一文夯实并发编程的理论基础
cnblogs 2024-09-30 16:39:00 阅读 72
JMM内存模型
定义
java内存模型(即 java Memory Model,简称JMM),不存在的东西,是一个概念,约定
主要分成两部分来看,一部分叫做主内存,另一部分叫做工作内存。
- <li>
每一个线程都有其自己的工作内存,当线程要执行代码的时候,就必须在工作内存中完成。比如线程操作共享变量,它是不能直接在主内存中操作共享变量的,只能够将共享变量先复制一份,放到线程自己的工作内存当中,线程在其工作内存对该复制过来的共享变量处理完后,再将结果同步回主内存中去。
java当中的共享变量;都放在主内存当中,如类的成员变量(实例变量),还有静态的成员变量(类变量),都是存储在主内存中的。每一个线程都可以访问主内存;
主内存是 所有线程都共享的,都能访问的。所有的共享变量都存储于主内存;共享变量主要包括类当中的成员变量,以及一些静态变量等。局部变量是不会出现在主内存当中的,因为局部变量只能线程自己使用;工作内存每一个线程都有自己的工作内存,工作内存只存储 该线程对共享变量的副本。线程对变量的所有读写操作都必须在工作内存中完成,而不能直接读写主内存中的变量,不同线程之间也不能直接访问 对方工作内存中的 变量;线程对共享变量的操作都是对其副本进行操作,操作完成之后再同步回主内存当中去;
JMM的同步约定:
线程解锁前,必须把共享变量立刻刷回主存
线程加锁前,必须读取主存中的最新值到工作内存中
加锁和解锁是同一把锁
也就是说,JMM是一种抽象的结构,它提供了合理的禁用缓存和禁止重排序的方案来解决可见性、有序性的问题
作用:主要目的就是在多线程对共享变量进行读写时,来保证共享变量的可见性、有序性、原子性;在编程当中是通过两个关键字 synchronized 和 volatile 来保证共享变量的三个特性的。
主内存与工作内存交互
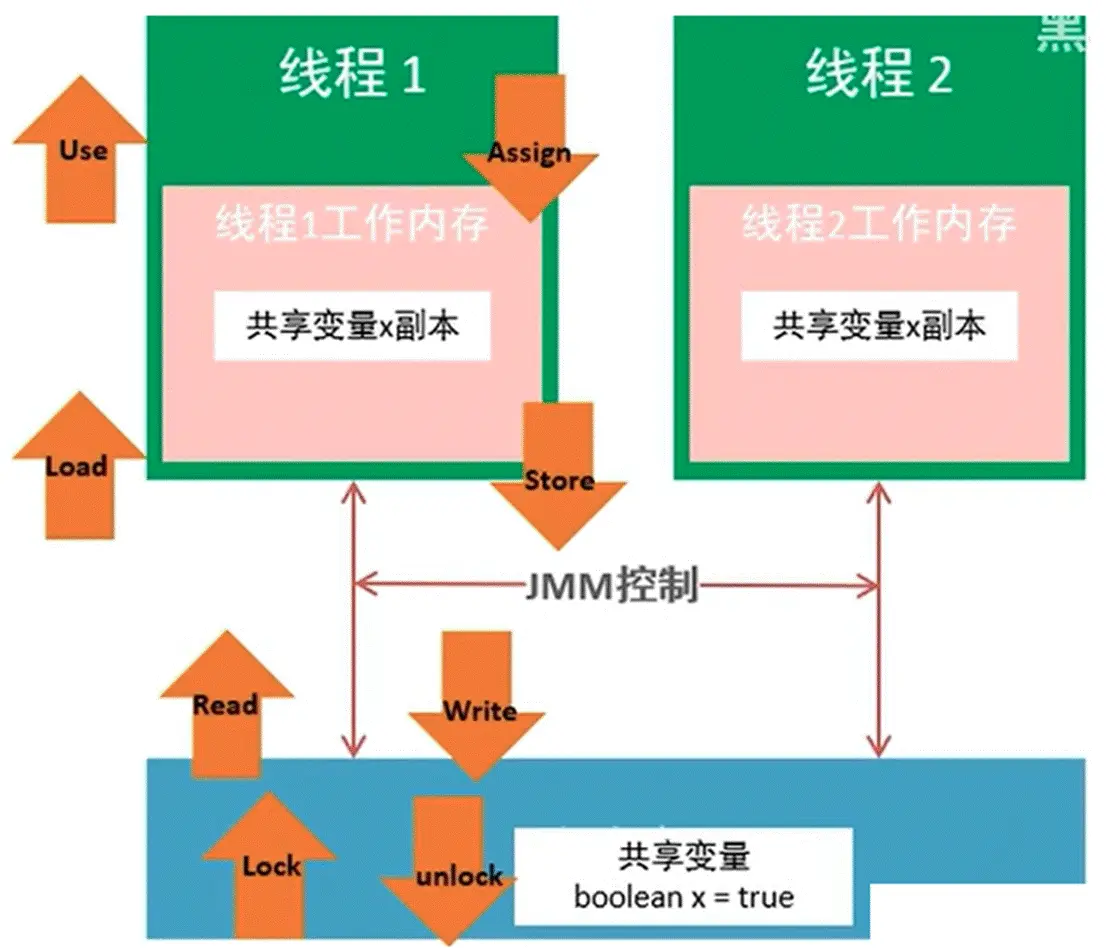
一个变量如何从主内存拷贝到工作内存、如何从工作内存同步回主内存的呢?
