多模态大模型中的幻觉问题及其解决方案
人工智能大模型讲师培训咨询叶梓 2024-08-28 12:31:04 阅读 64
人工智能咨询培训老师叶梓 转载标明出处
多模态大模型在实际应用中面临着一个普遍的挑战——幻觉问题(hallucination),主要表现为模型在接收到用户提供的图像和提示时,可能会产生与图像内容不符的描述,例如错误地识别颜色、数量或位置等。这种误判可能对实际应用造成严重影响,如在自动驾驶场景中,错误的图像解读可能导致严重的交通事故。
为了解决这一问题,中国科学技术大学的安徽数字安全重点实验室与上海人工智能实验室的研究人员联合提出了一种名为OPERA的新型解码方法。该方法基于“过度信任惩罚”(Over-trust Penalty)和“回顾分配”(Retrospection-Allocation)策略,旨在无需额外数据、知识或训练的情况下,减轻MLLMs的幻觉问题。

OPERA在减少幻觉方面的表现
方法
OPERA方法包含三个主要部分:MLLMs的生成过程公式化、过度信任惩罚(Over-Trust Logit Penalty)的计算和回顾分配(Retrospection-Allocation Strategy)策略。
生成过程公式化
MLLMs的生成过程可以分解为三个关键部分:输入制定、模型前向传播和解码。输入制定阶段,MLLMs将图像和文本作为输入。通常,模型使用视觉编码器从原始图像中提取视觉标记,并通过跨模态映射模块将这些视觉标记映射到LLMs的输入空间。这些视觉标记与文本输入一起,构成了模型的最终输入序列。
在模型前向传播阶段,MLLMs以自回归方式进行训练,使用因果注意力掩码,每个标记基于前一个标记预测下一个标记。模型的隐藏状态h由最后一层的输出确定,这些状态随后被用来通过词汇表头H投影,以获取下一个标记的logits(或概率)。
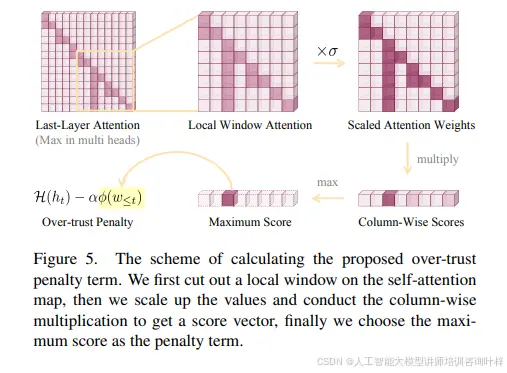
如图5所示,解码阶段基于这些logits进行,其中包括贪婪解码、束搜索解码等策略。OPERA方法基于束搜索解码,这是一种累积分数的解码策略,它保持多个候选序列,并根据logits中的概率选择最佳候选。
过度信任惩罚
