Python头歌集合(部分参考题解)
没你乖Eric 2024-07-13 13:35:02 阅读 59
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言一、Python初体验——Hello World第1关:Hello Python,我来了!第2关:我想看世界第3关:学好Python
二、Python入门之基础语法第1关:行与缩进第2关:标识符与保留字第3关:注释第4关:输入输出
三、函数结构第1关:函数的参数 - 搭建函数房子的砖第2关:函数的返回值 - 可有可无的 return第3关:函数的使用范围:Python 作用域
四、函数调用第1关:内置函数 - 让你偷懒的工具第2关:函数正确调用 - 得到想要的结果第3关:函数与函数调用 - 分清主次
五、模块第1关:模块的定义第2关:内置模块中的内置函数
六、字符串处理第1关:字符串的拼接:名字的组成第2关:字符转换第3关:字符串查找与替换
七、元组与字典第1关:元组的使用:这份菜单能修改吗?第2关:字典的使用:这份菜单可以修改第3关:字典的遍历:菜名和价格的展示第4关:嵌套 - 菜单的信息量好大
八、玩转列表第1关:列表元素的增删改:客人名单的变化第2关:列表元素的排序:给客人排序第3关:数值列表:用数字说话第4关:列表切片:你的菜单和我的菜单
九、循环结构第1关:While 循环与 break 语句第2关:for 循环与 continue 语句第3关:循环嵌套第4关:迭代器
十、顺序与选择结构第1关:顺序结构第2关:选择结构:if-else第3关:选择结构 : 三元操作符
十一、类的基础语法第1关:类的声明与定义第2关:类的属性与实例化第3关:类的导入
十二、类的继承第1关:初识继承第2关:覆盖方法第3关:多重继承
十三、类的其它特性第1关:类的私有化
十四、NumPy基础及取值操作第1关:ndarray对象第2关:形状操作第3关:基础操作第4关:随机数生成第5关:索引与切片
十五、NumPy数组的高级操作第1关:堆叠操作第2关:比较、掩码和布尔逻辑第3关:花式索引与布尔索引第4关:广播机制第5关:线性代数
十六、Numpy 进阶第1关:Numpy 广播第2关:Numpy 高级索引第3关:Numpy 迭代数组
十七、Pandas初体验第1关:了解数据处理对象--Series第2关:了解数据处理对象-DataFrame第3关:读取CSV格式数据第4关:数据的基本操作——排序第5关:数据的基本操作——删除第6关:数据的基本操作——算术运算第7关:数据的基本操作——去重第8关:层次化索引
十八、Pandas 进阶第1关:Pandas 分组聚合第2关:Pandas 创建透视表和交叉表
十九、 Matplotlib接口和常用图形第1关:画图接口第2关:线形图第3关:散点图第4关:直方图第5关:饼图
二十、Matplotlib子图与多子图第1关:手动创建子图第2关:网格子图第3关:更复杂的排列方式
二十一、Python面向对象编程实训第1关:按揭贷款——定义抽象类
二十二、机器学习第1关:kNN算法---红酒分类
二十三、K-means聚类算法第1关:计算欧几里得距离第2关:计算样本的最近邻聚类中心第3关:计算各聚类中心第4关:评估聚类效果第5关:组合已实现的函数完成K-means算法
二十四、机器学习 --- 神经网络第1关:神经网络基本概念第2关:激活函数第3关:反向传播算法
二十五、机器学习 --- 模型评估、选择与验证第1关:为什么要有训练集与测试集第2关:欠拟合与过拟合第3关:偏差与方差第4关:验证集与交叉验证第5关:衡量回归的性能指标
二十六、Python机器学习软件包Scikit-Learn的学习与运用第1关:使用scikit-learn导入数据集第2关:数据预处理 — 标准化
二十七、使用机器学习解决实际问题第2关:识别花朵第3关:预测房价第4关:癌症诊断
前言
<code>提示:这里是本文要记录的大概内容:
头歌实践教学平台,是国内广泛使用的在线实践教学服务平台与创新环境,尤其为高校和企业的实践与创新能力提升作出了贡献。这个平台集成了多种工具,如实验、作业、视频、考试和毕设等,形成了线上线下的协同空间。
对于学习Python来说,头歌平台提供了以下好处:
1、交互式编程体验:学习者可以通过Python交互式编程以及脚本编程,初步地体验Python编程的魅力,例如实现一个简单的打印字符串功能。
基础语法与结构:该平台涵盖了Python的基础语法,顺序结构,分支结构等基础知识点,帮助学习者对Python有一个全面而深入的认识。
2、实际编程练习:头歌平台上有各种编程任务和挑战,例如要求在特定的文件中填写代码以实现特定的功能,如打印输出"Hello Python"。这些实际的编程练习可以帮助学习者巩固理论知识并提高实际应用能力。
3、自动化作业管理:头歌平台的作业管理组件能够自动批阅、统计学生的作业,并将数据与教务系统对接,为教师节省了大量时间。
提示:以下是本篇文章正文内容,下面题解可供参考
一、Python初体验——Hello World
第1关:Hello Python,我来了!
任务描述
Python 编程语言具有简洁、易读等特点,并提供了交互式编程以及脚本编程两种不同的模式,学习者很容易上手。
本关任务是,首先,通过命令行连接,进入 Python 交互编程环境,完成打印Hello world、整数加减法以及利用Help命令查询相应内置函数的使用,感受和体验 Python 的交互式编程模式;然后,通过脚本编程方式,编写相应的代码,利用 Python 提供的print()内置函数,打印输出Hello Python,初步体验和感受 Python 编程的魅力。
编程要求
本关任务是在hello_python.py中填写相应的打印语句,实现打印输出Hello Python的功能。**(请仔细阅读下面的编程要求,注意区分大小写)**具体要求如下:
1.交互环境下的编程(在“命令行”窗口完成),步骤如下:
打开右侧"命令行"窗口,自动连接后台容器;进入容器终端,键入python,回车后系统自动输出 Python 命令提示符>>>,进入交互编程环境;
在交互式编程环境中,使用 Python 打印函数print及相应参数,打印输出Hello Python;
在交互式编程环境中,完成几项四则运算任务,包括10+4,10-4,10*4和10/4。
2.代码文件方式编程(在“代码”窗口完成),步骤如下:
打开左侧"代码"窗口,在hello_python代码文件中Begin-End区间补充代码,使用 Python 打印函数print及相应参数,实现打印输出Hello Python的功能。
#coding=utf-8
#请在此处添加代码完成输出“Hello Python”,注意要区分大小写!
###### Begin ######
print('Hello Python')
###### End ######
第2关:我想看世界
任务描述
本关任务:字符串拼接。接收用户输入的两个字符串,将它们组合后输出。
编程要求
根据提示,在右侧编辑器Begin-End区间补充代码,观察测试输入输出的特点,通过format()方法,按要求输出指定语句。
#coding=utf-8
#请在此处补充代码,按要求完成输出
###### Begin ######
name = input("请输入一个人的名字:")
country = input("请输入一个国家的名字:")
print("世界那么大,{}想去{}看看。".format(name, country))
###### End ######
第3关:学好Python
任务描述
本关任务:简单的人名对话。
编程要求
根据提示,在右侧编辑器Begin-End区间补充代码,根据用户输入的人名给出一些不同的回应。
提示:第二句和第三句可以模仿已经给出的第一句的部分代码,注意观察后两句话的特点,可以发现第一个字,是通过字符串索引提取。
例如:
输入姓名:郭靖
输出:
郭靖同学,学好Python,前途无量!
郭大侠,学好Python,大展拳脚!
靖哥哥,学好Python,人见人爱!
#coding=utf-8
#请在此处补充代码,按要求完成输出
###### Begin ######
#coding=utf-8
#请在此处补充代码,按要求完成输出
###### Begin ######
name=input("输入姓名:")
print("{}同学,学好Python,前途无量!".format(name)) #请将命令行补充完整
print("{}大侠,学好Python,大展拳脚!".format(name[0])) #请将命令行补充完整
print("{}哥哥,学好Python,人见人爱!".format(name[1:])) #请将命令行补充完整
###### End ######
二、Python入门之基础语法
第1关:行与缩进
任务描述
本关任务:改正代码中不正确的缩进,使其能够正常编译,并输出正确的结果。
编程要求
根据提示,改正右侧编辑器中代码的缩进错误,使其能够正确运行,并输出结果。
#有错误的函数1
def wrong1():
print("wrong1")
print("这里有一个错误缩进")
#有错误的函数2
def wrong2():
print("wrong2")
#有错误的函数3
def wrong3():
print("wrong3")
print("hello world")
#这里是调用三个函数的代码
#不要修改
if __name__ == '__main__':
wrong1()
wrong2()
wrong3()
第2关:标识符与保留字
任务描述
本关任务:改正程序中的错误,并输出 Python3 的所有保留字。
编程要求
根据提示,改正右侧编辑器的代码,并输出 Python3 的所有保留字。
import keyword
if __name__ == '__main__':
#错误1
str1 = "string"
print(str1)
#错误2
t = 1024
print(t)
#错误3
k = 1.024
print(k)
#错误3
a = False
print(a)
#在此处输出保留关键字
print(keyword.kwlist)
print("end")
第3关:注释
任务描述
本关任务:修改程序,得到正确的结果。
编程要求
根据提示,对右侧编辑器中,部分代码添加注释或者取消注释,使其输出结果与测试说明中的结果一致。
# 输出1
print(1)
# 输出3
print(3)
# 输出5
print(5)
# 输出hello world
print("hello world")
# 输出3
print(3)
# 输出4
print(4)
第4关:输入输出
任务描述
本关任务:编写一个对用户输入,进行加减乘除四则运算的程序。
编程要求
根据提示,在右侧编辑器 Begin-End 区间补充代码,接收用户输入的两个数 a 和 b,对其进行加减乘除四则运算,通过print函数打印四次运算结果,使结果输出形式与预期输出保持一致。
if __name__ == "__main__":
a = int(input())
b = int(input())
# ********** Begin ********** #
print("%d + %d = %d" % (a, b, a + b))
print("%d - %d = %d" % (a, b, a - b))
print("%d * %d = %d" % (a, b, a * b))
print("%d / %d = %.6f" % (a, b, a / b))
# ********** End ********** #
三、函数结构
第1关:函数的参数 - 搭建函数房子的砖
任务描述
当我们需要在程序中多次执行同一类型的任务时,不需要反复编写代码段来完成任务,而是可以利用函数工具来大大方便我们的编程工作。函数是可重复使用的、用来实现相关联功能的代码段。
本实训的目标是让学习者了解并掌握函数结构的相关知识,本关的小目标则是让学习者先了解并掌握函数参数的有关知识。
编程要求
本关的编程任务是补全src/Step1/plus.py文件的代码,实现相应的功能。具体要求如下:
定义并调用一个函数,功能是对输入的列表中的数值元素进行累加,列表中元素的个数没有确定;
将累加结果存储到变量d中;
输出累加结果d。
# coding=utf-8
# 创建一个空列表numbers
numbers = []
# str用来存储输入的数字字符串,lst1是将输入的字符串用空格分割,存储为列表
str = input()
lst1 = str.split(' ')
# 将输入的数字字符串转换为整型并赋值给numbers列表
for i in range(len(lst1)):
numbers.append(int(lst1.pop()))
# 定义一个函数,实现对输入列表中数值元素的累加求和
def sum_numbers(numbers):
return sum(numbers)
# 调用函数,将累加结果存储到变量d中
d = sum_numbers(numbers)
# 输出累加结果d
print(d)
第2关:函数的返回值 - 可有可无的 return
任务描述
函数在进行运算处理后,返回的值被称为返回值。函数返回的值是通过return语句执行。返回值能够让我们直接得到函数处理的结果,而不必关心函数内部复杂繁重的运算过程,大大提高了编程效率。本关的主要目标是让学习者了解并掌握函数返回值的相关知识。
编程要求
本关的编程任务是补全src/step2/return.py文件的代码,实现相应的功能。具体要求如下:
定义一个函数gcd,功能是求两个正整数的最大公约数;
调用函数gcd,得到输入的两个正整数的最大公约数,并输出这个最大公约数。
# coding=utf-8
def gcd(a, b):
while b:
a, b = b, a % b
return a
a = int(input())
b = int(input())
print(gcd(a, b))
第3关:函数的使用范围:Python 作用域
任务描述
函数是有使用范围的,在一个模块中,我们可以定义很多函数和变量。但我们希望有的函数和变量别人可以使用,有的函数和变量仅仅可以在模块内部使用,这就是 Python 作用域的相关问题。本关的目标就是让学习者了解并掌握函数的使用范围,即 Python 作用域的相关知识。
编程要求
本关的编程任务是补全src/step3/scope.py文件的代码,实现相应的功能。具体要求如下:
编写程序,功能是求两个正整数的最小公倍数;
要求实现方法:先定义一个private函数 _gcd()求两个正整数的最大公约数,再定义public函数lcm()调用 _gcd()函数求两个正整数的最小公倍数;
调用函数lcm(),并将输入的两个正整数的最小公倍数输出。
# coding=utf-8
def _gcd(a, b):
while b:
a, b = b, a % b
return a
def lcm(a, b):
return a * b // _gcd(a, b)
# 输入两个正整数a,b
a = int(input())
b = int(input())
# 调用函数,并输出a,b的最小公倍数
print(lcm(a, b))
四、函数调用
第1关:内置函数 - 让你偷懒的工具
任务描述
我们在编程过程中会用到很多函数,但我们不需要每个函数都自己去编写,因为 Python 内置了很多十分有用的函数,我们在编程过程中可以直接调用。本关目标是让学习者了解并掌握一些常用的 Python 内置函数的用法。
编程要求
本关的编程任务是补全src/Step2/prime.py文件的代码,实现相应的功能。具体要求如下:
定义一个函数,功能是判断一个数是否为素数;
调用函数,对输入的整数进行判断。如果是素数则输出为True,否则输出为False。
# coding=utf-8
def is_prime(num):
if num < 2:
return False
for i in range(2, int(num**0.5) + 1):
if num % i == 0:
return False
return True
n = int(input())
print(is_prime(n))
第2关:函数正确调用 - 得到想要的结果
任务描述
函数被定义后,本身是不会自动执行的,只有在被调用后,函数才会被执行,得到相应的结果。本关的目标是让学习者了解并掌握函数调用的相关知识。
编程要求
本关的编程任务是补全src/Step2/func_call.py文件的代码,实现相应的功能。具体要求如下:
定义一个函数,实现对输入的数值列表进行从小到大的顺序排序;
输出排序后的数值列表。
# coding=utf-8
# 输入数字字符串,并转换为数值列表
a = input()
num1 = a.split(',')
numbers = [int(i) for i in num1]
# 请在此添加代码,对数值列表numbers实现从小到大排序
########## Begin ##########
numbers.sort()
########## End ##########
print(numbers)
第3关:函数与函数调用 - 分清主次
任务描述
我们一般将字符串、列表等变量作为参数进行函数调用。但函数本身也是一个对象,所以我们也可以将函数作为参数传入另外一个函数中并进行调用。
本关的目标是让学习者了解并掌握函数作为参数传入另外一个函数中并进行调用的相关知识。
编程要求
本关的编程任务是补全src/step3/func_ref.py文件的代码,实现相应的功能。具体要求如下:
定义一个函数,要求实现圆的面积的计算;
根据输入的不同整数值的半径,调用函数计算,并输出圆的面积,结果保留两位小数。
# coding=utf-8
from math import pi as PI
def calculate_circle_area(radius):
return PI * radius * radius
n = int(input())
area = calculate_circle_area(n)
print("{:.2f}".format(area))
五、模块
第1关:模块的定义
任务描述
在 Python 程序的开发过程中,为了代码维护的方便,我们可以把函数进行分组,分别放到不同的.py文件里。这样,每个文件包含的代码就相对较少,这个.py文件就称之为一个模块(Module)。本关的目标是让学习者了解并掌握 Python 模块定义的相关知识。
编程要求
本关的编程任务是补全src/step1/module.py文件的代码,实现相应的功能。具体要求如下:
输入直角三角形的两个直角边的边长a和b,要求计算出其斜边边长;
要求使用math模块,并输出计算结果,结果保留小数点后三位小数。
import math
# 输入正整数a和b
a = float(input())
b = float(input())
