AI 绘画Stable Diffusion 研究(三)sd模型种类介绍及安装使用详解
CSDN 2024-06-15 08:01:19 阅读 90
本文使用工具,作者:秋葉aaaki
免责声明:
工具免费提供 无任何盈利目的
大家好,我是风雨无阻。
今天为大家带来的是 AI 绘画Stable Diffusion 研究(三)sd模型种类介绍及安装使用详解。
目前,AI 绘画Stable Diffusion的各种模型层出不穷,这些模型都有什么作用?又该怎么安装使用?对于新手朋友来说,是非常大的困扰。
这篇文章将会为你介绍AI 绘画Stable Diffusion的模型种类、模型的安装及使用方法、以及模型的选择和下载。
不同的模型有不同的画风如:线条风格、手绘风格、立体风格、科幻风格、真人风格。
还有不同的概念,例如:人物、物体、动作等。
这些都是目前Stable Diffusion 模型众多的原因。
那么,Stable Diffusion的模型具体有哪些种类呢,都有什么作用呢?
一、Stable Diffusion的模型详解
1、模型种类
当前,常见的模型可以分为两大类:
大模型:这里的大模型特指标准的 latent-diffusion 模型,拥有完整的 TextEncoder、U-Net、VAE。
微调大模型的小模型
由于想要炼制、微调大模型非常的困难,需要比较好的显卡、比较高的算力, 因此更多的选择是去炼制小型模型。
这些小型模型通过作用在大模型的不同部分,来修改大模型,从而达到目的。
常见的用于微调大模型的小模型又分为以下几种:
Textual inversion (Embedding模型)Hypernetwork模型LoRA模型
还有一种叫做 VAE (VAE, Variational autoencoder,变分自编码器,负责将潜空间的数据转换为正常图像)的模型,通常来讲 VAE 可以看做是类似滤镜一样的东西,会影响出图的画面的色彩和某些极其微小的细节。
如图:

其实大模型本身就自带 VAE 的,但是一些融合模型的 VAE坏了 (例如:Anything-v3),有时画面发灰就是因为这个原因。所以需要外置 VAE 的覆盖来补救。
由于模型的种类不同、作用位置也不同,所以想要使用这些模型必须分清这些模型类别,并且正确的使用,模型才会生效。
2、模型的区分方法
如何区分这些模型对新手来说是一件非常困难的事情,因为他们都可以拥有一样的后缀名。
