【Python数据魔术】:揭秘类型奥秘,赋能代码创造
爱喝兽奶的荒天帝 2024-06-19 16:35:10 阅读 73
文章目录
🚀一.运算符🌈1. 算术运算符🌈2. 身份运算符🌈3. 成员运算符⭐4. 增量运算符⭐5. 比较运算符⭐6. 逻辑运算符 🚀二.可变与不可变🚀三.字符串转义🚀四.编码与解码💥1. 基础使用 🚀五.进制转化💥1.python进制转化 🚀六.深浅拷贝(复制)❤️1. 浅拷贝❤️2. 深拷贝 🚀七.运算升级🚀八.常用方法🚀九.操作扩展
🚀一.运算符
🌈1. 算术运算符
下面以a=10 ,b=20为例进行计算
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 两个对象相加 a + b 输出结果 30 |
| - | 减 | 得到负数或是一个数减去另一个数 a - b 输出结果 -10 |
| * | 乘 | 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 |
| / | 除 | x除以y b / a 输出结果 2 |
| // | 向下取整 | 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
| % | 取模(余) | 返回除法的余数 b % a 输出结果 0 |
| ** | 幂 | 返回x的y次幂 a**b 为10的20次方, 输出结果 100000000000000000000 |
🌈2. 身份运算符
身份运算符| 运算符 | 描述 | 详解 |
|---|---|---|
| is | 同一性运算符 | 变量ID是否相同,ID即变量的唯一标识,变量值可能相同但ID不一定相同 |
| is not | 非同一性 | 判断两个变量的引用是否来之不同对象 |
"""1.举个例子,在python命令行模式下:为什么同样值a,b与c,d的结果却不一样呢?""">>> a = 1000>>> b = 1000>>> a is bFalse>>> c = 10>>> d = 10>>> c is dTrue# 注意,因为python对小整数在内存中直接创建了一份,不会回收,所有创建的小整数变量直接从对象池中引用即可。# 但是注意Python仅仅对比较小的整数对象进行缓存(范围为范围[-5, 256])缓存起来,而并非是所有整数对象。# 也就说只有在这个[-5,256]范围内创建的变量值使用is比较时候才会成立。 而保存为文件执行,结果是不一样的,这是因为解释器做了一部分优化。即使整数超过256,使用is也是成立的。 使用is注意python关于字符串的intern机制存储
# 注意: python中创建两个内容一样的变量时(变量名不一样),# 一般都会在内存中分配两个内存地址(id地址)分别给这两个变量。# 即两个变量的内容虽然一样,但是变量的引用地址不一样。# 所以两个变量使用==比较成立,但是使用 is比较不成立。# 但是在python中有两个意外情况:# 1.使用python命令行时对于小整数[-5,256]区间内的整数,python会创建小整数对象池,这些对象一旦创建,# 就不会回收,所有新创建的在这个范围的整数都是直接引用他即可。# 所以造成在[-5,256]区间内的整数不同变量只要值相同,引用地址也相同。# 此范围外的整数同样遵循新建一个变量赋予一个地址。# 2.python中虽然字符串对象也是不可变对象,但python有个intern机制,# 简单说就是维护一个字典,这个字典维护已经创建字符串(key)和它的字符串对象的地址(value),# 每次创建字符串对象都会和这个字典比较,没有就创建,重复了就用指针进行引用就可以了。# 相当于python对于字符串也是采用了对象池原理。# (但是注意:如果字符串(含有空格),不可修改,没开启intern机制,不共用对象。# 比如"a b"和"a b",这种情况使用is不成立的形式 只有在命令行中可以。# 使用pycharm同样是True,因为做了优化) # 交互式模式(命令行模式)>>> a ='abc' #没有空格内容一样的两个变量,在命令行模式下is 结果True>>> b = 'abc'>>> a ==bTrue>>> a is bTrue>>> c ='a b ' #有空格内容一样的两个变量,在命令行模式下is 结果false>>> d= 'a b '>>> c ==dTrue>>> c is dFalse# pycharm自己实践
🌈3. 成员运算符
| 运算符 | 描述 |
|---|---|
| in | 如果在指定序列中找到值就返回True,否则返回False |
| not in | 如果在指定序列中没有找到值就返回True,否则返回False |
str1 = [1, 2, 3, '哈哈哈']print(1 in str1) # Trueprint(1 not in str1) # False
⭐4. 增量运算符
| 运算符 | 实例 |
|---|---|
| += | c += a 等效于 c = c + a |
| -= | c -= a 等效于 c = c - a |
| *= | c *= a 等效于 c = c * a |
| /= | c /= a 等效于 c = c / a |
| %= | c %= a 等效于 c = c % a |
| **= | c ** = a 等效于 c = c ** a |
| //= | c //= a 等效于 c = c // a |
a = 1a += 1 # 展开形式:a = a + 1print(a) # 2
⭐5. 比较运算符
| 运算符 | 描述 |
|---|---|
| == | 比较两个对象的值是否相同,这里要与is区别出来,==是不识别ID的 |