# 计算斜边长度
c = math.sqrt(a**2 + b**2)
# 输出结果,保留三位小数
print("{:.3f}".format(c))
第2关:内置模块中的内置函数
任务描述
我们在安装好了 Python 配置文件后,也将 Python 本身带有的库也安装好了, Python 自带的库也叫做 Python 的内置模块。Python 的内置模块是 Python 编程的重要组织形式,内置模块中的内置函数也极大方便了编程过程中对函数等功能的使用。本关的目标是让学习者了解并掌握 Python 内置模块和内置函数的相关知识。
编程要求
本关的编程任务是补全src/step2/built-module.py文件的代码,实现相应的功能。具体要求如下:
输入两个正整数a和b,要求判断是否存在两个整数,它们的和为a,积为b;
如果存在,则输出Yes,若不存在,则输出No。
# coding=utf-8
import math
a = int(input())
b = int(input())
for i in range(1, a):
if i * (a - i) == b:
print("Yes")
break
else:
print("No")
六、字符串处理
第1关:字符串的拼接:名字的组成
任务描述
本关任务是将两个不同的字符串,拼接形成一个字符串,并将新字符串输出来。字符串或串(String)是由数字、字母、下划线组成的一串字符。在 Python 中,字符串用单引号或者双引号括起来。在很多情况下,我们需要将两个字符串拼接起来,形成一个字符串。
编程要求
本关的编程任务是补全src/Step1/full_name.py文件中 Begin-End 区间的代码,实现如下功能:
将存放姓氏的字符串变量和存放名字的字符串变量拼接起来,中间用一个空格隔开,并将结果存储在full_name变量中;
打印输出full_name变量。
# coding=utf-8
# 存放姓氏和名字的变量
first_name = input()
last_name = input()
# 请在下面添加字符串拼接的代码,完成相应功能
########## Begin ##########
full_name = first_name + " " + last_name
print(full_name)
########## End ##########
第2关:字符转换
任务描述
本关任务:对给定的字符串进行处理,包括字符串长度计算、大小写转换以及去除字符串前后空格等。
在字符串处理中,经常需要统计字符串的长度、进行大小写转换以及去除字符串前后空格等操作。例如,在基于关键词的搜索引擎中,要查询关键词是否在文档或者网页中出现,搜索引擎并不需要区分关键词中字符的大小写以及关键词前后的空格等。这时就需要对字符串进行处理,将其中的大写字符都转换为小写,并剔除字符串开头和结尾处的空格,然后再统一进行字符串匹配。
编程要求
本关的编程任务是,补全src/Step2/method1.py文件中 Begin-End 区间的代码,实现给定字符串的转换功能,具体要求如下:
step1 :将输入的源字符串source_string首尾的空格删除;
step2 :将 step1 处理后的字符串的所有单词的首字母变为大写,并打印输出;
step3 :将 step2 转换后的字符串的长度打印输出。
# coding=utf-8
# 获取待处理的源字符串
source_string = input()
# 删除首尾空格
trimmed_string = source_string.strip()
# 将单词首字母大写
capitalized_string = trimmed_string.title()
# 打印输出转换后的字符串
print(capitalized_string)
# 打印输出字符串长度
print(len(capitalized_string))
第3关:字符串查找与替换
任务描述
本关的任务是,给定一个字符串,要利用 Python 提供的字符串处理方法,从该字符串中,查找特定的词汇,并将其替换为另外一个更合适的词。例如,给定一个字符串Where there are a will, there are a way,我们发现这句话中存在语法错误,其中are应该为is,需要通过字符串替换将其转换为Where there is a will, there is a way。
在大家日常工作使用 Word 编写文档的过程中,经常会遇到一个问题,发现前面写的文档中某个词用错了,需要换为另外一个词来表达。Word 提供了全文查找与替换的功能,可以帮助用户很方便的处理这一问题。那么,这一功能最基础和核心的就是字符替换,如果我们要自己基于 Python 来实现,该怎么做呢?
编程要求
本关的编程任务是,补全src/Step3/method2.py文件中 Begin-End 区间的代码,实现如下功能:
step1 :查找输入字符串source_string中,是否存在day这个子字符串,并打印输出查找结果;
step2 :对输入字符串source_string执行字符替换操作,将其中所有的 day替换为time,并打印输出替换后的字符串;
step3 :对 step2 进行替换操作后的新字符串,按照空格进行分割,并打印输出分割后的字符列表。
# coding = utf-8
source_string = input()
# 请在下面添加代码
########## Begin ##########
# step1:查找输入字符串source_string中,是否存在day这个子字符串,并打印输出查找结果;
index = source_string.find('day')
print(index)
# step2:对输入字符串source_string执行字符替换操作,将其中所有的 day替换为time,并打印输出替换后的字符串;
replaced_string = source_string.replace('day', 'time')
print(replaced_string)
# step3:对 step2 进行替换操作后的新字符串,按照空格进行分割,并打印输出分割后的字符列表。
split_string = replaced_string.split(' ')
print(split_string)
########## End ##########
七、元组与字典
第1关:元组的使用:这份菜单能修改吗?
任务描述
元组看起来犹如列表,但元组使用圆括号()而不是[]来标识,而且列表的元素可以修改,但元组的元素不能修改。本关介绍元组的常见使用方法以及元组和列表的使用区别。下面用饭店菜单的例子来说明列表和元组使用的应用场景:
现在有一个餐馆要向每个包厢都投放两份菜单,菜单上有4种菜名。我们想将两个菜单上最后一道菜名互换一下,也想快速知道改变后的两份菜单上单词首字母最大的菜名。而我们首先需要判断该用列表的方法还是元组的方法实现这个目标。为了实现这个目标,我们需要先学习元组的相关使用知识以及元组与列表的区别。
编程要求
本关的编程任务是补全src/Step1/menu_test.py文件的代码内容,实现如下功能:
将输入的菜单menu_list转换为元组类型;
打印输出生成的元组;
打印输出元组中首字母最大的元素。
# coding=utf-8
# 创建并初始化menu_list列表
menu_list = []
while True:
try:
food = input()
menu_list.append(food)
except:
break
# 对menu_list进行元组转换以及元组计算等操作,并打印输出元组及元组最大的元素
menu_tuple = tuple(menu_list)
print(menu_tuple)
if menu_tuple:
max_element = max(menu_tuple, key=lambda x: x[0])
print(max_element)
else:
print("元组为空")
第2关:字典的使用:这份菜单可以修改
任务描述
字典和列表一样,都是 Python 中十分重要的可变容器模型,都可以存储任意类型元素。我们将以菜单的例子来说明字典使用的基本知识,餐馆的菜单上不仅包含菜名,菜名后面还必须包含该道菜的价格。如果要用列表实现,就需要两个列表,例如:
list_menu = [‘fish’,‘pork’,‘potato’,‘noodles’]
list_price = [40,30,15,10]
给定一个菜名,要查找相应的价格,就先要在list_menu中找到相应的位置,再在list_price中找到相应的价格。这种方式效率低下,那么我们是否可以将菜名和价格都存储在一个可变容器中呢?答案是可以的。
在本关中,我们将学习和掌握能够将相关信息关联起来的 Python 字典的相关知识,并完成对包含菜名和价格的菜单的处理操作。
编程要求
本关的编程任务是补全src/Step2/menu.py文件的代码,实现相应的功能。具体要求如下:
向menu_dict字典中添加一道菜名lamb,它的价格是50;
获取menu_dict字典中的fish的价格并打印出来;
将menu_dict字典中的fish的价格改为100;
删除menu_dict字典中noodles这道菜;
输出新的menu_dict菜单。
# coding=utf-8
# 创建并初始化menu_dict字典
menu_dict = { }
while True:
try:
food = input()
price = int(input())
menu_dict[food]= price
except:
break
# 向menu_dict字典中添加一道菜名lamb,它的价格是50;
menu_dict['lamb'] = 50
# 获取menu_dict字典中的fish的价格并打印出来;
print(menu_dict['fish'])
# 将menu_dict字典中的fish的价格改为100;
menu_dict['fish'] = 100
# 删除menu_dict字典中noodles这道菜;
del menu_dict['noodles']
# 输出新的menu_dict菜单。
print(menu_dict)
第3关:字典的遍历:菜名和价格的展示
任务描述
Python 字典中包含大量数据,它和列表一样,支持遍历操作。Python有多种遍历字典的方式,可以遍历字典的所有键-值对、键或值。例如,餐馆的菜单包含了菜名和价格等信息,餐馆需要将菜名和价格都展示给顾客,但也有些时候只需要将菜名都展示给厨师,还有些时候只需要将价格展示给收银员,这三种情况就用到了字典不同的遍历方式。
本关的目标是让学习者掌握字典遍历的相关知识和用法,并基于这些知识实现对菜单不同的查找和展示处理。
编程要求
本关的编程任务是补全src/Step3/key-values.py文件的代码,实现相应的功能。具体要求如下:
将menu_dict菜单的键遍历输出;
将menu_dict菜单的值遍历输出。
# coding=utf-8
# 创建并初始化menu_dict字典
menu_dict = { }
while True:
try:
food = input()
price = int(input())
menu_dict[food]= price
except:
break
# 请在此添加代码,实现对menu_dict的遍历操作并打印输出键与值
########## Begin ##########
for key in menu_dict.keys():
print(key)
for value in menu_dict.values():
print(value)
########## End ##########
第4关:嵌套 - 菜单的信息量好大
任务描述
Python 的列表和字典可以存储任意类型的元素,所以我们可以将字典存储在列表中,也可以将列表存储在字典中,这种操作称为嵌套。例如,餐馆中的菜单不仅仅包含菜名和价格,可能还会包含很多其他信息,这时候我们可能就需要采取嵌套的存储方式。
本关任务是让学习者利用嵌套方式存储菜单,让读者掌握 Python 嵌套的基本操作。
编程要求
本关的编程任务是补全src/Step4/menu_nest.py文件的代码,实现相应的功能。具体要求如下:
menu_total列表中初始时只包含menu1字典,menu1字典中包含两道菜和两道菜的价格;
编程要求是向menu_total列表中添加另外一个菜单字典menu2,menu2菜单中的菜名和menu1菜单一样,菜的价格是menu1菜的价格的2倍;
输出新的menu_total列表。
#coding=utf-8
#初始化menu1字典,输入两道菜的价格
menu1 = { }
a=menu1['fish']=int(input())
b=menu1['pork']=int(input())
#menu_total列表现在只包含menu1字典
menu_total = [menu1]
# 请在此添加代码,实现编程要求
#********** Begin *********#
menu2 = { }
menu2['fish']=a*2
menu2['pork']=b*2
menu_total = [menu1,menu2]
#********** End **********#
#输出menu_total列表
print(menu_total)
八、玩转列表
第1关:列表元素的增删改:客人名单的变化
任务描述
本关任务是对一个给定的列表进行增、删、改等操作,并输出变化后的最终列表。列表是由按一定顺序排列的元素组成,其中的元素根据需要可能会发生变化。其中,列表元素的添加、删除或修改等是最常见的操作。
下面以一则请客的故事来说明列表元素操作的应用场景:
有个人邀请几个朋友吃饭,初步拟定了一个客人名单列表guests=[‘Zhang san’,‘Li si’,‘Wang wu’,‘Zhao liu’]。后面因为一些临时情况,这个客人名单不断变化:
Zhao liu说要带他的朋友Hu qi一起来;
Zhang san因临时有事不能来了;
Wang wu说由他的弟弟Wang shi代他赴宴。
最终的客人名单列表如下:
[‘Li si’,‘Wang shi’,‘Zhao liu’,‘Hu qi’]
编程要求
本关的编程任务是补全src/Step1/guests.py文件的代码,实现相应的功能。具体要求如下:
step 1:将guests列表末尾的元素删除,并将这个被删除的元素值保存到deleted_guest变量;
step 2:将deleted_guest插入到 step 1 删除后的guests列表索引位置为2的地方;
step 3:将 step 2 处理后的guests列表索引位置为1的元素删除;
打印输出 step 1 的deleted_guest变量;
打印输出 step 3 改变后的guests列表。
# coding=utf-8
# 创建并初始化Guests列表
guests = []
while True:
try:
guest = input()
guests.append(guest)
except:
break
# 请在此添加代码,对guests列表进行插入、删除等操作
deleted_guest = guests.pop()
guests.insert(2, deleted_guest)
guests.pop(1)
print(deleted_guest)
print(guests)
第2关:列表元素的排序:给客人排序
任务描述
本关的任务是学会列表排序相关操作的使用方法,实现对列表元素的排序。一般情况下我们创建的列表中的元素可能都是无序的,但有些时候我们需要对列表元素进行排序。
例如,我们想将参加会议的专家名单guests列表中的五个名字元素[‘zhang san’,‘li si’,‘wang wu’,‘sun qi’,‘qian ba’],分别按照首字母从小到大的顺序和从大到小的顺序分别排序。排序后的输出分别为:
[‘li si’,‘qian ba’,‘sun qi’,‘wang wu’,‘zhang san’]
[‘zhang san’,‘wang wu’,‘sun qi’,‘qian ba’,‘li si’]
编程要求
本关的编程任务是补全src/step2/sortTest.py 文件中的函数部分,要求实现对输入列表source_list中的元素按照首字母从小到大的顺序进行排序,并且输出排序后的列表。
# coding=utf-8
# 创建并初始化source_list列表
source_list = []
while True:
try:
list_element = input()
source_list.append(list_element)
except:
break
# 请在此添加代码,对source_list列表进行排序等操作并打印输出排序后的列表
########## Begin ##########
source_list.sort(key=lambda x: x[0])
print(source_list)
########## End ##########
第3关:数值列表:用数字说话
任务描述
本关任务是利用合适的方法快速创建数字列表,并能够对列表中的元素数值进行简单的统计运算。在数据可视化的背景下,数字列表在 Python 列表中的应用十分广泛,列表十分适合存储数字集合。
本关目标是让学习者掌握一些处理数字列表的基本方法,主要包括数字列表的创建、对数字列表进行简单的统计运算等。例如,我们要创建一个从2到10的偶数的数字集合,然后计算出该集合的数值之和:
data_set = [2,4,6,8,10]
sum=30
编程要求
编程任务是补全src/Step3/numbers_square.py文件的代码内容,实现如下功能:
step1:根据给定的下限数lower, 上限数upper以及步长step,利用range函数生成一个列表;
step2:计算该列表的长度;
step3:求该列表中的最大元素与最小元素之差。
#coding=utf-8
# 创建并读入range函数的相应参数
lower = int(input())
upper = int(input())
step = int(input())
# 请在此添加代码,实现编程要求
###### Begin ######
list1=[]
for i in range(lower,upper,step):
list1.append(i)
print(len(list1))
list1.sort()
a=list1[-1]-list1[0]
print(a)
####### End #######
第4关:列表切片:你的菜单和我的菜单
任务描述
我们在前三关中学习了如何处理单个列表元素和所有列表元素,在这一关中我们还将学习如何处理部分列表元素(Python 中称为切片)。例如,当我们去餐馆吃饭点菜时,你的菜单和我的菜单有些时候是一模一样,也有些时候是部分菜名一样。那么如何根据我已经点好的菜单生成你的菜单呢?
