【联邦学习(Federated Learning)】- 从基本分布式思想开始理解联邦学习
1 + 1=王 2024-06-20 16:01:07 阅读 58
文章目录
联邦学习的基本概念联邦学习的定义联邦学习的特点 分布式机器学习面向扩展性的分布式机器学习面向隐私保护的分布式机器学习分布式机器学习平台 联邦学习架构C-S架构P2P对等网络架构
联邦学习的基本概念
联邦学习的定义
机器学习和人工智能的成功离不开大量的数据,但随着人工智能在各行各业的应用落地,人们对于用户隐私数据保安全的关注度也在不断提高。如何在遵守更加严格的、新的隐私保护条例的前提下,解决数据碎片化和数据隔离的问题,是当前人工智能研究者必须解决的问题。
在以上的背景基础下,人们开始寻求一种不必将所有数据集中到一个中心存储点就能够训练机器学习模型的方法。
联邦学习旨在建立一个基于分布数据集的联邦学习模型。 其基本思想为:
由每一个拥有数据源的组织训练一个模型,之后让各个组织在各自的模型上彼此交流沟通,最终通过模型聚合得到一个全局模型。为了确保用户隐私和数据安全,各组织间交换模型信息的过程将会被精心地设计,使得没有组织能够猜测到其他任何组织的隐私数据内容。同时,当构建全局模型时,各数据源仿佛已被整合在一起。
联邦学习的特点
联邦学习是一种具有以下特征的用来建立机器学习模型的算法框架。
有两个或以上的联邦学习参与方协作构建一个共享的机器学习模型。每一个参与方都拥有若干能够用来训练模型的训练数据。 在联邦学习模型的训练过程中,每一个参与方拥有的数据都不会离开该参与方,即数据不离开数据拥有者。 联邦学习模型相关的信息能够以加密方式在各方之间进行传输和交换,并且需要保证任何一个参与方都不能推测出其他方的原始数据。 联邦学习模型的性能要能够充分逼近理想模型(是指通过将所有训练数据集中在一起并训练获得的机器学习模型)的性能。
分布式机器学习
分布式机器学习是指利用多个计算节点进行机器学习或者深度学习的算法和系统,旨在提高性能、保护隐私,并可扩展至更大规模的训练数据和更大的模型。如下图是一个由三个计算节点和一个参数服务器组成的分布式机器学习系统:
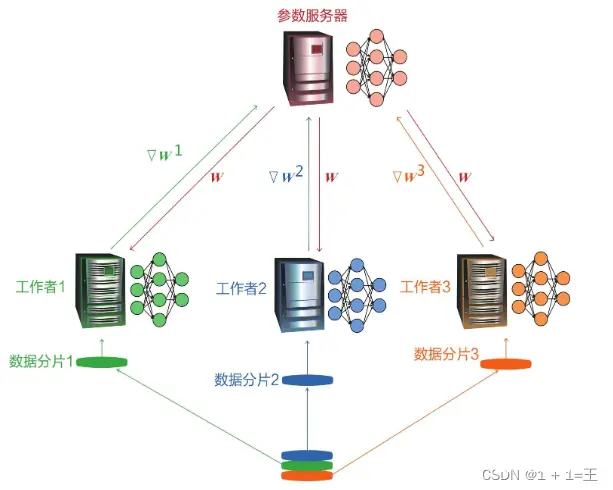
分布式机器学习通常可分为: 面向扩展性的分布式机器学习和面向隐私保护的分布式机器学习。
面向扩展性的分布式机器学习
面向扩展性的分布式机器学习是指用来解决不断增长的扩展性和计算需求问题的机器学习。
常见的解决方法有:
数据并行:先将训练数据划分为多个子集(也称为分片或者切片),然后将各子集置于多个计算实体中,之后并行地训练同一个模型。数据并行指利用不同的计算设备,通过使用同一个模型的多个副本,对多个训练数据分块(也称为分片或者切片)进行处理,并定期通信交换最新的模型训练结果。模型并行:随着DNN模型变得越来越大,如BERT模型,我们可能会面临一个DNN模型不能加载到单一计算节点内存中的问题。对于这种情况,我们需要分割模型,并将各部分置于不同的计算节点中,这种方法被称为模型并行,主要目的是避免内存容量限制任务并行:任务并行指的是计算机程序在同一台或多台机器的多个处理器上执行。它着力并行执行不同的操作以最大化利用处理器或内存等计算资源。任务并行的一个例子是一个应用程序创建多个线程进行并行处理,每个线程负责不同的操作。图并行混合并行和交叉并行