Java内存模型中定义了上图中的 8 种操作(橙色箭头)来完成,虚拟机实现时必须保证每一种操作都是原子的、不可再分的。
举个例子:假设现在线程1想要来访问主内存当中的共享变量 x ,即当前主内存中的共享变量x的取值为 boolean x = true;
- <li>线程1首先会做一个原子操作叫做Read,读取主内存当中的共享变量x的取值,即 boolean x = true;
- 接下来就是 Load 操作,把在主内存中读取到的共享变量加载到了工作内存当中(副本);
- 接着执行 Use 操作,如果线程1需要对共享变量x进行操作,即会取到从主内存中加载过来的共享变量x的取值去进行一些操作;
- 操作之后会有一个新的结果返回,假设令这个共享变量的取值变为false,完成 Assign 操作,即给共享变量x赋新值;
- 操作完成之后;就需要同步回主内存,首先会完成一个 Store 的原子操作,来保存这个处理结果;
- 接着执行Write操作,即在工作内存中,Assign 赋值给共享变量的值同步到主内存当中,主内存中共享变量取值x由true更改为false。
- 另外还有两个与锁相关的操作,Lock与unlock,比如说加了synchronized,才会产生有lock与unlock操作;如果对共享变量的操作没有加锁,那么也就不会有lock与unlock操作。
注意:如果对共享变量执行 lock 操作,该线程就会去主内存中获取到共享变量的最新值,刷新工作内存中的旧值,保证可见性;(加锁说明要对这个共享变量进行写操作了,先刷新旧值,再操作新值)对共享变量执行 unlock 操作,必须先把此变量同步回主内存中,再执行 unlock;(因为对共享变量释放锁,接下来其他线程就能访问到这个共享变量,就必须使这个共享变量呈现的是最新值)这两点就是 synchronized为什么能保证“可见性”的原因。
规则:
- 不允许read、load、store、write操作之一单独出现,也就是read操作后必须load,store操作后必须write。
- 不允许线程丢弃他最近的assign操作,即工作内存中的变量数据改变了之后,必须告知主存。
- 不允许线程将没有assign的数据从工作内存同步到主内存。
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是对变量实施use、store操作之前,必须经过load和assign操作。
- 一个变量同一时间只能有一个线程对其进行lock操作。多次lock之后,必须执行相同次数unlock才可以解锁。
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值。在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值。
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量。
- 一个线程对一个变量进行unlock操作之前,必须先把此变量同步回主内存。
总结
主内存 与 工作内存 之间的 数据交互过程(即主内存与工作内存的交互是通过这8个原子操作来保证数据的正确性的):lock → read → load → use → assign → store → write → unlock
并发编程中的三个问题
线程不安全示例
<code>// 案例演示:5个线程各执行1000次i++操作:
public class Test01Atomicity {
private static int number = 0;
public static void main(String[] args) throws InterruptedException {
// 5个线程都执行1000次 i++
Runnable increment = () -> {
for (int i = 0; i < 1000; i++) {
number++;
}
}; // 5个线程
ArrayList<Thread> ts = new ArrayList<>();
for (int i = 0; i < 5; i++) {
Thread t = new Thread(increment);
t.start();
ts.add(t);
}
for (Thread t : ts) {
t.join();
}
/* 最终的效果即,加出来的效果不是5000,可能会少于5000
那么原因就在于 i++ 并不是一个原子操作
下面会通过java反汇编的方式来进行演示和分析,这个 i++ 其实有4条指令 */
System.out.println("number = " + number);
}
}
可见性:CPU缓存引起
可见性:是指当一个线程对共享变量进行了修改,那么另外的线程可以立即看到修改后的最新值。
//线程1执行的代码
int i = 0;
i = 10;
//线程2执行的代码
j = i;
假设执行线程1的是CPU1,执行线程2的是CPU2。由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到CPU1的高速缓存中,然后赋值为10,那么在CPU1的高速缓存当中i的值变为10了,却没有立即写入到主存当中。
此时线程2执行 j = i,它会先去主存读取i的值并加载到CPU2的缓存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10.
