展示广告预估技术最新突破:基于原生图文信息的多模态预估模型
阿里妈妈技术 2024-09-05 10:01:01 阅读 90
一、摘要
目前,搜索推荐及广告领域的预估模型主要基于大规模稀疏ID特征结合MLP构建。然而,ID特征难以刻画item的内容语义信息,因此业界一直在探索如何引入原生多模态内容信息以提升模型性能。为此,需要思考几个关键问题:
多模态信息在预估模型中带来效果提升的关键,以及如何设计预训练任务以获取多模态表征;
在基于ID体系的预估模型中如何释放多模态表征的效果。
本文将介绍阿里妈妈展示广告团队在预估模型与多模态结合方向上的最新突破。我们发现,多模态信息能否大幅提升效果的关键在于,其能否通过精准建模“目标商品”和“用户历史行为商品”之间的语义相似度,从而实现相较于ID特征更优的行为序列建模。为此,我们首先设计了语义感知的对比学习预训练SCL方法,让多模态编码器能够从多模态原始信息中抽取出其蕴含的电商业务语义信息。随后,我们提出了SimTier和MAKE算法,利用多模态表征的语义判别能力进行行为序列建模。通过这些技术创新,我们取得了显著成果——精排CTR模型的GAUC提升超过1个百分点,这是近几年来展示广告离线效果提升最大的迭代,在目前的高技术水位下显得尤为可贵。目前,多模态的应用也在粗排等其他模型中全面上线,均取得显著的线上收益。
基于这一工作的研究论文已被CIKM 2024会议接收,欢迎阅读交流。
论文:Enhancing Taobao Display Advertising with Multimodal Representations: Challenges, Approaches and Insights
作者:Xiang-Rong Sheng*, Feifan Yang*, Litong Gong*, Biao Wang*, Zhangming Chan, Yujing Zhang, Yueyao Cheng, Yong-Nan Zhu, Tiezheng Ge, Han Zhu, Yuning Jiang, Jian Xu, Bo Zheng (*Equal contribution)
链接(点击↓阅读原文↓):https://arxiv.org/pdf/2407.19467
二、背景
目前,业界的预估模型普遍采用大规模稀疏ID特征结合多层感知机(MLP)作为核心架构。ID特征的优势在于其高复杂度和强大拟合能力,在数据量较大的情况下往往能够取得优异的效果 [1]。然而,ID特征天然难以刻画商品的内容语义信息。因此,业界一直在探索将多模态信息引入预估模型的解决方案 [2] - 这些方案通常采取两阶段的建模框架,第一阶段进行多模态表征的预训练,第二阶段将这些表征引入预估模型。尽管过去的研究在一定程度上提高了模型在长尾样本上的预估准度,但尚缺乏能够大幅提升整体预测效果的方案。
在本文中,我们希望探明预估模型与多模态的有效结合方式,为模型迭代提供ID体系之外的第二增长曲线。为此,我们需要回顾当前业界预估模型中哪些模块起到了最重要的作用,并思考如何利用多模态数据来改进这些模块。
