQueue().add(task);//任务入队
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&//判断run-after-shutdown参数
remove(task))//移除任务
task.cancel(false);
else
ensurePrestart();//启动一个新的线程等待任务
}
}
说明: delayedExecute是执行任务的主方法,方法执行逻辑如下:
如果池已关闭(ctl >= SHUTDOWN),执行任务拒绝策略;
池正在运行,首先把任务入队排序;然后重新检查池的关闭状态,执行如下逻辑:
A: 如果池正在运行,或者 run-after-shutdown 参数值为true,则调用父类方法ensurePrestart启动一个新的线程等待执行任务。ensurePrestart源码如下:
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
ensurePrestart是父类 ThreadPoolExecutor 的方法,用于启动一个新的工作线程等待执行任务,即使corePoolSize为0也会安排一个新线程。
B: 如果池已经关闭,并且 run-after-shutdown 参数值为false,则执行父类(ThreadPoolExecutor)方法remove移除队列中的指定任务,成功移除后调用ScheduledFutureTask.cancel取消任务
scheduleAtFixedRate 和 scheduleWithFixedDelay
/**
* 创建一个周期执行的任务,第一次执行延期时间为initialDelay,
* 之后每隔period执行一次,不等待第一次执行完成就开始计时
*/
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0)
throw new IllegalArgumentException();
//构建RunnableScheduledFuture任务类型
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),//计算任务的延迟时间
unit.toNanos(period));//计算任务的执行周期
RunnableScheduledFuture<Void> t = decorateTask(command, sft);//执行用户自定义逻辑
sft.outerTask = t;//赋值给outerTask,准备重新入队等待下一次执行
delayedExecute(t);//执行任务
return t;
}
/**
* 创建一个周期执行的任务,第一次执行延期时间为initialDelay,
* 在第一次执行完之后延迟delay后开始下一次执行
*/
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0)
throw new IllegalArgumentException();
//构建RunnableScheduledFuture任务类型
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),//计算任务的延迟时间
unit.toNanos(-delay));//计算任务的执行周期
RunnableScheduledFuture<Void> t = decorateTask(command, sft);//执行用户自定义逻辑
sft.outerTask = t;//赋值给outerTask,准备重新入队等待下一次执行
delayedExecute(t);//执行任务
return t;
}
说明: scheduleAtFixedRate和scheduleWithFixedDelay方法的逻辑与schedule类似。
注意scheduleAtFixedRate和scheduleWithFixedDelay的区别: 乍一看两个方法一模一样,其实,在unit.toNanos这一行代码中还是有区别的。没错,scheduleAtFixedRate传的是正值,而scheduleWithFixedDelay传的则是负值,这个值就是 ScheduledFutureTask 的period属性。
shutdown()
public void shutdown() {
super.shutdown();
}
//取消并清除由于关闭策略不应该运行的所有任务
@Override void onShutdown() {
BlockingQueue<Runnable> q = super.getQueue();
//获取run-after-shutdown参数
boolean keepDelayed =
getExecuteExistingDelayedTasksAfterShutdownPolicy();
boolean keepPeriodic =
getContinueExistingPeriodicTasksAfterShutdownPolicy();
if (!keepDelayed && !keepPeriodic) {//池关闭后不保留任务
//依次取消任务
for (Object e : q.toArray())
if (e instanceof RunnableScheduledFuture<?>)
((RunnableScheduledFuture<?>) e).cancel(false);
q.clear();//清除等待队列
}
else {//池关闭后保留任务
// Traverse snapshot to avoid iterator exceptions
//遍历快照以避免迭代器异常
for (Object e : q.toArray()) {
if (e instanceof RunnableScheduledFuture) {
