全面了解三大 AI 绘画:Midjourney、Stable Diffusion、DALL·E 的区别和特点
设计师阿威 2024-07-20 08:31:01 阅读 55
大家好,我是设计师阿威
在当前,比较流行的 AI 绘画软件主要有三个,分别是:StabilityAI 公司的 Stable Diffusion,OpenAI 公司的 DALL·E2,以及更为大众所熟知的,Leap Motion公司创始人 David Holz 携十一人团队创建的 Midjourney。
它们各自有各自的特点以及适用场景,接下来我们一一来介绍一下。

(提示词:ditorial Style photo Mid-range Classic Clothing 35 Asian Full-body shot Dior Cotton, Silk High Pastel Colors Romantic and Elegant Studio Lighting Elegant Mansion Evening Sophisticated --v 5.2)
01、Midjourney
首先是 Midjourney。Midjourney 广为大众所熟知,是从今年 3 月份一张广州情侣的照片开始的。就是下面这张,相信很多人都看过这个新闻。大家都以为这是一张真人照片,但实际是由 AI 生成的,使用的就是 Midjourney V5。

还有后来美国人整蛊的,川普被捕的图片,也都是出自 Midjourney 之手。
在三大绘画中,如果仅仅评价文生图的质量,midjourney 毫无疑问是最好的。而且 Midjourney 的上手门槛是最低的,普通人不需要经过特别严格的训练,就可以生成相当漂亮好看的图片。
但 Midjourney 的缺点也很明显,那就是其发散性相当大,虽然生成的图片非常好看清晰,但是如果你想精确控制图片的内容,往往是相当困难的。也就是说,Midjourney 介入绘画相当深。虽然可以通过参数–s设置其艺术加工的程度,但是对于一些专业领域的场景,比如给定一个毛坯房照片生成装修图,或者给定线稿生图,生成的图片总是与参考图是有一些差异的。这是 Midjourney 的缺点。
这与 Midjourney 自身的定位有关。Midjourney 的定位就是一款大众化的文生图模型,所以其易用性,通用性,上手门槛是最低的。像这种高级、复杂、定制的需求场景,需要使用更加专业的工具来实现。比如 Stable Diffusion。
02、Stable Diffusion
Stable Diffusion 的概念非常复杂。(SD安装包和安装教程请看我往期入门教程或扫描获取哦)

同 Midjourney 不同的是,Stable Diffusion是一个开源模型。也就是说,我们可以下载或者看到其完整源代码,并部署在本地个人电脑上(对显卡和显存有一定要求)。
当然,StabilityAI 公司也做了一个公有服务,可以免部署直接使用。当然也是收费的。所以,当我们说起 SD 的时候,需要明白我们说的是公有云版,还是私有部署版,他们区别相当大,几乎不是一回事。
这其中主要在于模型的区别。当我们讨论 Midjourney 的时候,我们不需要太关注模型这个概念,这也是它简单的地方。但当我们讨论 Stable Diffusion 的时候,其实我们主要是在讨论模型。
Stable Diffusion 的模型分为基础(base)模型和定制化(fine-tuned)模型。基础模型,就是公有服务上提供的那些,也可以称之为“通用模型”,如:

顾名思义,既然是“通用模型”,那必然是没有什么特点。事实上,在 SDXL1.0 模型出来之前,使用通用模型,在没有任何调教的情况下,画出的画,质量是不高的。
那么我们如何画出好看的画?小某书和网上那些好看的图片又是如何画出来的?不也是用的 Stable Diffusion 么?