本关将通过菜名列表的部分复制,让学习者了解并掌握列表切片的基础知识。
编程要求
本关的编程任务是补全src/Step4/foods.py文件的代码内容,实现如下功能:
利用切片方法从my_menu列表中每3个元素取1个,组成子序列并打印输出;
利用切片方法获取my_menu列表的最后三个元素组成子序列并打印输出。
# coding=utf-8
# 创建并初始化my_menu列表
my_menu = []
while True:
try:
food = input()
my_menu.append(food)
except:
break
# 请在此添加代码,对my_menu列表进行切片操作
###### Begin ######
list_slice = my_menu[::3]
print(list_slice)
pppp=my_menu[-3:-1]
pppp.append(my_menu[-1])
print(pppp)
####### End #######
九、循环结构
第1关:While 循环与 break 语句
任务描述
程序的第三大结构是循环结构。在此结构中,通过一个判断语句来循环执行一个代码块,直到判断语句为假时跳出循环。循环语句分为while循环、for循环、循环嵌套和迭代器。循环语句中有一个语句break,通过这个语句可以跳出整个循环。
以下场景便模拟了循环结构与跳出循环的现实场景:
在一个工厂的流水线上每天需要加工零件100件,且每件零件所做的加工都是一样的,也就是说流水线每天要循环做相同的工作100次。但是如果在加工时突然停电,则流水线停止对后面所有零件的加工,跳出循环。
本关的任务是让学习者学会使用while循环与break语句。
编程要求
本关的编程任务是补全line.py文件中的判断语句部分,具体要求如下:
填入当已处理零件数小于总零件数count < partcount时的while循环判断语句;
在停电时填入break语句跳出循环。
partcount = int(input())
electric = int(input())
count = 0
#当count < partcount时的while循环判断语句
while(count < partcount):
count += 1
print("已加工零件个数:",count)
if(electric):
print("停电了,停止加工")
break
第2关:for 循环与 continue 语句
任务描述
Python 中还为我们提供了一种循环结构:for循环。for循环可以遍历序列成员,直到序列中的成员全部都遍历完后才跳出循环。循环语句中有一个continue语句,这个语句的作用是跳出当前循环。
以下场景便模拟了for循环结构与跳出当前循环的现实场景:
全班同学的试卷为一个序列,老师在批阅一个班同学的试卷时,需要从第一个同学开始一个一个批阅,然后根据每个同学的具体答卷情况给出最后得分。如果评阅到某张试卷时发现这位同学缺考,为空白卷,那么就不评阅这张试卷,直接评阅下一张。当全部同学的试卷都评阅完毕时,结束评阅,跳出循环。
本关的任务是让学习者学会使用for循环与continue语句。
编程要求
本关的编程任务是补全checkWork.py文件中的部分代码,具体要求如下:
填入循环遍历studentname列表的代码;
当遍历到缺席学生时,填入continue语句跳过此次循环。
absencenum = int(input())
studentname = []
inputlist = input()
for i in inputlist.split(','):
result = i
studentname.append(result)
count = 0
#循环遍历studentname列表
for i in studentname:
student=i
count += 1
if(count == absencenum):
continue
print(student,"的试卷已阅")
第3关:循环嵌套
任务描述
在Python 中,除了while循环与for循环,还有循环嵌套。循环嵌套就是在一个循环体里嵌入另一个循环。以下场景便模拟了循环嵌套与跳出循环的现实场景:
在一次考试结束后,学校需要统计每位同学的考试总成绩。在这个场景中,我们先将所有同学组成一个序列,然后遍历每位同学。在遍历到每位同学时还要遍历每位同学的每门分数并进行计算,最后得出每位同学的总成绩。
本关的任务是让学习者学会使用循环嵌套。
编程要求
本关的编程任务是补全sumScore.py文件中的部分代码,具体要求如下:
当输入学生人数后,填入在for循环遍历学生的代码;
当输入各科目的分数后的列表后,填入for循环遍历学生分数的代码。
studentnum = int(input())
#for循环遍历学生人数
for student in range(studentnum):
sum = 0
subjectscore = []
inputlist = input()
for i in inputlist.split(','):
result = i
subjectscore.append(result)
#for循环遍历学生分数
for score in subjectscore:
score = int(score)
sum = sum + score
print("第%d位同学的总分为:%d" %(student,sum))
第4关:迭代器
任务描述
迭代器用来循环访问一系列元素,它不仅可以迭代序列,也可以迭代不是序列但是表现出序列行为的对象。本关的任务是让学习者理解与学会使用迭代器。
相关知识
迭代器的优点:
迭代器访问与for循环访问非常相似,但是也有不同之处。对于支持随机访问的数据结构如元组和列表,迭代器并无优势。因为迭代器在访问的时候会丢失数据索引值,但是如果遇到无法随机访问的数据结构如集合时,迭代器是唯一访问元素的方式;
迭代器仅仅在访问到某个元素时才使用该元素。在这之前,元素可以不存在,所以迭代器很适用于迭代一些无法预先知道元素总数的巨大的集合;
迭代器提供了一个统一的访问集合的接口,定义iter()方法对象,就可以使用迭代器访问。
理解迭代器:
可直接作用于for循环的数据类型如list、tuple、dict等统称为可迭代对象:Iterable。使用isinstance()可以判断一个对象是否是可迭代对象。例如:
from collections import Iterable
result = isinstance([],Iterable)
print(result)
result = isinstance((),Iterable)
print(result)
result = isinstance(‘python’,Iterable)
print(result)
result = isinstance(213,Iterable)
print(result)
结果为:
True
True
True
False
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。next()函数访问每一个对象,直到对象访问完毕,返回一个StopIteration异常。使用isinstance()可以判断一个对象是否是Iterator对象。例如:
from collections import Iterator
result = isinstance([],Iterator)
print(result)
result = isinstance((),Iterator)
print(result)
result = isinstance((x for x in range(10)),Iterator)
print(result)
结果为:
False
False
True
所有的Iterable都可以通过iter()函数转化为Iterator。
定义迭代器:
当自己定义迭代器时,需要定义一个类。类里面包含一个iter()函数,这个函数能够返回一个带next()方法的对象。例如:
class MyIterable:
def iter(self):
return MyIterator()
class MyIterator:
def init(self):
self.num = 0
def next(self):
self.num += 1
if self.num >= 10:
raise StopIteration
return self.num
复制迭代器:
迭代器当一次迭代完毕后就结束了,在此调用便会引发StopIteration异常。如果想要将迭代器保存起来,可以使用复制的方法:copy.deepcopy():x = copy.deepcopy(y),不可使用赋值的方法,这样是不起作用的。
如果您想了解更多迭代器的相关知识,请参考:[美] Wesley J.Chun 著《 Python 核心编程》第八章。
编程要求
本关的编程任务是补全ListCalculate.py文件中的部分代码,具体要求如下:
当输入一个列表时,填入将列表List转换为迭代器的代码;
填入用next()函数遍历迭代器IterList的代码。
本关涉及的代码文件ListCalculate.py的代码框架如下:
List = []
member = input()
for i in member.split(‘,’):
result = i
List.append(result)
#请在此添加代码,将List转换为迭代器的代码
########## Begin ##########
########## End ##########
while True:
try:
# 请在此添加代码,用next()函数遍历IterList的代码
########## Begin ##########
########## End ##########
result = int(num) * 2
print(result)
except StopIteration:
break
测试说明
本文的测试文件是ListCalculate.py,具体测试过程如下:
平台自动编译生成ListCalculate.exe;
平台运行ListCalculate.exe,并以标准输入方式提供测试输入;
平台获取ListCalculate.exe输出,并将其输出与预期输出对比。如果一致则测试通过,否则测试失败。
以下是平台对src/step4/ListCalculate.py的样例测试集:
预期输入:
5,6,7,8,9
预期输出:
10
12
14
16
18
开始你的任务吧,祝你成功!