这里感谢 秋葉aaaki 提供的模型种类检测工具 ,在本地将模型文件拖入即可识别。
3、模型后缀名详解
目前,常见的 AI绘画标准模型后缀名有如下几种:
ckpt
pt
pth
这三种是 pytorch(深度学习框架)的标准模型格式,由于使用了 Pickle,会有一定的安全风险 。
safetensors:新型的模型格式 。正如同名字:safe,为了解决前面几种模型的安全风险而出现的,safetensors 格式与 pytorch 的模型可以通过工具进行任意转换,只是保存数据的方式不同,内容数据没有任何区别。
注意:safetensors模型需要 webui 更新到2022年12月底以后的版本才能用。
4、常见模型安装及使用方法
(1)、大模型安装及使用
大模型,常见格式为 ckpt,顾名思义,就是大。大小在GB级别,常见有 2G、4G、7G模型,模型大小不代表模型质量。
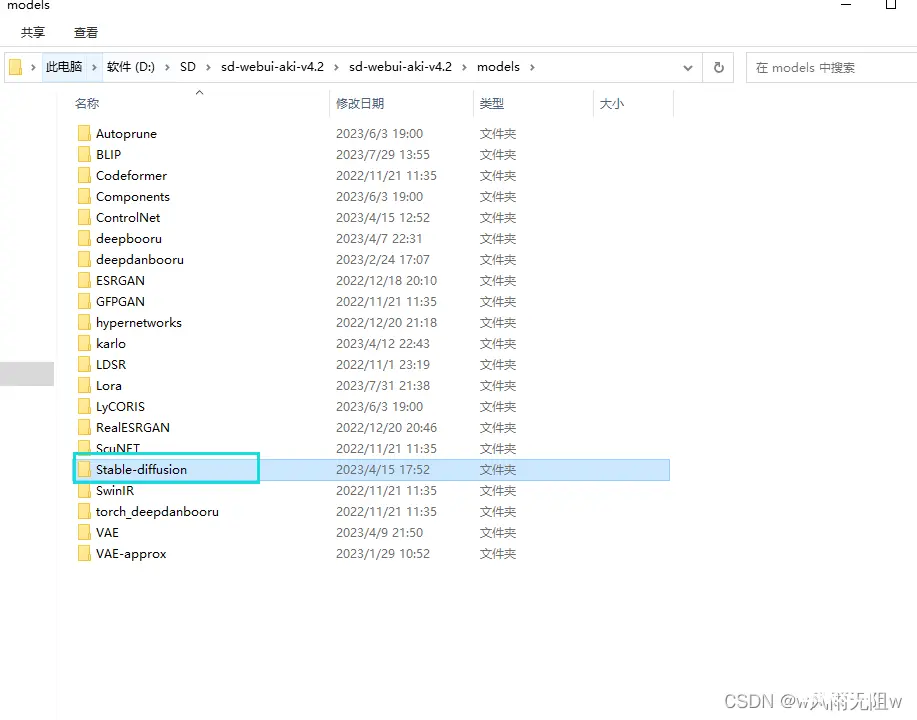
安装方法:放在Stable-diffusion文件夹内。
\sd-webui-aki-v4.2\models\Stable-diffusion
如图:
使用方法:
第一步,在 webui 左上角选择对应的模型