答案就是:用定制化模型。定制化模型是在以上那些通用模型的基础上,通过添加特定风格的图片作为素材样本进行训练得到的模型。也可以叫“微调模型”。
C站(https://civitai.com/)就是这样一个汇集了各路人才训练出的模型的地方。上面有各种风格的模型:
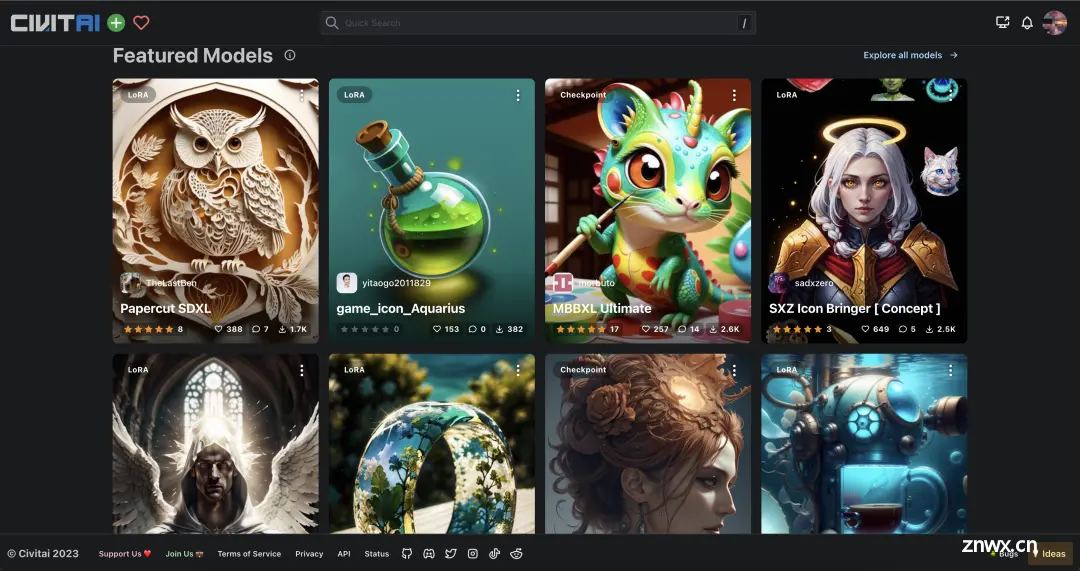
也就是说,如果你想画人物,需要下载一个人物模型;如果你想画卡通,下载一个卡通模型:社区有。不同于通用模型,这些微调模型全是各领域的专家,画特定的风格表现非常突出。但是下什么模型,就只能画什么风格的图片。每个模型的大小大约在 1-5 个G 之间,但如果是 LoRA 会小一些,在几十 M 到几百 M 之间。
公有版只能使用基础模型。想使用微调模型,只能本地部署 Stable Diffusion
这里是私有部署 Stable Diffusion 后的一个界面:
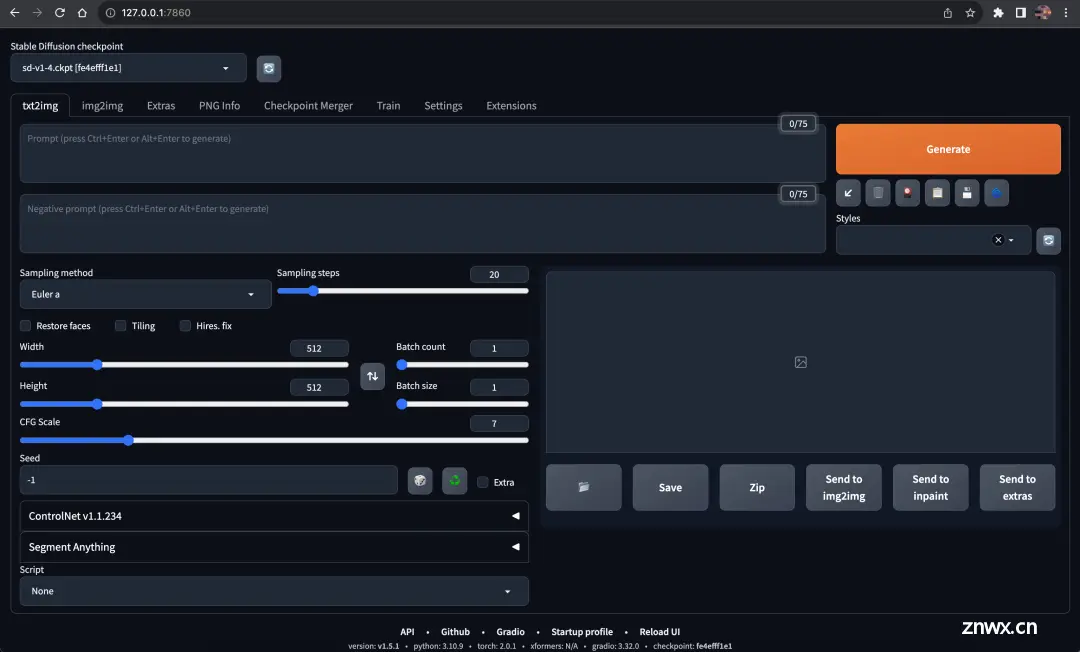
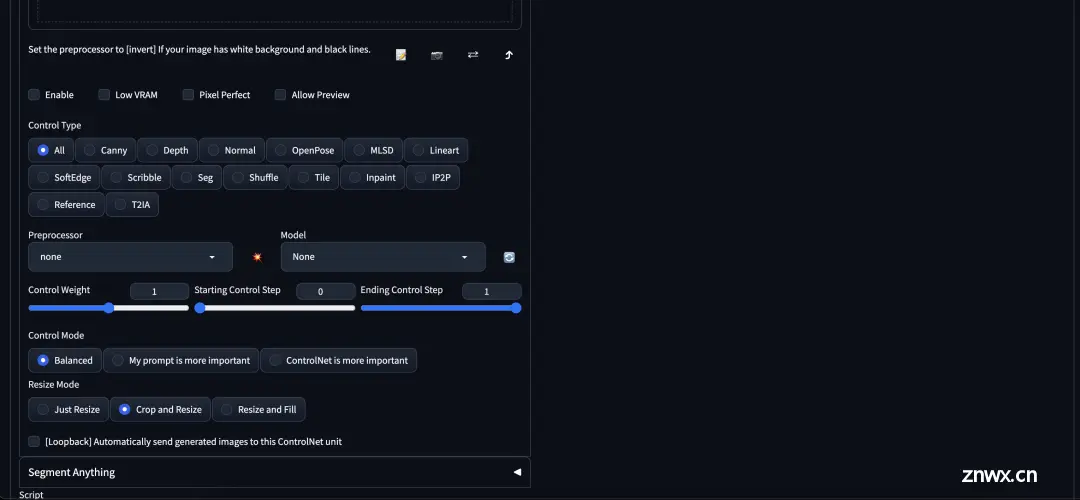