预估模型的核心模块:行为序列建模模块。在预估模型中,一个(最为)重要的模块是行为序列建模模块,其核心在于通过建模“目标商品”和“用户历史行为商品”之间的相关性,以实现精准个性化推荐(图1以DIN为例进行了介绍);
ID特征做行为序列建模的局限:难以建模商品之间的语义相似度。由于ID特征稀疏性和无泛化性的特点,其难以有效建模商品之间语义相似度,例如商品pairwise的视觉相似度和文本语义相似度。
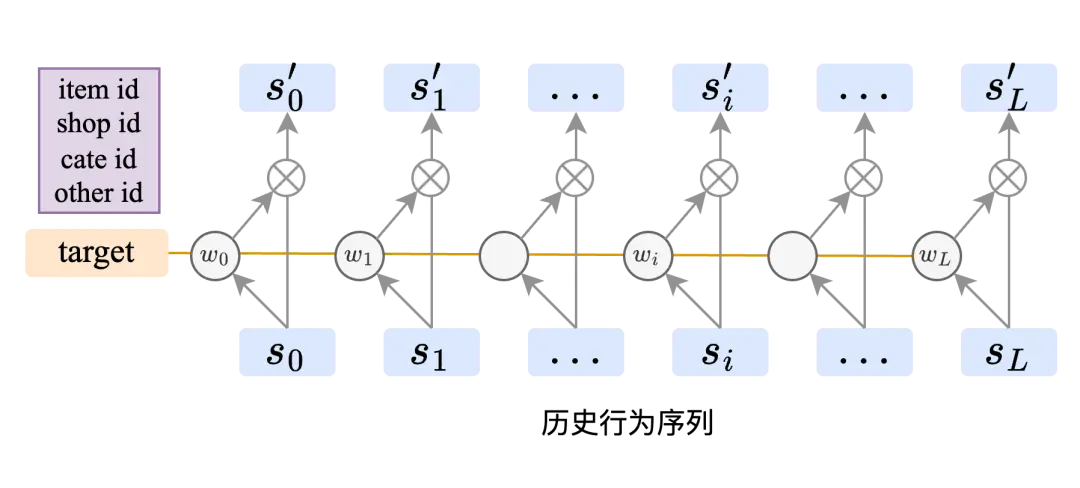
图1. DIN利用ID特征端到端建模“Target商品”和“用户历史行为商品”之间基于ID协同过滤信息的pairwise相似度(用作attention score),但由于ID的稀疏性和无泛化性特点,其难以建模商品之间的视觉及文本语义相似度。
针对ID特征的不足,我们思考是否可以利用多模态信息来实现更好的行为序列建模。直观上,多模态信息可以更好地建模“目标商品”和“用户历史行为商品”之间的视觉和文本语义相似度。例如,商品的图片可以帮助模型判定目标商品与历史行为商品之间的视觉相似度,从而辅助预测。明确了多模态信息的利用方式后,我们设计了基于原生图文信息的多模态预估模型建模框架(如图2所示),核心解决了以下两个问题:
如何设计预训练任务,使多模态表征具备度量商品之间语义相似度的能力;
如何有效应用多模态表征的语义相似度度量能力提升序列建模能力。
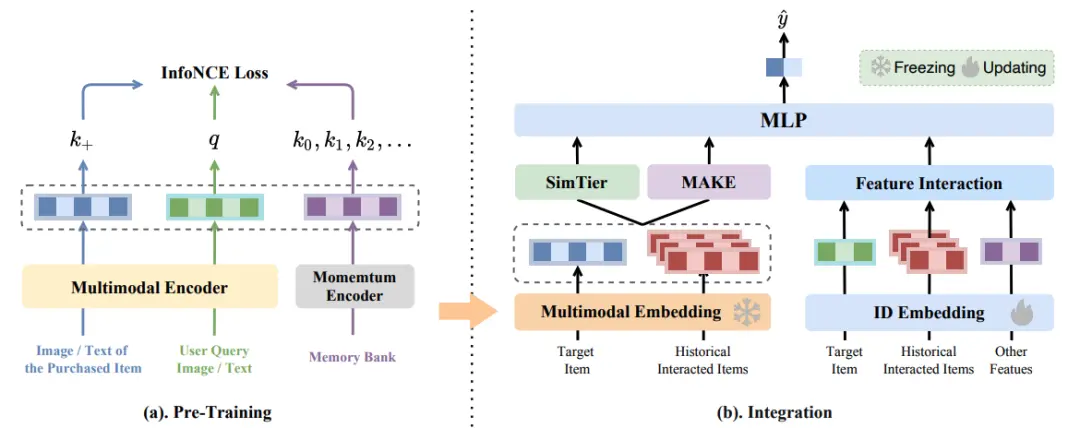
图2. 基于原生图文信息的多模态预估模型建模框架。
针对多模态表征预训练,我们提出了语义感知的对比学习方法SCL(Semantic-aware Contrastive Learning)。SCL的设计motivation来源于我们的实验发现 - 我们发现多模态预训练(表征质量)的关键不在于选择哪个基座模型,而在于如何构造预训练数据,更具体地,如何定义语义相似/不相似的商品对,来使得表征可以刻画电商场景下不同商品之前的语义相似度。
更具体地,我们发现电商场景下用户的搜索-购买行为链可以很好地定义多模态之间的语义相似性。以图像为例,如果用户搜索了一张枕头的图片,随后购买了一个枕头,这一连串的动作表明查询的图片和购买商品的图片在语义上足够相似,从而满足了用户的购买意图。因此我们使用用户的搜索-购买行为链定义语义相似pair,通过对比学习让多模态encoder提取多模态中蕴含的电商业务语义信息。在训练文本编码器时,我们将用户搜索查询的文本与他们最终购买的商品标题配对,作为语义相似对。同样地,对于图像模态,我们将用户搜索的图片与后续购买商品的图像进行配对。这种配对策略自然地捕捉了在电商场景中与用户最相关的语义相似信息(反映了影响他们购买决策的关键因素)。
在获得蕴含电商业务语义的多模态表征后,接下来的问题是如何将这些多模态表征引入基于ID体系的预估模型。我们对不同的应用方式进行了实验,并有两个有趣的观察:
简化多模态表征的使用方式通常可以提升多模态表征的效果;
由于泛化能力的不同,基于ID的模型和基于多模态的模型在训练时的epoch数上存在差异。
针对以上的这两个观察,我们设计了两个多模态表征应用算法。首先,我们提出了SimTier方法,通过构造行为序列与target商品的同款相似度分布,简化模型对语义相似度分布的建模难度。此外,为了解决多模态表征和ID特征之间在训练epoch上存在的差异,我们引入了多模态知识提取(MAKE)模块。MAKE模块将与多模态表征相关参数的优化与基于ID模型的参数优化分离开来,通过多个epoch的训练,使多模态表征相关参数能够充分学习。
接下来的章节我们会对表征预训练和表征应用方式做详细介绍,同时也会介绍实验分析和线上系统架构。
三、SCL:语义感知的对比学习预训练
为了得到能够度量语义相似度的表征,我们提出了语义感知的对比学习方法SCL,SCL的核心想法是在表征空间拉近语义相似样本对的距离,推远语义不相似样本对的距离。为实现这一目标,我们需要定义电商场景下的语义相似(正样本)和不相似(负样本)的样本对。正负样本的定义直接决定了表征质量 - 以图3为例,这里展示了三个几乎相同的枕头,它们之间存在着细微的差异(图案和外观上有微小不同)。如果语义相似/不相似样本对的定义不够准确,那么表征将无法捕捉这些细微差别,进而影响后续的序列建模应用。实际上,我们在实验中发现这些微小差异通常无法被关注整图语义的预训练表征刻画,这也是之前业界使用通用预训练表征收效甚微的原因。

图3. 图A与图B在图案上相对图C更一致。
那么,如何构造这种语义相似的样本对(pair)呢?如第二章所述,我们发现在电商场景中用户的搜索-购买行为链可以用来定义语义相似商品pair:
以图像为例:如果用户搜索了一张枕头的图片,随后购买了一个枕头,这一连串的动作表明查询的图片和购买商品的图片在语义上足够相似,从而满足了用户的购买意图。
以文本为例:如果用户搜索“毛绒绒的玩具”,随后购买了一只标题为“毛绒玩偶”,这表明搜索的文本和购买商品的文本在语义上足够相似,从而满足了用户的购买意图。
因此,在训练文本encoder时,我们将用户搜索查询的文本与他们最终购买的商品标题配对,作为语义相似对。同样地,对于图像模态,我们将用户搜索的图片与后续购买商品的图像进行配对。我们实验中发现使用搜索-购买行为链作为正样本效果最佳,而其他一些常见的商品相似度定义指标,例如swing i2i等,并不适合作为多模态预训练的label。原因在于诸如swing i2i等指标并不是基于商品pair的多模态语义相似性定义,如果用这种pair进行训练,会导致多模态encoder的学习偏离预期(退化为ID表征),学习不到商品的多模态语义信息。因此定义语义相似的商品对时,需要保证这一相似性能够归因于图像、文本的多模态语义相似性,而不是其他无关因素。