面向隐私保护的分布式机器学习
面向隐私保护的分布式机器学习主要目的是保护用户隐私和数据安全。在面向隐私保护的分布式机器学习系统中,有多个参与方且每一方都拥有一些训练数据。因此,需要使用分布式机器学习技术来利用每个参与方的训练数据,从而协同地训练机器学习模型。
对于隐私保护的分布式机器学习系统,它通常能保护下列的信息:训练数据输入、预测标签输出、模型信息(包括模型参数、结构和损失函数)和身份识别信息(如记录的数据来源站点、出处或拥有者)等。
在面向隐私的分布式机器学习中,常用的用于保护数据隐私的方法大概分为以下两个类别:
模糊处理。随机化、添加噪声或修改数据使其拥有某一级别的隐私,如差分隐私方法。密码学方法。通过不将输入值传给其他参与方的方式或者不以明文方式传输,使分布式计算过程安全化,如安全多方计算(MPC),包括不经意传输、秘密共享、混淆电路和同态加密。
分布式机器学习平台
Apache Spark MLlib数据处理系统:https://spark.apache.org/mllib/微软发布的DML工具包(Distributed ML Toolkit,DMTK):http://www.dmtk.ioTensorFlow通过tf.distribute支持DNN的分布式训练:https://www.tensorflow.org/guide/distributed_trainingPyTorch中的分布式包(即torch.distributed):https://pytorch.org/tutorials/intermediate/dist_tuto.html联邦学习架构
C-S架构
在此场景中,协调方是一台聚合服务器(也称为参数服务器),可以将初始模型发送给各参与方A~C。参与方A~C分别使用各自的数据集训练该模型,并将模型权重更新发送到聚合服务器。之后,聚合服务器将从参与方处接收到的模型更新聚合起来并将聚合后的模型更新发回给参与方。这一过程将会重复进行,直至模型收敛、达到最大迭代次数或者达到最长训练时间。
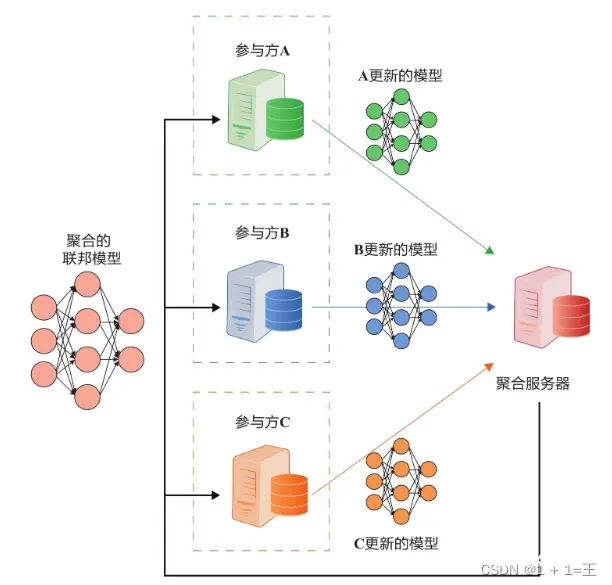
在这种体系结构下,参与方的原始数据永远不会离开自己。这种方法不仅保护了用户的隐私和数据安全,还减少了发送原始数据所带来的通信开销。此外,聚合服务器和参与方还能使用加密方法来防止模型信息泄露。
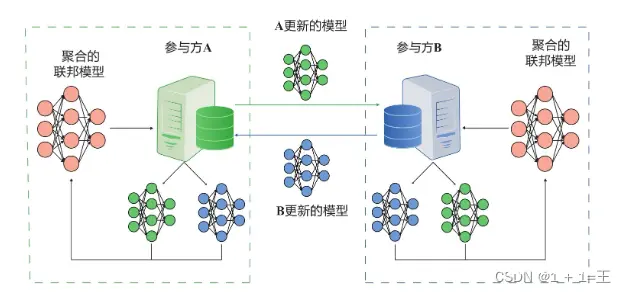
P2P对等网络架构
在对等网络架构中,不需要第三方服务器的存在,各个参与方直接通信且通过加密解密的方式来保证隐私安全
参考文献:
[1] 杨强,刘洋等. 联邦学习(Federated Learning). 电子工业出版社.

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。