解决可见性:
在共享变量前面加上volatile关键字修饰;volatile 的底层实现原理是内存屏障(Memory Barrier),保证了对 volatile 变量的写指令后会加入写屏障,对 volatile 变量的读指令前会加入读屏障。
写屏障(sfence)保证在写屏障之前的,对共享变量的改动,都同步到主存当中;
读屏障(lfence)保证在读屏障之后,对共享变量的读取,加载的是主存中最新数据;
,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。这是因为synchronized 同步时会对应 JMM 中的 lock 原子操作,lock 操作会刷新工作内存中的变量的值,得到共享内存(主内存)中最新的值,从而保证可见性。
- synchronized 同步的时候会对应8个原子操作当中的 lock 与 unlock 这两个原子操作,lock操作执行时该线程就会去主内存中获取到共享变量最新值,刷新工作内存中的旧值,从而保证可见性。
原子性: 分时复用引起
原子性(Atomicity): 在一次或多次操作中,要么所有的操作都执行,并且不会受其他因素干扰而中断,要么所有的操作都不执行;
int i = 1;
// 线程1执行
i += 1;
// 线程2执行
i += 1;
这里需要注意的是:i += 1需要三条 CPU 指令
- 将变量 i 从内存读取到 CPU寄存器;
- 在CPU寄存器中执行 i + 1 操作;
- 将最后的结果i写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
由于CPU分时复用(线程切换)的存在,线程1执行了第一条指令后,就切换到线程2执行,假如线程2执行了这三条指令后,再切换会线程1执行后续两条指令,将造成最后写到内存中的i值是2而不是3。
x = 10; //语句1: 直接将数值10赋值给x,也就是说线程执行这个语句的会直接将数值10写入到工作内存中
y = x; //语句2: 包含2个操作,它先要去读取x的值,再将x的值写入工作内存,虽然读取x的值以及 将x的值写入工作内存 这2个操作都是原子性操作,但是合起来就不是原子性操作了。
x++; //语句3: x++包括3个操作:读取x的值,进行加1操作,写入新的值。
x = x + 1; //语句4: 同语句3
上面4个语句只有语句1的操作具备原子性。也就是说,只有简单的读取、赋值(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。
解决原子性:
Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
有序性: 重排序引起
有序性(Ordering):是指程序代码在执行过程中的先后顺序,由于java在编译器以及运行期的优化,导致了代码的执行顺序未必就是开发者编写代码的顺序。
int i = 0;
boolean flag = false;
i = 1; //语句1
flag = true; //语句2
为什么要重排序?一般会认为编写代码的顺序就是代码最终的执行顺序,那么实际上并不一定是这样的,为了提高程序的执行效率,java在编译时和运行时会对代码进行优化(JIT即时编译器),会导致程序最终的执行顺序不一定就是编写代码时的顺序。重排序 是指 编译器 和 处理器 为了优化程序性能 而对 指令序列 进行 重新排序 的一种手段;
从 java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序:

- <li>编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读 / 写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
上述的 1 属于编译器重排序,2 和 3 属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。对于编译器,JMM 的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM 的处理器重排序规则会要求 java 编译器在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel 称之为 memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
解决有序性:
可以使用 synchronized 同步代码块来保证有序性;加了synchronized,依然会发生指令重排序(可以看看DCL单例模式),只不过,由于存在同步代码块,可以保证只有一个线程执行同步代码块当中的代码,也就能保证有序性。
给共享变量加volatile关键字来解决有序性问题。
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后;
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前;
Happens-Before 规则
Happens-Before是一种可见性规则,它表达的含义是前面一个操作的结果对后续操作是可见的。解释为 “先行发生于...”

