超分AI模型学习
tiger119 2024-09-30 15:31:04 阅读 55
概述
超分(超分辨率:Super Resolution,SR):是计算机视觉和图像处理领域的一个热门话题。主要是将低分辨率图像恢复出高分辨率图像。可以采用的方法和手段很多,最近项目中有涉及(红外成像的超分处理),将碰到的一些零散的知识整理了一下,记录一下。
技术手段:
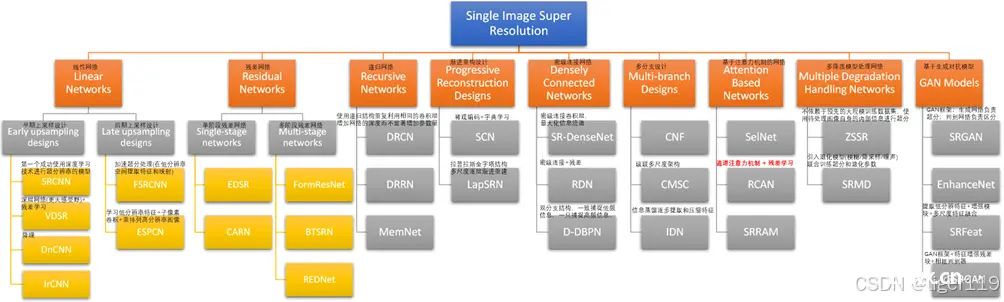
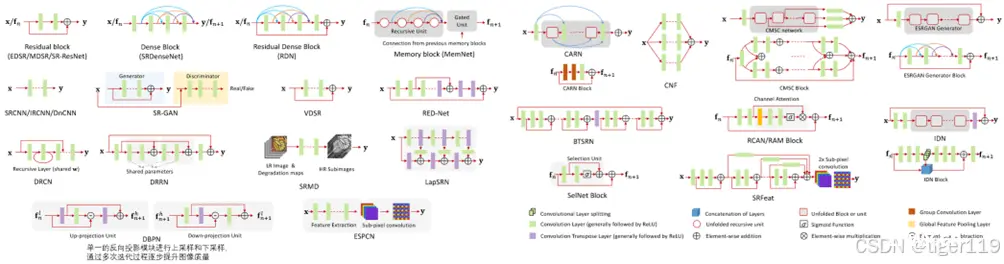
基于插值的超分辨率:
最早的超分技术,包括双线性插值,双三次插值等方法。这种方法比较快速,但通常无法恢复出细节,重建的图细节不丰富。这是一种纯算法的做法,比较传统。
基于重建的超分辨率:
这是通过解决逆问题来重建高分辨率图像。使用的是信号处理技术,如最小二乘法,正则化法。尝试从多个低分辨率图像中恢复分辨率图像,考虑了退化过程中的模糊和嗓声。注意:这针对的是多张图片。如果是单张,需要有模型假设(如:假定图像平滑),或者先验知识(如:利用有人脸的固有特征)。
基于学习的超分辨率:
机器学习的方法,基于已有图像的训练,学习复杂的特征。
基于生成对抗网络(GAN)的超分辨率:
GAN由一个生成器和一个判别器组成,生成器负责生成高分辨率图像,判别器则判断图像的真实性。这种方法可以生成具有高感知质量的图像,尤其擅长恢复细节和纹理。
基于视频的超分辨率:
专注于从低分辨率视频序列中恢复高分辨率视频。不仅考虑单个图像的信息,还利用时间维度上连续帧之间的信息,来提高重建质量。
技术阶段:
基于深度学习的超分辨率技术发展可以概括为以下几个阶段:
初期阶段(2014年前后):
深度学习在超分辨率领域的应用始于2014年,当时最著名的方法是SRCNN(Super-Resolution Convolutional Neural Network)。SRCNN开创性地使用了三层卷积网络来学习从低分辨率到高分辨率图像的非线性映射,显著提高了超分辨率的性能。
深层网络时代(2015-2017年):
在SRCNN之后,研究者开始探索更深的网络结构以提高超分辨率的效果,例如VDSR(Very Deep Super-Resolution)使用了20层网络,展示了深层网络在性能上的优势。EDSR(Enhanced Deep Super-Resolution)进一步改进了网络设计,移除了不必要的模块,提高了训练的稳定性和效果。
注意力机制与GAN的融合(2017年后):
引入了注意力机制来提高模型的性能,如RCAN(Residual Channel Attention Network)通过在通道维度上引入注意力机制,有效地提升了图像细节的恢复。GAN在超分辨率中的应用也变得流行,SRGAN(Super-Resolution Generative Adversarial Network)和后续的ESRGAN(Enhanced SRGAN)通过对抗训练生成更加逼真的高分辨率图像。