RunnableScheduledFuture<?> t =
(RunnableScheduledFuture<?>)e;
if ((t.isPeriodic() ? !keepPeriodic : !keepDelayed) ||
t.isCancelled()) { // also remove if already cancelled
//如果任务已经取消,移除队列中的任务
if (q.remove(t))
t.cancel(false);
}
}
}
}
tryTerminate(); //终止线程池
}
说明: 池关闭方法调用了父类ThreadPoolExecutor的shutdown,具体分析见 ThreadPoolExecutor 篇。这里主要介绍以下在shutdown方法中调用的关闭钩子onShutdown方法,它的主要作用是在关闭线程池后取消并清除由于关闭策略不应该运行的所有任务,这里主要是根据 run-after-shutdown 参数(continueExistingPeriodicTasksAfterShutdown和executeExistingDelayedTasksAfterShutdown)来决定线程池关闭后是否关闭已经存在的任务。
ScheduledThreadPoolExecutor吞掉异常
如果ScheduledThreadPoolExecutor中执行的任务出错抛出异常后,不仅不会打印异常堆栈信息,同时还会取消后面的调度, 直接看例子。
@Test
public void testException() throws InterruptedException {
// 创建1个线程的调度任务线程池
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
// 创建一个任务
Runnable runnable = new Runnable() {
volatile int num = 0;
@Override
public void run() {
num ++;
// 模拟执行报错
if(num > 5) {
throw new RuntimeException("执行错误");
}
log.info("exec num: [{}].....", num);
}
};
// 每隔1秒钟执行一次任务
scheduledExecutorService.scheduleAtFixedRate(runnable, 0, 1, TimeUnit.SECONDS);
Thread.sleep(10000);
}

- 只执行了5次后,就不打印,不执行了,因为报错了
- 任务报错,也没有打印一次堆栈,更导致调度任务取消,后果十分严重。
解决方法也非常简单,只要通过try catch捕获异常即可。
<code>public void run() {
try {
num++;
// 模拟执行报错
if (num > 5) {
throw new RuntimeException("执行错误");
}
log.info("exec num: [{}].....", num);
} catch (Exception e) {
e.printStackTrace();
}
}
原理探究
那大家有没有想过为什么任务出错会导致异常无法打印,甚至调度都取消了呢?从源码出发,一探究竟。
从上面delayedExecute方法可以看到,延迟或周期性任务的主要执行方法, 主要是将任务丢到队列中,后续再由工作线程获取执行。
- 在任务入队列后,就是执行任务内容了,任务内容其实就是在继承了Runnable类的run方法中。
// ScheduledFutureTask#run方法
public void run() {
// 是不是周期性任务
boolean periodic = isPeriodic();
if (!canRunInCurrentRunState(periodic))
cancel(false);
// 不是周期性任务的话, 直接调用一次下面的run
else if (!periodic)
ScheduledFutureTask.super.run();
// 如果是周期性任务,则调用runAndReset方法,如果返回true,继续执行
else if (ScheduledFutureTask.super.runAndReset()) {
// 设置下次调度时间
setNextRunTime();
// 重新执行调度任务
reExecutePeriodic(outerTask);
}
}
- 这里的关键就是看
ScheduledFutureTask.super.runAndReset()方法是否返回true,如果是true的话继续调度。
- runAndReset方法也很简单,关键就是看报异常如何处理。
<code>// FutureTask#runAndReset
protected boolean runAndReset() {
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return false;
// 是否继续下次调度,默认false
boolean ran = false;
int s = state;
try {
Callable<V> c = callable;
if (c != null && s == NEW) {
try {
// 执行任务
c.call();
// 执行成功的话,设置为true
ran = true;
// 异常处理,关键点
} catch (Throwable ex) {
// 不会修改ran的值,最终是false,同时也不打印异常堆栈
setException(ex);
}
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
// 返回结果
return ran && s == NEW;
}
- 关键点ran变量,最终返回是不是下次继续调度执行