List = []
member = input()
for i in member.split(','):
result = i
List.append(result)
#将List转换为迭代器
it = iter(List)
while True:
try:
#用next()函数遍历IterList
num = next(it)
result = int(num) * 2
print(result)
except StopIteration:
break
十、顺序与选择结构
第1关:顺序结构
任务描述
程序最基本的结构就是顺序结构,顺序结构就是程序按照语句顺序,从上到下依次执行各条语句。
本关要求学习者理解顺序结构,并对输入的三个数changeone、changetwo、plus先交换changeone、changetwo值,然后再计算changeone + plus的值。
编程要求
本关的编程任务是补全inTurn.py文件中的函数部分,程序中给出a、b、c三个整数,要求实现先交换a、b的值,然后计算a + c的值并输出。
changeOne = int(input())
changeTwo = int(input())
plus = int(input())
#交换changeOne,changeTwo的值,然后计算changeOne和plus的和result的值
tmp = changeOne
changeOne = changeTwo
changeTwo = tmp
result = changeOne + plus
print(result)
第2关:选择结构:if-else
任务描述
程序的第二大结构就是选择结构。在此结构中,程序通过对一个代码块或者几个代码块的判断来决定接下来运行哪一个代码块。以下场景还原了选择结构的现实场景:
某公司根据员工的工龄来决定员工工资的涨幅,如下所示:
工龄大于等于5年并小于10年时,涨幅是现工资的5%;
工龄大于等于10年并小于15年时,涨幅是现工资的10%;
工龄大于等于15年时,工资涨幅为15%。
本关的任务是让学习者理解选择结构,学会使用最基本的选择语句:if-else语句。
编程要求
本关的编程任务是补全choose.py文件中的判断语句部分,具体要求如下:
填入如果workYear < 5的判断语句;
填入如果workYear >= 5 and workYear < 10的判断语句;
填入如果workYear >= 10 and workYear < 15的判断语句;
填入当上述条件判断都为假时的判断语句。
workYear = int(input())
#如果workYear < 5的判断语句
if workYear < 5:
print("工资涨幅为0")
#如果workYear >= 5 and workYear < 10的判断语句
if workYear >=5 and workYear < 10:
print("工资涨幅为5%")
#如果workYear >= 10 and workYear < 15的判断语句
if workYear >= 10 and workYear < 15:
print("工资涨幅为10%")
#当上述条件判断都为假时的判断语句
else:
print("工资涨幅为15%")
第3关:选择结构 : 三元操作符
任务描述
程序中的选择结构中除了if-else、elif之外,还有一个三元操作符。三元操作符也是根据条件判断执行哪一个代码块,但它的最大特点是不需要像if-else语句那样写多行代码,而是只需一行代码。
本关要求学习者能够学会并使用三元操作符来判断谁才是射击比赛的赢家。
编程要求
本关的编程任务是补全isWin.py文件中的判断语句部分,具体要求如下:
根据输入的jim与jerry的射击得分进行判断;
若jim得分更高,则赢家为jim,输出jim的名字;
若jerry得分更高,则赢家为jerry,输出jerry的名字。
jimscore = int(input())
jerryscore = int(input())
#判断若jim的得分jimscore更高,则赢家为jim。
#若jerry的得分jerryscore更高,则赢家为jerry并输出赢家的名字。
if jimscore < jerryscore:
winner = 'jerry'
else:
winner = 'jim'
print(winner)
十一、类的基础语法
第1关:类的声明与定义
任务描述:
Python 是一门面向对象的语言。面向对象编程 - Object Oriented Programming(简称 OOP)是一种编程思想,在面向对象编程中,把对象作为程序的基本单元,把程序视为一系列对象的集合。一个对象包括了数据和操作数据的方法,消息传递成为联系对象的方法。
编程要求:
本关的编程任务是补全Book.py文件中的代码,具体要求如下:
在类头部填入定义Book类的代码。
本关涉及的代码文件Book.py的代码框架如下:
请在下面填入定义Book类的代码
########## Begin ##########
########## End ##########
‘书籍类’
def init(self,name,author,data,version):
self.name = name
self.author = author
self.data = data
self.version = version
def sell(self,bookName,price):
print(“%s的销售价格为%d” %(bookName,price))
class Book:
def __init__(self, name, author, data, version):
self.name = name
self.author = author
self.data = data
self.version = version
def sell(self, bookName, price):
print("%s的销售价格为%d" % (bookName, price))
第2关:类的属性与实例化
任务描述:
属性就是对类和对象特征的描述,外部以属性来区分不同的类,类具有数据属性和方法。而由类创建出来的实例-对象,具有它所属的类的数据属性和方法。
例如,书本是一个类,它具有作者、书名、出版社等数据属性,它还具有销售这一个方法。《 Python 核心编程》就是书本类的一个对象,它也具有作者、书名、出版社等数据属性和销售这一个方法。本关的任务是让学习者掌握类的属性与实例化。
编程要求:
本关的编程任务是补全People.py文件中的声明变量和实例化部分,具体要求如下:
填入声明两个变量名分别为name和country的字符串变量的代码;
填入对类People进行实例化的代码,实例对象为p。
本关涉及的代码文件People.py的代码框架如下:
class People:
def introduce(self,name,country):
self.name = name
self.country = country
print(“%s来自%s” %(name,country))
name = input()
country = input()
请在下面填入对类People进行实例化的代码
########## Begin ##########
########## End ##########
p.introduce(name,country)
class People:
def introduce(self, name, country):
self.name = name
self.country = country
print("%s来自%s" % (name, country))
name = input()
country = input()
# 请在下面填入对类People进行实例化的代码,对象为p
p = People()
########## Begin ##########
########## End ##########
p.introduce(name, country)
第3关:类的导入
任务描述:
当我们在写代码时,经常会遇到一种情况:我们要用到的一些功能已经在别的模块里定义过了,如果我们重新写一遍这个功能必然会使得代码冗长且效率低下。于是我们使用导入的方法将其它模块里的功能导入到自己的代码里,让我们在编写代码时能够使用。本关的任务就是让学习者者掌握如何导入类。
编程要求:
本关的测试文件DataChangetest.py中定义了一个类DataChange,这个类实现了将八进制转换为十进制然后输出,这个功能由这个类中的eightToten(self,p)方法实现。
本关的编程任务是补全DataChange.py文件中的导入模块并调用方法实现数制转换功能,具体要求如下:
从DataChangetest模块中导入DataChange类,并使用该类中的eightToten(self,p)方法,实现将输入的八进制转换成十进制输出,其中p是输入的变量。
本关涉及的代码文件DataChange.py的代码框架如下:
从 DataChangetest 模块中导入 DataChange 类,并使用该类中的 eightToten(self,p) 方法,实现将输入的八进制转换成十进制输出。
########## Begin ##########
########## End ##########
# 这题值得注意的是:你需要在DataChange类中添加一个名为eightToten的方法,该方法接收一个八进制字符串作为参数,并返回其对应的十进制整数。####Jzh##
from DataChangetest import DataChange
class MyDataChange(DataChange):
def eightToten(self, p):
return int(p, 8)
def main():
## p为能够接受八进制数据的变量 ####Jzh##
p = input()
data_change = MyDataChange()
result = data_change.eightToten(p)
print(result)
if __name__ == "__main__":
main()
十二、类的继承
第1关:初识继承
任务描述:
在面向对象编程中,有一种机制叫做继承。通过继承,子类可以继承其父类所有的属性和方法,这在很大程度上增强了代码的重用。以下场景便模拟了继承的现实场景:在自然界中存在着许多的动物,动物间有许多的共性。比如:呼吸、奔跑、觅食等,但是它们之间也存在着不同之处,比如鱼会游泳、豹子会爬树……
在上面这个场景里,动物就是父类,它具有着所有动物都有的共性,而鱼和豹子是子类,它们不仅具有共性:呼吸、奔跑、觅食,还有着自己独特的特征:游泳、爬树。本关的任务是让学习者掌握 Python 中类的继承机制。
编程要求:
本关的测试文件中定义了一个父类animals类(animalstest模块中已经定义好的类),在此类中定义了三个方法,分别为:breath()、run()、foraging()。而在通关文件中,定义了两个类:fish与leopard,这两个类都继承自animals类。
本关的编程任务是补全animals.py文件中的定义子类部分,具体要求如下:
填入定义继承自animals类的fish类的代码;
填入定义继承自animals类的leopard类的代码。
本关涉及的代码文件src/Step1/animals.py的代码框架如下:
import animalstest
请在下面填入定义fish类的代码,fish类继承自animals类
########## Begin ##########
########## End ##########
def init(self,name):
self.name = name
def swim(self):
print(“%s会游泳” %self.name)
请在下面填入定义leopard类的代码,leopard类继承自animals类
########## Begin ##########
########## End ##########
def init(self,name):
self.name = name
def climb(self):
print(“%s会爬树” %self.name)
fName = input()
f = fish(fName)
f.breath()
f.swim()
f.foraging()
lName = input()
l = leopard(lName)
l.breath()
l.run()
l.foraging()
import animalstest
# 请在下面填入定义fish类的代码,fish类继承自animals类
########## Begin ##########
class fish(animalstest.animals):
########## End ##########
def __init__(self,name):
self.name = name
def swim(self):
print("%s会游泳" %self.name)
# 请在下面填入定义leopard类的代码,leopard类继承自animals类
########## Begin ##########
class leopard(animalstest.animals):
########## End ##########
def __init__(self,name):
self.name = name
def climb(self):
print("%s会爬树" %self.name)
fName = input()
lName = input()
f = fish(fName)
f.breath()
f.swim()
f.foraging()
l = leopard(lName)
l.breath()
l.run()
l.foraging()
第2关:覆盖方法
任务描述:
在子类继承父类的方法时,若子类需要这个方法具有不同的功能,那么可以通过覆盖(overriding)来重写这个方法。本关的任务是让学习者掌握通过继承覆盖方法。
编程要求:
本关的任务是补全Point.py文件中的代码,具体要求如下:
填入覆盖父类getPoint()方法的代码,并在这个方法中分别得出x - y与z - h结果的绝对值。
本关涉及的代码文件src/Step2/Point.py的代码框架如下:
class point:
def init(self,x,y,z,h):
self.x = x
self.y = y
self.z = z
self.h = h
def getPoint(self):
return self.x,self.y,self.z,self.h
class line(point):
# 请在下面填入覆盖父类getPoint()方法的代码,并在这个方法中分别得出x - y与z - h结果的绝对值
########## Begin ##########
########## End ##########
print(length_one,length_two)
class Point:
def __init__(self,x,y,z,h):
self.x = x
self.y = y
self.z = z
self.h = h
def getPoint(self):
return self.x,self.y,self.z,self.h
class Line(Point):
# 请在下面填入覆盖父类getPoint()方法的代码,并在这个方法中分别得出x - y与z - h结果的绝对值
########## Begin ##########
def getPoint(self):
length_one = abs(self.x - self.y)
length_two = abs(self.z - self.h)
########## End ##########
print(length_one,length_two)
第3关:多重继承
任务描述:
在 Python 中,多重继承就是允许子类继承多个父类,子类可以调用多个父类的方法和属性。但是,当多个父类拥有相同方法名的方法时,我们通过方法名调用父类方法就有一定的顺序。本关的任务就是让学习者掌握多重继承。
在这个例子中,类C继承自类A和类B,类D继承自类A和类B,类E继承自类C和类D。继承情况如下图所示:
编程要求:
本关的编程任务是补全src/Step4/multiInherit.py文件的代码,实现当调用类E的test()时,继承的是类A的test()。具体要求如下:
填入定义子类C的代码;
填入定义子类D的代码。
本关涉及的代码文件src/Step4/multiInherit.py的代码框架如下:
class A(object):
def test(self):
print(“this is A.test()”)
class B(object):
def test(self):
print(“this is B.test()”)
def check(self):
print(“this is B.check()”)
请在下面填入定义类C的代码
########## Begin ##########
########## End ##########
pass
请在下面填入定义类D的代码
########## Begin ##########
########## End ##########
def check(self):
print(“this is D.check()”)
class E(C,D):
pass
e = E()
e.test()
<code>class A(object):
def test(self):
print("this is A.test()")
class B(object):
def test(self):
print("this is B.test()")
def check(self):
print("this is B.check()")
# 请在下面填入定义类C的代码
########## Begin ##########
class C(A,B):
########## End ##########
pass
# 请在下面填入定义类D的代码
########## Begin ##########
class D(A,B):
########## End ##########
def check(self):
print("this is D.check()")
class E(C,D):
pass
十三、类的其它特性
第1关:类的私有化
任务描述:
在默认的情况下,Python 中的属性都是公开的(public),这就意味着此类所在的模块和导入了这个类的模块都可以访问到这个类中的属性和方法。但有时我们不希望外界直接访问某方法或属性,此时我们可以将这个方法和属性私有化。本关的任务就是让学习者掌握类的私有化。
编程要求:
在本关的Bagtest.py文件中,分别定义了两个私有变量:__price与_price。本关的编程任务是补全Bag.py文件中的调用Bagtest.py文件中私有变量的代码,具体要求如下:
填入输出Bag类中变量__price的代码;
填入输出Bag类中变量_price的代码。
本关涉及的代码文件src/step2/Bag.py的代码框架如下:
import Bagtest
price = int(input())
bag = Bagtest.Bag(price)
请在下面填入输出Bag类中变量__price的代码
########## Begin ##########
########## End ##########
请在下面填入输出Bag类中变量_price的代码
########## Begin ##########
########## End ##########
import Bagtest
price = int(input())
bag = Bagtest.Bag(price)
# 请在下面填入输出Bag类中变量__price的代码
print(bag._Bag__price)
# 请在下面填入输出Bag类中变量_price的代码
print(bag._price)
十四、NumPy基础及取值操作
第1关:ndarray对象
任务描述:
本关任务:根据本关所学知识,补全右侧代码编辑器中缺失的代码,完成程序的编写并通过所有测试用例。
编程要求:
根据提示,在右侧编辑器Begin-End中填充代码,根据测试用例的输入,实例化出对应的ndarray对象并打印。
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
shape:为需要实例化出来的ndarray对象的shape;
data:表示需要实例化出来的ndarray对象中元素的值。
例如:{‘shape’:[1, 2], ‘data’:[[1, 2]]}表示ndarray对象的形状为1行2列,第1行第1列的值为1,第1行第2列的值为2。
测试输入:
{‘shape’:[1, 2], ‘data’:[[1, 2]]}
预期输出:
[[1 2]]
import numpy as np
def print_ndarray(input_data):
'''
实例化ndarray对象并打印