可以看到有多少参数,这些参数仅仅占了所有参数的 1/3,剩余选项卡下面大约还有这么多的参数。SD 的上手难度和 Midjourney 不是一个级别的。
另外,得益于 ControlNet 和 inpaint(局部重绘) 的加持,SD 几乎可以胜任任何 Midjourney 不能胜任的工作,比如说:换脸换装、线稿生图、毛坯房装修、上色等等等等。
可以说,如果你对 SD 足够精通,你几乎可以将图片的控制粒度达到像素级别。前提是你要对 SD 的使用“足够精通”。这需要很长时间的学习成本和大量的实践练习。
(文末附全套AI绘画Midjourney和Stable Diffusion学习教程资料)
03、DALL·E2
最后我们来简单介绍一下 DALL·E2。不知道 OpenAI 是不是把资金都投入到 GPT 的研发上了,DALL·E2 的表现非常一般。和通用模型下的 SD 表现相当。这里就不过多赘述了。不过 DALL·E2 也有个优点,就是生成速度快,也许可以当做图形验证码来用。
综上所述,Midjourney 的特点是:上手难度低,易操作。通过一个简单的描述词就可以生成画面精美的图片,适合大多数用户,可用来辅助设计、logo、头像、创意等。
Stable Diffusion 的特点是:上手难度高,参数多,可玩性高,可定制化程度极高,适合专业人士和动手、探索能力强的极客玩家。
DALL·E 的特点是生成速度快,效果差。可用于批量生成图片验证码的场景。
Midjourney 就像以前的全自动傻瓜相机,只要稍微一按,就会为你生成很不错的照片; Stable Diffusion 就像单反,成本高,造价贵,需要调一堆参数,但是如果用对了,能力也更强。
另外需要补充的一点是,Stable Diffusion 在两周前最新推出的SDXL1.0(Stable Diffusion XL v1.0) 通用模型,已经具备了接近甚至媲美 Midjourney 的能力,而且更为重要的一点:SDXL1.0 模型支持指定文字!这在其他任何一款绘画 AI 包括 Midjourney 中都还是无法实现的一项功能,其生成效果如下图所示:
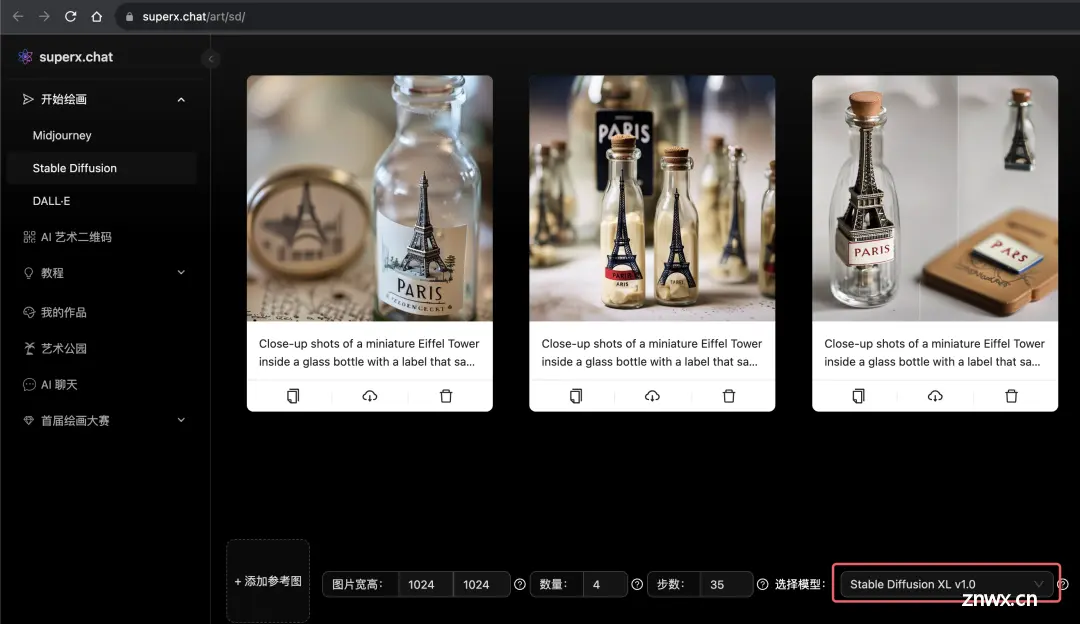