OPERA方法的核心是解决MLLMs在生成文本时可能出现的幻觉问题。幻觉现象通常与知识聚合模式有关,这些模式表现为模型在解码时过度依赖某些摘要标记,而忽略其他重要信息。为了应对这一问题,OPERA引入了过度信任惩罚机制。
OPERA通过在自注意力权重的局部窗口上进行列乘积来计算度量值,并选择列分数向量中的最大值作为知识聚合模式的特征。这个惩罚项随后被纳入模型的logits中,以影响当前标记和候选序列的选择。如果候选序列累积了大量惩罚,它的优先级就会降低,从而可能省略产生幻觉的输出。
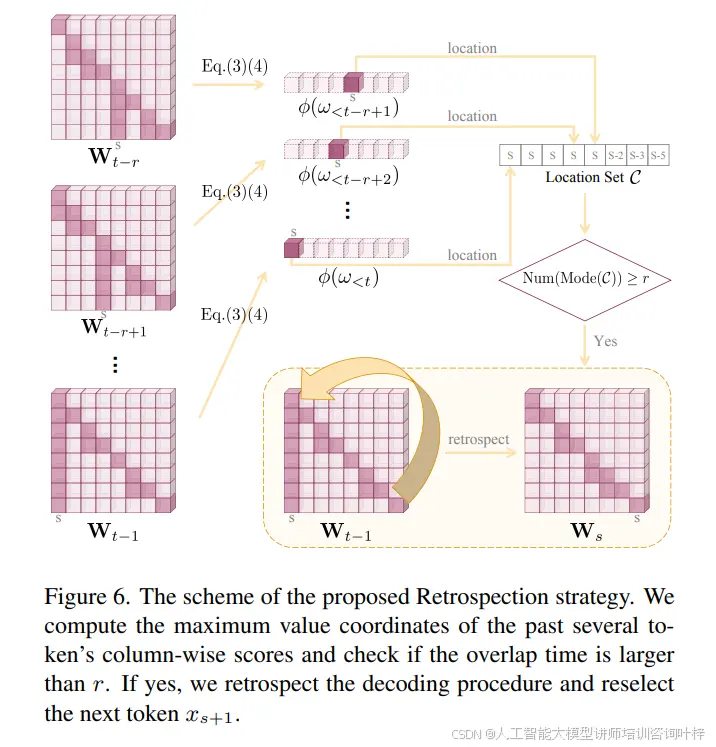
如图6所示,当解码过程遇到不可避免的幻觉时,OPERA的回顾分配策略会触发回滚机制,回到摘要标记的位置,并重新选择下一个标记的候选,以避免幻觉的发生。这种策略通过检查过去几个标记的列分数最大值坐标的重叠次数来决定是否触发回滚,如果重叠次数超过设定的阈值r,就会实施回顾。
回顾分配
即使有了过度信任惩罚,仍然存在所有候选都受到惩罚,幻觉已经发生的情况。这促使研究者重新思考这种聚合模式的起源:由于后续几个标记过度信任摘要标记,而惩罚未能纠正它们。因此,提出了回顾分配策略,即如果能够排除导致幻觉的标记,并在摘要标记之后重新选择正确的几个标记,模式将大大削弱。
回顾策略:当解码过程遇到知识聚合模式并且幻觉不可避免时,它将回滚到摘要标记并为下一个标记预测选择其他候选,除了之前选择的候选。回顾的条件是几个连续标记的列分数最大值的空间重叠,设置阈值计数为r。
回顾过程:基于前述,可以轻松推导出最近几个解码标记的最大分数坐标的位置坐标集。如果重叠次数达到阈值r,则考虑实施回顾,将模式坐标s视为摘要标记的位置。然后,解码过程将回滚到序列{ x0, x1, ..., xs },并在补集Y/{xs+1}中选择新的下一个标记。
实验
实验选取了四个具有代表性的MLLM模型进行评估,包括InstructBLIP、MiniGPT-4、LLaVA-1.5和Shikra。这些模型大致可以分为两类:InstructBLIP和MiniGPT-4使用Q-former来桥接视觉和文本模态的特征,而LLaVA-1.5和Shikra则使用线性投影层对两种模态的特征进行对齐。所有这些模型都采用了预训练的视觉编码器(如CLIP和EVA)和语言模型(如LLaMA或Vicuna)。实验中使用的所有模型都是7B级别的模型