A happens-before B,也就意味着A的执行结果对B是可见的
单一线程(程序顺序)原则
Single Thread rule:在一个线程内,在程序前面的操作先行发生于后面的操作。
as-id-serio 语义

管程锁定(监视器锁)规则
Monitor Lock Rule :对一个锁的解锁 Happens-Before 于后续对这个锁 的加锁

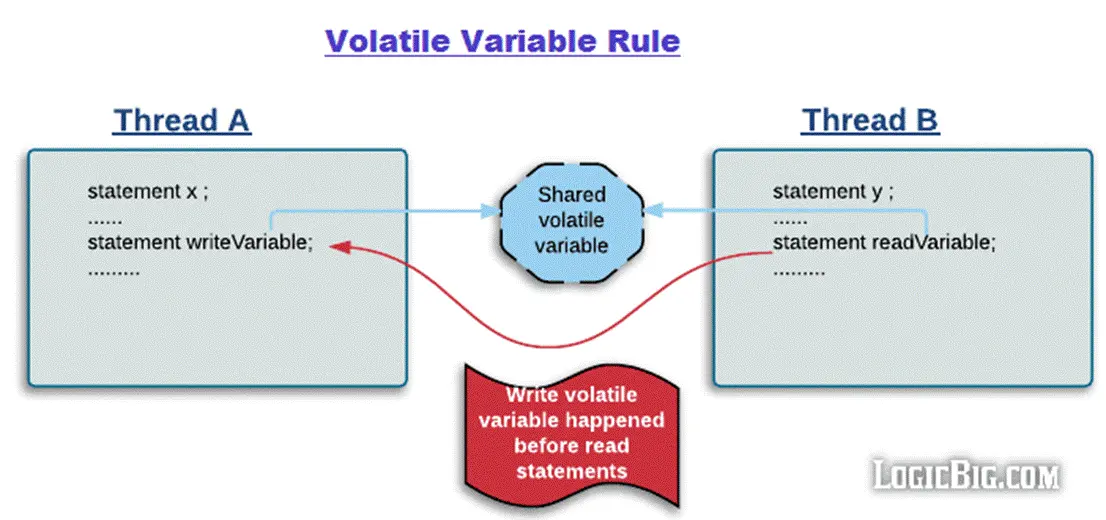
volatile 变量规则
Volatile Variable Rule:对一个volatile域的写,happens-before于任意后续对这个volatile域的读
线程启动start规则
Thread Start Rule:Thread 对象的 start() 方法调用先行发生于此线程的每一个动作。
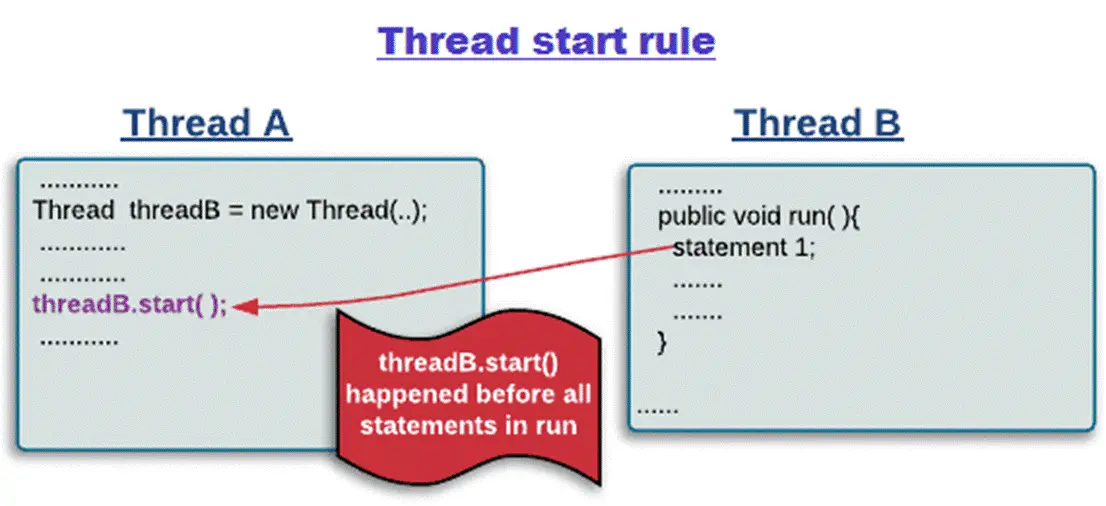
如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作

线程加入join规则
Thread Join Rule:Thread 对象的结束先行发生于 join() 方法返回。
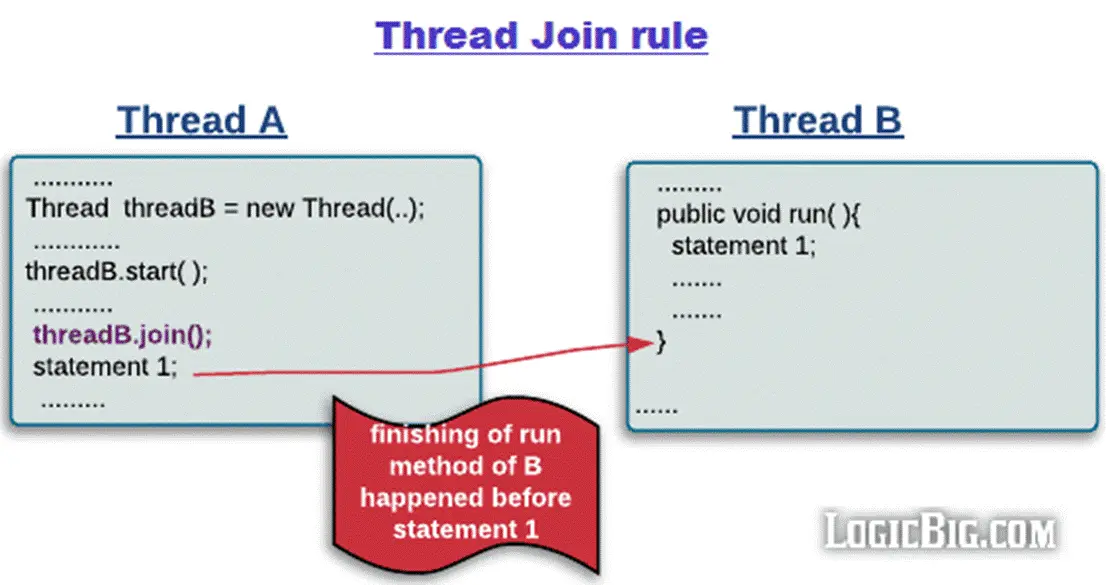
如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回

