Linly-Dubbing,一键视频多语言AI配音,视频翻译,字幕生成,人声分离,自动下载视频(WIN/MAC)
CSDN 2024-09-30 16:01:04 阅读 98
今天分享一个视频多语言AI配音的项目——Linly-Dubbing。该项目作者提供一键处理视频的功能,你只需要填入视频链接,就可以得到该视频翻译后并添加字幕的视频。
该项目的部署过程中确实遇到了一些问题,踩了很多坑。除了提供整合包之外,我还为那些打算自行部署的朋友们准备了部署过程中出现的问题的解决方案。
Linly-Dubbing,一键视频多语言AI配音,视频翻译,字幕生成,人声分离,自动下载视频(WIN/MAC)
项目介绍
Linly-Dubbing是一个智能视频多语言AI配音和翻译工具,该项目在YouDub-webui的基础上进行拓展和优化。
Linly-Dubbing 在多语言配音的自然性和准确性方面达到了新的高度,适用于国际教育、全球娱乐内容本地化等多种场景,帮助团队将优质内容传播到全球各地。
如何使用
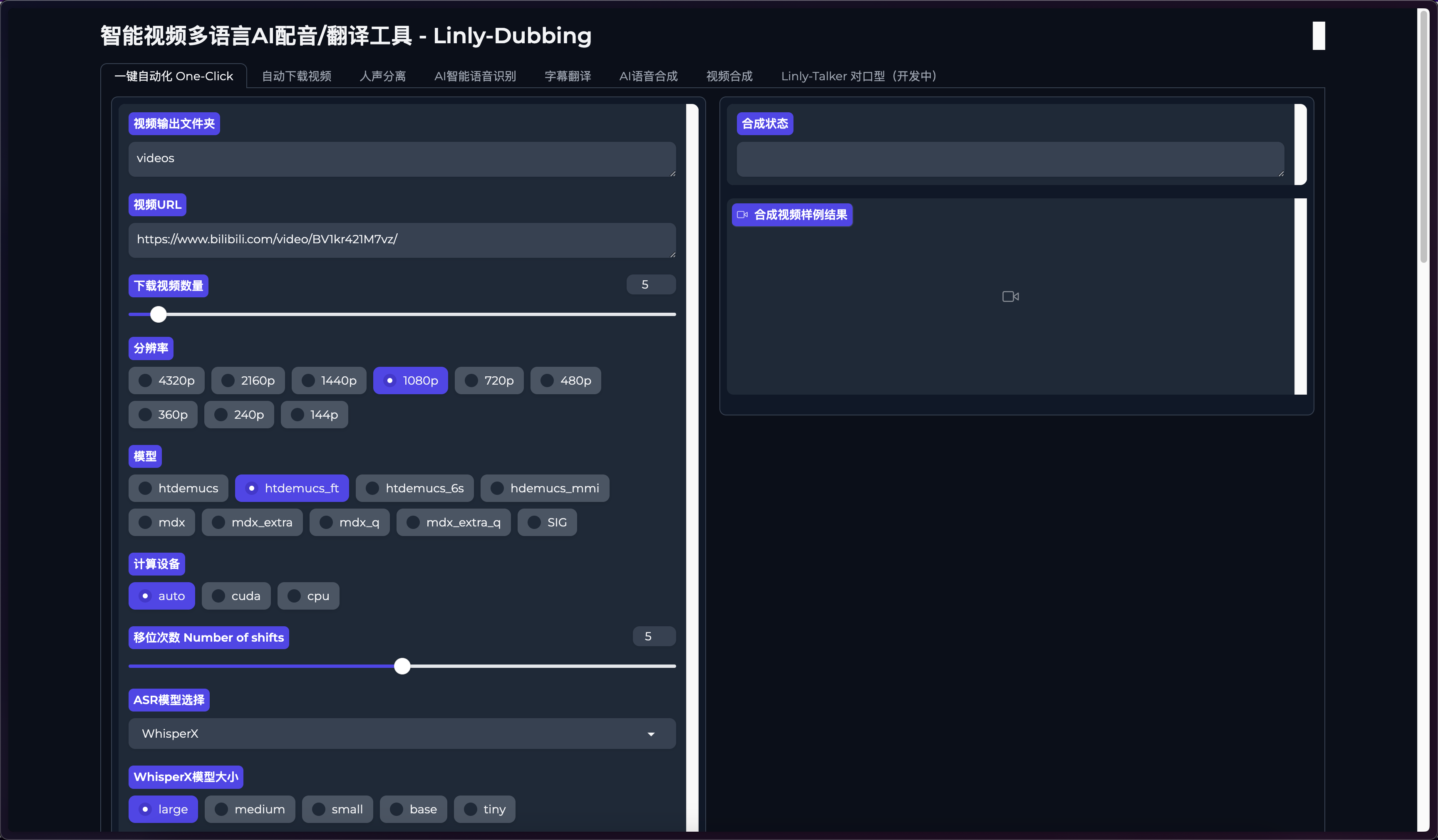
使用很简单,首先来到<code>一键自动化这里。
视频下载
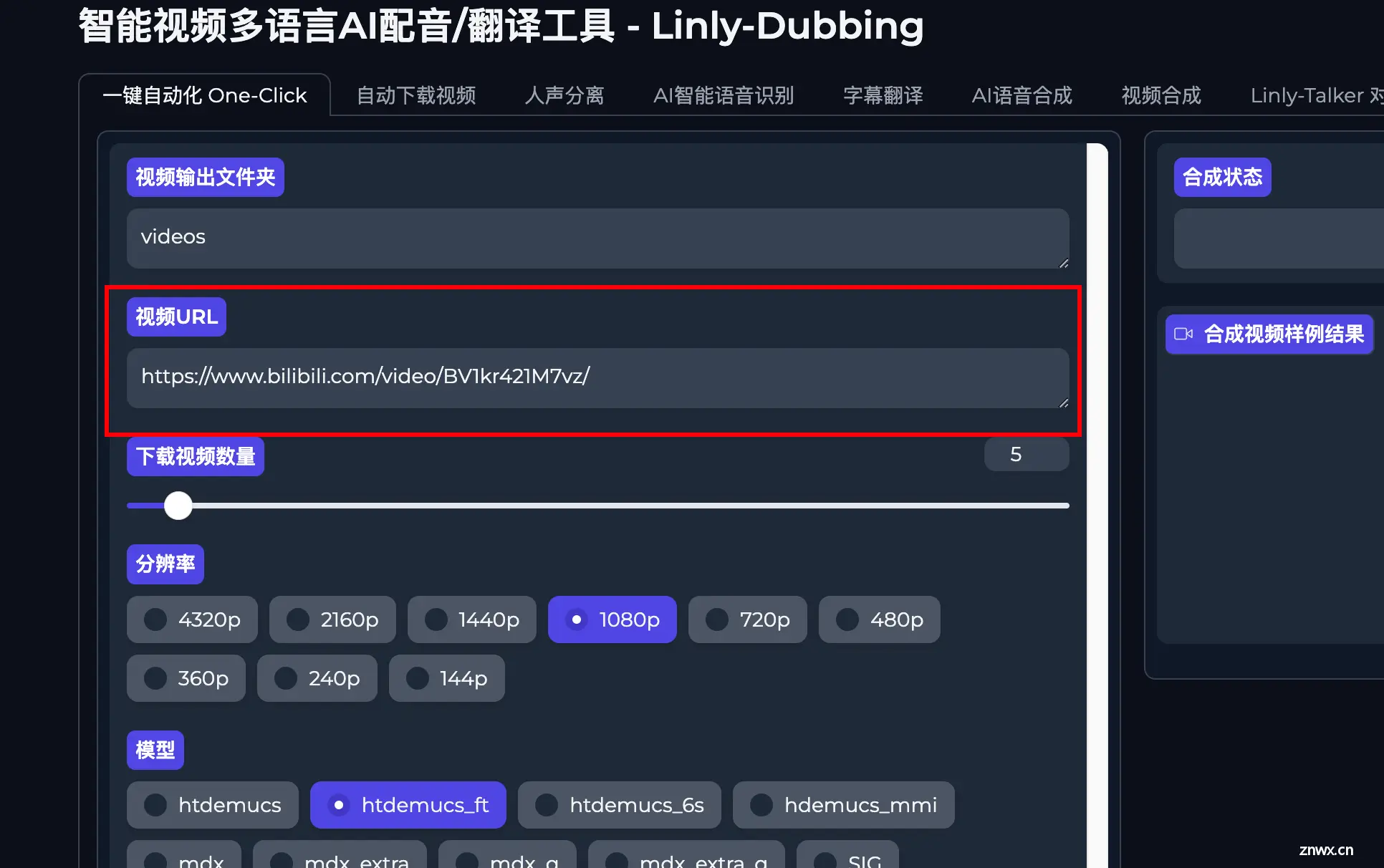
输入你想要处理的视频URL。
该项目视频下载使用的是yt-dlp项目,支持数千个网站下载,具体支持哪些网站可以点击下方链接进行查看。
📢需注意的是下载国外的网站视频时需开启对应的网络环境。
https://github.com/yt-dlp/yt-dlp/blob/master/supportedsites.md