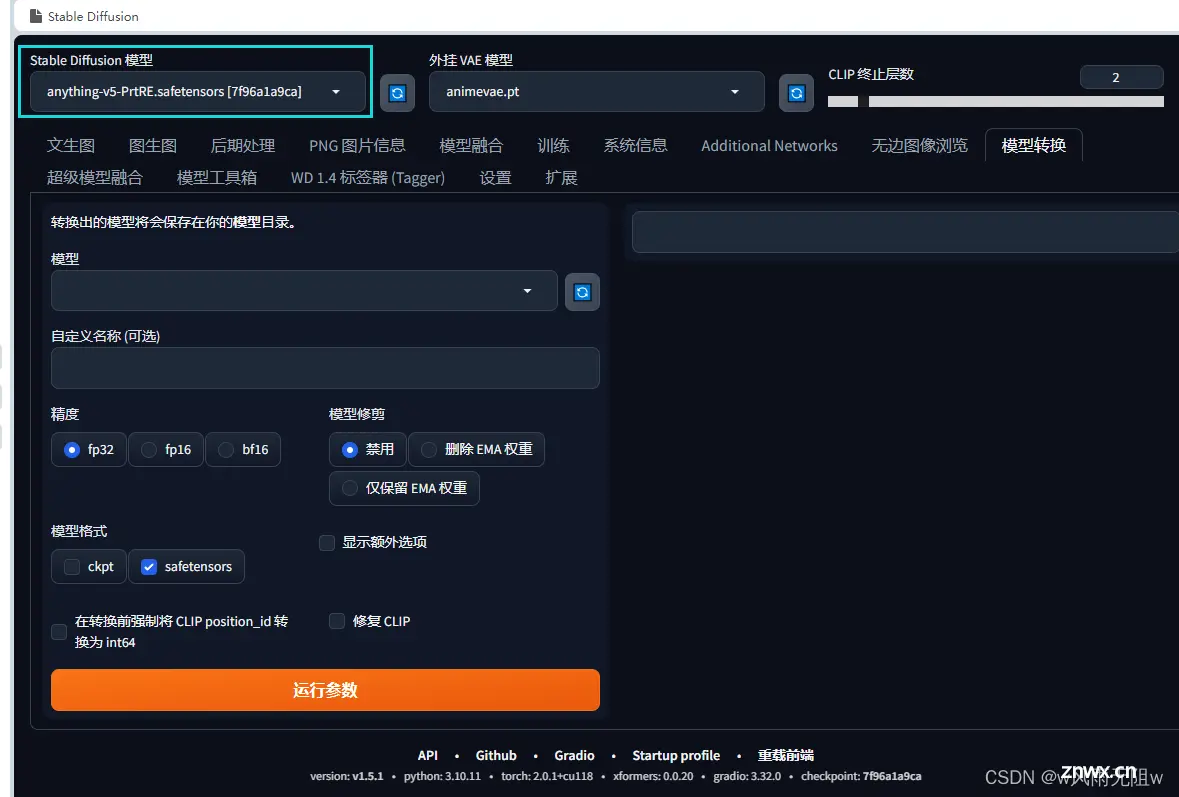
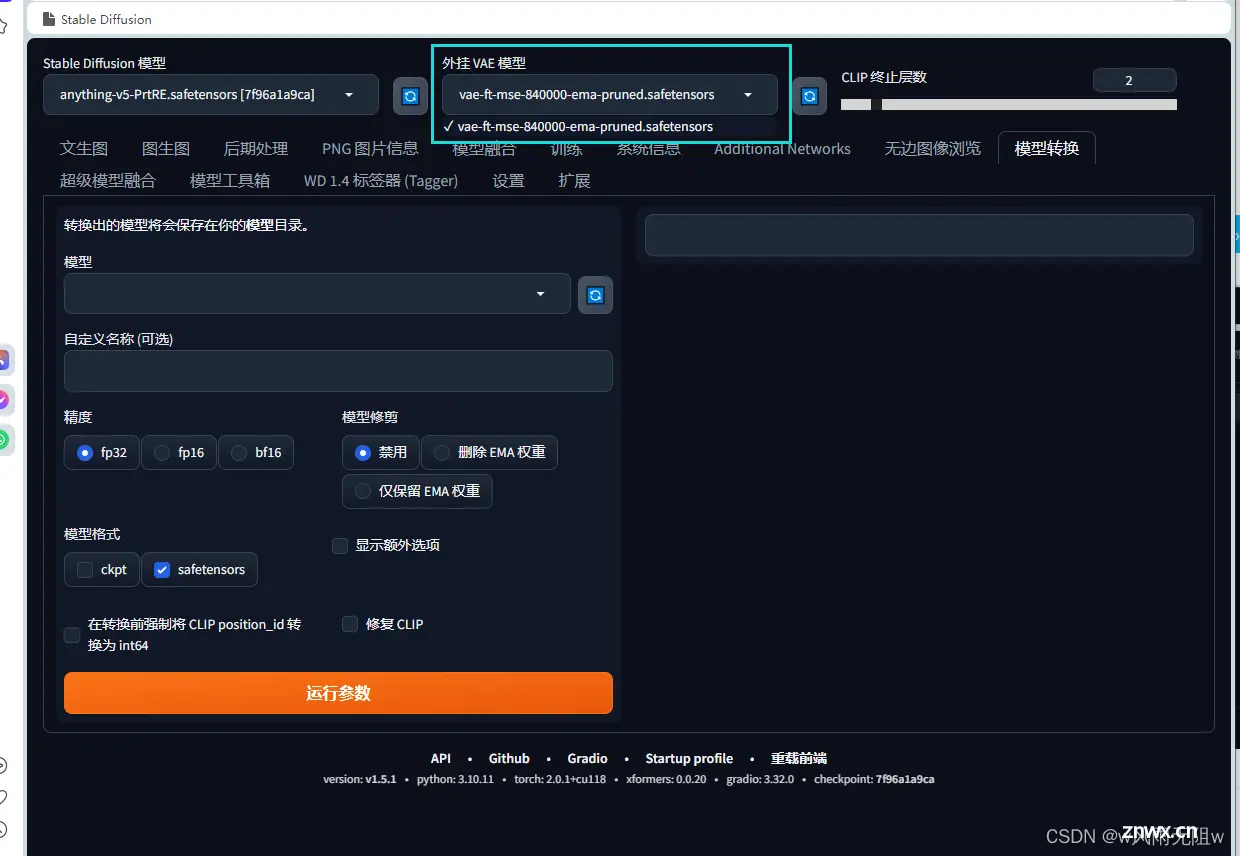
第二步,手动选择vae并应用保存
前面也说到,部分合并出来的大模型VAE烂了,画面会发灰,因此需要去设置中手动选择vae并应用保存。
(2)、Embedding (Textual inversion)模型安装及使用
embedding 模型,常见格式为 pt、png图片、webp图片,大小一般在 KB 级别。
例如:

安装方法:
放在 embeddings 这个文件夹里面
\sd-webui-aki-v4.2\embeddings
使用方法:
生成图片的时候需要带上文件名作为 tag。
例如,上面这张图里面的 shiratama_at_2-3000.pt 这个模型,使用的时候就需要带上这个tag:shiratama_at_2-3000
(3)、Hypernetwork安装及使用
常见格式为 pt,大小一般在几十兆到几百兆不等,由于这种模型可以自定义的参数非常多,也有的 Hypernetwork 模型可以达到 GB 级别。
例如:

安装方法:放在hypernetworks 文件夹内。