实时与轻量化网络(2018年至今):
随着实时应用的需求增加,研究者开始关注于开发既快速又高效的超分辨率模型,如FSRCNN(Fast Super-Resolution Convolutional Neural Network)和Real-Time SR网络。这些模型通常设计得更加轻量化,以便在资源受限的设备上运行,同时保持良好的重建质量。
多尺度与多任务学习(近年发展):
为了进一步提高超分辨率技术的适应性和效率,最新的研究开始探索多尺度和多任务学习策略。例如,通过同时进行超分辨率和其他图像处理任务(如去噪、色彩校正等),可以提高网络的通用性和性能。
上面的技术路线,其实说明了超分技术一些发展方向。首先会向轻量级设备上应用,另外,比较提倡多技术的融合处理。
评估指标:
PSNR:峰值信噪比
这里的重点是,MSE是如何计算的?

较高的PSNR,表示重建的图像与原始图像更接近,质量更好,一般来说,PSNR值大于30db就表示质量较好。当然,实际情况,我们还要结合其它指标(如:结构相似信)来综合判断,见下。
另外,对于细节和纹理恢复方面,可能并不能反映人类视觉对图像质量的感知。
SSIM:结构相似性指数

它不但考虑了结构相似,还有亮度和对比度。
这个计算相对是比较复杂的。
MSE(均方误差):
MSE是衡量两幅图像之间差异的一种方法,它计算了每个像素点之间的平均差的平方。MSE越小表示重建图像与原始图像越接近,但它并未考虑人眼感知的差异,所以在图像质量评估中常与PSNR或SSIM一起使用。上面有详细介绍,它往往是PSNR的一个子计算。
LPIPS(Learned Perceptual Image Patch Similarity):
LPIPS是一种基于深度学习的图像质量评估指标,旨在更好地模拟人类视觉系统对图像差异的感知能力。与传统的像素级或结构相似性指标(如PSNR、SSIM)不同,LPIPS利用深度神经网络学习从图像中提取特征,并计算这些特征之间的距离来衡量图像之间的感知差异。
SSIM-MS (Multi-Scale Structural Similarity Index):
SIM-MS是对结构相似性指数(SSIM)的扩展,它考虑了多尺度的结构噪息,更全面地评估图像之间的相似性。与标准的SSIM相比,SSIM-MS在计算过程中引入了多个尺度的噪息。它通过对图像进行多次降采样和卷积操作,得到不同尺度下的结构相似性指数,最终综合考虑了更广泛的图像特征,更适合于对复杂场景下的图像质量评估。
PSNR-HVS(Peak Signal-to-Noise Ratio – Human Visual System):