构造完正样本后,接下来的问题是如何构造负样本。一种直观的方式是使用同mini-batch下的样本作为负样本,在实践中,我们发现对于负样本,扩大负样本的数量可以进一步提升效果。为了在训练过程中增加可用的负样本数量,我们借鉴MoCo的动量更新技术,从更大的memory bank中采样出更多的负样本。最终的样本组成如下表所示:
| 模态 | 正样本(语义相似)pair | 负样本 |
|---|---|---|
| 图像 | <用户搜索的图片,用户搜后购买的商品图> | MoCo memory bank |
| 文本 | <用户搜索的文本,用户搜后购买的商品标题> | MoCo memory bank |
构造完正/负样本pair后,我们采用InfoNCE作为损失函数进行对比学习。具体来说,给定一个多模态encoder提取的搜索query表征及其对应的正样本表征,以及memory bank中的一组负样本表征,InfoNCE 利用点积来度量相似性(所有表征均进行了L2归一化)。如公式1所示,当query 与其指定的正样本的相似度较高,并且与memory bank中的所有其他样本的相似度较低时,损失值将降低。
()
在公式(1)中,是一个可学习的温度参数。在实践中,我们将memory bank的大小设置为196,800。
通过SCL预训练获得的表征能够为下游预估模型提供区分商品语义相似度的能力。除了上述的预训练过程,我们在实验中还发现显示增加难负样本对最终的表征质量也有一定帮助。例如对于图像,我们会额外构造难负样本,例如用户被商品图A trigger(类query)后的点击商品B作为难负样本(具有一定的视觉相似性但又不完全视觉相似的样本pair),并取得了进一步的效果提升。
四、SimTier&Make:多模态表征用于序列建模
4.1 观察和思考
在获得蕴含电商业务语义的多模态表征后,接下来的问题是如何利用多模态表征的语义判别能力进行序列建模。我们首先回顾当前业界主流的多模态表征应用思路,主要可以分为:(a) 聚类 (b) 相似度 (c) 原始表征 几种方式:
聚类:将多模态embedding聚类为ID,并应用Target Attention等序列建模方法;
相似度:计算target item与行为item的相似度,将其作为序列行为的sideinfo并应用pooling等建模方法;
原始表征:直接引入原始embedding,采用和ID embedding完全一样的序列建模方式,进行target attention等计算。
我们对不同的应用方式进行了实验,并有两个有趣的观察:
观察1:简化多模态表征的使用方式通常可以提升多模态表征的效果。 我们发现,直接将多模态原始表征采用和ID embedding一样的复杂应用方式,往往不能带来最佳的效果。这是因为与多模态表征相关的参数(例如与多模态表征连接的MLP的参数),在与ID embedding的联合训练过程中无法充分学习。相反,那些简化多模态表征使用的策略,例如将它们转换为聚类ID和相似度的方式 [3, 4],往往可以提供相对更好的效果。