| != | 比较两个对象值是否不相同 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
print(2 > 1) # True# 比较结果为布尔值(True, False)
⭐6. 逻辑运算符
| 运算符 | 逻辑表达式 | 描述 |
|---|---|---|
| and | x and y | 同时满足x和y两个条件返回True,否则返回False |
| or | x or y | 只需要满足x或y中的任意一个条件就返回True,两个都不满足时返回False |
| not | not x | 满足条件x时返回False,不满足条件x时返回True |
a = 1b = 1c = 2# and 两边为真则为真,其余情况为假print(a > 0 and a < c) # Trueprint(a > 1 and a < c) # False# or 两边为假则为假, 其余情况为真print(a > 0 and a < b) # Falseprint(a == 1 and a < c) # True# not: 取反print(not c < a) # True# 优先级: not and ora = 1b = 1c = 2print(a > 1 and c < 3 or not a == 1) # False
🚀二.可变与不可变
不可变(immutable):数值类型(int, bool, float,complex), 字符串(str),元组(tuple)可变(mutable):列表(list), 集合(set),字 典(dict)🚀三.字符串转义
# 字符前存在\,在特定情况下字符就不再表示本身的意思
常见:
| 符号 | 解释 | 案例 |
|---|---|---|
| \n | 换行符 | print(‘s\nd’) |
| \t | 水平制表符 | print('ss\t’dd) |
| \b | 退格(删除一格) | print(‘帅 \b 不帅’) |
| \r | 当前位置移到本行开头 | print(‘d\rhahahs’) |
| \\ | 反斜杠 | print(‘\\’) |
| \‘’ | 一个双引号 | |
| \0 | 一个空格符 | |
| \a | 系统提示音(交互界面) |
字符串前面加上r就可以防止转义
# --- 交互界面 --->>> print('a\000c')a c>>> print('a\0c')a c
🚀四.编码与解码
💥1. 基础使用
统一码(Unicode),也叫万国码、单一码,由统一码联盟开发,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。统一码是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
encode() 和 decode() 是常用的字符串编码和解码方法,用于将 Unicode 字符串按照指定的编码格式转换为二进制数据,并将二进制数据按照指定的编码格式解析为 Unicode 字符串。
下面是两个方法的详细说明:
encode([encoding='utf-8', errors='strict'])
该方法用于将 Unicode 字符串进行编码,生成一个包含了字符编码后的字节串对象。其中,可选参数 encoding 表示指定的字符集,如果不指定则默认采用 utf-8 编码;errors 参数用于设置错误处理方式,取值范围为 'strict'、'ignore' 和 'replace'。
示例代码如下:
s = "Hello, 你好"b = s.encode(encoding="utf-8", errors="strict")print(b) # 输出: b'Hello, \xe4\xbd\xa0\xe5\xa5\xbd'
decode([encoding='utf-8', errors='strict'])
该方法用于将已经编码的二进制数据解码为 Unicode 字符串。其中,可选参数 encoding 表示待解码的字符编码,如果不指定,则默认采用 utf-8 解码;errors 参数用于设置错误处理方式,取值范围为 'strict'、'ignore' 和 'replace'。
示例代码如下:
b = b'Hello, \xe4\xbd\xa0\xe5\xa5\xbd's = b.decode(encoding="utf-8", errors="strict")print(s) # 输出:Hello, 你好
需要注意的是,字符串编码和解码涉及到多种字符编码方式和错误处理方式,如果不正确地进行设置和使用,可能会导致字符集转换错误、乱码等问题。因此,在实际开发中,应该根据具体情况选择合适的编码和解码方式,并对数据的合法性进行严格的校验和处理。
🚀五.进制转化
💥1.python进制转化
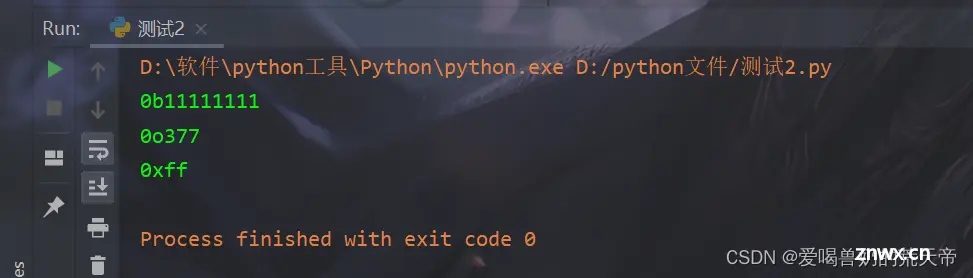
在 Python 中,可以使用内置的 bin()、oct()、hex() 函数将十进制数转化为二进制、八进制和十六进制字符串。
示例代码如下:
dec = 255# 十进制转二进制bin_str = bin(dec)print(bin_str) # 输出 '0b11111111'# 十进制转八进制oct_str = oct(dec)print(oct_str) # 输出 '0o377'# 十进制转十六进制hex_str = hex(dec)print(hex_str) # 输出 '0xff'
需要注意的是,这些函数返回的结果都是字符串类型,并且带有对应进制的前缀,即 '0b' 表示二进制,'0o' 表示八进制,'0x' 表示十六进制。如果需要去除前缀并获取整数值,可以使用 int() 函数。