PSNR-HVS是一种改进的PSNR指标,考虑了人类视觉系统对于亮度、对比度和颜色变化的敏感度。与传统PSNR不同,PSNR-HVS使用了更精确的模型来估计人类视觉系统的感知能力,因此更能反映出人类真实感知中的差异。它可以更准确地预测在视觉上的图像质量变化。
我们可以提前看一下一些通用数据集和常见算法的测量指标。对于PSNR,超过30就算是一个比较高的指标。

常见的超分模型
整理一下常见的超分模型:
| 模型名称
| S
| Params
(M)
| Multi-Adds
(G)
| Set5
(PSNR/
SSIM)
| Set14
(PSNR/
SSIM)
| BSD200 (PSNR/
SSIM)
| Publish
|
| SRCNN | 第一个端到端学习的超分辨率模型,简单高效,3层卷积网络。结构简单。效果有限。 | ||||||
|
| 2
| 0.057
| 52.7/18.7G
| 36.66/
0.9542
| 32.45/
0.9067
| 30.29/
0.8977
| 2014
|
| FSRCNN | 比SRCNN更快的,改进的SRCNN,适合于实时应用。8层卷积网络。 | ||||||
|
| 2
| 0.012
| 6/4.08G
| 37.000/0.9558
| 32.63/0.9088
| 31.8/0.9074
| 2016
|
| DRRN | 深度递归残差网络,深层的特征提取。性能好,但计算量很大。 | ||||||
|
| 2
| 0.297
| 6796
| 37.66/0.9589
| 33.19/0.9133
| 32.01/0.8969
| 2017
|
| CARN-M | 级联的残差网络,用于手机的版本。高效,适用于受限设备。在超高分辨率上效果有限 | ||||||
|
| 2
| 0.412
| 91.2
|
|
|
| 2018
|
| FALSR-B | 多层卷积,反卷积网络,通过搜索。快速,精准,轻量。需要复杂的NAS过程。 | ||||||
|
| 2
| 0.326
| 74.7
|
|
|
| 2019
|
| BSRN-S | 综合不同层级的卷积网络。通过特征融合提高分辨率效果,模型较复杂,运算量大。 | ||||||
|
| 2
| 0.33
| 102.48
|
|
|
| 2022
|
| LESRCNN | RCNN的轻量级版本。适用于移动设备,效果不如原型型好。 | ||||||
|
|
| 0.516
| 3.08
|
|
|
| 2020
|
| PAN | 包含像素注意力机制的卷积网络。可捕捉细节,但计算复杂度高。 | ||||||
|
| 2
| 0.261
| 100
|
|
|
| 2020
|
| ESPCN | 使用子像素卷积提升分辨率。速度快,适合实时场景。 | ||||||
|
| 2
| 0.02
| 6.94
|
|
|
| 2016
|