观察2:由于泛化能力的不同,基于ID的模型和基于多模态的模型对于训练所需epoch数存在差异。 业界基于ID的模型通常只训练一个epoch,以避免过拟合 [1]。相反,我们发现完全基于多模态表征(无ID特征)的模型由于其良好的泛化性,可以进行多个epoch的训练,并且随着训练epoch数的增加,其性能显著提升(详见图4)。

图4. 多模态预估模型(只以多模态表征为输入,无ID特征)训练多个epoch后测试GAUC持续上涨,而ID预估模型在训练的第二个epoch测试GAUC会有急剧下滑(One-Epoch现象)。
针对以上的这两个观察,我们设计了两个多模态表征应用算法SimTier及MAKE,将分别在4.2和4.3中进行介绍。
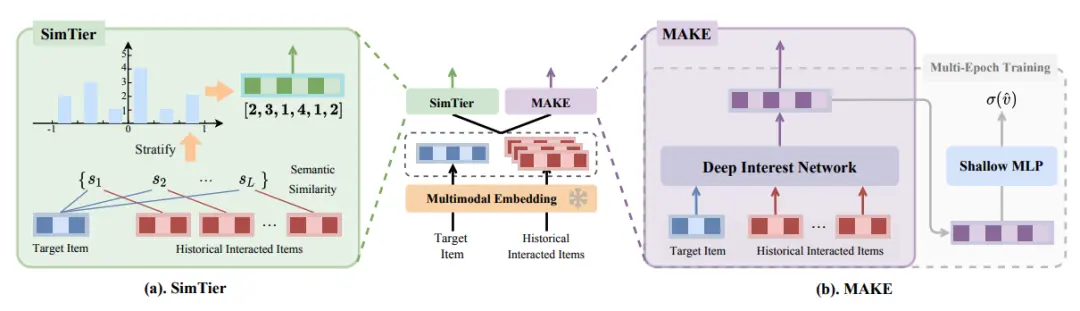
图5. 本文提出的预估模型应用多模态表征方法:SImTier(a)及MAKE(b)
4.2 SimTier:构造语义相似度分布
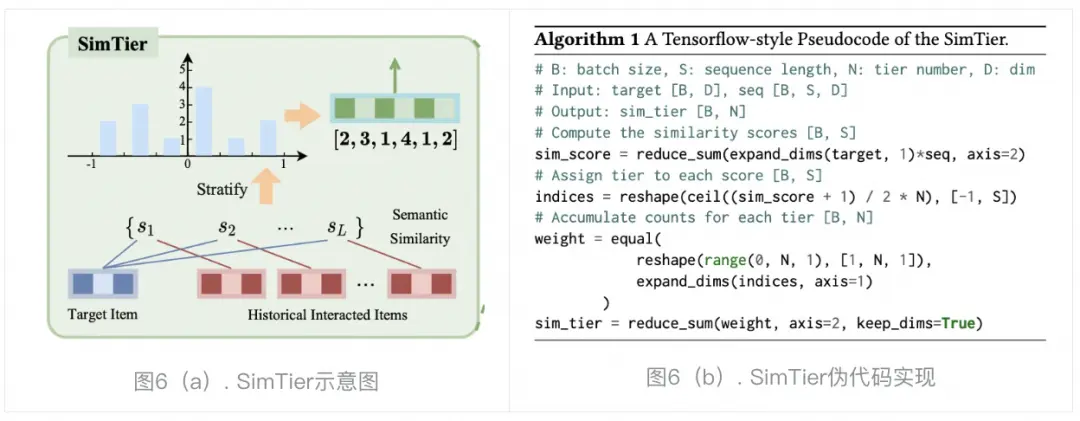
4.1章的观察1启发了我们要简化多模态表征的使用方式。为此,我们提出了SimTier方法,通过构造target商品与行为序列的语义相似度分布,简化模型序列建模的难度。如图6(a)所示,SimTier首先计算Target商品与用户历史行为商品的多模态相似度(L为序列长度),
在得到相似度分数之后,我们的想法是将相似度分数离散化后分档,并统计每个档位行为个数,以此来表示target商品与历史行为商品的相似度分布。具体地,我们先将相似度的值域 [-1.0, 1.0] 平均划分为N个层级。在每个层级中,我们计算其对应范围内的相似度分数的数量。由此,我们将L个相似度分数转换为了得到一个N维向量,每个维度代表该对应层级中的相似度分数的数量。通过这样方式,SimTier有效地将一组高维的多模态表征转换为一个低维(N维)向量,该向量刻画了Target商品与用户历史行为商品之间的相似度分布。SimTier得到的N维向量会与其他ID embedding拼接,并输入到随后的MLP中。图6给出了SimTier向量计算的伪代码。
4.3 MAKE:解耦多模态表征和ID特征的优化过程
为了解决4.1章观察2中多模态表征和ID特征之间在训练epoch上存在的差异,我们引入了多模态知识提取(MAKE)模块。MAKE模块将与多模态表征相关参数的优化与其他参数优化分离开来,通过多个epoch的训练,使多模态表征相关参数能够更有效地学习。如图7(a)所示,MAKE 模块包括两个步骤:1)将多模态相关参数通过多个epoch训练充分 2)将预训练充分的多模态知识引入下游CTR等任务。
多个epoch训练多模态相关参数
MAKE模块的目标是通过多轮训练预训练多模态表征相关的参数,以确保它们的收敛。实践中,我们采用点击率预估任务作为多模态参数的“预训练”任务(注意到这里的预训练不同于表征预训练,是预训练多模态预估模型,其只以Target和序列侧多模态表征、为输入)。如图7(a)所示,我们首先构造一个基于DIN的用户行为建模模块,该模块只使用多模态特征为输入,得到输出:
然后,我们将输入到一个四层的MLP()中,得到logit及预估点击率,通过多轮训练使其模型参数训练收敛(表征fix不更新)。
将预训练充分的多模态知识引入下游CTR等任务
在获取到训练充分的多模态预估模型后,接下来的步骤是将其引入到下游推荐任务中。在实践中,我们将、的中间层输出、logits拼接,送到预估模型中联合训练。通过MAKE模块的多轮训练,我们有效解决了ID特征和多模态表征所需训练epoch的差异,最终带来了更好的预估效果。
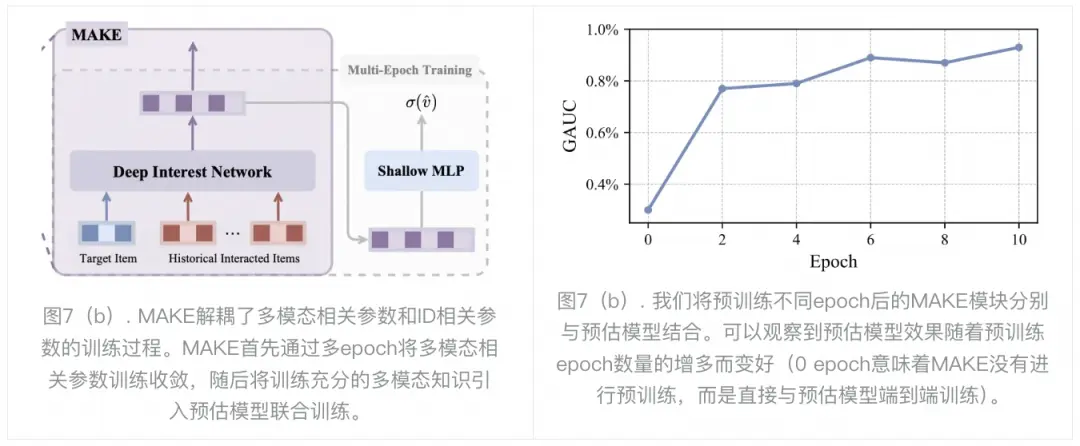
我们还对MAKE进行了消融实验,来验证第一阶段MAKE多epoch预训练对下游预估模型的正向作用。如图7(b)所示,我们将预训练不同epoch后的MAKE模块分别与预估模型结合。可以观察到预估模型效果随着MAKE预训练epoch数量的增多而变好(0 epoch意味着MAKE没有进行预训练,而是直接与预估模型端到端训练)。这说明第一阶段的预训练起到非常关键的作用,这一阶段为多模态相关的模型参数提供更好的初始化,使得ID和多模态表征联合训练时效果更优。
五、实验分析
在本节中,我们以图像表征在点击率(CTR)预估模型的应用为实验setting,在此基础上进行实验分析。
5.1 预训练任务对比
我们将SCL与其他一系列广泛应用的预训练方法进行了对比。
CLIP-O:基于通用数据集预训练的CLIP模型;
CLIP-E:在电商场景中基于CLIP-O模型进行微调的版本,使用对齐的商品描述和商品图片;
SCL:本文提出的语义感知的对比学习方法。
对于预训练方法的评估,我们主要采用准确率Acc(多模态检索匹配语义相似商品能力)及正负差异性指标(衡量测试样本与正负样本之间距离的差距)。具体来说,Acc@N指标量化了表征识别语义相似商品对的能力。但由于准确率只是评估了正负样本的相对距离大小,而模型使用时会使用相似度的绝对值,因此我们也会比较正负差异性指标,评估正样本pair与负样本pair之间距离差距。具体来说,正负差异性指标计算逻辑是检索top1相似度与检索top10相似度的差,直观上正负差异性指标越大,表征区分正负样本pair的能力越强。预训练指标与预估模型GAUC的关系详见论文6.2。

图8. 不同预训练方法的对比。
各个预训练方法的效果对比详见图8。从中我们可以得到两个结论。首先,SCL预训练方法优于其他不考虑语义相似性的方法,这显示了语义感知预训练的必要性。其次,Momentum Contrast(MoCo)和Triplet loss(引入hard negative)等负样本增强技术可以进一步提升多模态表征的质量,这说明负样本的选择对表征质量有很大影响。
5.2 预估模型对比
我们将SimTier和MAKE与其他方法进行了对比,包括
基于ID的生产基线模型(ID-based model);
原始表征应用(vector)方法,即直接引入原始embedding,进行target attention等计算;
相似度方法(SimScore):SimScore方法可以看作是Vector方法的简化版本。它将每个历史行为与Target的相似度作为辅助信息引入模型。