实验选择了四种解码方法作为基线对比,包括贪婪解码、Nucleus采样、束搜索解码和专为减轻LLMs幻觉问题设计的DoLa方法。这些方法在解码时采用了不同的策略,例如贪婪解码逐步选择概率最高的标记,而束搜索解码则维护多个候选序列以扩大候选范围。
OPERA基于束搜索实现,采用了一些关键的超参数设置,例如σ=50用于放大注意力值,Ncan=5作为候选数量,α=1、β=5和r=15用于调整惩罚权重和回顾分配策略。
实验使用了CHAIR(Caption Hallucination Assessment with Image Relevance)指标来评估幻觉现象。CHAIR通过计算描述中未在真实标签集中出现的物体的比例来量化图像描述中的物体幻觉程度。实验在MSCOCO数据集上进行,随机选取了500张验证集图像,并使用不同的MLLM模型生成描述。

CHAIR幻觉评估的结果
CHAIR评估结果:OPERA在减少幻觉方面的表现优于所有基线方法。特别是在Shikra模型上,OPERA相比DoLa实现了约35%的改进。这些结果在长描述和短描述生成中都保持了一致性。
由于CHAIR无法识别某些类型的幻觉(如属性、位置和关系幻觉),实验采用了HalluBench基准,利用GPT-4来判断描述中的幻觉。GPT-4根据MLLM生成的描述,逐句判断是否存在幻觉。
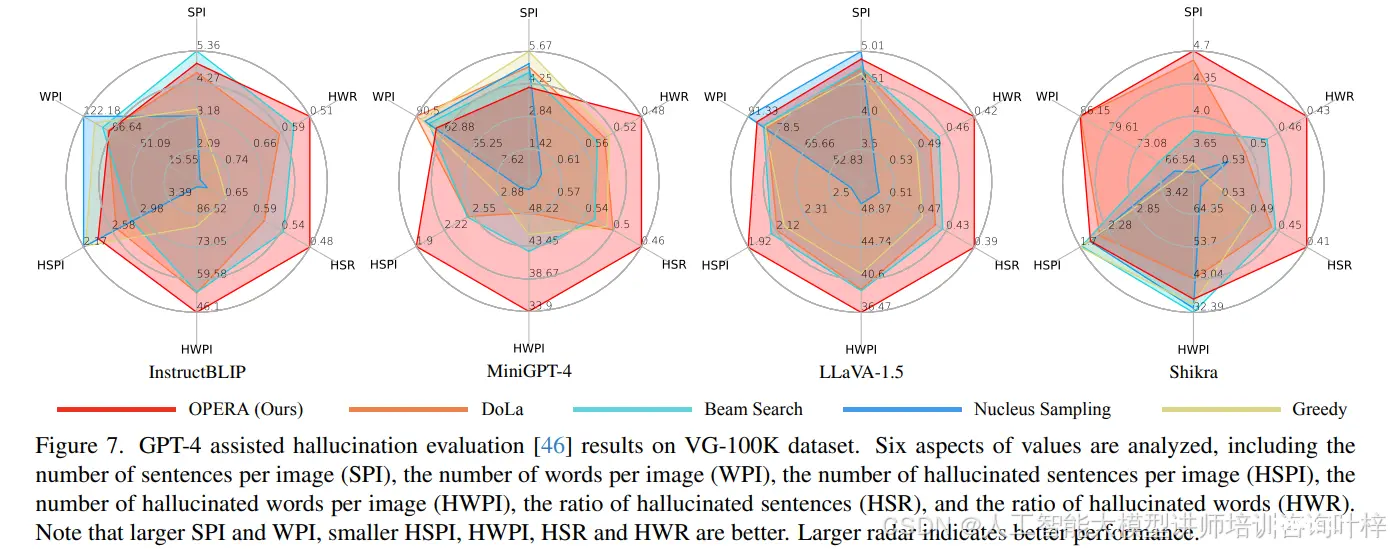
在VG-100K数据集上使用GPT-4辅助幻觉评估的结果
GPT-4辅助评估结果:OPERA在减少描述每个图像时的幻觉句子或单词数量方面表现更好,例如在幻觉句子比率(HSR)上比贪婪解码提高了约30.4%,在幻觉单词比率(HWR)上比DoLa提高了约15.4%。
进一步使用GPT-4V(ision)对Beam search和OPERA解码得到的描述进行评分,基于准确性和详细性两个方面。
GPT-4V辅助评估结果:OPERA在减少幻觉方面相比Beam search解码有高达27.5%的改进,同时保持了答案的详细性。