:param input_data: 测试用例,类型为字典类型
:return: None
'''
#********* Begin *********#
print(np.array(input_data['data']))
#********* End *********#
第2关:形状操作
任务描述:
本关任务:根据本关所学知识,补全右侧代码编辑器中缺失的代码,完成程序的编写并通过所有测试用例。
编程要求:
根据提示,在右侧编辑器Begin-End中填充代码,根据测试用例的输入,将列表转换成ndarray后变形成一维数组并将其打印。
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
[[1, 2, 3], [4, 5, 6]]
预期输出:
[1, 2, 3, 4, 5, 6]
import numpy as np
a = np.zeros((3, 4))
import numpy as np
a = np.zeros((3, 4))
import numpy as np
a = np.zeros((3, 4))
import numpy as np
def reshape_ndarray(input_data):
'''
将ipnut_data转换成ndarray后将其变形成一位数组并打印
:param input_data: 测试用例,类型为list
:return: None
'''
#********* Begin *********#
temp = np.array(input_data)
tat = temp.reshape((1,-1))
for i in tat:
print(i)
#********* End *********#
第3关:基础操作
任务描述:
本关任务:根据本关所学知识,补全右侧代码编辑器中缺失的代码,完成程序的编写并通过所有测试用例。
编程要求:
根据提示,在右侧编辑器Begin-End处补充代码,根据测试用例的输入,打印每行的最大值的位置。
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
[[0.2, 0.7, 0.1], [0.1, 0.3, 0.6]]
预期输出:
[1 2]
import numpy as np
def get_answer(input_data):
'''
将input_data转换成ndarray后统计每一行中最大值的位置并打印
:param input_data: 测试用例,类型为list
:return: None
'''
#********* Begin *********#
temp = np.array(input_data)
List = []
for value in temp:
List.append(value.argmax())
print(np.array(List))
#********* End *********#
第4关:随机数生成
任务描述:
本关任务:根据本关所学知识,补全右侧代码编辑器中缺失的代码,完成程序的编写并通过所有测试用例。
编程要求:
根据提示,在右侧编辑器Begin-End处补充代码,将测试用例输入打乱顺序并返回打乱结果。
具体要求请参见后续测试样例。
注意:评测程序内部已经设置好了随机种子,为了顺利评测,请使用np.random.choice()函数来实现打乱顺序。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
[1, 2, 3, 4, 5, 6]
预期输出:
[4, 3, 5, 1, 2, 6]
import numpy as np
def shuffle(input_data):
'''
打乱input_data并返回打乱结果
:param input_data: 测试用例输入,类型为list
:return: result,类型为list
'''
# 保存打乱的结果
result = []
#********* Begin *********#
temp = np.random.choice(input_data,size=len(input_data),replace=False)
result = temp.tolist()
#********* End *********#
return result
第5关:索引与切片
任务描述
本关任务:根据本关所学知识,补全右侧代码编辑器中缺失的代码,完成ROI提取的功能。
编程要求
在图像处理中,我们通常会将我们感兴趣的区域提取出来再进行处理,而这个感兴趣区域成为ROI(Region Of Interest)。本关的任务是根据提示,在右侧编辑器Begin-End处补充代码,根据测试用例的输入将ROI的提取并返回(ROI是一个矩阵)。
import numpy as np
def get_roi(data, x, y, w, h):
'''
提取data中左上角顶点坐标为(x, y)宽为w高为h的ROI
:param data: 二维数组,类型为ndarray
:param x: ROI左上角顶点的行索引,类型为int
:param y: ROI左上角顶点的列索引,类型为int
:param w: ROI的宽,类型为int
:param h: ROI的高,类型为int
:return: ROI,类型为ndarray
'''
#********* Begin *********#
return data[x:x+h+1,y:y+w+1]
#********* End *********#
十五、NumPy数组的高级操作
第1关:堆叠操作
任务描述
本关任务:根据本关所学知识,实现均值统计功能。
编程要求
根据本关所学知识,补充完成get_mean(featur1, feature2)函数,其中:
feature1:待hstack的ndarray;
feature2:待hstack的ndarray;
返回值:类型为ndarray,其中值为hstack后每列的平均值;
import numpy as np
def get_mean(feature1, feature2):
'''
将feature1和feature2横向拼接,然后统计拼接后的ndarray中每列的均值
:param feature1:待`hstack`的`ndarray`
:param feature2:待`hstack`的`ndarray`
:return:类型为`ndarray`,其中的值`hstack`后每列的均值
'''
#********* Begin *********#
return np.mean(np.hstack((feature1,feature2)), 0)
#********* End *********#
第2关:比较、掩码和布尔逻辑
任务描述
本关任务:编写一个能比较并筛选数据的程序。
编程要求
请在右侧编辑器Begin-End处补充代码,根据输入的数据筛选出大于num的值。
import numpy as np
def student(num,input_data):
result=[]
# ********* Begin *********#
a = np.array(input_data)
result = a[a > num]
# ********* End *********#
return result
第3关:花式索引与布尔索引
任务描述
本关任务:根据本关所学知识,过滤大写字母。
编程要求
请在右侧编辑器Begin-End处补充代码,根据函数参数input_data过滤出所有的大写字母。
import numpy as np
def student(input_data):
result=[]
#********* Begin *********#
a = np.array(input_data)
result = a[(a>='A')&(a<='Z')]
# ********* End *********#
return result
第4关:广播机制
任务描述
本关任务:利用广播机制实现Z-score标准化。
编程要求
请在右侧编辑器Begin-End处补充代码,将输入数据转换为array并计算它们的和。
import numpy as np
def student(a,b,c):
result=[]
# ********* Begin *********#
a = np.array(a)
b = np.array(b)
c = np.array(c)
result = a + b + c
# ********* End *********#
return result
第5关:线性代数
任务描述
本关任务:编写一个能求解线性方程的函数。
编程要求
请在右侧编辑器Begin-End处补充代码,计算性别为男的线性方程解,前两个数为方程左边,最后一个数为方程右边。
from numpy import linalg
import numpy as np
def student(input_data):
'''
将输入数据筛选性别为男,再进行线性方程求解
:param input_data:类型为`list`的输入数据
:return:类型为`ndarray`
'''
result=[]
# ********* Begin *********#
a = np.array(input_data)
x=[]
y=[]
for i in a:
if i[0]=="男":
x.append([int(i[1]),int(i[2])])
y.append([int(i[-1])])
if x==[] and y==[]:
return result
x=np.array(x)
y=np.array(y)
result=linalg.solve(x,y)
# ********* End *********#
return result
十六、Numpy 进阶
第1关:Numpy 广播
任务描述
本关任务:给定两个不同形状的数组,求出他们的和。
编程要求
首先用 arange() 生成一个数组,然后用 reshape() 方法,将数组切换成 4x3 的形状,最后再与 basearray 相加,输出它们的和。
请按照编程要求,补全右侧编辑器 Begin-End 内的代码。
import numpy as np
basearray = eval(input())
# *********** Begin ************ #
arr=np.arange(12).reshape(4,3)
# ************ End ************* #
print("{} + \n{}".format(arr,basearray))
print("结果为:\n{}".format(basearray+arr))
第2关:Numpy 高级索引
任务描述
本关任务:给定一个二维数组,请以整数数组索引、布尔索引、花式索引三种方式,来获取我们需要的数组元素。
编程要求
首先,利用花式索引获取 arr 数组第 line 行(至少两行)的数组 a;然后,利用整数数组索引获取数组四个角(按行优先的顺序获取)的元素得到数组 b;最后,再利用布尔索引获取大于 10 的元素得到数组 c,并输出 c。
请按照编程要求,补全右侧编辑器 Begin-End 内的代码。
import numpy as np
'''
arr为一个ndarray类型的数组,line为花式索引的索引数组
'''
def advanced_index(arr,line):
# ********** Begin *********** #
a = arr[line]
row,column = a.shape
b = a[[0,0,row-1,row-1],[0,column-1,0,column-1]]
c = b[b>10]
# *********** End ************ #
return c
def main():
line = list(map(lambda x:int(x),input().split(",")))
arr = np.arange(24).reshape(6, 4)
print(advanced_index(arr,line))
if __name__ == '__main__':
main()
第3关:Numpy 迭代数组
任务描述
本关任务:利用本关相关知识,将一个 ndarray 类型的数组,顺时针旋转 90 度后输出。
编程要求
根据提示,在右侧编辑器 Begin-End 内补充代码,将一个 ndarray 类型的数组顺时针旋转 90 度后输出。
提示:
建议使用外部循环;
np.vstack()可以将两个数组竖直堆叠成为新的数组。
import numpy as np
'''传入的参数为ndarray类型数组'''
def rotate_array(arr):
# ******* Begin ******* #
result= np.ones((arr.shape[1],arr.shape[0]),dtype=np.int64)
for i in range(arr.shape[1]):
for j in range(arr.shape[0]):
result[i][arr.shape[0]-1-j] = arr[j][i]
# ******* End ******** #
return result
def main():
arr = eval(input())
print(rotate_array(arr))
if __name__ == '__main__':
main()
十七、Pandas初体验
第1关:了解数据处理对象–Series
任务描述
本关任务:仔细阅读编程要求,完成相关要求。
编程要求
根据提示,在右侧编辑器Begin-End处补充代码:
创建一个名为series_a的series数组,当中值为[1,2,5,7],对应的索引为[‘nu’, ‘li’, ‘xue’, ‘xi’];
创建一个名为dict_a的字典,字典中包含如下内容{‘ting’:1, ‘shuo’:2, ‘du’:32, ‘xie’:44};
将dict_a字典转化成名为series_b的series数组。
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def create_series():
'''
返回值:
series_a: 一个Series类型数据
series_b: 一个Series类型数据
dict_a: 一个字典类型数据
'''
# 请在此添加代码 完成本关任务
# ********** Begin *********#
series_a=Series([1,2,5,7],index=['nu','li','xue','xi'])
dict_a={ 'ting':1, 'shuo':2, 'du':32, 'xie':44}
series_b=Series(dict_a)
# ********** End **********#
# 返回series_a,dict_a,series_b
return series_a,dict_a,series_b
第2关:了解数据处理对象-DataFrame
任务描述
本关任务:根据编程要求,完成相关代码的编写。
编程要求
根据提示,在右侧编辑器begin-end处补充代码:
创建一个五行三列的名为df1的DataFrame数组,列名为 [states,years,pops],行名[‘one’,‘two’,‘three’,‘four’,‘five’];
给df1添加新列,列名为new_add,值为[7,4,5,8,2]。
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def create_dataframe():
'''
返回值:
df1: 一个DataFrame类型数据
'''
# 请在此添加代码 完成本关任务
# ********** Begin *********#
dictionary = { 'states':['0hio','0hio','0hio','Nevada','Nevada'],
'years':[2000,2001,2002,2001,2002],
'pops':[1.5,1.7,3.6,2.4,2.9]}
df1 = DataFrame(dictionary)
df1=DataFrame(dictionary,index=['one','two','three','four','five'])
df1['new_add']=[7,4,5,8,2]
# ********** End **********#
#返回df1
return df1
第3关:读取CSV格式数据
任务描述
本关任务:根据编程要求,完成相关代码的编写。
编程要求
根据提示,在右侧编辑器begin-end处补充代码:
将test3/uk_rain_2014.csv中的数据导入到df1中;
将列名修改为[‘water_year’,‘rain_octsep’,‘outflow_octsep’,‘rain_decfeb’, ‘outflow_decfeb’, ‘rain_junaug’, ‘outflow_junaug’];
计算df1的总行数并存储在length1中。
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def read_csv_data():
'''
返回值:
df1: 一个DataFrame类型数据
length1: 一个int类型数据
'''
# 请在此添加代码 完成本关任务
# ********** Begin *********#
df1 = pd.read_csv('test3/uk_rain_2014.csv', header=0)
df1.columns = ['water_year','rain_octsep','outflow_octsep','rain_decfeb', 'outflow_decfeb', 'rain_junaug', 'outflow_junaug']
length1=len(df1)
# ********** End **********#
#返回df1,length1
return df1,length1
第4关:数据的基本操作——排序
任务描述
本关任务:根据编程要求,完成相关代码的编写。
编程要求
根据提示,在右侧编辑器Begin-End处补充代码:
对代码中s1进行按索引排序,并将结果存储到s2;
对代码中d1进行按值排序(index为f),并将结果存储到d2。
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def sort_gate():
'''
返回值:
s2: 一个Series类型数据
d2: 一个DataFrame类型数据
'''
# s1是Series类型数据,d1是DataFrame类型数据
s1 = Series([4, 3, 7, 2, 8], index=['z', 'y', 'j', 'i', 'e'])
d1 = DataFrame({ 'e': [4, 2, 6, 1], 'f': [0, 5, 4, 2]})
# 请在此添加代码 完成本关任务
# ********** Begin *********#
s2=s1.sort_index()
d2=d1.sort_values(by='f')code>
# ********** End **********#
#返回s2,d2
return s2,d2
第5关:数据的基本操作——删除
任务描述
本关任务:根据编程要求,完成相关代码的编写。
编程要求
根据提示,在右侧编辑器Begin-End处补充代码:
在s1中删除z行,并赋值到s2;
d1中删除yy列,并赋值到d2。
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import numpy as np
import pandas as pd
def delete_data():
'''
返回值:
s2: 一个Series类型数据
d2: 一个DataFrame类型数据
'''
# s1是Series类型数据,d1是DataFrame类型数据
s1 = Series([5, 2, 4, 1], index=['v', 'x', 'y', 'z'])
d1=DataFrame(np.arange(9).reshape(3,3), columns=['xx','yy','zz'])
# 请在此添加代码 完成本关任务
# ********** Begin *********#
s2=s1.drop('z')
d2=d1.drop(['yy'],axis=1)
# ********** End **********#
# 返回s2,d2
return s2, d2
第6关:数据的基本操作——算术运算
任务描述
本关任务:根据编程要求,完成相关代码的编写。
编程要求
根据提示,在右侧编辑器Begin-End处补充代码:
让df1与df2相加得到df3,并设置默认填充值为4。
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import numpy as np
import pandas as pd
def add_way():