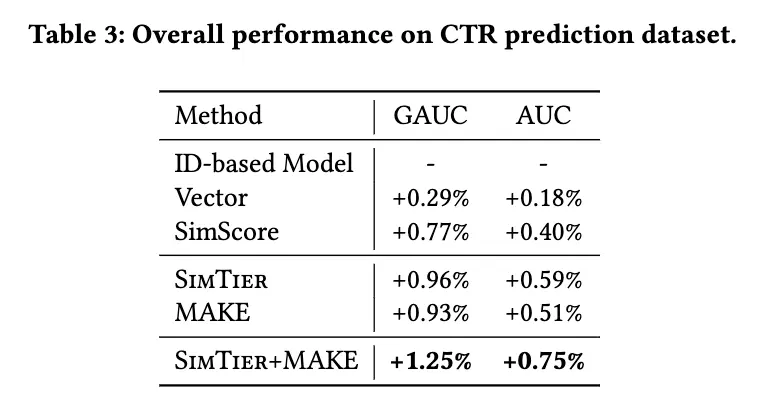
图9. 不同多模态应用方法的对比。
实验结果如图9所示,从中我们可以得到两个结论,首先SimTier和MAKE显著优于其他方法。其次,SimTier和MAKE叠加后可以进一步提升预估效果,相比于基于ID的模型,GAUC提升+1.25%,AUC提升+0.75%。此外我们也验证了多模态表征对于长尾商品的帮助,更详尽的实验分析见论文6.3。
六、在线部署和效果
为了最大化多模态表征的效果,我们需要保障多模态表征在用户行为序列侧和target商品侧的特征覆盖率。这要求我们构建高效的实时表征产出能力,使得新建商品/广告能够迅速请求多模态encoder生成表征,供模型训练和在线预测使用。为此,我们也对系统架构进行了升级,如图10所示,在接收到上游触发源(新商品/新广告)的消息后,我们会请求多模态encoder模型,实时推理得到商品主图/广告创意embedding,并写入多模态索引表。下游ODL训练任务和在线预估引擎可以从索引中查询表征进行应用。通过表征实时推理能力的建设,,新商品/新广告从创建到对应表征可以被下游应用的时延降低至秒级,多模态特征覆盖率提升至99%以上 - 这不仅提升了多模态表征的效果,还大大缓解了新广告的冷启动问题。
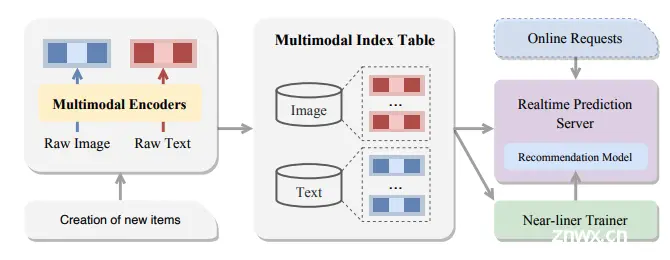
图10. 在线系统架构。
自2023年中期以来,原生图像、文本表征已经在阿里妈妈展示广告系统中的粗排、精排和融合模型中全量上线,带来了显著的业务收益。例如,在精排CTR预估模型中引入图像表征取得大盘CTR+3.5%,RPM+1.5%,ROI+2.9%的提升。特别地,对于新广告(创建时间在最近24小时内)提升更加显著,CTR+6.9%,RPM+3.7%,ROI+7.7%,这也验证了多模态信息在缓解冷启动问题上的效果。
七、总结和展望
多模态内容信息能补充ID特征难以刻画的语义信息,因此一直吸引着业界的广泛关注。在本文中,我们通过设计语义感知的预训练SCL方法,并结合创新的多模态应用算法SimTier及MAKE,构建了基于原生图文信息的多模态预估模型。在取得显著的业务效果的同时,也突破传统预估模型对ID特征过度依赖的问题。
对于预估模型X多模态方向,未来还有诸多值得继续探索的方向,包括但不限于
如何利用多模态表征全面革新传统序列建模技术,例如多模态结合长序列建模 [5];
如何将多模态表征与大模型世界知识进行结合,突破用户行为反馈数据的闭环;
如何将多模态与生成式推荐结合,实现预估模型的scaling law。
未来我们也会在这些方向进行持续探索。
▐ References
Zhao-Yu Zhang, Xiang-Rong Sheng, Yujing Zhang, Biye Jiang, Shuguang Han, Hongbo Deng, and Bo Zheng. Towards Understanding the Overfitting Phenomenon of Deep Click-Through Rate Models. In CIKM 2022.