| DRCN | 深度递归卷积网络。训练复杂,计算资源要求高。 | ||||||
|
|
|
|
|
|
|
| 2016
|
| LapSRN | 使用拉普拉斯金字塔结构进行多尺度超分辨率。适合于高分辨率 | ||||||
|
| 2
| 0.251/1.31
| 4357.08
|
|
|
| 2017
|
| ECBSR-M4C8 | M4C8, 等变体,表示不同层数和通道数。 | ||||||
|
| 2
| 0.06
| 3.73
|
|
|
| 2021(无权重)
|
| ECBSR-M4C16 | M4C16 | ||||||
|
| 2
| 0.21
| 13.45
|
|
|
| 2021
|
| ECBSR-M10C16 | M10C16, | ||||||
|
| 2
| 0.48
| 30.41
|
|
|
| 2021
|
| ECBSR-M10C32 | M10C32 | ||||||
|
| 2
| 1.82
| 117.39
|
|
|
| 2021
|
| MOREMNAS-C | 通过神经架构搜索优化的超分辨率网络。自动化搜索,计算成本高 | ||||||
|
| 2
| 0.025
| 5.5
|
|
|
| 2019(无模型)
|
| TPSR | |||||||
| 2 | 0.06 | 19.86 | 2020 | ||||
| TPSR-NoGAN | 不使用GAN的变换预测超分辨率模型。无需GAN,运算少。 | ||||||
|
| 2
| 0.06
| 19.86
|
|
|
| 2020
|
| IMDN-RTC | 使用信息多重蒸馏技术的超分模型。效果好,性能优。但模型复杂,训练时间长 | ||||||
|
| 2
| 0.7
| 17.9
|
|
|
| 2019
|
| RepRFN | 使用代表性特征提取技术。计算复杂度高 | ||||||
|
| 2
| 0.402
| 22.1
|
|
|
| 2023
|
| MDRN | |||||||
| 2 | 0.30 | 91G | 2023 | ||||
| TelunXupt(MDRN) | 使用多尺度残差网络的超分模型。计算复杂度高。 | ||||||
|
| 2
| 0.3
| 90.9
|
|
|
| 2023
|
| SwinIR | Swin Transformer for Image Restoration,利用Swin Transformer的层次化特征表示能力,捕捉图像的多尺度信息。在多个图像恢复任务上表现出色,如图像超分辨率、降噪和去模糊。计算量较大,性能好。 | ||||||
| 0.87 | 295G | 2021 | |||||
| PSRGAN | 基于ResNet的生成器网络,带有跳跃连接和上采样模块,对图像细节和纹理的恢复效果显著,适用于对视觉质量要求高的应用。训练成本较高, | ||||||
