【AI 大模型】提示工程 ④ ( 自然语言处理 NLG | 自然语言理解 NLU | 自然语言生成 NLG | 使用 提示词 + 大模型 实现 NLU | 使用 提示词 + 大模型 实现 NLG )
CSDN 2024-07-08 17:01:03 阅读 95
文章目录
一、自然语言处理 NLP二、自然语言理解 NLU三、自然语言生成 NLG四、使用 提示词 + 大模型 实现 NLU五、使用 提示词 + 大模型 实现 NLG
一、自然语言处理 NLP
自然语言处理 ( NLP , Natural Language Processing ) , 指的是 " 人工智能 “ " 理解 " 和 ” 生成 " 人类语言的能力 , 包括
识别文本中的意图提取信息回答问题进行推理情感分析语言翻译
等多种任务 , 是一门 交叉学科 , 融合了 语言学、计算机科学、数学 等 多个学科领域 , 使用了如下技术 :
机器学习算法 , 如 : 分类、聚类、序列标注 ;深度学习模型 , 如 : 循环神经网络、Transformer 模型 ;统计模型 ;
自然语言处理 ( NLP , Natural Language Processing ) 主要包含
自然语言理解 ( NLU , Natural Language Understanding )自然语言生成 ( NLG , Natural Language Generation )
两个 子领域 ;
在实际应用中 , 自然语言理解 NLU 和 自然语言理解 NLG 的功能是互补的 ,
NLU 提供了理解用户输入的能力 , 将 自然语言 转为 指定格式的 状态数据 , 如 JSON 格式 / XML 格式 , 计算机可以使用编程语言 处理这些 状态数据 ;NLG 则将 理解后的 状态数据 内容 , 转化为自然语言输出 ;
二、自然语言理解 NLU
自然语言理解 ( NLU , Natural Language Understanding ) 指的是 计算机系统 能够 理解 和 推断 人类语言 的 含义和意图 , 能够 处理和理解 人类语言的复杂性,将 文本输入 转换成 计算机可以操作的形式 , 如 : JSON 或 XML 格式 , 从而支持各种应用程序和系统的开发和改进 ;
自然语言理解 ( NLU , Natural Language Understanding ) 可以实现 :
语义理解意图分类情感分析命名实体识别问答系统
等功能 ;
自然语言理解 ( NLU , Natural Language Understanding ) 工作原理 :
文本预处理 : 对 输入文本数据 进行 分词、文本清洗、归一化等预处理操作 ;语法分析 : 理解句子的 结构 和 语法关系 , 包括 词性标注 和 依存语法分析 ;语义分析 : 理解 文本的语法结构 之后 , 进行 实体识别、关系抽取、意图识别 等语义分析操作 ;语境理解 : 管理 对话状态 和 理解上下文 , 保证 连续对话 的 连贯性 ;
三、自然语言生成 NLG
自然语言生成 ( NLG , Natural Language Generation ) 是一种人工智能技术 , 将 结构化数据 或 非语言格式的数据 转换成人类可以理解的 自然语言文本 ;
