MyBaits 二级缓存原理
程序猿进阶 2024-10-02 15:05:01 阅读 100
优质博文:IT-BLOG-CN
一级缓存原理
默认关闭,一般不建议使用。为什么不建议使用我们要清楚。
先给不建议使用的原因: <code>MyBatis的二级缓存是和命名空间绑定的,所以通常情况下每一个Mapper映射文件都拥有自己的二级缓存,不同Mapper的二级缓存互不影响。在常见的数据库操作中,多表联合查询非常常见,由于关系型数据库的设计, 使得很多时候需要关联多个表才能获得想要的数据。在关联多表查询时肯定会将该查询放到某个命名空间下的映射文件中,这样一个多表的查询就会缓存在该命名空间的二级缓存中。涉及这些表的增、删、改操作通常不在一个映射文件中,它们 的命名空间不同, 因此当有数据变化时,多表查询的缓存未必会被清空,这种情况下就会产生脏数据。
一、二级缓存配置
1、配置mybatis核心配置文件
<settings>
<!--因为cacheEnabled的取值默认就为true,所以这一步可以省略不配置。
为true代表开启二级缓存;为false代表不开启二级缓存。-->
<setting name="cacheEnabled" value="true"/>code>
</settings>
2、XML开发方式: 在xxxMapper.xml映射中配置cache或者cache-ref。
<mapper namespace="com.lagou.dao.UserMapper">code>
<!--当前映射文件开启二级缓存-->
<cache></cache>
<!--
<select>标签中设置useCache=”true”代表当前这个statement要使用二级缓存。如果不使用二级缓存可以设置为false
注意:
如果每次查询都需要最新的数据sql,要设置成useCache="false",禁用二级缓存。code>
-->
<select id="findById" parameterType="int" resultType="user" useCache="true"code>
>
SELECT * FROM `user` where id = #{id}
</select>
</mapper>
type:cache使用的类型,默认是PerpetualCache,这在一级缓存中提到过。
eviction: 定义回收的策略,常见的有FIFO,LRU。
flushInterval: 配置一定时间自动刷新缓存,单位是毫秒。
size: 最多缓存对象的个数。
readOnly: 是否只读,若配置可读写,则需要对应的实体类能够序列化。
blocking: 若缓存中找不到对应的key,是否会一直blocking,直到有对应的数据进入缓存。
cache-ref代表引用别的命名空间的Cache配置,两个命名空间的操作使用的是同一个Cache。(为了解决下述问题)
先看下二级缓存存在的问题:多表联合查询产生脏数据
@Test
public void testCacheWithDiffererntNamespace() throws Exception {
SqlSession sqlSession1 = factory.openSession(true);
SqlSession sqlSession2 = factory.openSession(true);
SqlSession sqlSession3 = factory.openSession(true);
StudentMapper studentMapper = sqlSession1.getMapper(StudentMapper.class);
StudentMapper studentMapper2 = sqlSession2.getMapper(StudentMapper.class);
ClassMapper classMapper = sqlSession3.getMapper(ClassMapper.class);
System.out.println(studentMapper.getStudentByIdWithClassInfo(1));
sqlSession1.close();
System.out.println(studentMapper2.getStudentByIdWithClassInfo(1));
classMapper.updateClassName("重点一班",1);
sqlSession3.commit();
System.out.println(studentMapper2.getStudentByIdWithClassInfo(1));
}
执行结果:在这个实验中,我们引入了两张新的表,一张class,一张classroom。class中保存了班级的id和班级名,classroom中保存了班级id和学生id。我们在StudentMapper中增加了一个查询方法getStudentByIdWithClassInfo,用于查询学生所在的班级,涉及到多表查询。在ClassMapper中添加了updateClassName,根据班级id更新班级名的操作。
DEBUG [main] - Cache Hit Ratio [mapper.StudentMapper]: 0.0
DEBUG [main] - ==> Preparing: SELECT s.id,s.name,s.age,c.className as className FROM classrome cr JOIN student s ON cr.student_id == s.id JOIN class c ON cl.class_id == c.id WHERE s.id = ?
DEBUG [main] - ==> Parameters: 1(Integer)
TRACE [main] - <== Columns: id, name, age, className
TRACE [main] - <== Row: 1, 小明, 13, 一班
DEBUG [main] - <== Total: 1
StudentEntity{id=1, name='小明', age=13, className='一班'}code>
DEBUG [main] - Cache Hit Ratio [mapper.StudentMapper]: 0.5
StudentEntity{id=1, name='小明', age=13, className='一班'}code>
DEBUG [main] - ==> Preparing: UPDATE class SET name = ? WHERE id = ?