然后分辨率这里根据你原视频选择,如果原视频没4K的,你选4K也没有用。或者保持默认也可以。
人声分离
这里选择对应的人声分离模型,不同的模型处理的效率和质量也不一样。
语音识别ASR
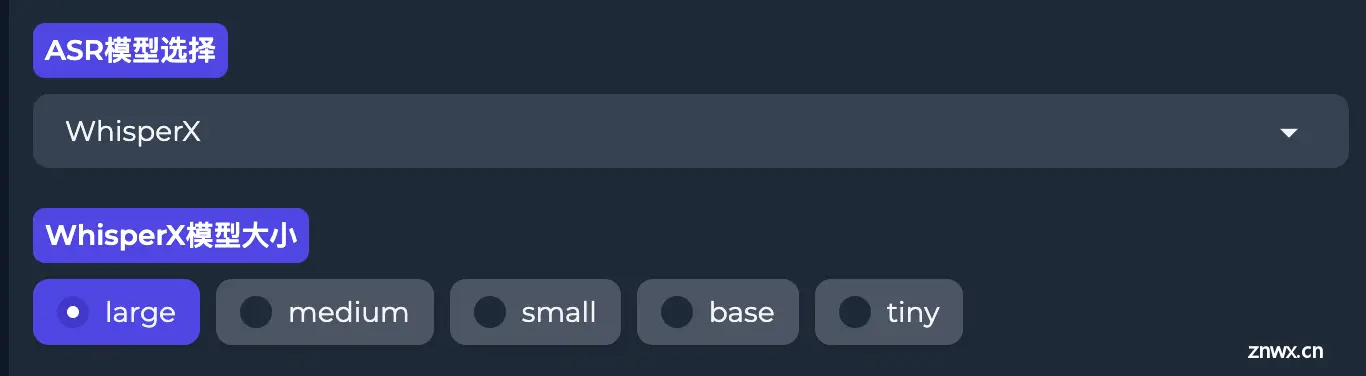
这部分用来识别视频中的声音生成对应的文本。
ASR模型有两个选择:
WhisperX
WhisperX 是一个基于OpenAI开源项目Whisper的语音识别工具,具备单词级时间戳和说话者辨识功能,支持高效准确的语音转文本。
FunASR
FunASR 是由阿里巴巴集团的达摩院开发的一个端到端的语音识别工具包,旨在连接学术研究和工业应用。支持语音识别(ASR)、语音活动检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。