\sd-webui-aki-v4.2\models\hypernetworks
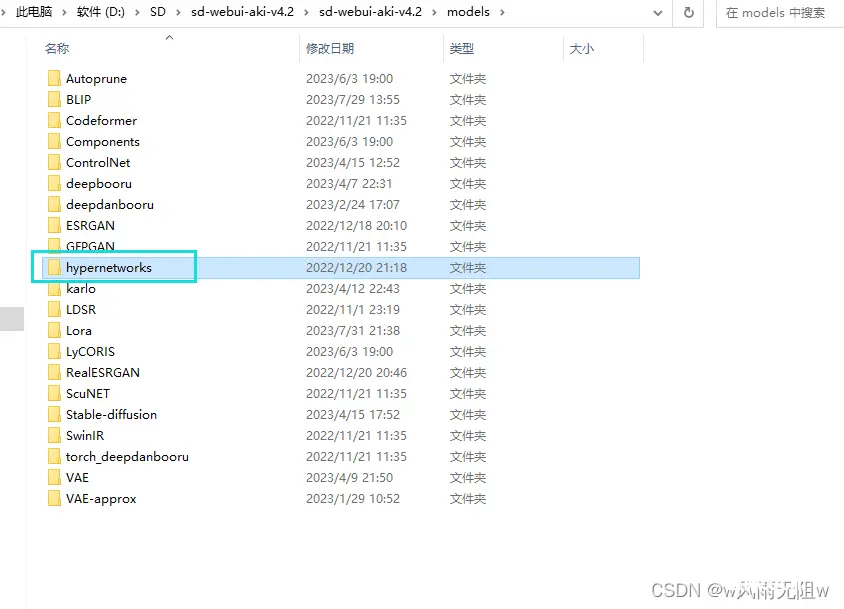
使用方法:
第一步,点击生成下方的第三个按钮
第二步,选择hypernetworks 标签页
如图所示
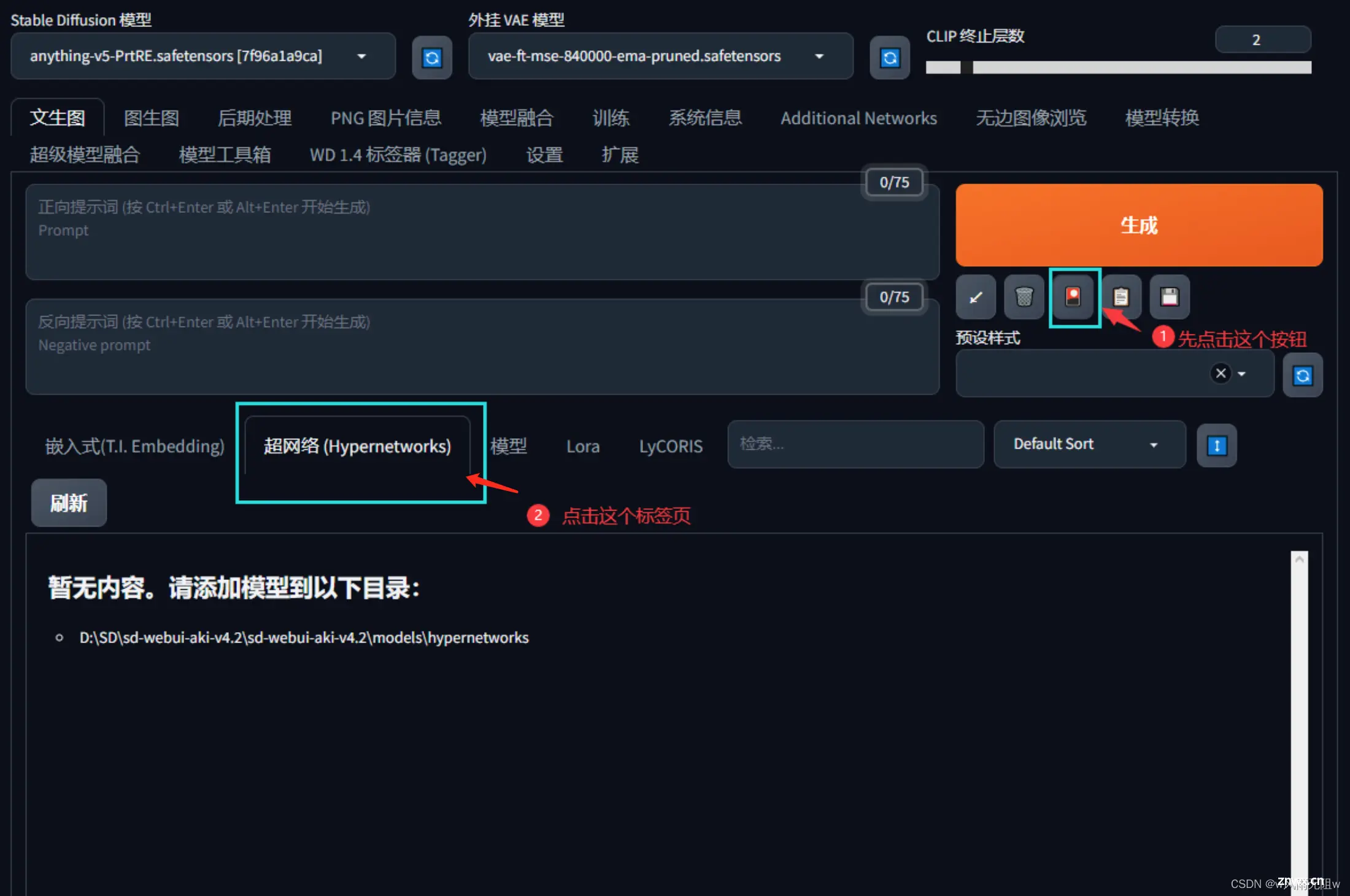
常见格式为 pt、ckpt,大小一般在8mb~144mb不等。
安装方法:模型需要放在 Lora 文件夹。
\sd-webui-aki-v4.2\models\Lora
使用方法:
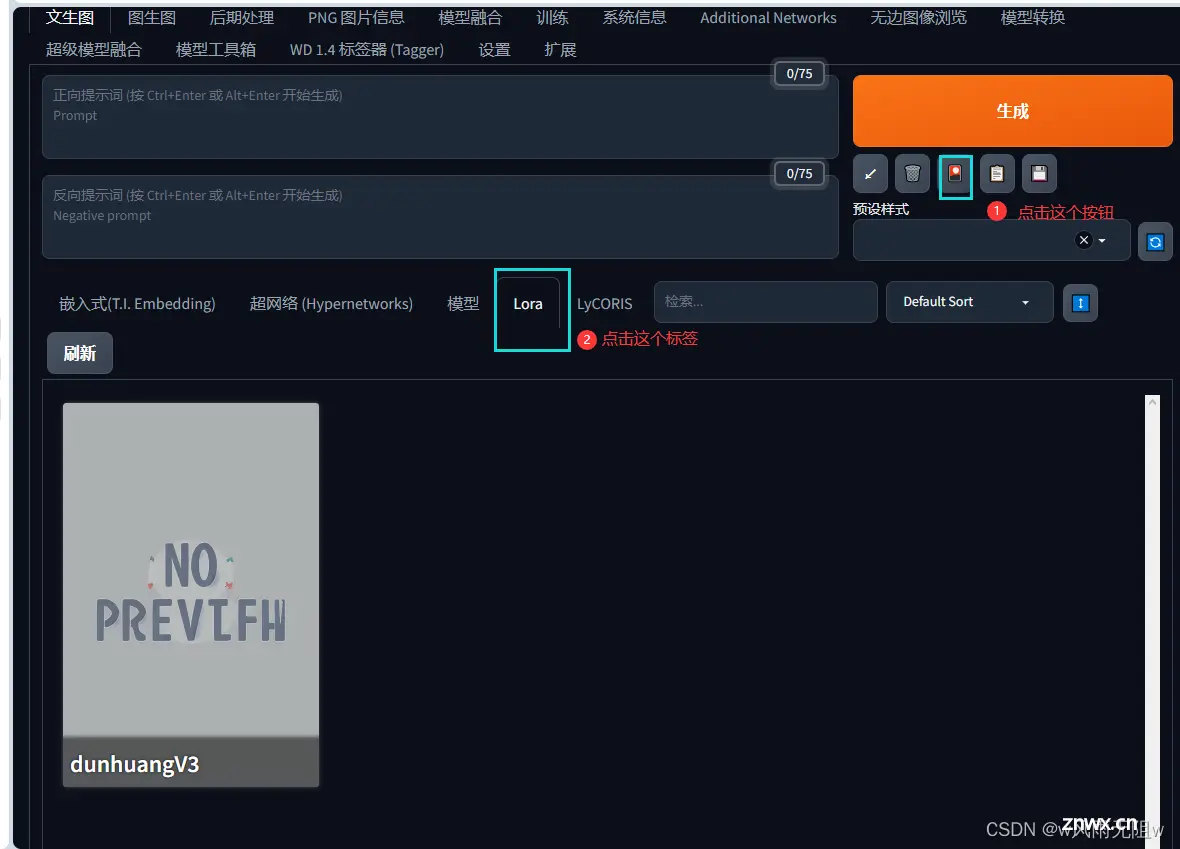
第一步,点击生成下方的第三个按钮
第二步,选择Lora 标签页
如图:
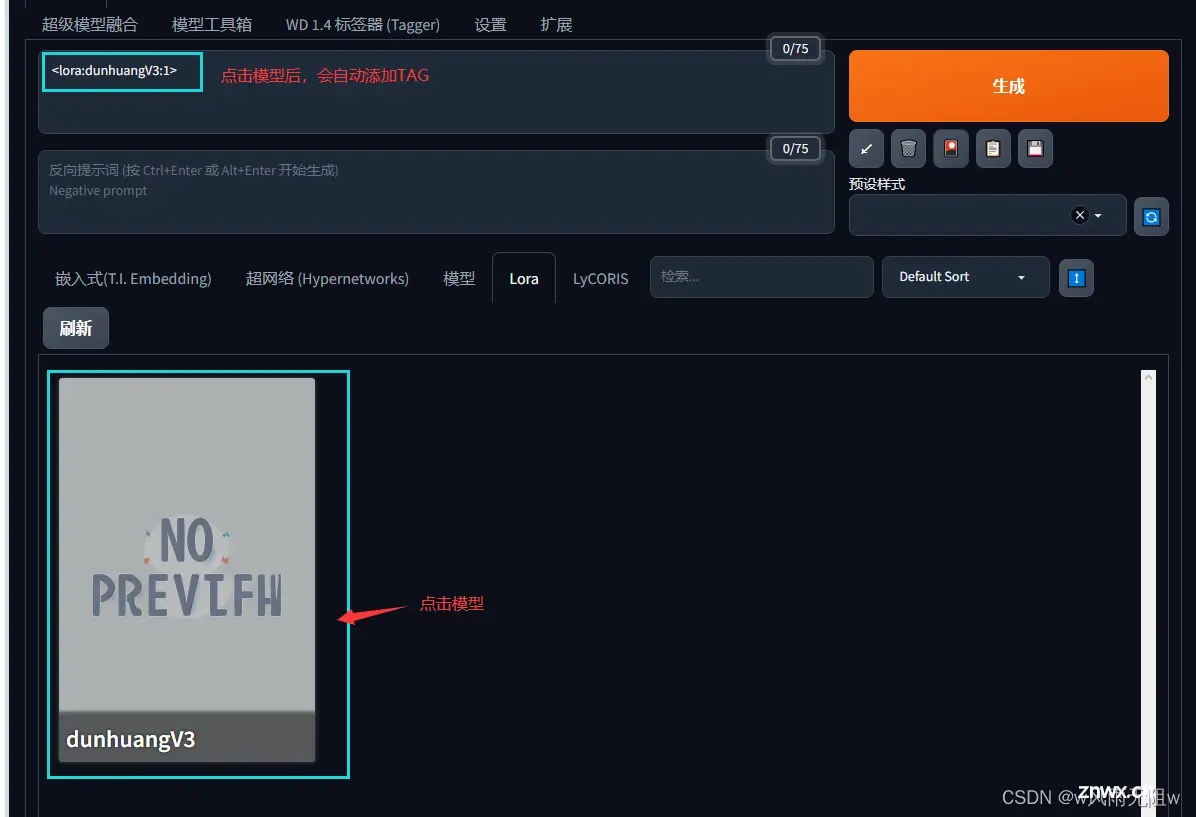
第三步,点击一个模型以后会向提示词列表添加类似这么一个tag, 也可以直接用这个tag调用lora模型。
<lora:模型名:权重>
常见格式为 .pt ,如图:
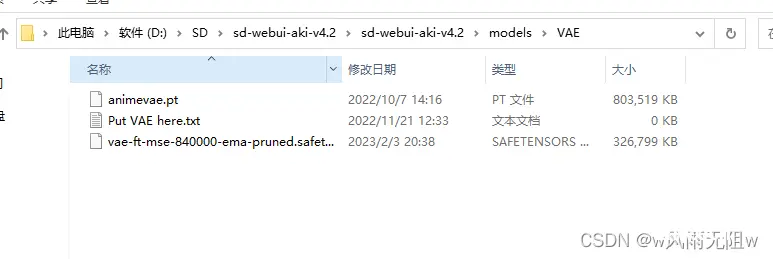