以下是一个示例代码:
# 字符串转整数(删除前缀 -- 通过切片处理)int_val = int(bin_str[2:], 2)print(int_val) # 输出 255int_val = int(oct_str[2:], 8)print(int_val) # 输出 255int_val = int(hex_str[2:], 16)print(int_val) # 输出 255
如上所示,使用 int() 函数时可以指定第二个参数 base 来指定进制,例如 base=2 表示二进制,base=8 表示八进制,base=16 表示十六进制。在实际应用中,可以根据需要选择合适的函数和参数来进行进制转换。
# ord() 是 Python 内置函数之一,用于将ASCII字符转换为对应的 Unicode 码点。具体而言,ord() 接受一个字符串参数,表示要转换为码点的字符,然后返回该字符所对应的 Unicode 码点。# 将字符转换为 Unicode 编码print(ord('A')) # 输出 65print(ord('a')) # 输出 97print(ord('€')) # 输出 8364# chr() 是 Python 内置函数之一,用于将 Unicode 码点转换为对应的ASCII字符。具体而言,chr() 接受一个整数参数,表示 Unicode 码点(介于 0 到 0x10ffff 之间),并返回与该码点相对应的字符。# 将 Unicode 编码转换为字符print(chr(65)) # 输出 'A'print(chr(97)) # 输出 'a'print(chr(8364)) # 输出 '€'
🚀六.深浅拷贝(复制)
❤️1. 浅拷贝
外层不受影响,内层会受影响
l1 = [1234, 5678, 910]l2 = ['a', l1]l3 = l2.copy()l1.append('帅')>>> id(l1)1750917116360>>> id(l2)1750917140744>>> id(l2[1])1750917116360# 内层id地址相同print(id(l2)) # 2429073232384print(id(l2[1])) # 2104199485056print(id(l3)) # 2429073240128print(id(l3[1])) # 2104199485056# 浅复制 外层不同,内层id相同
❤️2. 深拷贝
内外层都不影响
import copyl1 = [1234, 5678, 910]l2 = ['a', l1]l4 = copy.deepcopy(l2)l1.append('帅')print(id(l1)) # 1633334532096print(id(l2)) # 1633334532352print(id(l4)) # 1633334448384print(id(l2[1])) # 1633334532096print(id(l2[0])) # 1633303890928print(id(l4[0])) # 1633303890928print(id(l4[1])) # 1633334532672l2[0] = 1234print(id(l4[0])) # 外层地址不同print(id(l2[0])) # 内外层都不同
🚀七.运算升级
| 运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
| + | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字符串、列表、元组 |
| * | ‘Hi!’ * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 复制 | 字符串、列表、元组 |
| in | 3 in (1, 2, 3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
注意,in在对字典操作时,判断的是字典的键而不是值
🚀八.常用方法
| 函数名 | 描述 |
|---|---|
| sum(item) | 计算容器中元素值的和 |
| len(item) | 计算容器中元素个数 |
| max(item) | 返回容器中元素最大值 |
| min(item) | 返回容器中元素最小值 |
| del(item) | 删除变量 |
# 当然还有 id,type这些常见方法# isinstance(x, A_tuple) --- 判断 x 是否是 A_tuple类型;注意A_tuple也可以是元组包多个,案例如下:print(isinstance('a', list)) # False# isinstance(x, (A, B, ...)) 相当于isinstance(x, A) or isinstance(x, B) or ...

🚀九.操作扩展
链式赋值
a = b = c = [1, 2, 3, 4]# 其id相同,引用的同一组数据# 改变其中一组, 另外一组也会改变
序列解包
a = [1, 2]b, c = a# a--1 b--2# 注意: 常规解包, 多少个元素就需要多少变量去解demo = [1, 2, 3, 4]data, *lets = demo# data -- 1 lets -- [2, 3, 4]# 注意: 这里利用了不定长参数中的 * , 不限接收数据多少
交换变量
a = 1b = 2b, a = a, b# a -- 2 b -- 1
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。