如果选择WhisperX的话需要选择模型大小。配置较低的话可以选择<code>tiny
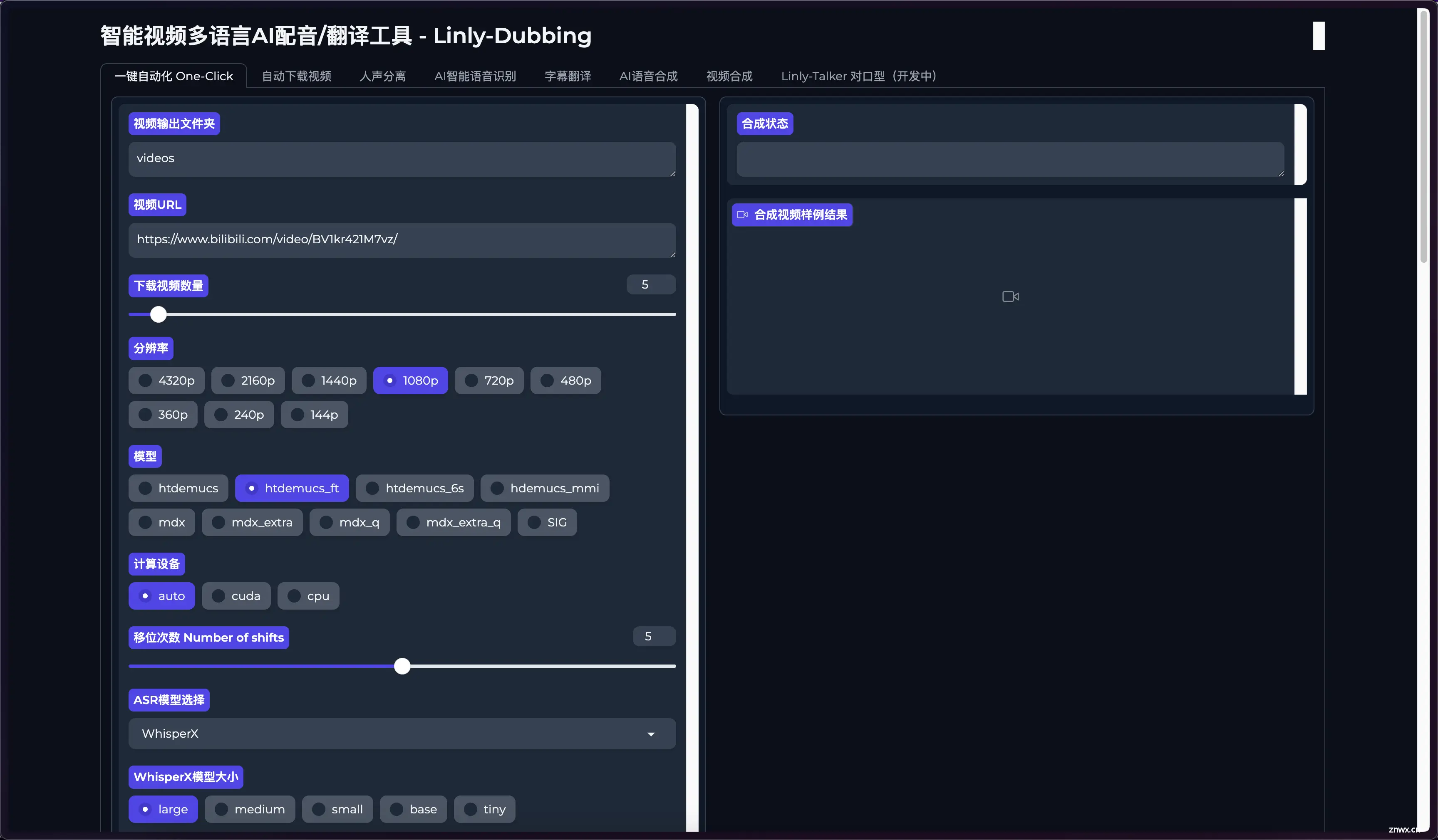
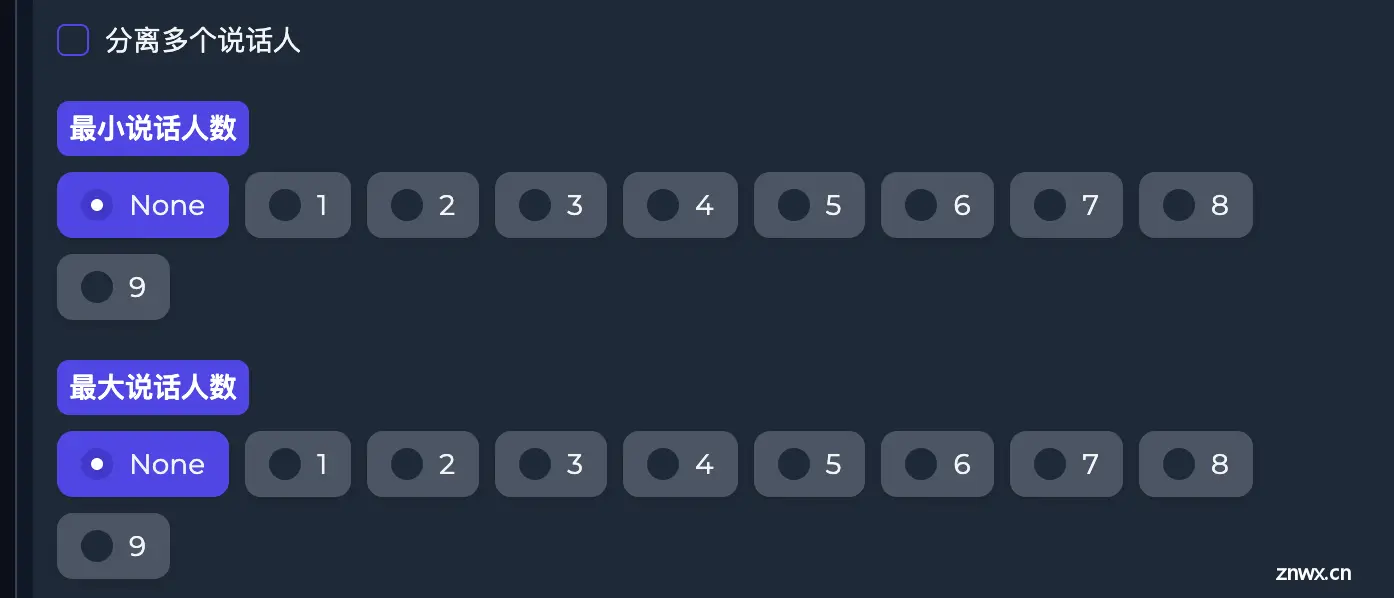
如果你视频中只有一个人说话,取消勾选<code>分离多个说话人选项。如果是多个,则需要指定最小说话人数和最大说话人数。
字幕翻译
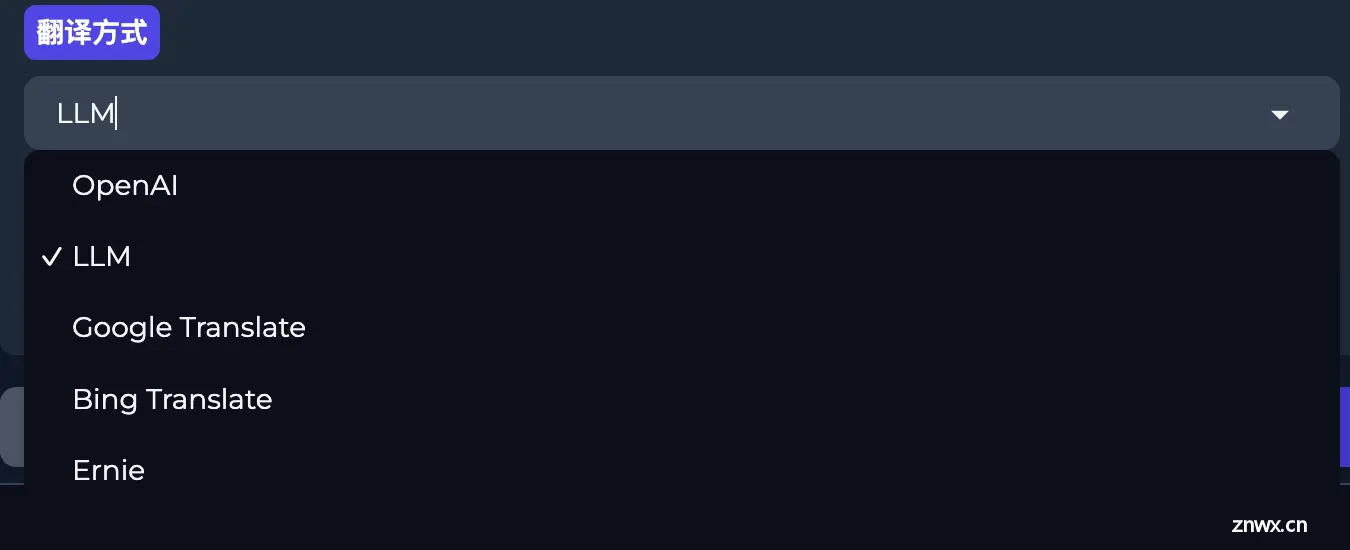
设置翻译的方式和最后翻译的语言。

翻译方式有5种。默认是LLM(本地大模型进行翻译)。
OpenAI
使用gpt模型进行翻译。
使用该选项时需要到项目根目录下的<code>.env文件设置OPENAI_API_KEY
