大数据-86 Spark 集群 WordCount 用 Scala & Java 调用Spark 编译并打包上传运行 梦开始的地方
CSDN 2024-09-08 08:35:01 阅读 54
点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)
HDFS(已更完)
MapReduce(已更完)
Hive(已更完)
Flume(已更完)
Sqoop(已更完)
Zookeeper(已更完)
HBase(已更完)
Redis (已更完)
Kafka(已更完)
Spark(正在更新!)
章节内容
上节我们完成了如下的内容:
Spark RDD 操作方式ActionSpark RDD的 Key-Value RDD详细解释与测试案例
梦的开始
写一个WordCount程序虽然看似简单,但它在大数据学习中有着深远的意义。就像编程世界中的“Hello World”,WordCount是我们迈入分布式计算世界的第一步。在这个过程中,我不仅加深了对Spark生态系统的理解,还亲身体验了大数据处理的核心思想:分而治之。
通过编写和运行这个程序,我意识到,尽管代码本身很简单,但其背后的概念却揭示了大数据处理的复杂性与挑战性。每个词频的统计背后,都代表着分布式系统中对数据的高效切分、分发和聚合。这使我更加意识到,在大数据的世界里,性能优化和资源管理是永恒的主题。
更重要的是,WordCount让我感受到Scala语言在处理并行计算时的优势。通过在实际环境中部署和运行这个程序,我也看到了自己从理论学习向实践应用迈出的重要一步。这不仅是一段代码的完成,更是我在大数据领域探索旅程的一个重要里程碑。
总的来说,这段经历让我更加坚定了继续深入学习和应用大数据技术的决心。WordCount不仅是学习的起点,更是打开大数据世界大门的一把钥匙。
环境依赖
首先要确保你之前的环境都搭建完毕了,最起码的要有单机的Spark,最好是有Spark集群,可以更好的进行学习和测试。
导入依赖
<code><project xmlns="http://maven.apache.org/POM/4.0.0"code>
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"code>
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">code>
<modelVersion>4.0.0</modelVersion>
<groupId>icu.wzk</groupId>
<artifactId>spark-wordcount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.12.10</scala.version>
<spark.version>2.4.5</spark.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>com.typesafe</groupId>
<artifactId>config</artifactId>
<version>1.3.4</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.4.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<archive>
<manifest>
<mainClass>cn.lagou.sparkcore.WordCount</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
编写Scala
使用Scala完成我们的Word Count程序:
package icu.wzk
import org.apache.spark.rdd.RDD
import org.apache.spark.{ SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
var conf = new SparkConf().setAppName("ScalaHelloWorldCount")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val lines: RDD[String] = sc.textFile(args(0))
val words: RDD[String] = lines.flatMap(line => line.split("\\s+"))
val wordMap: RDD[(String, Int)] = words.map(x => (x, 1))
val result: RDD[(String, Int)] = wordMap.reduceByKey(_ + _)
result.foreach(println)
sc.stop()
}
}
大致的项目结构和内容,如下图所示:
编译项目
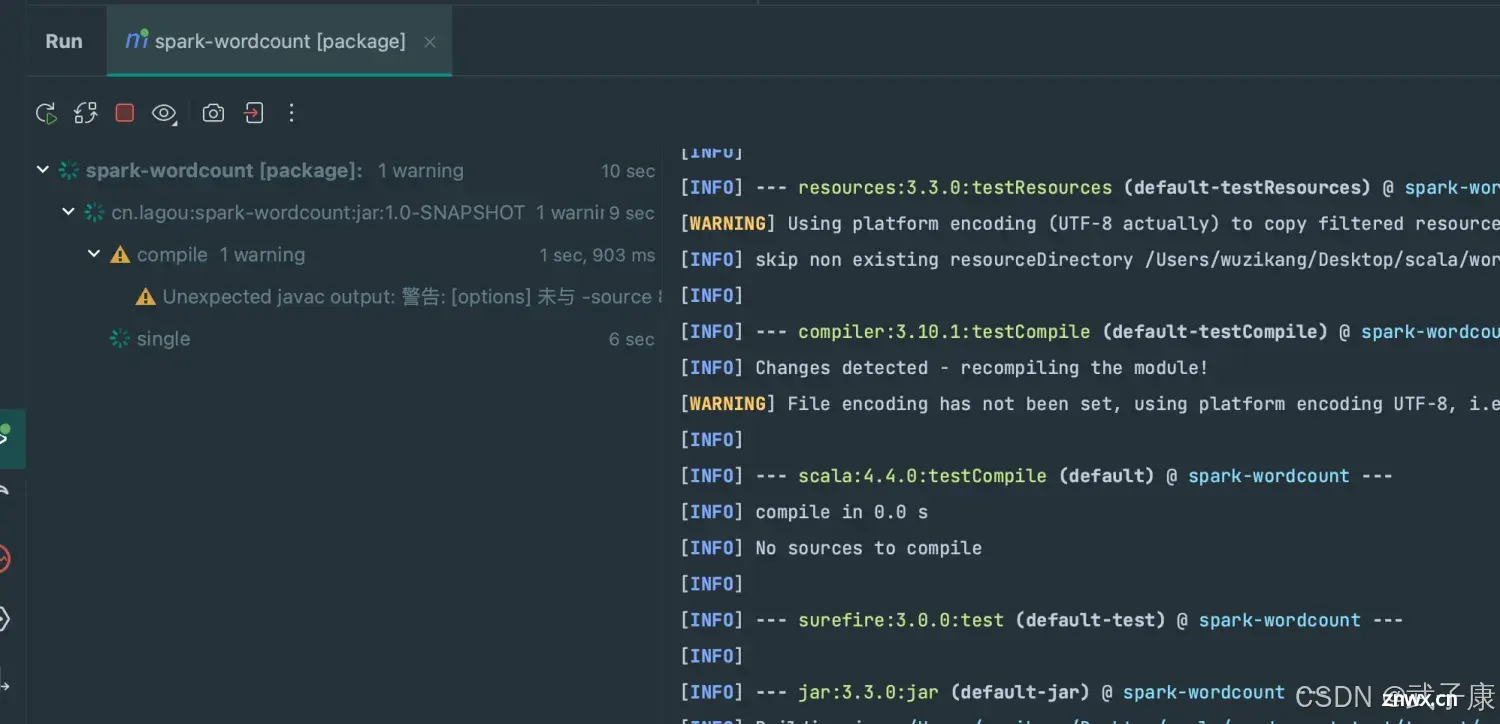
运行Maven的Package,等待执行完毕后,会在 target 下打包出一个 Jar 包。
如果是第一次打包,需要下载包,时间会比较久。
<code># 你也可以用Shell的方式
mvn clean package
运行的过程如下图所示:

打包完的结果大致如下:
上传项目
将项目上传到Spark的集群中:
<code>cd /opt/wzk
我上传到该目录,该目录的情况大致如下:
运行项目
编写如下的指令,将任务提交到Spark集群中进行运行。
我这里随便找了个文件,你也可以找个文件进行运行。
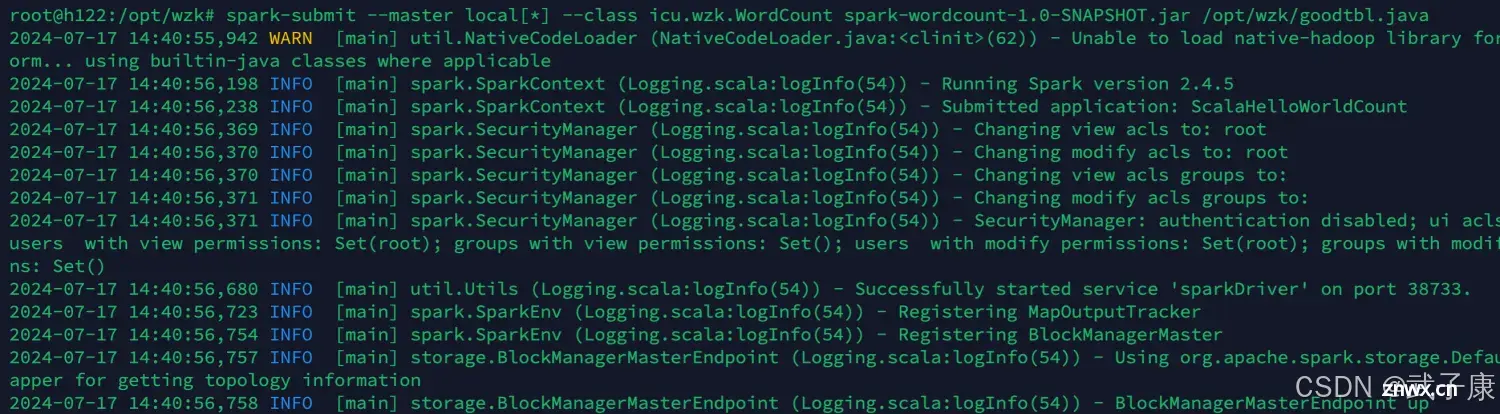
<code>spark-submit --master local[*] --class icu.wzk.WordCount spark-wordcount-1.0-SNAPSHOT.jar /opt/wzk/goodtbl.java
运行结果如下图:
经过一段时间的计算之后,可以看到最终的结果如下图所示:

编写Java
<code>package icu.wzk;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class JavaWordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("JavaWordCount")
.setMaster("local[*]");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("WARN");
JavaRDD<String> lines = sc.textFile(args[0]);
JavaRDD<String> words = lines
.flatMap(line -> Arrays.stream(line.split("\\s+")).iterator());
JavaPairRDD<String, Integer> wordsMap = words
.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> results = wordsMap.reduceByKey((x, y) -> x + y);
results.foreach(elem -> System.out.println(elem));
sc.stop();
}
}
编译项目
和上面一样,Scala的方式一样:

上传项目
同样的,和上述的Scala的过程一样,将项目上传:
<code>/opt/wzk/spark-wordcount-1.0-SNAPSHOT.jar
运行项目
这里注意,写的是Java的类,而不是Scala的启动:
spark-submit --master local[*] --class icu.wzk.JavaWordCount spark-wordcount-1.0-SNAPSHOT.jar /opt/wzk/goodtbl.java
运行的过程截图如下图所示:
等待执行完毕,最终的结果如下图所示:

上一篇: 别让代码愁白头发!15 个 Python 函数拯救你的开发生活
下一篇: 【C++】C++ STL探索:Vector使用与背后底层逻辑
本文标签
大数据-86 Spark 集群 WordCount 用 Scala & Java 调用Spark 编译并打包上传运行 梦开始的地方
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。