线程中断规则
Thread Interruption Rule:对线程 interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过 interrupted() 方法检测到是否有中断发生。
对象终结规则
Finalizer Rule:一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize() 方法的开始。
传递性
Transitivity:如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那么操作 A 先行发生于操作 C。
安全发布对象
发布与逃逸
发布的意思是使一个对象能够被当前范围之外的代码所使用
<code>public static Hashset<Person> persons;
public void init(){
persons = new HashSet<Person>;
}
不安全发布:私有数组,但外部范围也能使用,导致不安全发布
private string[] states = {"a","b","c","d"};
//发布出去一个
public string[] getstates(){
return states;
}
public static void main(string[] args){
App unSafePub = new App();
System.out.printIn("Init array is:" + Arrays.tostring(unsafePub.getstates()));
unsafePub.getstates()[0] = "Seven!";
System.out.printin("After modify.the array is: " + Arrays.tostring(unsafePub.getstates()));
}
对象溢出:
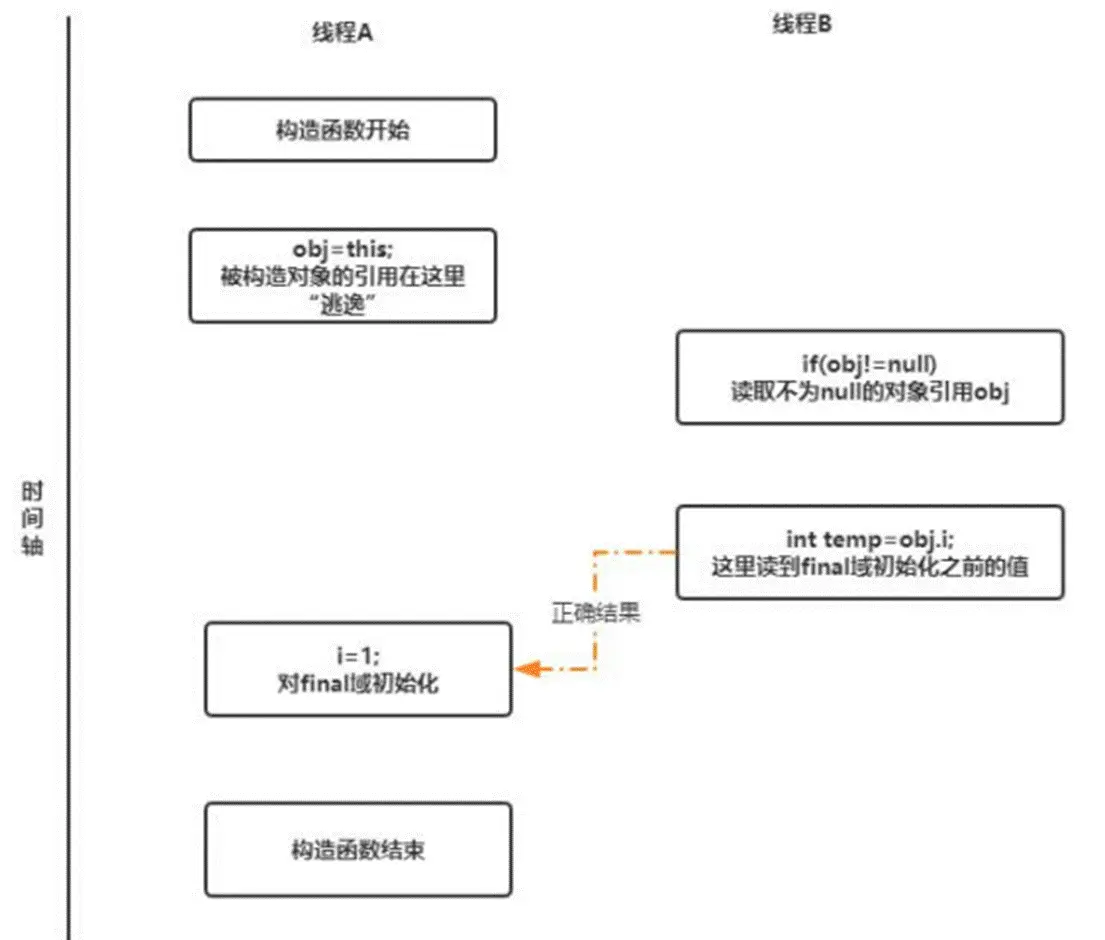
一种错误的发布,当一个对象还没有构造完成时,就使它被其他线程所见
public cass FinalReferenceEscapeExample {
final int i;
static FinalReferenceEscapeExample obj;
public FinalReferenceEscapeExample() {
i = 1; //1.写fina]域
obj = this; //2.this 引用"逃逸"
}
public static void writer() {
new FinalReferenceEscapeExample();
}
public static void reader() {
if(obj != null){ //3.
int temp = obj.i; //4.