自然语言生成 是 自然语言处理 ( NLP , Natural Language Processing ) 领域中的一个重要子领域 , 通过 计算机在特定交互目标下生成语言文本 , 模拟人类语言和思考过程 , 以满足用户对数据和信息的需求 ;
自然语言生成 ( NLG , Natural Language Generation ) 的 步骤 :
确定内容 : 确定包含在 生成 的 文本 中 的信息 , 这个信息比 最终生成的信息 要多 ;文本组织 : 按照语言逻辑 , 组织文本顺序 , 如 : 描述一个事件 , 优先将日期 , 人物 , 场景 描述出来 , 然后描述动作 , 最后描述 结果 ;句子构建 : 选择 单词 和 短语 来构成 完整句子 , 将多个信息合并到一个句子里进行表达 , 并添加 连接词 使内容看起来是一个完整的句子 ;
四、使用 提示词 + 大模型 实现 NLU
GPT 大模型 可以解析 提示词 Prompt 中的 文本信息 , 将其中的关键信息筛选出来 ;
在 提示词 中 , 可以使用如下 话术 , 将 GPT 大模型 的 输出 限定为 JSON 格式 , 并且可以指定每个 JSON 字段的名称和值 , 以及值的类型 ;
<code>以JSON格式输出。
1. xxx字段的取值为xxx类型,取值是xxx;
实现 NLU 的 提示词 模板如下 :
# prompt 模版
prompt = f"""
{ instruction}
{ output_format}
用户输入:
{ input_text}
"""
instruction 字符串 用于描述 要处理的任务要求 , 一般都是 你的任务是识别用户输入的内容。xxx。根据用户输入,识别用户的xxx种属。
# 任务描述
instruction = """
你的任务是识别用户输入的内容。
这是一个高考志愿推荐系统,识别出考生姓名,考生所在的省份,考生的分数。
根据用户输入,识别用户的上述三种属。
"""
output_format 字符串 用于描述 输出格式 :
# 输出描述
output_format = """
以JSON格式输出。
1. name字段的取值为string类型,取值是考生的姓名;
2. province字段的取值为string类型,取值是考生所在的省份;
3. score字段的取值为int类型,取值是考生的考试分数;
只输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段,不输出值为null的字段。
"""
input_text 字符串 是 用户输入 , instruction 和 output_format 参数是固定的 , 但是 input_text 参数 每次都要重新拼接进去 ;
# 用户输入
input_text = """
我叫韩曙亮,河北省的高考考生,高考成绩485分,我能上清华大学吗,我劝你耗子尾汁,给我一个肯定的答复。
"""
在下面的代码中 , 使用 Python 语言 调用 OpenAI 的 API , 输入上述提示词 , 可以自动获取 包含 指定 字段 的 JSON 输出结果 ;
代码示例 :
from openai import OpenAI
client = OpenAI(
api_key="sk-6o3KJuuocEXpb1Ug39D0A4913a844fCaBa892eDe9814Df8a",code>
base_url="https://api.xiaoai.plus/v1",code>