'''
返回值:
df3: 一个DataFrame类型数据
'''
# df1,df2是DataFrame类型数据
df1 = DataFrame(np.arange(12.).reshape((3, 4)), columns=list('abcd'))
df2 = DataFrame(np.arange(20.).reshape((4, 5)), columns=list('abcde'))
# 请在此添加代码 完成本关任务
# ********** Begin *********#
df3=df1.add(df2,fill_value=4)
# ********** End **********#
# 返回df3
return df3
第7关:数据的基本操作——去重
任务描述
本关任务:根据编程要求,完成相关代码的编写。
编程要求
根据提示,在右侧编辑器Begin-End处补充代码:
去除df1中重复的行,并把结果保存到df2中。
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def delete_duplicated():
'''
返回值:
df2: 一个DataFrame类型数据
'''
# df1是DataFrame类型数据
df1 = DataFrame({ 'k1': ['one'] * 3 + ['two'] * 4, 'k2': [1, 1, 2, 3, 3, 4, 4]})
# 请在此添加代码 完成本关任务
# ********** Begin *********#
df2=df1.drop_duplicates()
# ********** End **********#
# 返回df2
return df2
第8关:层次化索引
任务描述
本关任务:根据编程要求,完成相关代码的编写。
编程要求
根据提示,在右侧编辑器Begin-End处补充代码:
对s1进行数据重塑,转化成DataFrame类型,并复制到d1。
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
def suoying():
'''
返回值:
d1: 一个DataFrame类型数据
'''
#s1是Series类型数据
s1=Series(np.random.randn(10),
index=[['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'd', 'd'], [1, 2, 3, 1, 2, 3, 1, 2, 2, 3]])
# 请在此添加代码 完成本关任务
# ********** Begin *********#
d1=s1.unstack()
# ********** End **********#
# 返回d1
return d1
suoying()
十八、Pandas 进阶
第1关:Pandas 分组聚合
任务描述
本关任务:使用 Pandas 加载 drinks.csv 文件中的数据,根据数据信息求每个大洲红酒消耗量的最大值与最小值的差以及啤酒消耗量的和。
编程要求
使用 Pandas 中的 read_csv() 函数读取 step1/drinks.csv 中的数据,数据的列名如下表所示,请根据 continent 分组并求每个大洲红酒消耗量的最大值与最小值的差以及啤酒消耗量的和。在右侧编辑器 Begin-End 内补充代码。
列名 说明
country 国家名
beer_servings 啤酒消耗量
spirit_servings 白酒消耗量
wine_servings 红酒消耗量
total_litres_of_pure_alcohol 纯酒精总量
continent 大洲名
import pandas as pd
import numpy as np
#返回最大值与最小值的差
def sub(df):
######## Begin #######
return df.max() - df.min()
######## End #######
def main():
######## Begin #######
data = pd.read_csv("step1/drinks.csv")
df = pd.DataFrame(data)
mapping = { "wine_servings":sub,"beer_servings":np.sum}
print(df.groupby("continent").agg(mapping))
######## End #######
if __name__ == '__main__':
main()
第2关:Pandas 创建透视表和交叉表
任务描述
本关任务:使用 Pandas 加载 tip.csv 文件中的数据集,分别用透视表和交叉表统计顾客在每种用餐时间、每个星期下的小费总和情况。
编程要求
使用 Pandas 中的 read_csv 函数加载 step2/tip.csv 文件中的数据集,分别用透视表和交叉表统计顾客在每种用餐时间(time) 、每个星期下(day) 的 小费(tip)总和情况。在右侧编辑器 Begin-End 内补充代码。
数据集列名信息如下表:
列名 说明
total_bill 消费总账单
tip 小费金额
day 消费日期(星期几)
time 用餐时间段(早、中、晚)
size 吸烟数量
#-*- coding: utf-8 -*-
import pandas as pd
#创建透视表
def create_pivottalbe(data):
###### Begin ######
return data.pivot_table(index=["day"],values=["tip"],columns=["time"],margins=True,aggfunc=sum)
###### End ######
#创建交叉表
def create_crosstab(data):
###### Begin ######
return pd.crosstab(index=[data.day],columns=[data.time],values=data.tip,aggfunc=sum ,margins=True)
###### End ######
def main():
#读取csv文件数据并赋值给data
###### Begin ######
data = pd.read_csv("step2/tip.csv")
###### End ######
piv_result = create_pivottalbe(data)
cro_result = create_crosstab(data)
print("透视表:\n{}".format(piv_result))
print("交叉表:\n{}".format(cro_result))
if __name__ == '__main__':
main()
十九、 Matplotlib接口和常用图形
第1关:画图接口
任务描述
本关任务:掌握matplotlib的基本使用技巧,并能简单使用matplotlib进行可视化。
编程要求
在右侧编辑器Begin-End补充代码,对传入的x,y两个数组做折线图,x对应x轴,y对应y轴。并保存到Task1/image1/T2.png,具体要求如下:
折线图的figsize为(10, 10);
文件名为Task1/image1/T2.png。
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
def student(x,y):
# ********** Begin *********#
fig = plt.figure(figsize=(10,10))
plt.savefig("Task1/image1/T2.png")
plt.show()
# ********** End **********#
第2关:线形图
任务描述
本关任务:学习掌握matplotlib的第一个图形线形图,并能够使用线形常用配置。
编程要求
在右侧编辑器Begin-End补充代码,根据输入数据input_data,input_data1绘制两条折线图。依次为两组数据设置颜色样式为–g,:r;设置图例为L1,L2,具体要求如下:
折线图的figsize为(10, 10);
图形保存到Task2/img/T1.png。
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
def student(input_data,input_data1):
# ********* Begin *********#
fig = plt.figure(figsize=(10,10))
plt.plot(input_data,'--g')
plt.plot(input_data1,':r')
plt.legend(['L1','L2'])
plt.savefig("Task2/img/T1.png")
plt.show()
# ********* End *********#
第3关:散点图
任务描述
本关任务:编写一个包含三组不同样式的散点图。
编程要求
在右侧编辑器补充代码,根据输入的三组数据绘制三组不同参数的散点图,具体要求如下:
第一组数据参数设置标记大小为area,透明度为0.5;
第二组数据参数设置标记大小为area,标记颜色为绿色,透明度为0.6
第三组数据参数设置标记大小为area,标记颜色为area,标记样式为v,透明度为0.7;
图形的figsize为(10, 10);
图形保存到Task3/img/T1.png。
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
import numpy as np
def student(x,y,x2,y2,x3,y3,area):
'''
根据输入的三组数据绘制三组不同参数的散点图
:param x,y: 第一组数据,类型为array
:param x2,y2: 第二组数据,类型为array
:param x3,y3: 第三组数据,类型为array
:param area: 标记大小参数的值,类型为array
:return: None
'''
# ********* Begin *********#
fig = plt.figure(figsize=(10,10))
plt.scatter(x,y,s = area, alpha = 0.5)
plt.scatter(x2,y2,s = area, c = 'g', alpha = 0.6)
plt.scatter(x3,y3,s = area, marker = 'v', alpha = 0.7)
plt.savefig("Task3/img/T1.png")
plt.show()
# ********* End *********#
第4关:直方图
任务描述
本关任务:绘制一个包含直方图与线形图的图形。
编程要求
在右侧编辑器Begin-End处补充代码,根据输入数据将直方图与线形图绘制在同一面板中,并设置直方图为红色,线形图为蓝色,具体要求如下:
图形的figsize为(10, 10);
文件名为Task4/img/T1.png。
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
def student(data,x,y):
'''
根据输入数据将直方图与线形图绘制在同一面板中,并设置直方图为红色,线形图为蓝色
:param data: 绘制直方图数据,类型为list
:param x,y: 绘制线形图数据,类型为list
:return: None
'''
# ********* Begin *********#
fig = plt.figure(figsize=(10,10))
plt.hist(data,facecolor="red")code>
plt.plot(x,y,color="blue")code>
plt.savefig("Task4/img/T1.png")
plt.show()
# ********* End *********#
第5关:饼图
任务描述
本关任务:绘制一个饼图。
编程要求
在右侧编辑器Begin-End处补充代码,根据输入数据labels、quants绘制饼图,并设置第二块突出0.1和显示各块的百分比,具体要求如下:
输入数据labels、quants为长度为10的列表
图形的figsize为(6, 6)
文件名为Task5/img/T1.png
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import numpy as np
def student(labels,quants):
# ********* Begin *********#
fig=plt.figure(figsize=(6,6))
sizes = quants
plt.pie(sizes,labels=labels,explode=(0,0.1,0,0,0,0,0,0,0,0),autopct='%1.1f%%')code>
plt.savefig("Task5/img/T1.png")
plt.show()
# ********* End *********#
二十、Matplotlib子图与多子图
第1关:手动创建子图
任务描述
本关任务:绘制一个包含两个样式不一致的子图。
编程要求
根据提示,在右侧编辑器Begin-End处补充代码,根据输入数据绘制一个一行两列的折线图子图。子图一设置输入数据为x轴,输入数据的平方为y轴;设置颜色为红色;linestyle为–;线的宽度为1;透明的为0.3。子图二设置输入数据为x轴,输入数据的自然对数为y轴,具体可视化要求如下:
图形的figsize为(12, 12);
图形保存到Task1/img/T1.png。
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
def student(x):
'''
根据输入数据绘制不同的两个子图
:param x: 输入数据,类型为array
:return: None
'''
# ********* Begin *********#
fig = plt.figure(figsize=(12, 12))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
ax1.plot(x,x**2,ls="--",c="red",lw=1,alpha=0.3)code>
ax2.plot(x,np.log(x))
plt.savefig('Task1/img/T1.png')
plt.show()
# ********* End *********#
x = np.linspace(1, 10, 100)
student(x)
第2关:网格子图
任务描述
本关任务:编写一个能绘制一个两行四列的网格子图的程序。
编程要求
在右侧编辑器Begin-End处补充代码,绘制不同一个两行四列的网格子图,并设置图形高度与宽度为0.4,具体可视化要求如下:
图形的figsize为(10, 10);
图形保存到Task2/img/T1.png。
import matplotlib
matplotlib.use("Agg")
import numpy as np
import matplotlib.pyplot as plt
def student():
'''
绘制不同一个两行四列的网格子图,并设置图形高度与宽度为0.4
:param: None
:return: None
'''
# ********* Begin *********#
fig = plt.figure(figsize=(10, 10))
fig.subplots_adjust(hspace=0.4,wspace=0.4)
for i in range(1,9):
plt.subplot(2,4,i)
plt.savefig("Task2/img/T1.png")
plt.show()
# ********* End *********#
第3关:更复杂的排列方式
任务描述
本关任务:编写一个绘制不规则子图的函数。
编程要求
在右侧编辑器Begin-End处补充代码,绘制一个2行4列的不规则子图宽高间隔分别为0.4、0.3。第0行设置2个子图,第一个子图占3,第二个子图占1。第二行相反,具体可视化要求如下:
图形的figsize为(10, 10);
图形保存到Task3/img/T1.png。
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
def student():
'''
绘制一个2行4列的不规则子图宽高间隔分别为0.4、0.3。
第0行设置2个子图,第一个子图占3,第二个子图占1。第二行相反
:param: None
:return: None
'''
# ********* Begin *********#
fig = plt.figure(figsize=(10, 10))
grid=plt.GridSpec(2,4,wspace=0.4,hspace=0.3)
plt.subplot(grid[0,0:3])
plt.subplot(grid[0,-1])
plt.subplot(grid[-1,0])
plt.subplot(grid[-1,1:])
plt.savefig('Task3/img/T1.png')
plt.show()
# ********* End *********#
二十一、Python面向对象编程实训
第1关:按揭贷款——定义抽象类
任务描述
本关主题是利用 Python 面向对象编程技术,对按揭贷款的问题,进行面向对象建模与编程。请仔细阅读下面“相关知识”中的内容,理解每个函数所需完成的操作,补全相关函数,以实现计算按揭贷款的要求。
编程要求
本关的编程任务是补全 7-1.py 文件中 findPayment 、init 、 makePayment 以及 getTotalPaid 四个函数,以实现计算按揭贷款的要求。具体要求如下:
本关要求补全上述描述的 4 个函数,并通过研究按揭贷款的规则,来帮助人们选择合适的贷款方式;
具体请参见后续测试样例。
def findPayment(loan, r, m):
#********** Begin *********#
# 请在下面编写代码
up = r*(1+r)**m
dn = (1+r)**m-1
# loan*(up/dn)为每月还款数
return loan*(up/dn)
# 请不要修改下面的代码
#********** End *********#
class Mortgage(object):
def __init__(self, loan1, annRate1, months1):
#********** Begin *********#
# 请在下面编写代码
self.loan = loan1
self.annRate = annRate1
self.months = months1
# 将年利率转化为月利率
self.rate = self.annRate/12/100
# 初始化已支付金额列表和剩余贷款金额列表
self.paid = [0.0]
self.owed = [loan1]
# 计算每月还款金额
self.payment = findPayment(loan1,self.rate,months1)
# 请不要修改下面的代码
#********** End *********#
self.legend = None
def makePayment(self):
#********** Begin *********#
# 请在下面编写代码
self.paid.append(self.payment)
reduction = self.payment - self.owed[-1] * self.rate
self.owed.append(self.owed[-1] - reduction)
# 请不要修改下面的代码
#********** End *********#
def getTotalPaid(self):
#********** Begin *********#
# 请在下面编写代码
return sum(self.paid)
# 请不要修改下面的代码
#********** End *********#
def __str__(self):
return 'The Mortgage is {self.legend}, Loan is {self.loan}, Months is {self.months}, Rate is {self.rate:.2f}, Monthly payment is {self.payment:.2f}'.format(self=self)
if __name__=="__main__":
print(Mortgage(100000, 6.5, 36))
print(Mortgage(100000, 6.5, 120))
二十二、机器学习
第1关:kNN算法—红酒分类
任务描述
本关任务: sklearn 中的 KNeighborsClassifier 类实现了 kNN 算法的分类功能,本关你需要使用 sklearn 中 KNeighborsClassifier 来对红酒数据进行分类。