}
}
}
逃逸带来的问题
安全发布对象的四种方法
- <li>
将对象的引用保存到volatile类型的域或者AtomicReference对象中(利用volatile happen-before规则)
将对象的引用保存到某个正确构造对象的final类型域中(初始化安全性)
将对象的引用保存到一个由锁保护的域中(读写都上锁)
在静态初始化函数中初始化一个对象引用
线程安全的实现方法
互斥同步
synchronized 和 ReentrantLock。
非阻塞同步
互斥同步最主要的问题就是线程阻塞和唤醒所带来的性能问题,因此这种同步也称为阻塞同步。
互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
CAS
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略: 先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
乐观锁需要操作和冲突检测这两个步骤具备原子性,这里就不能再使用互斥同步来保证了,只能靠硬件来完成。硬件支持的原子性操作最典型的是: 比较并交换(Compare-and-Swap,CAS)。CAS 指令需要有 3 个操作数,分别是内存地址 V、旧的预期值 A 和新值 B。当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B。
AtomicInteger
J.U.C 包里面的整数原子类 AtomicInteger,其中的 compareAndSet() 和 getAndIncrement() 等方法都使用了 Unsafe 类的 CAS 操作。
以下代码使用了 AtomicInteger 执行了自增的操作。
<code>private AtomicInteger cnt = new AtomicInteger();
public void add() {
cnt.incrementAndGet();
}
以下代码是 incrementAndGet() 的源码,它调用了 unsafe 的 getAndAddInt() 。
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
以下代码是 getAndAddInt() 源码,var1 指示对象内存地址,var2 指示该字段相对对象内存地址的偏移,var4 指示操作需要加的数值,这里为 1。通过 getIntVolatile(var1, var2) 得到旧的预期值,通过调用 compareAndSwapInt() 来进行 CAS 比较,如果该字段内存地址中的值等于 var5,那么就更新内存地址为 var1+var2 的变量为 var5+var4。
可以看到 getAndAddInt() 在一个循环中进行,发生冲突的做法是不断的进行重试。
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
ABA
如果一个变量初次读取的时候是 A 值,它的值被改成了 B,后来又被改回为 A,那 CAS 操作就会误认为它从来没有被改变过。
J.U.C 包提供了一个带有标记的原子引用类 AtomicStampedReference 来解决这个问题,它可以通过控制变量值的版本来保证 CAS 的正确性。大部分情况下 ABA 问题不会影响程序并发的正确性,如果需要解决 ABA 问题,改用传统的互斥同步可能会比原子类更高效。
无同步方案
要保证线程安全,并不是一定就要进行同步。如果一个方法本来就不涉及共享数据,那它自然就无须任何同步措施去保证正确性。
栈封闭
多个线程访问同一个方法的局部变量时,不会出现线程安全问题,因为局部变量存储在虚拟机栈中,属于线程私有的。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class StackClosedExample {
public void add100() {
int cnt = 0;
for (int i = 0; i < 100; i++) {
cnt++;
}
System.out.println(cnt);
}
}
线程本地存储(Thread Local Storage)
如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行。如果能保证,就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题。
符合这种特点的应用并不少见,大部分使用消费队列的架构模式(如“生产者-消费者”模式)都会将产品的消费过程尽量在一个线程中消费完。其中最重要的一个应用实例就是经典 Web 交互模型中的“一个请求对应一个服务器线程”(Thread-per-Request)的处理方式,这种处理方式的广泛应用使得很多 Web 服务端应用都可以使用线程本地存储来解决线程安全问题。
可以使用 java.lang.ThreadLocal 类来实现线程本地存储功能。
对于以下代码,thread1 中设置 threadLocal 为 1,而 thread2 设置 threadLocal 为 2。过了一段时间之后,thread1 读取 threadLocal 依然是 1,不受 thread2 的影响。
public class ThreadLocalExample {
public static void main(String[] args) {
ThreadLocal threadLocal = new ThreadLocal();
Thread thread1 = new Thread(() -> {
threadLocal.set(1);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadLocal.get());
threadLocal.remove();
});
Thread thread2 = new Thread(() -> {
threadLocal.set(2);
threadLocal.remove();
});
thread1.start();
thread2.start();
}
}
ThreadLocal 从理论上讲并不是用来解决多线程并发问题的,因为根本不存在多线程竞争。
在一些场景 (尤其是使用线程池) 下,由于 ThreadLocal.ThreadLocalMap 的底层数据结构导致 ThreadLocal 有内存泄漏的情况,应该尽可能在每次使用 ThreadLocal 后手动调用 remove(),以避免出现 ThreadLocal 经典的内存泄漏甚至是造成自身业务混乱的风险。
可重入代码(Reentrant Code)
这种代码也叫做纯代码(Pure Code),可以在代码执行的任何时刻中断它,转而去执行另外一段代码(包括递归调用它本身),而在控制权返回后,原来的程序不会出现任何错误。
可重入代码有一些共同的特征,例如不依赖存储在堆上的数据和公用的系统资源、用到的状态量都由参数中传入、不调用非可重入的方法等。
关于作者
来自一线程序员Seven的探索与实践,持续学习迭代中~
本文已收录于我的个人博客:https://www.seven97.top
公众号:seven97,欢迎关注~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。