)
# 任务描述
instruction = """
你的任务是识别用户输入的内容。
这是一个高考志愿推荐系统,识别出考生姓名,考生所在的省份,考生的分数。
根据用户输入,识别用户在上述三种属。
"""
# 输出描述
output_format = """
以JSON格式输出。
1. name字段的取值为string类型,取值是考生的姓名;
2. province字段的取值为string类型,取值是考生所在的省份;
3. score字段的取值为int类型,取值是考生的考试分数;
只输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段,不输出值为null的字段。
"""
# 用户输入
input_text = """
我叫韩曙亮,河北省的高考考生,高考成绩485分,我能上清华大学吗,我劝你耗子尾汁,给我一个肯定的答复。
"""
# prompt 模版
prompt = f"""
{ instruction}
{ output_format}
用户输入:
{ input_text}
"""
completion = client.chat.completions.create(
model="gpt-3.5-turbo",code>
messages=[
{ "role": "user", "content": prompt}
],
temperature=0, # 要生成稳定的状态数据 , 设置最小随机性
)
print(completion.choices[0].message.content)
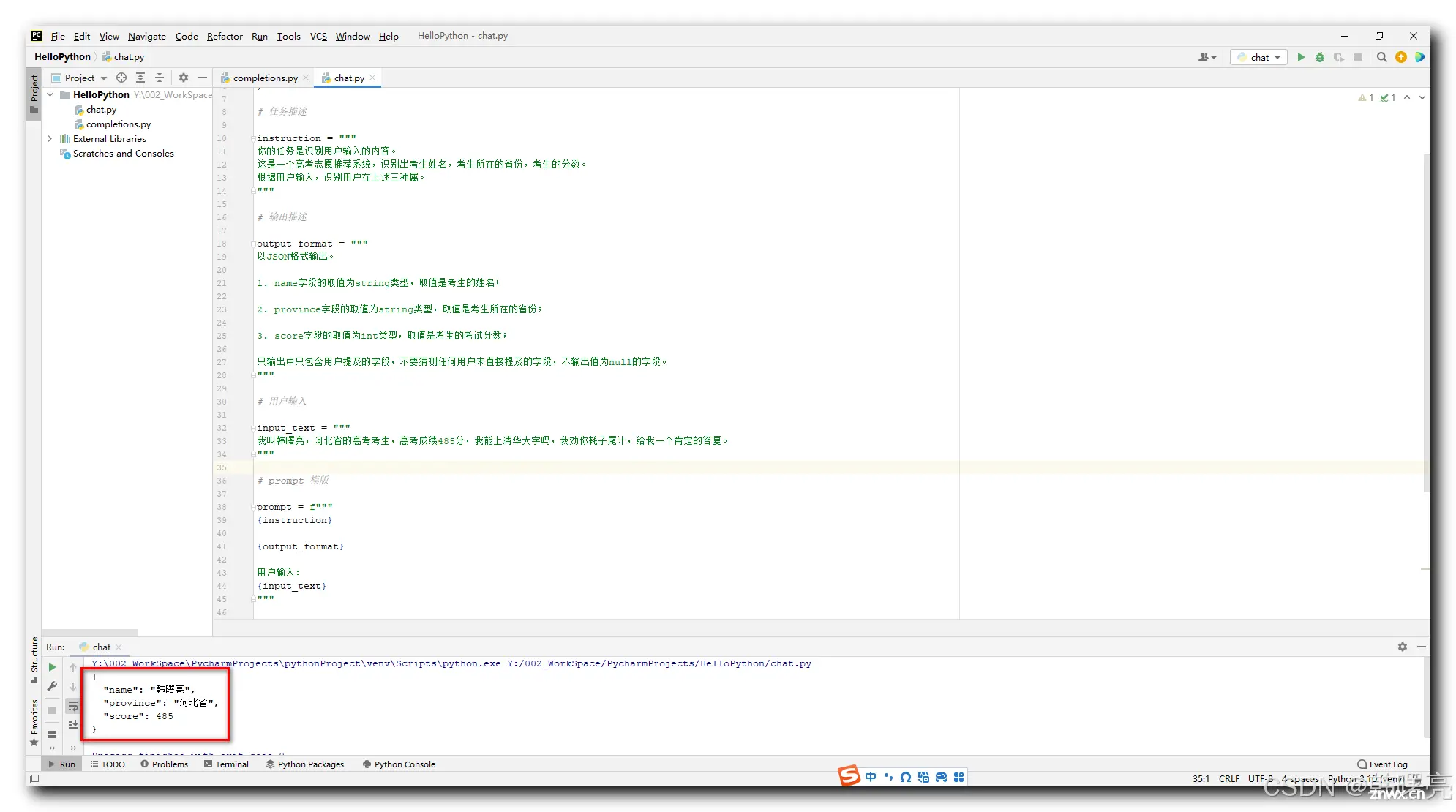
执行结果 : 最终得到一个 JSON 格式的输出结果 ;
{
"name": "韩曙亮",
"province": "河北省",
"score": 485
}
五、使用 提示词 + 大模型 实现 NLG
自然语言生成 ( NLG , Natural Language Generation ) 是 将 格式化的 状态数据 转为 自然语言文本 ;
在上面的 NLU 中 , 将用户输入的语言 , 处理后得到 JSON 数据如下 :
<code>{
"name": "韩曙亮",
"province": "河北省",
"score": 485
}
在本 NLG 示例中 , 给定上述 JSON 数据 , 在任务描述中 , 解释每个字段的作用 ,
# 任务描述
instruction = """
你的任务是识别用户输入的内容。
这是一个高考志愿推荐系统,name字段是考生姓名,province字段是考生所在的省份,score字段是考生的分数。
给出一个高考志愿推荐。
"""
在 输出描述 中 , 针对不同的参数给出不同的操作 ;
# 输出描述
output_format = """
给出高考志愿推荐。
650分以上推荐清华大学。
550分以上推荐河北农业大学。
450分以上推荐衡水学院。
语气要委婉,口语化,亲切一些。
"""
将上述 任务描述 , 输出描述 , 用户输入 , 组合成提示词 ;
# 任务描述
instruction = """
你的任务是识别用户输入的内容。
这是一个高考志愿推荐系统,name字段是考生姓名,province字段是考生所在的省份,score字段是考生的分数。