Polling-based Object Probing Evaluation (POPE)是一种新近引入的方法,用于评估MLLMs中的幻觉问题。POPE使用问答格式来确定模型是否能够识别图像中特定的物体。
POPE评估结果:OPERA在各种解码策略中表现最佳,尽管改进幅度不大。
为了全面评估生成文本的质量,实验采用了PPL(Perplexity)以及GPT-4对生成文本的语法、流畅性和自然性进行评估。

生成文本质量的评估结果
文本质量评估结果:OPERA能够从各个方面保持生成文本的质量。此外,在MLLM基准测试MME和MMBench上,OPERA能够维持甚至提高MLLM的性能。
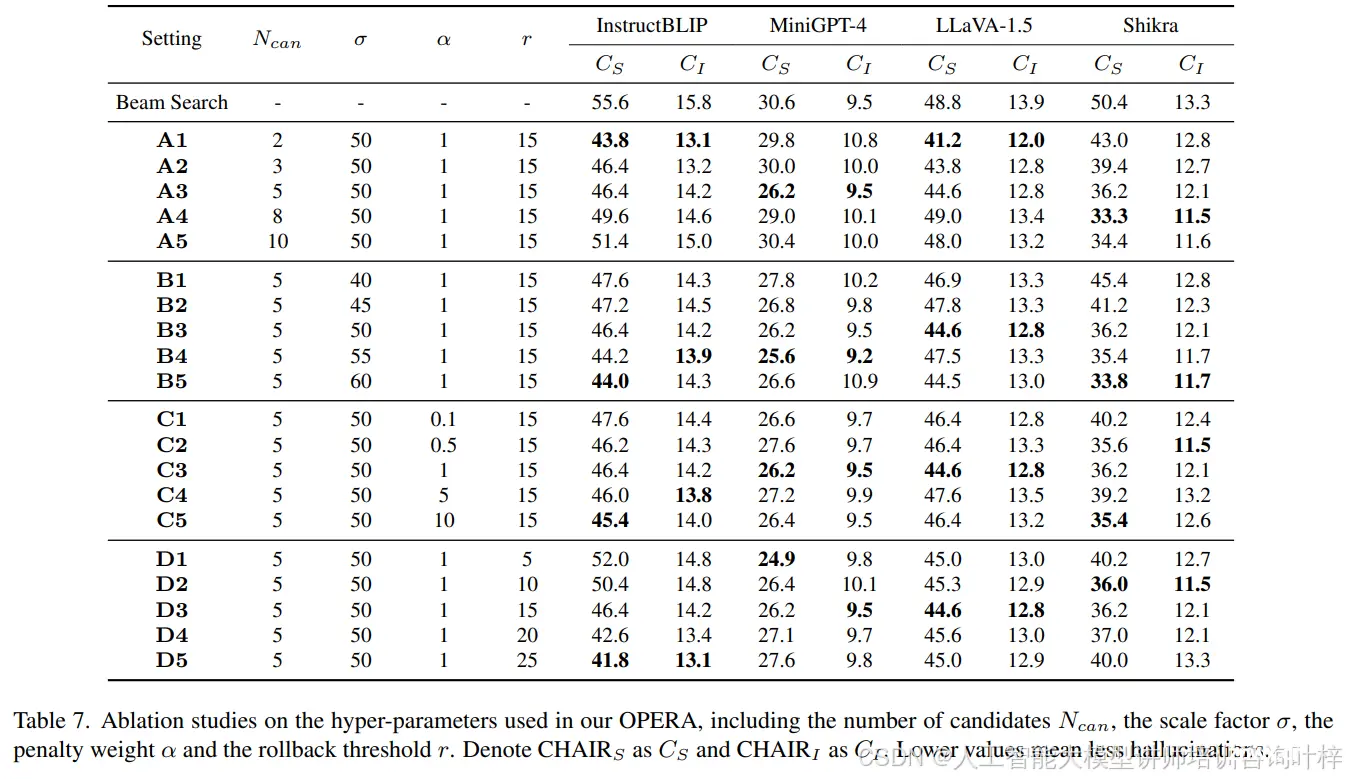
研究者们还对OPERA中的超参数进行了详细的消融研究,这些超参数包括候选数量Ncan、缩放因子σ、惩罚权重α和回顾阈值r。消融研究的目的是确定这些参数对OPERA性能的具体影响,并找出最优的参数配置。
OPERA中使用的超参数的消融研究结果
候选数量 Ncan:这个参数限制了每个束在logit中预测的最高词汇数量。如果Ncan设置得太小,可能会减少回顾重分配的效果;如果太大,则可能引入与整体序列无关的不合理词汇。实验结果显示,不同的MLLM模型可能偏好不同的Ncan值。
缩放因子 σ:在通过列乘法在注意力图中描述知识聚合模式之前,设置了一个缩放因子σ来放大通常较小的注意力值。不同的MLLM模型偏好不同的σ值,这可能是因为不同的序列长度导致自注意力权重值的不同幅度。
惩罚权重 α:研究者们进一步消融了与模型logit结合的惩罚项的权重。OPERA的性能在α变化时相对稳健,不同的MLLM可能偏好不同的α值,但数值波动通常很小。
回顾阈值 r:考虑了几个连续标记的列分数最大值的空间重叠作为回顾的条件,设置了阈值r来统计重叠次数。如果重叠次数达到阈值r,则触发回滚。实验结果显示,InstructBLIP在r=25时表现更好,而其他三个MLLM在r=15时表现更佳。
GPT-4评估遵循了HalluBench [46]中提出的方法,并在VG数据集上实施。VG数据集中的每个图像都有关于所有出现物体的详细真实描述。由于GPT-4无法处理图像数据,研究者们将所有真实描述整合到输入提示中,以帮助GPT-4理解图像内容。然后,给定MLLM生成的图像描述,GPT-4需要判断MLLM描述的每个句子是否包含幻觉内容。