| 0.31 | 174.3G | 2021 | |||||
| IRSRMamba | 深度卷积神经网络(DCNN),通常包含多层卷积和反卷积层。 多层卷积结构能够有效提取图像的层次化特征。图像质量好:通过深度学习方法,生成的高分辨率图像质量较高,细节恢复较好。
| ||||||
| 72 | 2024 | ||||||
| SwinIR-BSRGAN (GAN) | 结合SwinIR的层次化特征表示和BSRGAN的GAN框架,提供多尺度信息捕捉和高视觉质量。提供高视觉质量的图像,特别是在细节和纹理恢复上效果显著。 | ||||||
| 11.6M | 3891G | 2021 | |||||
| BSRGAN | 生成对抗网络(GAN),强大的抗噪能力和退化处理能力 | ||||||
| 16.66M | 5529G | 2021 | |||||
| SinIR | 基于卷积神经网络(CNN),多层卷积和反卷积网络,强调特征提取和图像细节恢复 | ||||||
| 4 | 456MB | 2021 | |||||
| Real-ESRGAN(mamba) | 生成对抗网络(GAN),基于残差网络,提供高视觉质量的图像,特别是在细节和纹理恢复上效果好。 | ||||||
| 16.69M | 5874G | 2021 | |||||
| ESRGAN | 增强的超分GAN。生成图像在细节和纹理上效果优异 | ||||||
| 2 | 16.7M | 5874G | 2018 | ||||
| SRGAN | 基于ResNet的网络,GAN网络,提升了图像的视觉质量和细节恢复 | ||||||
| 2 | 1.4M | 475.63G | 2017 | ||||
| DiVANet | 深度卷积神经网络(DCNN),多层卷积和反卷积网络,高效的特征提取和细节恢复能力 | ||||||
| 2 | 0.939M | 57G | 2022 | ||||
| CAMixerSR-S | 卷积神经网络(CNN),通道注意力机制 | ||||||
| 0.351M | 2024 | ||||||
| ELAN | 轻量级卷积神经网络(CNN),通道注意力机制 | ||||||
| 0.601M | 43.2G | 2022 | |||||
| RCAN | |||||||
| 0.08 | 20G | 2018 | |||||
在上面模型中,SwinIR(BSRGAN)、BSRGAN、SinIR以及Real-ESRGAN模型效果不错,
还有一些和超分相关的融合模型:(不仅仅是处理超分)
DPIR:图像去嗓,去模糊,超分处理。
USRNet:图像去模糊,超分处理。恢复图像细节和结构。
DnCNN:利用残差学习去噪。
FFDNet:图像去噪。采用可变变的降噪强度参数。
SRMD:通过深度卷积网络解决多种退化条件下的超分辨率的问题,通过联合训练模型,提升图像细节恢复能力。