LLM
使用Qwen1.5-4B-Chat模型
Google Translate
谷歌翻译
Bing Translate
Bing翻译
ERNIE
ERNIE(Enhanced Representation through kNowledge IntEgration)是由百度提出的一系列预训练语言模型,旨在通过整合知识图谱等多源丰富知识来增强文本表示的效果。ERNIE模型在自然语言处理(NLP)领域取得了显著的成果,特别是在中文语料的处理上。
使用该选项时需要到项目根目录下的.env文件设置BAIDU_API_KEY
📢注意注意,坑来了!
如果你选择的是<code>LLM选项,可能会遇到这个问题:总结失败

这是由于该项目使用4B的模型,有时候这个大模型能力不足导致的。
怎么解决?
重新再点击生成,多尝试几次就可以。(亲测,刚开始我以为是我环境配置的问题,结果同样的设置,重新点击生成后又成功了)换个翻译方式,别死磕本地LLM,换个<code>OpenAI的,很稳定。如果你既没有openAI的网络环境,还想要稳定的话,直接选Google Translate或Bing Translate。直接翻译完事。
目标语言选择你最后要翻译的结果语言。

语音合成
将翻译好的文本内容合成对应的语音。
语音生成方法有三种:
xtts
XTTS(eXtended Text-to-Speech)是一个先进的文本转语音(TTS)模型,它能够通过一个简短的6秒音频剪辑克隆不同语言的语音。
CosyVoice
CosyVoice 是阿里巴巴通义实验室开源的多语言、多情感声音克隆模型,专注于自然语音生成,支持多语言、音色和情感控制。