Tiezheng Ge, Liqin Zhao, Guorui Zhou, Keyu Chen, Shuying Liu, Huiming Yi, Zelin Hu, Bochao Liu, Peng Sun, Haoyu Liu, Pengtao Yi, Sui Huang, Zhiqiang Zhang, Xiaoqiang Zhu, Yu Zhang, and Kun Gai. Image Matters: Visually Modeling User Behaviors Using Advanced Model Server. In CIKM 2018.
Jia-Qi Yang, Chenglei Dai, Dan Ou, Ju Huang, De-Chuan Zhan, Qingwen Liu, Xiaoyi Zeng, and Yang Yang. COURIER: Contrastive User Intention Reconstruction for Large-Scale Pre-Train of Image Features. CoRR abs/2306.05001 (2023).
Anima Singh, Trung Vu, Raghunandan H. Keshavan, Nikhil Mehta, Xinyang Yi, Lichan Hong, Lukasz Heldt, Li Wei, Ed H. Chi, and Maheswaran Sathiamoorthy. 2023. Better Generalization with Semantic IDs: A case study in Ranking for Recommendations. CoRR abs/2306.08121 (2023).
Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction. Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, Kun Gai. In CIKM 2020.
END

也许你还想看
丨展示广告预估模型优势特征应用实践
丨展示广告多模态召回模型:混合模态专家模型
丨排序和准度联合优化:一种基于混合生成/判别式建模的方案
丨深度点击率预估模型的One-Epoch过拟合现象剖析
丨CC-GNN:基于内容协同图神经网络的电商召回方法
丨BOMGraph:基于统一图神经网络的电商多场景召回方法
丨基于特征自适应的多场景预估建模
丨点击率模型特征交叉方向的发展及CAN模型介绍
关注「阿里妈妈技术」,了解更多~
喜欢要“分享”,好看要“点赞”哦ღ~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。