评估指标:包括每个图像的句子数(SPI)、每个图像的单词数(WPI)、每个图像的幻觉句子数(HSPI)、每个图像的幻觉单词数(HWPI)、幻觉句子比率(HSR)和幻觉单词比率(HWR)。
提示:采用的GPT-4提示基于HalluBench [46],要求GPT-4基于六项指标对MLLM的描述进行判断。

用于GPT-4和GPT-4V评估的提示
GPT-4V评估对Beam search和OPERA进行了双重评估。给定一个训练好的MLLM模型和一张图像,分别使用Beam search解码和OPERA解码获得两个描述。然后,采用GPT-4V的提示,要求GPT-4V基于图像对两个描述进行0到10的评分,评分涉及准确性和详细性两个方面。
准确性:反映描述与给定图像的一致性。如果GPT-4V认为描述中的任何内容与给定图像不一致,即存在更多幻觉,它将获得较低的分数。
详细性:反映表达能力的程度,即描述对图像的描述有多全面。

用于GPT-4和GPT-4V评估的提示
MLLMs的重复问题表现为模型不断重复特定句子。OPERA能够很好地处理这种重复,如文中图8所示。重复句子的自注意力图显示出周期性的知识聚合模式。因此,OPERA可以帮助序列在其他适当的词汇(如“eos”标记)处进行回顾和重分配。
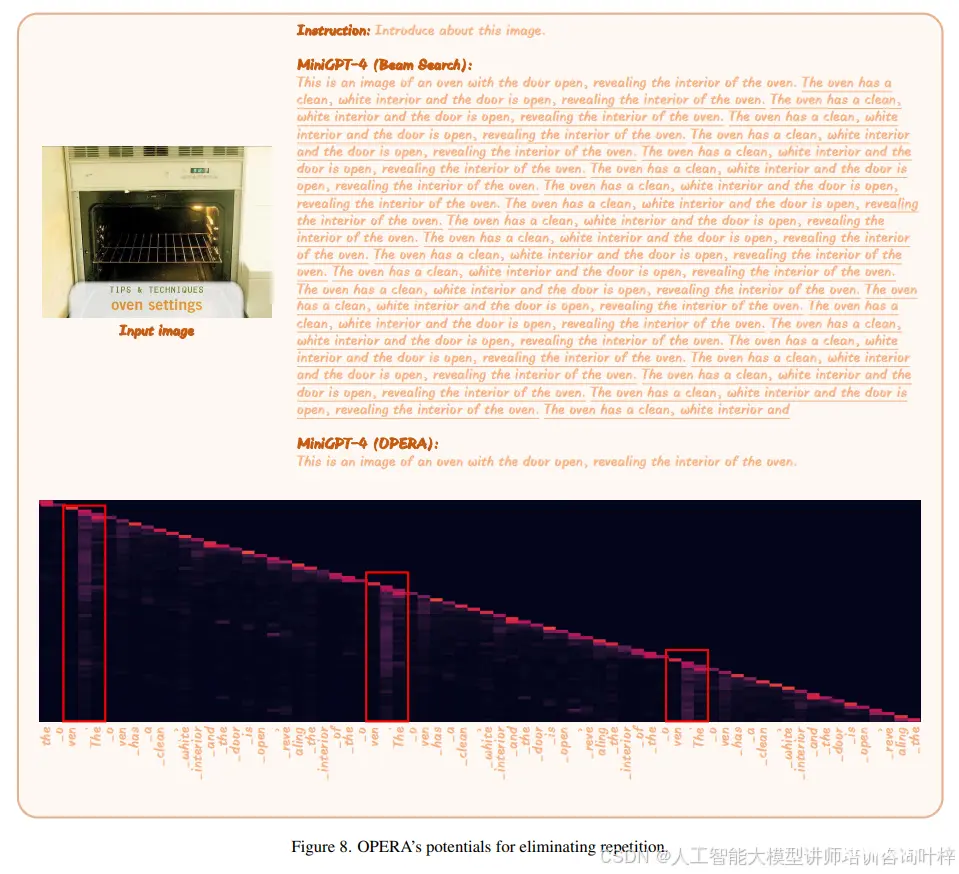
图9、图10案例使用了不同的MLLM和不同的指令,包括“请详细描述这张图片。”、“你在这张图片中能看到什么?”和“介绍这张图片。”等,展示了OPERA在减轻幻觉方面的强能力。

OPERA在减少幻觉方面的表现

OPERA在减少LLaVA-1.5-7B模型幻觉方面的表现
虽然OPERA无法解决所有类型的MLLMs幻觉问题,特别是当模型的偏见过于强烈或视觉感知不够稳健时。然而,这些局限性并不妨碍OPERA在推动多模态大型语言模型发展方面的重要作用。
论文链接:https://arxiv.org/abs/2311.17911
代码链接:https://github.com/shikiw/OPERA
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。