深度学习笔记: 最详尽解释混淆矩阵 Confusion Matrix
Purepisces 2024-08-19 13:01:01 阅读 88
欢迎收藏Star我的Machine Learning Blog:https://github.com/purepisces/Wenqing-Machine_Learning_Blog。如果收藏star, 有问题可以随时与我交流, 谢谢大家!
混淆矩阵
假设我们有包含临床测量数据的医疗数据,例如胸痛、良好的血液循环、动脉阻塞和体重。我们希望应用机器学习方法来预测某人是否会患上心脏病。
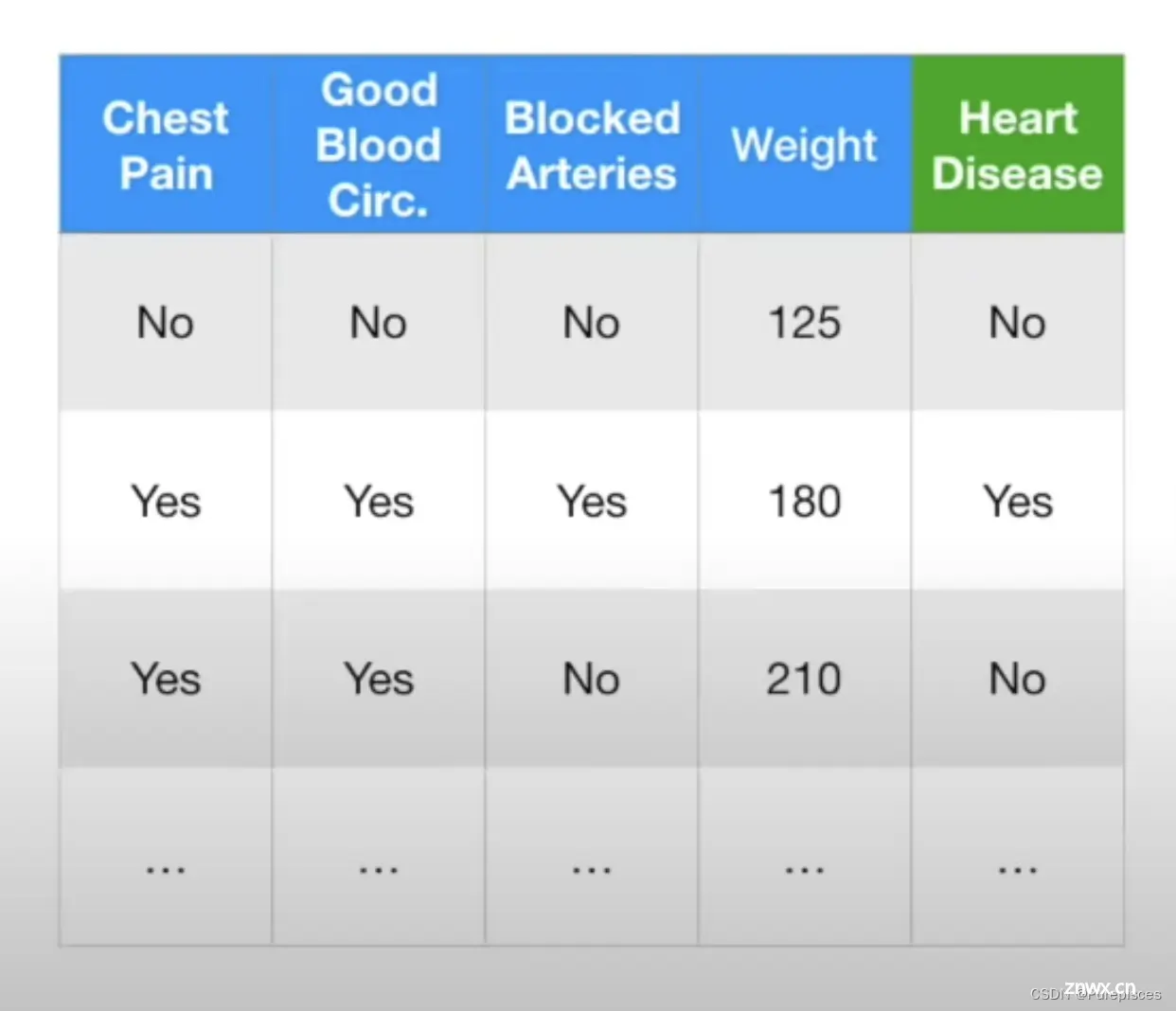
我们可以使用逻辑回归、k最近邻算法、随机森林或其他方法。为了决定哪种方法效果最好,我们首先将数据分为训练集和测试集。请注意,这将是一个使用交叉验证的绝佳机会。我们在训练数据上训练所有方法,并在测试集上测试每种方法,然后用混淆矩阵总结它们的性能。
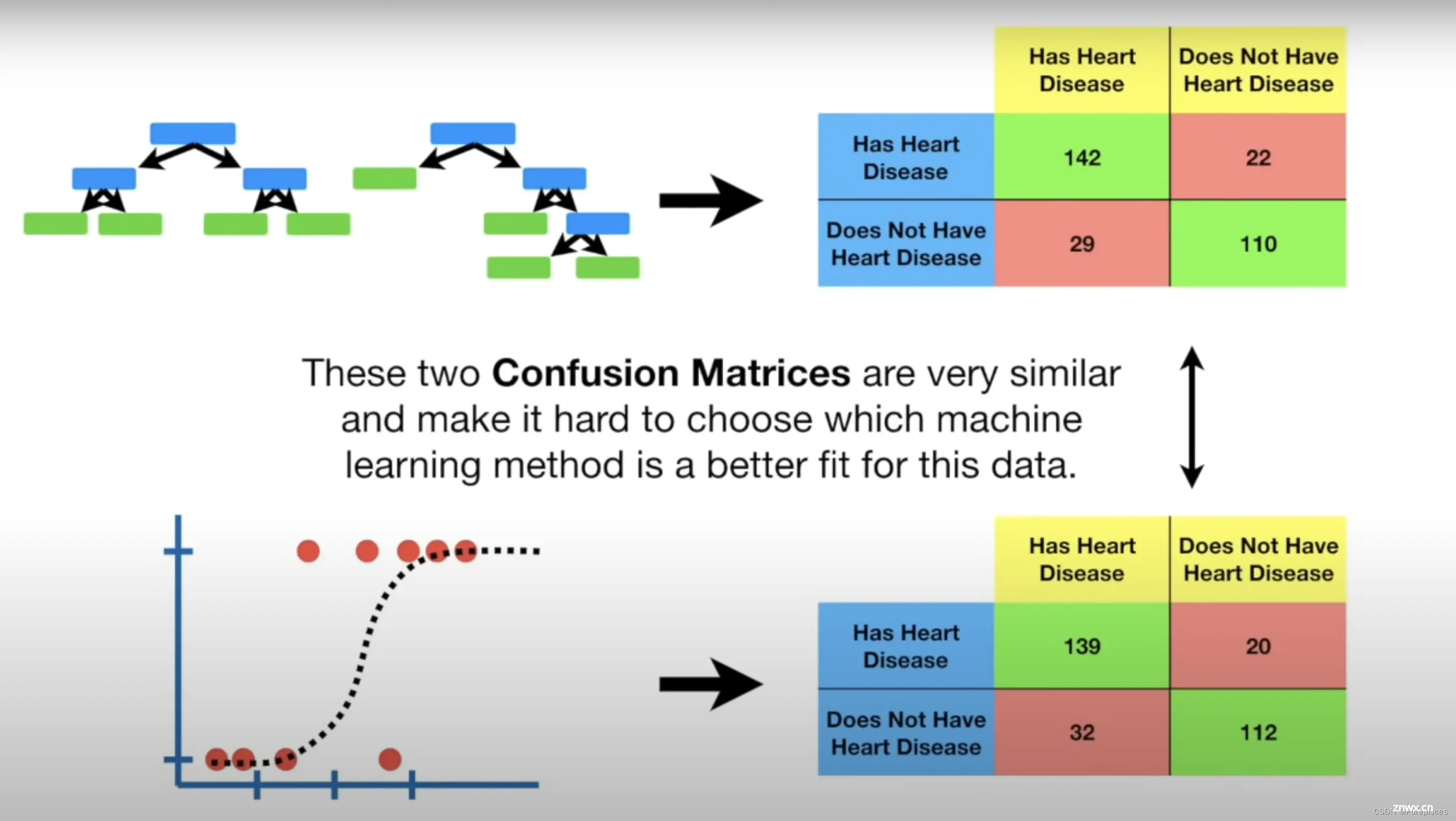
