C++ :内联函数inline|nullptr
Harper·Lee 2024-07-13 13:05:03 阅读 93
欢迎来到Harper·Lee的学习笔记!
博主主页传送门:Harper·Lee博客主页!
欢迎交流学习!
一、inline关键字
1.1 什么是内联函数?
内联函数:用** inline 修饰的函数叫做内联函数,编译时C++编译器会在调用的地方展开内联函数**,这样调用内联函数就需要创建栈桢,就提高效率了。
1.2 为什么会有内联函数?
1.2.1 回顾宏
主要目的就是为了替代C语言中的宏。先回顾一下什么是宏:
宏就是一种替换,右边的替换掉左边的;
<code>#include<iostream>
using namespace std;
//right
#define ADD(x,y) ((x)+(y))//括起来
int main()
{
int ret = ADD(1,2);//替换后:int ret = ((1)+(2));
cout << ADD(1,2) << endl;
return 0;
}
宏的末尾不能加分号,否则 ; 对语句造成干扰,出现语法错误。
#include<iostream>
using namespace std;
//如果加了分号
#define ADD(x,y) ((x)+(y));
int main()
{
int ret = ADD(1,2);//替换后:int ret = ((1)+(2));
cout << ADD(1,2); << endl;//error
return 0;
}
宏用于替换的表达式一定加整体括号。
C语言中宏的缺点:
不能进行调试(预处理时宏就被处理掉了)。没有类型安全的检查。缺一个括号都容易出现错误。有里面的括号,也有外层的括号。括号的优先级最高。复杂时容易写错。例如一个加法函数:
//right
#define ADD(x,y) ((x)+(y))//括起来
int main()
{
int ret = ADD(1,2);//替换后:int ret = ((1)+(2));
return 0;
}
//error
#define ADD(x,y) (x+y)
#define ADD(x,y) (x)+(y)
#define ADD(x,y) (x+y)
#define ADD(x,y) ((x)+(y));//不能加分号
#define ADD(int x,int y) return x+y;//不能加分号;
1.2.2 宏的改进–内联函数
根据上面的回顾可知,宏的问题缺陷很多,因此C++将它改进为一种函数——内联函数。
C语言实现宏函数时,也会在预处理是替换展开,但是宏函数实现很复杂很容易出错,而且不方便调试,C++设计实现 inline 的目的就是替代C的宏函数。
1.3 内联函数的特性
宏不能进行调试,但是内联函数可以。宏的原理是直接替换,内联函数的原理根据反汇编研究。
#include<iostream>
using namespace std;
inline int Add(int a, int b)
{
int ret = a + b;
return ret;
}
int main()
{
int ret = Add(1, 2);
cout << Add(1, 2) * 5 << endl;
cout << ret << endl;
return 0;
}
inline 对于编译器而言只是一个建议,不同编译器关于 inline 什么情况展开各不相同。也就是说,就算加了 inline,编译器也可以选择在调用的地方不展开。因为C++标准没有规定这个。一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性,直接选择调用该函数,不再展开。**VS编译器debug版本下默认是不展开 inline 的,这样方便调试。**让编译器展开 inline 内联函数的具体操作如下:(两个地方改动)编译器无条件展开其实是有条件的 :如果某个大函数有许多地方都在调用,若每个位置都展开,函数的合计展开次数就会很大,指令就会非常多。大函数进行内联展开,编译的可执行程序变大,用户体验感变差。
a.
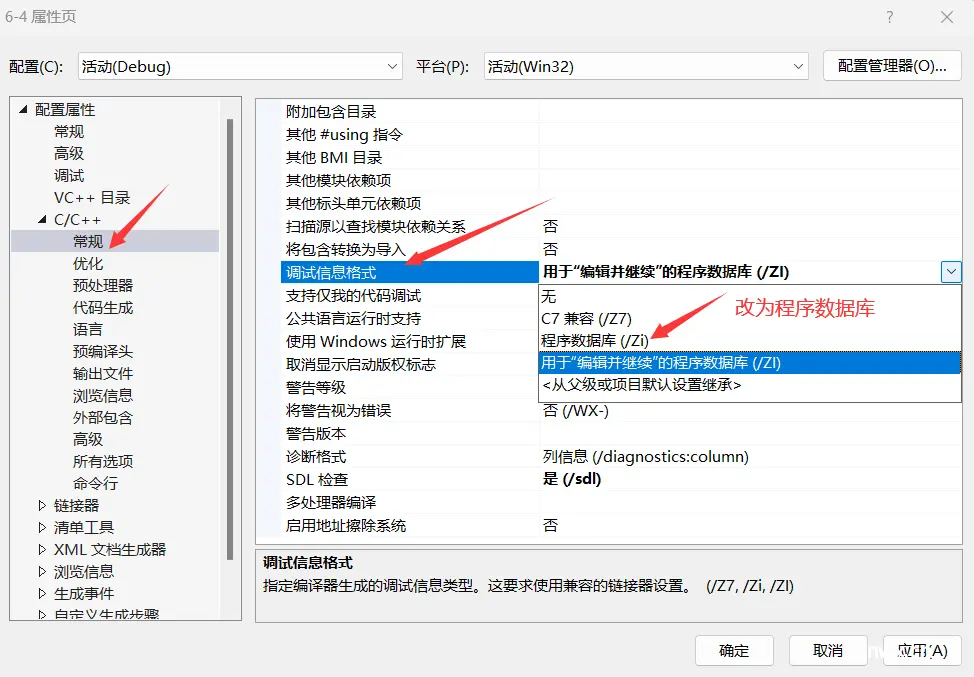
b.