安装方法:模型需要放在 VAE 文件夹。
\sd-webui-aki-v4.2\models\VAE
模型放置完毕后,在设置页面进行如下设置,并重启。
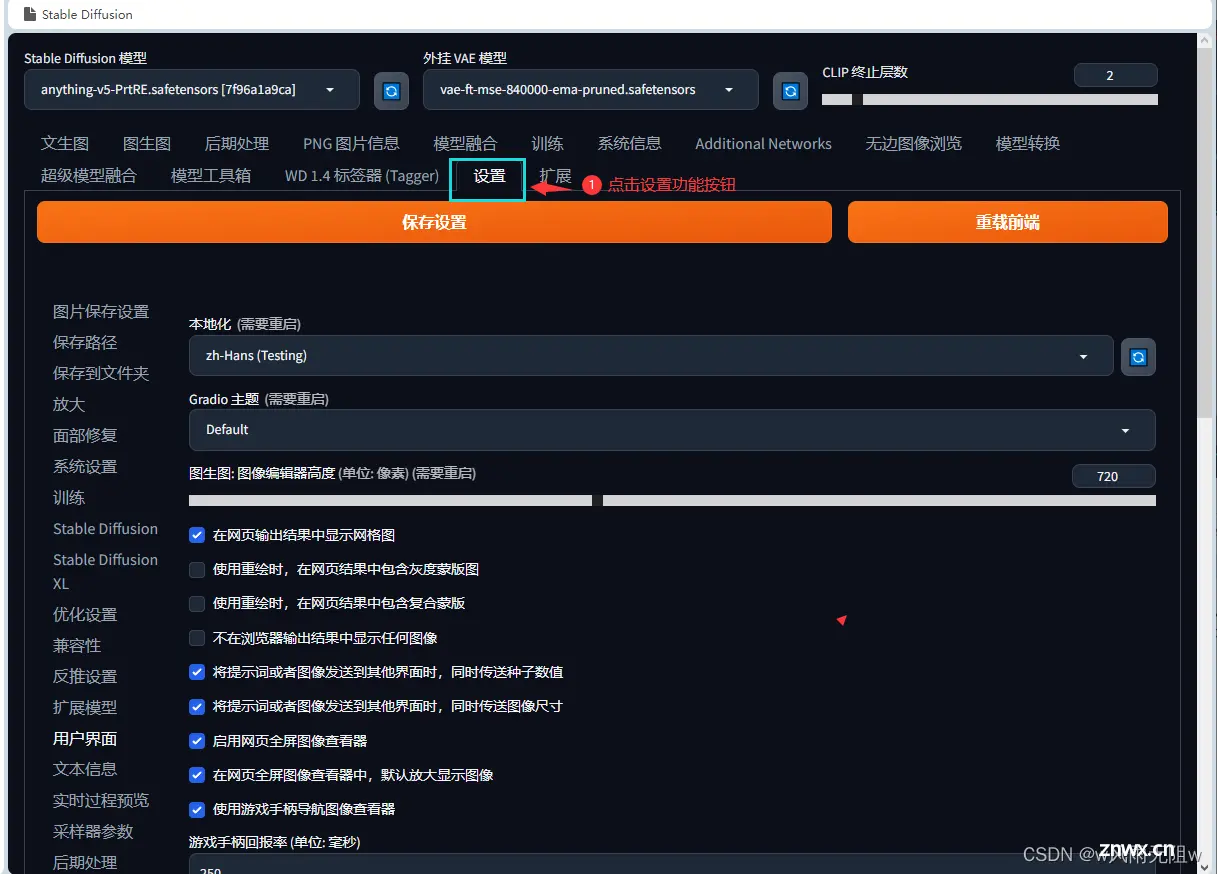
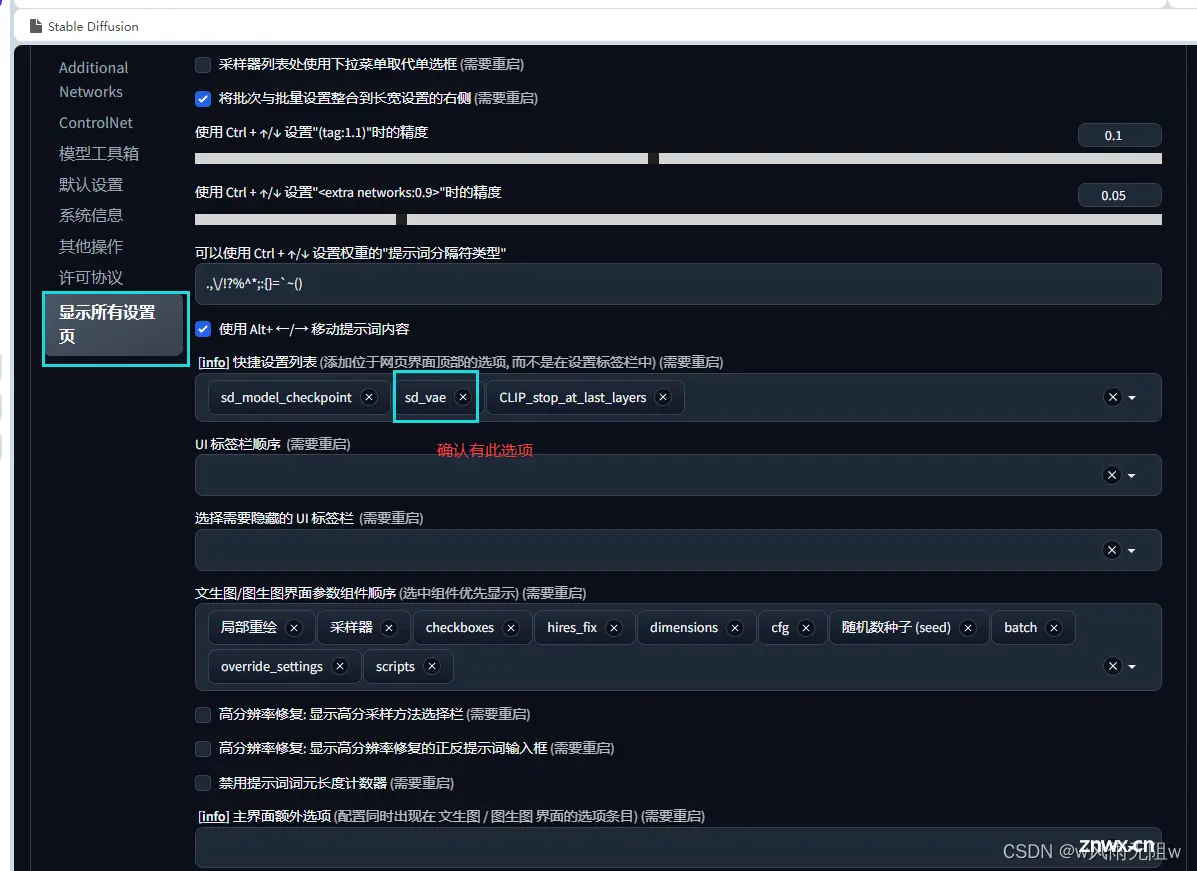
如果没有sd_vae 选项,则需要补充上。
添加在 sd_model_checkpoint 之后,语法如下:
,sd_vae
大家都知道,要用Stable Diffusion画出漂亮的图片,首先得选好模型。
目前,模型数量最多的两个网站是civitai 和huggingface。
civitai又称c站,有非常多精彩纷呈的模型,有了这些模型,我们分分钟就可以变成绘画大师,用AI画出各种我们想要的效果。
我们这里就以 civitai 站下载模型进行安装为例,进行详细说明。
二、模型的下载及选择方法

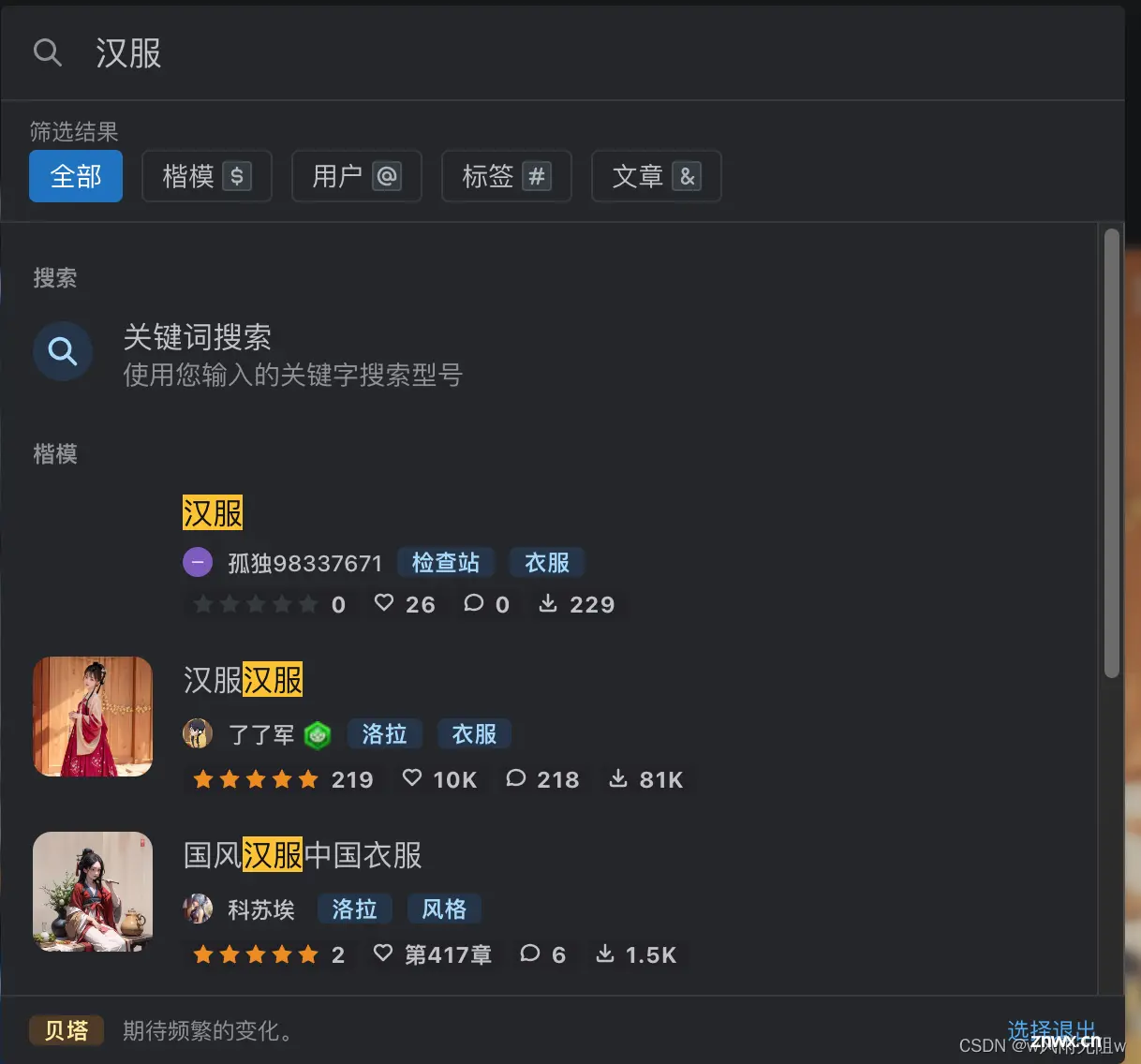
1、直接搜索想要的模型
最上面是搜索框,我们可以直接通过关键词来搜索想要的模型。

2、按照菜单分类选择模型
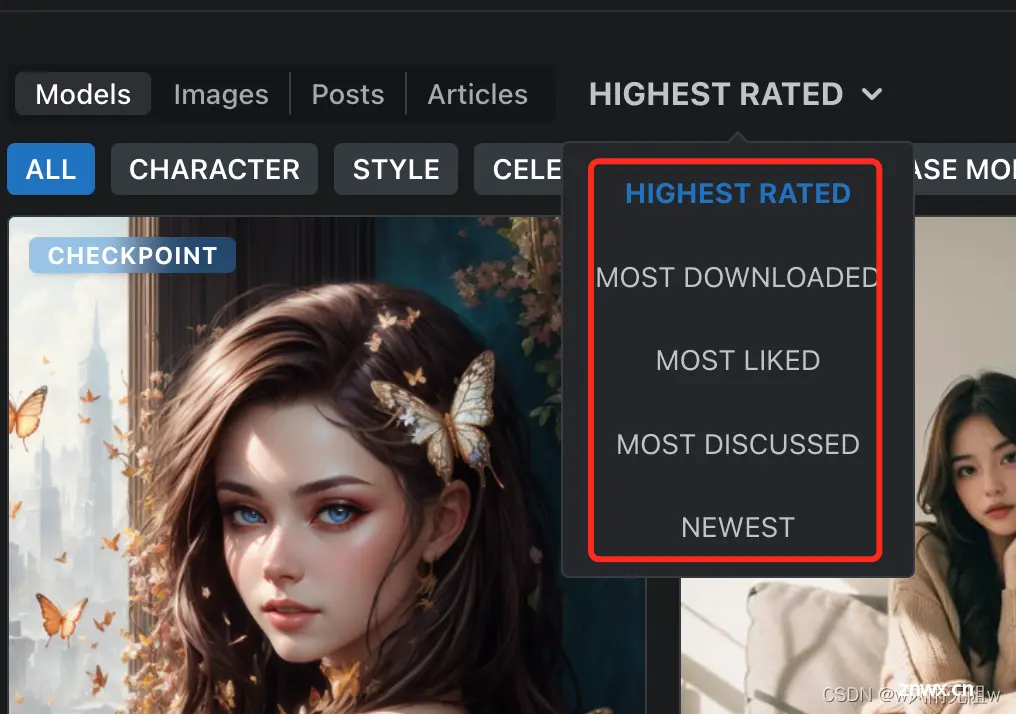