混淆矩阵的行对应于机器学习算法的预测,而列对应于已知的真实情况。由于有两个类别,对于二分类(“有心脏病”或“没有心脏病”),混淆矩阵看起来像这样:左上角包含真正例(TP),即正确识别的心脏病患者。真正负例(TN)在右下角,即正确识别的无心脏病患者。左下角包含假负例(FN),即被错误识别为无心脏病的心脏病患者。右上角包含假正例(FP),即被错误识别为有心脏病的健康患者。
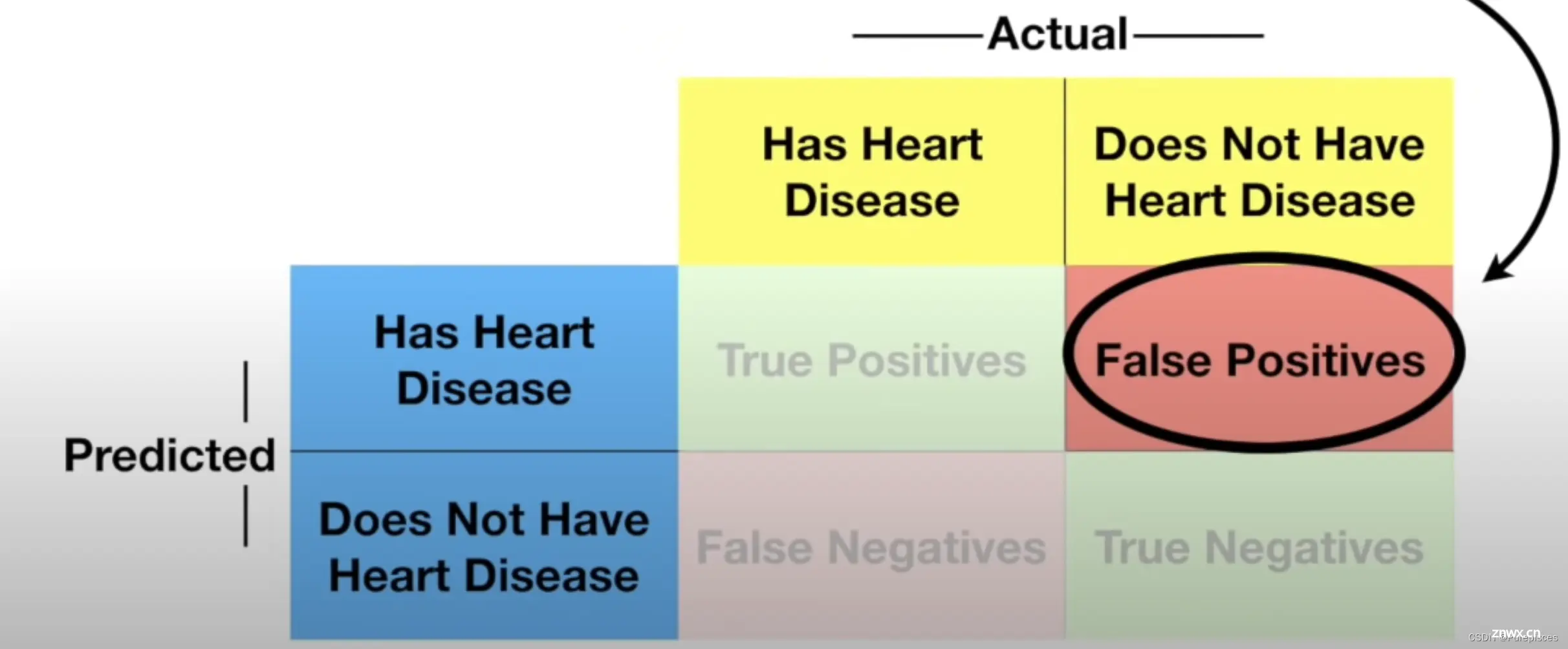
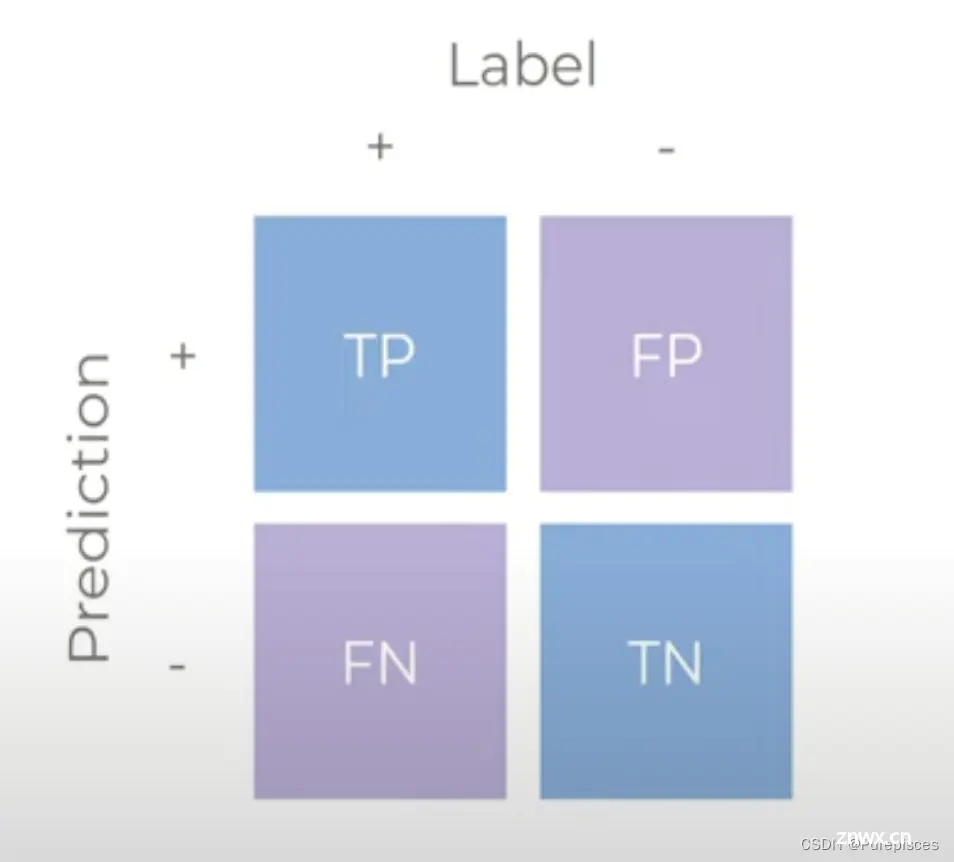
真正例 (TP): 正确识别的心脏病患者。真正负例 (TN): 正确识别的无心脏病患者。假负例 (FN): 被误分类为健康的心脏病患者。假正例 (FP): 被误分类为心脏病患者的健康人。
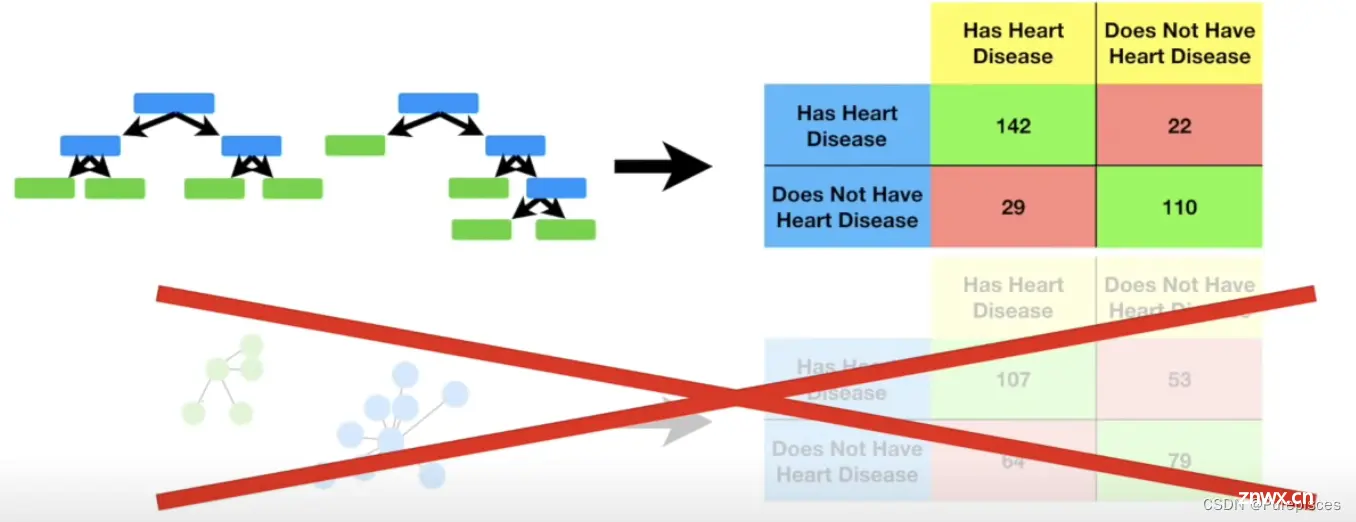
例如,当将随机森林应用于测试数据时,我们得到:
真正例 (TP): 142真正负例 (TN): 110假负例 (FN): 29假正例 (FP): 22
对角线上的数字(绿色框)是正确分类的样本,而非对角线上的数字(红色框)是错误分类的样本。

将随机森林的混淆矩阵与k最近邻算法的混淆矩阵进行比较:
随机森林: TP=142, TN=110k最近邻算法: TP=107, TN=79
由于107 < 142且79 < 110,随机森林的表现更好,因此我们会选择随机森林而不是k最近邻算法。
当应用逻辑回归时,随机森林和逻辑回归的混淆矩阵非常相似,难以选择。我们将在未来讨论更复杂的指标,如敏感性、特异性、ROC和AUC,以帮助做出决定。
多类混淆矩阵
现在,让我们看看一个更复杂的混淆矩阵。
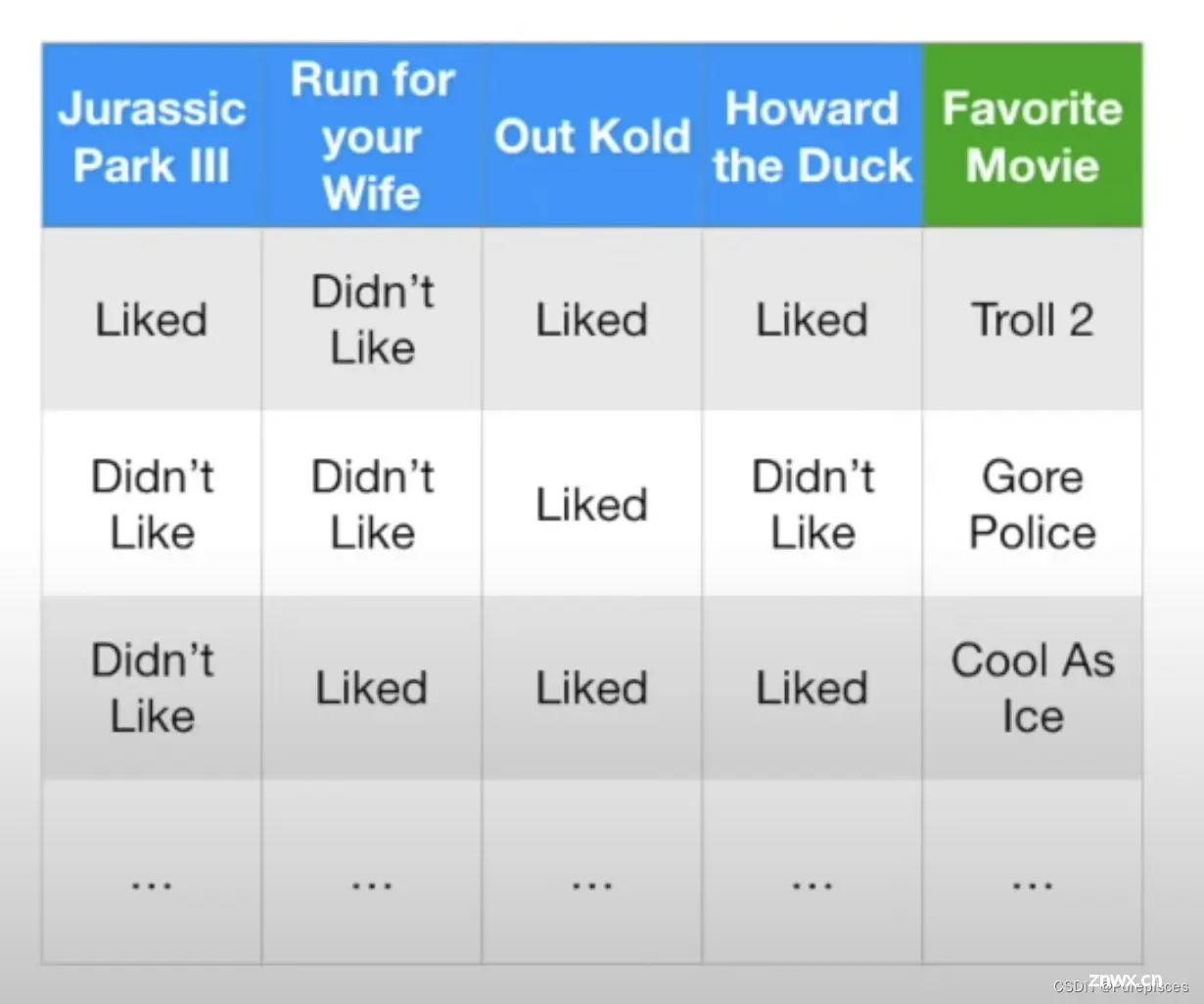
这是一个新的数据集。基于人们对电影《侏罗纪公园III》、《老婆大逃亡》、《Out Kold》和《Howard the Duck》的看法,我们能否使用机器学习方法预测他们最喜欢的电影?