DEBUG [main] - ==> Parameters: 重点一班(String) 1(Integer)
DEBUG [main] - <== Updates: 1
DEBUG [main] - Cache Hit Ratio [mapper.StudentMapper]: 0.66666666666666666
StudentEntity{id=1, name='小明', age=13, className='一班'}code>
当sqlsession1的studentmapper查询数据后,二级缓存生效。保存在StudentMapper的namespace下的cache中。当sqlSession3的classMapper的updateClassName方法对class表进行更新时,updateClassName不属于StudentMapper的namespace,所以StudentMapper下的cache没有感应到变化,没有刷新缓存。当StudentMapper中同样的查询再次发起时,从缓存中读取了脏数据。
为了解决上述的问题,可以使用Cache ref,让ClassMapper引用StudenMapper命名空间,这样两个映射文件对应的SQL操作都使用的是同一块缓存了。
<cache-ref namespace="mapper.StudentMapper"/>code>
执行结果:不过这样做的后果是,缓存的粒度变粗了,多个Mapper namespace下的所有操作都会对缓存使用造成影响。
DEBUG [main] - Cache Hit Ratio [mapper.StudentMapper]: 0.0
DEBUG [main] - ==> Preparing: SELECT s.id,s.name,s.age,c.className as className FROM classrome cr JOIN student s ON cr.student_id == s.id JOIN class c ON cl.class_id == c.id WHERE s.id = ?
DEBUG [main] - ==> Parameters: 1(Integer)
TRACE [main] - <== Columns: id, name, age, className
TRACE [main] - <== Row: 1, 小明, 13, 一班
DEBUG [main] - <== Total: 1
StudentEntity{id=1, name='小明', age=13, className='一班'}code>
DEBUG [main] - Cache Hit Ratio [mapper.StudentMapper]: 0.5
StudentEntity{id=1, name='小明', age=13, className='一班'}code>
DEBUG [main] - ==> Preparing: UPDATE class SET name = ? WHERE id = ?
DEBUG [main] - ==> Parameters: 重点一班(String) 1(Integer)
DEBUG [main] - <== Updates: 1
DEBUG [main] - Cache Hit Ratio [mapper.StudentMapper]: 0.3333333333333
DEBUG [main] - ==> Preparing: SELECT s.id,s.name,s.age,c.className as className FROM classrome cr JOIN student s ON cr.student_id == s.id JOIN class c ON cl.class_id == c.id WHERE s.id = ?
DEBUG [main] - ==> Parameters: 1(Integer)
TRACE [main] - <== Columns: id, name, age, className
TRACE [main] - <== Row: 1, 小明, 13, 重点一班
DEBUG [main] - <== Total: 1
StudentEntity{id=1, name='小明', age=13, className='重点一班'}code>
注解开发方式: 或者配置Mapper接口,添加注解
@CacheNamespace
public interface UserMapper { ...}
二级缓存的开启需要进行配置,实现二级缓存的时候,
MyBatis要求返回的POJO必须是可序列化的,也就是要求实现Serializable接口。
二、二级缓存清除方式
映射文件XML中添加flushCache=“true”
<select flushCache="true"></select>code>
三、原理分析
在一级缓存中,其最大的共享范围就是一个SqlSession内部,如果多个SqlSession之间需要共享缓存,则需要使用到二级缓存。开启二级缓存后,会使用CachingExecutor装饰Executor,进入一级缓存的查询流程前,先在CachingExecutor进行二级缓存的查询,具体的工作流程如下所示。
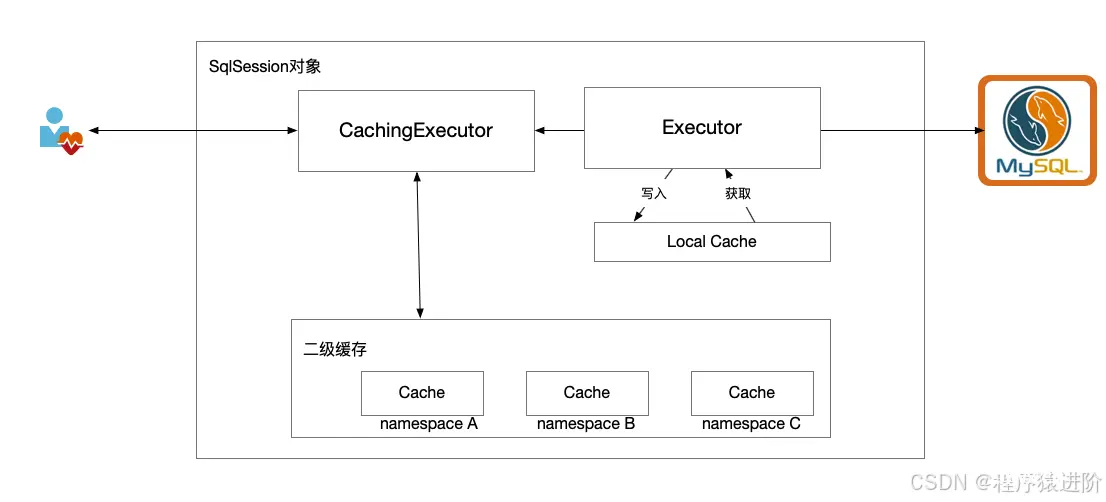
二级缓存开启后,同一个<code>namespace下的所有操作语句,都影响着同一个Cache,即二级缓存被多个SqlSession共享,是一个全局的变量。
当开启缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -> 数据库。
CachingExecutor是Executor的装饰者,以增强Executor的功能,使其具有缓存查询的功能,这里用到了设计模式中的装饰者模式。
CachingExecutor的query方法,首先会从MappedStatement中获得在配置初始化时赋予的Cache。
Cache cache = ms.getCache();
以下是具体这些Cache实现类的介绍,他们的组合为Cache赋予了不同的能力。
SynchronizedCache:同步Cache,实现比较简单,直接使用synchronized修饰方法。
LoggingCache:日志功能,装饰类,用于记录缓存的命中率,如果开启了DEBUG模式,则会输出命中率日志。
