ChatGPT4o免费体验?OpenAI 又在深夜放大招了!
阿木木AEcru 2024-07-05 12:31:03 阅读 60
👩🏽💻个人主页:阿木木AEcru
🔥 系列专栏:《Docker容器化部署系列》 《Java每日面筋》
💹每一次技术突破,都是对自我能力的挑战和超越。
目录
一、GPT4o是什么?二、官网简介三、体验GPT-4o
一、GPT4o是什么?
GPT-4o 中的“o”代表“omni”——指的是 GPT-4o 的多模态。
二、官网简介
感兴趣的小伙伴可以到OpenAI官网查看具体内容,当然是需要魔法上网的。下面是我从官网中截取的一些内容。
我们宣布gpt-4o,我们的新旗舰模型,可以在音频,视觉和文本中进行实时推理。
GPT-4o(“o”表示“omni”)是朝着更自然的人机交互迈出的一步——它接受文本、音频和图像的任何组合作为输入,并生成文本、音频或图像输出的任何组合。它可以在232毫秒内对音频输入做出响应,平均320毫秒,这与人类在对话中的响应时间(在新窗口中打开)相似。它在英语文本和代码方面与GPT-4 Turbo的性能相匹配,在非英语语言文本方面有显著改进,同时在API中速度更快,价格便宜50%。与现有型号相比,GPT-4o在视觉和音频理解方面尤其出色。
在GPT-4o之前,您可以使用语音模式与ChatGPT通话,平均延迟为2.8秒(GPT-3.5)和5.4秒(GPT-4)。为了实现这一点,语音模式是一个由三个独立模型组成的管道:一个简单模型将音频转录为文本,GPT-3.5或GPT-4接收文本并输出文本,第三个简单模型则将文本转换回音频。这一过程意味着,主要的智力来源GPT-4会丢失大量信息——它无法直接观察音调、多个扬声器或背景噪音,也无法输出笑声、歌声或表达情感。
使用GPT-4o,我们在文本、视觉和音频中端到端地训练了一个新模型,这意味着所有输入和输出都由同一个神经网络处理。因为GPT-4o是我们第一个将所有这些模式结合在一起的模型,所以我们仍在探索该模型的作用及其局限性。



GPT-4o具有跨模态设计内置的安全性,通过过滤训练数据和通过后期训练改进模型行为等技术。我们还创建了新的安全系统,为语音输出提供护栏。
我们已经根据我们的准备框架并根据我们的自愿承诺对GPT-4o进行了评估。我们对网络安全、CBRN、说服力和模型自主性的评估表明,GPT-4o在这些类别中的得分都不高于中等风险。该评估涉及在整个模型训练过程中运行一套自动化和人工评估。我们使用自定义微调和提示测试了模型的安全前缓解和安全后缓解版本,以更好地获得模型功能。
GPT-4o还与社会心理学、偏见和公平以及错误信息等领域的70多名外部专家进行了广泛的外部红团队合作,以识别新增加的模式引入或放大的风险。我们利用这些知识制定了我们的安全干预措施,以提高与GPT-4o互动的安全性。一旦发现新的风险,我们将继续降低风险。
我们认识到GPT-4o的音频模式存在各种新的风险。今天,我们将公开发布文本、图像输入和文本输出。在接下来的几周和几个月里,我们将致力于技术基础设施、后期培训的可用性以及发布其他模式所需的安全性。例如,在发布时,音频输出将仅限于预设的声音选择,并将遵守我们现有的安全政策。我们将在即将推出的系统卡中分享有关GPT-4o全系列模式的进一步细节。
以上内容均来源于 https://openai.com/index/hello-gpt-4o/ 更多内容可自行访问浏览。
三、体验GPT-4o
通过官网进入体验