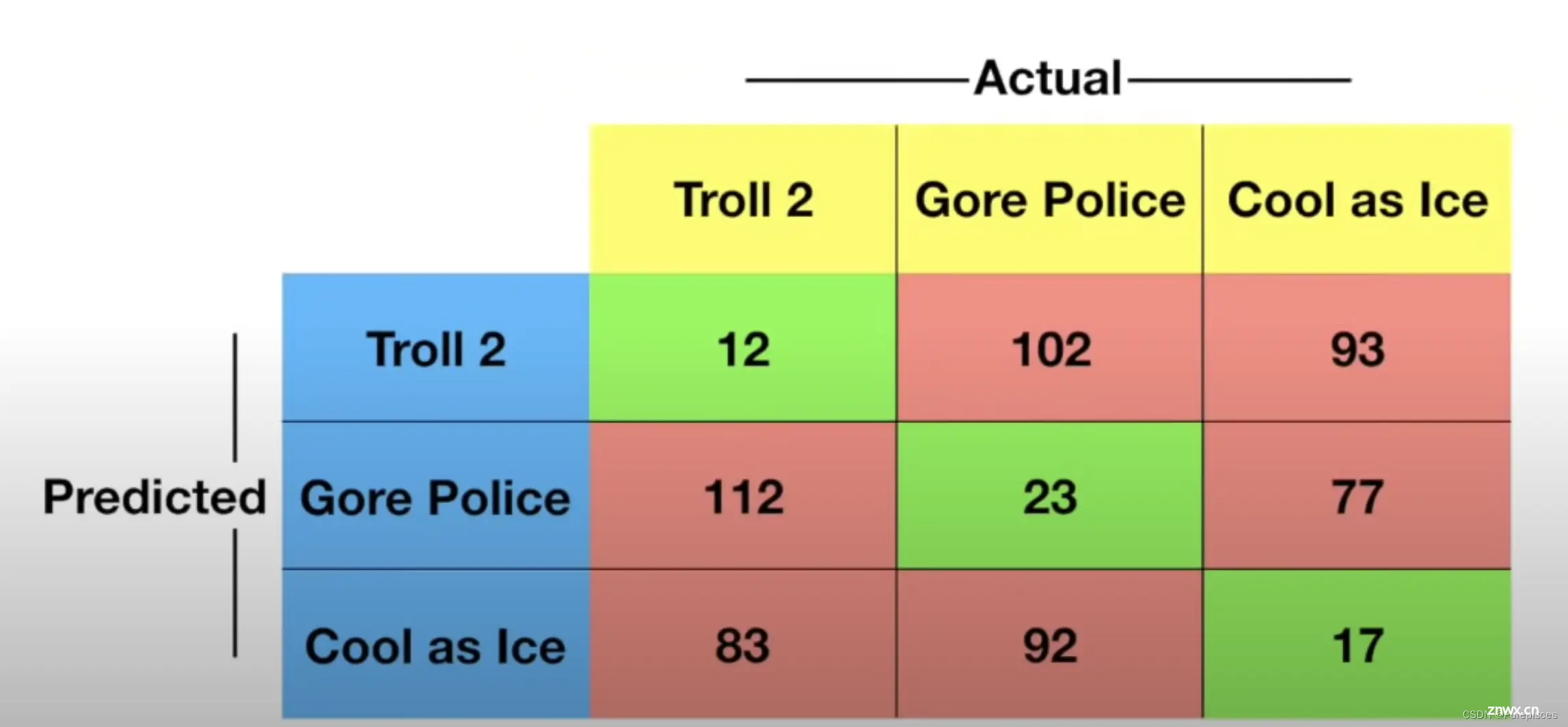
如果最喜欢的电影选项是《Troll 2》、《Gore Police》或《Cool as Ice》,则混淆矩阵将有3行和3列。对角线(绿色框)是机器学习算法做对的地方,其他地方是算法出错的地方。
混淆矩阵的大小取决于预测类别的数量。
2个类别: 2x2混淆矩阵。3个类别: 3x3混淆矩阵。