SerializedCache:序列化功能,将值序列化后存到缓存中。该功能用于缓存返回一份实例的Copy,用于保存线程安全。
LruCache:采用了Lru算法的Cache实现,移除最近最少使用的Key/Value。
PerpetualCache: 作为为最基础的缓存类,底层实现比较简单,直接使用了HashMap。
是否需要刷新缓存,代码如下所示:
flushCacheIfRequired(ms);
在默认的设置中SELECT语句不会刷新缓存,insert/update/delte会刷新缓存。进入该方法。代码如下所示:
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}
MyBatis的CachingExecutor持有了TransactionalCacheManager,即上述代码中的tcm。TransactionalCacheManager中持有一个Map,代码如下所示:
private Map<Cache, TransactionalCache> transactionalCaches = new HashMap<Cache, TransactionalCache>();
这个Map保存了Cache和用TransactionalCache包装后的Cache的映射关系。
TransactionalCache实现了Cache接口,CachingExecutor会默认使用他包装初始生成的Cache,作用是如果事务提交,对缓存的操作才会生效,如果事务回滚或者不提交事务,则不对缓存产生影响。
在TransactionalCache的clear,有以下两句。清空了需要在提交时加入缓存的列表,同时设定提交时清空缓存,代码如下所示:
@Override
public void clear() {
clearOnCommit = true;
entriesToAddOnCommit.clear();
}
CachingExecutor继续往下走,ensureNoOutParams主要是用来处理存储过程的,暂时不用考虑。
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
之后会尝试从tcm中获取缓存的列表。
List<E> list = (List<E>) tcm.getObject(cache, key);
在getObject方法中,会把获取值的职责一路传递,最终到PerpetualCache。如果没有查到,会把key加入Miss集合,这个主要是为了统计命中率。
Object object = delegate.getObject(key);
if (object == null) {
entriesMissedInCache.add(key);
}
CachingExecutor继续往下走,如果查询到数据,则调用tcm.putObject方法,往缓存中放入值。
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
tcm的put方法也不是直接操作缓存,只是在把这次的数据和key放入待提交的Map中。
@Override
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}
从以上的代码分析中,我们可以明白,如果不调用commit方法的话,由于TranscationalCache的作用,并不会对二级缓存造成直接的影响。因此我们看看Sqlsession的commit方法中做了什么。代码如下所示:
@Override
public void commit(boolean force) {
try {
executor.commit(isCommitOrRollbackRequired(force));
因为我们使用了CachingExecutor,首先会进入CachingExecutor实现的commit方法。
@Override
public void commit(boolean required) throws SQLException {
delegate.commit(required);
tcm.commit();
}
会把具体commit的职责委托给包装的Executor。主要是看下tcm.commit(),tcm最终又会调用到TrancationalCache。
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();
reset();
}
看到这里的clearOnCommit就想起刚才TrancationalCache的clear方法设置的标志位,真正的清理Cache是放到这里来进行的。具体清理的职责委托给了包装的Cache类。之后进入flushPendingEntries方法。代码如下所示:
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
................
}
在flushPendingEntries中,将待提交的Map进行循环处理,委托给包装的Cache类,进行putObject的操作。
后续的查询操作会重复执行这套流程。如果是insert|update|delete的话,会统一进入CachingExecutor的update方法,其中调用了这个函数,代码如下所示:
private void flushCacheIfRequired(MappedStatement ms)
在二级缓存执行流程后就会进入一级缓存的执行流程,因此不再赘述。
MyBatis的二级缓存相对于一级缓存来说,实现了SqlSession之间缓存数据的共享,同时粒度更加的细,能够到namespace级别,通过Cache接口实现类不同的组合,对Cache的可控性也更强。
MyBatis在多表查询时,极大可能会出现脏数据,有设计上的缺陷,安全使用二级缓存的条件比较苛刻。
在分布式环境下,由于默认的
MyBatis Cache实现都是基于本地的,分布式环境下必然会出现读取到脏数据,需要使用集中式缓存将MyBatis的Cache接口实现,有一定的开发成本,直接使用Redis、Memcached等分布式缓存可能成本更低,安全性也更高。
上一篇: 计算机毕业设计:Java高校校园二手物品交易平台系统开题报告+源代码效果图
下一篇: 基于大数据爬虫+Python+数据可视化大屏的旅游数据分析推荐与可视化平台(源码+论文+PPT+部署文档教程等)
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。