- 如果抛出异常的话,可以看到不会修改ran为true。
小结
Java的ScheduledThreadPoolExecutor定时任务线程池所调度的任务中如果抛出了异常,并且异常没有捕获直接抛到框架中,会导致ScheduledThreadPoolExecutor定时任务不调度了。
封装包装类,统一调度
在实际项目使用中,可以在自己的项目中封装一个包装类,要求所有的调度都提交通过统一的包装类,从而规范代码,如下代码:
@Slf4j
public class RunnableWrapper implements Runnable {
// 实际要执行的线程任务
private Runnable task;
// 线程任务被创建出来的时间
private long createTime;
// 线程任务被线程池运行的开始时间
private long startTime;
// 线程任务被线程池运行的结束时间
private long endTime;
// 线程信息
private String taskInfo;
private boolean showWaitLog;
/**
* 执行间隔时间多久,打印日志
*/
private long durMs = 1000L;
// 当这个任务被创建出来的时候,就会设置他的创建时间
// 但是接下来有可能这个任务提交到线程池后,会进入线程池的队列排队
public RunnableWrapper(Runnable task, String taskInfo) {
this.task = task;
this.taskInfo = taskInfo;
this.createTime = System.currentTimeMillis();
}
public void setShowWaitLog(boolean showWaitLog) {
this.showWaitLog = showWaitLog;
}
public void setDurMs(long durMs) {
this.durMs = durMs;
}
// 当任务在线程池排队的时候,这个run方法是不会被运行的
// 但是当任务结束了排队,得到线程池运行机会的时候,这个方法会被调用
// 此时就可以设置线程任务的开始运行时间
@Override
public void run() {
this.startTime = System.currentTimeMillis();
// 此处可以通过调用监控系统的API,实现监控指标上报
// 用线程任务的startTime-createTime,其实就是任务排队时间
// 这边打印日志输出,也可以输出到监控系统中
if(showWaitLog) {
log.info("任务信息: [{}], 任务排队时间: [{}]ms", taskInfo, startTime - createTime);
}
// 接着可以调用包装的实际任务的run方法
try {
task.run();
} catch (Exception e) {
log.error("run task error", e);
}
// 任务运行完毕以后,会设置任务运行结束的时间
this.endTime = System.currentTimeMillis();
// 此处可以通过调用监控系统的API,实现监控指标上报
// 用线程任务的endTime - startTime,其实就是任务运行时间
// 这边打印任务执行时间,也可以输出到监控系统中
if(endTime - startTime > durMs) {
log.info("任务信息: [{}], 任务执行时间: [{}]ms", taskInfo, endTime - startTime);
}
}
}
当然,也还可以在包装类里面封装各种监控行为,如本例打印日志执行时间等。
其它使用注意点
- 为什么ThreadPoolExecutor 的调整策略却不适用于 ScheduledThreadPoolExecutor?
由于 ScheduledThreadPoolExecutor 是一个固定核心线程数大小的线程池,并且使用了一个无界队列,所以调整maximumPoolSize对其没有任何影响(所以 ScheduledThreadPoolExecutor 没有提供可以调整最大线程数的构造函数,默认最大线程数固定为Integer.MAX_VALUE)。此外,设置corePoolSize为0或者设置核心线程空闲后清除(allowCoreThreadTimeOut)同样也不是一个好的策略,因为一旦周期任务到达某一次运行周期时,可能导致线程池内没有线程去处理这些任务。
- Executors 提供了哪几种方法来构造 ScheduledThreadPoolExecutor?
newScheduledThreadPool: 可指定核心线程数的线程池。
newSingleThreadScheduledExecutor: 只有一个工作线程的线程池。如果内部工作线程由于执行周期任务异常而被终止,则会新建一个线程替代它的位置。
注意: newScheduledThreadPool(1, threadFactory) 不等价于newSingleThreadScheduledExecutor。newSingleThreadScheduledExecutor创建的线程池保证内部只有一个线程执行任务,并且线程数不可扩展;而通过newScheduledThreadPool(1, threadFactory)创建的线程池可以通过setCorePoolSize方法来修改核心线程数。
面试题专栏
Java面试题专栏已上线,欢迎访问。
- 如果你不知道简历怎么写,简历项目不知道怎么包装;
- 如果简历中有些内容你不知道该不该写上去;
- 如果有些综合性问题你不知道怎么答;
那么可以私信我,我会尽我所能帮助你。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。