(提示词:Close-up shots of a miniature Eiffel Tower inside a glass bottle with a label that says “Paris”)
没有最好的,只有最适合的。大家可以根据自己的实际需要,选择适合自身应用场景的 AI 绘画工具。
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
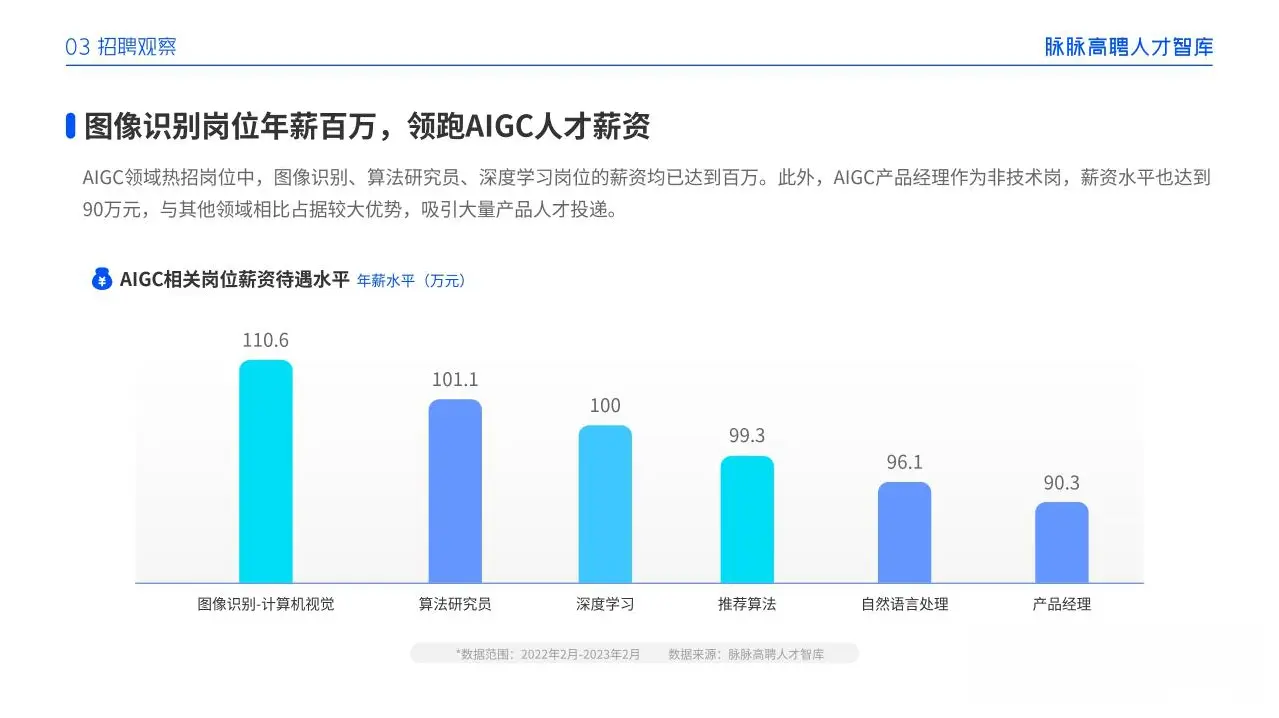
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
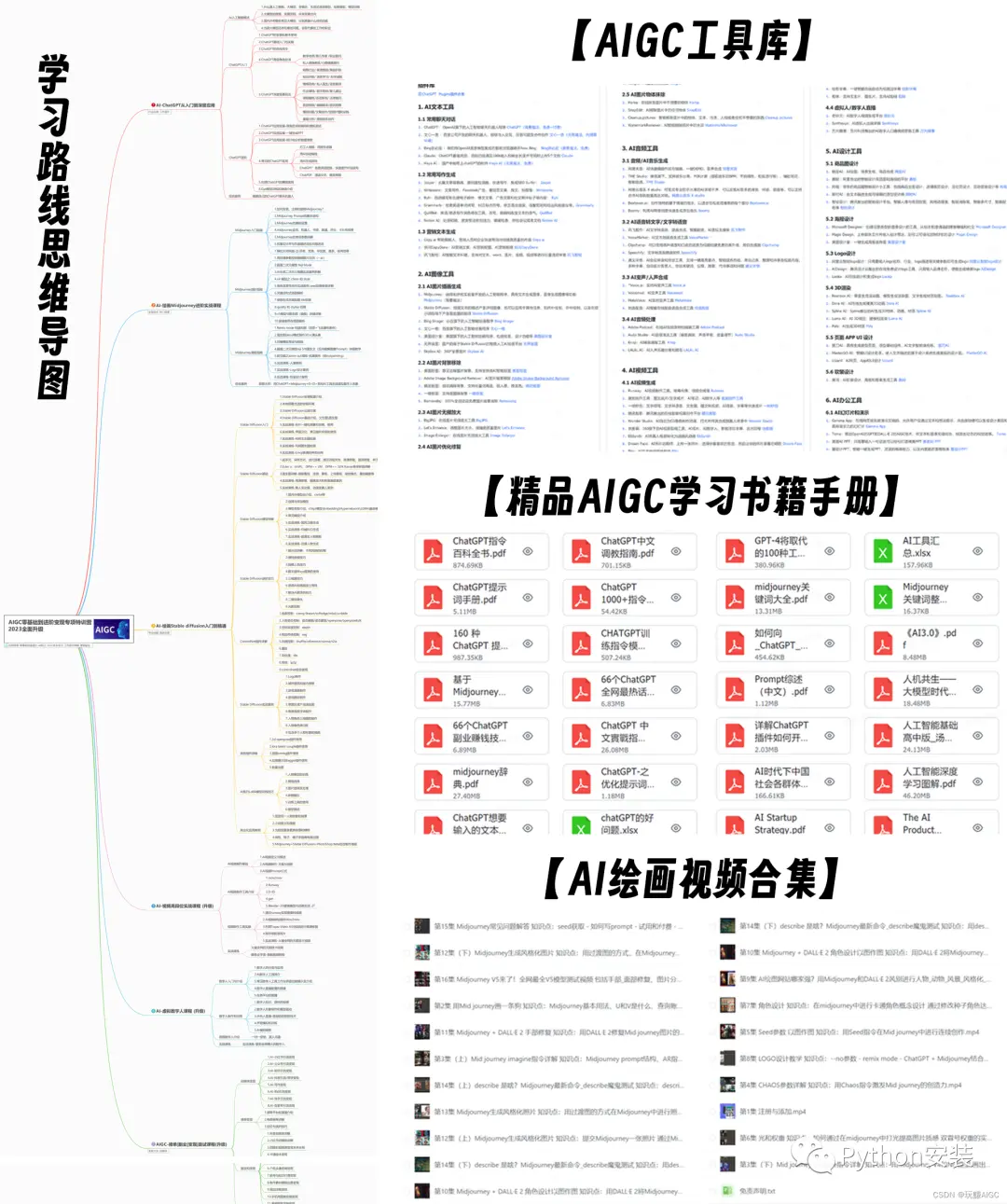
二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
若有侵权,请联系删除
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。