4个类别: 4x4混淆矩阵。40个类别: 40x40混淆矩阵。

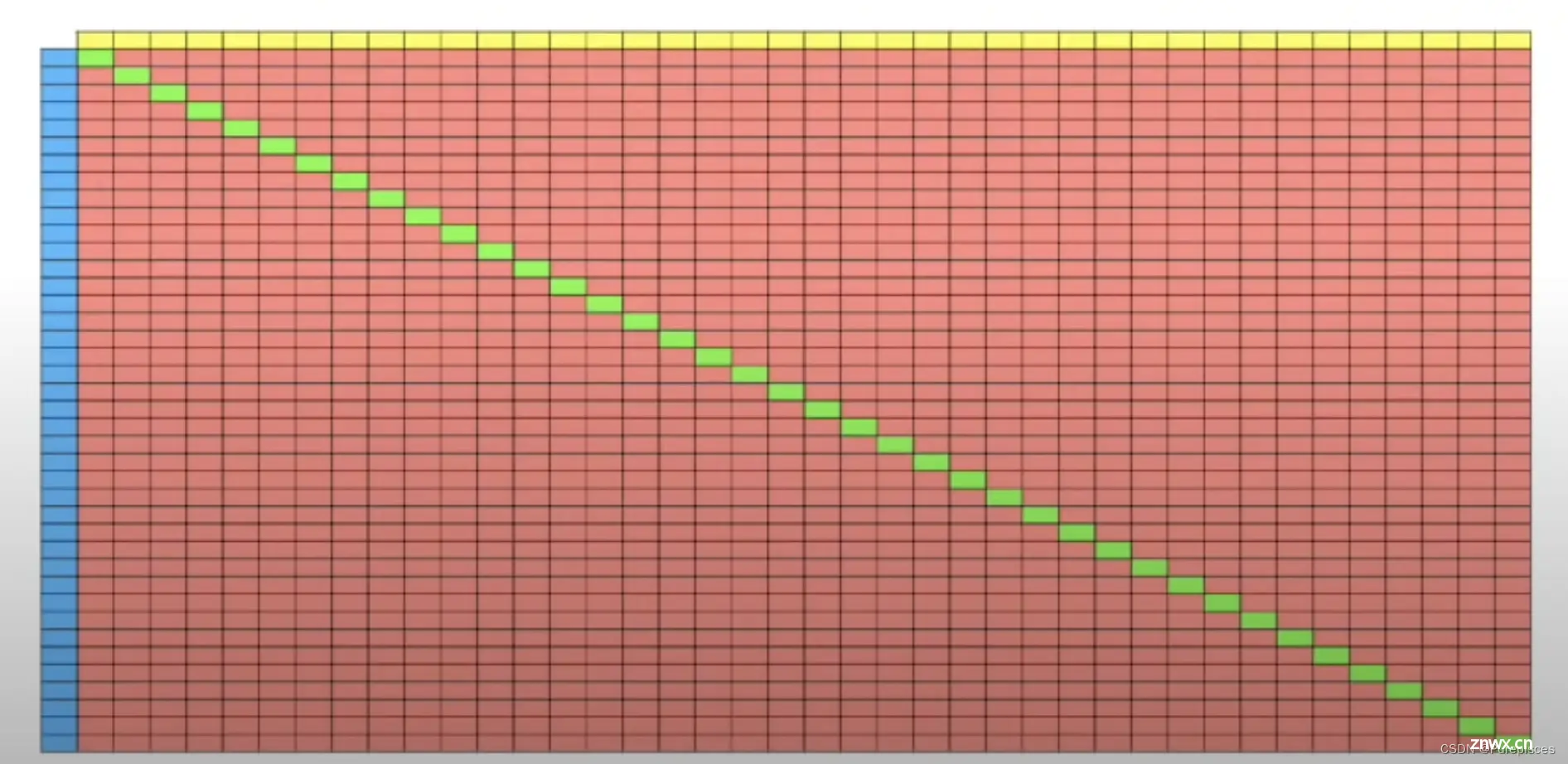
总之,混淆矩阵展示了你的机器学习算法做对和做错的地方。

参考资料:
在YouTube上观看视频图片来源之一:YouTube视频
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。