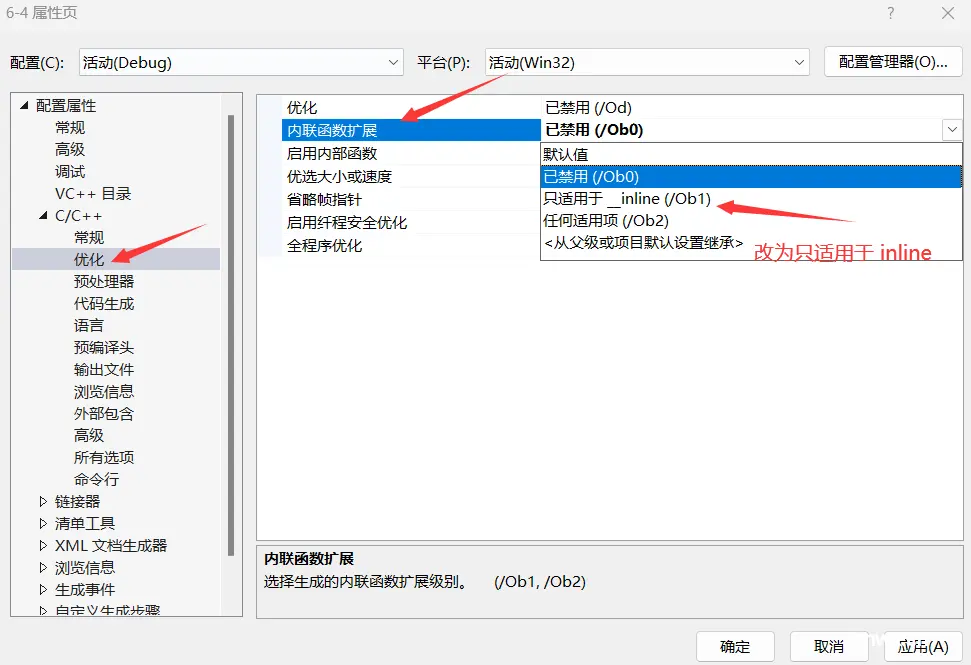
**inline 不建议声明和定义分离到两个文件,分离会导致链接错误。C++编译器默认不需要函数地址。**所以 inline 被展开,没有函数地址,链接时就会出现报错。也就是说,**加了inline的函数会让编译器认为这并不是一个函数,所以不会被存到函数调用符号表里,因此不能将声明和定义分离!!**正确做法:将inline的声明和定义都放在头文件里!这样子在预处理的时候该定义就会被放到执行文件里。
<code>// F.h
#include <iostream>
using namespace std;
inline void f(int i);//声明
// F.cpp
#include "F.h"
void f(int i)//定义
{
cout << i << endl;
}
// main.cpp
#include "F.h"
int main()
{
// 链接错误:⽆法解析的外部符号
f(10);//链接:但是.h文件中函数的声明被inline修饰了,就没有函数地址
return 0;
}
二、指针空值nullptr
2.1 C和C++中NULL的含义
NULL实际上是一个宏NULL,在传统C语言文件stddef.h中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
由上面的代码可以看出,NULL可能被定义为是字面常量0,或者被定义为是无类型指针(void)的常量。这两种定义在使用空值指针时,就会出现歧义。比如下面:*
#include<iostream>
using namespace std;
void f(int x)
{
cout << "f(int x)" << endl;
}
void f(int* ptr)
{
cout << "f(int* ptr)" << endl;
}
int main()
{
f(0);
// 本想通过f(NULL)调⽤指针版本的f(int*)函数,但是由于NULL被定义成0,调⽤了f(intx),因此与程序的初衷相悖。
f(NULL);
f((int*)NULL);//NULL写成0也可以
// f((void*)NULL);//强转成void*,编译报错:error C2665: “f”: 2 个重载中没有⼀个可以转换所有参数类型
f(nullptr);
return 0;
}
运行结果:
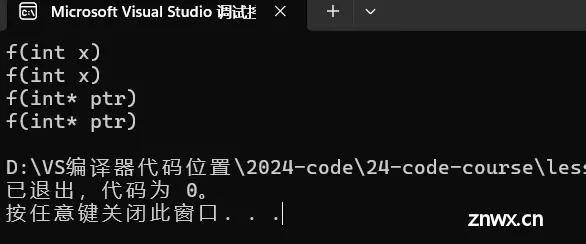
根据运行结果可知,NULL被定义为0,就没有调用指针版本的 f(int*) 函数。
为了解决这个问题,C++11中引入了一个特殊的关键字——nullptr,这样就可以调用该函数了。
2.2 nullptr的特点
nullptr有以下几个特点:
nullptr是一种特殊类型的字面量,它可以转化成任一其他类型的指针类型。使用nullptr定义空指针可以避免类型转换的问题,因为nullptr只能被隐式转换位指针类型,而不能转换成整数类型。
<code>int* p1 = nullptr; //right
int i = nullptr; //error
2.3 C和C++中void*的区别
上面的例子代码中,f(void*) NULL;会报错,报错原因分析:C语言中 void 指针是一个垃圾桶,什么类型的指针都可以接受;C++中 void 指针需要进行强制类型转换。**
//test.c
void* p1 = NULL; //p1表示空指针
void* p2 = p1; //right,不用强转
//test.cpp
void* p3 = NULL;
int* p4 = p3; //error
int* p5 = (int*)p3;//right,需要强转
喜欢的uu记得三连支持一下哦!

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。