DPSR:结合Plug-and-Play框架和深度学习模型,用于超分任务。通过交替优化图像和先验模型,实现高质量的图像放大。
BSRGAN:采取对抗训练机制,重建超分。
SwinIR:利用Transformer模型强大的建模能力。处理图像去噪,超分,去模糊的任务。
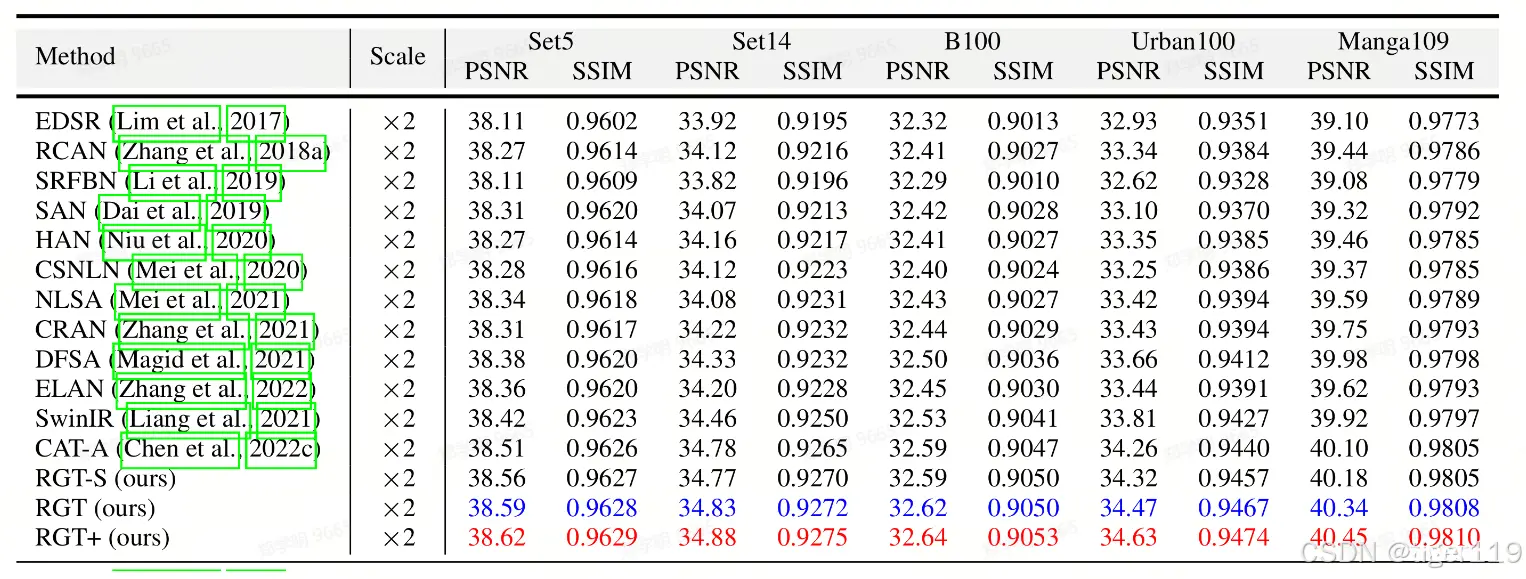
详解:超分模型RCAN
RCAN:Residual Channel Attention Network。
RCAN引入了通道注意力机制,在残差学习的基础上通过关注更重要的特征通道来提高性能。通道注意力机制使得模型能够更有效地利用特征,提升了超分辨率的精度和视觉质量。
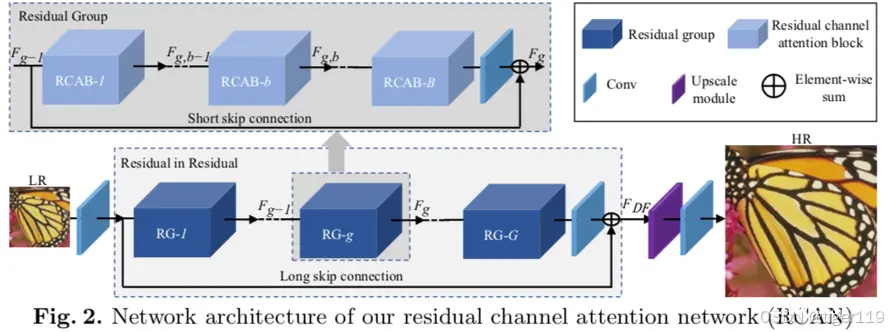
如上图:输入为LR,输出为HR。
1:初始卷积,提取特征。
2:多个残差组。每个残差组包括多个残差注意力块(RCAB-i)
3:在每个RCAB内部通过Short skip connction(短跳跃连接),将特征直接传递到残差块末端,增强梯度流动。
4:在整个残差组的输入,输出之间,有一个Long skip connection(长跳跃连接),使得输入特征直接传递到最后的特征融合阶段,进一步增强梯度流动。
5:特征融合上采样——残差输出通过卷积进行融合,特征相加,上采样处理。
RCAN 通过残差学习和通道注意力机制,逐步增强图像特征,实现高质量的图像超分辨率。短跳跃连接和长跳跃连接的结合,确保了深层网络的有效训练和稳定性。
拆出网络结构,可以看出,相对比较简单:(下图是部分网络结构)。
输入:1*3*320*640。 3通道 320 *640 的图像
可以看到 Add层,就是残差连接,帮助梯度更好的传递,解决可能的梯度消失问题。
在推理阶段,我们将注意力机制去掉,得到的模型很少,参数约 80K。
| Model
| Image Size
| MACs
| Parameters
|
| RCAN
| 1*3*360*640
| 20.135G
| 80.603K
|
残差网络流程
我们来看进一步看一下残差,自注意力机制的应用:
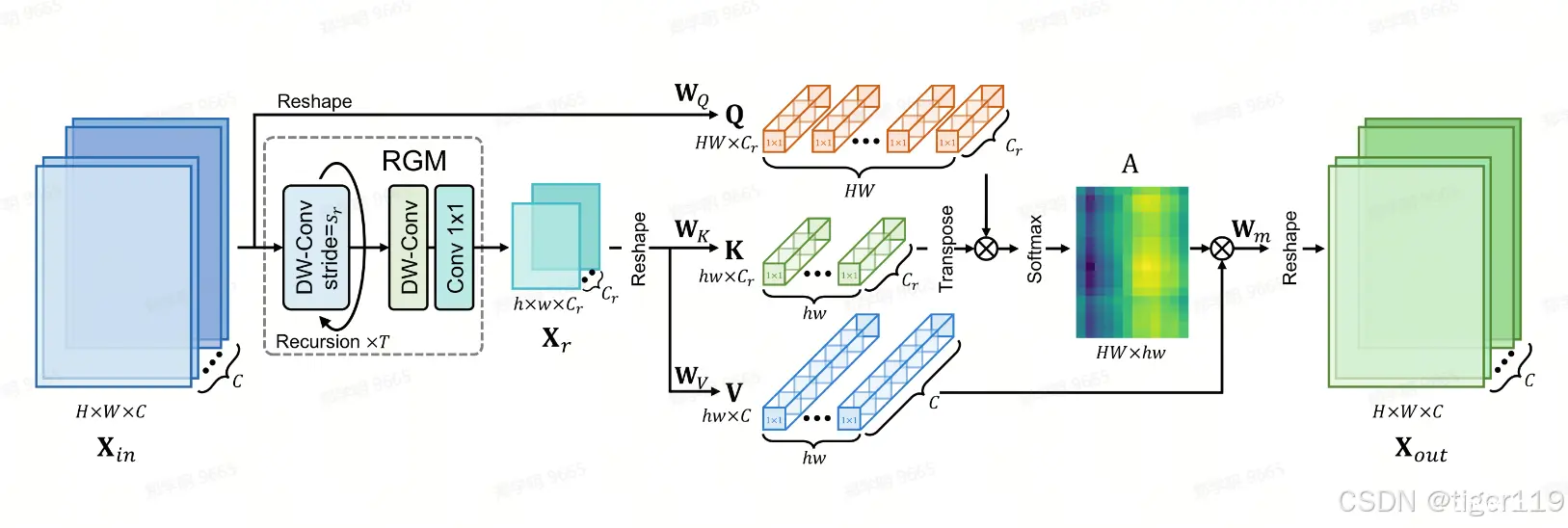
处理过程:
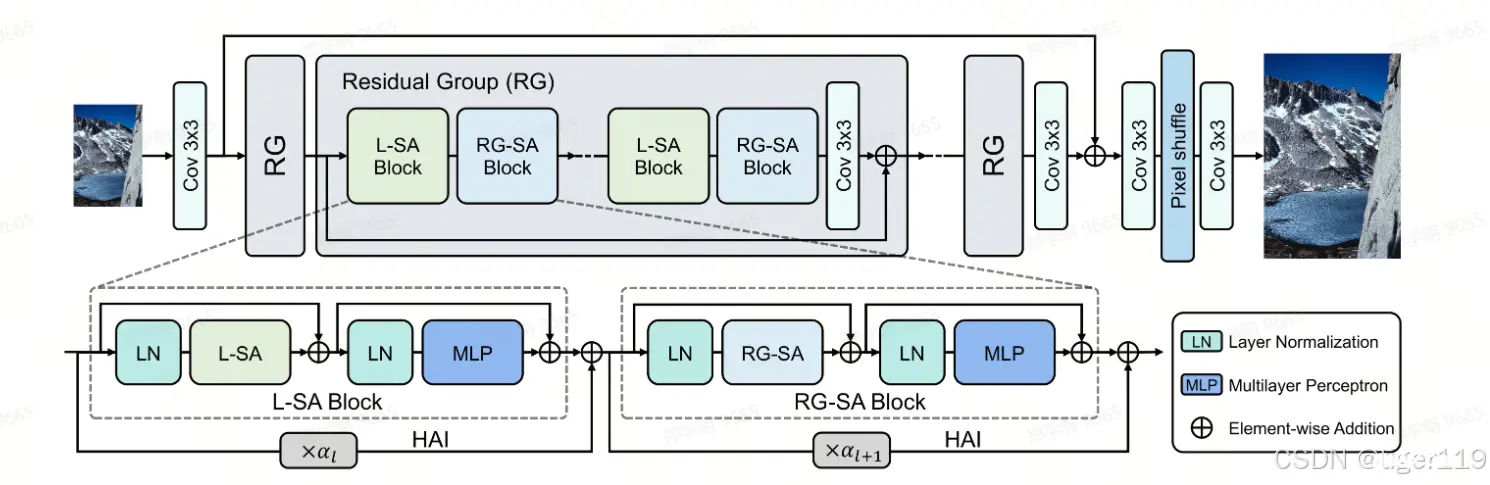
输入图像通过初始卷积层,生成初始特征。初始特征通过多个残差组进行处理,每个残差组内部包含多个L-SA Block和RG-SA Block。处理后的特征通过最终的卷积层和像素重排模块,生成高分辨率图像。
该网络通过多层次的残差组和高级注意力模块,逐步增强输入图像的特征,最终生成高分辨率图像。使用局部和全局自注意力机制,有效捕捉图像中的重要特征和全局信息,提升超分辨率效果。
注意力机制