给出一个高考志愿推荐。
"""
# 输出描述
output_format = """
给出高考志愿推荐。
650分以上推荐清华大学。
550分以上推荐河北农业大学。
450分以上推荐衡水学院。
语气要委婉,口语化,亲切一些。
"""
# 用户输入
input_text = """
{
"name": "韩曙亮",
"province": "河北省",
"score": 485
}
"""
# prompt 模版
prompt = f"""
{ instruction}
{ output_format}
用户输入:
{ input_text}
"""
代码示例 :
from openai import OpenAI
client = OpenAI(
api_key="sk-6o3KJuuocEXpb1Ug39D0A4913a844fCaBa892eDe9814Df8a",code>
base_url="https://api.xiaoai.plus/v1",code>
)
# 任务描述
instruction = """
你的任务是识别用户输入的内容。
这是一个高考志愿推荐系统,name字段是考生姓名,province字段是考生所在的省份,score字段是考生的分数。
给出一个高考志愿推荐。
"""
# 输出描述
output_format = """
给出高考志愿推荐。
650分以上推荐清华大学。
550分以上推荐河北农业大学。
450分以上推荐衡水学院。
语气要委婉,口语化,亲切一些。
"""
# 用户输入
input_text = """
{
"name": "韩曙亮",
"province": "河北省",
"score": 485
}
"""
# prompt 模版
prompt = f"""
{ instruction}
{ output_format}
用户输入:
{ input_text}
"""
completion = client.chat.completions.create(
model="gpt-3.5-turbo",code>
messages=[
{ "role": "user", "content": prompt}
],
temperature=0, # 要生成稳定的状态数据 , 设置最小随机性
)
print(completion.choices[0].message.content)
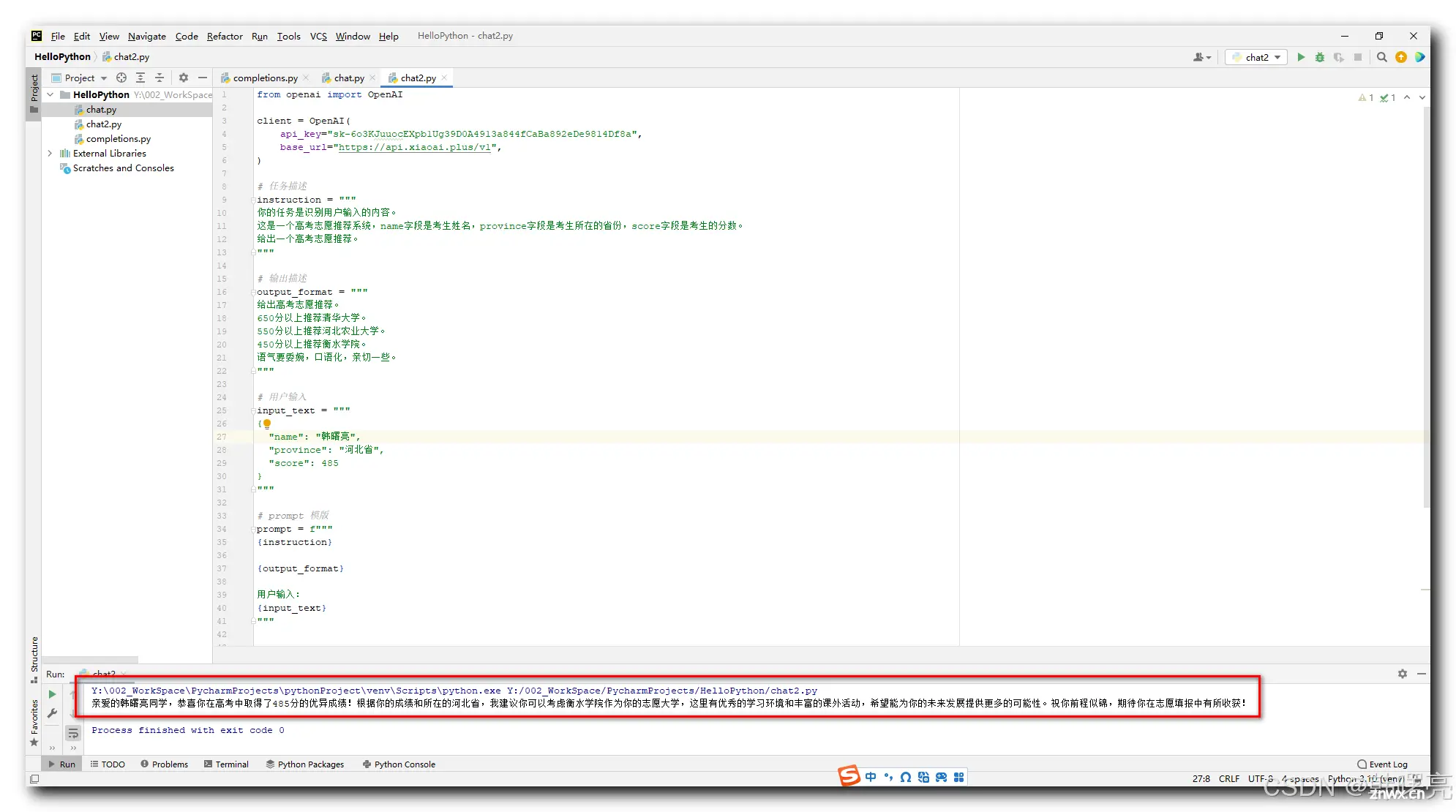
执行结果 :
亲爱的韩曙亮同学,恭喜你在高考中取得了485分的优异成绩!根据你的成绩和所在的河北省,我建议你可以考虑衡水学院作为你的志愿大学,这里有优秀的学习环境和丰富的课外活动,希望能为你的未来发展提供更多的可能性。祝你前程似锦,期待你在志愿填报中有所收获!
上一篇: 【Text-to-CAD】基于生成式AI的CAD文件生成工具
下一篇: 深度学习环境配置(pytorch版本)----超级无敌详细版(有手就行)
本文标签
【AI 大模型】提示工程 ④ ( 自然语言处理 NLG | 自然语言理解 NLU | 自然语言生成 NLG | 使用 提示词 + 大模型 实现 NLU | 使用 提示词 + 大模型 实现 NLG )
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。