进入之后就可以自行注册登录了。
PS:目前GPT3.5是可以免费使用的无需登录,但是想要体验GPT4o就需要登录了,因为也是有免费次数限制的。
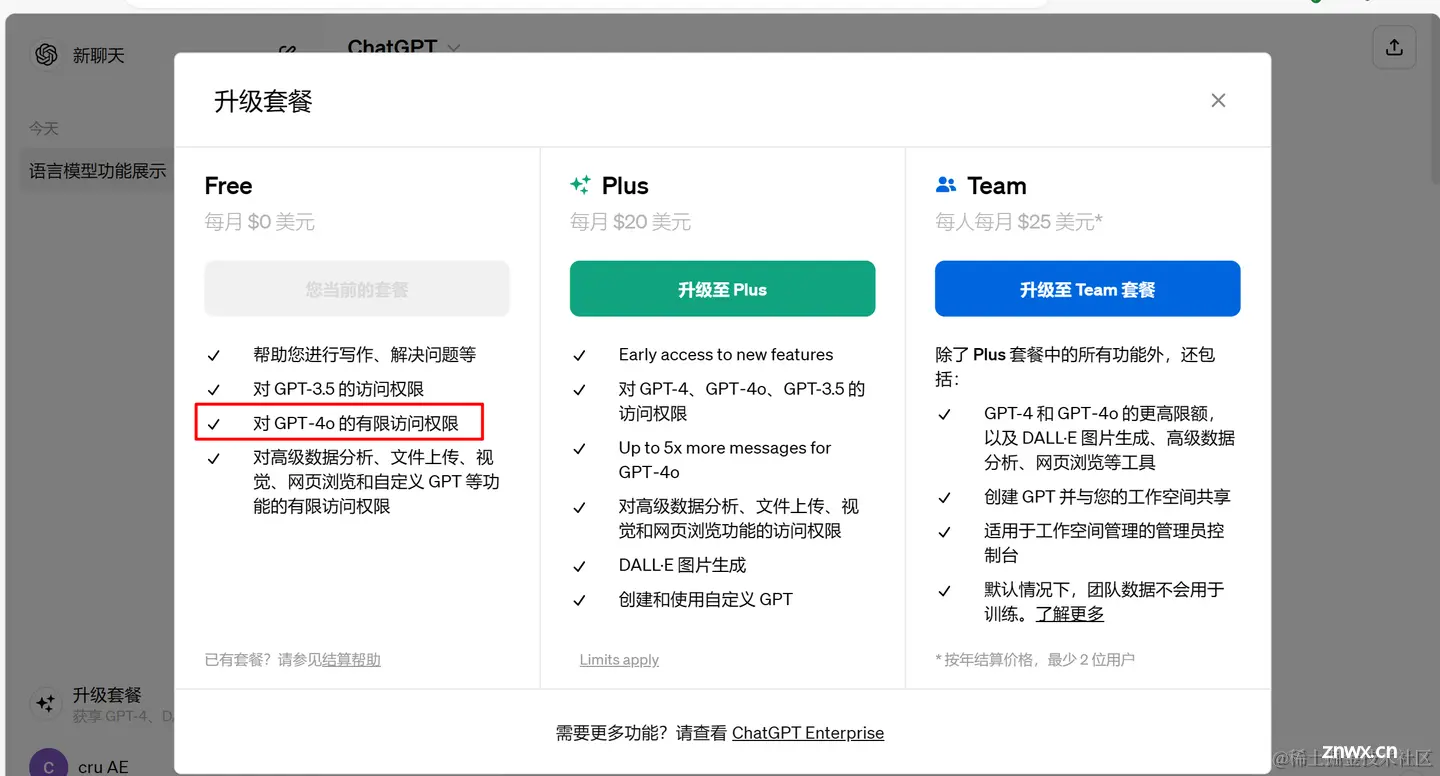
在升级套餐中会显示有GPT4o的有限访问,就是有体验权限了。 我下面初步的使用了一下。

回复内容如下:




目前体验下来的感觉就是 大部分功能再体验版本是没有的,例如图片生成、视频生成 等。 我尝试有用到的功能就可以联网搜索 内容然后优化它的回答,就不只是局限于GPT3.5自身的一个大模型知识库。
非常感谢您花时间阅读本文,希望我的内容对您有所帮助。如果您觉得本文对您有帮助,用您发财的小手点赞、收藏、转发一下吧,您的支持就是作者最大的动力。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。