递归泛化自注意力(RG-SA)机制。首先,通过递归泛化模块(RGM),RG-SA生成具有固定尺寸(h×w)的代表性特征图。接着,输入特征与代表性特征图之间进行交叉注意力操作,以捕获全局信息。符号⊗表示矩阵乘法。
训练数据集:
1:艾睿光电
对于训练数据,拿红外成像的数据为例,可以使用 艾睿光电的数据集。

建立一个高分辨率多场景真实世界红外图像超分数据库,提供高质量的真实世界数据,使研究人员能够评估和比较不同超分算法的性能,并开发新的、更准确的算法。该数据库包含海景图像、动物图像、工业场景、城市景观、自然景观、室内图像、人像、监控视角、车载视角图像等九类场景的共计7224张图像,分为测试集726张,训练集6498张,均为单通道图像以bmp格式保存。
红外图像超分辨率数据库
数据集的使用,先对数据进行处理,对开源的数据集中的图像HR,做双三次下采样bicubic downsampling ,得到低分辨率图像LR。作为训练数据的输入数据集。
去噪后再超分,效果会更好。
2:顶级红外数据集
https://universe.roboflow.com/browse/infrared
任务:目标检测、分类、实例分割、语义分割
3:Resul-C 红外测试数据集
results-C Dataset | Papers With Code
results-C数据集是由22张红外图像组成的数据集,常用于测试红外图像超分辨率模型的性能。
针对红外超分,数据集名称:results-A(22张) results-c(22张)
使用该数据集的红外超分模型:PSRGAN、IRSRMamba
训练:
有一个开源项目:KAIR:GitHub - cszn/KAIR: Image Restoration Toolbox (PyTorch). Training and testing codes for DPIR, USRNet, DnCNN, FFDNet, SRMD, DPSR, BSRGAN, SwinIR
KAIR (Kernel-based AI for Image Restoration) 是一个基于 PyTorch 的开源图像修复工具箱。它提供了多种高级图像修复方法的训练和测试代码,如 DPIR、USRNet、DnCNN、FFDNet、SRMD、DPSR、BSRGAN 和 SwinIR。KAIR 支持图像去噪、超分辨率和去模糊等任务,并提供了多种预训练模型和网络架构,方便研究人员和从业者开发和评估图像修复技术。
具体训练很简单,按照开源例中的配置即可。
我们重点说一下特殊的方法:
因为我们需要推理期的小模型(用于受限设备),但又想要更好的效果,所以,尝试在小模型上添加BSRGAN的处理。具体的方法是:
1:找到BSTGAN的一个同质的算法。
2:在准备低分图时,对高分图使用BSRGAN的处理,生成低分图。
3:使用准备好的图进行训练。