EdgeTTS
微软 Microsoft Edge 的在线文本转语音服务
目标语言跟上面保持一致。如果你选择的是EdgeTTS,可以在<code>EdgeTTS声音选择选择对应的声音。

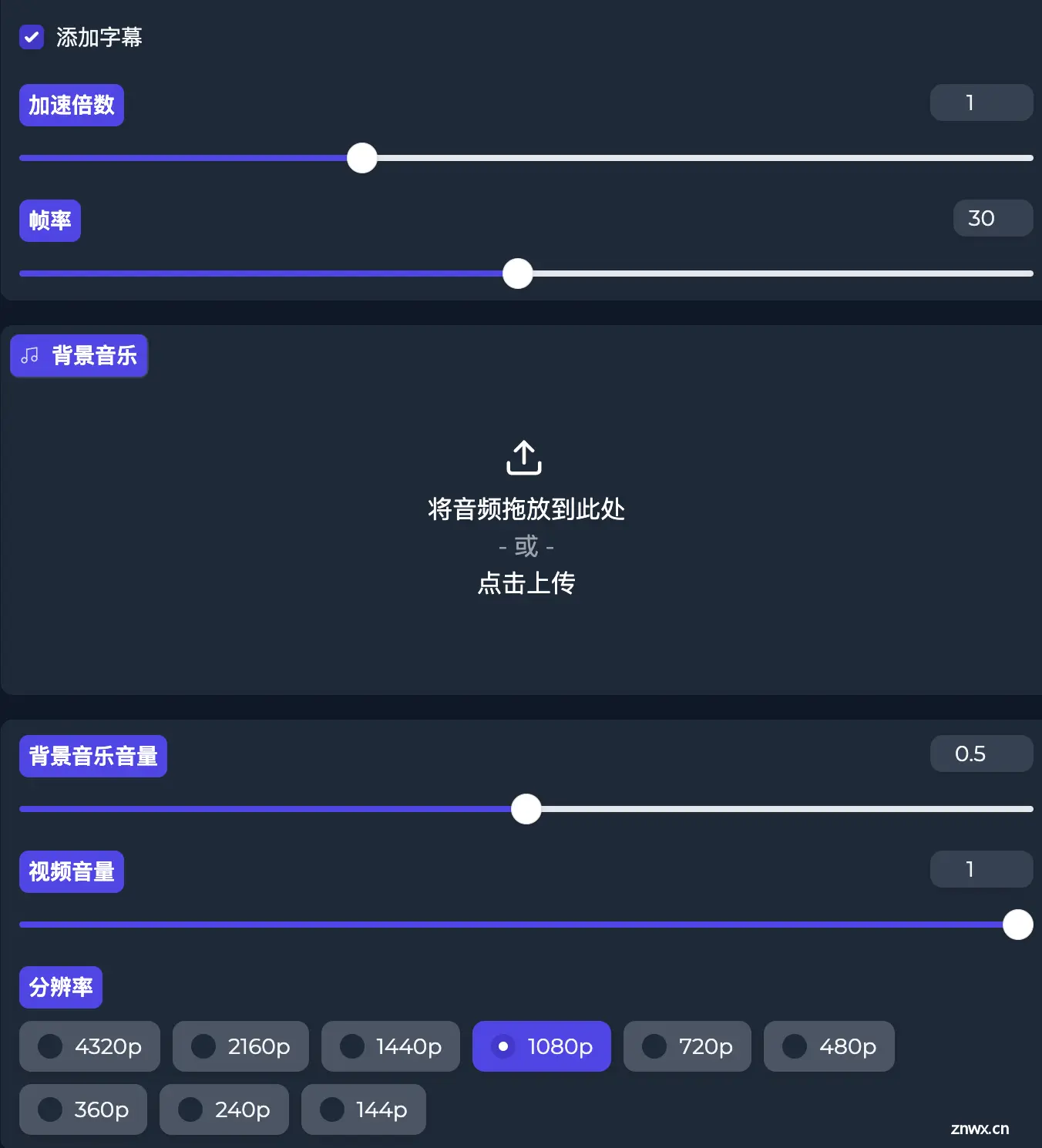
视频合成
对最后输出的视频进行设置。根据自己的需要选择即可。
合成
最后点击<code>Submit等待视频处理。

本地部署的问题
如果你只使用整合包可以直接忽略这部分,这部分是给想自己本地部署的小伙伴们一个参考。
问题一
Model has been downloaded but the SHA256 checksum does not not match. Please retry loading the model.