点击左上角菜单,可以看到这里是按照 以下几项来分类的:
最高评价HIGHEST RATED最多下载MOST DOWNLOADED点赞最多MOST LIKED讨论最多MOST DISCuSSED最新上传NEWEST。
3、按照时间排序来选模型
点击右上角,可以按照时间排序来选模型:最近一周、最近一月、所有时间的。

4、按照模型类型、Stable Diffusion版本选择模型
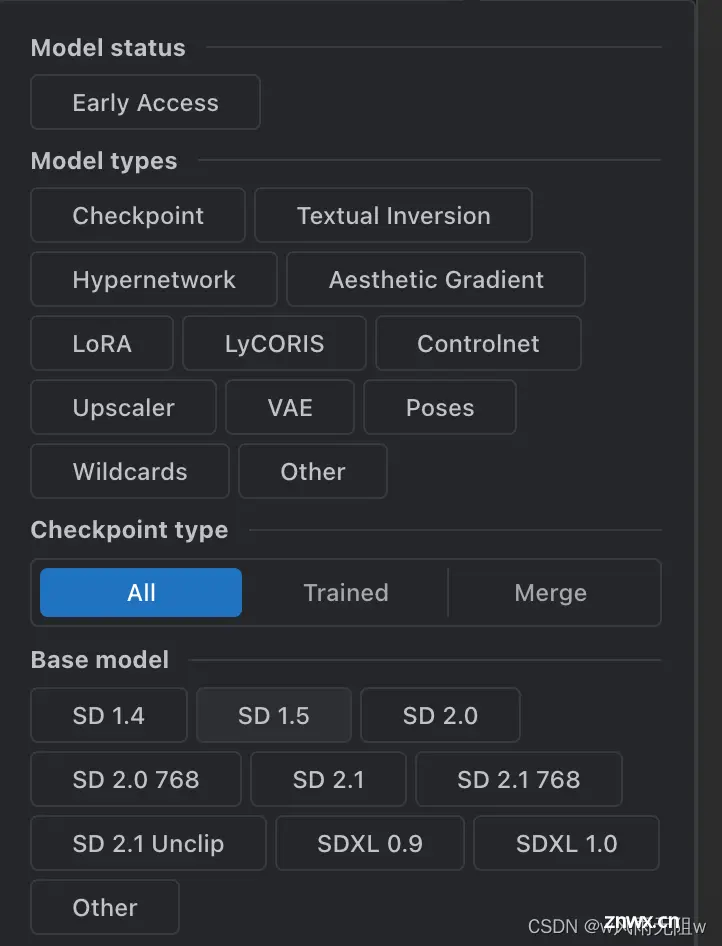
Stable Diffusion目前有SD 1.4、SD 1.5、SD 2.0、SD 2.0 768、SD 2.1、SD 2.1768、SD 2.1 Unclip 等版本。
注意:
通常来说版本越高,效果越好。
目前比较流行的还是1.5版本,1.5之前的版本没啥限制,可以自由出各种图片。
2.0以上版本提供了一个 图像无损放大模型:Upscaler Diffusion ,可以将生成图像的分辨率提高 4 倍,适合出高清大图。2.0加入了一些限制,不能出一些不可描述的图片。
所以,具体使用哪个版本,还是要根据自己的需求来选择。
挑到喜欢的模型后,怎么安装模型呢?