所以,我们不用增加推理模型的参数量,这样可以达到更好的模型性能,但模型并未增加。
这样试验下来,好像是有不错的效果。比如:我们试用的是SwinIR-lw + BSRGAN。可以达到不错的效果。但算力需求从 SwinIR的 3900G 降到 300G。参数从11.6M 降到0.9M。
附件:
在线超分工具:
Image Upscaler Online – Increase Resolution of Image Using AI
Image Upscaler Online – AI 放大照片而不损失质量
名词解释:
双线性插值:在X,Y方向上估值,确定是否要插入值。
双三次插值:在4*4的像素范围,在X,Y方向上进行三次插值。精度高于双线性。
GAN:生成式对抗网络(Generate adversarial network)。首先它有两个神经网络,一个用于生成数据,一个用来判别数据。两者是零和游戏的关系,所以,是对抗关系。生成数据方利图生成新数据骗过判别器。判别器接收真实数据和生成数据,进行分类和反馈误磋,不断提高区分真假数据的能力。这很神奇,并不清楚设计网络的理论基础是什么。生成器不断的调整参数来生成数据,尽量做到能欺骗到判断器,输出更高的真实概率。
注意力机制:在超分领域的注意力机制,主要用于计算图中特征的关联性,关联性越高的,可能会是关注度较高的图形,需要加权重点处理。
退化模型:主要针对图像的常见的画质降低的几种原因。如:镜头失焦,传感器的噪声,JPEG图片压缩的失真。针对这些原因,会有对应的退化模型——高斯模糊,添加噪声,压缩伪影。使用这些模型,可以帮助在训练过程中学习如何恢复图像。
残差学习:顾名思义,残差(residual)是残差网络的核心元素,但这个概念却并不复杂。没有引入残差的普通网络将输入 x 映射为 H(x),训练的意义就在于使用大量训练数据来拟合出映射关系 H(x)。可残差网络独辟蹊径,它所拟合的对象并不是完整的映射 H(x),而是映射结果与输入之间的残差函数 F(x)=H(x)−x。换句话说,整个网络只需要学习输入和输出之间差异的部分,这就是残差网络的核心思想。残差网络在一定程度上解决了深度结构训练难的问题,降低了优化的难度。在深层网络中,层与层之间的乘积关系导致了梯度弥散(gradient vanishing)和梯度爆炸(gradient explosion)这些常见的问题,参数初始化不当很容易造成网络的不收敛。但残差网络有效地解决了这个问题,即使是一百层甚至是一千层的网络也可以达到收敛。
上一篇: 【大数据AI人工智能之推荐系统】基于Elasticsearch实现推荐引擎的原理与详细实现方案以及源代码详解(Java实现)【1】
下一篇: 全网最全RAG评估指南:全面解析RAG评估指标并提供代码示例
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。