报错说模型SHA256 校验和不匹配。怀疑下载过程中文件损坏,重新下载了,还是报错。
解决方法
Windows
<code>C:/Users/XXX/.cache/torch/whisperx-vad-segmentation.bin
MAC
/Users/xxxx/.cache/torch/whisperx-vad-segmentation.bin
whisperx和Torch的BUG,目录下的.bin文件删除。解决。
问题二
Library cublas64_12.dll is not found or cannot be loaded
安装的torch版本问题。
我之前安装的版本是
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu118
重新安装cuda12.1版本的torch就可以。
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu121
问题三
cosyvoice.utils.common.ras_sampling
使用cosyvoice遇到的问题。
cosyvoice模型的问题,这个是由于cosyvoice模型部分添加了一个采样器,但 GitHub 上开源的代码中没有包含该采样器。
解决方法
打开项目目录下的models/TTS/CosyVoice-300M/cosyvoice.yaml文件
屏蔽这段代码,解决。
# sampling: !name:cosyvoice.utils.common.ras_sampling
# top_p: 0.8
# top_k: 25
# win_size: 10
# tau_r: 0.1
问题四
unknown format: 3
使用cosyvoice遇到的问题。
修改tools/step040_tts.py文件中的adjust_audio_length函数。
def adjust_audio_length(method,wav_path, desired_length, sample_rate = 24000, min_speed_factor = 0.6, max_speed_factor = 1.1):
if method == 'cosyvoice':
try:
data, sr = sf.read(wav_path)
temp_wav_path = wav_path.rsplit('.', 1)[0] + '_temp.wav'
sf.write(temp_wav_path, data, sr, subtype='PCM_16')code>
except Exception as e:
print(f"Error preprocessing audio: {e}")
return None, None
else:
temp_wav_path=wav_path
try:
wav, sample_rate = librosa.load(temp_wav_path, sr=sample_rate)
except Exception as e:
if temp_wav_path.endswith('.wav'):
temp_wav_path = temp_wav_path.replace('.wav', '.mp3')
wav, sample_rate = librosa.load(temp_wav_path, sr=sample_rate)
current_length = len(wav)/sample_rate
speed_factor = max(
min(desired_length / current_length, max_speed_factor), min_speed_factor)
logger.info(f"Speed Factor {speed_factor}")
desired_length = current_length * speed_factor
if temp_wav_path.endswith('.wav'):
target_path = temp_wav_path.replace('.wav', f'_adjusted.wav')
elif temp_wav_path.endswith('.mp3'):
target_path = temp_wav_path.replace('.mp3', f'_adjusted.wav')
stretch_audio(temp_wav_path, target_path, ratio=speed_factor, sample_rate=sample_rate)
wav, sample_rate = librosa.load(target_path, sr=sample_rate)
return wav[:int(desired_length*sample_rate)], desired_length
修改tools/step040_tts.py116行
wav, length = adjust_audio_length(method,output_path, end-start)
问题五
生成的视频有水印问题。
修改tools/step050_synthesize_video.py文件
def synthesize_all_video_under_folder(folder, subtitles=True, speed_up=1.00, fps=30, background_music=None, bgm_volume=0.5, video_volume=1.0, resolution='1080p', watermark_path='docs/linly_watermark.png'):code>
watermark_path = None if not os.path.exists(watermark_path) else watermark_path
output_video = None
for root, dirs, files in os.walk(folder):
if 'download.mp4' in files:
output_video = synthesize_video(root, subtitles=subtitles,
speed_up=speed_up, fps=fps, resolution=resolution,
background_music=background_music,
watermark_path=None, bgm_volume=bgm_volume, video_volume=video_volume)
# if 'download.mp4' in files and 'video.mp4' not in files:
# output_video = synthesize_video(root, subtitles=subtitles,
# speed_up=speed_up, fps=fps, resolution=resolution,
# background_music=background_music,
# watermark_path=watermark_path, bgm_volume=bgm_volume, video_volume=video_volume)
# elif 'video.mp4' in files:
# output_video = os.path.join(root, 'video.mp4')
# logger.info(f'Video already synthesized in {folder}')
return f'Synthesized all videos under {folder}', output_video
以上就是我部署过程中遇到的问题。希望可以帮到大家。
整合包获取
👇🏻👇🏻👇🏻下方下方下方👇🏻👇🏻👇🏻
关注公众号,发送【LinlyDubbing】关键字获取整合包。
如果发了关键词没回复你!记得看下复制的时候是不是把空格给粘贴进去了!
Linly-Dubbing,一键视频多语言AI配音,视频翻译,字幕生成,人声分离,自动下载视频(WIN/MAC)
制作不易,如果本文对您有帮助,还请点个免费的赞或在看!感谢您的阅读!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。