三、模型的下载安装实操
接下来我们来说明一下安装实操步骤。
1、下载模型文件,在c站 搜搜到喜欢的模型,并下载
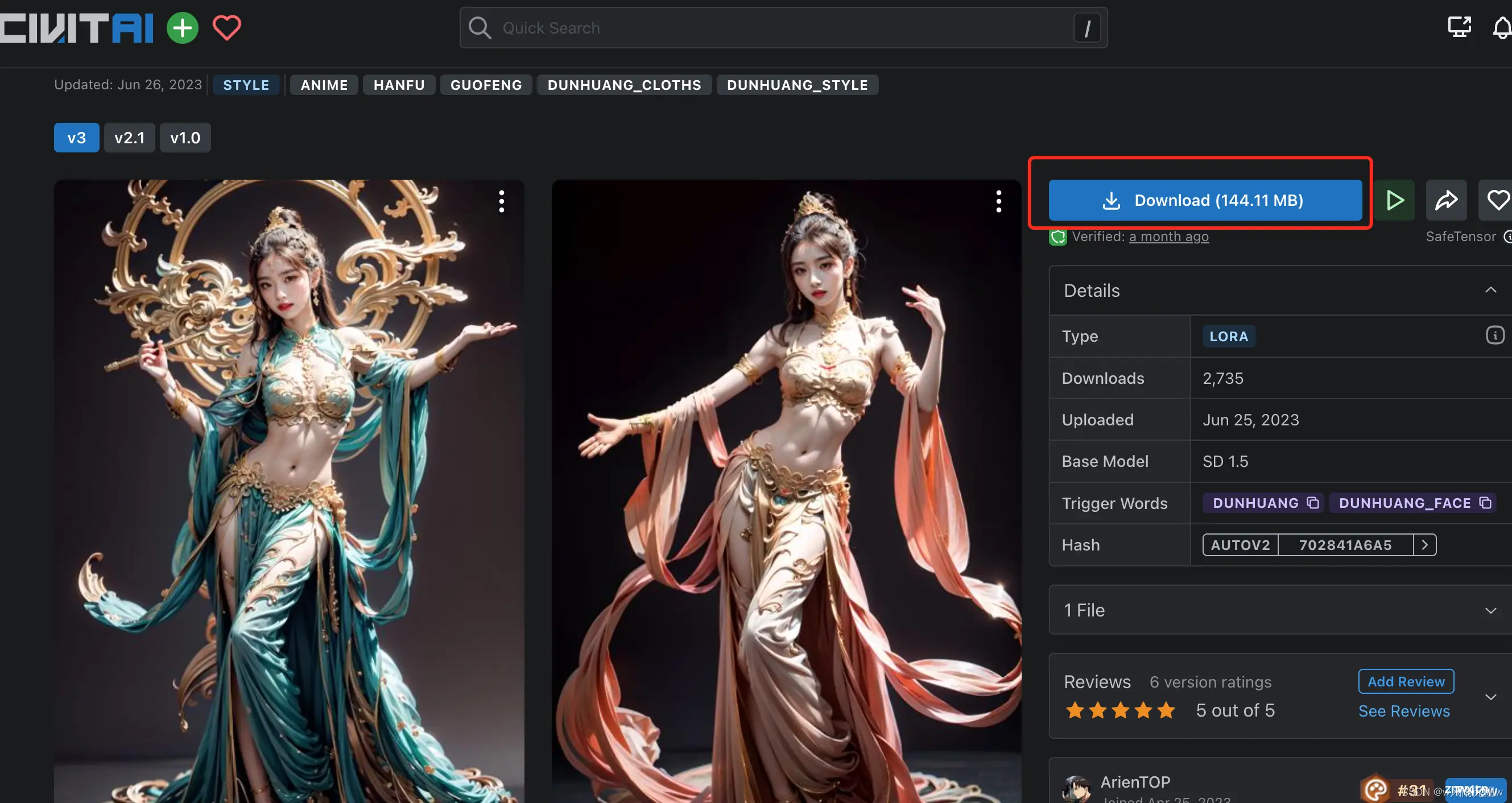
2、下载成功后,我们会获得模型文件

如图:
将模型文件拖入该工具后,会获得以下信息:
文件名dunhuangV3.safetensors文件大小144.11 MB模型种类LoRA 模型模型用法放入 models/Lora 文件夹后,在 webui 中,“生成” 按钮的下方选择 🎴 按钮,找到 Lora 选项卡点击使用。Info{ss_batch_size_per_device:"6"ss_bucket_info:{}ss_bucket_no_upscale:"True"ss_cache_latents:"True"ss_caption_dropout_every_n_epochs:"0"ss_caption_dropout_rate:"0.0"ss_caption_tag_dropout_rate:"0.0"ss_clip_skip:"None"ss_color_aug:"False"ss_dataset_dirs:{}ss_enable_bucket:"True"ss_epoch:"10"ss_face_crop_aug_range:"None"ss_flip_aug:"False"ss_full_fp16:"False"ss_gradient_accumulation_steps:"1"ss_gradient_checkpointing:"False"ss_keep_tokens:"0"ss_learning_rate:"0.0001"ss_lowram:"False"ss_lr_scheduler:"cosine_with_restarts"ss_lr_warmup_steps:"0"ss_max_bucket_reso:"1024"ss_max_grad_norm:"1.0"ss_max_token_length:"None"ss_max_train_steps:"6750"ss_min_bucket_reso:"256"ss_min_snr_gamma:"None"ss_mixed_precision:"fp16"ss_network_alpha:"64.0"ss_network_dim:"128"ss_network_module:"networks.lora"ss_new_sd_model_hash:"e4a30e4607faeb06b5d590b2ed8e092690c631da0b2becb6224d4bb5327104b7"ss_noise_offset:"None"ss_num_batches_per_epoch:"675"ss_num_epochs:"10"ss_num_reg_images:"0"ss_num_train_images:"4050"ss_optimizer:"bitsandbytes.optim.adamw.AdamW8bit"ss_output_name:"dunhuang_20230625021029"ss_prior_loss_weight:"1.0"ss_random_crop:"False"ss_reg_dataset_dirs:"{}"ss_resolution:"(512, 768)"ss_sd_model_hash:"1d5a534e"ss_sd_model_name:"majicmix_realv6_fp16.safetensors"ss_sd_scripts_commit_hash:"(unknown)"ss_seed:"2361018997"ss_session_id:"801586992"ss_shuffle_caption:"False"ss_tag_frequency:{}ss_text_encoder_lr:"1e-05"ss_total_batch_size:"6"ss_training_comment:"None"ss_training_finished_at:"1687645290.3126323"ss_training_started_at:"1687630234.599286"ss_unet_lr:"0.0001"ss_v2:"False"sshs_legacy_hash:"14dab82f"sshs_model_hash:"f747a8b2ab9a85d407f26183afb59d53fc023c2fbde928fe8512721fda5a11aa"}
根据工具输出信息可知, dunhuangV3.safetensors 模型的模型种类是LoRA 模型。
4 、将模型dunhuangV3.safetensors 放入 models/Lora 文件夹。
5、在 webui 中,“生成” 按钮的下方选择 🎴 按钮,找到 Lora 选项卡点击使用。
好,今天的内容就到此结束,我们来总结一下。
今天主要给大家分享了 Stable Diffusion的模型种类说明,以及常见模型的下载、安装、使用方法, 没理解到的朋友,请收藏起来多看几遍。
关注我,后续继续分享sd更多干货 , 敬请期待。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。