编程要求
根据提示,在右侧编辑器的 begin-end 间补充代码,完成 classification 函数。函数需要完成的功能是使用 KNeighborsClassifier 对 test_feature 进行分类。其中函数的参数如下:
train_feature : 训练集数据,类型为 ndarray;
train_label : 训练集标签,类型为 ndarray;
test_feature : 测试集数据,类型为 ndarray。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
def classification(train_feature, train_label, test_feature):
'''
对test_feature进行红酒分类
:param train_feature: 训练集数据,类型为ndarray
:param train_label: 训练集标签,类型为ndarray
:param test_feature: 测试集数据,类型为ndarray
:return: 测试集数据的分类结果
'''
# 数据标准化
scaler = StandardScaler()
train_feature = scaler.fit_transform(train_feature)
test_feature = scaler.transform(test_feature)
# 创建KNN分类器
knn = KNeighborsClassifier()
# 使用训练集数据进行训练
knn.fit(train_feature, train_label)
# 对测试集数据进行分类
predicted_labels = knn.predict(test_feature)
return predicted_labels
二十三、K-means聚类算法
第1关:计算欧几里得距离
任务描述
本关实现一个函数来计算欧几里得距离。
编程要求
本关卡要求你实现函数 euclid_distance,在右侧编辑器
Begin-End 区间补充代码,需要填充的代码块如下:
-- coding: utf-8 -- import numpy as np def euclid_distance(x1, x2):
“”“计算两个点之间点欧式距离
参数:
x1-numpy数组
x2-numpy数组
返回值:
ret-浮点型数据
“””
# 请在此添加实现代码 #
ret = 0
#********** Begin #
#* End ***********#
return ret
# -*- coding: utf-8 -*-
import numpy as np
def euclid_distance(x1, x2):
"""计算欧几里得距离
参数:
x1 - numpy数组
x2 - numpy数组
返回值:
distance - 浮点数,欧几里得距离
"""
distance = np.sqrt(np.sum((x1 - x2) ** 2))
return distance
第2关:计算样本的最近邻聚类中心
任务描述
本关实现一个函数来计算距离每个样本最近的簇中心。
编程要求
本关卡要求你实现函数nearest_cluster_center,在右侧编辑器 Begin-End 区间补充代码,需要填充的代码块如下:
-- coding: utf-8 --
-- coding: utf-8 -- def nearest_cluster_center(x, centers):
“”“计算各个聚类中心与输入样本最近的
参数:
x - numpy数组
centers - numpy二维数组
返回值:
cindex - 整数,簇中心的索引值,比如3代表分配x到第3个聚类中
“””
cindex = -1
from distance import euclid_distance
# 请在此添加实现代码 #
#********** Begin #
#* End ***********#
return cindex
# -*- coding: utf-8 -*-
import numpy as np
from distance import euclid_distance
def nearest_cluster_center(x, centers):
"""计算各个聚类中心与输入样本最近的
参数:
x - numpy数组
centers - numpy二维数组
返回值:
cindex - 整数,簇中心的索引值,比如3代表分配x到第3个聚类中
"""
cindex = -1
min_distance = float('inf')
for i, center in enumerate(centers):
distance = euclid_distance(x, center)
if distance < min_distance:
min_distance = distance
cindex = i
return cindex
第3关:计算各聚类中心
任务描述
本关实现一个函数来计算各簇的中心。
编程要求
本关卡要求你实现函数 estimate_centers,在右侧编辑器
Begin-End 区间补充代码,需要填充的代码块如下:
-- coding: utf-8 -- import numpy as np def estimate_centers(X, y_estimated, centers): “”“重新计算各聚类中心
参数:
X - numpy二维数组,代表数据集的样本特征矩阵
y_estimated - numpy数组,估计的各个样本的聚类中心索引
n_clusters - 整数,设定的聚类个数
返回值:
centers - numpy二维数组,各个样本的聚类中心
“””
centers = np.zeros((n_clusters, X.shape[1]))
# 请在此添加实现代码 #
#********** Begin #
#* End ***********#
return centers
# -*- coding: utf-8 -*-
import numpy as np
def estimate_centers(X, y_estimated, n_clusters):
"""重新计算各聚类中心
参数:
X - numpy二维数组,代表数据集的样本特征矩阵
y_estimated - numpy数组,估计的各个样本的聚类中心索引
n_clusters - 整数,设定的聚类个数
返回值:
centers - numpy二维数组,各个样本的聚类中心
"""
centers = np.zeros((n_clusters, X.shape[1]))
# 请在此添加实现代码 #
#********** Begin *********#
for i in range(n_clusters):
cluster_samples = X[y_estimated == i]
if len(cluster_samples) > 0:
centers[i] = np.mean(cluster_samples, axis=0)
#********** End ***********#
return centers
第4关:评估聚类效果
任务描述
本关实现准确度评估函数,来评估聚类算法的效果。
编程要求
本关卡要求你实现函数 acc,在右侧编辑器 Begin-End 区间补充代码,需要填充的代码块如下:
-- coding: utf-8 --
def acc(x1, x2):
“”“计算精度
参数:
x1 - numpy数组
x2 - numpy数组
返回值:
value - 浮点数,精度
“””
value = 0
# 请在此添加实现代码 #
#********** Begin #
#* End ***********#
return value
import numpy as np
def acc(x1, x2):
"""计算精度
参数:
x1 - numpy数组
x2 - numpy数组
返回值:
value - 浮点数,精度
"""
value = 0
for i in range(len(x1)):
if np.array_equal(x1[i], x2[i]):
value += 1
value /= len(x1)
return value
第5关:组合已实现的函数完成K-means算法
任务描述
本关综合前面四个关卡的内容来实现K-means聚类算法。
编程要求
本关卡要求你完整如下代码块中星号圈出来的区域,实现K-means的核心算法步骤:
-- coding: utf-8 --
import numpy as np
import pandas as pd
from distance import euclid_distance
from estimate import estimate_centers
from loss import acc
from near import nearest_cluster_center
#随机种子对聚类的效果会有影响,为了便于测试,固定随机数种子
np.random.seed(5)
#读入数据集
dataset = pd.read_csv(‘./data/iris.csv’)
#取得样本特征矩阵
X = dataset[[‘150’,‘4’,‘setosa’,‘versicolor’]].as_matrix()
y = np.array(dataset[‘virginica’])
#读入数据
n_clusters, n_iteration = input().split(‘,’)
n_clusters = int(n_clusters)#聚类中心个数
n_iteration = int(n_iteration)#迭代次数
#随机选择若干点作为聚类中心
point_index_lst = np.arange(len(y))
np.random.shuffle(point_index_lst)
cluster_centers = X[point_index_lst[:n_clusters]]
#开始算法流程
y_estimated = np.zeros(len(y))# 请在此添加实现代码 #
#********** Begin #
#* End ***********#
print(‘%.3f’ % acc(y_estimated, y))
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from distance import euclid_distance
from estimate import estimate_centers
from loss import acc
from near import nearest_cluster_center
#随机种子对聚类的效果会有影响,为了便于测试,固定随机数种子
np.random.seed(5)
#读入数据集
dataset = pd.read_csv('./data/iris.csv')
#取得样本特征矩阵
X = dataset[['150','4','setosa','versicolor']].as_matrix()
y = np.array(dataset['virginica'])
#读入数据
n_clusters, n_iteration = input().split(',')
n_clusters = int(n_clusters)#聚类中心个数
n_iteration = int(n_iteration)#迭代次数
#随机选择若干点作为聚类中心
point_index_lst = np.arange(len(y))
np.random.shuffle(point_index_lst)
cluster_centers = X[point_index_lst[:n_clusters]]
#开始算法流程
y_estimated = np.zeros(len(y))
# 请在此添加实现代码 #
#********** Begin *********#
# 开始算法流程
for _ in range(n_iteration):
for i in range(len(X)):
y_estimated[i] = nearest_cluster_center(X[i], cluster_centers)
cluster_centers = estimate_centers(X, y_estimated, n_clusters)
#********** End ***********#
print('%.3f' % acc(y_estimated, y))
二十四、机器学习 — 神经网络
第1关:神经网络基本概念
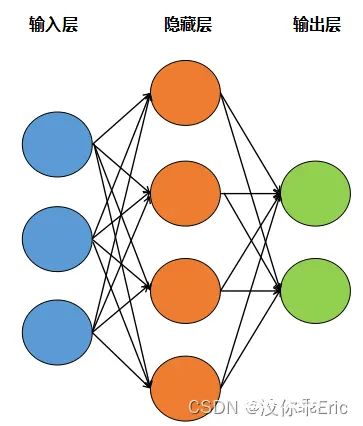
神经网络中的权重是连接神经元之间的参数,它们决定了网络对输入数据的反应方式。在训练过程中,权重会根据梯度下降算法进行调整,以最小化损失函数。所以本题选C,看有多少条线即可。
第2关:激活函数
任务描述
本关任务:用Python实现常用激活函数。
编程要求
根据提示,在右侧编辑器补充Python代码,实现relu激活函数,底层代码会调用您实现的relu激活函数来进行测试。
<code>#encoding=utf8
def relu(x):
'''
x:负无穷到正无穷的实数
'''
#********* Begin *********#
if x > 0:
return x
else:
return 0
#********* End *********#
第3关:反向传播算法
任务描述
本关任务:用sklearn构建神经网络模型,并通过鸢尾花数据集中鸢尾花的4种属性与种类对神经网络模型进行训练。我们会调用你训练好的神经网络模型,来对未知的鸢尾花进行分类。
编程要求
使用sklearn构建神经网络模型,利用训练集数据与训练标签对模型进行训练,然后使用训练好的模型对测试集数据进行预测,并将预测结果保存到./step2/result.csv中。保存格式如下:
<code>#encoding=utf8
import os
if os.path.exists('./step2/result.csv'):
os.remove('./step2/result.csv')
#********* Begin *********#
#获取训练数据
import pandas as pd
from sklearn.neural_network import MLPClassifier
train_data = pd.read_csv('./step2/train_data.csv')
#获取训练标签
train_label = pd.read_csv('./step2/train_label.csv')
train_label = train_label['target']
#获取测试数据
test_data = pd.read_csv('./step2/test_data.csv')
#构建神经网络模型并训练
mlp = MLPClassifier(solver='lbfgs',max_iter=100,code>
alpha=1e-4,hidden_layer_sizes=(20, ))
mlp.fit(train_data, train_label)
#获取预测值
predict = mlp.predict(test_data)
#将预测标签写入csv
df = pd.DataFrame({ 'result':predict})
df.to_csv('./step2/result.csv', index=False)
#********* End *********#
二十五、机器学习 — 模型评估、选择与验证
特别的,本节通过头歌系统的一些题目阐述了机器学习当中模型训练时的一些注意点,很有参考价值,同时也有助于我们理解在训练过程中调参的前因后果!
第1关:为什么要有训练集与测试集
相关知识 为了完成本关任务,你需要掌握:1.为什么要有训练集与测试集,2.如何划分训练集与测试集。
为什么要有训练集与测试集
我们想要利用收集的西瓜数据构建一个机器学习模型,用来预测新的西瓜的好坏,但在将模型用于新的测量数据之前,我们需要知道模型是否有效,也就是说,我们是否应该相信它的预测结果。不幸的是,我们不能将用于构建模型的数据用于评估模型的性能。因为我们的模型会一直记住整个训练集,所以,对于训练集中的任何数据点总会预测成正确的标签。这种记忆无法告诉我们模型的泛化能力如何,即预测新样本的能力如何。我们要用新数据来评估模型的性能。新数据是指模型之前没见过的数据,而我们有这些新数据的标签。通常的做法是,我们把手头上的数据分为两部分,训练集与测试集。训练集用来构建机器学习模型,测试集用来评估模型性能。
如何划分训练集与测试集 通常我们将手头数据的百分之 70 或 80 用来训练数据,剩下的百分之 30 或 20
作为测试用来评估模型性能。值得注意的是,在划分数据集之前,我们要先把手头上的数据的顺序打乱,因为我们搜集数据时,数据可能是按照标签排放的。比如,现在有
100 个西瓜的数据,前 50 个是好瓜,后 50 个是坏瓜,如果将后面的 30
个西瓜数据当做测试集,这时测试集中只有坏瓜一个类别,这无法告诉我们模型的泛化能力如何,所以我们将数据打乱,确保测试集中包含所有类别的数据。
1、
下面正确的是?
A、
将手头上所有的数据拿来训练模型,预测结果正确率最高的模型就是我们所要选的模型。
B、
将所有数据中的前百分之70拿来训练模型,剩下的百分之30作为测试集,预测结果正确率最高的模型就是我们所要选的模型。
C、
将所有数据先随机打乱顺序,一半用来训练模型,一半作为测试集,预测结果正确率最高的模型就是我们所要选的模型。
D、
将所有数据先随机打乱顺序,百分之80用来训练模型,剩下的百分之20作为测试集,预测结果正确率最高的模型就是我们所要选的模型。
训练集和测试集划分往往8/2或者7/3,故选(D)
2、
训练集与测试集的划分对最终模型的确定有无影响?
A、
有
B、
无
选(A)
第2关:欠拟合与过拟合
相关知识
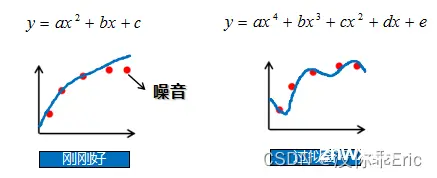
为了完成本关任务,你需要掌握:1.什么是欠拟合与欠拟合的原因,2.什么是过拟合与过拟合的原因。
什么是欠拟合与欠拟合的原因
欠拟合:模型在训练集上误差很高;
欠拟合原因:模型过于简单,没有很好的捕捉到数据特征,不能很好的拟合数据。
如上面例子,我们的数据是一份非线性数据,如果你想要用线性回归来拟合这份数据,由于数据是非线性的,模型是线性,则过于简单。所以,无论模型怎么训练,最终都不能很好的拟合数据。
什么是过拟合与过拟合的原因
过拟合:在训练集上误差低,测试集上误差高;
过拟合原因:模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,模型泛化能力太差。
如上面例子,在训练集上,模型为了拟合数据,添加了更多的多次项,使模型过于复杂,对噪音数据也能很好的拟合,所以在训练集上正确率很高,而在测试集上没有这些噪音数据,所以正确率很低。
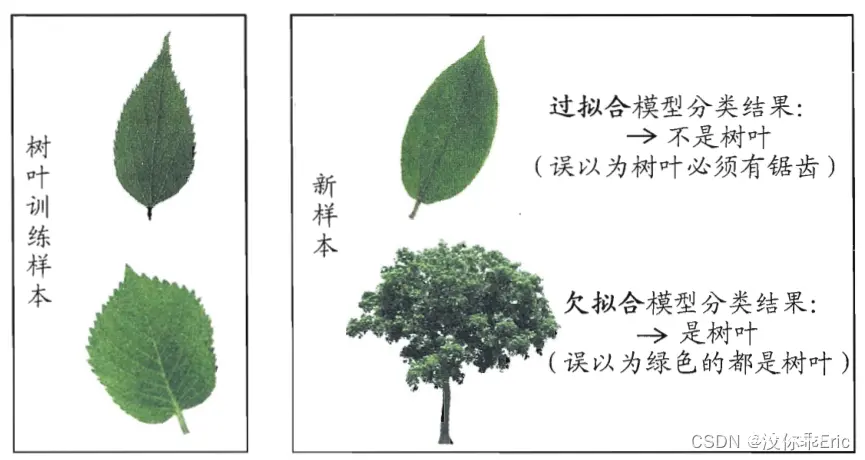
在分类的问题中,如下例子:
欠拟合:由于模型过于简单,只学习到绿色这个特征,只要是绿色就都判断为树叶,结果将树当做了树叶。
过拟合:模型过于复杂,将锯齿这个普通特征,看的过于重要,认为必须有锯齿才是树叶,结果将树叶误判为不是树叶
题目
1
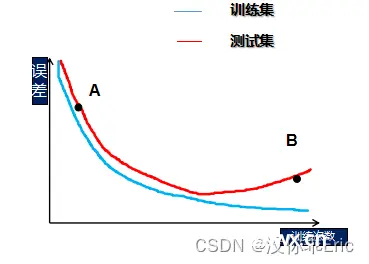
请问,图中A与B分别处于什么状态?
A、
欠拟合,欠拟合
B、
欠拟合,过拟合
C、
过拟合,欠拟合
D、
过拟合,过拟合
A处训练集和测试集准确率都很低,显然欠拟合了,但B处训练集准确率高于测试集,模型泛化能力下降,故选(B)
2、
如果一个模型在训练集上正确率为99%,测试集上正确率为60%。我们应该怎么做?
A、
加入正则化项
B、
增加训练样本数量
C、
增加模型复杂度
D、
减少模型复杂度
第3关:偏差与方差
相关知识
为了完成本关任务,你需要掌握:1.模型误差来源,2.偏差与方差。
模型误差来源
在上一部分,我们知道了欠拟合是模型在训练集上误差过高,过拟合模型是在训练集上误差低,在测试集上误差高。那么模型误差的来源是什么呢?
其实,模型在训练集上的误差来源主要来自于偏差,在测试集上误差来源主要来自于方差。
上图表示,如果一个模型在训练集上正确率为 80%,测试集上正确率为 79% ,则模型欠拟合,其中 20% 的误差来自于偏差,1% 的误差来自于方差。如果一个模型在训练集上正确率为 99%,测试集上正确率为 80% ,则模型过拟合,其中 1% 的误差来自于偏差,19% 的误差来自于方差。
可以看出,欠拟合是一种高偏差的情况。过拟合是一种低偏差,高方差的情况。
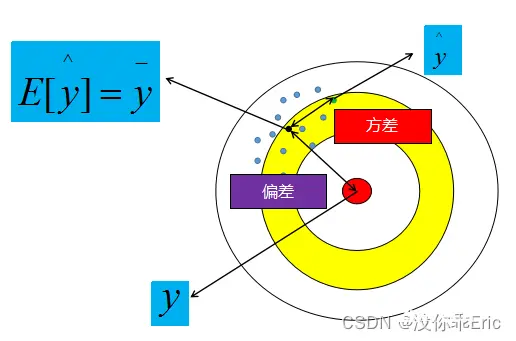
偏差与方差
偏差:预计值的期望与真实值之间的差距;
方差:预测值的离散程度,也就是离其期望值的距离。
以射击打靶为例,蓝色的小点是我们在靶子上的射击记录,蓝色点的质心(黑色点)到靶心的距离为偏差,某个点到质心的距离为方差。所以,某个点到质心的误差就是由偏差与方差所组成。那么,为什么欠拟合是一直高偏差情况,过拟合是一种低偏差高方差情况呢?
我们知道,欠拟合是因为模型过于简单,模型过于简单我们可以当做是我们射击时射击的范围比较小,它所涵盖的范围不包括靶心,所以无论怎么射击,射击点的质心里靶心的距离都很远,所以偏差很高。但是因为射击范围很小,所以所有射击点相互离的比较紧密,则方差低。
而过拟合是因为模型过于复杂,我们可以理解为这个时候射击的范围很大了,经过不断的训练射击的点的质心离靶心的距离很近了,但是由于数据量有限,而射击范围很大,所以所有射击点之间非常离散,也就是方差很大。
题目
1、
如果一个模型,它在训练集上正确率为85%,测试集上正确率为80%,则模型是过拟合还是欠拟合?其中,来自于偏差的误差为?来自方差的误差为?
A、
欠拟合,5%,5%
B、
欠拟合,15%,5%
C、
过拟合,15%,15%
D、
过拟合,5%,5%
正确率85%并不高,显然模型过拟合了;偏差=1-训练集准确率,方差则为训练集准确率和测试集准确率的差值,易得本题选(B)

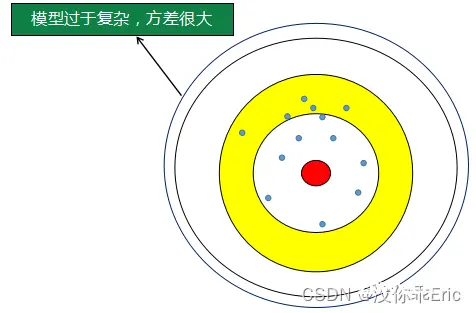
第4关:验证集与交叉验证
相关知识
为了完成本关任务,你需要掌握:1.为什么需要验证集,2.k 折交叉验证。
为什么需要验证集
在机器学习中,通常需要评估若⼲候选模型的表现并从中选择模型。这⼀过程称为模型选择。可供选择的候选模型可以是有着不同超参数的同类模型。以神经网络为例,我们可以选择隐藏层的个数,学习率大小和激活函数。为了得到有效的模型,我们通常要在模型选择上下⼀番功夫。从严格意义上讲,测试集只能在所有超参数和模型参数选定后使⽤⼀次。不可以使⽤测试数据选择模型,如调参。由于⽆法从训练误差估计泛化误差,因此也不应只依赖训练数据选择模型。鉴于此,我们可以预留⼀部分在训练数据集和测试数据集以外的数据来进⾏模型选择。这部分数据被称为验证数据集,简称验证集。
为了方便大家理解,举一个生活中的案例进行类比,我们一般是通过考试衡量学生的学习情况。老师上完课后,给学生布置的作业相当于训练数据集,中期的测试题相当于验证集,期末考试题相当于测试数据集。为了更加客观的衡量学生学习情况,期末考试题的内容不应该出现在平常的作业题和中期的测试题中,因为之前做过的题,对于计算机而言,相当于已经记住了,如果再次做同样的题,准确率就会很高。同样的道理,平常的作业题也不应该出现在中期的测试题里。中期的测试题,是为了掌握学生的学习情况,了解自己哪些方面内容没掌握,从而调整下一步学习的方向,为期末考试做好准备。
k折交叉验证
由于验证数据集不参与模型训练,当训练数据不够⽤时,预留⼤量的验证数据显得太奢侈。⼀种改善的⽅法是 K 折交叉验证。在 K折交叉验证中,我们把原始训练数据集分割成 K个不重合的⼦数据集,然后我们做K次模型训练和验证。每⼀次,我们使⽤⼀个⼦数据集验证模型,并使⽤其它 K−1 个⼦数据集来训练模型。在这 K次训练和验证中,每次⽤来验证模型的⼦数据集都不同。最后,我们对这 K 次训练误差和验证误差分别求平均。 k 的值由我们自己来指定,如以下为
5 折交叉验证。
还是以考试为例,解释上图内容。交叉验证,相当于把平常的作业题和中期的测试题合并成一个题库,然后等分成几份。图中所示,将题库分成了五份,第一行的意思是,先让学生做后面的四份训练题,再用第一份题进行测试。以此类推,再重复四次,每一次相当于重新进行学习。最后,取五次的平均成绩,平均成绩高,说明老师的教学方法好,对应到模型,就是超参数更好。
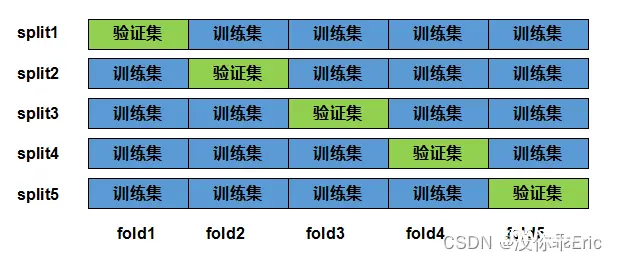
集成学习
在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好)。集成学习就是组合这里的多个弱监督模型以期得到一个更好更全面的强监督模型。集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。集成方法是将几种机器学习技术组合成一个预测模型的元算法,以达到减小方差、偏差或改进预测的效果。
自助法
在统计学中,自助法是一种从给定训练集中有放回的均匀抽样,也就是说,每当选中一个样本,它等可能地被再次选中并被再次添加到训练集中。自助法以自助采样法为基础,给定包含m 个样本的数据集 D,我们对它进行采样产生数据集 D’;每次随机从 D 中挑选一个赝本,将其拷贝放入D’,然后再将该样本放回初始数据集D 中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行 m 次后,就得到了包含m个样本的数据集 D’,这就是自助采样的结果。自助法在数据集较小、难以有效划分训练/测试集时很有用;此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习等方法有很大的好处。然而,自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差。
1、
假设,我们现在利用5折交叉验证的方法来确定模型的超参数,一共有4组超参数,我们可以知道,5折交叉验证,每一组超参数将会得到5个子模型的性能评分,假设评分如下,我们应该选择哪组超参数?
A、
子模型1:0.8 子模型2:0.7 子模型3:0.8 子模型4:0.6 子模型5:0.5
B、
子模型1:0.9 子模型2:0.7 子模型3:0.8 子模型4:0.6 子模型5:0.5
C、
子模型1:0.5 子模型2:0.6 子模型3:0.7 子模型4:0.6 子模型5:0.5
D、
子模型1:0.8 子模型2:0.8 子模型3:0.8 子模型4:0.8 子模型5:0.6
根据计算结果,D组超参数的平均评分最高,为0.76。因此,我们应该选择D组超参数作为最优超参数。
2、
下列说法正确的是?
A、
相比自助法,在初始数据量较小时交叉验证更常用。
B、
自助法对集成学习方法有很大的好处
C、
使用交叉验证能够增加模型泛化能力
D、
在数据难以划分训练集测试集时,可以使用自助法
选BCD可以通过评测,但其实D是错误的。在数据难以划分训练集测试集时,应该使用交叉验证,而不是自助法。正确的应是ABC
第5关:衡量回归的性能指标
AB,不做了解
二十六、Python机器学习软件包Scikit-Learn的学习与运用
第1关:使用scikit-learn导入数据集
任务描述 使用 scikit-learn 的datasets模块导入 iris 数据集,并打印数据。
编程要求
本关任务是,使用scikit-learn 的datasets模块导入iris数据集,提取前 5 条原数据、前 5 条数据标签及原数据的数组大小。
<code>from sklearn import datasets
def getIrisData():
'''
导入Iris数据集
返回值:
X - 前5条训练特征数据
y - 前5条训练数据类别
X_shape - 训练特征数据的二维数组大小
'''
#初始化
X = []
y = []
X_shape = ()
# 请在此添加实现代码 #
#********** Begin *********#
iris = datasets.load_iris()
X = iris.data[:5]
y = iris.target[:5]
X_shape = iris.data.shape
#********** End **********#
return X,y,X_shape
第2关:数据预处理 — 标准化
任务描述
在前一关卡,我们已经学会了使用 sklearn导入数据,然而原始数据总是比较杂乱、不规整的,直接加载至模型中训练,会影响预测效果。本关卡,将学习使用sklearn对导入的数据进行预处理。 编程要求 本关任务希望对于 California housing 数据集进行标准化转换。
代码中已通过fetch_california_housing函数加载好了数据集 California housing 数据集包含 8
个特征,分别是[‘MedInc’, ‘HouseAge’, ‘AveRooms’, ‘AveBedrms’, ‘Population’, ‘AveOccup’, ‘Latitude’,‘Longitude’],可通过dataset.feature_names访问数据具体的特征名称,通过在上一关卡的学习,相信大家对于原始数据的查看应该比较熟练了,在这里不过多说明。
本次任务只对 California housing 数据集中的两个特征进行操作,分别是第 1 个特征 MedInc,其数据服从长尾分布;第6 个特征 AveOccup,数据中包含大量离群点。
本关分成为几个子任务:
1.使用 MinMaxScaler 对特征
数据 X 进行标准化转换,并返回转换后的特征数据的前 5 条;
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import scale
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import fetch_california_housing
'''
Data descrption:
The data contains 20,640 observations on 9 variables.
This dataset contains the average house value as target variable
and the following input variables (features): average income,
housing average age, average rooms, average bedrooms, population,
average occupation, latitude, and longitude in that order.
dataset : dict-like object with the following attributes:
dataset.data : ndarray, shape [20640, 8]
Each row corresponding to the 8 feature values in order.
dataset.target : numpy array of shape (20640,)
Each value corresponds to the average house value in units of 100,000.
dataset.feature_names : array of length 8
Array of ordered feature names used in the dataset.
dataset.DESCR : string
Description of the California housing dataset.
'''
dataset = fetch_california_housing("./step4/")
X_full, y = dataset.data, dataset.target
#抽取其中两个特征数据
X = X_full[:, [0, 5]]
def getMinMaxScalerValue():
'''
对特征数据X进行MinMaxScaler标准化转换,并返回转换后的数据前5条
返回值:
X_first5 - 数据列表
'''
X_first5 = []
# 请在此添加实现代码 #
# ********** Begin *********#
X_minmax_scaler = MinMaxScaler().fit_transform(X)
X_first5 = X_minmax_scaler[:5]
# ********** End **********#
return X_first5
def getScaleValue():
'''
对目标数据y进行简单scale标准化转换,并返回转换后的数据前5条
返回值:
y_first5 - 数据列表
'''
y_first5 = []
# 请在此添加实现代码 #
# ********** Begin *********#
y_first5 = scale(y)[:5]
# ********** End **********#
return y_first5
def getStandardScalerValue():
'''
对特征数据X进行StandardScaler标准化转换,并返回转换后的数据均值和缩放比例
返回值:
X_mean - 均值
X_scale - 缩放比例值
'''
X_mean = None
X_scale = None
# 请在此添加实现代码 #
#********** Begin *********#
X_std_scaler = StandardScaler().fit(X)
X_mean = X_std_scaler.mean_
X_scale = X_std_scaler.scale_
#********** End **********#
return X_mean,X_scale
二十七、使用机器学习解决实际问题
第2关:识别花朵
任务描述
本关任务:使用 sklearn 实现 knn 算法,并利用已知标签的鸢尾花数据对模型进行训练,再预测未知标签的鸢尾花数据的类别。
#encoding=utf8
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def knn(train_data,train_label,test_data):
'''
input:train_data用来训练的数据
train_label用来训练的标签
test_data用来测试的数据
'''
#********* Begin *********#
# 创建KNN分类器对象
knn = KNeighborsClassifier()
# 使用训练数据和标签训练模型
knn.fit(train_data, train_label)
# 对测试数据类别进行预测
predict = knn.predict(test_data)
#********* End *********#
return predict
这一题其实并没有结束,但是只有上述残缺代码能通过测评,下面几关也有同样问题,可以在讯飞星火直接生成完整代码研究。完整的花朵识别模型的训练应是如下所示:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def knn(train_data, train_label, test_data):
'''
input: train_data用来训练的数据
train_label用来训练的标签
test_data用来测试的数据
'''
# 创建KNN分类器对象
knn = KNeighborsClassifier()
# 使用训练数据和标签训练模型
knn.fit(train_data, train_label)
# 对测试数据类别进行预测
predict = knn.predict(test_data)
return predict
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 调用knn函数进行预测
predict = knn(X_train, y_train, X_test)
# 计算预测准确率
accuracy = accuracy_score(y_test, predict)
print("预测准确率:", accuracy)
完整的模型训练流程为:数据集收集->数据集整理->训练模型->测试模型->优化模型->模型上线
卷积神经网络的相关资料后续在文章{}中发布
第3关:预测房价
任务描述
本关任务:使用 sklearn
构建线性回归算法,并利用已知标签的波斯顿房价数据对模型进行训练,然后对未知标签的波斯顿房价数据进行预测。
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
def lr(train_data, train_label, test_data):
'''
input: train_data用来训练的数据
train_label用来训练的标签
test_data用来测试的数据
'''
# 创建线性回归模型
lr = LinearRegression()
# 利用已知数据与标签对模型进行训练
lr.fit(train_data, train_label)
# 对未知数据进行预测
predict = lr.predict(test_data)
return predict
第4关:癌症诊断
任务描述 本关任务:使用 sklearn 构建逻辑回归算法,并利用癌细胞数据对模型进行训练,然后对未知的癌细胞数据进行识别。
#encoding=utf8
from sklearn.linear_model import LogisticRegression
def cancer_clf(train_data,train_label,test_data):
'''
train_data(ndarray):训练数据
train_label(ndarray):训练标签
test_data(ndarray):ces数据
'''
#********* Begin *********#
logreg = LogisticRegression(C=100)
logreg.fit(train_data, train_label)
predict = logreg.predict(test_data)
#********* End *********#
return predict
Author:Jzh
创作不易,xdm抄happy了就点个赞吧
上一篇: 【Python】类和对象高级特性
下一篇: 【C++】输入输出流 ⑧ ( cout 输出格式控制 | 设置进制格式 - dex、hex、oct | 指定输出宽度 / 填充 - setw / setfill | 指定浮点数格式 )
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。